↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) often generate inaccurate or biased information, hindering their real-world deployment. Existing methods for mitigating this, such as retraining, can be computationally expensive and may negatively impact other model capabilities. This paper addresses this limitation by focusing on editing internal representations of LLMs at inference time.
This paper introduces Spectral Editing of Activations (SEA), a novel inference-time editing technique. SEA projects input representations into directions that maximize covariance with positive examples (e.g., truthful statements) and minimize covariance with negative examples (e.g., hallucinations). Extensive experiments across different LLMs demonstrate SEA’s effectiveness in improving truthfulness and fairness, with only a small impact on other model capabilities. The method also offers computational and data efficiency, requiring fewer demonstrations for effective editing.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model alignment because it introduces a novel, training-free method (SEA) to improve truthfulness and reduce bias. SEA’s efficiency and generalizability across different LLMs makes it highly relevant to current research trends. This opens new avenues for research focusing on inference-time editing techniques and their applications in improving LLM capabilities while minimizing negative side effects.
Visual Insights#
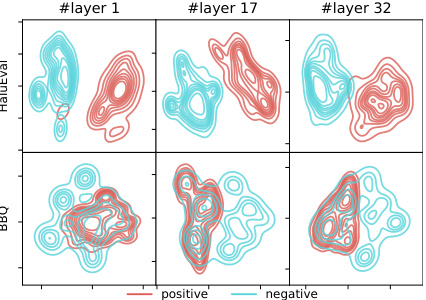
This figure shows the t-distributed Stochastic Neighbor Embedding (t-SNE) visualization of the activations of the LLaMA-2-chat-7B language model. The plot displays the activations from the first, seventeenth, and thirty-second layers. Activations from positive (truthful) and negative (hallucinatory) examples from two datasets, HaluEval and BBQ, are shown separately. The visualization aims to illustrate the degree of separation between the positive and negative examples in the activation space, suggesting the potential for editing these representations to improve the model’s behavior.
