TL;DR#
Generating realistic and synchronized audio from silent videos (V2A) is challenging due to issues like low audio quality, poor temporal alignment between audio and visual content, and slow generation speed. Existing methods often struggle to balance these aspects, leading to suboptimal results. Autoregressive models struggle with temporal alignment and efficiency, while diffusion models require numerous steps for high quality, impacting efficiency.
FRIEREN tackles these issues with a novel approach. By employing ‘rectified flow matching,’ FRIEREN efficiently regresses the transport vector field from noise to spectrogram latents, enabling faster generation. The model incorporates a non-autoregressive vector field estimator with strong temporal alignment, facilitating synchronized audio output. Further efficiency improvements are achieved through ‘reflow’ and ‘one-step distillation,’ allowing for high-quality audio generation with minimal sampling steps. Experiments on VGGSound demonstrate FRIEREN’s superiority in audio quality, alignment, and speed compared to state-of-the-art baselines.
Key Takeaways#
Why does it matter?#
This paper is important because it presents FRIEREN, a novel and efficient video-to-audio generation network that achieves state-of-the-art performance. It addresses the challenges of audio quality, temporal synchronization, and generation efficiency in V2A, offering a significant advancement over existing methods. The use of rectified flow matching and innovative techniques like reflow and one-step distillation opens new avenues for research in efficient generative models for multimedia applications.
Visual Insights#
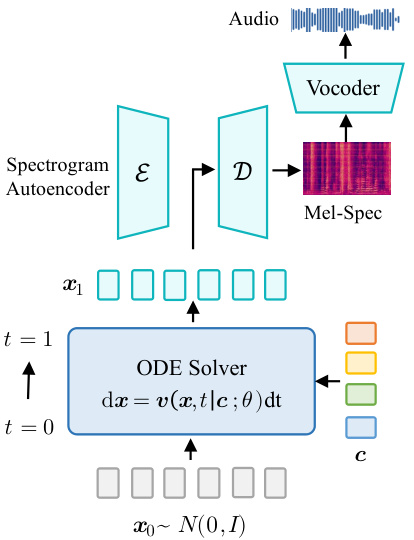
🔼 This figure illustrates the sampling process within the rectified flow-based video-to-audio (V2A) architecture. It shows how the model generates audio by solving an ordinary differential equation (ODE). Starting with noise sampled from a normal distribution (x0 ~ N(0, I)), the model uses a vector field estimator (represented by the ODE solver block) to progressively transform this noise into the latent representation of the mel-spectrogram (x1). The vector field, v(x, t|c; θ), is conditioned on visual features from the video (c). The resulting mel-spectrogram is then converted to audio using a vocoder.
read the caption
Figure 1: Illustration of the sampling process of our rectified-flow based V2A architecture.
