↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
The rise of powerful LLMs brings concerns about misuse, such as generating fake news. Existing LLM-generated text (LGT) detection methods often struggle with the vast number of LLMs and the diversity of generated text styles. This paper focuses on a characteristic of modern LLMs: alignment training, where models are trained to produce human-preferable output. This alignment leads to subtle but detectable differences in LLM-generated text compared to human-written text.
ReMoDetect, the proposed method, uses a reward model to quantify these differences. The reward model is further fine-tuned using two strategies: continual preference fine-tuning to amplify the reward signal for aligned LGTs and incorporating human/LLM mixed text as a median preference corpus to better delineate the decision boundary. Extensive experiments across twelve aligned LLMs and six text domains demonstrate ReMoDetect’s superior performance compared to existing methods, signifying its robustness and efficacy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on LLM safety and security because it introduces a novel method for detecting LLM-generated text, which is a critical issue in mitigating risks of malicious use of LLMs. It addresses the limitation of previous methods by focusing on a common feature of powerful LLMs (alignment training), offering a more robust solution that is less susceptible to overfitting. This novel approach opens avenues for research on enhanced LLM alignment and detection of sophisticated text generation.
Visual Insights#

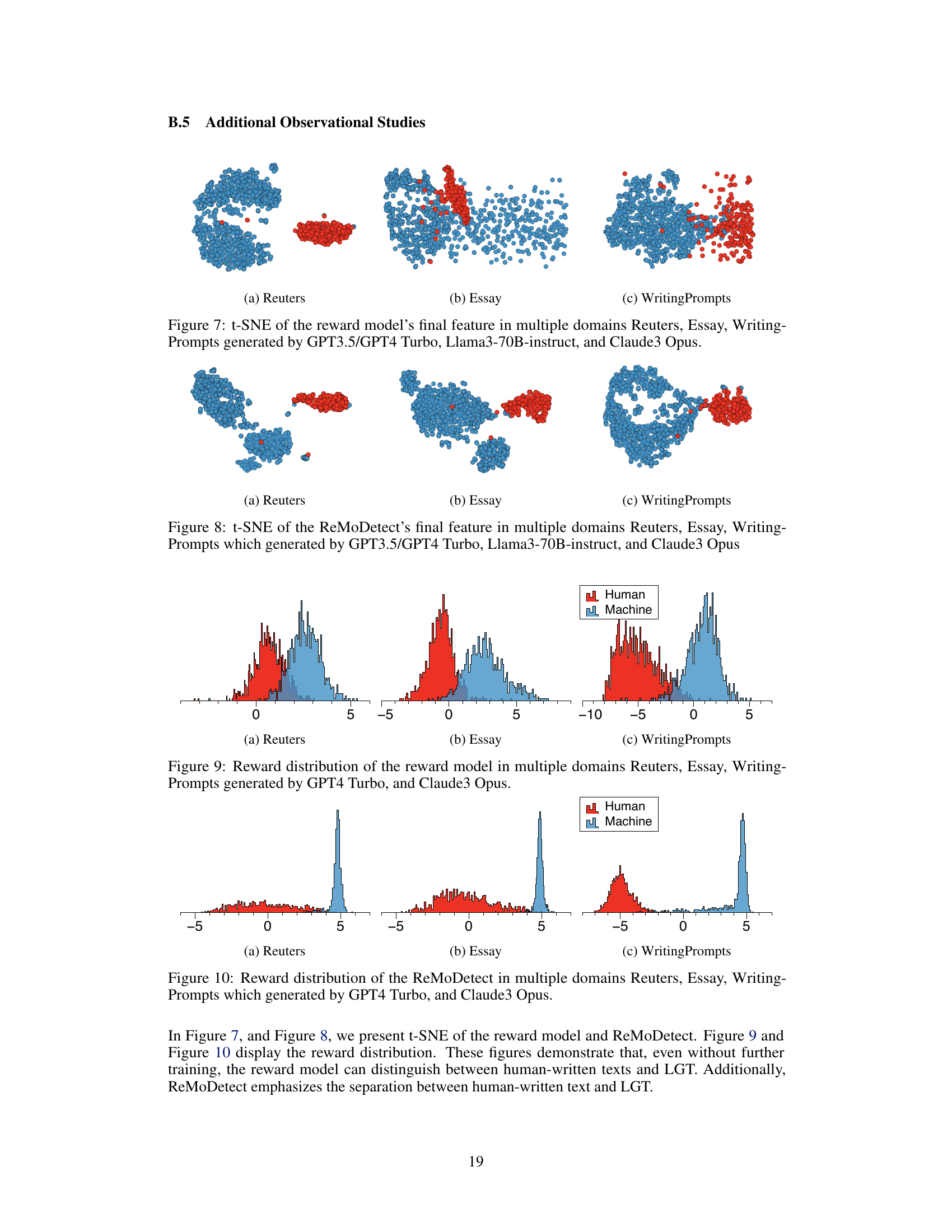
🔼 This figure demonstrates that aligned Large Language Models (LLMs) generate texts with higher reward scores (as predicted by a reward model trained on human preferences) than human-written texts. Panel (a) shows a t-SNE visualization of the reward model’s feature embeddings, clearly separating machine-generated and human-written text. Panel (b) presents histograms of the predicted reward scores, further emphasizing the distinct distributions.
read the caption
Figure 1: Motivation: Aligned LGTs and human-written texts are easily distinguishable by using the reward model. We visualize the (a) t-SNE of the reward model's final feature and the (b) histogram of the predicted reward score. Here, 'Machine' indicates the text generated by GPT3.5/GPT4 Turbo, Llama3-70B, and Claude on the Reuters domain.
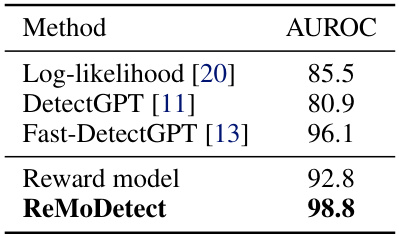
🔼 This table presents the Area Under the Receiver Operating Characteristic curve (AUROC) scores, expressed as percentages, for various LLM-generated text (LGT) detection methods. The methods are evaluated on the WritingPrompts dataset from the Fast-DetectGPT benchmark. GPT-4 was used to generate the LGTs for this evaluation. One method shown is a baseline using a pre-trained reward model to assess the quality of the text. The highest AUROC score is achieved by the ReMoDetect method, highlighting its superior performance compared to existing methods.
read the caption
Table 1: AUROC (%) of LLM-generated text detection methods on WritingPrompts from the Fast-DetectGPT benchmark, where GPT4 is used for text generation. 'Reward model' indicates the detection using the reward score of the pre-trained reward model. The bold denotes the best result.
In-depth insights#
Reward Model Use#
The utilization of reward models in the provided research paper is a crucial element for detecting Large Language Model (LLM) generated text. The core idea revolves around the observation that aligned LLMs, trained to maximize human preference, generate texts with higher estimated preferences than human-written text. This difference in predicted reward scores, as determined by the reward model, forms the basis of the proposed detection method. The paper further enhances this approach by employing continual preference fine-tuning, which further amplifies the reward score difference, and by incorporating Human/LLM mixed texts to refine the reward model’s decision boundary. This multifaceted use of reward models demonstrates the power of leveraging inherent characteristics of aligned LLMs for robust and effective LLM-generated text detection.
Continual Tuning#
Continual tuning, in the context of machine learning models, involves iteratively refining a model’s parameters over time, adapting to new data and scenarios without catastrophic forgetting. This technique is particularly valuable in situations where the data distribution changes over time, requiring the model to continually update its understanding. The core challenge is striking a balance between learning from new data and retaining previously acquired knowledge. Effective strategies for continual tuning often incorporate mechanisms like replay buffers, which store past data to ensure the model doesn’t lose its ability to handle prior patterns. Another key aspect is careful model architecture design, to promote robust and stable adaptation to new inputs. Successfully applying continual tuning may require careful consideration of learning rates and regularization techniques, as overly aggressive updates could lead to instability or degradation of performance. Therefore, developing robust and reliable continual tuning methods is crucial for building adaptable and resilient AI systems.
Mixed Data#
The concept of “Mixed Data” in the context of a research paper likely refers to a methodology where data from different sources or distributions are combined. This approach is valuable for improving model robustness and generalization. One common application is in generating synthetic data points to bridge the gap between existing datasets. In the context of LLM-generated text detection, the creation of “Mixed Data” involves blending human-written text with text generated by large language models (LLMs), creating samples that represent an intermediate state between the two data sources. This technique is particularly helpful for training reward models, as it aids in learning more effective decision boundaries between human- and machine-generated text. By incorporating mixed data, the model can learn to distinguish subtle nuances and resist overfitting to any specific data source. Furthermore, the strategic use of mixed data can address challenges associated with limited data availability in certain domains. However, careful consideration of the mixing ratio and selection method of the data is essential to avoid introducing biases or artifacts that could negatively impact the model’s performance and generalization capability.
Rephrasing Robustness#
Rephrasing robustness in LLM-generated text detection is crucial because it evaluates a system’s ability to identify AI-generated content even after it has been modified. Robustness against rephrasing attacks demonstrates the model’s ability to generalize beyond specific training examples. A model lacking rephrasing robustness might fail to detect paraphrased text, significantly impacting its real-world applicability. The effectiveness of various detection methods, including those based on reward models or other zero-shot approaches, hinges on their capacity to recognize underlying patterns unaffected by surface-level changes. A high degree of rephrasing robustness implies that the detector is capturing deeper semantic features and not just superficial stylistic elements, which is critical for reliable detection in diverse contexts. Therefore, thorough testing against rephrased text is essential in evaluating and improving the efficacy and trustworthiness of LLM-generated text detection frameworks.
Future Work#
The paper’s “Future Work” section would ideally explore several avenues. Extending ReMoDetect’s capabilities to encompass a broader range of LLMs, including those not explicitly trained with alignment techniques, is crucial. This involves investigating how the reward model’s effectiveness changes with diverse alignment strategies and architectural designs. Furthermore, research into the robustness of ReMoDetect against more sophisticated adversarial attacks is vital. This requires examining advanced techniques to rephrase or obfuscate LLM-generated text to evade detection. The investigation should also consider the impact of different reward models and their respective biases on the accuracy and fairness of LLM detection. Finally, a detailed analysis of the computational cost and resource demands of ReMoDetect, with potential optimizations for enhanced efficiency, is necessary. This includes exploring methods to reduce inference times and make the detection framework more accessible.
More visual insights#
More on figures

