↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current LLM agents struggle with adaptability, requiring elaborate designs and expert prompts for task completion in specific domains. This limits their usability and scalability across diverse applications. The problem stems from their inability to autonomously build environmental understanding and adapt to new scenarios. This is unlike humans who readily learn and adapt through interactive experiences.
AutoManual solves this by enabling LLM agents to learn from interaction and adapt to new environments. This is achieved through two key agents: the Planner, which develops actionable plans based on learned rules, and the Builder, which updates these rules through dynamic interaction. A third agent, the Formulator, consolidates the rules into a comprehensive, human-readable manual. The framework significantly improves task success rates in complex environments, demonstrating its potential to improve the overall adaptability and usability of LLM agents.
Key Takeaways#
Why does it matter?#
This paper is important because it presents AutoManual, a novel framework that allows LLM agents to autonomously learn and adapt to new environments. This addresses a critical limitation of existing LLM agents, which often require extensive hand-crafted rules or demonstrations to operate effectively in specific domains. The method’s effectiveness on benchmark tasks demonstrates its potential to significantly improve the adaptability and efficiency of LLM agents across various applications. The code availability further facilitates broader adoption and future research.
Visual Insights#
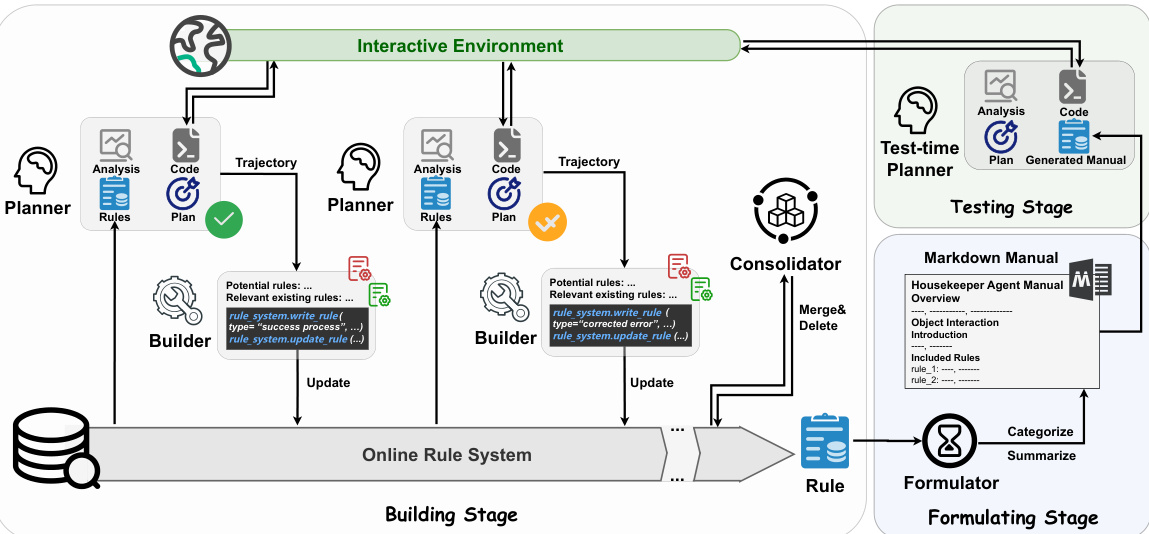
This figure illustrates the AutoManual framework’s three main stages. The Building Stage shows the Planner and Builder agents iteratively interacting with the environment and updating a rule system. The Planner generates plans as executable code, and the Builder refines the rules based on the interaction results. The Formulating Stage depicts the Formulator agent compiling the rules into a human-readable Markdown manual. Finally, the Testing Stage shows a test-time Planner using the generated manual to perform tasks in the environment.
