TL;DR#
Vision Transformers (ViTs) are powerful but computationally expensive due to their self-attention mechanism. Recent token reduction methods address this by merging similar tokens, but these methods often depend on intermediate ViT features, limiting their flexibility and requiring extensive end-to-end training. This dependence restricts the ability to optimize token merging independently and fully leverage pre-trained models.
This paper introduces Decoupled Token Embedding for Merging (DTEM), which enhances token merging through a decoupled embedding module trained via a continuously relaxed merging process. This decoupling allows for the extraction of dedicated features for merging, independent of the ViT forward pass. The continuous relaxation facilitates differentiable training, enabling modular optimization with pre-trained models and enhanced generalization across different reduction rates. Experiments across various ViT models and tasks (classification, captioning, segmentation) demonstrate consistent improvement in token merging with significant FLOP reduction while maintaining high accuracy.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes a novel and efficient method for token merging in Vision Transformers (ViTs), a crucial aspect of improving the efficiency and performance of these powerful models. The method’s modularity and adaptability make it highly relevant to current research trends and its continuous relaxation of token merging opens new avenues for developing advanced token reduction techniques.
Visual Insights#
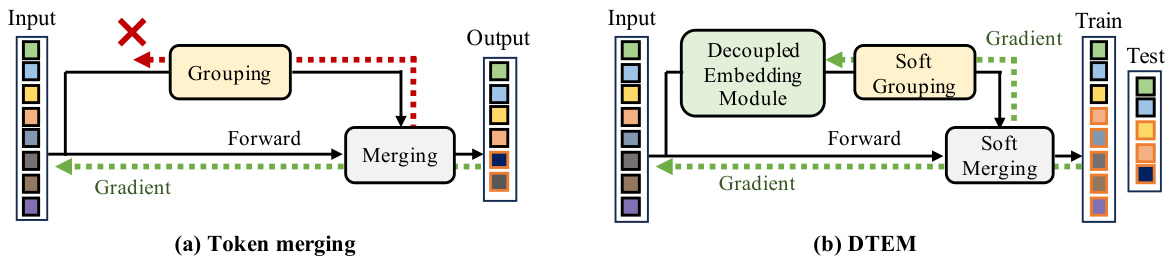
🔼 The figure compares conventional token merging with the proposed DTEM method. Conventional methods directly use intermediate features from the Vision Transformer (ViT) to determine which tokens to merge. DTEM, in contrast, uses a separate, learned ‘decoupled embedding module’ to extract features specifically designed for the token merging process. This decoupled approach allows for continuous relaxation of the merging operations during training, enabling more effective learning and facilitating integration with pre-trained ViT models.
read the caption
Figure 1: Comparison of our method with conventional token merging. Contrary to prior works that merge tokens directly based on intermediate features in ViT, our method leverages a decoupled embedding to extract features tailored for token merging. The embedding module is trained via continuous relaxation of grouping and merging operators, i.e., soft grouping and merging, respectively, that allow differentiation.
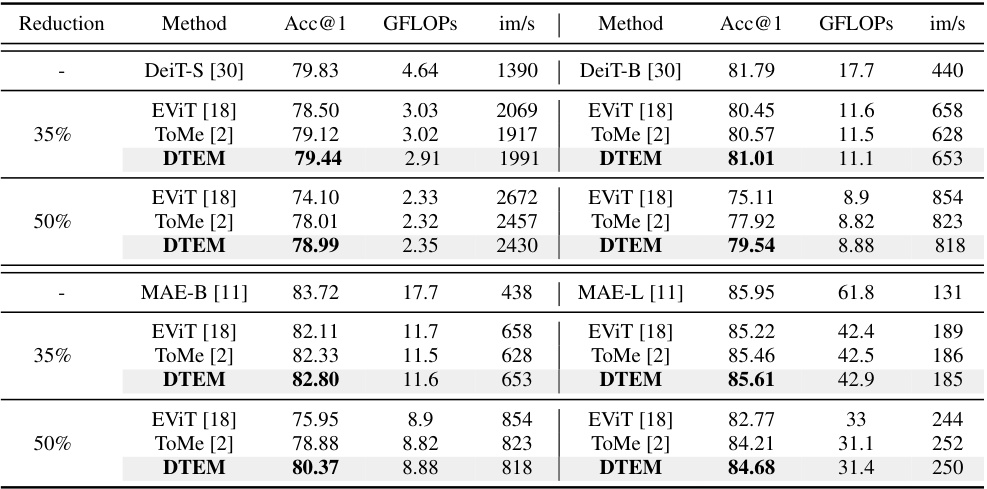
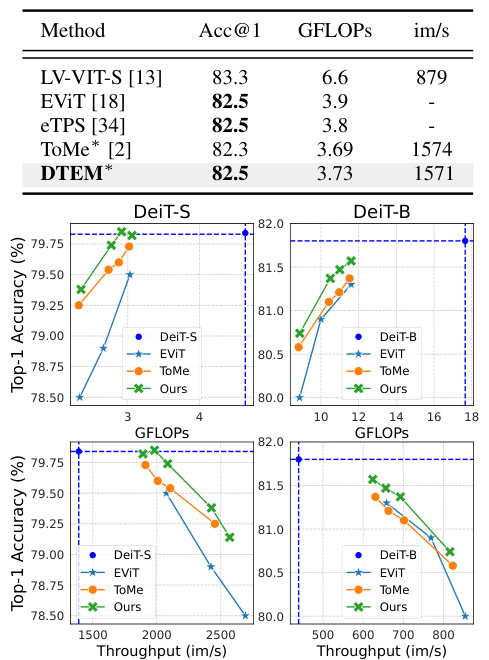
🔼 This table presents the classification accuracy (Acc@1), GFLOPs (floating point operations), and images per second (im/s) for different vision transformer models (DeiT-S, DeiT-B, MAE-B, MAE-L) with varying token reduction rates (35% and 50%). The results compare the performance of our proposed method (DTEM) against existing methods (EVIT and ToMe). It demonstrates the impact of DTEM on model efficiency while maintaining competitive accuracy.
