↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Semi-supervised learning (SSL) struggles with limited labeled data. Existing SSL methods often rely on heuristics or predefined rules for pseudo-label generation, hindering performance. This often leads to suboptimal model training. The paper tackles this problem by formulating SSL as a reinforcement learning (RL) problem.
The proposed method, RLGSSL, uses an RL agent to learn how to generate high-quality pseudo-labels. It introduces a novel RL loss function that incorporates a weighted reward, balancing labeled and unlabeled data to maximize model generalization. RLGSSL also integrates a teacher-student framework for increased stability. Experiments on benchmark datasets demonstrate that RLGSSL consistently outperforms current state-of-the-art SSL methods, showcasing its effectiveness. This innovative approach addresses key limitations of existing SSL techniques by dynamically adapting to data and improving pseudo-label quality.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to semi-supervised learning by integrating reinforcement learning, offering a more adaptive and robust method with superior performance. It addresses the challenge of limited labeled data and opens new avenues for research in leveraging RL for enhancing SSL methods, impacting various applications where labeled data is scarce.
Visual Insights#
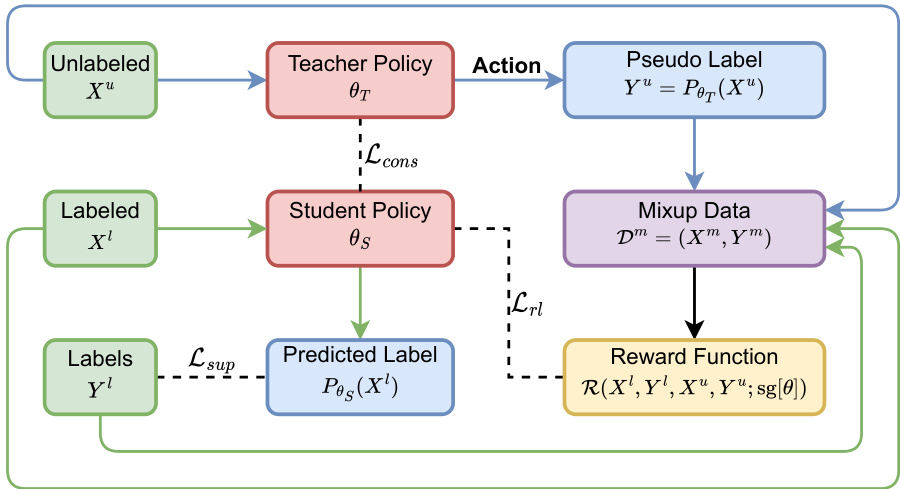
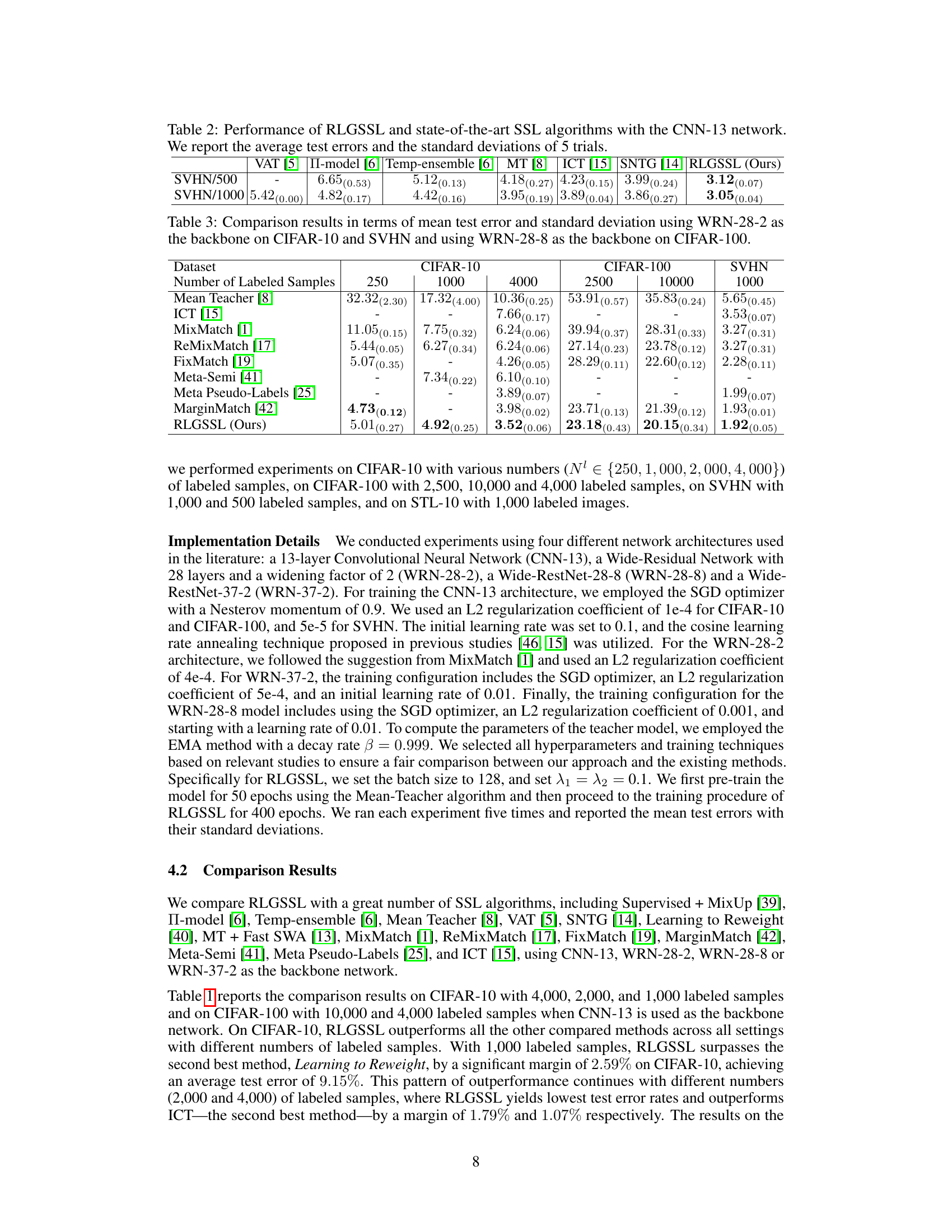
This figure illustrates the RLGSSL framework, which formulates semi-supervised learning as a one-armed bandit problem. The framework consists of a teacher and student network, where the teacher network generates pseudo-labels for unlabeled data. These pseudo-labels, along with the labeled data, are used to create mixup data. A reward function evaluates the performance of the model on this mixup data, guiding the learning process through an RL loss. The framework also incorporates a supervised loss on labeled data and a consistency loss to improve learning stability and enhance generalization. The teacher network provides stability by using an exponential moving average of the student network’s weights.
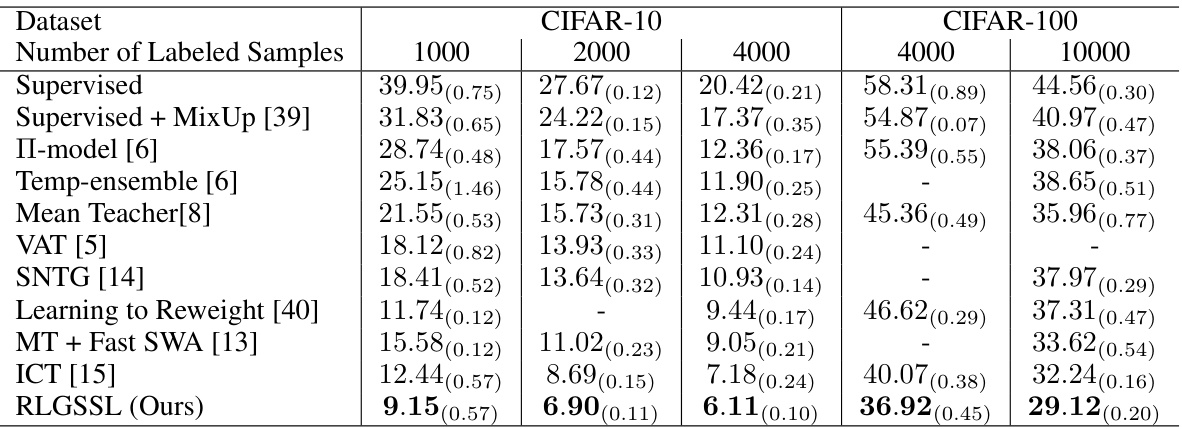
This table presents a comparison of the proposed RLGSSL method against several state-of-the-art semi-supervised learning (SSL) algorithms. The comparison is based on the average test error and standard deviation across 5 trials using the CNN-13 network architecture. Different datasets (CIFAR-10 and CIFAR-100) are used with varying numbers of labeled samples to evaluate the performance of each algorithm. The results show that the RLGSSL consistently outperforms other methods across all settings.
