↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating high-quality animated 3D models from videos is a challenging task in computer vision and graphics. Existing methods often require multiple views or time-consuming iterative processes, limiting their applicability. This paper addresses these issues by introducing L4GM, a novel model that efficiently reconstructs animated 3D objects from a single-view video.
L4GM leverages a large-scale dataset of multiview videos of rendered animated objects for training. It uses a unique approach, building on top of pre-trained 3D models and adding temporal self-attention layers for consistency across time. The model outputs a per-frame 3D Gaussian representation and upsamples it to higher fps for temporal smoothness, showcasing remarkable speed and generalization to in-the-wild videos, significantly outperforming state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers in computer vision, computer graphics, and machine learning because it introduces a novel approach to generate high-quality animated 3D models from videos. Its speed and accuracy surpasses previous methods, opening new avenues for research in virtual and augmented reality, video game development, and film production. The use of readily available datasets lowers the barrier to entry and allows more researchers to engage with this important area.
Visual Insights#

This figure shows examples of 4D object reconstruction from real-world videos using the L4GM model. The top row displays the input video frames for two different objects (a panda and a robot). The subsequent rows showcase multi-view renderings of the 3D models generated by L4GM at different points in time. This demonstrates the model’s ability to create animated 3D assets from single-view video inputs.
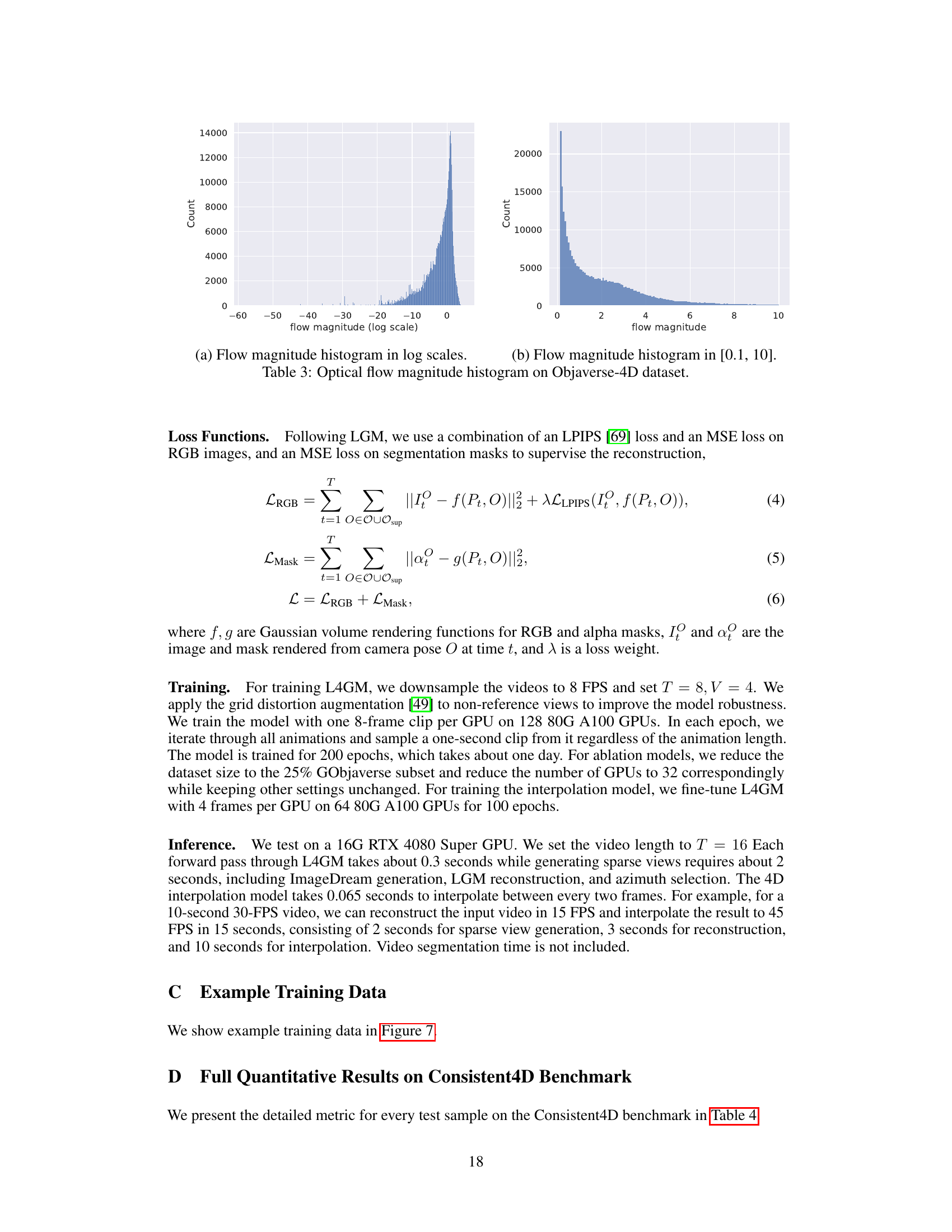
This table presents a quantitative comparison of L4GM against other state-of-the-art video-to-4D generation approaches on a standard benchmark. The metrics used for comparison are LPIPS (lower is better), CLIP (higher is better), and FVD (lower is better), representing perceptual similarity, semantic similarity, and video quality, respectively. The table also shows the inference time taken by each method. The results demonstrate that L4GM significantly outperforms other methods in terms of all three quality metrics while achieving a speedup of 100 to 1000 times.
In-depth insights#
4D Gaussian LGM#
The concept of “4D Gaussian LGM” suggests an extension of the Large Gaussian Model (LGM) to incorporate temporal information, moving beyond static 3D reconstruction to dynamic 4D representations. This likely involves representing objects as a sequence of 3D Gaussian distributions over time, where each Gaussian encodes shape, pose, and appearance. The “4D” aspect highlights the model’s ability to capture and generate animations. The LGM foundation likely provides a strong base for efficient single-view reconstruction; however, the 4D extension might involve significant