read the caption
Table 1: Classification results with off-the-shelf frozen pre-trained models. Reduction roughly represents the decreases in FLOPs.
In-depth insights#
Decoupled Embedding#
The concept of “Decoupled Embedding” presented in the paper is a key innovation for efficient token merging in Vision Transformers. Instead of relying on intermediate features within the transformer network, which are already tasked with contextual encoding, a separate embedding module is introduced. This module learns a dedicated embedding specifically designed for the token merging process. This decoupling addresses the limitations of previous methods that directly used intermediate features, which are not optimized for the specific needs of merging. By training this dedicated module using a continuously relaxed merging process, the model learns a differentiable representation that enhances token merging’s efficiency and modularity. This approach allows the model to seamlessly integrate with existing ViT backbones, and to be trained either modularly, by learning the decoupled embeddings alone, or end-to-end by fine-tuning the entire network. The effectiveness of this method is demonstrated through consistent improvements across multiple tasks and ViT architectures.
Soft Token Merging#
Soft token merging, as a concept, presents a compelling approach to enhancing the efficiency of Vision Transformers (ViTs). The core idea revolves around replacing the discrete nature of traditional token merging techniques with a continuous, differentiable alternative. This shift allows for the seamless integration of token merging within the training process, significantly simplifying the optimization landscape. By using soft grouping and merging operators, the model learns to weigh the contribution of each token to the overall representation, instead of making hard decisions about which tokens to combine. This approach is particularly beneficial when working with pre-trained models, as it allows for modular training, avoiding extensive and computationally expensive fine-tuning of the entire network. Continuous relaxation also enables the use of gradient-based optimization to refine the parameters of the decoupled embedding module. This contributes to more accurate and effective token merging, leading to improvements in various downstream tasks, such as classification and segmentation. A key advantage of this approach is the generalization capabilities; the continuous nature of merging helps the model perform well across a range of reduction rates, and it can be readily applied to different ViT architectures. However, careful design and consideration are needed to appropriately relax the discrete merging process, ensuring effective convergence to desired hard merging behavior during inference. Further analysis on the implications of different soft operators and their impact on overall performance is needed to fully assess and optimize this promising method.