In-depth insights#
RL in Semi-Supervised Learning#
Reinforcement learning (RL) offers a powerful paradigm shift in semi-supervised learning (SSL). Traditional SSL methods often rely on heuristics for pseudo-labeling, limiting adaptability. RL elegantly addresses this by formulating SSL as a sequential decision-making process. The agent (model) learns to generate high-quality pseudo-labels through interaction with the environment (data), optimizing a reward function that balances the utilization of labeled and unlabeled data. This dynamic approach allows the model to actively adapt its labeling strategy based on performance, leading to improved generalization and robustness. The incorporation of RL techniques allows for more flexible and adaptive SSL methods, potentially surpassing the performance of traditional approaches which are largely static. Furthermore, combining RL with teacher-student frameworks adds enhanced stability and efficiency to the learning process. The resulting algorithms demonstrate superior performance in numerous benchmark experiments, showcasing the potential of RL to significantly improve the state-of-the-art in SSL.
RLGSSL Framework#
The Reinforcement Learning Guided Semi-Supervised Learning (RLGSSL) framework innovatively integrates reinforcement learning (RL) into semi-supervised learning (SSL). It formulates the SSL problem as a one-armed bandit, where the prediction model acts as a policy, and pseudo-labeling is the action. A key contribution is the carefully designed reward function that dynamically balances labeled and unlabeled data, boosting generalization. This reward guides the learning process through a novel RL loss, adapting to data characteristics. A teacher-student framework enhances learning stability, and a supervised learning loss further accelerates training and improves accuracy. This unique integration of RL and SSL components provides a flexible and robust method, outperforming traditional SSL techniques by leveraging RL’s exploration and adaptation capabilities.
Adaptive Reward Design#
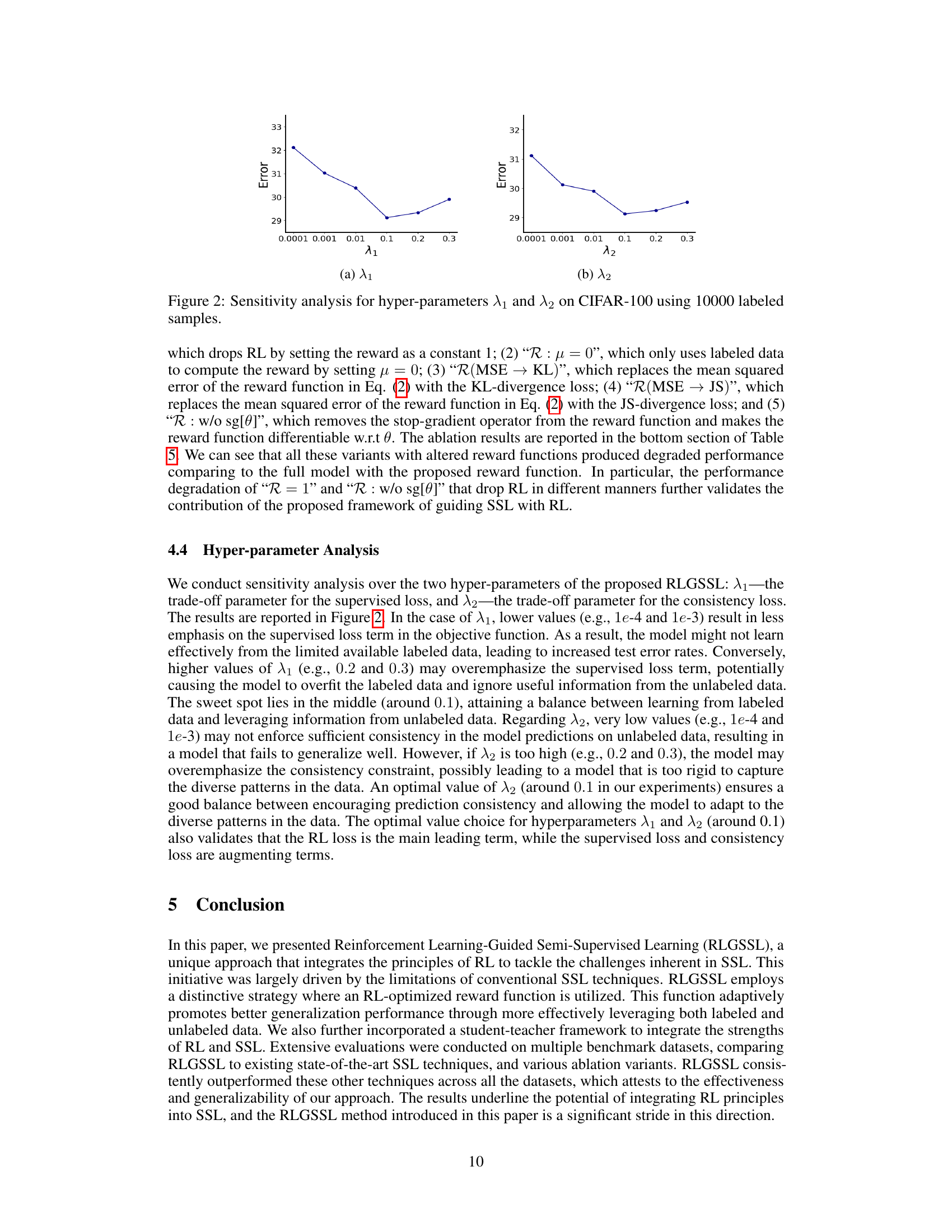
In reinforcement learning (RL), reward design is crucial for effective agent training. An adaptive reward design, rather than a static one, offers significant advantages by dynamically adjusting rewards based on the agent’s performance and the learning context. This approach is particularly beneficial in complex environments where the optimal reward function might be unknown or change over time. For instance, an adaptive reward function might increase the reward for correct actions in challenging situations, incentivizing exploration and risk-taking where needed. Conversely, it might reduce rewards for easy tasks once mastered, steering the agent towards more complex aspects of the problem. Successful adaptive reward design requires careful consideration of the specific problem and the agent’s learning capabilities. It involves balancing exploration and exploitation, ensuring that the agent does not get stuck in local optima or become overly risk-averse. This frequently involves incorporating heuristics or advanced techniques such as meta-learning or reward shaping to guide the adaptation process. The ultimate goal is to design a reward function that efficiently guides the agent to learn the desired behavior while promoting adaptability and robustness. Adaptive reward design is a highly active area of research with the potential to improve RL’s effectiveness in solving real-world problems.
Teacher-Student RL-SSL#