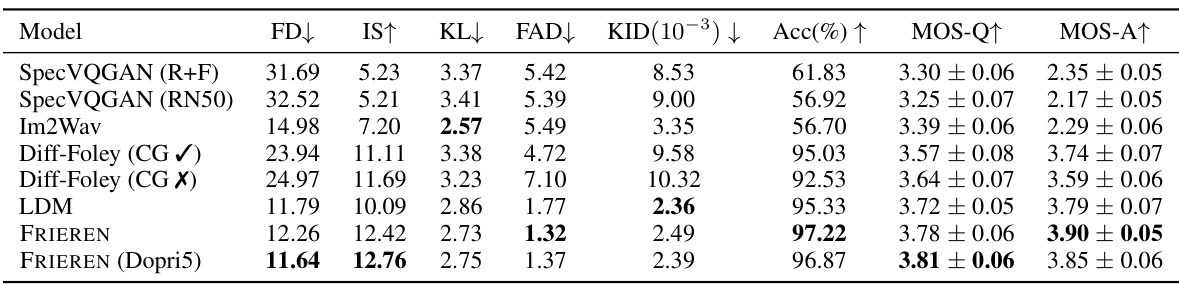
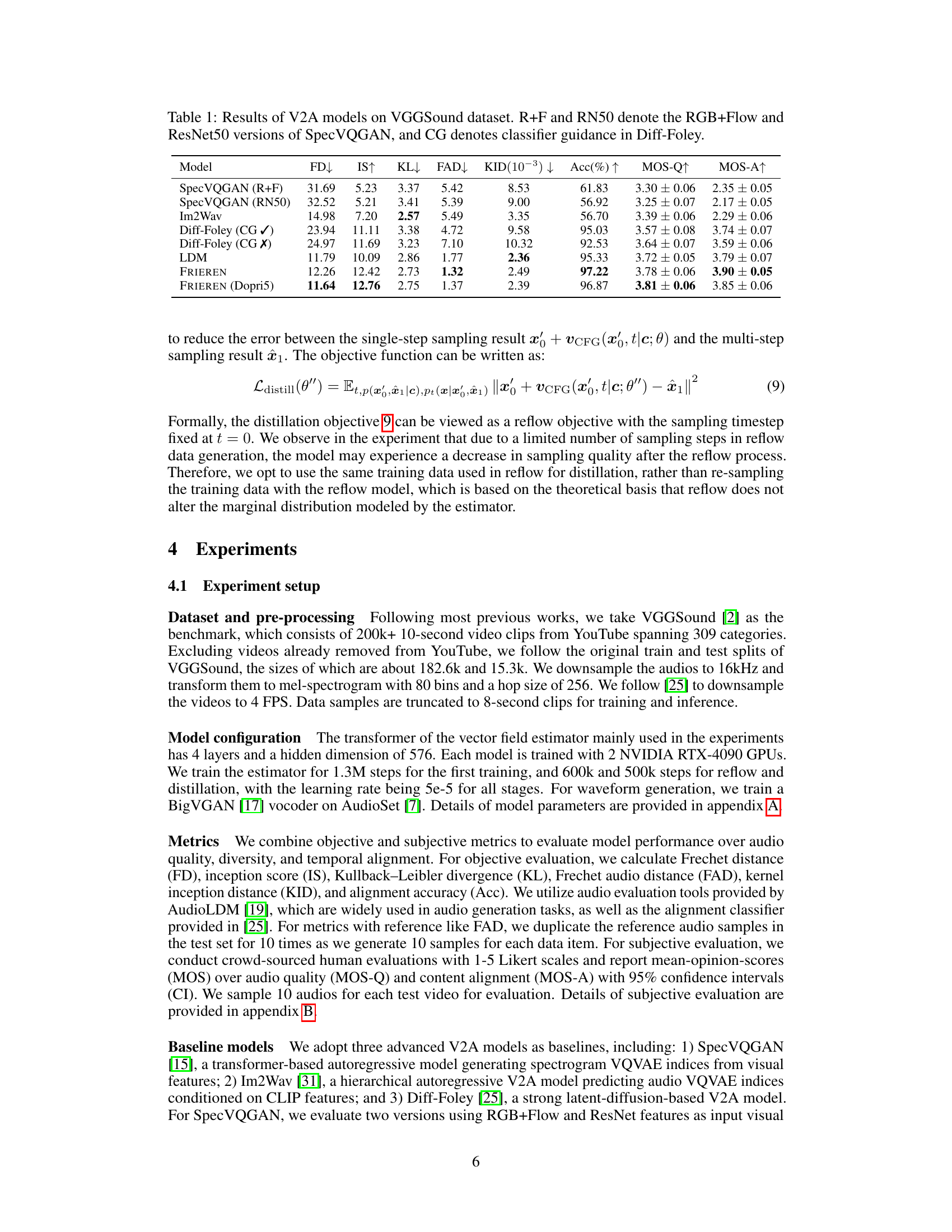
🔼 This table presents a comparison of various video-to-audio (V2A) generation models’ performance on the VGGSound dataset. It includes several state-of-the-art models for comparison, such as SpecVQGAN (with both RGB+Flow and ResNet50 features), Im2Wav, Diff-Foley (with and without classifier guidance), and LDM. The performance is evaluated based on several objective metrics including: Frequency Distance (FD), Inception Score (IS), Kullback-Leibler Divergence (KL), Frechet Audio Distance (FAD), Kernel Inception Distance (KID), Alignment Accuracy (Acc), Mean Opinion Score for Quality (MOS-Q), and Mean Opinion Score for Alignment (MOS-A). Lower values are generally better for FD, KL, FAD, and KID, while higher values are preferred for IS, Acc, MOS-Q, and MOS-A.
read the caption
Table 1: Results of V2A models on VGGSound dataset. R+F and RN50 denote the RGB+Flow and ResNet50 versions of SpecVQGAN, and CG denotes classifier guidance in Diff-Foley.
In-depth insights#
Rectified Flow V2A#
Rectified Flow V2A represents a novel approach to video-to-audio (V2A) generation, leveraging the efficiency and stability of rectified flow matching. This method directly regresses the transport vector field between a noise distribution and the target audio spectrogram latent space, creating straighter paths for sampling. Unlike autoregressive or score-based diffusion models which rely on iterative steps, often leading to temporal misalignment and inefficiency, rectified flow aims for faster, more accurate audio generation by utilizing an ODE solver and potentially only a single sampling step. The incorporation of a feed-forward transformer and channel-level cross-modal feature fusion ensures strong visual-audio alignment, crucial for realistic V2A outputs. Furthermore, techniques like reflow and one-step distillation further improve efficiency and audio quality. The model’s superior performance on metrics like Inception Score and alignment accuracy highlights the effectiveness of its core approach. However, the model’s reliance on a pre-trained autoencoder and the computational implications of the transformer architecture should be considered. Future work could explore scalability and applications to longer videos to fully realize its potential.