Modular Training#
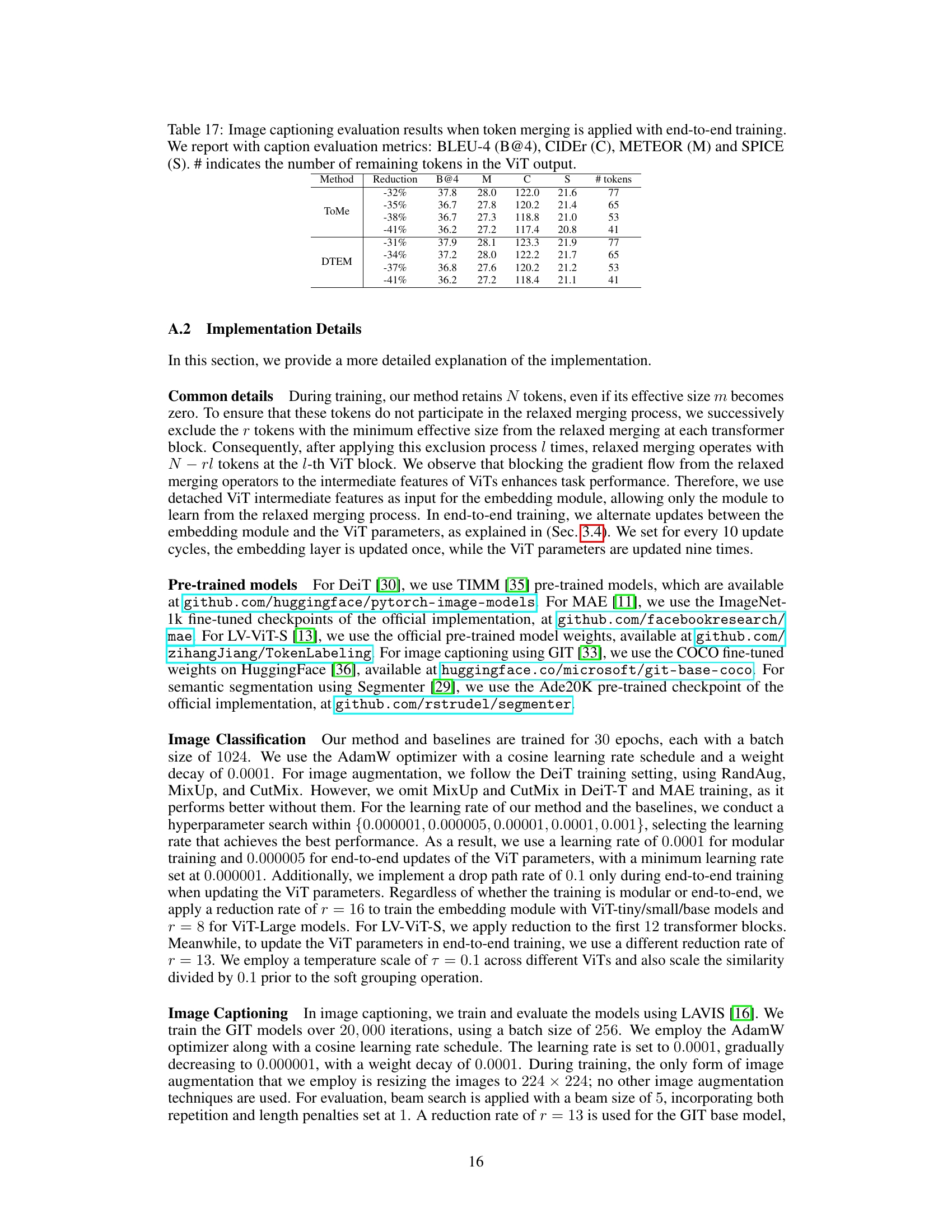
Modular training, as presented in the context of the research paper, offers a compelling approach to enhance the efficiency and effectiveness of Vision Transformers (ViTs). By decoupling the embedding module from the main ViT architecture, the method allows for training the merging policy without altering the pre-trained model’s parameters. This significantly reduces the computational cost associated with end-to-end training, enabling the effective utilization of existing pre-trained models. The modularity also facilitates training with smaller datasets and fewer training epochs, making it more practical and resource-efficient. Moreover, the continuous relaxation of grouping and merging operators allows for differentiable training of the decoupled embedding, leading to improved generalization across various token reduction rates. This approach offers a strong alternative to end-to-end training, especially when computational resources or large-scale training datasets are constrained. The seamless integration with existing ViT backbones highlights the modularity’s flexibility and potential for broader applicability.
Image Classification#
The Image Classification section likely details experiments evaluating the proposed method’s effectiveness on a standard image classification benchmark, such as ImageNet. Results would show accuracy metrics (e.g., top-1 and top-5 accuracy) comparing the method against state-of-the-art techniques. A key aspect will be demonstrating improvements in accuracy while achieving computational efficiency (measured by FLOPs or inference time). The discussion might delve into ablation studies, investigating the impact of specific components (e.g., the decoupled embedding module) on performance and efficiency. Analysis of different token reduction rates is also crucial, illustrating how the method balances accuracy and computational cost at various reduction levels. This section would provide compelling evidence supporting the method’s efficacy for real-world applications where computational resources are constrained.
