↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current document understanding methods heavily rely on OCR, which struggles with complex layouts and varying font sizes. Multimodal Large Language Models (MLLMs) offer a promising alternative but face challenges processing multi-scale visual inputs efficiently. Existing OCR-free methods are computationally expensive or fail to fully capture detailed visual information.
This work introduces a novel framework that leverages pretrained MLLMs for OCR-free document understanding. It uses a Hierarchical Visual Feature Aggregation (HVFA) module to efficiently manage multi-scale visual inputs, balancing information preservation and efficiency. A new instruction tuning task focusing on predicting relative text positions significantly enhances the model’s text reading capabilities. Extensive experiments demonstrate the superiority of this approach across multiple document understanding benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in document understanding and multimodal learning because it presents a novel OCR-free framework, showing improvements over existing methods. Its efficient multi-scale visual feature aggregation and novel instruction tuning technique directly address limitations of existing approaches. The framework’s superior performance opens exciting avenues for future research in complex document processing.
Visual Insights#

This figure illustrates the framework of the proposed OCR-free document understanding model. It shows how multi-scale visual features (global view, local scales 1 and 2) are extracted from a document image and aggregated using the Hierarchical Visual Feature Aggregation (HVFA) module. These aggregated features are then fed into a Large Language Model (LLM) to generate a text response. The red box highlights how the model focuses on specific regions of the image containing relevant text to answer an input question, emphasizing the importance of high-resolution details for accurate text recognition.

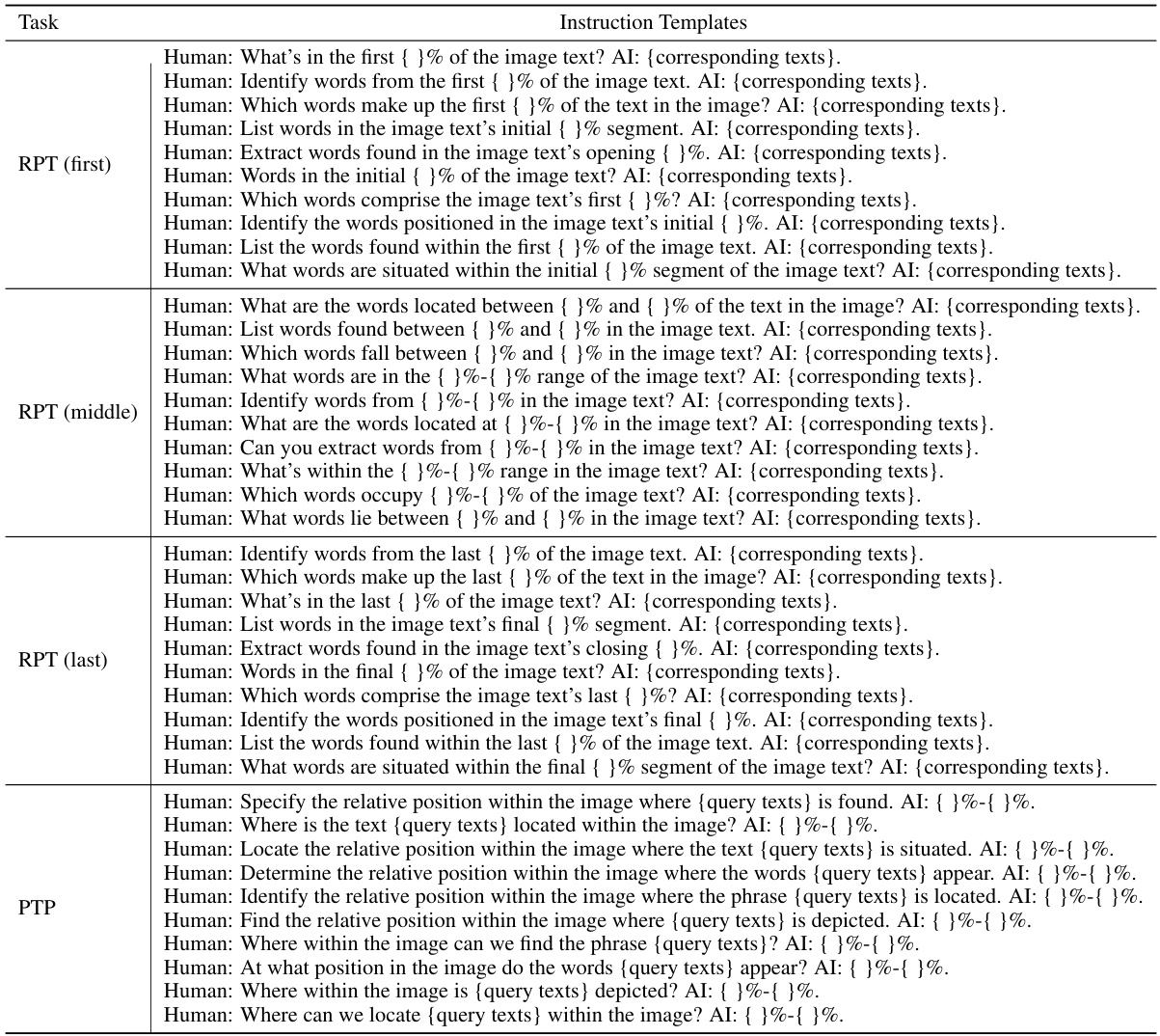
This table shows example instruction templates used for the Relative Text-Position Prediction (RTPP) task. The RTPP task is designed to help the model learn to read text using layout information by having it predict the positions of given text segments within an image. The table showcases examples for three variations of a reading partial text task (RPT), where the model is prompted to read specific portions of the text (first, middle, or last sections) and a predicting text position task (PTP), where the model is asked to specify the location (percentage range) of a given query text within the image. Appendix I contains the complete list of instruction templates.