Efficient Audio Synth#
Efficient audio synthesis is a crucial area of research focusing on generating high-quality audio quickly and using minimal computational resources. Speed and efficiency are paramount, especially for real-time applications. This often involves exploring novel architectures, algorithms and signal processing techniques that reduce latency and computational complexity. Model compression and quantization are essential for deploying efficient models on resource-constrained devices such as mobile phones or embedded systems. Researchers are also investigating methods to accelerate inference through techniques like parallel processing or hardware acceleration. A key challenge is to balance efficiency gains with maintaining a high level of audio quality and avoiding artifacts. The ultimate goal is to provide a seamless and realistic audio experience while minimizing the computational overhead. Different approaches to achieve this include waveform-based, vocoder-based, and autoregressive models, each with their unique tradeoffs in terms of efficiency and quality. The focus is continually shifting towards achieving better fidelity and naturalness in synthesized audio alongside the pursuit of speed and reduced resource consumption.
Temporal Alignment#
Achieving precise temporal alignment between generated audio and video frames is a critical challenge in video-to-audio (V2A) generation. Autoregressive models often struggle with explicit alignment, relying on implicit relationships learned during training. Diffusion-based models frequently need additional mechanisms like classifier guidance, increasing complexity. FRIEREN addresses this by using a non-autoregressive vector field estimator coupled with a channel-level cross-modal feature fusion. This design preserves temporal resolution while directly leveraging the inherent alignment of visual and audio data. Furthermore, techniques like reflow and one-step distillation with a guided vector field, significantly improve alignment accuracy while dramatically increasing efficiency. The strong temporal alignment achieved (up to 97.22% accuracy) showcases the effectiveness of FRIEREN’s approach in addressing a key limitation of prior V2A models.
Reflow & Distillation#
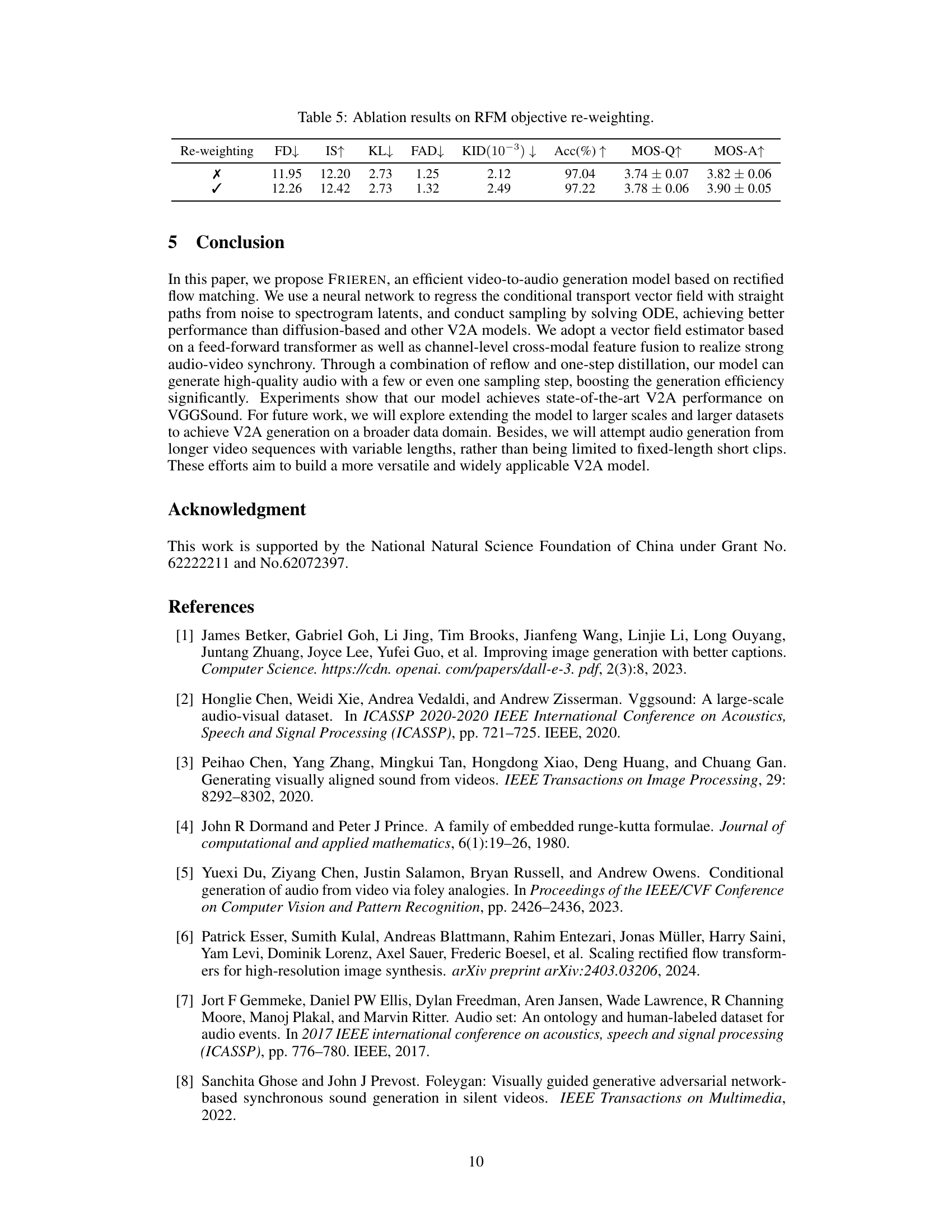