Future Directions#
Future research could explore more sophisticated token merging strategies beyond simple similarity metrics, perhaps incorporating semantic information or leveraging attention mechanisms to identify tokens for merging. Investigating the optimal balance between computational efficiency and accuracy gains is crucial, requiring careful experimentation across various datasets and model architectures. Exploring alternative training methodologies, such as curriculum learning or self-supervised learning, could improve the efficiency and generalization capabilities of decoupled token embedding. A deeper analysis into the impact of token merging on different vision tasks is needed, particularly understanding how it affects the model’s ability to capture long-range dependencies. Finally, extending these techniques to other modalities and architectures, such as audio or natural language processing, presents another exciting avenue for future work. Ultimately, the goal is to push the boundaries of efficient vision transformers and unlock new capabilities in computer vision applications.
More visual insights#
More on figures
🔼 The figure compares the proposed DTEM method with conventional token merging methods. Conventional methods directly use intermediate features from the Vision Transformer (ViT) to decide which tokens to merge. In contrast, DTEM uses a separate, learned embedding module to extract features specifically designed for the token merging process. This decoupling allows for more effective merging and enables training using continuously relaxed (soft) grouping and merging operators, which are differentiable and thus more easily trained.
read the caption
Figure 1: Comparison of our method with conventional token merging. Contrary to prior works that merge tokens directly based on intermediate features in ViT, our method leverages a decoupled embedding to extract features tailored for token merging. The embedding module is trained via continuous relaxation of grouping and merging operators, i.e., soft grouping and merging, respectively, that allow differentiation.
🔼 This figure compares the proposed method, Decoupled Token Embedding for Merging (DTEM), with conventional token merging methods. Conventional methods directly use intermediate features from the Vision Transformer (ViT) to determine which tokens to merge. In contrast, DTEM uses a separate, decoupled embedding module to learn features specifically for merging, independent of the ViT’s main processing. This decoupling allows for more effective merging and training flexibility. DTEM uses ‘soft’ grouping and merging during training, enabling a differentiable process that improves learning of the decoupled embedding. During inference, these soft operators transition to hard operators, resulting in a similar outcome to other methods but with improved efficiency and generalization.
read the caption
Figure 1: Comparison of our method with conventional token merging. Contrary to prior works that merge tokens directly based on intermediate features in ViT, our method leverages a decoupled embedding to extract features tailored for token merging. The embedding module is trained via continuous relaxation of grouping and merging operators, i.e., soft grouping and merging, respectively, that allow differentiation.

🔼 The figure compares the proposed method (DTEM) with conventional token merging methods. Conventional methods directly use intermediate features from the Vision Transformer (ViT) to determine which tokens to merge. In contrast, DTEM uses a separate, decoupled embedding module to learn features specifically designed for the token merging process. This decoupled module is trained using a continuous relaxation of the grouping and merging steps, making the training process differentiable. This allows for more effective learning and easier integration into pre-trained ViT models.
read the caption
Figure 1: Comparison of our method with conventional token merging. Contrary to prior works that merge tokens directly based on intermediate features in ViT, our method leverages a decoupled embedding to extract features tailored for token merging. The embedding module is trained via continuous relaxation of grouping and merging operators, i.e., soft grouping and merging, respectively, that allow differentiation.

🔼 This figure compares the proposed DTEM method with conventional token merging methods. Conventional methods directly use intermediate features from the Vision Transformer (ViT) to determine which tokens to merge. In contrast, DTEM uses a separate, decoupled embedding module to extract features specifically designed for the merging process. This decoupled module is trained using a continuous relaxation technique (soft grouping and merging), allowing for differentiable training and better optimization. The result is a more effective token merging strategy that avoids interfering with the ViT’s core function of feature extraction.
read the caption
Figure 1: Comparison of our method with conventional token merging. Contrary to prior works that merge tokens directly based on intermediate features in ViT, our method leverages a decoupled embedding to extract features tailored for token merging. The embedding module is trained via continuous relaxation of grouping and merging operators, i.e., soft grouping and merging, respectively, that allow differentiation.
