↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current video generation models rely on iterative denoising, leading to high computational costs. This limits real-time applications. The existing diffusion-based methods struggle to generate high-quality videos with fewer steps, particularly in a single step.
The researchers present SF-V, a novel method using adversarial training to fine-tune a pre-trained video diffusion model. This allows for single-step video generation. The improved architecture, incorporating spatial and temporal discriminator heads, enhances both image quality and motion consistency. The findings demonstrate significant computational gains (around 23x speedup) without compromising video quality, making real-time video generation feasible.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video generation and computer vision. It significantly advances single-step video synthesis, a computationally expensive area, enabling real-time applications and opening avenues for improved video editing and manipulation. The proposed method’s speed and quality improvements make it highly relevant to current research trends in efficient deep learning models.
Visual Insights#

This figure displays four example video generation results produced by the single-step image-to-video model presented in the paper. Each column shows a sequence of frames from a generated video, demonstrating the model’s ability to create high-quality, consistent motion across different scenes (an astronaut in space, a woman holding a torch, a robotic horse, and a monorail). The caption highlights that the model achieves this with only one sampling step during inference, showcasing its efficiency compared to existing multi-step approaches. View the full videos on the project’s webpage for a more comprehensive understanding.
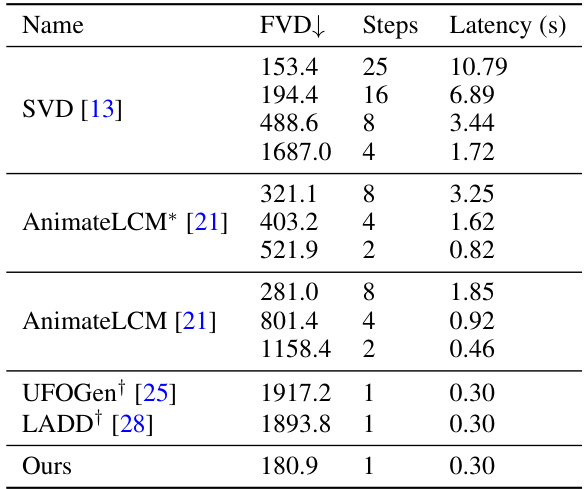
This table compares the performance of the proposed single-step video generation model against existing state-of-the-art methods. It shows the Fréchet Video Distance (FVD), number of sampling steps, and inference latency (on a single NVIDIA A100 GPU) for each model. The comparison includes the proposed model and other models using different numbers of sampling steps for a fair comparison.
In-depth insights#
Single-Step Synthesis#
The concept of “Single-Step Synthesis” in the context of video generation signifies a revolutionary advancement over traditional diffusion models. These models typically require multiple iterative denoising steps, leading to high computational costs and slow processing times. A single-step approach, however, drastically reduces the computational burden, paving the way for real-time video generation and editing. This is achieved by cleverly leveraging adversarial training techniques to effectively fine-tune pre-trained video diffusion models. The core idea involves training the model to perform a single forward pass, directly synthesizing high-quality, temporally consistent videos. Adversarial training plays a crucial role, ensuring the generated videos capture both spatial and temporal dependencies accurately. Reduced computational cost is a major advantage, but equally important is the potential for improved generation quality, as demonstrated by faster processing speed and higher fidelity outputs. This approach holds transformative potential for a wide array of applications where real-time video manipulation is vital, significantly expanding the possibilities for creating immersive and dynamic visual content.
Adversarial Training#
Adversarial training, in the context of this research paper, is a crucial technique for achieving single-step video generation. The method refines a pre-trained video diffusion model by pitting a generator network against a discriminator network in an adversarial game. The generator attempts to synthesize videos from noisy inputs, aiming to fool the discriminator. Simultaneously, the discriminator learns to distinguish between real and generated video frames, providing feedback to the generator for improvement. This process iteratively enhances the generator’s ability to produce high-quality, motion-consistent videos with significantly reduced computational cost compared to traditional multi-step diffusion models. The adversarial setup is key to bypassing the iterative denoising inherent in traditional diffusion models, allowing for a one-step forward pass. However, the effective implementation requires careful consideration of the architecture of both the generator and discriminator, particularly in addressing the spatial-temporal dependencies of video data. The success hinges on the discriminator’s ability to effectively evaluate both the spatial fidelity and temporal coherence of the generated video. The authors’ approach further optimizes this process by employing separate spatial and temporal discriminator heads to independently assess various aspects of video quality, ultimately leading to better performance.