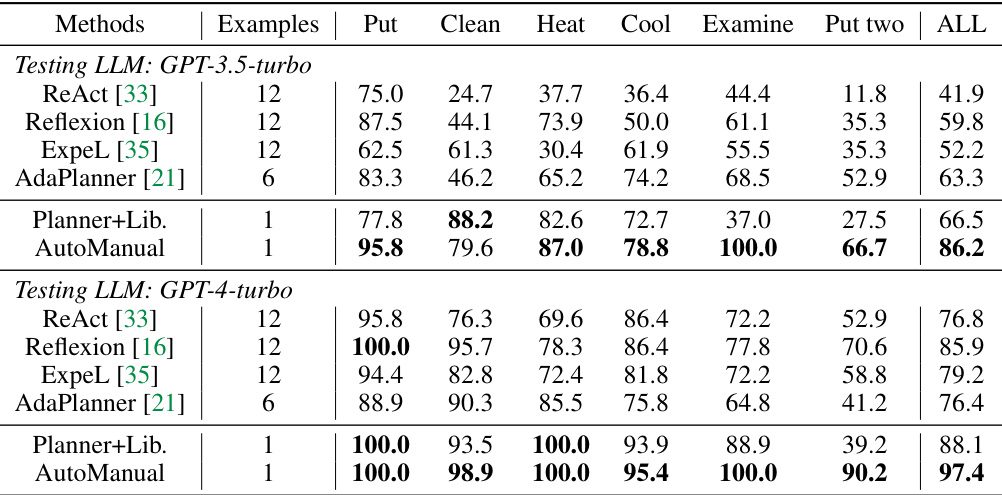
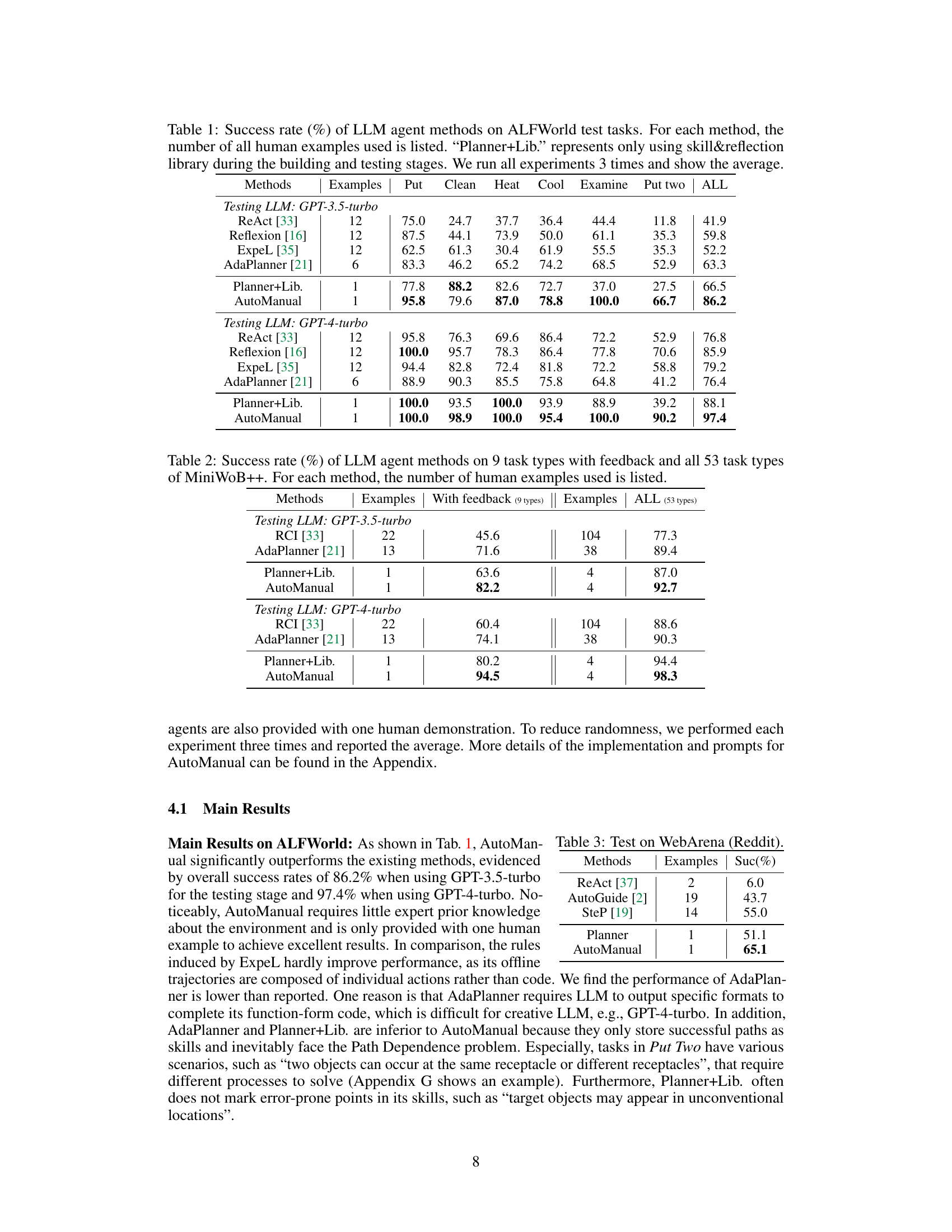
This table presents the success rates of different Large Language Model (LLM) agent methods on ALFWorld benchmark tasks. It compares the performance of AutoManual against several existing methods (ReAct, Reflexion, ExpeL, AdaPlanner) and a baseline (Planner+Lib). The table shows the success rates for each of six individual tasks within ALFWorld, along with an overall average success rate. The number of human examples used to train each method is also shown. The experiments were run three times, and the average success rate is reported.
In-depth insights#
LLM Agent Framework#
An LLM agent framework is a structured system designed to enable Large Language Models (LLMs) to perform complex tasks autonomously. It typically involves a system architecture comprising modules for perception, planning, action execution, and learning. Modular design is key for flexibility, allowing different LLMs and environments to be integrated. The framework’s effectiveness hinges on its ability to manage and learn from interactions with the environment, adapting its knowledge base (e.g., rules, skills) over time. Robustness is crucial; mechanisms for handling errors, uncertainties, and unexpected situations must be integrated. A well-designed framework is human-readable, facilitating both development and understanding, enabling humans to easily supervise, modify or debug the system. The interactive learning component is critical, allowing the agent to continuously update its understanding and refine its performance, moving beyond limitations of static knowledge representation. Ultimately, a successful LLM agent framework should demonstrate improved task completion rates, adaptability, and explainability compared to LLMs operating without such a supporting structure.
