↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Offline multi-agent reinforcement learning (MARL) is challenging due to the difficulty of coordinating multiple agents’ behaviors and the limited sample efficiency when training independent models for each agent. Existing offline MARL methods often suffer from issues such as extrapolation errors and low expressiveness, hindering effective learning from pre-collected datasets. This paper introduces MADIFF, a novel framework designed to overcome these limitations by using an attention-based diffusion model.
MADIFF models the complex interactions among agents using an attention mechanism which dynamically weighs interactions between agents. This allows it to effectively handle the coordination challenges inherent in multi-agent systems. Furthermore, MADIFF operates under a centralized training, decentralized execution scheme which improves sample efficiency. Experiments on several benchmark tasks demonstrate MADIFF’s superior performance over existing methods, showing its effectiveness in both decentralized and centralized settings.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MADIFF, the first framework using diffusion models for offline multi-agent reinforcement learning. This addresses the limitations of existing methods, which struggle with coordination and sample efficiency in multi-agent settings. It opens new avenues for research in offline multi-agent learning and trajectory prediction. The proposed attention-based diffusion model shows strong potential for handling complex interactions among multiple agents, paving the way for more effective solutions in various applications.
Visual Insights#
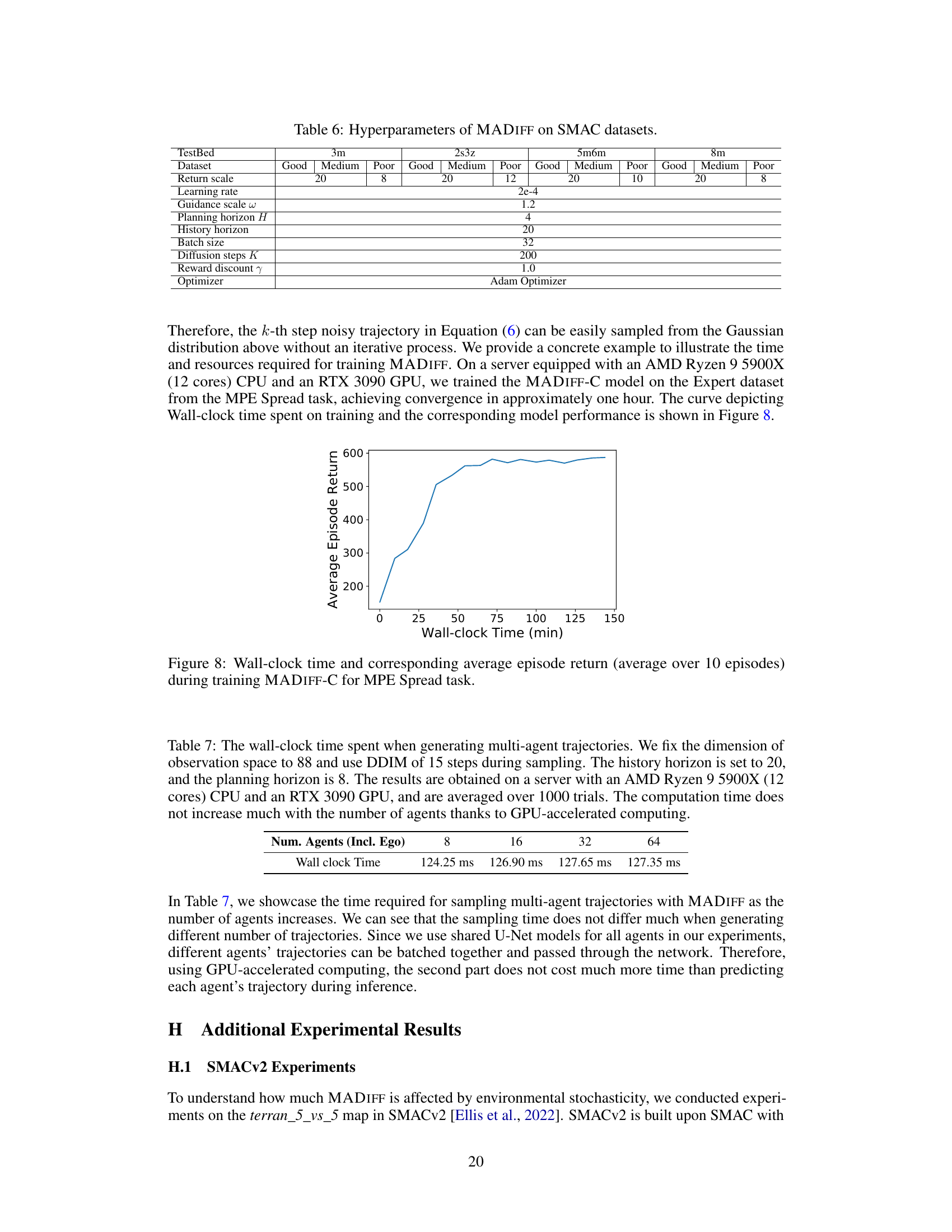
MADIFF is composed of an attention-based diffusion network. Each agent has its own U-Net (encoder-decoder structure). The key innovation is the attention layer that allows information to be shared between agents at each decoder layer. This facilitates coordination between agents. The inverse dynamics model predicts actions based on the generated state trajectories. Classifier-free guidance is used to condition the diffusion process, allowing the model to generate trajectories with specific characteristics.