🔼 This figure illustrates the ReMoDetect framework. It shows how the reward model is continually fine-tuned to distinguish between human-written text and LLM-generated text, using a replay buffer to avoid overfitting and incorporating human/LLM mixed text for improved boundary learning.
read the caption
Figure 2: Overview of Reward Model based LLM Generated Text Detection (ReMoDetect): We continually fine-tune the reward model rφ to prefer aligned LLM-generated responses YLM even further while preventing the overfitting by using the replay technique: (xbuf, ybuf) is the replay buffer and rφ0 is the initial reward model. Moreover, we generate a human/LLM mixed text YMIX by partially rephrasing the human response YHU using the aligned LLM, which serves as a median preference data compared to YLM and YHU, i.e., YLM > YMIX > YHU | x, to improve the reward model's detection ability.
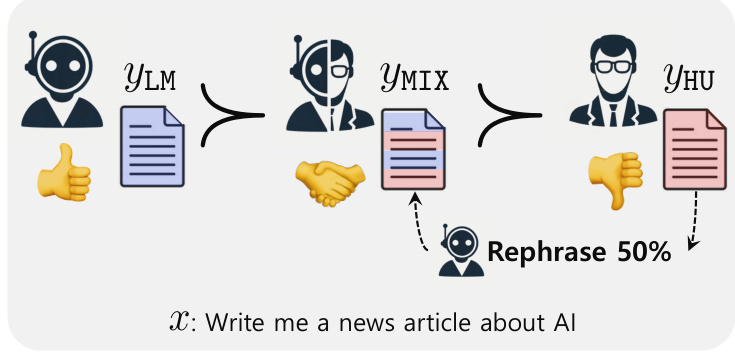
🔼 This figure illustrates the ReMoDetect framework. It shows how the reward model is continually fine-tuned to better distinguish between human-written text and LLM-generated text. A key aspect is the use of a ‘replay buffer’ to prevent overfitting, and the generation of mixed human/LLM texts to help the model learn the decision boundary more effectively. The process starts with an initial reward model and then iteratively refines it using two training components: continual preference tuning with replay and reward modeling with mixed responses.
read the caption
Figure 2: Overview of Reward Model based LLM Generated Text Detection (ReMoDetect): We continually fine-tune the reward model rθ to prefer aligned LLM-generated responses YLM even further while preventing the overfitting by using the replay technique: (xbuf, ybuf) is the replay buffer and rθ0 is the initial reward model. Moreover, we generate a human/LLM mixed text YMIX by partially rephrasing the human response YHU using the aligned LLM, which serves as a median preference data compared to YLM and YHU, i.e., YLM > YMIX > YHU | x, to improve the reward model's detection ability.
🔼 This figure demonstrates that aligned Large Language Model (LLM) generated texts (LGTs) are easily distinguishable from human-written texts using a reward model. Panel (a) shows a t-distributed stochastic neighbor embedding (t-SNE) plot of the reward model’s final feature vector, clearly separating LLM-generated and human-written texts. Panel (b) presents a histogram of the reward scores, highlighting the distinct distributions between the two text types. The results suggest that the reward model effectively captures a difference in text characteristics introduced by alignment training in LLMs.
read the caption
Figure 1: Motivation: Aligned LGTs and human-written texts are easily distinguishable by using the reward model. We visualize the (a) t-SNE of the reward model's final feature and the (b) histogram of the predicted reward score. Here, 'Machine' indicates the text generated by GPT3.5/GPT4 Turbo, Llama3-70B, and Claude on the Reuters domain.

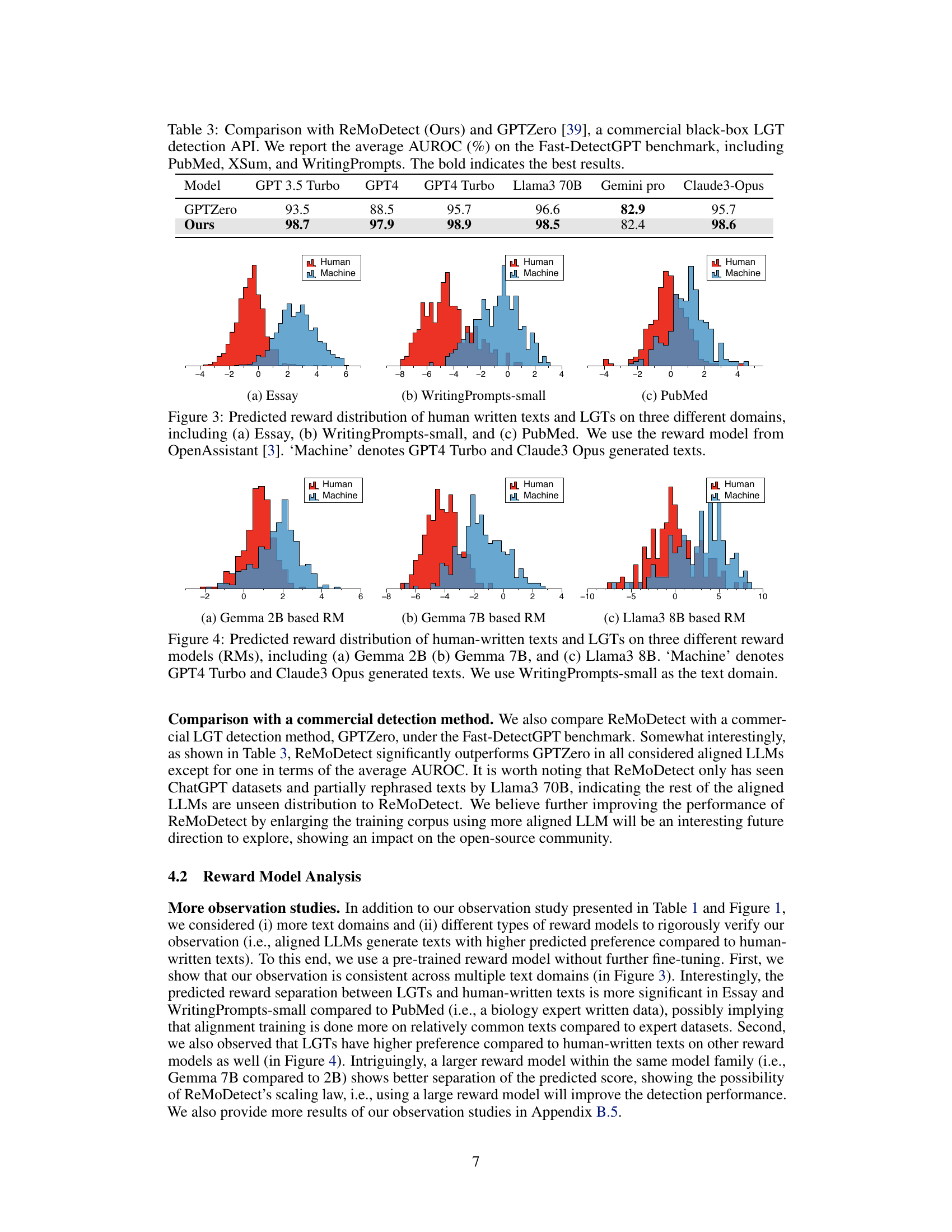
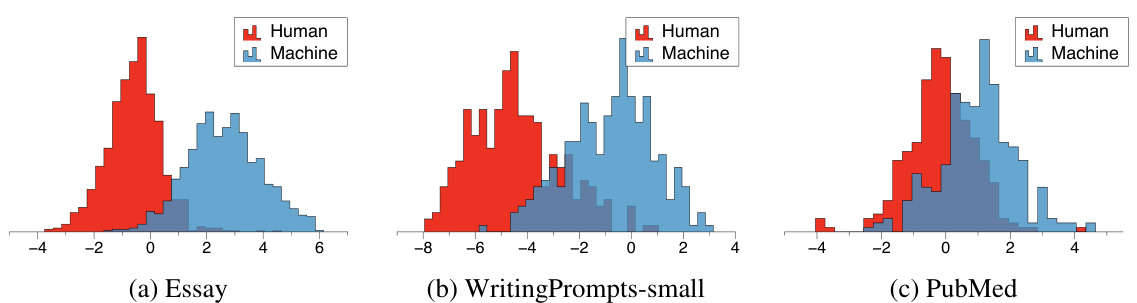
🔼 This figure visualizes the predicted reward scores given by three different reward models (Gemma 2B, Gemma 7B, and Llama3 8B) for both human-written texts and machine-generated texts (GPT4 Turbo and Claude3 Opus) on the WritingPrompts-small dataset. It shows how the reward models distinguish between human and machine-generated text based on the predicted reward score distribution.
read the caption
Figure 4: Predicted reward distribution of human-written texts and LGTs on three different reward models (RMs), including (a) Gemma 2B (b) Gemma 7B, and (c) Llama3 8B. 'Machine' denotes GPT4 Turbo and Claude3 Opus generated texts. We use WritingPrompts-small as the text domain.