Interactive Learning#
Interactive learning, within the context of AI research papers, often signifies a paradigm shift from traditional passive learning approaches. Instead of relying solely on pre-defined datasets, interactive learning emphasizes the role of dynamic feedback loops between an AI agent and its environment. This feedback helps the AI agent to not only adapt to unforeseen circumstances but also to actively refine its understanding of the task and its interaction with the environment. The iterative process of action, observation, and feedback allows the AI to learn far beyond what’s explicitly programmed, demonstrating a form of self-improvement. A crucial aspect involves efficient management and utilization of this feedback, which requires careful consideration of the representation, storage, and retrieval of learned experiences. Therefore, successful interactive learning systems often incorporate sophisticated memory mechanisms and effective strategies to guide the AI agent’s learning process. The goal is often to improve adaptability and reduce the dependence on pre-trained knowledge, creating systems capable of tackling diverse and evolving scenarios.
Rule System Design#
A robust rule system is crucial for the success of any intelligent agent, particularly one operating in complex or dynamic environments. The design of such a system requires careful consideration of several key factors. Data structure is paramount: will rules be represented as simple key-value pairs, more complex objects with attributes (e.g., type, confidence, source), or perhaps a graph to capture dependencies between rules? The choice impacts storage efficiency, query speed, and overall system complexity. Rule acquisition also presents a significant challenge. How will rules be obtained? Will they be hand-crafted by experts, learned from data (supervised, unsupervised, or reinforcement learning), or through a combination of methods? Rule management is equally important. Methods to add, update, and delete rules must be efficient and reliable, ensuring consistency and preventing conflicts or redundancies. Conflict resolution mechanisms are necessary to handle situations where multiple rules might apply simultaneously. Finally, rule representation must be considered. For human understanding and debugging, human-readable representations are essential, while for computational efficiency, a more compact representation (e.g., a numerical vector) might be needed. Extensibility is crucial; the system must be easily adapted to accommodate new rules and new knowledge as the agent interacts with its environment and learns from experience. A well-designed rule system should exhibit a balance between these factors, ensuring both effectiveness and maintainability.
Empirical Evaluation#
An empirical evaluation section in a research paper should meticulously document the experimental setup, including datasets used, evaluation metrics, and baseline methods. Detailed descriptions of the methodology are crucial for reproducibility. The results should be presented clearly, often using tables and figures, showing the performance of the proposed method against baselines across various settings. Statistical significance testing is essential to determine if observed differences are meaningful. A robust analysis should account for potential confounding factors and biases, and acknowledge any limitations of the evaluation. The discussion should connect the empirical findings back to the paper’s main claims, explaining how the results support or challenge the hypotheses. Strong empirical evidence strengthens the overall impact and credibility of the research. Careful consideration of factors such as dataset size, experimental design, and the selection of evaluation metrics can significantly influence the conclusions drawn from the study.
Future Works#
The ‘Future Works’ section of this research paper could explore several promising avenues. Extending AutoManual to handle more complex environments with richer sensory inputs and more nuanced actions is crucial. This would involve refining the rule system to manage the increased complexity and possibly incorporating techniques like reinforcement learning for better adaptation to unfamiliar scenarios. Investigating the scalability of AutoManual to larger LLMs and more complex tasks is another key direction. The current implementation relies on GPT-4, and scaling to less powerful models while maintaining performance would be significant. This could involve optimizing the rule system and possibly integrating techniques from knowledge transfer or few-shot learning. Addressing the limitations identified in the paper, such as reliance on GPT-4 and the potential for hallucinations, warrants further investigation. Developing more robust methods for rule extraction and verification could improve the accuracy and reliability of the manuals produced. Finally, a critical area for future work is evaluating the robustness of AutoManual across a wider variety of tasks and environments. Thorough testing and benchmarking against existing methods would enhance the generalizability and establish AutoManual’s efficacy in different contexts.
More visual insights#
More on figures
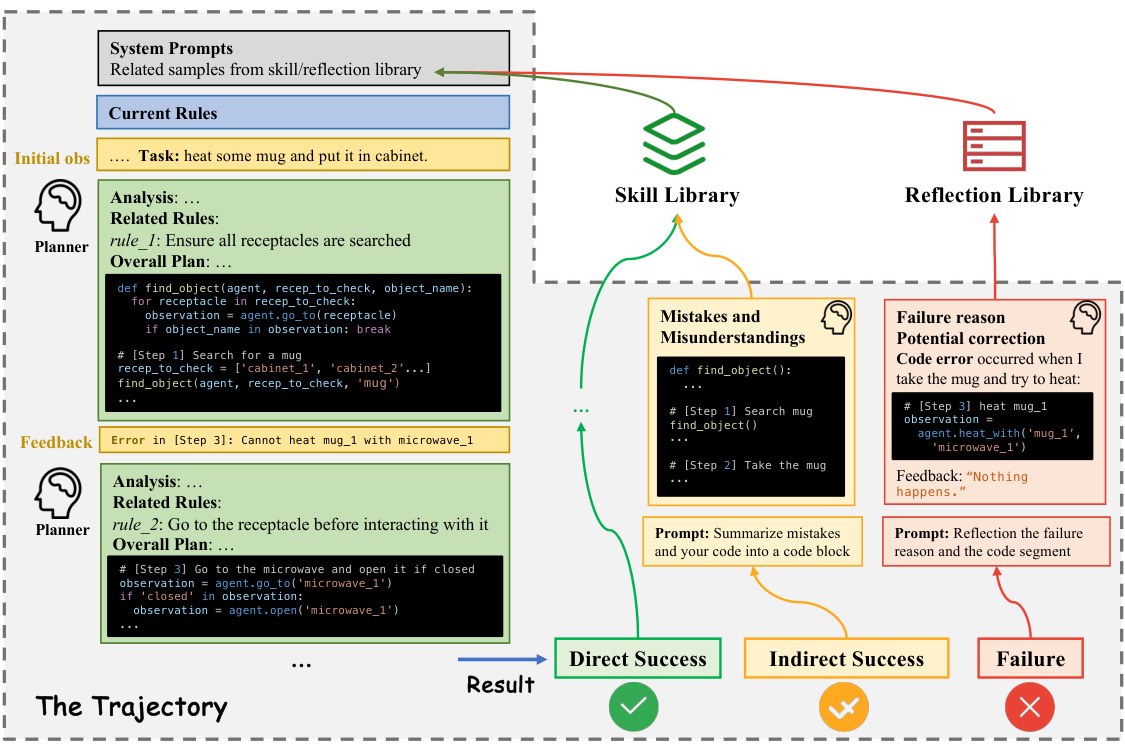
This figure illustrates the interactive process between the Planner agent and the environment. The Planner generates a plan in the form of free-form code to interact with the environment. The result of this interaction (success, partial success, or failure) is recorded along with the Planner’s code and analysis. This trajectory is then used by the Builder agent to update the rules, and successful plans are stored in a skill library while failed plans along with their analysis are added to a reflection library. This process of planning, acting, and reflecting is crucial to the AutoManual framework.