architectural changes, such as incorporating temporal self-attention layers to maintain consistency across time steps, and specialized loss functions to evaluate the accuracy of the generated animation. A key challenge would be handling temporal consistency and efficiently handling the increased data dimensionality, and generalizing well to real-world scenarios remains a major hurdle, particularly given that training data is likely scarce. Overall, a successful 4D Gaussian LGM represents a significant advance in the field of 3D/4D reconstruction, enabling high-quality animated 3D model generation from video. Its success hinges on addressing the challenges of temporal modeling and scalability.
Objaverse-4D Dataset#
The Objaverse-4D dataset represents a significant contribution to the field of 4D reconstruction. Its creation involved rendering 110,000 animations of 44,000 diverse objects from Objaverse 1.0, resulting in a massive 12 million multiview videos. This scale is crucial for training robust 4D reconstruction models, as it provides sufficient data to capture the complexities of dynamic object motion and appearance. The dataset’s focus on diverse objects and animations is vital for generalization; models trained on it should perform well on unseen objects and motions. However, the synthetic nature of the data needs further consideration. While effective for initial training, it may limit real-world generalizability, a point that requires additional discussion and future research. Overall, the dataset serves as a key enabler for the progress of 4D reconstruction, offering a substantial resource for researchers but also requiring a thoughtful evaluation of its limitations.
Autoregressive 4D#
An autoregressive approach to 4D reconstruction, as the name suggests, processes video data sequentially, frame-by-frame or in short chunks. This contrasts with a parallel or feedforward method that processes the entire video simultaneously. The key advantage is handling long videos that exceed the model’s temporal capacity. By processing the video in smaller segments, the autoregressive model maintains a manageable computational load and avoids potential memory limitations. Each segment uses the previous segment’s output as an input, creating a chain of temporal dependencies. This chained approach helps in maintaining consistency and smoothness across the entire video. However, this approach also introduces a new challenge: the accumulation of errors across segments. Careful model design is essential to prevent error propagation from degrading the overall reconstruction quality. Additionally, an autoregressive 4D model might be more suitable for real-time processing as it doesn’t demand the storage of the entire video in memory. The trade-off between computational efficiency and accuracy needs to be carefully considered when designing and applying an autoregressive 4D model.
Ablation Experiments#