A Teacher-Student RL-SSL framework integrates reinforcement learning (RL) into a semi-supervised learning (SSL) model using a teacher-student paradigm. The teacher model, possibly a pre-trained model or one updated via an exponential moving average (EMA) of student weights, generates pseudo-labels for unlabeled data. These act as actions in the RL process, guiding the student model’s learning. The student model is trained to maximize a reward function that balances labeled and unlabeled data contributions. This reward guides the student towards better generalization and reliable pseudo-label generation. The key advantage is the adaptive nature of RL, enabling dynamic adjustment to data characteristics and improving pseudo-label quality compared to heuristic SSL methods. Combining RL with teacher-student mechanisms further enhances stability and robustness, mitigating risks like overfitting or unreliable pseudo-labels. This approach leverages the strengths of both RL’s adaptive exploration and teacher-student methods’ stability to achieve superior SSL performance.
RLGSSL Limitations#
The RLGSSL approach, while demonstrating significant improvements in semi-supervised learning, presents certain limitations. A key constraint is the assumption that labeled and unlabeled data share the same distribution; this may not always hold true in real-world scenarios, potentially impacting the model’s generalizability. Further research should explore techniques to address this distribution mismatch, such as domain adaptation strategies. The reliance on a carefully designed reward function could also be a source of limitations, as the effectiveness of this function might be sensitive to the specific characteristics of the dataset and problem being tackled. Developing more robust and adaptive reward functions is important for broader applicability. Finally, the computational cost of integrating RL within the SSL framework needs further investigation; it could affect the scalability and efficiency of the RLGSSL approach, especially with large datasets. Investigating computational optimizations and alternative RL implementations would be valuable to mitigate potential scalability issues.
More visual insights#
More on tables

This table shows the performance comparison between the proposed RLGSSL method and other state-of-the-art semi-supervised learning (SSL) algorithms on the SVHN dataset. The CNN-13 network architecture was used. The results are presented as average test errors and their standard deviations, calculated across 5 independent trials. The table is organized to show the performance for two different numbers of labeled training samples (500 and 1000).

This table presents a comparison of the proposed RLGSSL method against various state-of-the-art semi-supervised learning (SSL) algorithms. The comparison is performed using the CNN-13 network architecture across three benchmark datasets (CIFAR-10, CIFAR-100, and SVHN). The table shows the average test error and standard deviation obtained by each method for different numbers of labeled training samples, providing a comprehensive assessment of the performance of each model relative to RLGSSL. The results demonstrate the superior performance of RLGSSL across various scenarios.

This table presents the comparison results of various SSL methods on the STL-10 dataset, using WRN-37-2 as the backbone network. It shows the mean test error and standard deviation for different SSL methods, including RLGSSL (the proposed method), with a fixed number of 1,000 labeled samples. The results demonstrate the effectiveness of RLGSSL compared to other state-of-the-art methods.
Full paper#