The authors introduce reflow and one-step distillation to significantly enhance the efficiency of their video-to-audio (V2A) generation model. Reflow, a crucial component of rectified flow matching, refines the learned transport paths by iteratively retraining the vector field estimator. This process produces straighter, more efficient trajectories between noise and data points, enabling larger sampling steps. One-step distillation further optimizes this by training the model to approximate the multi-step generation process in a single step. By combining these techniques, FRIEREN can generate high-quality audio with drastically fewer steps, achieving a significant speedup compared to baselines like Diff-Foley, which demands multiple sampling steps for comparable results. This efficiency improvement makes the model more practical for real-world applications, where fast inference is crucial.
Future V2A Research#
Future research in Video-to-Audio (V2A) generation should prioritize improving the quality and diversity of generated audio, especially for complex scenes and diverse acoustic environments. Addressing the temporal alignment issue remains crucial, aiming for perfect synchronization between audio and visuals, regardless of video frame rate or audio length. Efficiency improvements are also vital, especially for real-time applications and resource-constrained devices. This may involve exploring more efficient model architectures or sampling strategies. Addressing ethical concerns, such as the potential for misuse in creating deepfakes, is also paramount and requires careful consideration. Finally, exploring multi-modal aspects, including the integration of other modalities like text or action information for context-aware audio generation, will enhance the realism and expressiveness of synthesized audio. Research should focus on robustness, scalability and generalizability across diverse datasets and scenarios.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of the FRIEREN model at three levels: (a) shows the overall architecture, which includes visual encoder, length regulator, vector field estimator, and decoder; (b) details the vector field estimator network, which consists of visual and audio feature fusion via concatenation, feed-forward transformer blocks, and output vector field; and (c) shows the internal structure of a feed-forward transformer block. This figure helps to visualize the different components of the FRIEREN model and how they interact with each other.
read the caption
Figure 2: Illustration of model architecture of FRIEREN at different levels.

🔼 This figure compares the Inception Score (IS) and Frechet Audio Distance (FAD) for different models (Diff-Foley with and without classifier guidance, FRIEREN, FRIEREN with reflow, and FRIEREN with reflow and distillation) across varying numbers of inference steps (1, 5, 10, 15, 20, 25). It demonstrates the impact of reflow and distillation on the audio quality and diversity as the number of sampling steps decreases.
read the caption
Figure 4: IS and FAD of the models with different steps.