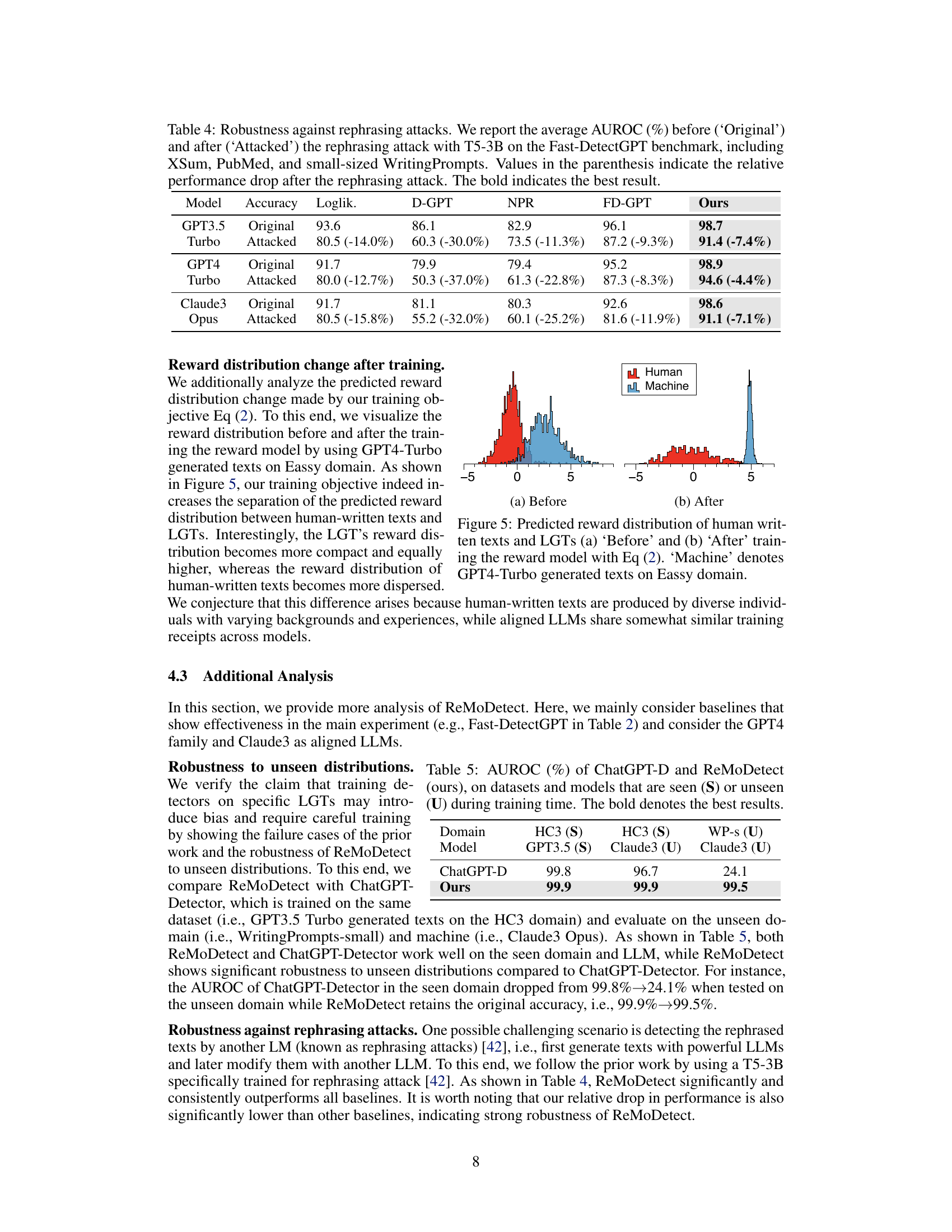
🔼 This figure visualizes the reward distribution predicted by the reward model before and after training with the proposed continual preference tuning method. The ‘before’ plot shows the initial distribution where LLM-generated texts (Machine) have slightly higher reward scores than human-written texts. The ‘after’ plot illustrates how the training shifts the distribution, significantly separating LLM-generated texts with substantially higher reward scores compared to human-written texts. This separation is crucial for accurate LLM-generated text detection.
read the caption
Figure 5: Predicted reward distribution of human-written texts and LGTs (a) 'Before' and (b) 'After' training the reward model with Eq (2). “Machine' denotes GPT4-Turbo generated texts on Eassy domain.

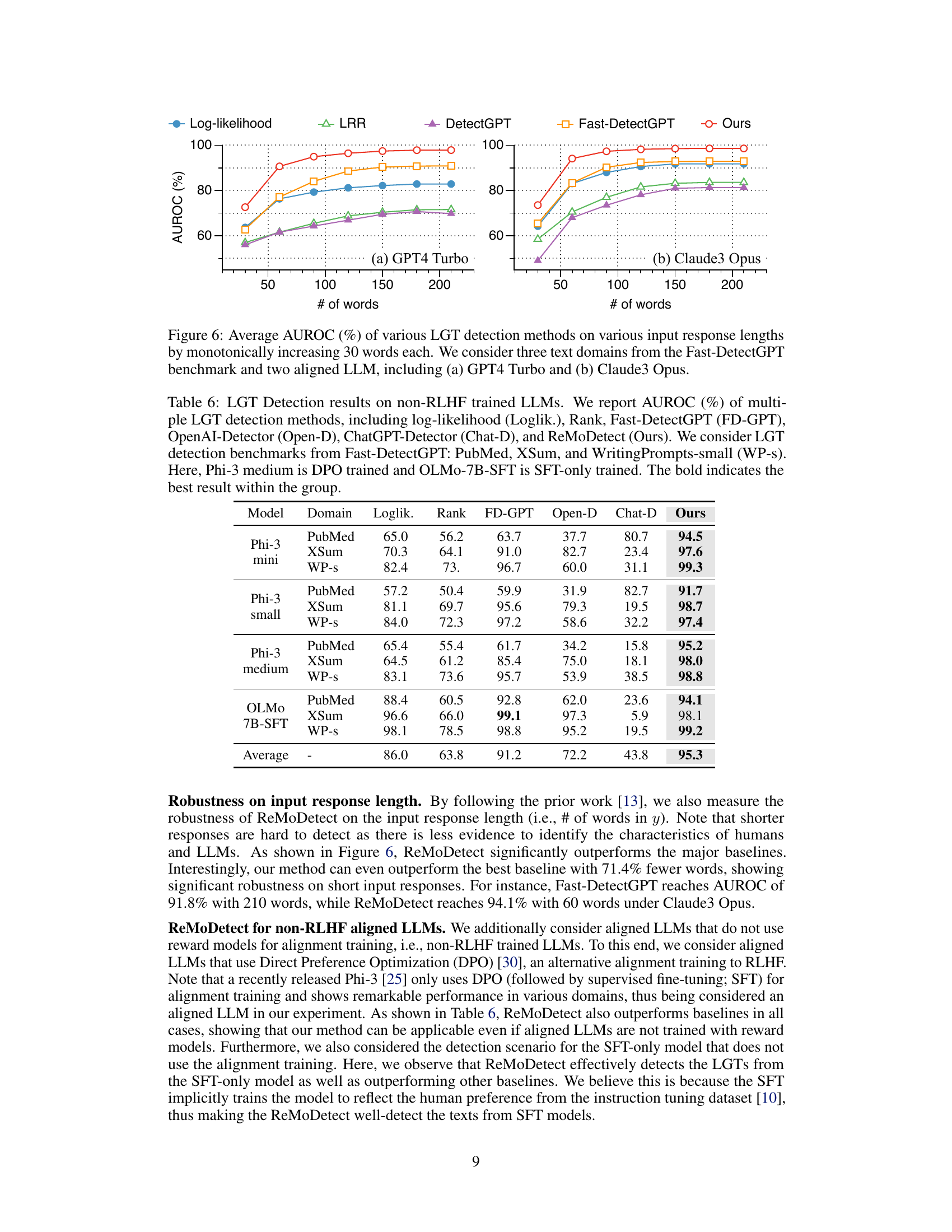
🔼 This figure shows the average AUROC scores for different LLM-generated text (LGT) detection methods across varying lengths of input text. The x-axis represents the number of words in the input text, increasing in increments of 30. The y-axis represents the AUROC score, a measure of the detector’s performance. Two different LLMs are tested: GPT4 Turbo and Claude3 Opus. The figure visually demonstrates the robustness of the proposed method (Ours) compared to other methods like Log-likelihood, LRR, DetectGPT, and Fast-DetectGPT, especially with shorter response lengths.
read the caption
Figure 6: Average AUROC (%) of various LGT detection methods on various input response lengths by monotonically increasing 30 words each. We consider three text domains from the Fast-DetectGPT benchmark and two aligned LLM, including (a) GPT4 Turbo and (b) Claude3 Opus.