In-depth insights#
Multi-scale Vision#
Multi-scale vision in document understanding addresses the challenge of variable text sizes and visual elements within documents. Effective handling of multiple scales is crucial because standard methods often struggle with inconsistent font sizes, leading to inaccuracies. A key strategy involves extracting features from multiple scales (e.g., global overview, localized regions, and fine-grained details) and aggregating them. This multi-scale approach allows the model to capture both holistic context and fine details, improving the representation of visual information. However, simply feeding all scales to an LLMs can be computationally expensive due to the quadratic complexity of self-attention mechanisms. Therefore, methods to aggregate and compress multi-scale features efficiently are needed. Efficient aggregation techniques balance the trade-off between preserving essential information from various scales and maintaining computational efficiency. The effectiveness of a multi-scale strategy is typically validated by comparing performance against single-scale baselines on various document understanding tasks, demonstrating that the multi-scale approach leads to improved performance.
HVFA Module#
The Hierarchical Visual Feature Aggregation (HVFA) module is a crucial component of the proposed OCR-free document understanding framework. Its primary function is to efficiently manage multi-scale visual features derived from document images, a critical aspect given the variability in font sizes and visual elements within documents. The HVFA module addresses the computational challenges posed by directly feeding these multi-scale features to large language models (LLMs), which have quadratic complexity with respect to input size. By employing cross-attentive pooling within a feature pyramid, the module achieves a balance between preserving essential visual information and reducing the number of input tokens. This design is particularly important as it allows the model to accommodate various document image sizes without compromising performance or exceeding the LLM’s token capacity. The effectiveness of HVFA is demonstrated through experiments that show superior performance compared to other approaches that do not efficiently address multi-scale visual input. The module’s integration with a novel instruction tuning task further enhances the model’s text-reading and layout understanding capabilities, highlighting its significance in enabling comprehensive OCR-free document analysis.
Instruction Tuning#
Instruction tuning, a crucial element in multimodal large language models (MLLMs), significantly enhances the model’s ability to understand and respond to complex instructions. Instead of relying solely on predefined tasks, instruction tuning exposes the MLLM to a wide range of instructions, fostering its ability to generalize and adapt to new, unseen tasks. This method is particularly valuable in document understanding where instruction diversity is critical for handling various document layouts, formatting, and information extraction needs. The effectiveness hinges on the quality and diversity of instructions. Well-crafted instructions not only guide the model toward desired behaviors but also help the model learn more robust and generalized visual-linguistic representations. However, the potential for biases embedded within the instructions needs careful consideration, as these biases can propagate and affect the model’s outputs. Furthermore, the computational cost associated with instruction tuning can be substantial, especially for large-scale datasets, requiring careful optimization and resource management.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a complex model. By removing or altering specific parts, researchers can isolate their effects and gain a deeper understanding of the model’s architecture. In this context, ablation studies would likely focus on the impact of multi-scale visual features, the effectiveness of the hierarchical visual feature aggregation (HVFA) module, and the contribution of the novel instruction tuning tasks. Removing multi-scale inputs would likely reduce accuracy on documents with diverse font sizes. Disabling the HVFA module should reveal whether it improves efficiency without significant information loss. Finally, omitting the instruction tuning components should demonstrate their importance in enhancing text reading ability and layout understanding. The results of these experiments would provide crucial insights into the design choices and the overall effectiveness of the proposed document understanding framework. Quantifying the performance impact for each ablation would offer strong evidence for the design choices made in creating the model.