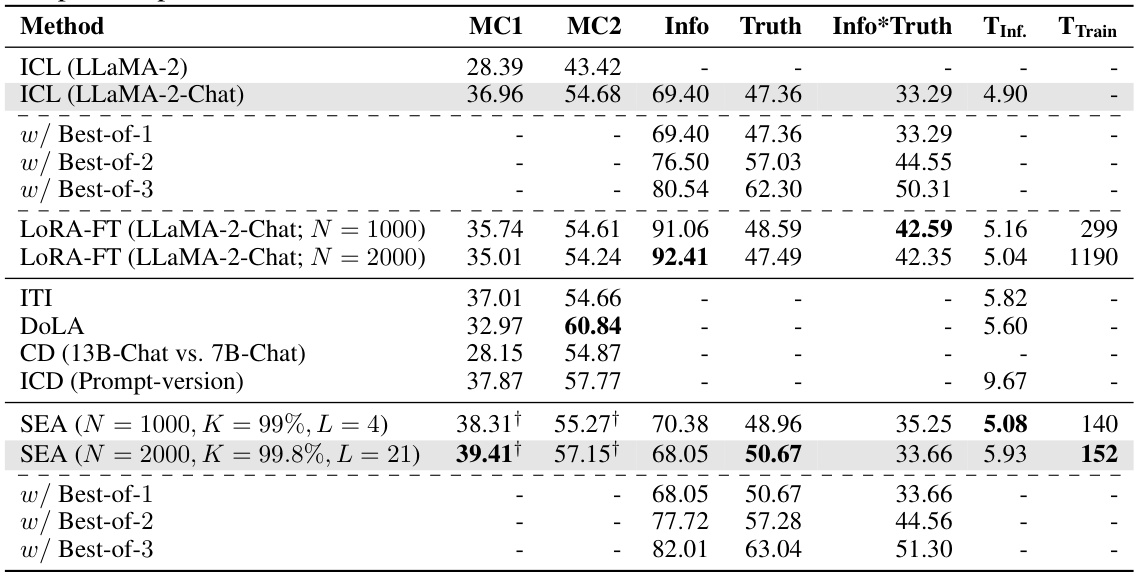
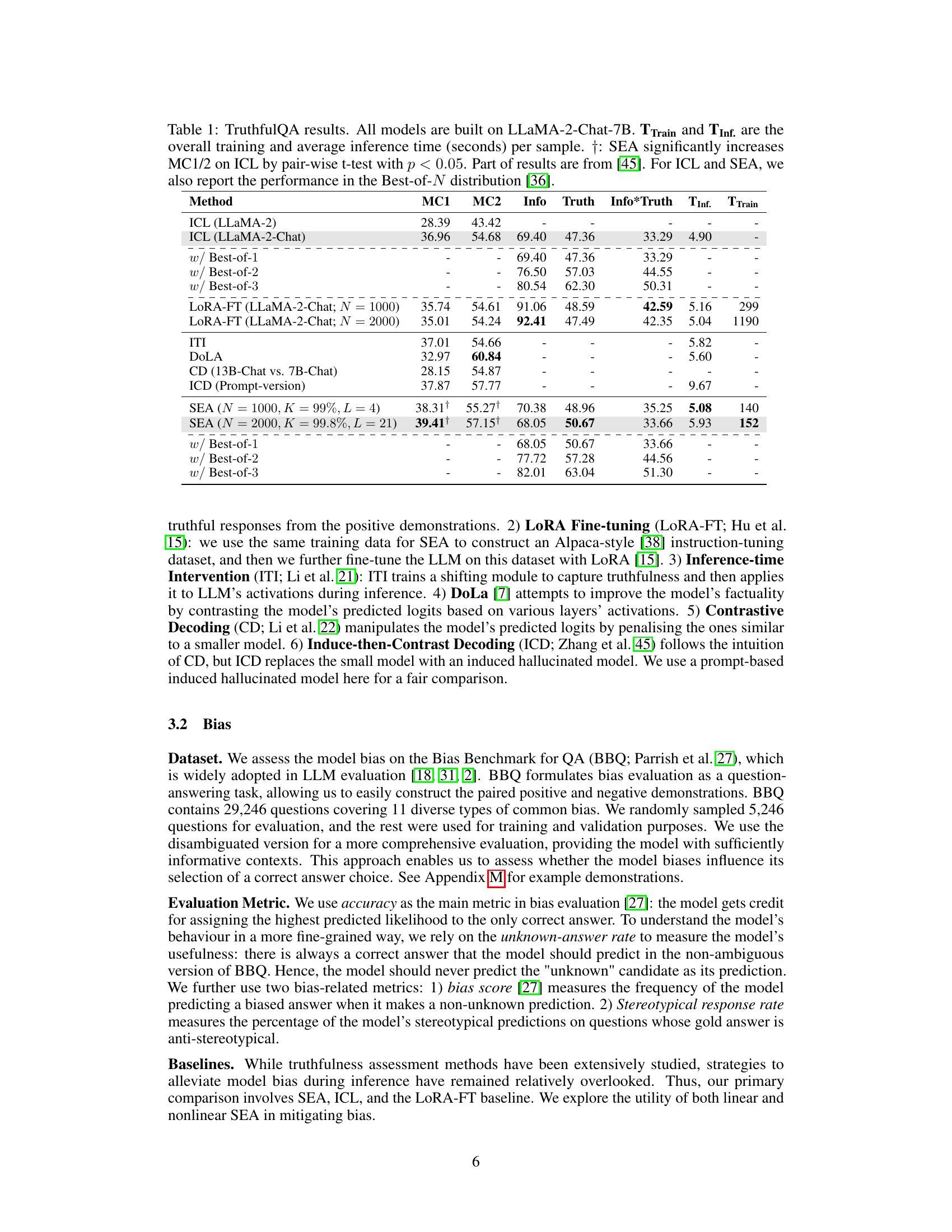
This table presents the results of several methods on the TruthfulQA benchmark, focusing on truthfulness evaluation. It compares the performance of In-Context Learning (ICL), LoRA Fine-tuning (LoRA-FT), Inference-time Intervention (ITI), Decoding by contrasting layers (DoLA), Contrastive Decoding (CD), Induce-then-Contrast Decoding (ICD), and Spectral Editing of Activations (SEA). The metrics include MC1, MC2, Info, Truth, Info*Truth, inference time (TInf.), and training time (TTrain). Best-of-N results are also shown for ICL and SEA to demonstrate the impact of ensemble methods.
In-depth insights#
Spectral Activation Edits#
Spectral activation editing presents a novel approach to manipulating large language model (LLM) behavior by directly modifying internal representations. This method avoids retraining, offering a computationally efficient alternative to traditional fine-tuning. By utilizing spectral decomposition, the technique identifies and selectively modifies activation patterns most strongly associated with positive (desired) or negative (undesired) model outputs. The core idea is to project input representations onto directions maximizing covariance with positive examples while minimizing covariance with negative ones. This can achieve improvements in aspects like truthfulness and fairness, with minimal impact on other LLM capabilities. Linear methods are simpler but might not capture complex non-linear relationships in activation spaces. Extending the approach to non-linear editing through feature functions could unlock improved performance on more nuanced tasks. Overall, spectral activation editing offers an innovative, efficient, and promising technique for LLM alignment, but limitations like potential negative impact on control tasks and the complexity of non-linear approaches warrant further investigation.