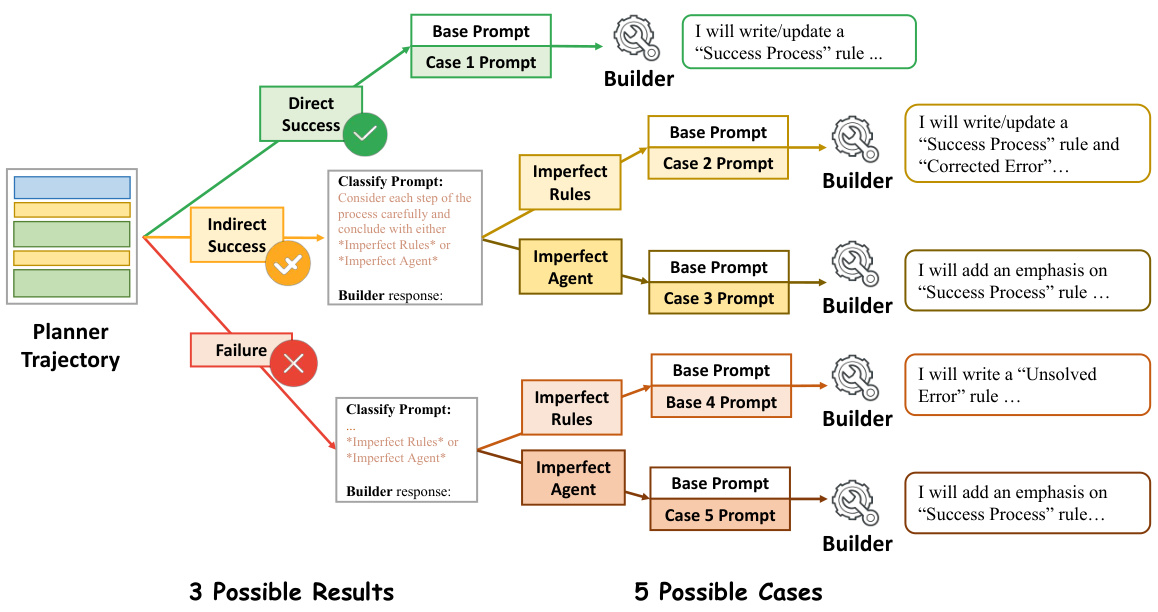
This figure illustrates the case-conditioned prompting strategy used in the AutoManual framework. Based on the outcome (Direct Success, Indirect Success, or Failure) of a Planner agent’s interaction with the environment, the Builder agent receives different prompts to guide its rule updates. The prompts are tailored to whether the failure was due to flaws in the rules themselves (‘Imperfect Rules’) or shortcomings of the Planner agent (‘Imperfect Agent’). This strategy helps mitigate issues caused by large language models (LLMs) generating hallucinations during rule management.