🔼 This figure shows that reward models can easily distinguish between texts generated by large language models (LLMs) and human-written texts. Panel (a) uses t-SNE to visualize the separation of aligned LLM-generated texts from human-written texts based on reward model features. Panel (b) shows a histogram illustrating the difference in the reward score distributions between human and machine-generated texts.
read the caption
Figure 1: Motivation: Aligned LGTs and human-written texts are easily distinguishable by using the reward model. We visualize the (a) t-SNE of the reward model's final feature and the (b) histogram of the predicted reward score. Here, 'Machine' indicates the text generated by GPT3.5/GPT4 Turbo, Llama3-70B, and Claude on the Reuters domain.

🔼 This figure demonstrates the effectiveness of reward models in distinguishing between human-written text and text generated by large language models (LLMs). Panel (a) shows a t-distributed stochastic neighbor embedding (t-SNE) plot visualizing the separation of human-written text and LLM-generated text based on their reward scores. Panel (b) presents a histogram comparing the distribution of predicted reward scores for both human-written and LLM-generated text, showcasing a clear distinction between the two distributions. The results support the main finding that aligned LLMs (trained to maximize human preferences) produce text with reward scores even higher than human-written texts, making them easier to detect using the reward model.
read the caption
Figure 1: Motivation: Aligned LGTs and human-written texts are easily distinguishable by using the reward model. We visualize the (a) t-SNE of the reward model’s final feature and the (b) histogram of the predicted reward score. Here, ‘Machine’ indicates the text generated by GPT3.5/GPT4 Turbo, Llama3-70B, and Claude on the Reuters domain.