Truthfulness & Fairness#
This research explores the crucial aspects of truthfulness and fairness in large language models (LLMs). The study highlights the challenge LLMs face in generating accurate and unbiased information, often producing inaccurate or biased content. The core of the research lies in proposing a novel method, Spectral Editing of Activations (SEA), designed to mitigate these issues by manipulating the model’s internal representations. SEA’s effectiveness is demonstrated through extensive experiments, evaluating its ability to improve truthfulness and reduce bias in various LLM architectures. The results showcase a significant improvement in model performance, emphasizing SEA’s potential as a valuable technique to enhance LLM alignment. The study delves into both linear and non-linear approaches to SEA, acknowledging and addressing limitations such as the impact on other model capabilities. Ultimately, the research positions SEA as a promising method for improving LLM reliability and ethical behaviour, offering a path toward more trustworthy and equitable AI systems.
Non-Linear SEA#
The concept of “Non-Linear SEA” extends the capabilities of Spectral Editing of Activations (SEA) by addressing the limitation of linearity in capturing complex relationships within large language model (LLM) activation spaces. Linear SEA, relying on Singular Value Decomposition (SVD), struggles to effectively edit activations when the relationship between positive and negative demonstrations isn’t linearly separable. This is a significant drawback since LLMs often exhibit non-linear behavioral patterns, such as bias or factual inaccuracy, which cannot be adequately addressed by a purely linear approach. Non-Linear SEA introduces invertible non-linear feature functions to map the original activation space into a richer, potentially higher-dimensional space where linear separability may be achieved. This transformation enables the application of the core SEA methodology (SVD-based projection), followed by an inverse transformation back to the original activation space. The choice of non-linear function is crucial, and the paper likely explores different options, each with its tradeoffs in terms of computational cost, the ability to preserve model performance and how effectively it disentangles the desired behaviors. This innovative approach is essential for improved effectiveness in scenarios where linear editing fails to adequately capture the nuances of LLM behavior, resulting in more robust and effective manipulation of LLM outputs.
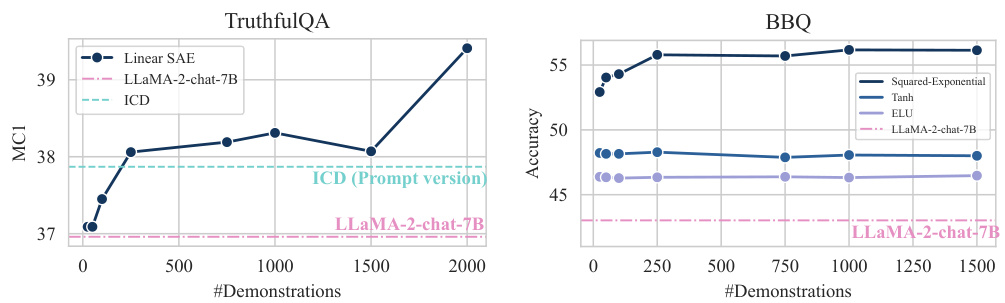
Data Efficiency Gains#
Achieving data efficiency is crucial for the practical application of machine learning models, especially in resource-constrained settings. A key aspect of data efficiency is reducing the amount of training data needed to achieve high performance. The ability of the proposed method to achieve significant improvements using only 25 demonstrations highlights its effectiveness. This is particularly noteworthy given the high computational cost and data requirements typically associated with large language models. This data efficiency stems from the method’s clever design. The algorithm does not require iterative optimization to find a target module, but instead utilizes a closed-form spectral decomposition. This makes the algorithm computationally efficient, reducing the computational burden and enabling faster training cycles. The remarkable data efficiency not only lowers the barrier to entry for leveraging LLMs but also opens doors to applications where data acquisition is challenging or expensive. The ability to achieve such improvements with limited data points is significant and suggests potential for broader applicability in resource-scarce scenarios and situations where obtaining sufficient data is difficult or costly.