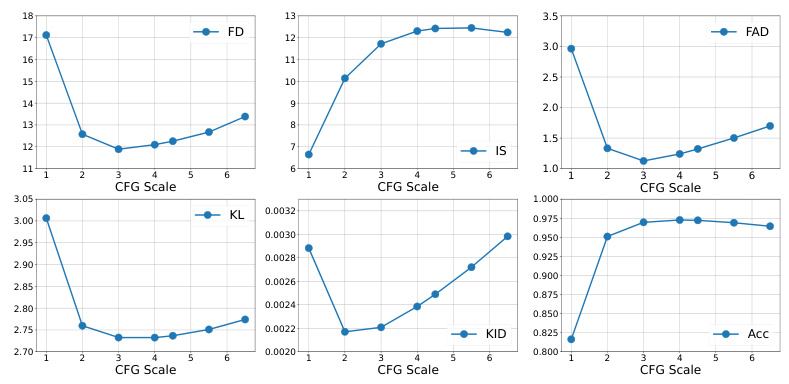
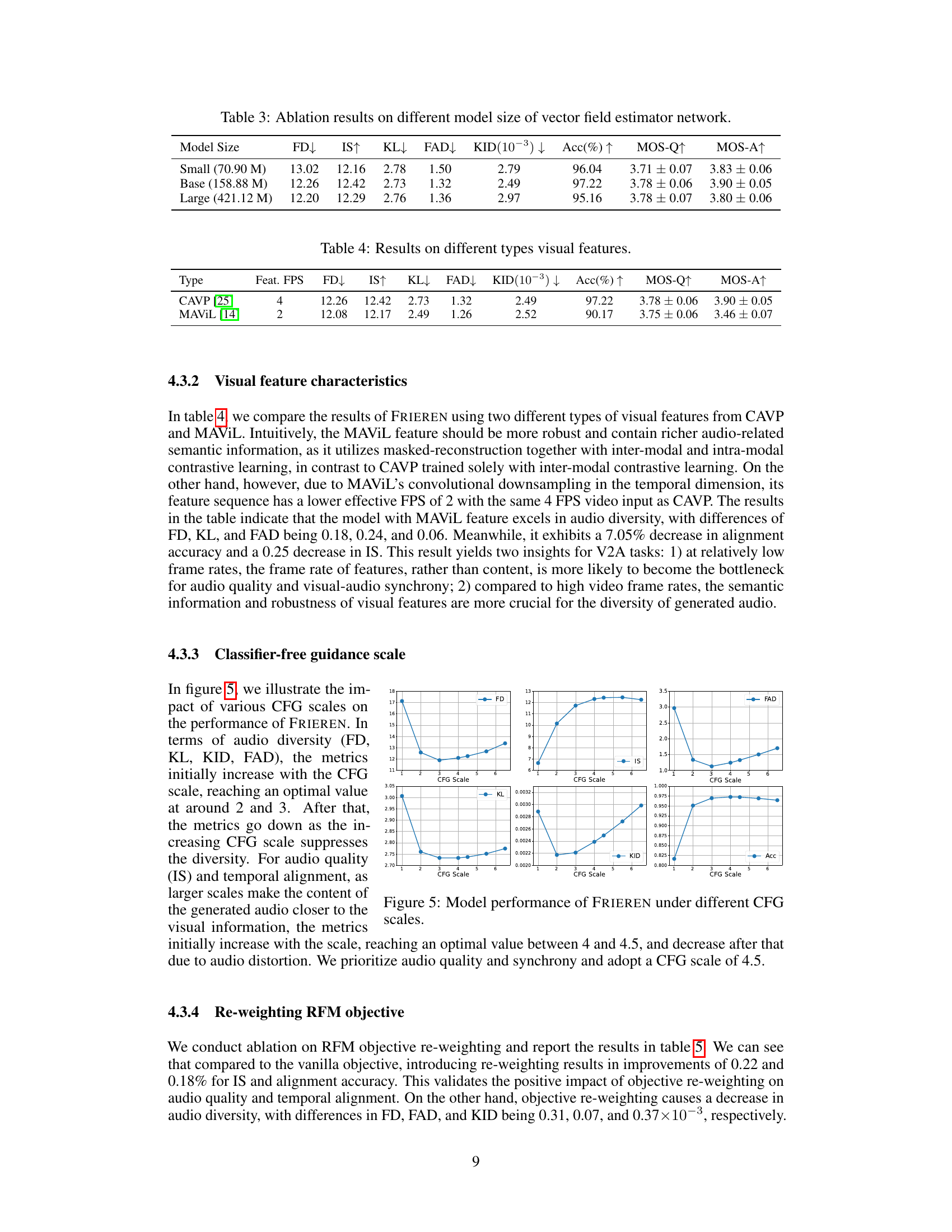
🔼 The figure shows the performance of FRIEREN model under different classifier-free guidance (CFG) scales. It displays the impact of CFG scaling on multiple metrics: Inception Score (IS), Frechet Distance (FD), Frechet Audio Distance (FAD), Kullback-Leibler Divergence (KL), Kernel Inception Distance (KID), and Alignment Accuracy (Acc). The plots illustrate how these metrics change as the CFG scale increases, indicating an optimal range for achieving a balance between audio quality, diversity, and alignment.
read the caption
Figure 5: Model performance of FRIEREN under different CFG scales.

🔼 This figure illustrates the sampling process of the FRIEREN model. It starts with noise sampled from a standard normal distribution (x0 ~ N(0, 1)). This noise is then conditioned on visual features (c) from the video and passed through an ODE solver using the estimated vector field (v(x, t|c; θ)) to generate the mel-spectrogram latent (x1). Finally, this latent representation is decoded using an autoencoder to produce the spectrogram, which is then converted to an audio waveform using a vocoder.
read the caption
Figure 1: Illustration of the sampling process of our rectified-flow based V2A architecture.