Computational Speedup#
This research demonstrates a significant computational speedup in video generation. By employing adversarial training to fine-tune a pre-trained video diffusion model, the authors achieve a single-step video generation process, eliminating the iterative denoising steps needed in traditional methods. This results in a substantial speed increase, estimated at 23x compared to the baseline Stable Video Diffusion (SVD) model and 6x faster than existing single-step approaches. The speed improvement is attributed to the model’s ability to synthesize high-quality videos with a single forward pass, bypassing the computationally expensive iterative sampling. This significant efficiency gain opens doors for real-time video synthesis and editing applications, previously hindered by the computational limitations of diffusion models. The speedup, however, comes with a trade-off: the model’s performance is slightly impacted on complex scenarios that require more motion consistency.
Spatial-Temporal Heads#
The concept of “Spatial-Temporal Heads” in video generation models is crucial for capturing both spatial and temporal dependencies within video data. Spatial heads focus on processing individual frames, extracting relevant spatial features to ensure high-quality image generation. Temporal heads, conversely, analyze the temporal relationships between frames, facilitating the generation of smooth and consistent motion. The combined use of both allows the model to understand the visual information and motion within the video sequence effectively. The integration of these two types of heads within a discriminator network, for example, enables the model to differentiate between real and artificially generated videos by evaluating both the image quality of individual frames and the coherence of the motion across the sequence, improving the quality and realism of the generated output. The architecture and design of these heads (e.g., the number of layers, the specific convolutional or recurrent units used) would significantly affect the model’s capacity to capture and utilize the spatial-temporal information. Effective implementation would require careful consideration of computational cost versus performance.
Future Work#
The paper’s success in achieving single-step video generation opens several exciting avenues for future work. Improving the model’s ability to handle complex motions is crucial, as current limitations show artifacts in scenes with rapid or intricate movements. Exploring alternative architectural designs, such as more sophisticated attention mechanisms, could enhance the model’s capacity to capture temporal dynamics more effectively. Furthermore, research on new loss functions tailored to prioritize temporal consistency and motion quality should be investigated, potentially supplementing or replacing existing metrics. Addressing the computational cost of the video encoder and decoder remains important, and investigating more efficient architectures or compression techniques is necessary to optimize real-time performance. Finally, extending the model to handle longer video sequences and diverse input modalities (e.g., text-to-video, multi-modal generation) represents a significant direction for advancement.
More visual insights#
More on figures
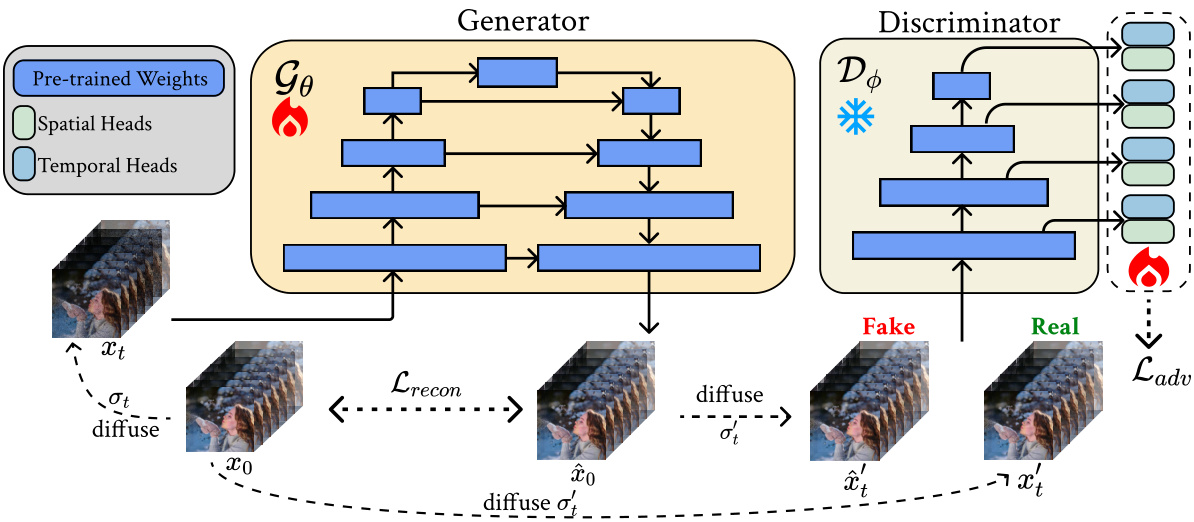
This figure illustrates the training pipeline of the proposed single-step video generation model. The generator and discriminator are initialized with pre-trained weights from an image-to-video diffusion model. The discriminator’s backbone is frozen, while spatial and temporal discriminator heads are added and trained. The training process involves adding noise to video latents, generating denoised latents using the generator, and calculating reconstruction and adversarial losses to refine the model. This process is designed to enable the generation of high-quality videos with a single forward pass.
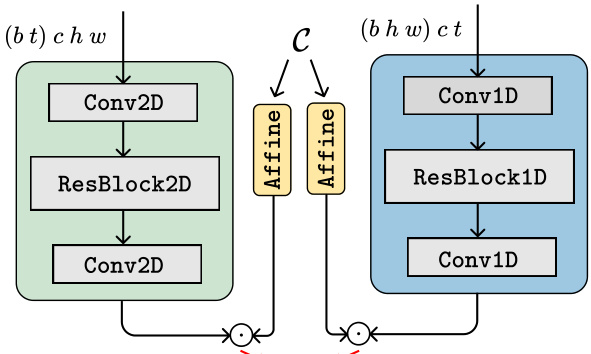
This figure illustrates the architecture of the spatial and temporal discriminator heads used in the model. The spatial head processes each frame independently by reshaping the input features to merge the temporal and batch axes. The temporal head, conversely, merges spatial dimensions to the batch axis, enabling it to capture temporal correlations between frames. Both heads receive intermediate features from the UNet encoder and use image conditioning (c) and frame index as input.