🔼 This figure shows that reward models can easily distinguish between texts generated by large language models (LLMs) and human-written texts. The t-SNE plot (a) visualizes the separation of LLM-generated and human-written texts in a feature space learned by a reward model, while the histogram (b) shows the distribution of predicted reward scores for each type of text, clearly indicating a difference in their distributions.
read the caption
Figure 1: Motivation: Aligned LGTs and human-written texts are easily distinguishable by using the reward model. We visualize the (a) t-SNE of the reward model's final feature and the (b) histogram of the predicted reward score. Here, 'Machine' indicates the text generated by GPT3.5/GPT4 Turbo, Llama3-70B, and Claude on the Reuters domain.
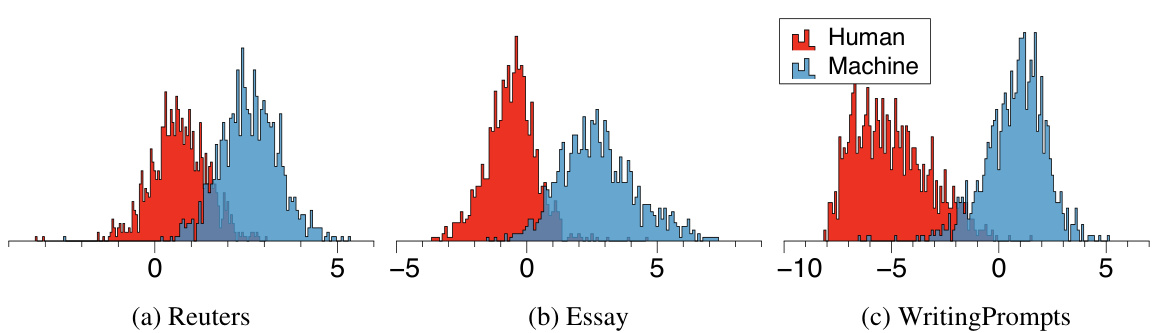
🔼 This figure demonstrates the effectiveness of reward models in distinguishing between aligned LLM-generated texts (LGTs) and human-written texts. Panel (a) shows a t-SNE visualization of the reward model’s feature embeddings, clearly separating machine-generated text from human-written text. Panel (b) displays a histogram of the predicted reward scores, further highlighting the distinct distributions of these two text types. This separation is crucial for the LGT detection method proposed in the paper.
read the caption
Figure 1: Motivation: Aligned LGTs and human-written texts are easily distinguishable by using the reward model. We visualize the (a) t-SNE of the reward model's final feature and the (b) histogram of the predicted reward score. Here, 'Machine' indicates the text generated by GPT3.5/GPT4 Turbo, Llama3-70B, and Claude on the Reuters domain.
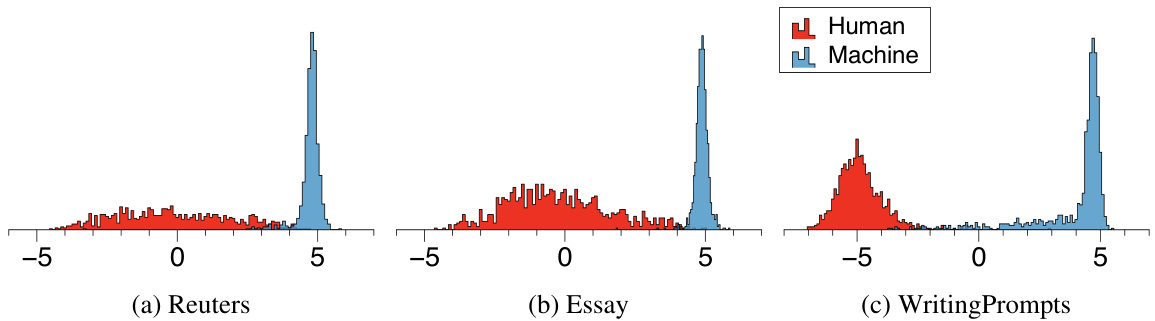
🔼 The figure demonstrates that aligned Large Language Model (LLM) generated texts (LGTs) and human-written texts have different reward scores, as predicted by a reward model trained to assess human preferences. The t-SNE plot (a) visually separates LLM generated texts from human-written ones in a 2-dimensional space, while the histogram (b) shows the reward scores for both LLM-generated and human-written texts, exhibiting a clear separation in the distribution. This motivates the use of the reward model for detecting LLM-generated texts.
read the caption
Figure 1: Motivation: Aligned LGTs and human-written texts are easily distinguishable by using the reward model. We visualize the (a) t-SNE of the reward model's final feature and the (b) histogram of the predicted reward score. Here, 'Machine' indicates the text generated by GPT3.5/GPT4 Turbo, Llama3-70B, and Claude on the Reuters domain.
More on tables
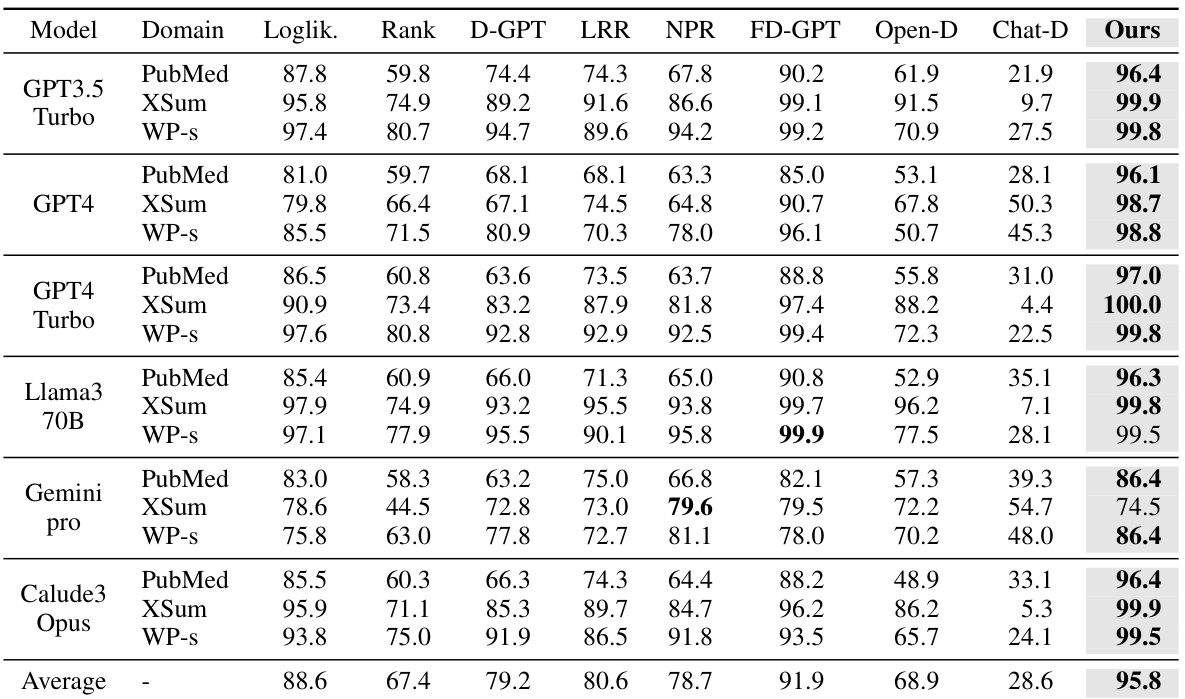
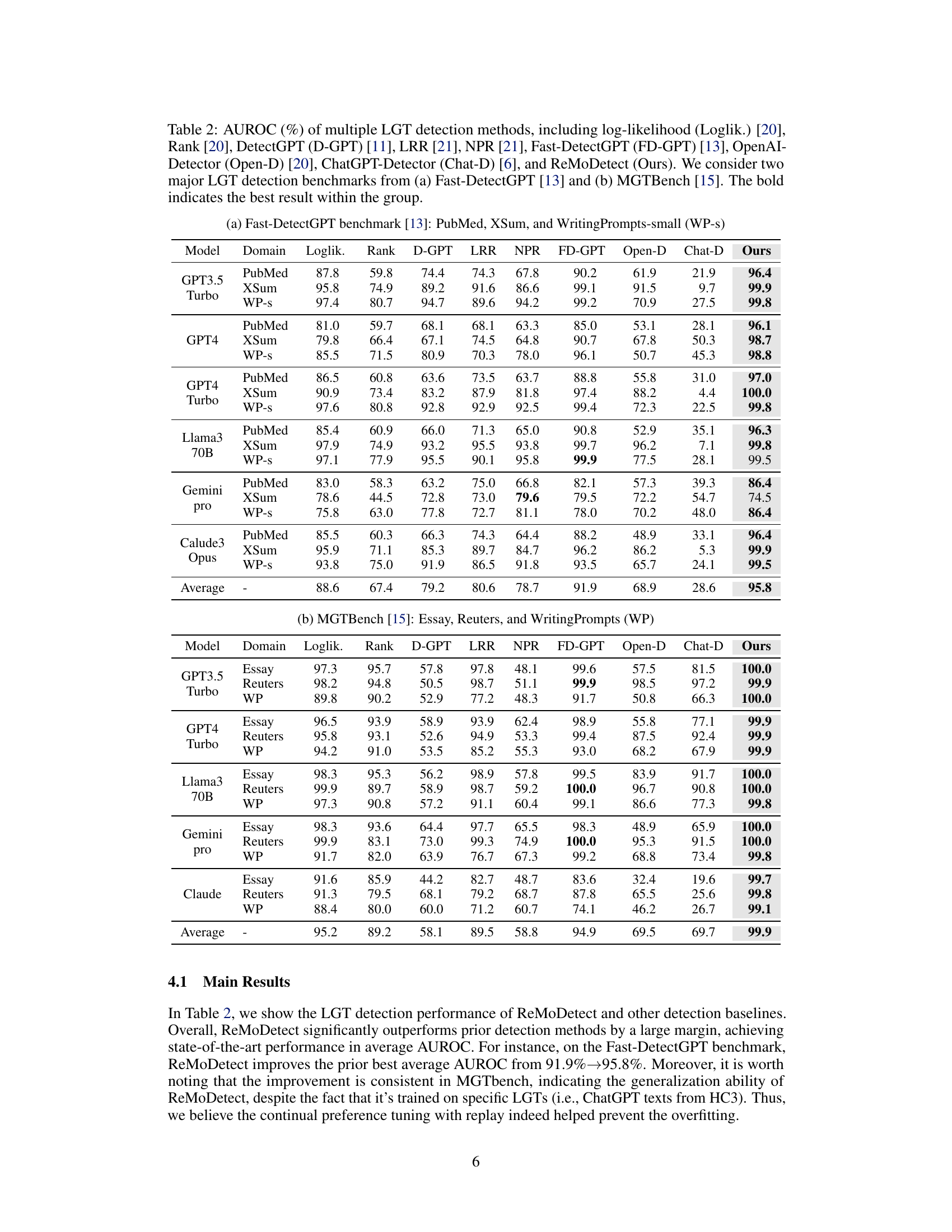
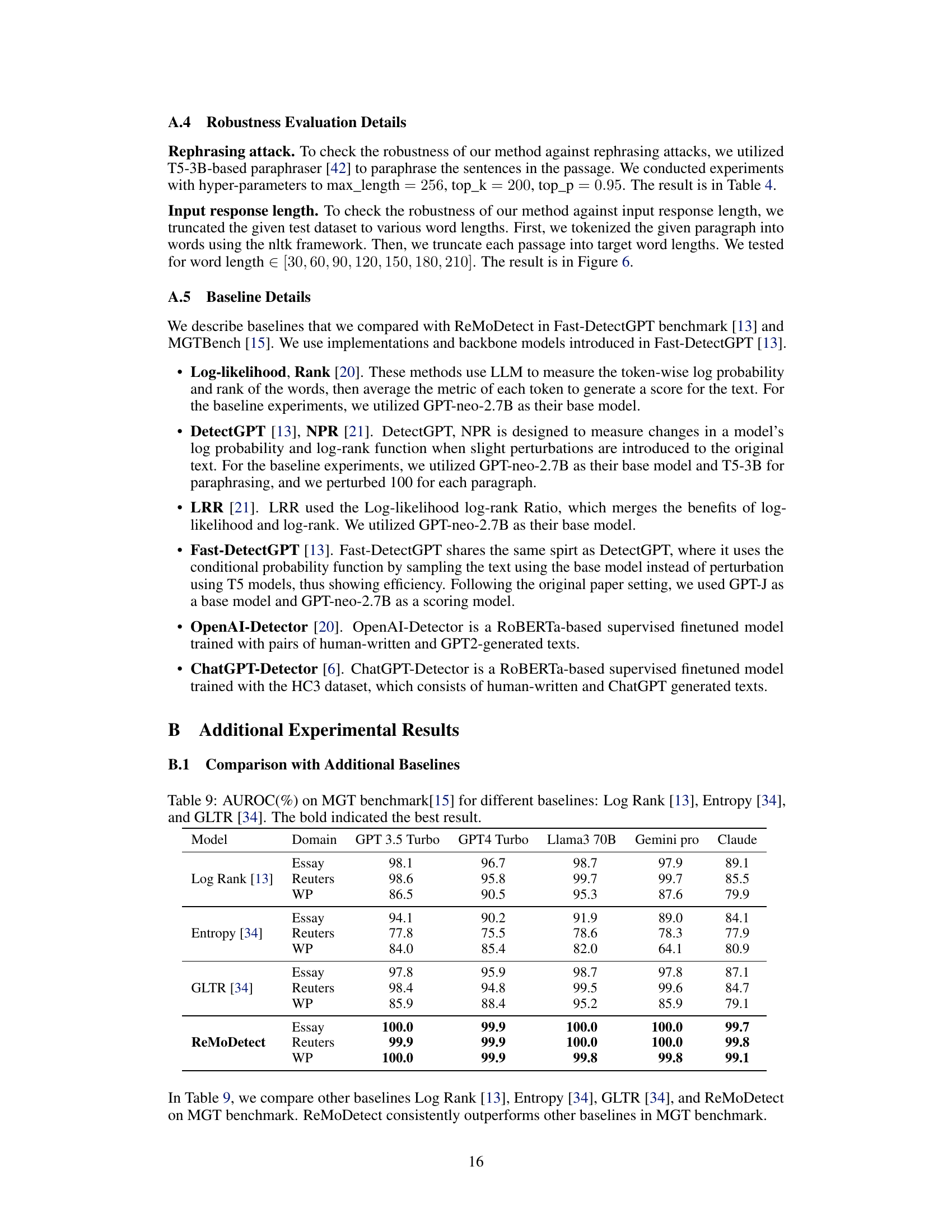
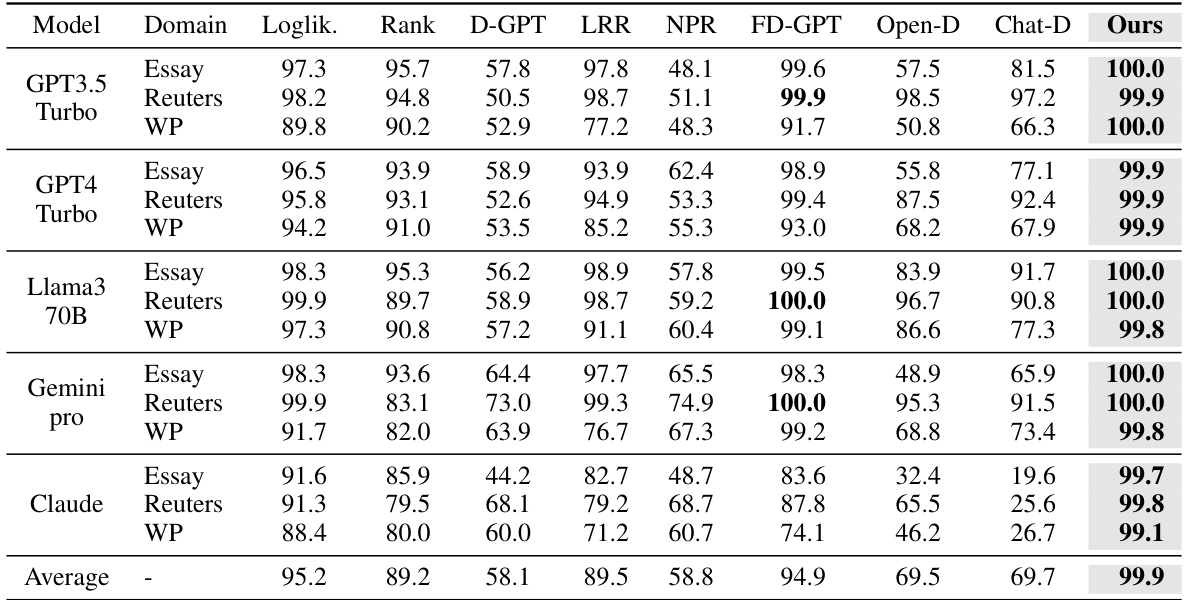
🔼 This table presents the Area Under the Receiver Operating Characteristic Curve (AUROC) scores for several LLM-generated text (LGT) detection methods. It compares the performance of these methods across two benchmark datasets: Fast-DetectGPT and MGTBench. The results are broken down by LLM model used to generate the text (GPT3.5 Turbo, GPT4, etc.) and by the specific text domain (PubMed, XSum, etc.). The bold values represent the best AUROC score for each combination.
read the caption
Table 2: AUROC (%) of multiple LGT detection methods, including log-likelihood (Loglik.) [20], Rank [20], DetectGPT (D-GPT) [11], LRR [21], NPR [21], Fast-DetectGPT (FD-GPT) [13], OpenAI-Detector (Open-D) [20], ChatGPT-Detector (Chat-D) [6], and ReMoDetect (Ours). We consider two major LGT detection benchmarks from (a) Fast-DetectGPT [13] and (b) MGTBench [15]. The bold indicates the best result within the group.
🔼 This table presents the AUROC scores achieved by various LLM-generated text detection methods on two benchmark datasets: Fast-DetectGPT and MGTBench. It compares the performance of several existing methods against the proposed ReMoDetect method across multiple text domains and LLMs. The results highlight ReMoDetect’s superior performance compared to existing techniques.
read the caption
Table 2: AUROC (%) of multiple LGT detection methods, including log-likelihood (Loglik.) [20], Rank [20], DetectGPT (D-GPT) [11], LRR [21], NPR [21], Fast-DetectGPT (FD-GPT) [13], OpenAI-Detector (Open-D) [20], ChatGPT-Detector (Chat-D) [6], and ReMoDetect (Ours). We consider two major LGT detection benchmarks from (a) Fast-DetectGPT [13] and (b) MGTBench [15]. The bold indicates the best result within the group.