SEA Generalization#
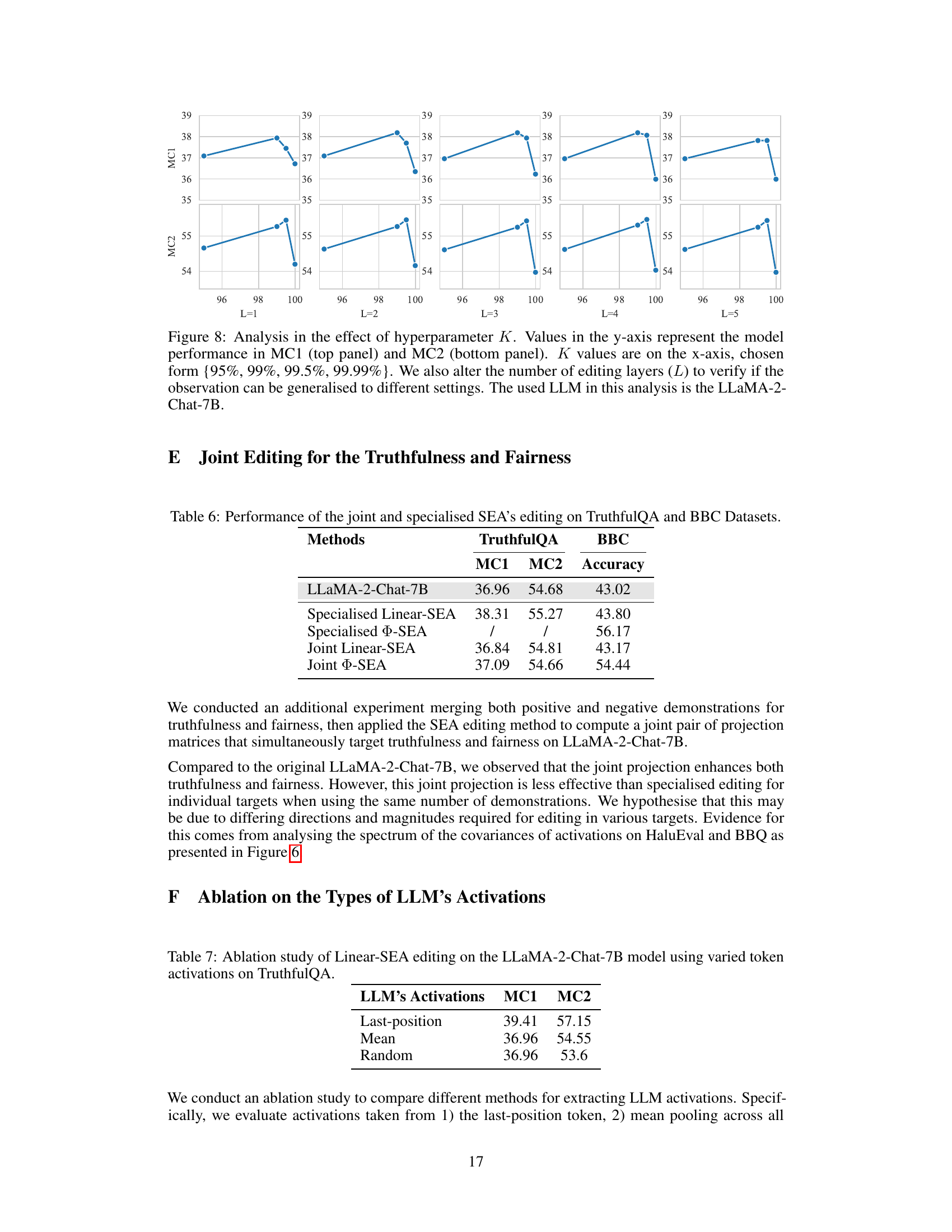
The heading ‘SEA Generalization’ suggests an investigation into the breadth of applicability of the Spectral Editing of Activations (SEA) method. A thoughtful analysis would explore how well SEA transfers to different LLMs, tasks, and datasets. Key aspects to consider include the consistency of performance improvements across various LLM architectures (e.g., Transformer-based models of different sizes and training data), different downstream tasks (beyond truthfulness and fairness, such as question answering, summarization, or translation), and diverse datasets (assessing generalization to datasets with different biases or characteristics). Furthermore, a robust analysis should delve into whether the hyperparameters of SEA need significant adjustments across different contexts or if they remain relatively stable, indicating the model’s ability to adapt. The extent to which the benefits of SEA scale with the number of demonstrations used for training the projection matrices is also crucial. Finally, a comprehensive evaluation should assess whether SEA’s improvements generalize to tasks that are significantly different from those used in its development, demonstrating a true capacity for generalization and broader applicability. A thorough examination of these factors will determine the robustness and practical value of SEA for wider deployment in real-world applications.
More visual insights#
More on figures

This figure illustrates the two-stage process of Spectral Editing of Activations (SEA). The left side shows the offline stage where editing projections are calculated using spectral decomposition on positive, negative, and neutral demonstrations. The right side depicts the online inference stage where these pre-calculated projections are applied to manipulate the LLM’s predictions. This method modifies the LLM’s internal representations to encourage positive behavior and discourage negative behavior, without requiring further training.