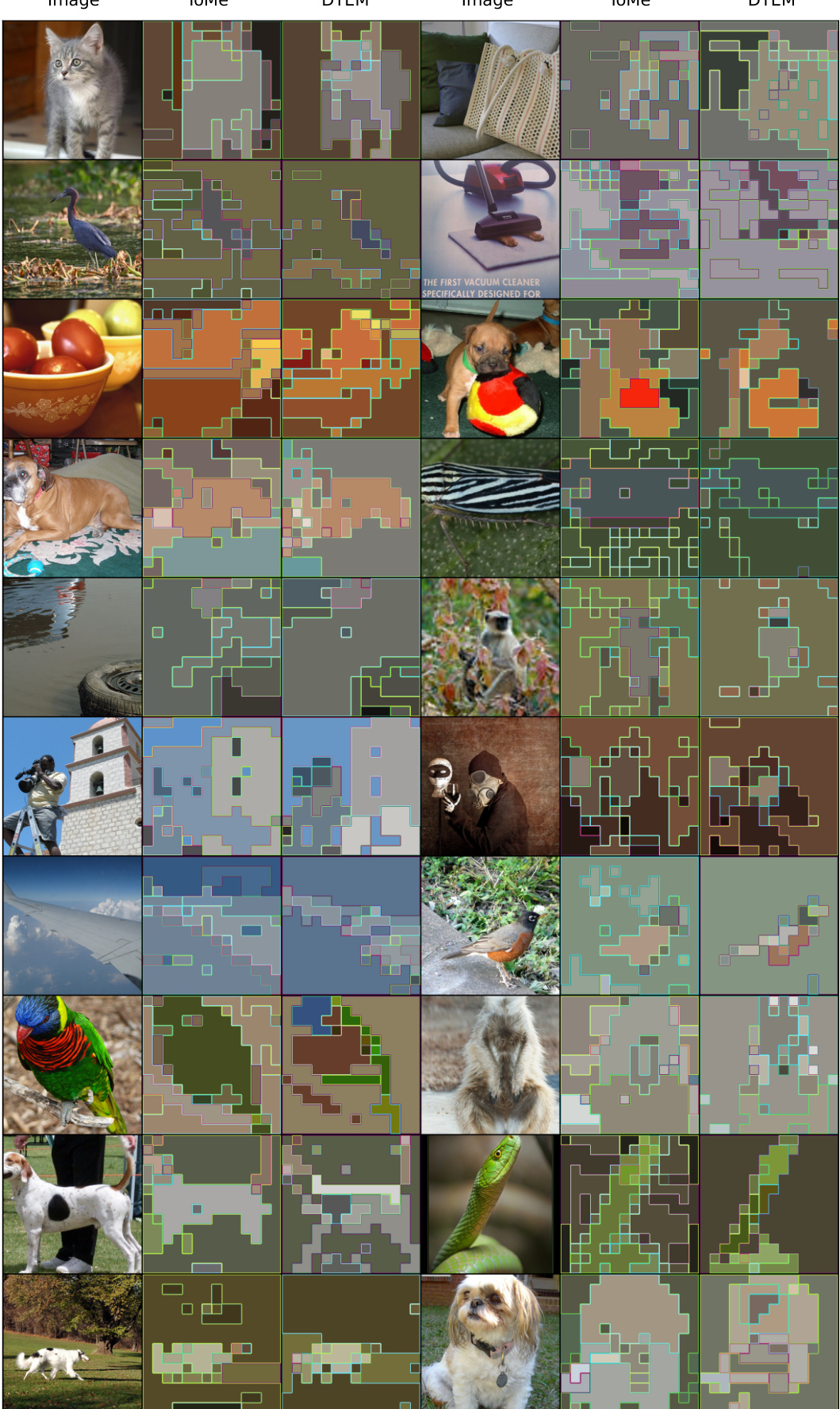
🔼 This figure shows a visualization of merged tokens using two different methods: ToMe and DTEM. It demonstrates the differences in how each method groups tokens together. Each image is divided into patches, and patches of similar color represent groups merged by the algorithms. Using a reduction rate of r=16 results in 11 remaining tokens after merging. The visualization highlights that DTEM focuses on merging background patches more effectively, resulting in a clearer separation of foreground objects compared to ToMe.
read the caption
Figure 6: More visualization of merged tokens. We apply a reduction profile with r = 16, leading to 11 tokens remaining in the final output.
More on tables

🔼 This table presents the classification accuracy (Acc@1), GFLOPs (floating point operations), and images per second (im/s) for different models on the ImageNet-1k dataset. The models used are DeiT-S, DeiT-B, MAE-B, and MAE-L. The results are shown for different token reduction rates (35% and 50%). The table compares the performance of the proposed DTEM method with existing methods like EViT and ToMe, demonstrating the efficiency gains achieved by DTEM with minimal accuracy loss. The reduction rate reflects the decrease in computational cost.
read the caption
Table 1: Classification results with off-the-shelf frozen pre-trained models. Reduction roughly represents the decreases in FLOPs.