Future Works#
Future research directions stemming from this OCR-free document understanding framework could explore several promising avenues. Extending the framework to multilingual scenarios is crucial for broader applicability. Investigating the use of alternative visual encoders beyond the current ViT architecture might yield further efficiency gains and potentially improve performance on documents with complex layouts or unusual visual elements. Exploring different instruction tuning strategies could also enhance the model’s text reading and overall understanding capabilities. For instance, incorporating more sophisticated layout information during training could improve the accuracy of relative position predictions. The effectiveness of various feature aggregation techniques beyond the proposed HVFA module warrants further investigation. A detailed comparative analysis of different pooling methods, alongside ablation studies to determine the impact of various architectural choices, could guide more efficient model designs. Finally, a comprehensive evaluation on a wider range of document types and sizes would be beneficial to demonstrate the generalization capabilities of this approach and potentially uncover any limitations in specific scenarios.
More visual insights#
More on figures
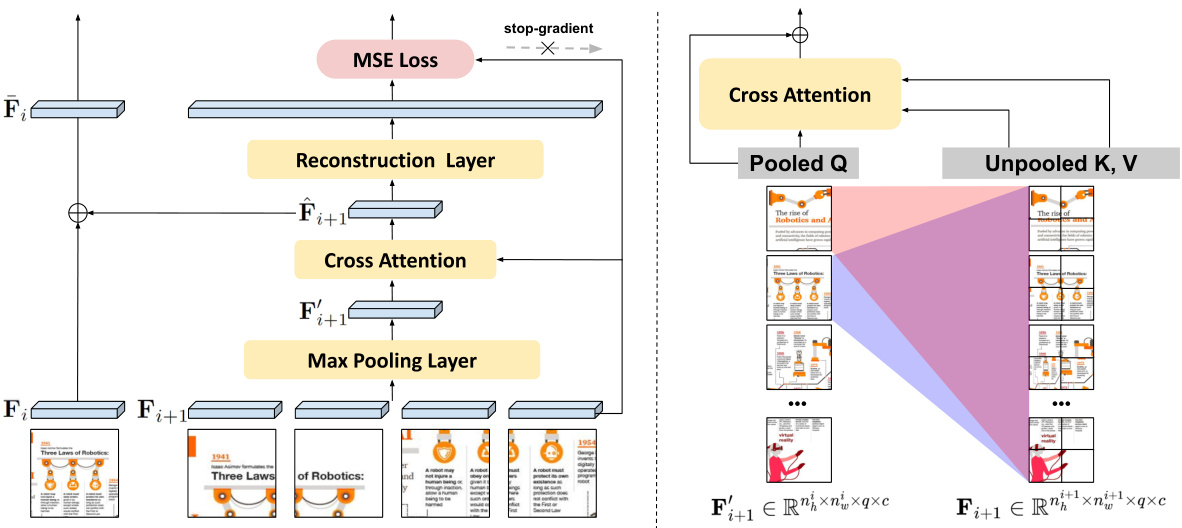
This figure illustrates the Hierarchical Visual Feature Aggregation (HVFA) module’s architecture. The left panel shows how the module uses a feature pyramid to combine visual features from different resolutions (high-resolution and low-resolution). The right panel zooms in on the cross-attentive pooling mechanism within the HVFA, illustrating how each low-resolution feature attends to all high-resolution features to compress information while maintaining detail.
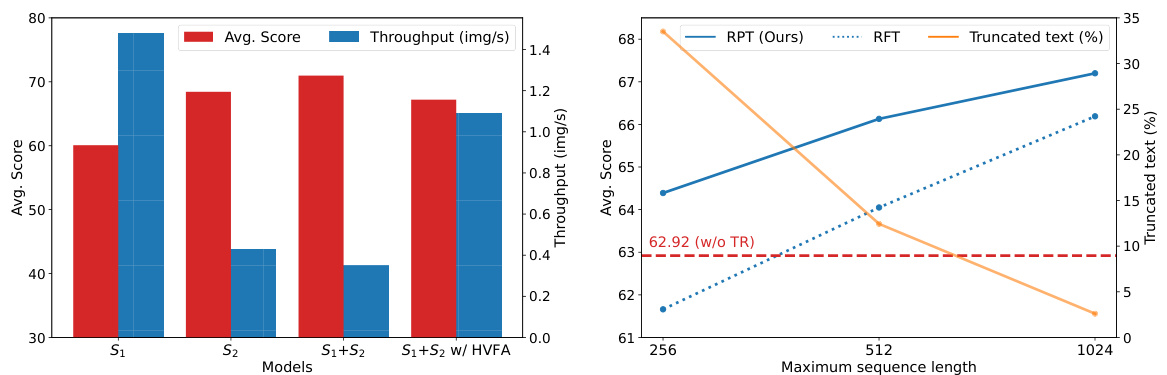
The left plot shows that using multiple scales and HVFA improves the model’s performance. The right plot demonstrates the model’s robustness to text truncation by using RPT which reads a portion of the text within the image.