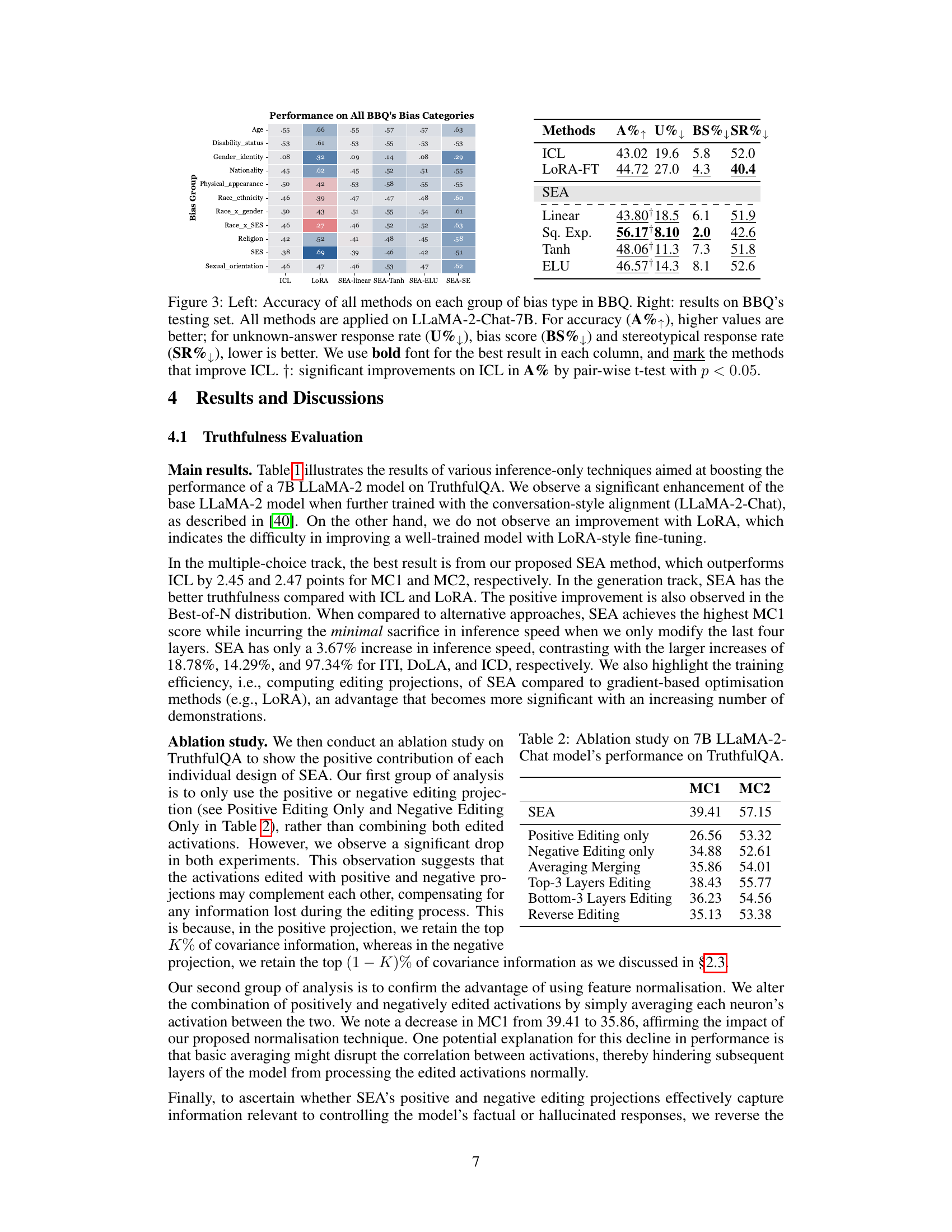
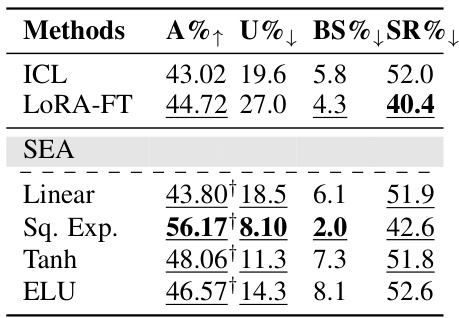
This figure shows the performance of different methods on the Bias Benchmark for QA (BBQ) dataset. The left panel displays the accuracy of In-Context Learning (ICL), LoRA Fine-tuning (LoRA-FT), and Spectral Editing of Activations (SEA) methods, broken down by bias category. The right panel presents an overall comparison of the methods across all bias categories using four metrics: accuracy (A%↑), unknown answer rate (U%↓), bias score (BS%↓), and stereotypical response rate (SR%↓). Higher accuracy is better, while lower values are preferred for the other three metrics. The table highlights statistically significant improvements over the ICL baseline.
This figure shows a t-SNE plot visualizing the activations of the LLaMA-2-chat-7B large language model. The plot separates activations into clusters based on whether the model’s generated text is considered positive (truthful, unbiased; shown in blue) or negative (hallucinatory, biased; shown in red). The data used to generate the plot comes from the HaluEval and BBQ benchmark datasets. The visualization helps illustrate the potential for separating positive and negative model behaviors in the activation space, suggesting that targeted modifications to these activations might be effective for improving model behavior.