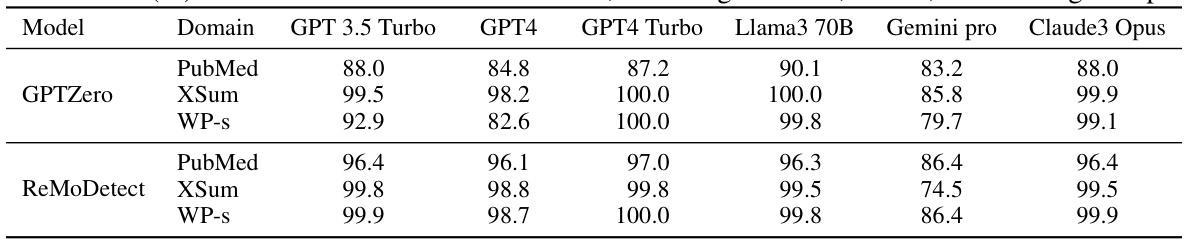
🔼 This table compares the performance of ReMoDetect with GPTZero, a commercial LLM detection API, across three datasets from the Fast-DetectGPT benchmark (PubMed, XSum, and WritingPrompts). The average AUROC (Area Under the Receiver Operating Characteristic curve) is presented for each model and dataset. ReMoDetect demonstrates superior performance.
read the caption
Table 3: Comparison with ReMoDetect (Ours) and GPTZero [39], a commercial black-box LGT detection API. We report the average AUROC (%) on the Fast-DetectGPT benchmark, including PubMed, XSum, and WritingPrompts. The bold indicates the best results.
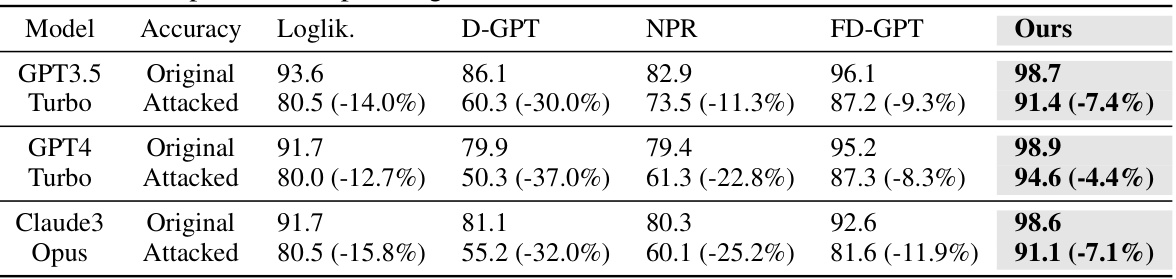
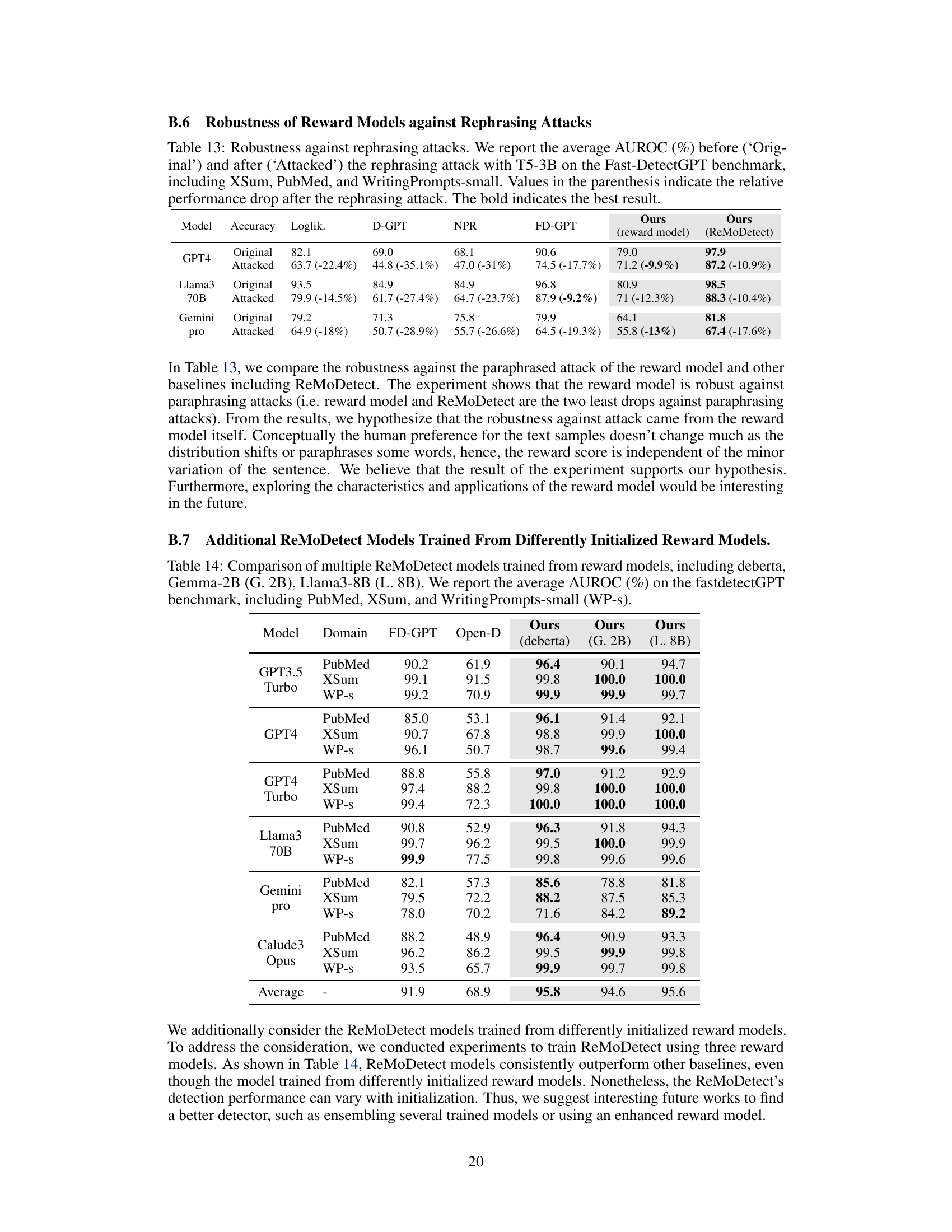
🔼 This table presents the results of an experiment evaluating the robustness of several LLM-generated text detection methods against rephrasing attacks. The experiment used the Fast-DetectGPT benchmark, and focused on three text domains (XSum, PubMed, and WritingPrompts-small). The methods’ AUROC scores are reported for both original texts and texts that have undergone a rephrasing attack using the T5-3B model. The relative decrease in performance after the attack is shown in parentheses, illustrating the impact of rephrasing on each method’s detection accuracy.
read the caption
Table 4: Robustness against rephrasing attacks. We report the average AUROC (%) before ('Original') and after ('Attacked') the rephrasing attack with T5-3B on the Fast-DetectGPT benchmark, including XSum, PubMed, and small-sized WritingPrompts. Values in the parenthesis indicate the relative performance drop after the rephrasing attack. The bold indicates the best result.