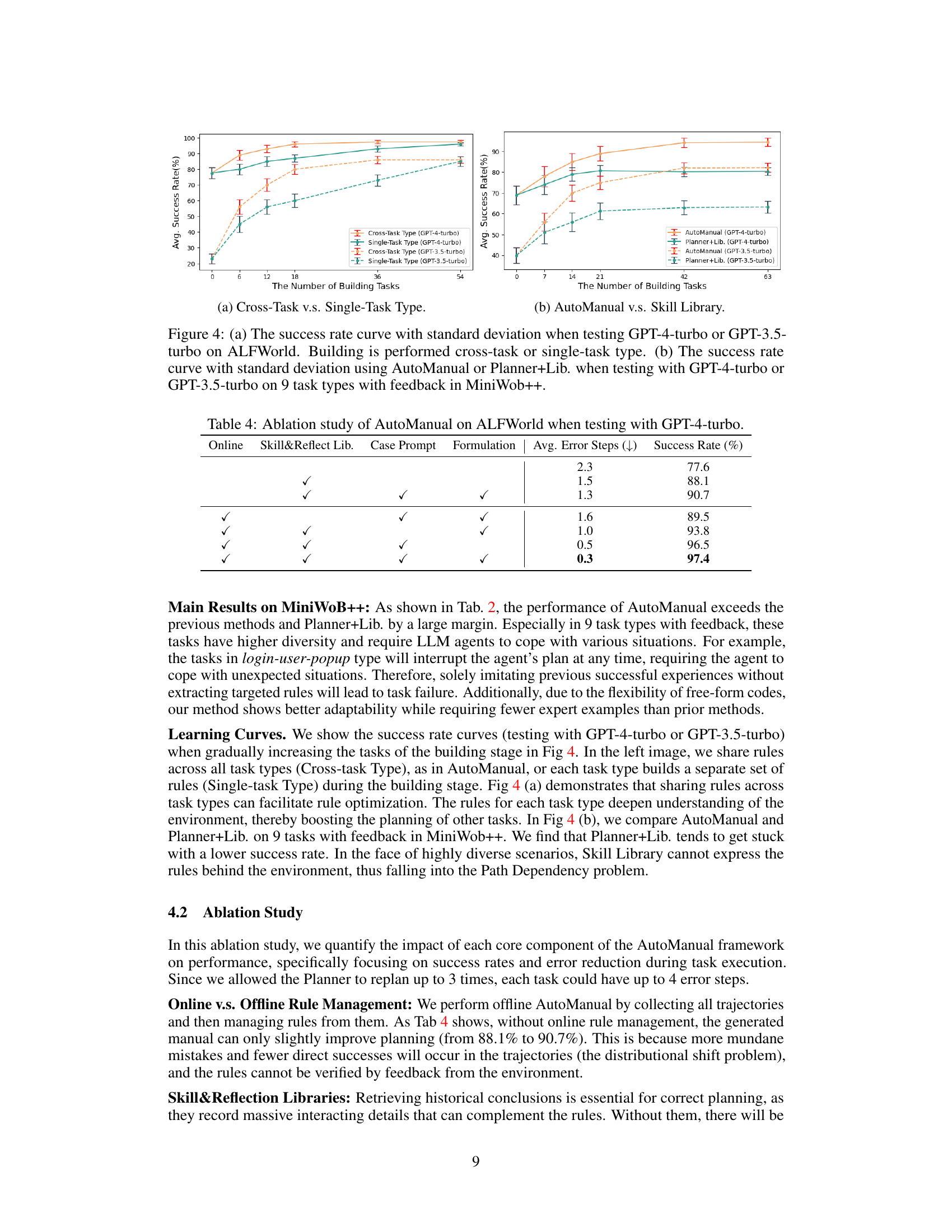
This figure presents two sub-figures showing the learning curves of different methods. Subfigure (a) compares the performance of cross-task and single-task training on ALFWorld using GPT-4-turbo and GPT-3.5-turbo. It demonstrates that cross-task training, where rules are shared across different tasks, leads to better overall performance. Subfigure (b) contrasts AutoManual with Planner+Lib. on MiniWoB++’s 9 feedback-rich tasks, revealing AutoManual’s superiority and the effectiveness of the online rule management system. Both subfigures showcase the learning curves with standard deviations, illustrating the stability and robustness of the approaches.
This figure illustrates the AutoManual framework’s three main stages. The Building Stage shows the Planner and Builder agents iteratively interacting with the environment and refining rules. The Planner generates plans as executable code, and the Builder updates the rule system based on the interaction results. The Formulating Stage depicts the Formulator agent compiling these rules into a human-readable Markdown manual. Finally, the Testing Stage shows a test-time Planner agent using the generated manual to perform new tasks. The figure visually represents the dynamic interaction and rule refinement process within the AutoManual framework.

This figure presents a high-level overview of the AutoManual framework. It shows three main stages: 1) Building Stage: The Planner agent interacts with the environment, generating code-based plans. The Builder agent then updates the rules based on this interaction. 2) Formulation Stage: The Formulator agent compiles the rules into a user-friendly Markdown manual. 3) Testing Stage: A test-time Planner agent evaluates the effectiveness of the generated manual in completing tasks. The figure visually depicts the flow between these three stages using a flowchart.

This figure presents a high-level overview of the AutoManual framework, illustrating the three main stages of operation: building, formulating, and testing. In the building stage, a Planner agent interacts with the environment, creating executable plans. These interactions, along with the resulting trajectory, are used to update a rule system managed by a Builder agent. The formulating stage sees a Formulator agent compile these rules into a human-readable manual. Finally, the testing stage evaluates the effectiveness of the generated manual by a test-time Planner agent performing tasks.