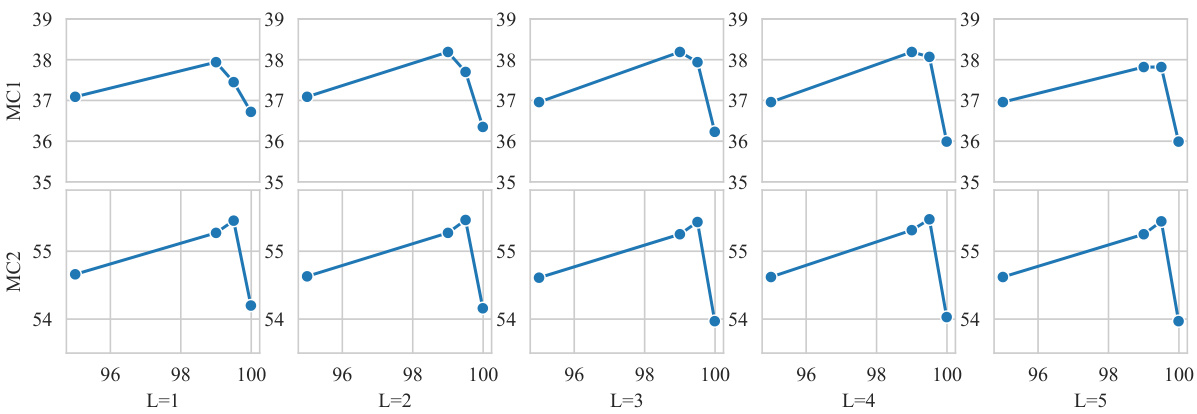
The figure visualizes the signature values across all layers of six different LLMs on the HaluEval dataset. The signature value represents the amount of information related to the model’s truthfulness contained within the layer’s activations. The graph shows that for most LLMs, this value is highest in the top layers, suggesting that higher-level reasoning and generation tasks are primarily responsible for truthfulness; however, the model Gemma shows a slightly different trend, with some bottom layers also containing significant truthfulness-related information.
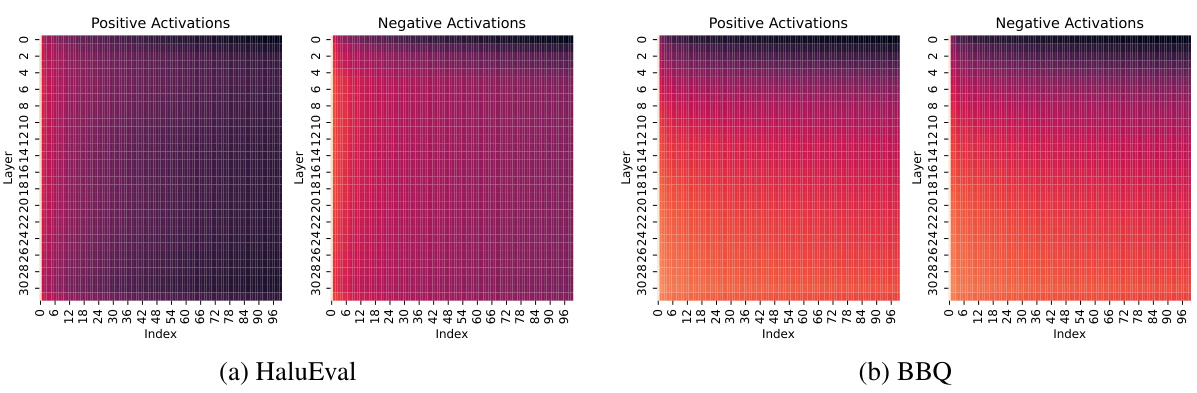
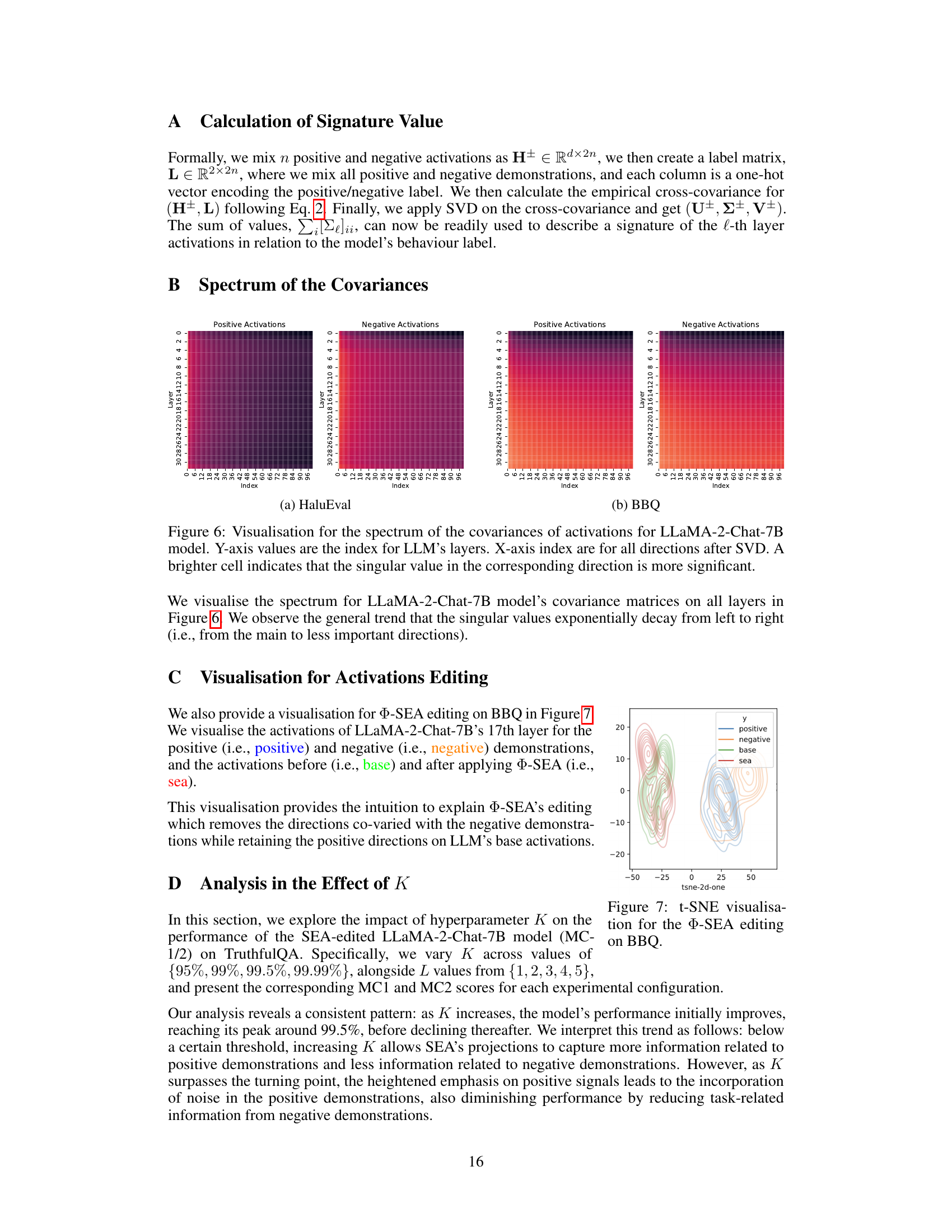
This figure visualizes the spectrum of covariances of activations for the LLaMA-2-Chat-7B model. The y-axis represents the index of the LLM layers, while the x-axis represents the index of all directions after singular value decomposition (SVD). The brightness of each cell indicates the significance of the singular value in the corresponding direction. Brighter colors mean higher significance.

This figure visualizes the effect of applying non-linear spectral editing of activations (Φ-SEA) on the BBQ dataset. It uses t-SNE to project high-dimensional LLM activations into a 2D space for visualization. The plot shows the distributions of activations for positive demonstrations (blue), negative demonstrations (orange), the original, unedited activations (green), and the activations after applying Φ-SEA (red). The visualization demonstrates how Φ-SEA shifts the distribution of the LLM’s activations, reducing the overlap between positive and negative examples and moving them towards the positive ones. This illustrates the method’s ability to non-linearly steer LLM behavior towards more desirable outputs.