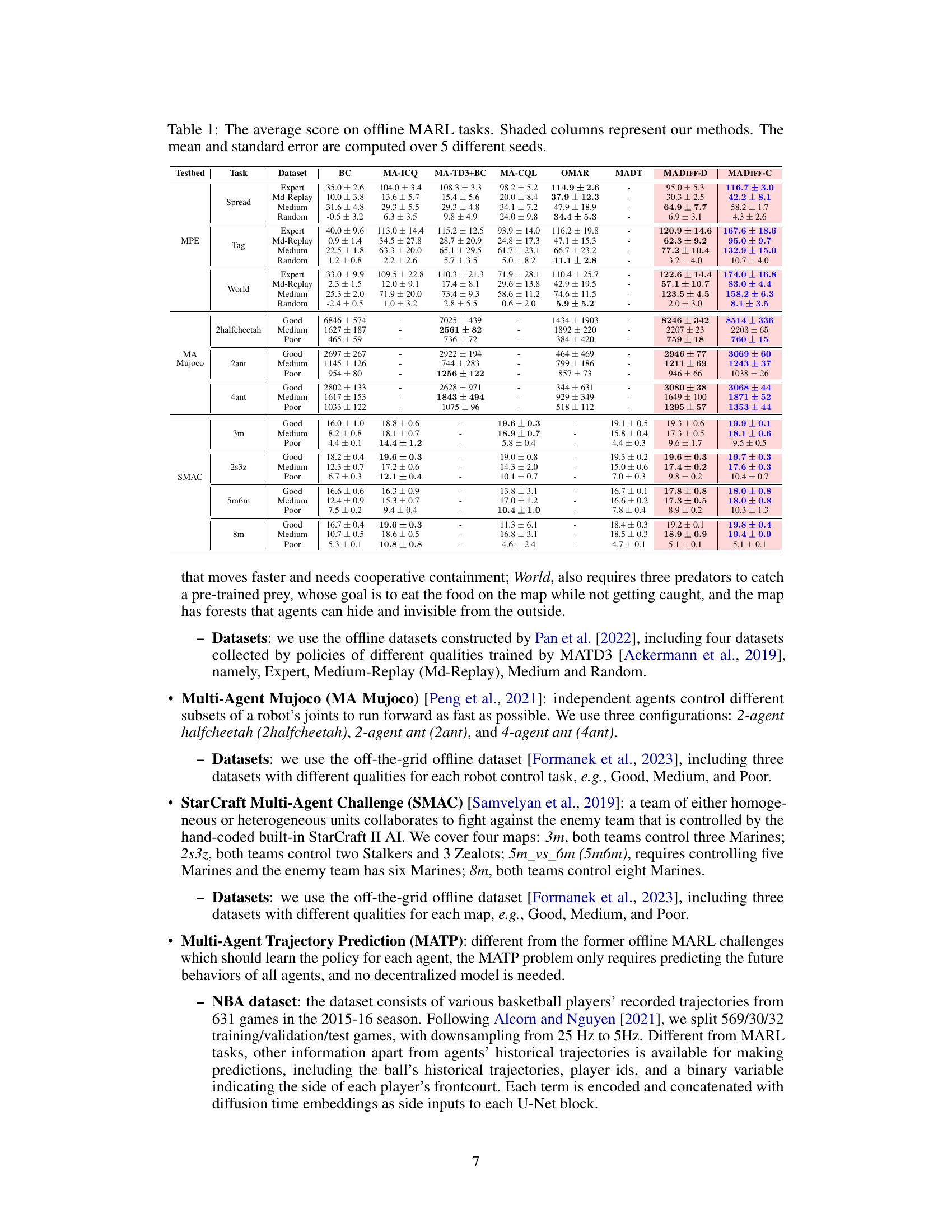
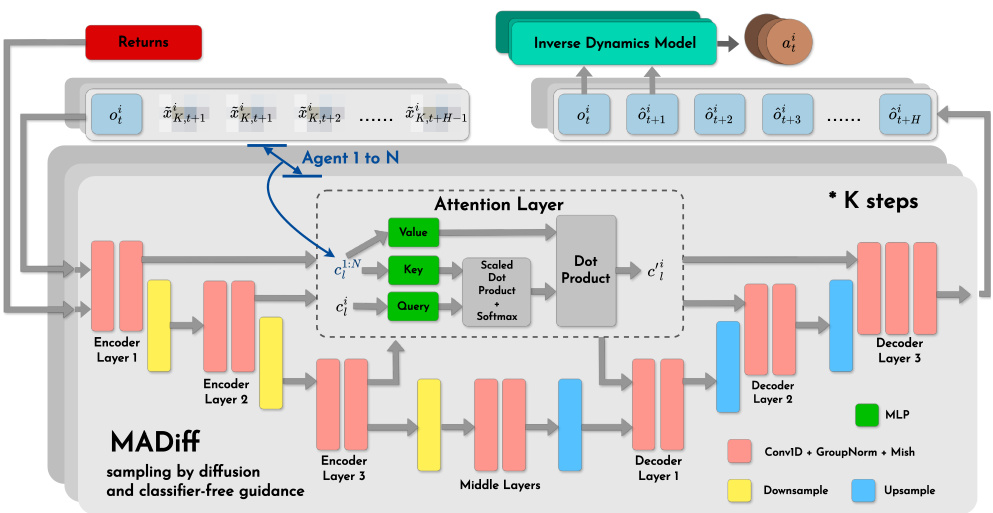
This table presents the average scores achieved by different multi-agent offline reinforcement learning methods across various tasks and datasets. The scores are normalized to account for variations in difficulty. The shaded columns highlight the performance of the MADIFF models, showcasing their improved performance compared to existing baselines.