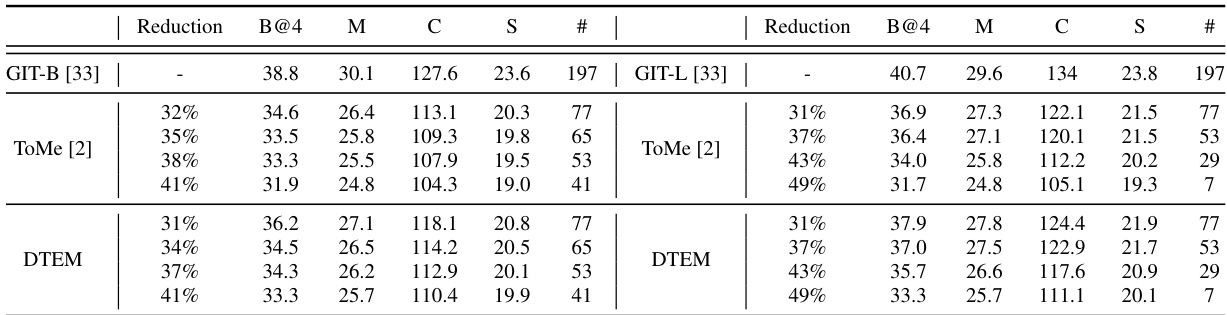
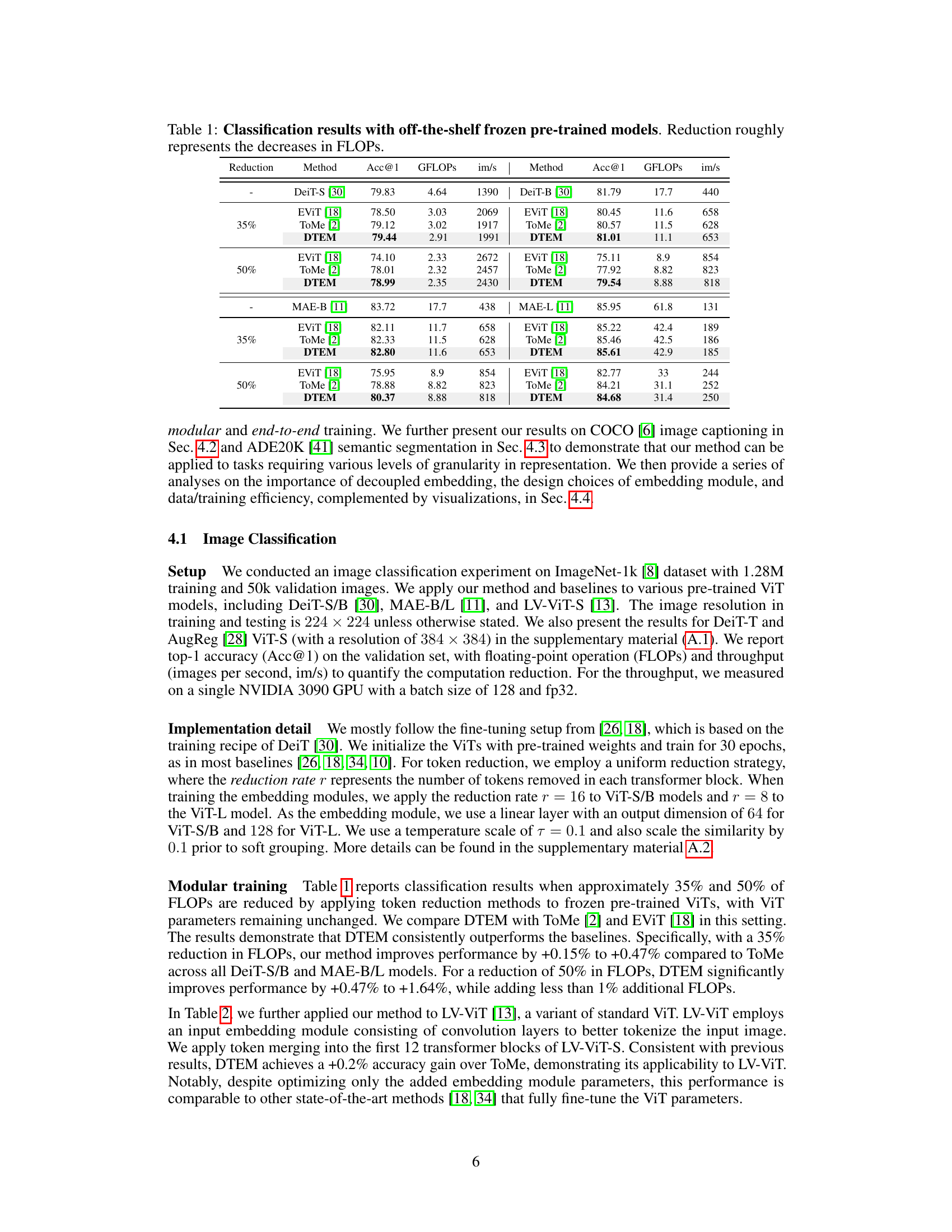
🔼 This table presents the results of image captioning experiments using different token merging methods. It shows the performance metrics (BLEU-4, CIDEr, METEOR, SPICE) achieved by different methods under various reduction rates (representing a decrease in FLOPs). The ‘#’ column indicates the number of tokens passed from the vision transformer to the language decoder. The table compares the performance of ToMe and the proposed DTEM method, highlighting the improvements in efficiency and performance achieved by DTEM.