This figure shows a t-SNE plot visualizing the activations of the LLaMA-2-chat-7B large language model. The plot displays how activations for positive (truthful) and negative (hallucinated) demonstrations from the HaluEval and BBQ datasets cluster in the activation space. The clustering suggests a degree of separability between truthful and hallucinated outputs in the model’s internal representations. This visualization supports the idea that editing LLM activations could be an effective technique for steering model behavior toward more truthful outputs.
More on tables
This table presents the results of applying ICL, linear SEA, and non-linear SEA to six different open-source LLMs on two datasets: BBQ and TruthfulQA. For each LLM and method, it shows the percentage increase/decrease in accuracy, unknown answer rate, bias score, and stereotypical response rate (BBQ) as well as the percentage increase in MC1 and MC2 scores (TruthfulQA). Improvements and worsens are highlighted to show the effectiveness of the proposed methods. The table aims to demonstrate the generalizability of the SEA approach across various LLMs.
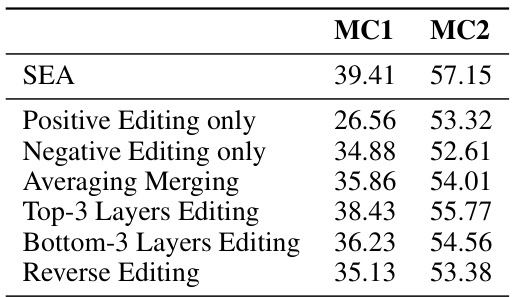
This table presents the results of an ablation study conducted to evaluate the contribution of each individual component of the SEA method on the TruthfulQA benchmark using the 7B LLaMA-2-Chat model. It shows the MC1 and MC2 scores for the full SEA method and variations where only positive or negative editing is used, averaging is performed instead of merging, only the top or bottom three layers are edited, and when the editing projections are reversed. The results highlight the importance of using both positive and negative projections, merging the edited activations, using the top layers and correctly orientating the edits for optimal performance.