🔼 This table presents the results of a robustness test performed on the ChatGPT-Detector and ReMoDetect models. The goal was to evaluate how well the models generalize to unseen data and models by comparing the Area Under the Receiver Operating Characteristic curve (AUROC) across several scenarios where either the data, the model, or both are unseen during the training phase. The results indicate that ReMoDetect demonstrates superior robustness compared to ChatGPT-Detector, especially in unseen scenarios.
read the caption
Table 5: AUROC (%) of ChatGPT-D and ReMoDetect (ours), on datasets and models that are seen (S) or unseen (U) during training time. The bold denotes the best results.
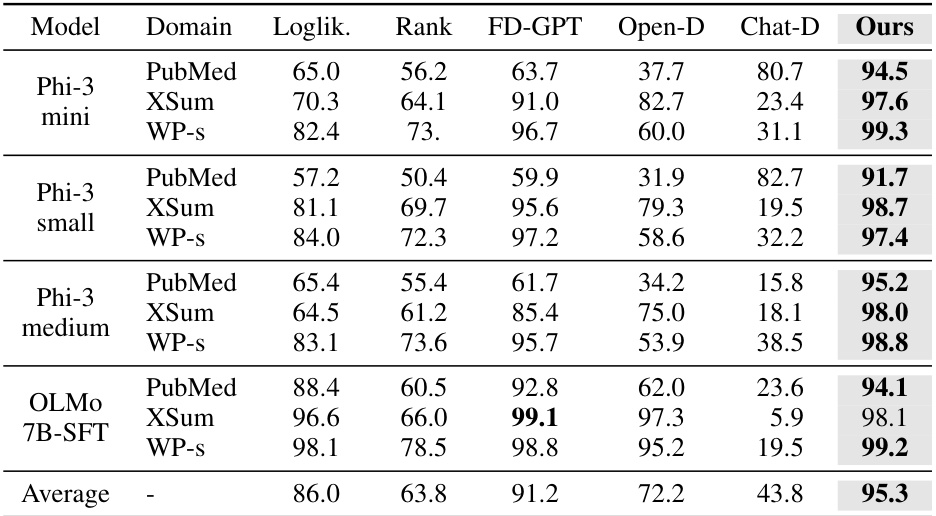
🔼 This table presents the Area Under the ROC Curve (AUROC) scores for several Large Language Model (LLM) generated text detection methods on three different datasets (PubMed, XSum, and WritingPrompts-small). It compares the performance of these methods on LLMs that were not trained using reinforcement learning from human feedback (RLHF), specifically using either direct preference optimization (DPO) or supervised fine-tuning (SFT). The table highlights ReMoDetect’s performance against various baselines, showcasing its effectiveness even on LLMs trained with methods other than RLHF.
read the caption
Table 6: LGT Detection results on non-RLHF trained LLMs. We report AUROC (%) of multiple LGT detection methods, including log-likelihood (Loglik.), Rank, Fast-DetectGPT (FD-GPT), OpenAI-Detector (Open-D), ChatGPT-Detector (Chat-D), and ReMoDetect (Ours). We consider LGT detection benchmarks from Fast-DetectGPT: PubMed, XSum, and WritingPrompts-small (WP-s). Here, Phi-3 medium is DPO trained and OLMo-7B-SFT is SFT-only trained. The bold indicates the best result within the group.
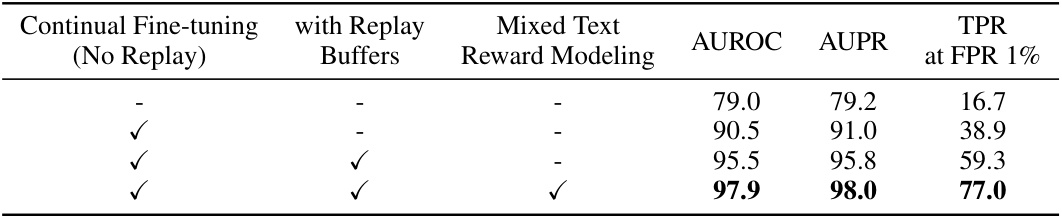
🔼 This table shows the ablation study of the proposed ReMoDetect model by gradually adding the components (Continual Preference Tuning, Replay Buffers, and Reward Modeling with Mixed Responses). It demonstrates the incremental improvements in AUROC, AUPR, and TPR@FPR1% metrics when each component is added, highlighting their individual contributions to the overall performance. The results are based on GPT-4 generated text across several domains.
read the caption
Table 7: Contribution of each proposed component of ReMoDetect on detecting aligned LGTs from human-written texts. We report the average detection performance of GPT4 under text domains in the Fast-DetectGPT benchmark. All values are percentages, and the best results are indicated in bold.
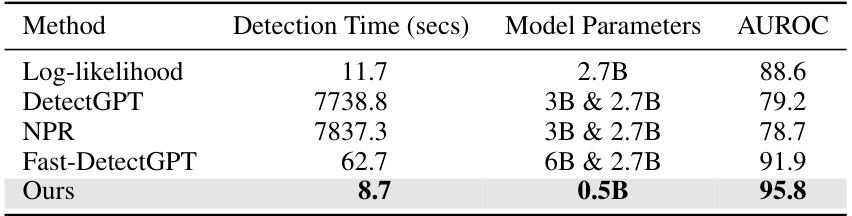
🔼 This table compares the detection time, model parameters, and AUROC of several LLM-generated text detection methods on the Fast-DetectGPT benchmark. The detection time is measured using an A6000 GPU and is based on 300 samples from the XSum dataset. The table highlights the efficiency and performance of the proposed ReMoDetect method compared to existing techniques.
read the caption
Table 8: Comparison of detection time, model parameters, and average AUROC (%) of Fast-DetectGPT benchmark for various LGT detection methods. Detection time was measured in an A6000 GPU, and the overall detection time was measured for 300 XSum dataset samples.
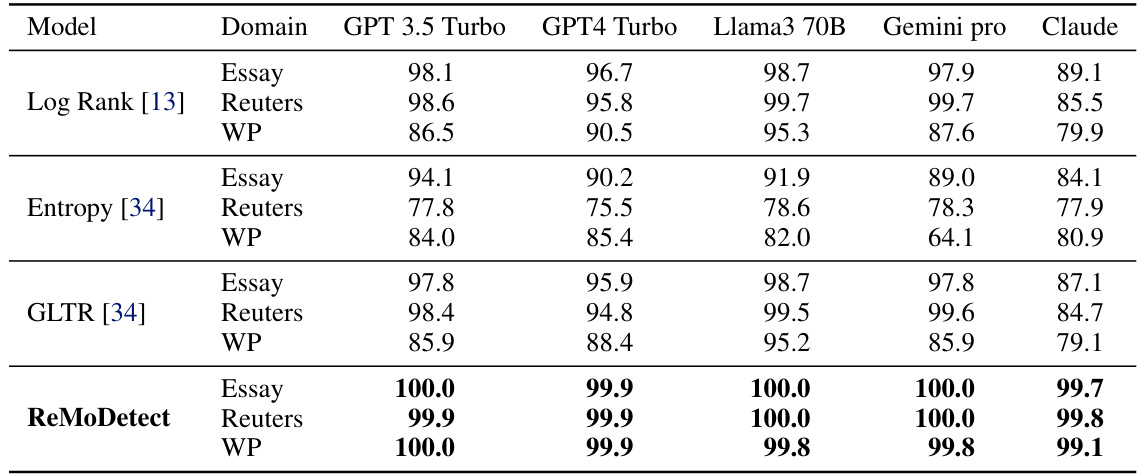
🔼 This table presents the Area Under the Receiver Operating Characteristic Curve (AUROC) scores achieved by several LLM-generated text (LGT) detection methods. It compares the performance of ReMoDetect against several baselines across two benchmark datasets: Fast-DetectGPT and MGTBench. The results are broken down by LLM model (GPT3.5 Turbo, GPT4, GPT4 Turbo, Llama 3 70B, Gemini Pro, Claude 3 Opus) and text domain (PubMed, XSum, WritingPrompts-small, Essay, Reuters, WritingPrompts). The bold values highlight the best-performing method in each row.
read the caption
Table 2: AUROC (%) of multiple LGT detection methods, including log-likelihood (Loglik.) [20], Rank [20], DetectGPT (D-GPT) [11], LRR [21], NPR [21], Fast-DetectGPT (FD-GPT) [13], OpenAI-Detector (Open-D) [20], ChatGPT-Detector (Chat-D) [6], and ReMoDetect (Ours). We consider two major LGT detection benchmarks from (a) Fast-DetectGPT [13] and (b) MGTBench [15]. The bold indicates the best result within the group.

🔼 This table presents the Area Under the Receiver Operating Characteristic Curve (AUROC) scores for different Large Language Models (LLMs) on the Fast-DetectGPT benchmark. The models evaluated include Claude3 Haiku, Claude3 Sonnet, and several baselines. The AUROC is a measure of the LLM’s ability to distinguish between human-written text and machine-generated text. Higher AUROC scores indicate better performance. The table is broken down by domain (PubMed, XSum, WritingPrompts-small) and shows the AUROC for each model within each domain. The best-performing model in each domain is highlighted in bold.
read the caption
Table 10: AUROC (%) on Fast-DetectGPT benchmark [13] for different models: Claude3 Haiku [5] and Sonnet [5]. The bold indicates the best result.