In-depth insights#
Offline MAL#
Offline multi-agent learning (MAL) presents unique challenges compared to single-agent offline RL. The core difficulty lies in the interdependencies between agents’ actions and observations. In offline settings, the lack of online interaction and the need to learn from a fixed dataset exacerbate this issue. Traditional methods struggle with extrapolation errors and limited model expressiveness when addressing the complex coordination dynamics inherent in multi-agent systems. The paper highlights the need for methods that can effectively model these intricate interactions from offline data alone. Approaches that simply treat the multi-agent system as a single monolithic agent tend to be inefficient and fail to capture the nuances of individual agent behavior and their collective impact. Thus, novel approaches, such as using diffusion models with attention mechanisms to model complex inter-agent coordination, are critical. This enables the disentanglement of individual agent policies while still capturing their synergistic effects for improved performance and sample efficiency.
Diffusion Models#
Diffusion models, a class of generative models, are highlighted for their ability to effectively model complex, high-dimensional data distributions. Unlike traditional methods in offline reinforcement learning, which often struggle with extrapolation errors or are limited by model expressiveness, diffusion models show promise in overcoming these challenges. The paper focuses on their application in multi-agent settings, where the coordination among agents presents unique complexities. A key advantage lies in the capacity to capture intricate dependencies between agents’ behaviors. By modeling the entire joint trajectory distribution, rather than individual agent trajectories separately, diffusion models offer a powerful approach to learning effective and coordinated policies from offline data. The attention-based approach, further enhancing coordination modeling, allows the model to efficiently capture interactions and relationships among multiple agents without the limitations of simplistic concatenation techniques. This innovative approach provides the foundation for the proposed MADIFF framework, demonstrating significant improvements in offline multi-agent learning tasks.
MADIFF Framework#
The MADIFF framework presents a novel approach to offline multi-agent reinforcement learning (MARL) by leveraging diffusion models. Its core innovation lies in employing an attention-based diffusion model to capture the complex interdependencies between agents’ actions. Unlike methods using independent models for each agent or concatenating all agent information, MADIFF allows for efficient and accurate coordination modeling. The framework adopts a centralized training, decentralized execution (CTDE) paradigm, enabling efficient training and deployment in real-world scenarios. The attention mechanism dynamically models agent interactions, significantly reducing the parameter count and improving sample efficiency. Furthermore, MADIFF inherently performs teammate modeling, offering a more complete understanding of agent behaviors without added computational costs. Its effectiveness is demonstrated across various multi-agent tasks, showcasing its ability to handle complex interactions and outperform existing offline MARL methods. The framework also extends to multi-agent trajectory prediction with promising results.