🔼 This figure illustrates the sampling process of the FRIEREN model. It shows how the model uses an ODE solver to generate audio from a latent representation derived from a noise distribution and conditioned on video features. The process starts with noise sampled from a normal distribution, which is then transformed through a series of steps guided by a vector field, ultimately leading to a latent representation of the audio spectrogram. This representation is then decoded into an audio waveform via an autoencoder and vocoder.
read the caption
Figure 1: Illustration of the sampling process of our rectified-flow based V2A architecture.
More on tables
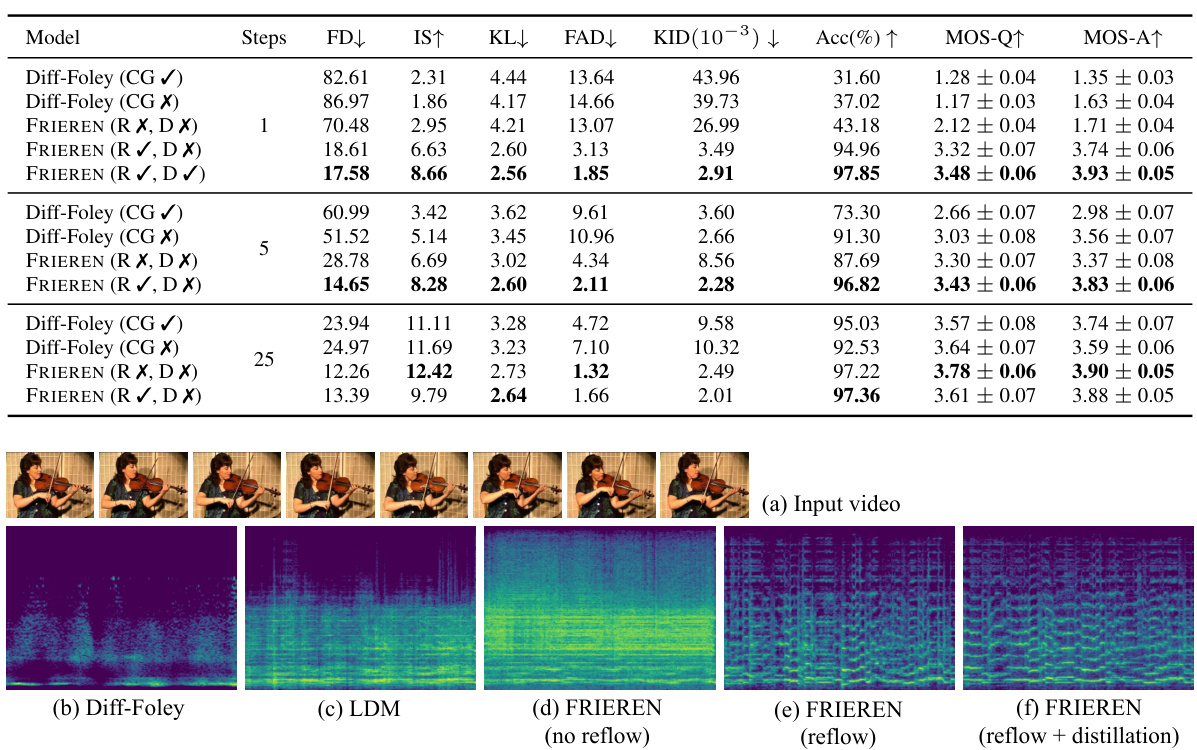
🔼 This table compares the performance of FRIEREN and Diff-Foley at different sampling steps (1, 5, and 25). It shows various metrics such as Fréchet distance (FD), Inception Score (IS), Kullback-Leibler divergence (KL), Frechet Audio Distance (FAD), Kernel Inception Distance (KID), alignment accuracy (Acc), and Mean Opinion Scores for quality (MOS-Q) and alignment (MOS-A). The impact of classifier guidance (CG), reflow (R), and one-step distillation (D) on the overall performance of both models is assessed.
read the caption
Table 2: Results of FRIEREN and Diff-Foley under different sampling steps. CG denotes classifier guidance, R denotes reflow and D denotes one-step distillation.

🔼 This table presents the ablation study results on varying the model size (number of parameters) of the vector field estimator in the FRIEREN model. It shows how different model sizes affect several key metrics, including Frechet Distance (FD), Inception Score (IS), Kullback-Leibler divergence (KL), Frechet Audio Distance (FAD), Kernel Inception Distance (KID), Alignment Accuracy (Acc), Mean Opinion Score for Quality (MOS-Q), and Mean Opinion Score for Alignment (MOS-A). The results demonstrate the impact of model size on the model’s performance across various aspects, allowing researchers to determine the optimal balance between model complexity and performance.
read the caption
Table 3: Ablation results on different model size of vector field estimator network.