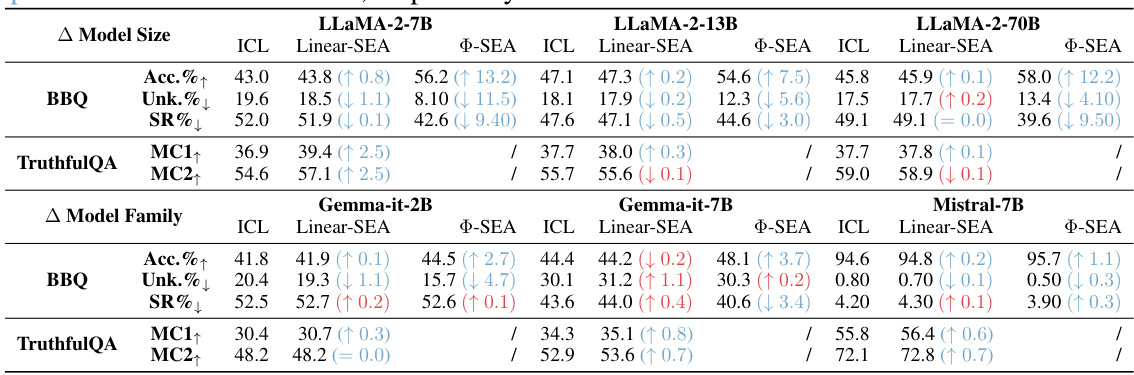
This table presents the results of applying three different methods (ICL, Linear SEA, and non-linear SEA) to six different open-source LLMs. The performance is evaluated on two benchmarks: BBQ (Bias Benchmark for QA) and TruthfulQA. For BBQ, the metrics are accuracy, unknown answer rate, and stereotypical response rate. For TruthfulQA, the metrics are MC1 and MC2 scores. The table highlights whether the performance of each method improves or worsens compared to the baseline (ICL).

This table presents the results of evaluating the LLaMA-2-Chat-7B model and three variants modified using Spectral Editing of Activations (SEA) on six different tasks. These tasks assess various aspects of language model capabilities, including multi-task performance, commonsense reasoning, and mathematical abilities. The table shows the performance of each model on each task, allowing for a comparison of the impact of SEA on these diverse capabilities. Note that the details of the evaluation methodology are described in Appendix H.4 of the paper.

This table presents the results of applying three different SEA methods (linear SEA, squared exponential Φ-SEA, and tanh Φ-SEA) on the CrowS-Pairs dataset, using demonstrations from the BBQ dataset. It evaluates the generalization of SEA’s bias-mitigating effects to a new dataset with similar bias categories. For each bias category and method, the table shows the percentage of stereotypical responses predicted by the model. Lower values indicate better performance, indicating less bias in the model’s output.

This table compares the performance of different spectral editing of activations (SEA) methods on two benchmark datasets: TruthfulQA (for truthfulness) and BBC (for bias). It contrasts the results of applying SEA in a specialized way (focused on either truthfulness or bias) versus a joint approach (targeting both simultaneously). The metrics used are MC1 and MC2 for TruthfulQA, and Accuracy for BBC. The table shows that specialized SEA outperforms the joint approach, suggesting that focusing on one attribute at a time yields better results.
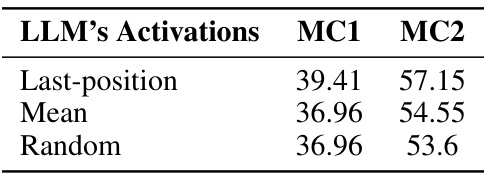
This table presents the results of an ablation study conducted to evaluate the impact of different methods for extracting LLM activations on the performance of Linear-SEA on the TruthfulQA benchmark. The study compared three methods: using activations from the last token, the mean of all tokens, and randomly selected tokens. The MC1 and MC2 scores are reported for each method, demonstrating the impact of activation selection on the model’s performance.
This table presents the results of different methods on the TruthfulQA benchmark, focusing on the multiple-choice question answering task. It compares the performance of In-Context Learning (ICL), LoRA fine-tuning, Inference-time Intervention (ITI), Decoding with Layer Attention (DOLA), Contrastive Decoding (CD), Induce-then-Contrast Decoding (ICD), and the proposed Spectral Editing of Activations (SEA) method. The metrics used are MC1, MC2, Info, Truth, and Info*Truth, along with inference and training times. The table highlights SEA’s superior performance and efficiency, particularly in conjunction with the Best-of-N evaluation strategy.
Full paper#