More on tables
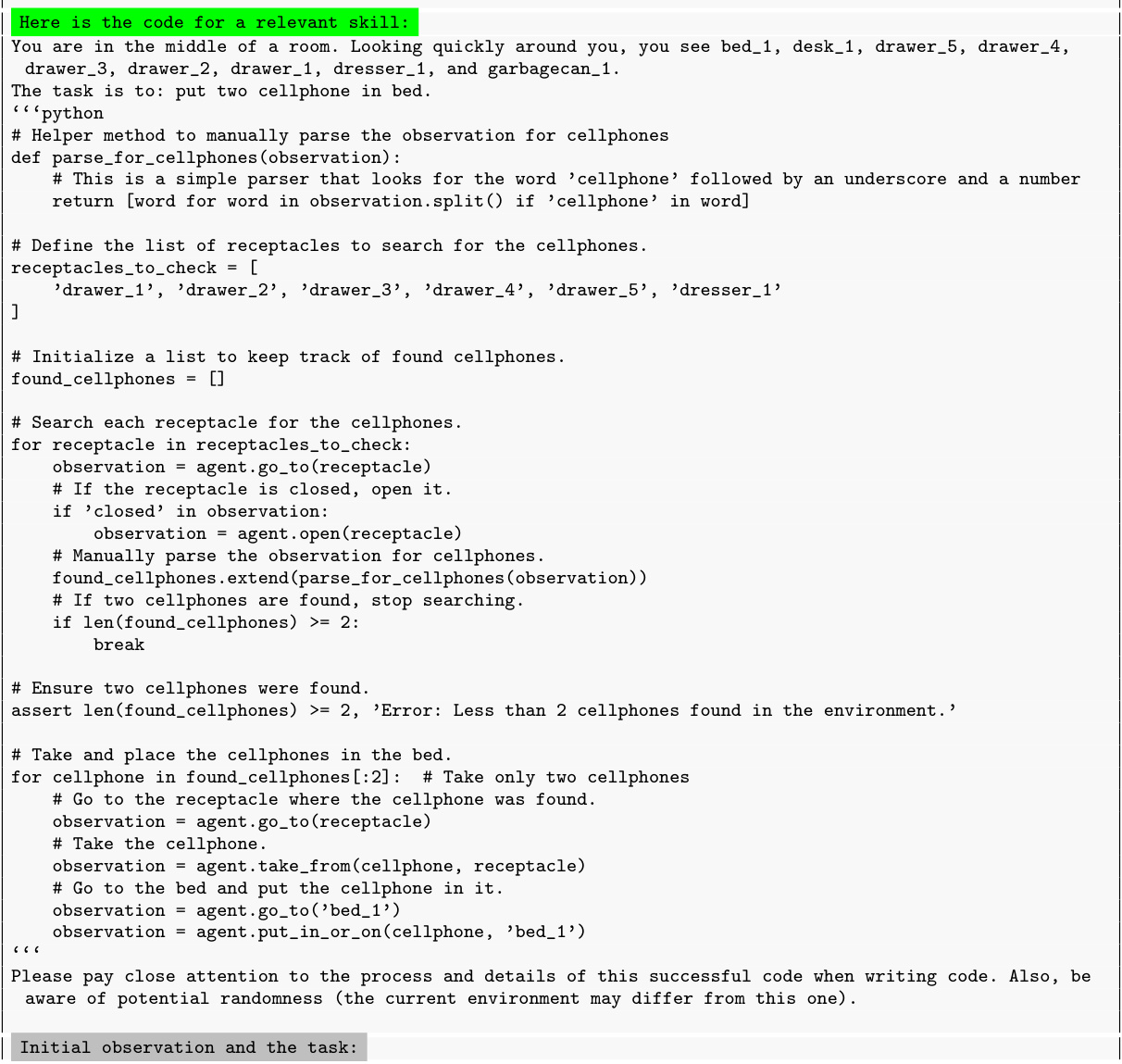
This table presents the success rates of various Large Language Model (LLM) agent methods on the MiniWoB++ benchmark. It compares the performance of AutoManual against other state-of-the-art methods (ReAct, Reflexion, ExpeL, AdaPlanner, and RCI) on two different sets of tasks within the MiniWoB++ environment: a subset of 9 tasks with feedback and the full set of 53 tasks. The number of human examples used to train each method is also provided to illustrate the relative data efficiency of each approach. The table highlights AutoManual’s superior performance across both task sets, especially with the GPT-4-turbo model, even when trained with a significantly reduced number of examples compared to other methods.
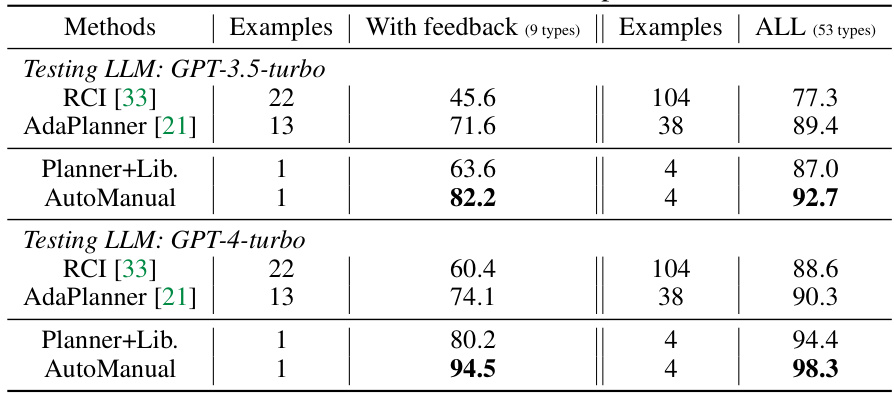
This table presents the success rate (%) of different LLM agent methods on the Reddit domain within the WebArena environment. It compares the performance of AutoManual against existing methods (ReAct, AutoGuide, and SteP) by showing the success rate achieved with a single example versus the number of examples used by the compared methods. The table highlights the performance improvement of AutoManual in a complex, realistic web environment.

This table presents the results of an ablation study conducted on the AutoManual framework using the GPT-4-turbo model for testing on ALFWorld. The study systematically removes components of the AutoManual framework (online rule management, skill and reflection libraries, case-conditioned prompting, and manual formulation) to assess their individual contributions to the overall performance. The results are presented in terms of the average number of error steps and the success rate. The table helps to understand the relative importance of each component in achieving high performance.