Ablation studies systematically remove components of a model to understand their individual contributions. In a 4D reconstruction model, this might involve removing temporal self-attention layers, the multi-view generation component, or the 3D prior. Removing the temporal layers would assess their impact on temporal consistency and smoothness of the animation, while removing the multi-view component would reveal how much reliance the model places on synthesized views versus the single input. Removing the 3D prior would test the model’s ability to learn 3D structure without a strong inductive bias. The results would reveal the relative importance of each component and help optimize the model architecture. Significant performance degradation after removing a particular component suggests its critical role in the model’s effectiveness, indicating that further optimization or alternative methods to achieve the same effect might be needed. Conversely, minor impact could mean the component is less essential and potentially replaceable or simplifiable.
Future of 4D Modeling#
The future of 4D modeling hinges on overcoming current limitations in data acquisition, computational cost, and model generalization. High-quality multi-view video datasets are crucial for training robust models that accurately capture complex dynamics. Future work will likely explore more efficient model architectures and training strategies that reduce computational costs, potentially by utilizing novel network designs or leveraging transfer learning from large 3D datasets. Improved algorithms for handling motion ambiguity and occlusion are essential for achieving faithful reconstructions from single-view videos. Research into incorporating physics-based priors or integrating neural fields may enhance the accuracy and realism of animated 3D assets. Finally, the future of 4D modeling likely includes seamless integration with other AI technologies, such as text-to-video generation, enabling users to create and edit 4D models more intuitively and efficiently. This will ultimately lead to more realistic virtual environments, enhance entertainment and education, and empower new applications such as AR and VR.
More visual insights#
More on figures
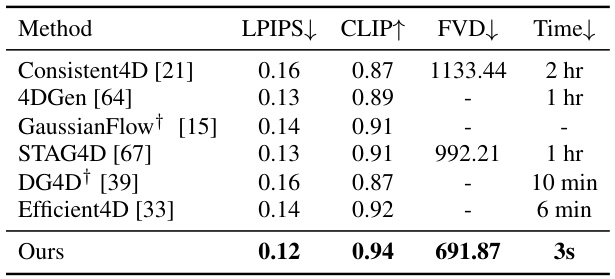
This figure illustrates the architecture of the L4GM model. The model takes as input a single-view video and a set of multiview images from a single time step. It then uses a U-Net architecture with cross-view self-attention and temporal self-attention layers to produce a sequence of 4D Gaussians representing the animated 3D object across time.
This figure illustrates the overall architecture of the L4GM model. The model takes a single-view video and a set of multiview images from a single time step as input. It processes these inputs through a U-Net architecture incorporating cross-view self-attention to maintain view consistency and temporal self-attention to maintain temporal consistency across time steps. The output of the model is a sequence of 4D Gaussian representations, one for each time step in the input video.