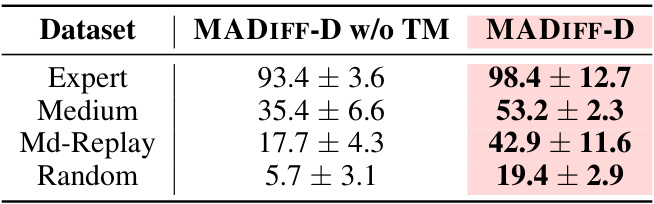
Teammate Modeling#
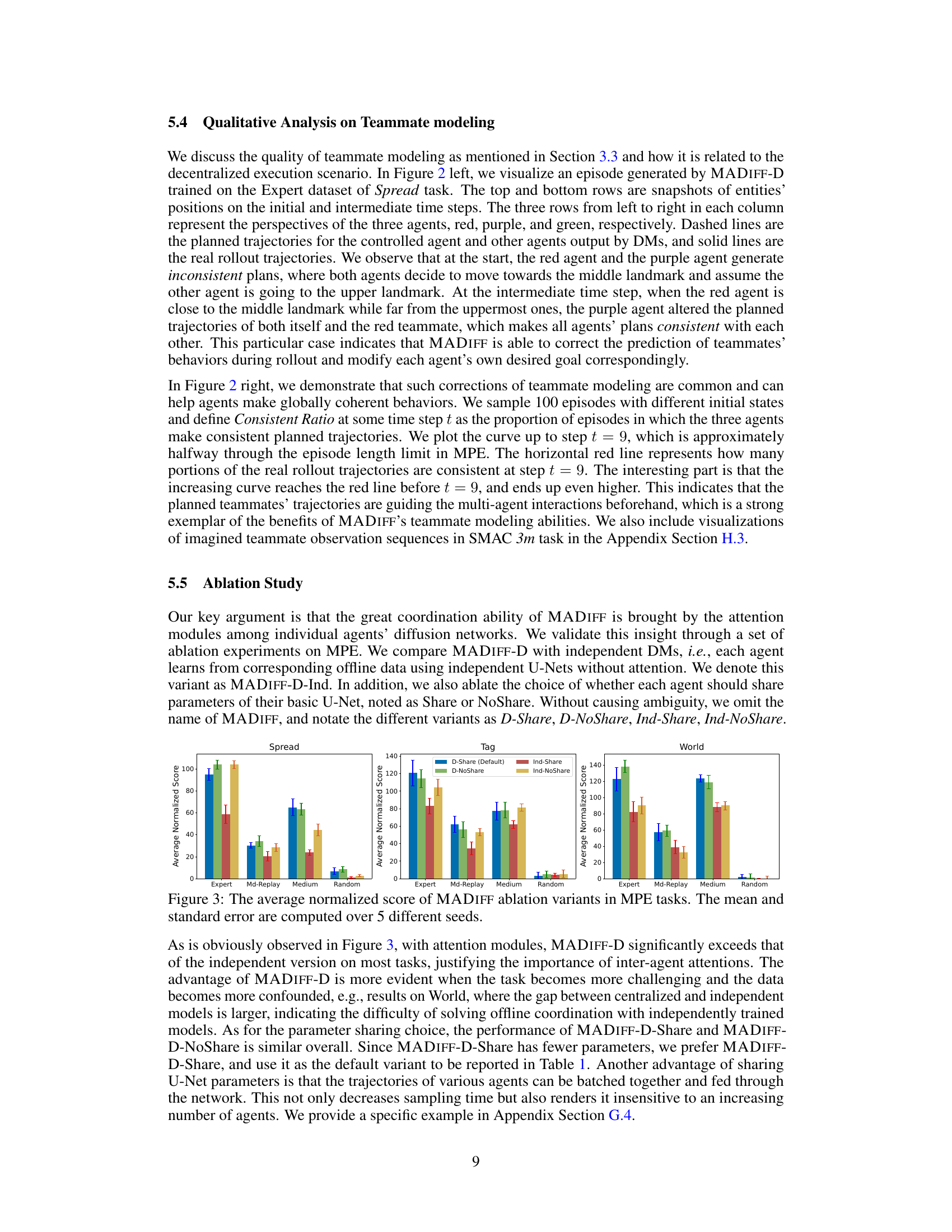
The concept of teammate modeling in multi-agent systems is crucial for achieving effective collaboration. It involves agents learning to predict and anticipate the actions and behaviors of their teammates. This predictive capability allows agents to coordinate more effectively, reducing conflicts and improving overall performance. MADIFF’s approach to teammate modeling is particularly noteworthy, as it integrates this functionality directly within the diffusion model framework. Rather than relying on separate modules, MADIFF’s attention mechanism enables each agent to implicitly model the behavior of others during trajectory generation. This centralized training decentralized execution approach offers a principled solution where agents learn coordinated behaviors during training, yet execute independently during inference. The effectiveness of this integrated teammate modeling is demonstrated empirically across multiple multi-agent tasks. The experiments highlight how MADIFF’s architecture allows agents to not only make better individual decisions, but also to correct inconsistent plans and anticipate teammates’ actions in a dynamic environment. This innovative approach surpasses baselines by accurately predicting and adapting to teammates’ behaviors, ultimately leading to improved coordination and significantly better results. Future work could investigate the scalability of this technique to larger numbers of agents and explore the impact of varying levels of teammate predictability on overall performance.
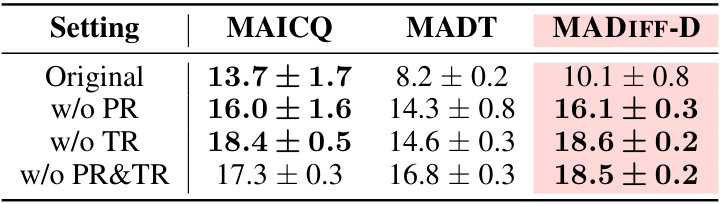
Ablation Study#
The ablation study section in this research paper is crucial for validating the core claims. By systematically removing components of the proposed model (MADIFF), the authors aim to isolate the contribution of each part and understand its impact on overall performance. The attention mechanism’s importance is specifically highlighted, showing significantly better results when active compared to an independent model architecture. This confirms the effectiveness of MADIFF’s design in handling complex multi-agent interactions. Further analysis is also performed, examining the influence of parameter sharing on model performance. The study’s results provide strong evidence for the model’s design choices and robustness, demonstrating the benefits of using an attention-based diffusion model and a unified framework in solving offline multi-agent problems. Although the study focuses on a specific set of tasks, the clear and detailed methodology strengthens the conclusions about the impact of various model components. Future work could extend this ablation study to a broader range of tasks and a larger-scale, more complex setting.