This table presents the success rates achieved by different Large Language Model (LLM) agent methods on ALFWorld test tasks. Each method is evaluated, and its performance is shown by the success rate. The table indicates how many human examples were used to train each method. There is also a comparative analysis involving the use of only the skill & reflection library during both building and testing phases. The average success rate across three runs is reported for each method.
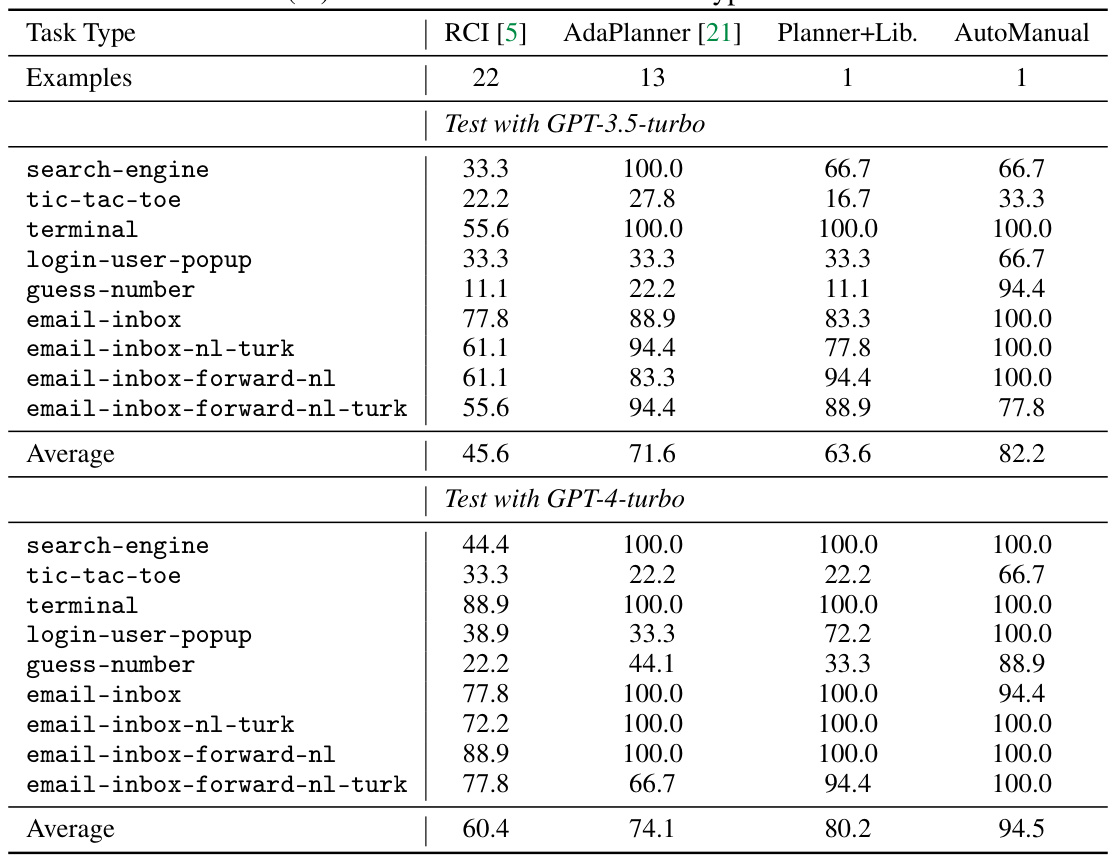
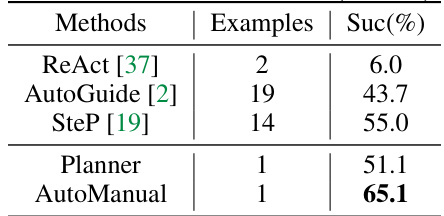
This table compares the success rates of different LLM agent methods (RCI, AdaPlanner, Planner+Lib, and AutoManual) on the MiniWoB++ benchmark. It shows the performance on two sets of tasks: 9 tasks with feedback and all 53 tasks. The number of human examples used for training each method is also indicated. The table helps demonstrate the effectiveness of AutoManual in achieving high success rates even with limited training data compared to other methods.