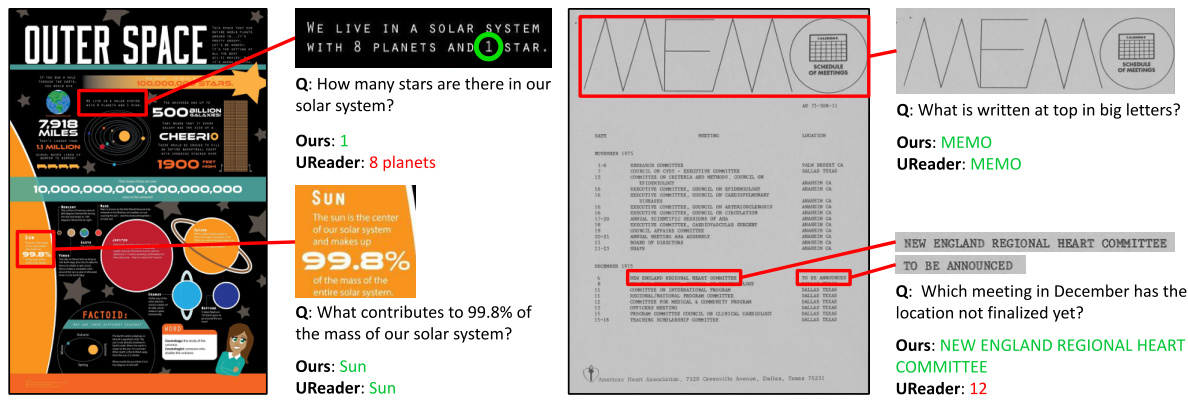
This figure illustrates the architecture of the proposed OCR-free document understanding framework. It shows how multi-scale visual features are extracted from a document image, aggregated using the Hierarchical Visual Feature Aggregation (HVFA) module, and fed into a large language model (LLM) to generate a textual response. The figure highlights the importance of using multi-scale features to handle varying font sizes and the role of the HVFA module in efficiently managing the information from different scales. The red box emphasizes the need to capture fine-grained visual details from high-resolution images.