More visual insights#
More on figures
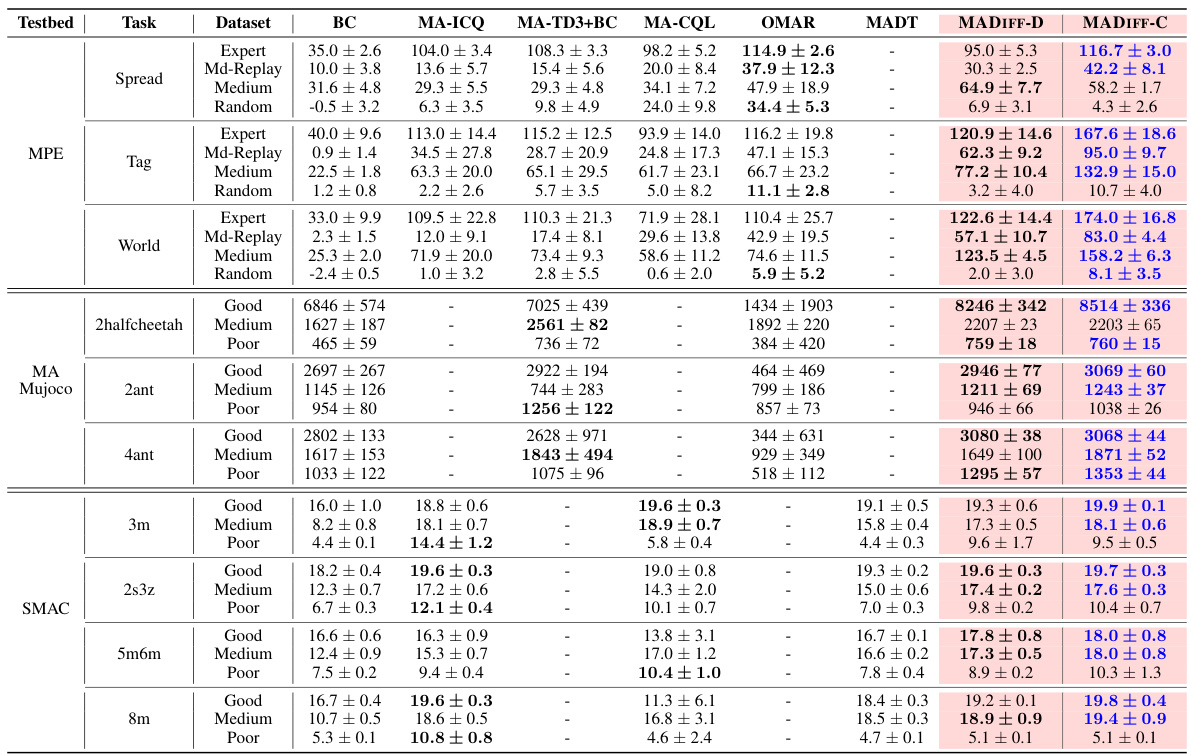
This figure visualizes an episode of the Spread task in the Multi-Agent Particle Environments (MPE) benchmark. It shows the trajectories of three agents (one planning agent and two other agents) aiming to cover three landmarks without collisions. The solid lines represent the actual trajectories followed by the agents during the episode’s execution. The dashed lines illustrate the trajectories planned by the MADIFF model. The figure highlights the agents’ initial inconsistent plans at time step t=0, where each agent makes independent decisions leading to potential collisions, and the eventual convergence towards consistent plans at time step t=4, showcasing MADIFF’s ability to coordinate agents’ behaviors. The adjacent plot demonstrates the ‘Consistent Ratio’ (proportion of episodes where agents show consistent trajectories) over environment steps, illustrating MADIFF’s correction capability over time.
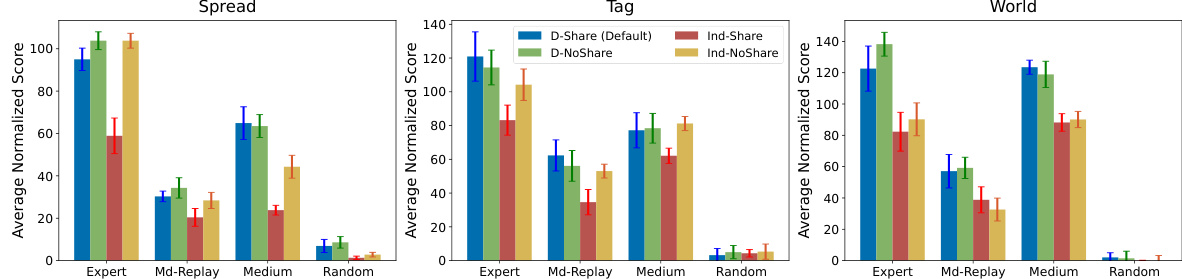
This figure presents the results of an ablation study on the MADIFF model, comparing its performance with variations in the attention mechanism and parameter sharing. Four datasets (Expert, Md-Replay, Medium, Random) are used for evaluation across three MPE tasks (Spread, Tag, World). The bars represent the average normalized scores, with error bars indicating standard deviation. The comparison shows the impact of using independent diffusion models (Ind-Share, Ind-NoShare) versus the attention-based approach (D-Share, D-NoShare) with and without shared parameters within the U-Net architecture of each agent. This helps determine the effect of the proposed attention mechanism and parameter sharing on coordination.