This figure showcases the qualitative results of the L4GM model on two real-world videos. The top row displays weightlifters performing different lifting actions, while the bottom row shows a frog character exhibiting various poses. For each video, multiple views of the generated 3D reconstructions are presented, demonstrating the model’s ability to generate high-quality, temporally consistent animations from in-the-wild video data. The image provides visual evidence of the model’s capacity for real-world generalization and 4D reconstruction.

This figure shows a qualitative comparison of the results of L4GM against three other state-of-the-art methods (OpenLRM, STAG4D, and DG4D) on various example videos. Each row represents a different video and shows the input view and novel view generated by each method. The comparison highlights L4GM’s ability to generate higher-quality, more detailed and temporally consistent novel views compared to the other approaches.
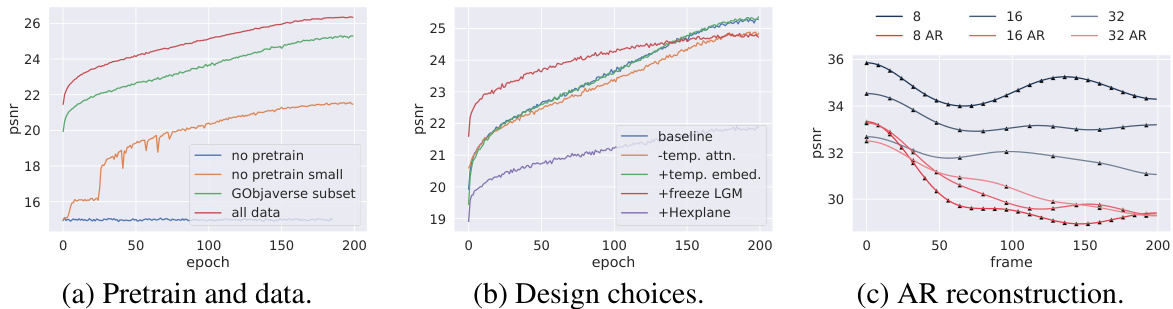
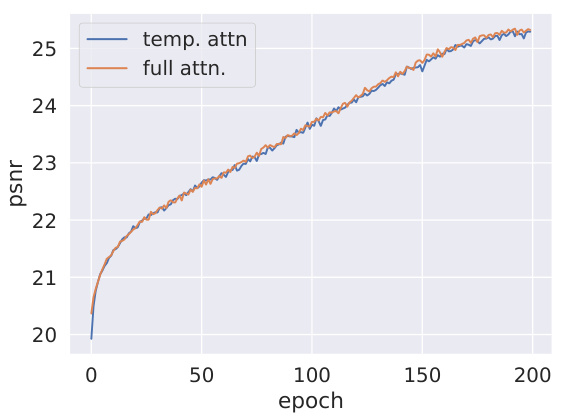
This figure presents three PSNR plots to show the effect of different training strategies on the model’s performance. Plot (a) compares training with different pretraining data and training datasets. Plot (b) shows the results with various design choices like using temporal attention, adding time embeddings, freezing the LGM, and using HexPlane. Plot (c) shows the performance of autoregressive reconstruction with various video lengths.
This figure illustrates the architecture of the L4GM model, which takes a single-view video and multi-view images as input to produce a sequence of 4D Gaussian representations. The model utilizes a U-Net architecture with cross-view and temporal self-attention layers to ensure view and temporal consistency in the output. The 4D Gaussians are then used to reconstruct the animated 3D objects.