More on tables
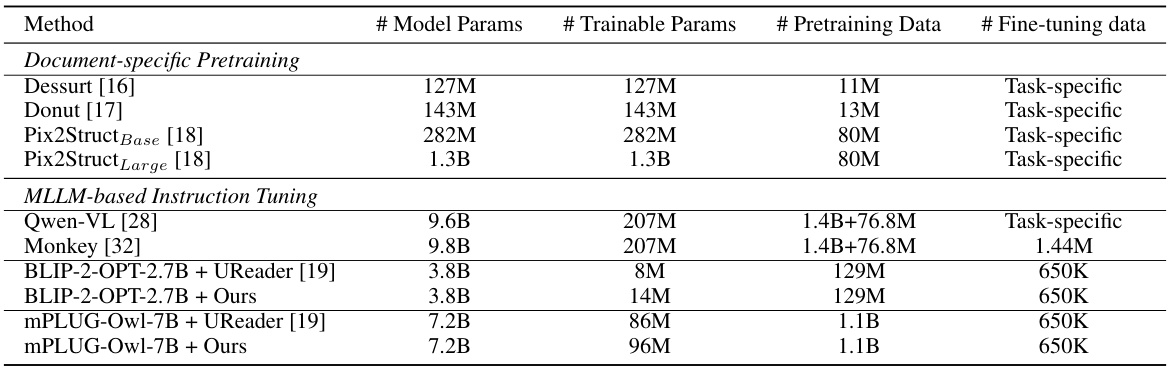
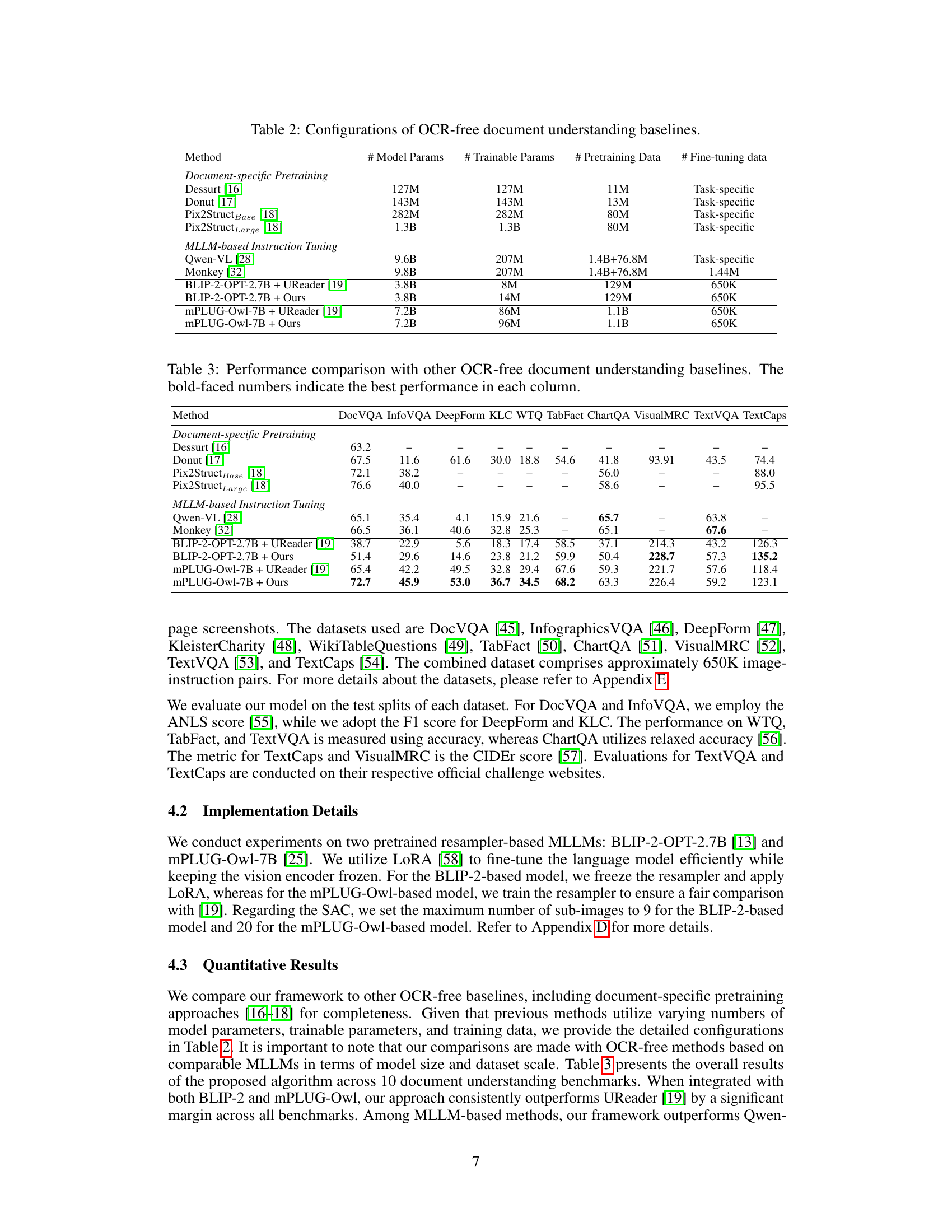
This table compares different baselines used for OCR-free document understanding. It lists the number of model parameters, trainable parameters, pretraining data, and fine-tuning data for each baseline. The baselines are categorized into two groups: ‘Document-specific Pretraining’ and ‘MLLM-based Instruction Tuning’. The table helps to illustrate the differences in model size, training data, and approach used among various OCR-free methods.