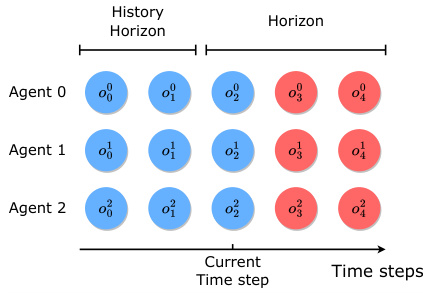
This figure shows how MADIFF models agents’ observations in both centralized and decentralized control settings. Panel (a) illustrates centralized control, where the model receives and conditions on all agents’ observations to generate future trajectories. Panel (b) depicts decentralized execution; only the current agent’s local observations are used for the model, thereby implicitly requiring it to model the other agents’ behaviors (teammate modeling). The figure highlights the difference in information used by the model, depending on the control paradigm.

This figure illustrates how MADIFF models agents’ observations in both centralized and decentralized execution scenarios. Panel (a) shows centralized control where MADIFF considers all agents’ observations when generating future trajectories. Panel (b) demonstrates decentralized execution, where only agent 1’s observations are used to generate agent 1’s trajectory, highlighting the model’s ability to predict other agents’ actions (teammate modeling) despite the decentralized nature of the decision-making.
This figure shows the architecture of MADIFF, a multi-agent diffusion model. It uses a U-Net architecture with attention mechanisms applied at each decoder layer to allow for information sharing between agents. The model takes as input the observations and actions of all agents and outputs the next actions for each agent. The attention mechanism is crucial for modeling the complex interactions between agents.
MADIFF is an attention-based diffusion network. It consists of multiple agent-specific U-Nets, each processing agent-specific observations. A key element is the attention layer that allows for the exchange of information between the agents at each decoder layer. This enables coordination among agents during trajectory generation. The inverse dynamics model predicts actions based on generated state transitions. Classifier-free guidance is used to condition the model on desired return values for targeted trajectory generation.
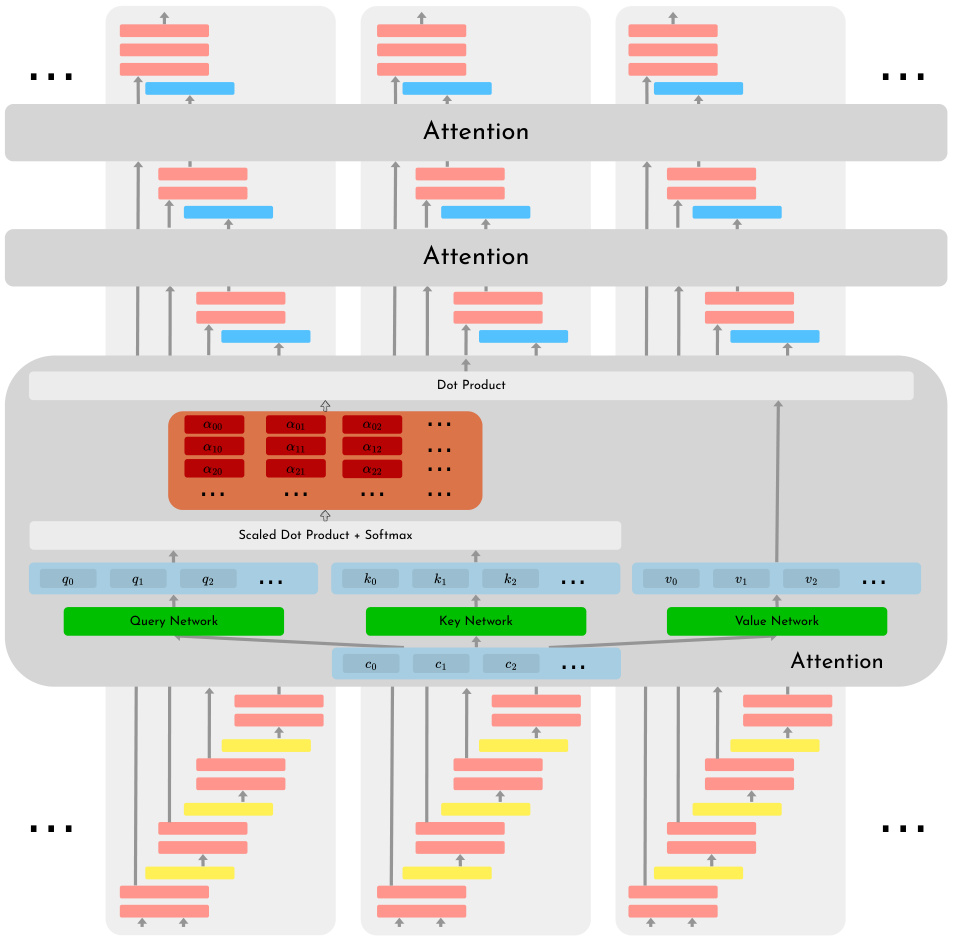
MADIFF is an attention-based diffusion model for multi-agent reinforcement learning. The figure shows its architecture, highlighting the use of a U-Net structure for each agent. Key features include attention layers applied at each decoder layer, allowing for information exchange between agents, and a shared backbone for efficient parameter sharing. The model takes in observations, processes them through encoder and decoder layers, and uses classifier-free guidance to generate future trajectories for all agents.