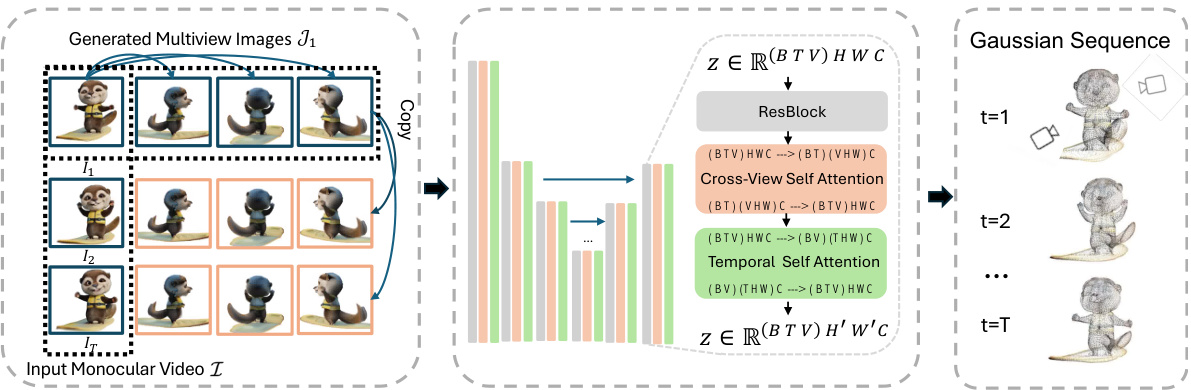
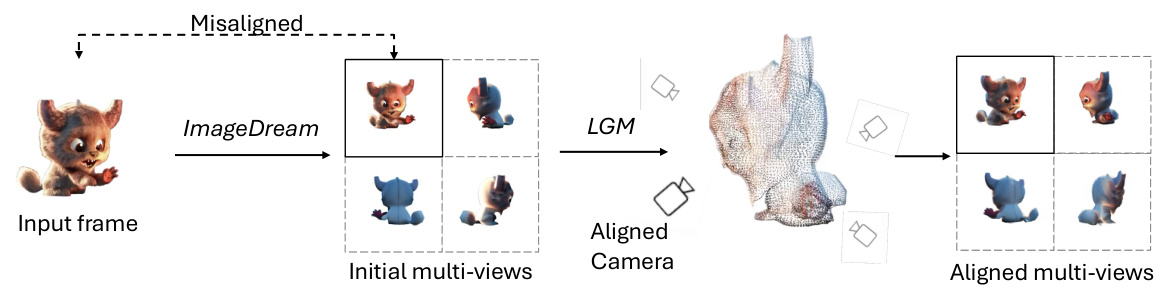
This figure shows example training data used for the L4GM model. It highlights the input format, demonstrating how a single input view is combined with multiple generated views (created using ImageDream) to form the input to the model for each time step. The masked input views indicate data that is not directly used for training; instead, these views are replaced with copies of the multiview images from the initial time step (t=1). This approach helps maintain temporal consistency throughout the training process.
This figure illustrates the architecture of the L4GM model. The model takes a single-view video and a set of multiview images from a single time step as input. It uses a U-Net architecture with cross-view self-attention to ensure consistency across different viewpoints and temporal self-attention to maintain consistency across time. The output of the model is a sequence of 3D Gaussian representations, one for each time step in the input video, forming the 4D representation.
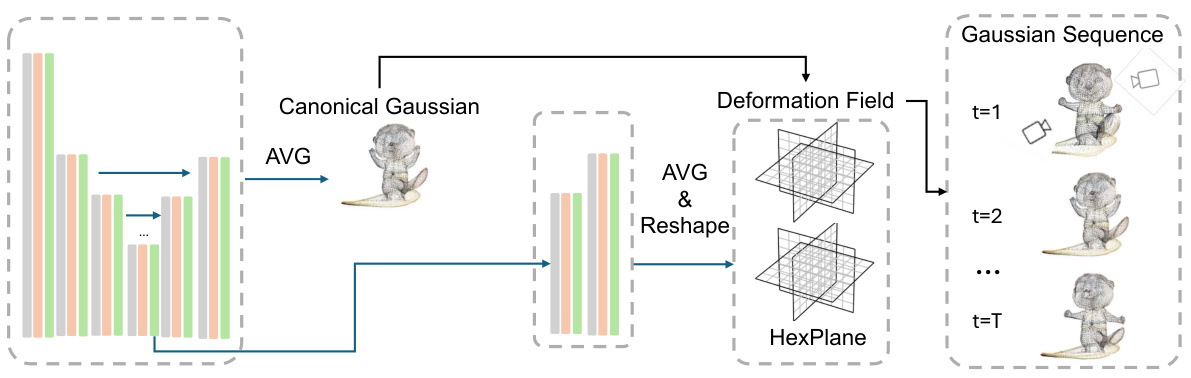
This figure illustrates the architecture of the HexPlane model used in the ablation study. The model takes a canonical Gaussian representation as input and processes it through an averaging and reshaping stage to create a deformation field represented by a HexPlane. This deformation field is then combined with the canonical Gaussian to produce a Gaussian sequence for each timestep, generating the final 4D representation.

This figure shows qualitative results of the L4GM model on two real-world videos. The images demonstrate the model’s ability to generate high-quality, temporally consistent 4D reconstructions of dynamic objects from single-view video inputs. The figure displays multiple frames from the generated 4D reconstructions, viewed from different angles, showcasing the quality and consistency of the results.

This figure compares the qualitative results of L4GM against three other state-of-the-art methods (OpenLRM, STAG4D, and DG4D) across four different animations. For each animation and method, the figure shows both the input view and a novel view generated by the model. The comparison highlights the superior quality and detail of L4GM’s generated views. The improvement of L4GM over the baselines is particularly noticeable in the quality of the rendered novel views, exhibiting better rendering of textures, and fewer artifacts. The overall visual fidelity and accuracy of 3D geometry are also significantly better in L4GM.

This figure presents a qualitative comparison of the results generated by OpenLRM, STAG4D, DG4D, and the proposed L4GM method on real-world videos. For each method, it displays the input view and a novel view generated by the model. The comparison focuses on showcasing the quality and realism of the generated 3D reconstructions for dynamic scenes captured from real-world videos. It visually demonstrates the relative strengths and weaknesses of each approach in handling real-world video data complexities.