read the caption
Table 4: Image captioning evaluation results when token merging is applied. We report with caption evaluation metrics: BLEU-4 (B@4), CIDEr (C), METEOR (M) and SPICE (S). Reduction represents the decreases in FLOPs within the ViT encoder, and # indicates the number of tokens passed to language decoder.
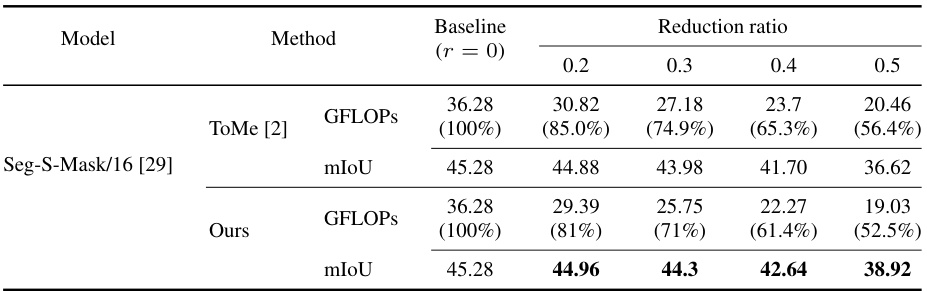
🔼 This table presents the results of semantic segmentation experiments using the Seg-S-Mask/16 model [29] with different token merging methods (ToMe [2] and the proposed DTEM). The baseline (r=0) represents the performance without token merging. The reduction ratio indicates the percentage of tokens merged. The table shows the GFLOPs (floating-point operations) and mIoU (mean Intersection over Union) for each method at different reduction ratios. Lower GFLOPs indicate improved efficiency, while higher mIoU indicates better segmentation accuracy.
read the caption
Table 5: Results on semantic segmentation when token merging is applied. The reduction ratio indicates the portion of merged tokens.

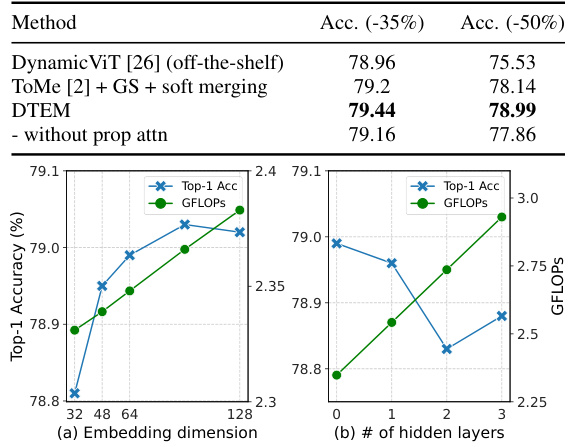
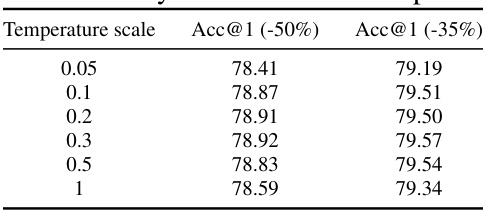
🔼 This table presents the results of an ablation study evaluating the impact of the proposed decoupled embedding module on the performance of token merging. The study is performed on the DeiT-S and DeiT-B models. It shows the impact of adding the soft token merging component and then further adding the decoupled embedding module, comparing the results to the baseline ToMe method. The accuracy is reported for two different reduction rates (-35% and -50%), representing the decrease in FLOPs.
read the caption
Table 6: Ablation study on the impact of decoupled embedding. We successively add soft token merging and decoupled embedding module into ToMe. The number in parentheses indicates the reduction in FLOPs.

🔼 This table presents the Kendall rank correlation coefficients between token similarities derived from self-attention keys and decoupled embeddings, before and after training. The correlation is calculated separately for three sets of transformer blocks (1-4, 5-8, 9-12). The results show a decrease in correlation after training, suggesting that the decoupled embedding learns a different feature representation for token merging, distinct from the self-attention features.
read the caption
Table 7: Kendall rank correlation coefficient changed through training. We report changes in the Kendall rank correlation between token similarities derived from two different features: self-attention keys and decoupled embedding.