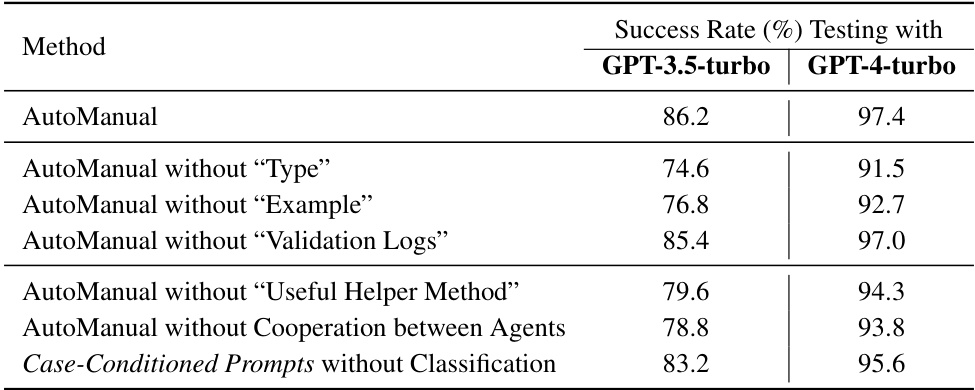
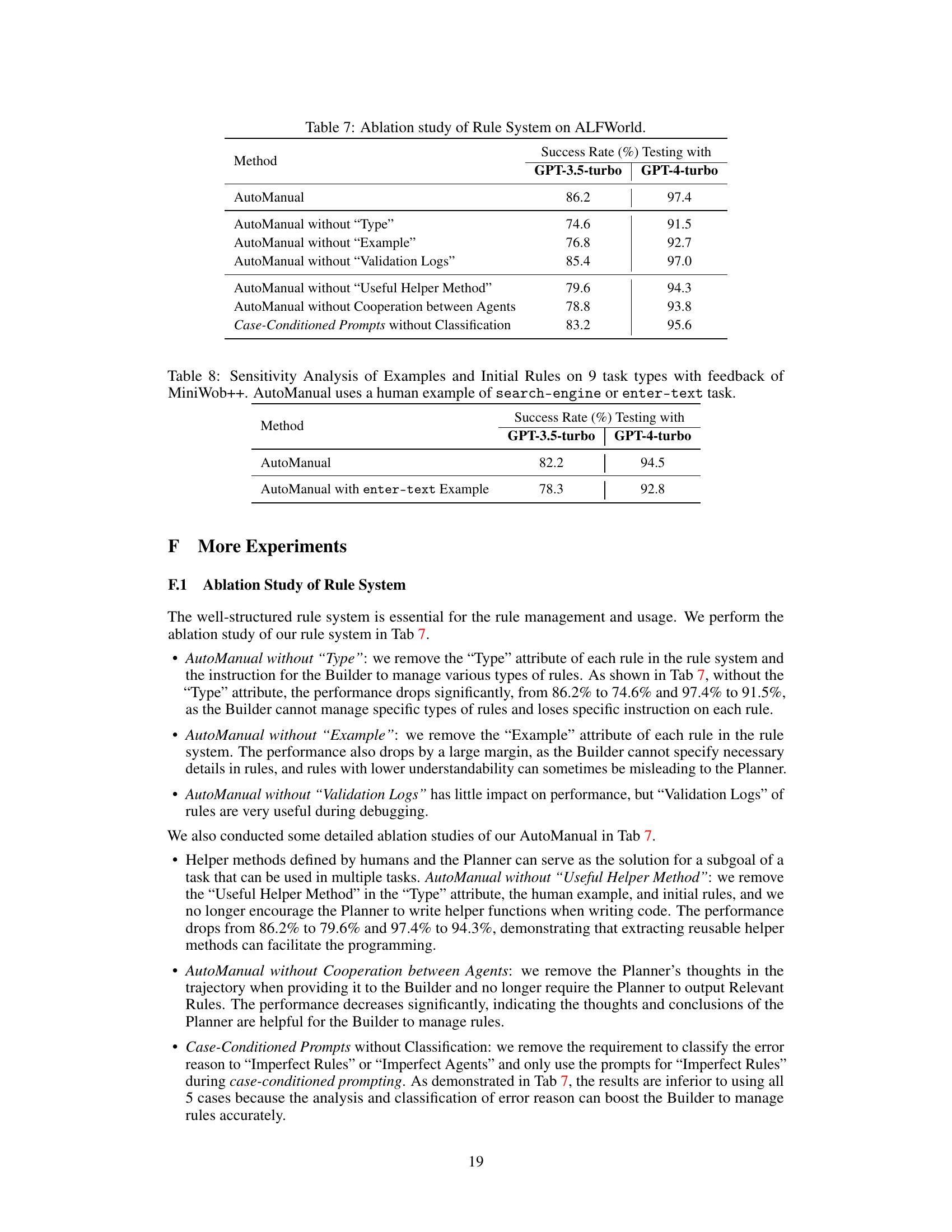
This table presents the results of an ablation study conducted on the ALFWorld benchmark to evaluate the impact of different components of the AutoManual framework on the success rate of LLM agents. The study removes components such as the ‘Type’ attribute, ‘Example’ attribute, ‘Validation Logs’, ‘Useful Helper Method’, and the cooperation between the agents, as well as testing the performance of the case-conditioned prompts without classification. The success rate is measured using both GPT-3.5-turbo and GPT-4-turbo language models. The results illustrate how each component contributes to the overall performance of the system.

This table presents the results of a sensitivity analysis conducted to evaluate the impact of different initial conditions (human examples and initial rules) on the performance of AutoManual. The experiment was conducted on 9 MiniWoB++ tasks that involve user feedback. Two scenarios are tested: using a ‘search-engine’ example and using a simpler ’enter-text’ example. The success rate is measured for both GPT-3.5-turbo and GPT-4-turbo language models. The results demonstrate the robustness of AutoManual to variations in initial conditions.

This table presents the success rates of different Large Language Model (LLM) agent methods on ALFWorld test tasks. It compares the performance of AutoManual against several existing methods (ReAct, Reflexion, ExpeL, AdaPlanner). The table shows success rates for different sub-tasks within ALFWorld (Put, Clean, Heat, Cool, Examine, Put Two) as well as the overall success rate. The number of human examples used for training each method is also listed. A control experiment called ‘Planner+Lib.’ uses only the skill and reflection library during both training and testing, providing a baseline comparison. The experiment was conducted three times, and the average success rate is presented.
Full paper#