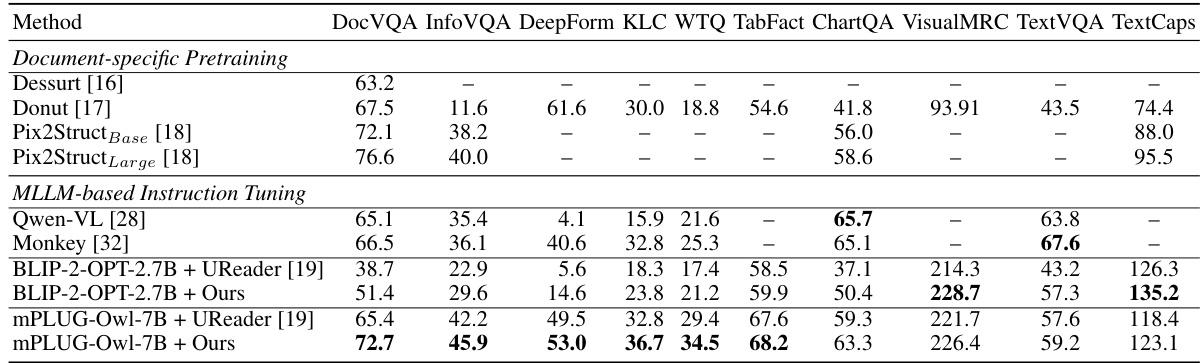
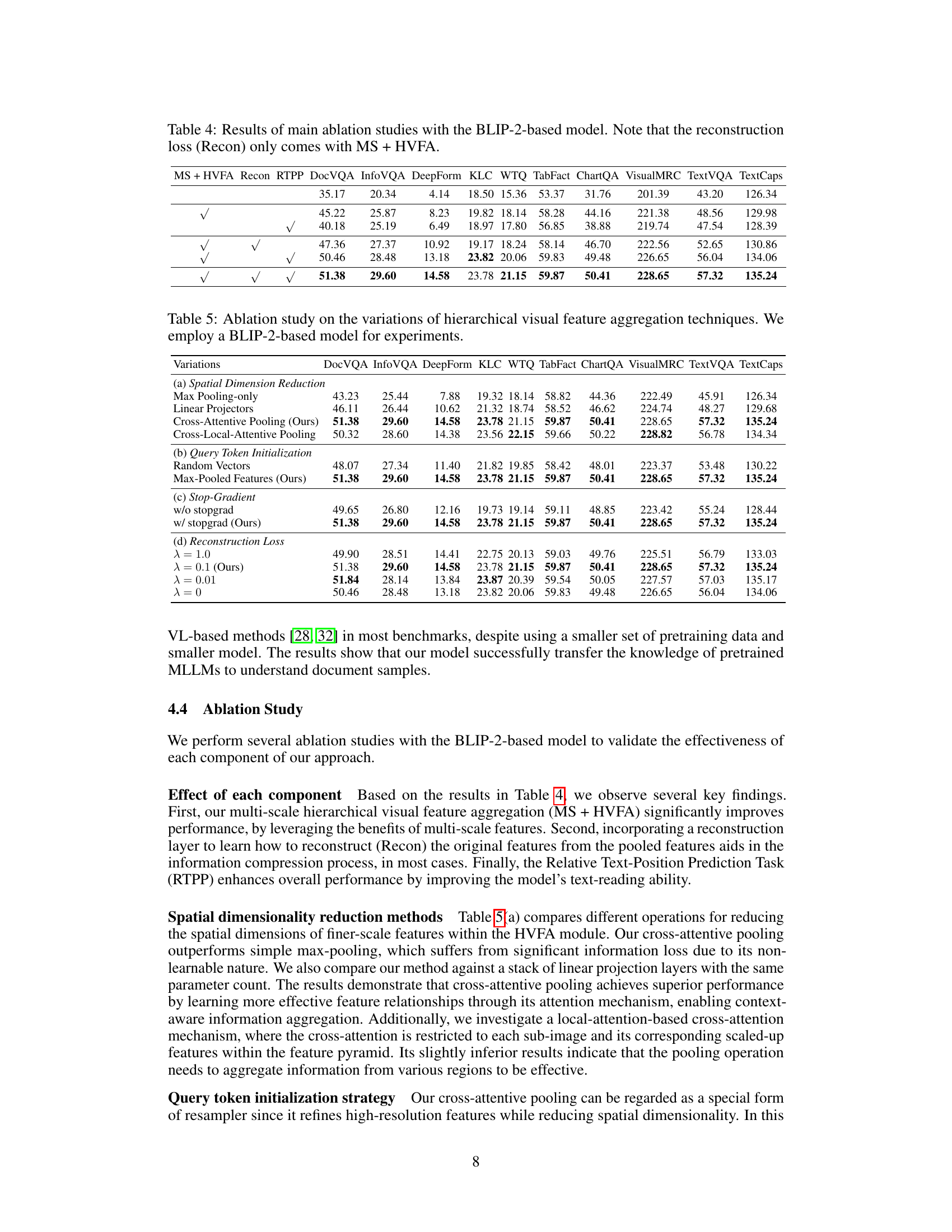
This table presents a quantitative comparison of the proposed model’s performance against other state-of-the-art OCR-free document understanding methods across various benchmark datasets. The datasets cover diverse document understanding tasks, including visual question answering, infographics question answering, form information extraction, table fact verification, chart question answering, visual machine reading comprehension, and text-based visual question answering. The table highlights the superior performance of the proposed approach, indicated by boldfaced numbers showing the best results in each task. The results demonstrate the effectiveness of the proposed method in handling various document types and complexity levels.