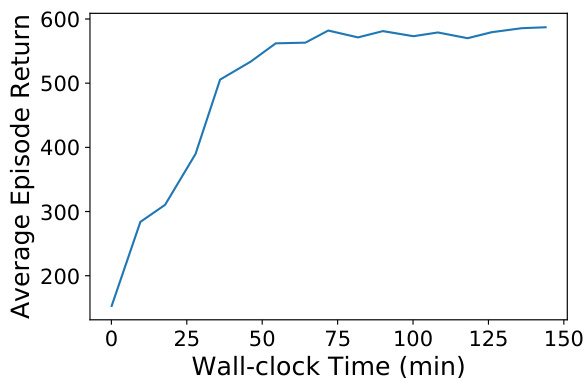
The figure shows the relationship between the training time (wall-clock time in minutes) and the average episode return achieved by the MADIFF-C model during training on the MPE Spread task. The x-axis represents the training time, while the y-axis represents the average episode return. The curve demonstrates the convergence of the MADIFF-C model towards a stable performance on the task. The training time is approximately one hour, and the average episode return reaches a plateau after about 60 minutes of training.
The figure shows the architecture of MADIFF, a multi-agent learning framework based on an attention-based diffusion model. The model uses a U-Net structure for each agent, with attention layers between decoder layers to allow for information exchange between agents. The inputs are observations, and the outputs are actions. The model uses inverse dynamics to predict actions. The model also uses classifier-free guidance and low-temperature sampling.
MADIFF is an attention-based diffusion model for multi-agent reinforcement learning. The figure shows the architecture of MADIFF, illustrating how it uses an attention mechanism to integrate information from multiple agents at each decoder layer. This allows the model to capture the complex interactions between agents and learn effective coordinated policies. The model consists of multiple agent-specific U-Nets with attention layers connecting them. These U-Nets process information from the agents, and the attention layers allow information to flow between the agents, enabling them to coordinate their actions.
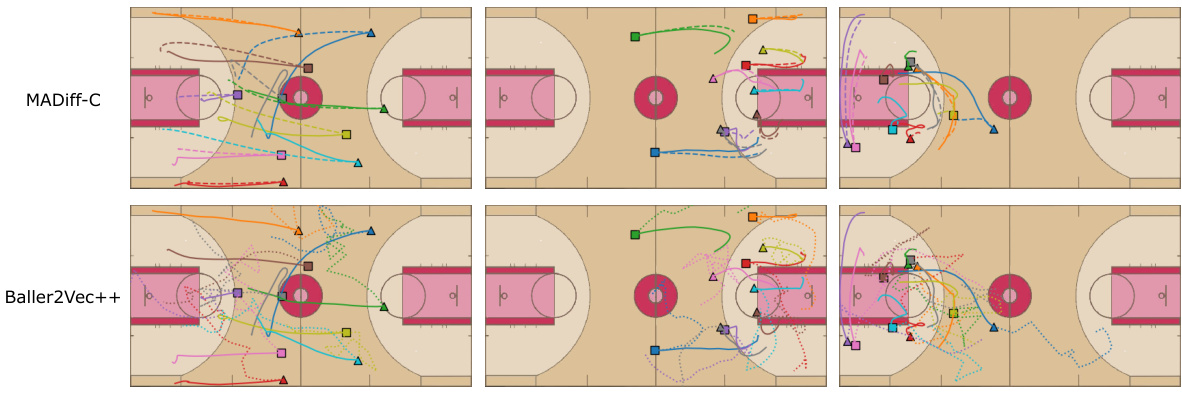
This figure visualizes the real and predicted trajectories of multiple basketball players. The top row shows trajectories generated by the MADIFF-C model, while the bottom row displays trajectories from the Baller2Vec++ model. Each trajectory is color-coded for easy identification of individual players. The figure demonstrates the visual comparison of the generated trajectories (dashed lines) with the actual trajectories (solid lines). This allows for an assessment of the accuracy and smoothness of each model’s predictions.
More on tables
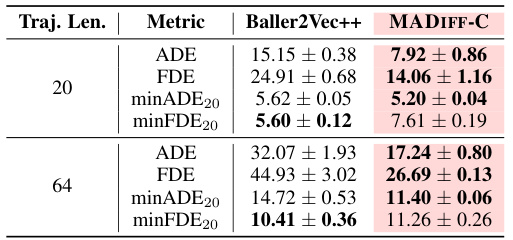
This table presents a comparison of the average scores achieved by different multi-agent offline reinforcement learning methods across various tasks. The scores represent the performance of each algorithm on different datasets and tasks, categorized by environment (MPE, MA Mujoco, SMAC) and task difficulty (Spread, Tag, World, etc.). The shaded columns highlight the performance of the proposed MADIFF method (MADIFF-D and MADIFF-C), showing its comparative advantage. The mean and standard error are calculated across five different random seeds to provide a measure of statistical significance.