🔼 This table presents the classification accuracy (Acc@1), GFLOPs (floating point operations), and images per second (im/s) for different vision transformer (ViT) models using three different token reduction methods: EViT, ToMe, and DTEM. The results are shown for two reduction rates (35% and 50%), indicating the computational savings achieved by each method. The table demonstrates the performance of DTEM compared to existing methods when using pre-trained models without further fine-tuning.
read the caption
Table 1: Classification results with off-the-shelf frozen pre-trained models. Reduction roughly represents the decreases in FLOPs.

🔼 This table shows the classification accuracy (Acc@1), GFLOPs, and images per second (im/s) for different vision transformer models (DeiT-S, DeiT-B, MAE-B, MAE-L) with varying reduction rates (35% and 50%). The results are presented for both the baseline models and models using the proposed DTEM method. The reduction percentage reflects the decrease in FLOPs achieved using token reduction techniques.
read the caption
Table 1: Classification results with off-the-shelf frozen pre-trained models. Reduction roughly represents the decreases in FLOPs.

🔼 This table presents the results of image captioning experiments using different token merging methods. It shows the performance of each method across various reduction rates (percentage decrease in FLOPs) on two different ViT models (GIT-B and GIT-L). The metrics used for evaluation are BLEU-4, CIDEr, METEOR, and SPICE, which are common in evaluating image captioning performance. The ‘#’ column indicates the number of tokens remaining after applying the token merging method, that is passed to the language decoder for caption generation.
read the caption
Table 4: Image captioning evaluation results when token merging is applied. We report with caption evaluation metrics: BLEU-4 (B@4), CIDEr (C), METEOR (M) and SPICE (S). Reduction represents the decreases in FLOPs within the ViT encoder, and # indicates the number of tokens passed to language decoder.

🔼 This table presents the results of image classification experiments conducted using DeiT-T and DeiT-S models with end-to-end training for 100 epochs. The table compares the performance of the proposed DTEM method against the dTPS method for different reduction rates (35% and 50%). The results show accuracy (Acc@1) achieved by each method under these conditions. The purpose is to demonstrate the effectiveness of DTEM, even with extensive training, in maintaining or surpassing the performance of a comparable method.
read the caption
Table 14: Image classification results with 100 epochs of end-to-end training.

🔼 This table presents the results of image classification experiments using DeiT-S and DeiT-T models trained for 100 epochs with end-to-end training. It compares the performance of DTEM and the dTPS method at different reduction rates (r), indicating the top-1 accuracy achieved. The table highlights the improvements in accuracy that DTEM provides compared to dTPS. The GFLOPs column shows the computational cost at different reduction rates.
read the caption
Table 14: Image classification results with 100 epochs of end-to-end training.

🔼 This table presents the results of image classification experiments using the LV-ViT-S model. It compares the performance of different token reduction methods, specifically ToMe and DTEM, when applied to a pre-trained LV-ViT-S model. The table shows the top-1 accuracy (Acc@1), GFLOPS (floating point operations per second), and images per second (im/s) for each method, with and without the use of pretrained models.
read the caption
Table 2: Classification results with LV-ViT-S. * indicates the results with off-the-shelf frozen pretrained model.
🔼 This table presents the classification accuracy (Acc@1), GFLOPs, and images per second (im/s) for different ViT models (DeiT-S, DeiT-B, MAE-B, MAE-L) using three token reduction methods (EViT, ToMe, DTEM) at two different reduction levels (35% and 50%). It demonstrates the performance of DTEM compared to existing methods while maintaining efficiency by reducing FLOPs.
read the caption
Table 1: Classification results with off-the-shelf frozen pre-trained models. Reduction roughly represents the decreases in FLOPs.

🔼 This table presents the results of image captioning experiments using two different token merging methods: ToMe and DTEM. The evaluation metrics used are BLEU-4, CIDEr, METEOR, and SPICE. The table shows the performance of each method at various reduction rates (representing decreased FLOPs in the ViT encoder), indicating the trade-off between computational efficiency and captioning quality. The ‘# tokens’ column shows how many tokens are passed to the language decoder after the token merging process.
read the caption
Table 4: Image captioning evaluation results when token merging is applied. We report with caption evaluation metrics: BLEU-4 (B@4), CIDEr (C), METEOR (M) and SPICE (S). Reduction represents the decreases in FLOPs within the ViT encoder, and # indicates the number of tokens passed to language decoder.
Full paper#