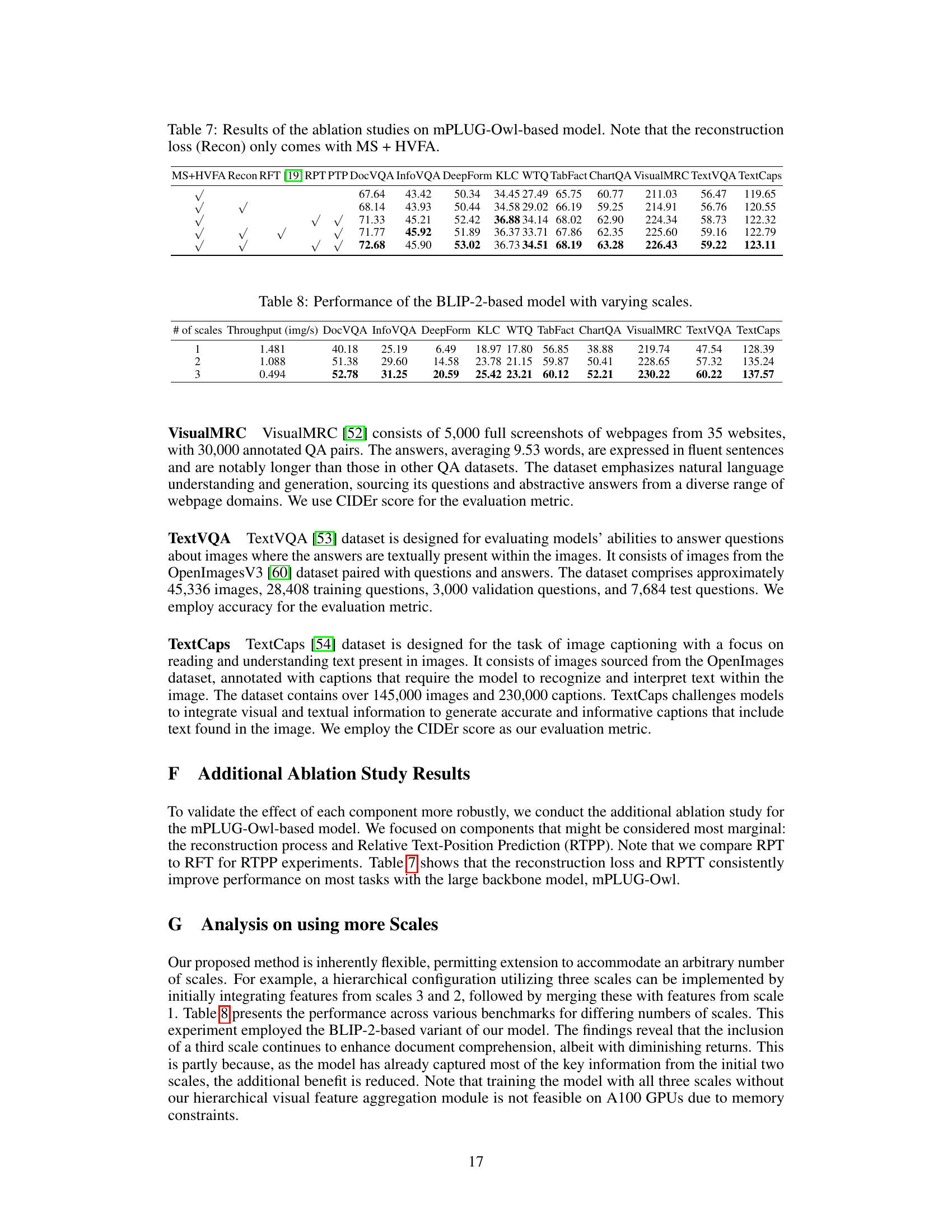
This table presents the results of ablation studies conducted using the BLIP-2-based model. The impact of different components on model performance is evaluated across various document understanding tasks (DocVQA, InfoVQA, DeepForm, etc.). The results show the effect of including multi-scale features (MS), the hierarchical visual feature aggregation (HVFA) module, a reconstruction layer, and the relative text position prediction (RTPP) task on overall performance. Notably, only when both multi-scale features and the HVFA module are used, reconstruction loss is considered.