This figure shows qualitative results of the proposed model on the Consistent4D dataset. The figure presents several examples of objects with their generated novel views from different angles. Each row represents a different object and shows the input view along with three generated novel views at two different time steps, illustrating the model’s capability to generate consistent and high-quality 4D representations.

This figure shows three examples where the L4GM model fails: motion ambiguity where the model struggles to produce natural motion across multiple views; multiple objects with occlusions where the model fails to reconstruct objects that are occluded; and ego-centric videos from Ego4D dataset [17] where the model fails when the input videos are taken from an ego-centric viewpoint.
This figure compares the qualitative results of L4GM against three baselines: OpenLRM, STAG4D, and DG4D. The comparison shows the input view and novel views generated by each method for several time steps. This allows for a visual assessment of the relative strengths and weaknesses of the various methods in terms of image quality, temporal coherence, and overall accuracy.

This figure shows qualitative results on the Consistent4D dataset. It presents several examples of 4D object reconstructions generated by the L4GM model, showcasing the model’s ability to generate consistent and high-quality animations from various viewpoints across different timesteps. Each row represents a different object from the dataset, and each column represents a view of the object at different timesteps, demonstrating the temporal consistency of the model’s output.
More on tables

This table presents the results of a user study comparing L4GM’s performance to three other state-of-the-art methods (DG4D, OpenLRM, and STAG4D) across five different aspects: Overall Quality, 3D Appearance, 3D Alignment with Input Video, Motion Alignment with Input Video, and Motion Realism. Each aspect is rated on a percentage scale based on user preferences from a total of 24 synthesized 4D scene examples. The table highlights that L4GM receives a higher percentage of favorable user ratings than the other methods across all five criteria.

This table presents a quantitative comparison of the proposed L4GM model against several state-of-the-art methods on the Consistent4D benchmark. The metrics used for comparison include LPIPS (Learned Perceptual Image Patch Similarity), CLIP (Contrastive Language–Image Pre-training) score, and FVD (Fréchet Video Distance). Lower LPIPS and FVD scores indicate better perceptual similarity and video quality, respectively, while higher CLIP scores represent better alignment with the ground truth. The table shows that L4GM outperforms existing methods across all metrics. Baseline results from Gao et al. [15] are also included for reference.
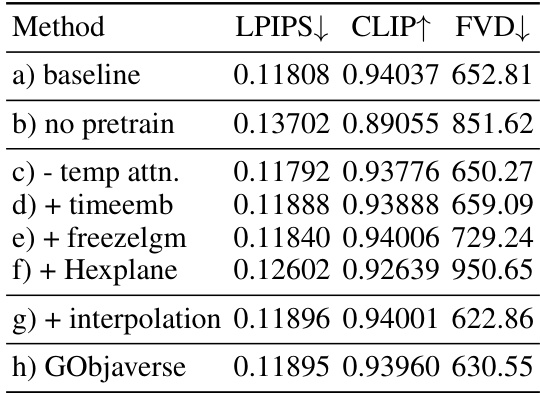
This table presents the ablation study results on the Consistent4D benchmark. It shows the performance of the L4GM model with different modifications, such as removing temporal attention, adding a time embedding, freezing the LGM model, adding a HexPlane, and using the interpolation model. Each row corresponds to a different variation of the model, with the baseline model in the first row. The results are reported using LPIPS, CLIP, and FVD metrics to evaluate the quality of the 4D reconstruction. The table helps to understand the impact of each model component on the overall performance.
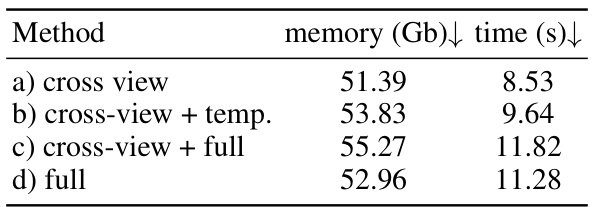
This table presents a comparison of memory usage (in GB) and processing time (in seconds) for different attention mechanisms used in the model. The methods compared include using only cross-view attention, cross-view attention with temporal attention, cross-view attention with full attention, and full attention alone. The results show that using full attention significantly increases both memory and processing time compared to using only cross-view or cross-view with temporal attention.
Full paper#