🔼 This table compares the performance of the FRIEREN model when using different types of visual features: CAVP and MAVIL. It shows the impact of visual feature choice on audio quality, diversity and temporal alignment metrics (FD, IS, KL, FAD, KID, Acc). It also includes subjective MOS scores (MOS-Q and MOS-A). Note that MAVIL features have a lower FPS (frames per second) than CAVP features.
read the caption
Table 4: Results on different types visual features.

🔼 This table presents the quantitative results of various video-to-audio (V2A) generation models on the VGGSound dataset. It compares the performance of FRIEREN against several baselines, including SpecVQGAN (with both RGB+Flow and ResNet50 features), Im2wav, and Diff-Foley (with and without classifier guidance). The metrics used to evaluate model performance include Frechet Distance (FD), Inception Score (IS), Kullback-Leibler divergence (KL), Frechet Audio Distance (FAD), Kernel Inception Distance (KID), Alignment Accuracy (Acc), and Mean Opinion Scores for audio quality (MOS-Q) and audio-visual alignment (MOS-A). Lower values for FD, KL, FAD, and KID indicate better performance. Higher values for IS, Acc, MOS-Q, and MOS-A indicate better performance.
read the caption
Table 1: Results of V2A models on VGGSound dataset. R+F and RN50 denote the RGB+Flow and ResNet50 versions of SpecVQGAN, and CG denotes classifier guidance in Diff-Foley.
🔼 This table presents the performance comparison of various Video-to-Audio (V2A) generation models on the VGGSound dataset. The models include SpecVQGAN (with RGB+Flow and ResNet50 features), Im2wav, Diff-Foley (with and without classifier guidance), Latent Diffusion Model (LDM), and the proposed FRIEREN model. Evaluation metrics encompass objective measures like Fréchet Distance (FD), Inception Score (IS), Kullback-Leibler divergence (KL), Fréchet Audio Distance (FAD), Kernel Inception Distance (KID), and alignment accuracy (Acc), as well as subjective Mean Opinion Scores (MOS) for audio quality (MOS-Q) and audio-visual alignment (MOS-A). Lower FD, KL, FAD, and KID values and higher IS, Acc, MOS-Q, and MOS-A indicate better performance.
read the caption
Table 1: Results of V2A models on VGGSound dataset. R+F and RN50 denote the RGB+Flow and ResNet50 versions of SpecVQGAN, and CG denotes classifier guidance in Diff-Foley.

🔼 This table presents a comparison of various video-to-audio (V2A) generation models’ performance on the VGGSound dataset. The models are evaluated based on several metrics: Frequency Distance (FD), Inception Score (IS), Kullback-Leibler Divergence (KL), Frechet Audio Distance (FAD), Kernel Inception Distance (KID), Alignment Accuracy (Acc), Mean Opinion Score for Quality (MOS-Q), and Mean Opinion Score for Alignment (MOS-A). Different versions of some models are included (e.g., SpecVQGAN with RGB+Flow features vs. ResNet50 features), highlighting the impact of different model architectures and feature inputs on the overall performance.
read the caption
Table 1: Results of V2A models on VGGSound dataset. R+F and RN50 denote the RGB+Flow and ResNet50 versions of SpecVQGAN, and CG denotes classifier guidance in Diff-Foley.

🔼 This table presents a comparison of different video-to-audio (V2A) models on the VGGSound dataset. The models are evaluated using several metrics including Frechet Distance (FD), Inception Score (IS), Kullback-Leibler Divergence (KL), Frechet Audio Distance (FAD), Kernel Inception Distance (KID), alignment accuracy (Acc), Mean Opinion Score for quality (MOS-Q), and Mean Opinion Score for alignment (MOS-A). The table shows that FRIEREN outperforms other state-of-the-art models, achieving superior performance in terms of both audio quality and temporal alignment.
read the caption
Table 1: Results of V2A models on VGGSound dataset. R+F and RN50 denote the RGB+Flow and ResNet50 versions of SpecVQGAN, and CG denotes classifier guidance in Diff-Foley.