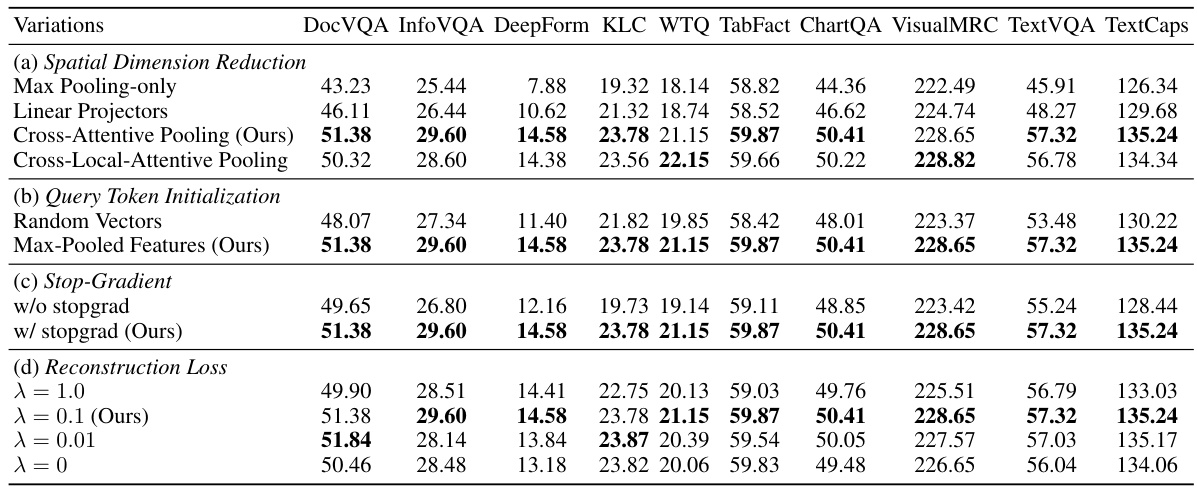
This table presents the results of an ablation study investigating different variations of the hierarchical visual feature aggregation (HVFA) techniques. The study uses a BLIP-2-based model and evaluates performance across multiple document understanding benchmarks (DocVQA, InfoVQA, DeepForm, KLC, WTQ, TabFact, ChartQA, VisualMRC, TextVQA, and TextCaps). Variations include: spatial dimension reduction methods (max pooling, linear projectors, cross-attentive pooling, and cross-local-attentive pooling), query token initialization strategies (random vectors and max-pooled features), stop-gradient techniques (with and without stop-gradient), and reconstruction loss weight adjustments (λ = 1.0, λ = 0.1, λ = 0.01, and λ = 0). The table shows the impact of each variation on the performance metrics for each benchmark.

This table compares the performance of the proposed OCR-free document understanding framework with other existing OCR-free baselines across ten different document understanding benchmarks. It shows the performance (measured using different metrics appropriate to each benchmark) for each model on several tasks. The bold numbers highlight the best performing model for each task.

This table presents a quantitative comparison of the proposed model’s performance against other state-of-the-art OCR-free document understanding baselines across multiple benchmark datasets. The datasets evaluate various aspects of document understanding, including visual question answering, information extraction, and table fact verification. The bold numbers highlight the best performance achieved by any model for each specific benchmark.

This table shows the performance of the BLIP-2 based model on various document understanding benchmarks with different numbers of visual scales used as input. The number of scales refers to the levels of detail incorporated through the shape-adaptive cropping (SAC) method (global, nh x nw, and 2nh x 2nw). The table presents the trade-off between model performance and computational efficiency, as adding scales improves accuracy but reduces the throughput (images processed per second).
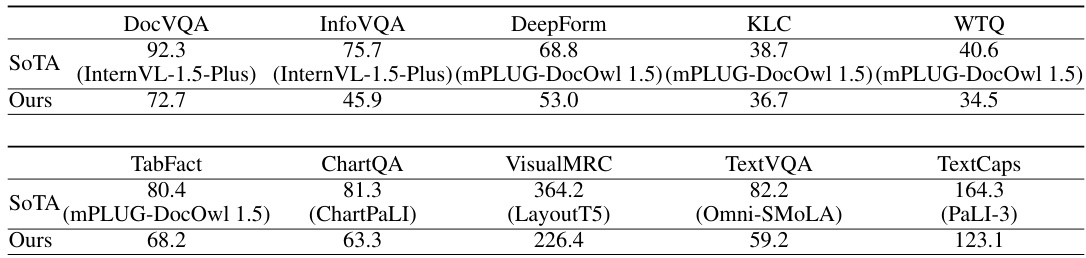
This table compares the performance of the proposed OCR-free document understanding framework with the state-of-the-art (SOTA) methods for each of the ten document understanding benchmark datasets. It highlights the relative performance of the proposed approach against task-specific models, showcasing its ability to perform well across diverse and challenging tasks compared to specialized methods.
This table presents the configurations of several OCR-free document understanding baselines. It compares different methods across several key metrics, including the number of model parameters, the number of trainable parameters, the size of the pretraining data used, and the size of the fine-tuning data used. This allows for a comparison of the computational resources and data requirements of different approaches to OCR-free document understanding.
Full paper#