🔼 This table presents the True Positive Rate (TPR) at a 1% False Positive Rate (FPR) and the Area Under the Precision-Recall Curve (AUPR) for several LLM-generated text detection methods. It compares the performance of ReMoDetect against baselines across different LLMs and text domains from the Fast-DetectGPT benchmark.
read the caption
Table 11: TPR(%) at FPR 1% and AUPR (%) of multiple LLM-generated text detection methods, including log-likelihood (Loglik.) [20], Rank [20], DetectGPT (D-GPT) [11], LRR [21], NPR [21], Fast-DetectGPT (FD-GPT) [13], OpenAI-Detector (Open-D) [20], ChatGPT-Detector (Chat-D) [6], and ReMoDetect (Ours). We consider LLM-generated text detection benchmarks from Fast-DetectGPT [13]. The bold indicates the best result within the group.

🔼 This table presents the Area Under the Receiver Operating Characteristic curve (AUROC) scores achieved by several LLM-generated text (LGT) detection methods on two benchmark datasets: Fast-DetectGPT and MGTBench. The methods compared include various zero-shot and supervised techniques. The results are broken down by LLM used for text generation (GPT3.5 Turbo, GPT4, etc.) and by the specific dataset and its sub-domains (PubMed, XSum, WritingPrompts). The table highlights the superior performance of ReMoDetect across diverse models and datasets.
read the caption
Table 2: AUROC (%) of multiple LGT detection methods, including log-likelihood (Loglik.) [20], Rank [20], DetectGPT (D-GPT) [11], LRR [21], NPR [21], Fast-DetectGPT (FD-GPT) [13], OpenAI Detector (Open-D) [20], ChatGPT-Detector (Chat-D) [6], and ReMoDetect (Ours). We consider two major LGT detection benchmarks from (a) Fast-DetectGPT [13] and (b) MGTBench [15]. The bold indicates the best result within the group.

🔼 This table presents the Area Under the ROC Curve (AUROC) scores achieved by various LLM-generated text (LGT) detection methods on two benchmark datasets: Fast-DetectGPT and MGTBench. The methods compared include several zero-shot and supervised approaches, along with the proposed ReMoDetect method. The AUROC scores are presented for different LLMs and across multiple text domains within each benchmark, allowing for a comprehensive comparison of performance.
read the caption
Table 2: AUROC (%) of multiple LGT detection methods, including log-likelihood (Loglik.) [20], Rank [20], DetectGPT (D-GPT) [11], LRR [21], NPR [21], Fast-DetectGPT (FD-GPT) [13], OpenAI-Detector (Open-D) [20], ChatGPT-Detector (Chat-D) [6], and ReMoDetect (Ours). We consider two major LGT detection benchmarks from (a) Fast-DetectGPT [13] and (b) MGTBench [15]. The bold indicates the best result within the group.
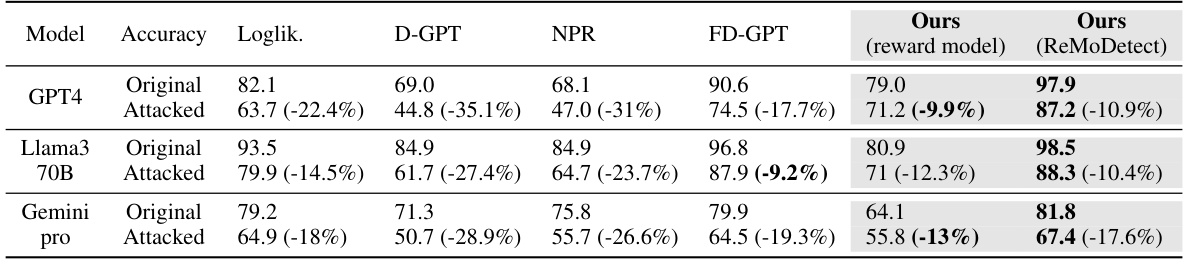
🔼 This table demonstrates the robustness of different LLM-generated text detection methods against rephrasing attacks. It shows the AUROC scores (Area Under the Receiver Operating Characteristic Curve) before and after a rephrasing attack using the T5-3B model. The results are broken down by model (GPT3.5 Turbo, GPT4, and Claude3 Opus) and dataset (XSum, PubMed, and WritingPrompts-small). The values in parentheses show the percentage drop in AUROC after the attack, highlighting the resilience of each method.
read the caption
Table 4: Robustness against rephrasing attacks. We report the average AUROC (%) before ('Original') and after ('Attacked') the rephrasing attack with T5-3B on the Fast-DetectGPT benchmark, including XSum, PubMed, and small-sized WritingPrompts. Values in the parenthesis indicate the relative performance drop after the rephrasing attack. The bold indicates the best result.

🔼 This table presents the Area Under the Receiver Operating Characteristic curve (AUROC) for several LLM-generated text (LGT) detection methods. It compares the performance of these methods across different LLMs (GPT3.5 Turbo, GPT4, GPT4 Turbo, Llama 3 70B, Gemini pro, Claude3 Opus) and datasets (PubMed, XSum, WritingPrompts, Essay, Reuters, and WritingPrompts-small) from two benchmark datasets: Fast-DetectGPT and MGTBench. The best performing method in each category is highlighted in bold.
read the caption
Table 2: AUROC (%) of multiple LGT detection methods, including log-likelihood (Loglik.) [20], Rank [20], DetectGPT (D-GPT) [11], LRR [21], NPR [21], Fast-DetectGPT (FD-GPT) [13], OpenAI-Detector (Open-D) [20], ChatGPT-Detector (Chat-D) [6], and ReMoDetect (Ours). We consider two major LGT detection benchmarks from (a) Fast-DetectGPT [13] and (b) MGTBench [15]. The bold indicates the best result within the group.
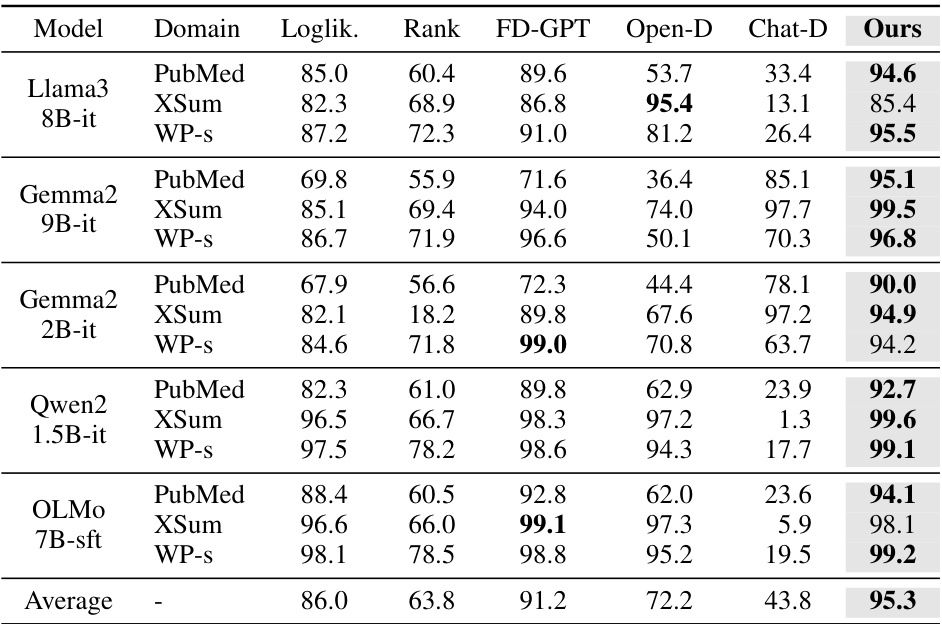
🔼 This table compares the performance of ReMoDetect against other LLM-generated text detection methods on two benchmark datasets: Fast-DetectGPT and MGTBench. The results are presented as AUROC (Area Under the Receiver Operating Characteristic curve) scores, a metric that measures the ability of a classifier to distinguish between human-written and LLM-generated text. The table shows the performance across multiple domains (PubMed, XSum, WritingPrompts) and different LLMs (GPT3.5 Turbo, GPT4, etc.).
read the caption
Table 2: AUROC (%) of multiple LGT detection methods, including log-likelihood (Loglik.) [20], Rank [20], DetectGPT (D-GPT) [11], LRR [21], NPR [21], Fast-DetectGPT (FD-GPT) [13], OpenAI-Detector (Open-D) [20], ChatGPT-Detector (Chat-D) [6], and ReMoDetect (Ours). We consider two major LGT detection benchmarks from (a) Fast-DetectGPT [13] and (b) MGTBench [15]. The bold indicates the best result within the group.
🔼 This table presents the Area Under the Receiver Operating Characteristic curve (AUROC) scores achieved by several LLM-generated text (LGT) detection methods on two benchmark datasets: Fast-DetectGPT and MGTBench. The methods compared include various zero-shot and supervised approaches, along with the authors’ proposed ReMoDetect method. The results are broken down by LLM used for text generation and by the text domain (e.g., PubMed, XSum, WritingPrompts). The table highlights the superior performance of ReMoDetect across different LLMs and domains.
read the caption
Table 2: AUROC (%) of multiple LGT detection methods, including log-likelihood (Loglik.) [20], Rank [20], DetectGPT (D-GPT) [11], LRR [21], NPR [21], Fast-DetectGPT (FD-GPT) [13], OpenAI-Detector (Open-D) [20], ChatGPT-Detector (Chat-D) [6], and ReMoDetect (Ours). We consider two major LGT detection benchmarks from (a) Fast-DetectGPT [13] and (b) MGTBench [15]. The bold indicates the best result within the group.
Full paper#