This table presents the average scores achieved by different multi-agent offline reinforcement learning methods across various tasks and datasets. The scores represent the performance of each algorithm on several benchmark environments, categorized by type (MPE, MuJoCo, SMAC) and dataset quality (Expert, Md-Replay, Medium, Random). Shaded columns highlight the results obtained using the MADIFF method (both centralized and decentralized versions), allowing for comparison against other state-of-the-art methods such as MA-ICQ, MA-TD3+BC, MA-CQL, and OMAR. The mean and standard error are calculated from results obtained across five independent experimental runs, indicating the statistical significance of the reported results.

This table presents the average scores achieved by different multi-agent offline reinforcement learning methods on various tasks. The shaded columns highlight the performance of the MADIFF methods (MADIFF-D and MADIFF-C). The table includes results for several benchmark algorithms and different datasets, providing a comprehensive comparison of the proposed approach against existing state-of-the-art methods. The scores are averages calculated across five different random seeds to ensure statistical reliability. The standard error is also reported for each entry.
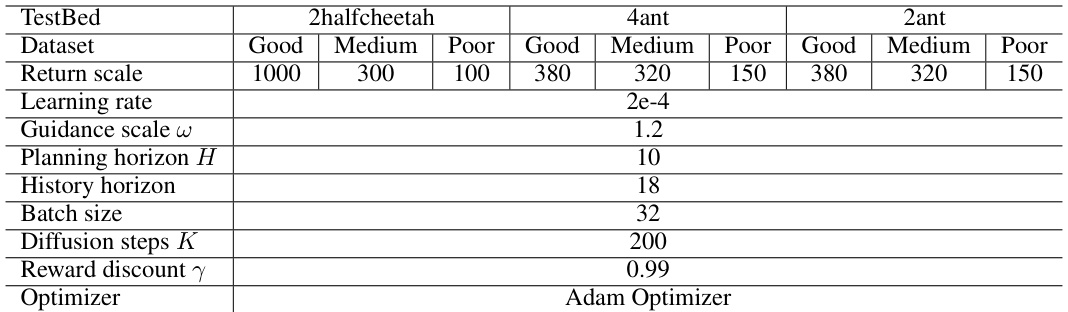
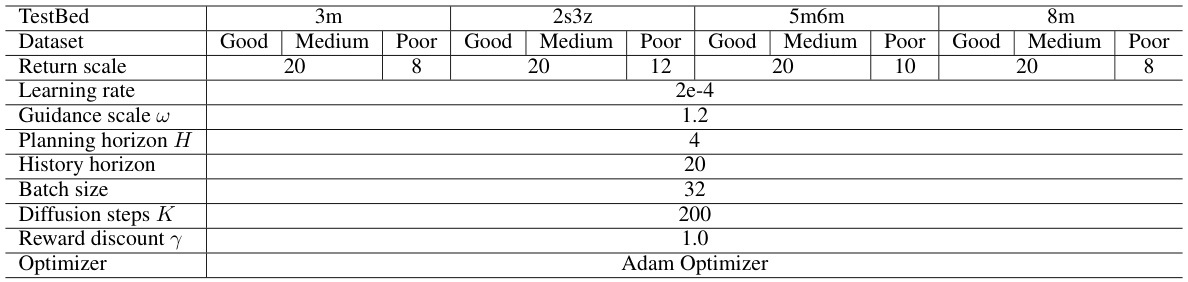
This table shows the hyperparameters used for training the MADIFF model on the MA Mujoco datasets. It details the settings used for each task (2halfcheetah, 2ant, 4ant) and dataset quality (Good, Medium, Poor). The parameters listed include the return scale, learning rate, guidance scale, planning horizon, history horizon, batch size, diffusion steps, reward discount, and the optimizer used. These hyperparameters were tuned for optimal performance on each specific task and dataset.
This table presents the average scores achieved by different multi-agent offline reinforcement learning methods across various tasks and datasets. The scores represent the performance of each algorithm, with shaded columns indicating the results obtained using the MADIFF methods proposed in the paper. The mean and standard error are calculated across five different random seeds for each entry, providing a measure of the statistical reliability of the results.

This table presents the average scores achieved by different multi-agent offline reinforcement learning (MARL) methods across various tasks and datasets. The scores are calculated as the episodic return in online rollouts. The table includes both baseline methods and the proposed method (MADIFF), with results shown for different dataset qualities (Expert, Md-Replay, Medium, and Random). Shaded columns highlight the performance of MADIFF, indicating its superior performance. The mean and standard error are calculated across five different random seeds for each method and dataset combination.
This table presents the average scores achieved by different offline multi-agent reinforcement learning (MARL) methods across various tasks and datasets. The methods are evaluated using the episodic return obtained in online rollout as a performance measure. The shaded columns highlight the performance of the proposed MADIFF methods (MADIFF-D and MADIFF-C). The results are averaged over five different random seeds to provide a measure of statistical significance. Each dataset represents a different level of data quality (Expert, Md-Replay, Medium, Random) that was used for training the algorithms.
This table presents the average scores achieved by different offline multi-agent reinforcement learning (MARL) methods across various tasks and datasets. The shaded columns highlight the performance of the proposed methods (MADIFF-D and MADIFF-C). The results are averaged over 5 different random seeds, and the standard error is included to indicate the variability of the results. The table allows for a comparison of the proposed method’s performance against existing state-of-the-art MARL algorithms.
Full paper#