This figure showcases the model’s ability to generate high-quality, motion-consistent videos from a single conditioning image. It presents several example video sequences generated from different images depicting various scenes and objects. Each video consists of 14 frames at 1024 x 576 resolution and a frame rate of 7 FPS. The diversity of scenes highlights the model’s adaptability across different domains.

This figure compares the video generation results of different methods, including SVD, AnimateLCM, LADD, UFOGen, and the proposed method. It shows that the proposed method achieves comparable quality to SVD with 25 steps, significantly outperforming other single-step methods and showing a significant speed increase.

This figure shows probability density functions (PDFs) of σ′ for different values of Pmean and Pstd. The parameter σ′ represents the noise level added to the samples before being passed to the discriminator during training. The different curves illustrate how the distribution of σ′ changes depending on the chosen values of Pmean and Pstd, influencing the training stability and overall model performance.

This figure shows the impact of different noise level distributions on the video generation quality. Four different noise distributions are tested, each defined by parameters Pmean and Pstd which control the mean and standard deviation of the lognormal distribution of noise levels. The results, shown as the first and last frames of generated videos, demonstrate that the quality of the generated video is highly sensitive to the noise distribution used in training. A balanced noise distribution generally yields superior video quality.

This figure compares the video generation results of several different models, including the proposed single-step method, highlighting the trade-off between the number of sampling steps and the quality of the generated video. The proposed method shows comparable video quality to models using significantly more steps, demonstrating its speed advantage.
Full paper#



