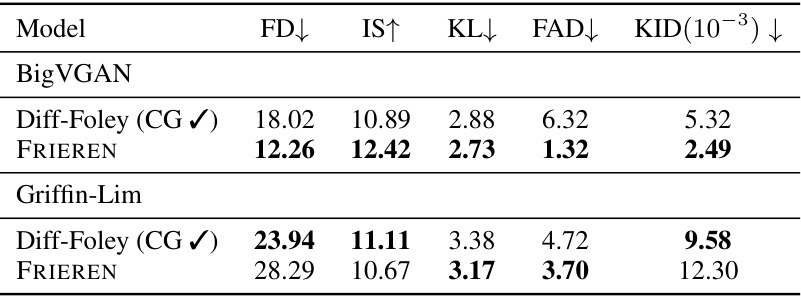
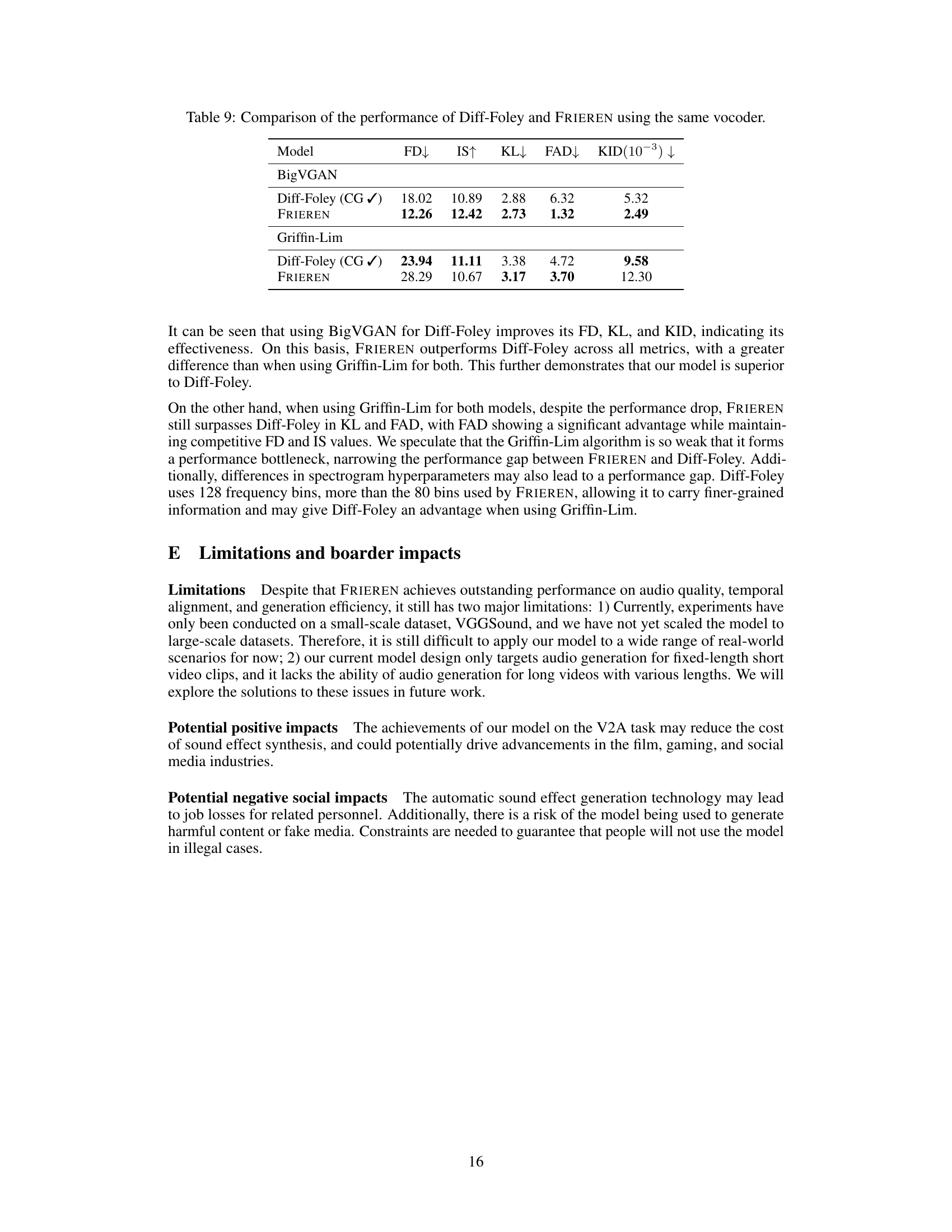
🔼 This table compares the performance of Diff-Foley and FRIEREN models when using the same vocoder (BigVGAN and Griffin-Lim). It shows the objective evaluation metrics (FD, IS, KL, FAD, KID) for both models under two different vocoder settings. The results highlight FRIEREN’s superior performance in most metrics across both vocoder implementations.
read the caption
Table 9: Comparison of the performance of Diff-Foley and FRIEREN using the same vocoder.
Full paper#