TL;DR#
Continual Knowledge Learning (CKL) in large language models (LLMs) faces challenges like catastrophic forgetting, where new information overwrites existing knowledge. Existing CKL methods often apply uniform weights to tokens during training, leading to inefficient updates and increased forgetting. This paper introduces TAALM, a novel CKL approach that dynamically predicts and applies weights to tokens based on their predicted usefulness using a meta-learning framework.
TAALM addresses the limitations of uniform weighting by focusing learning efforts on important tokens. The paper evaluates TAALM on new and established benchmarks, showing that it significantly improves learning efficiency and knowledge retention compared to baseline methods. The introduction of LAMA-CKL, a new CKL benchmark, allows for a clearer evaluation of the trade-off between learning and retaining information. TAALM’s superior performance and the new benchmark contribute significantly to the advancement of CKL in LLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to continual knowledge learning (CKL) in large language models, addressing the inefficiency of standard training procedures by dynamically weighting tokens based on their usefulness. It also proposes a new benchmark, enhancing the field’s ability to evaluate CKL methods more effectively.
Visual Insights#
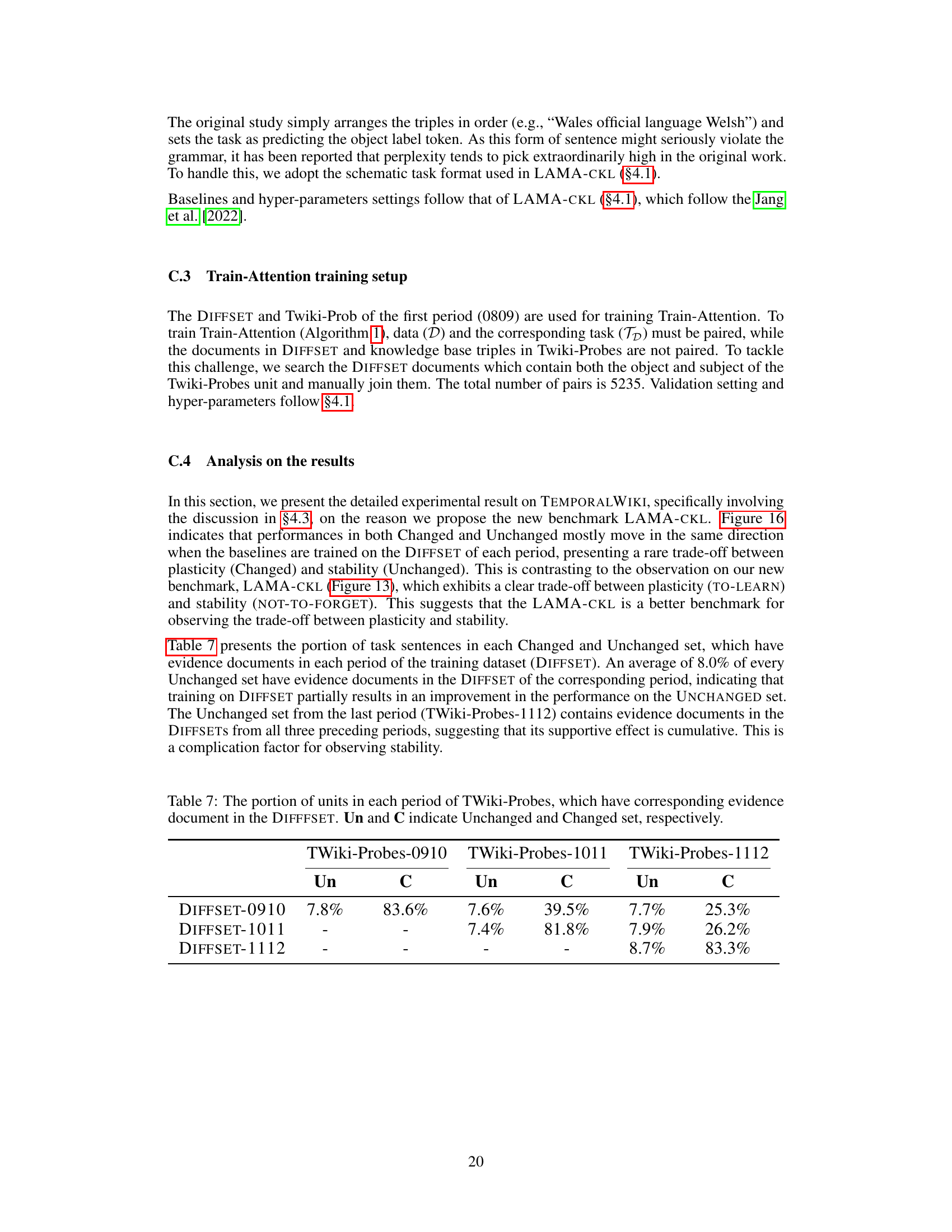
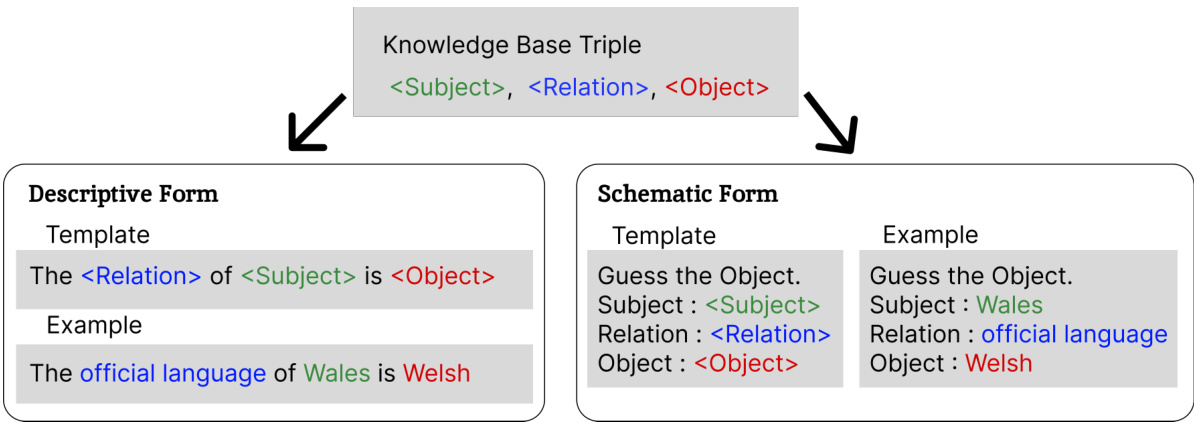
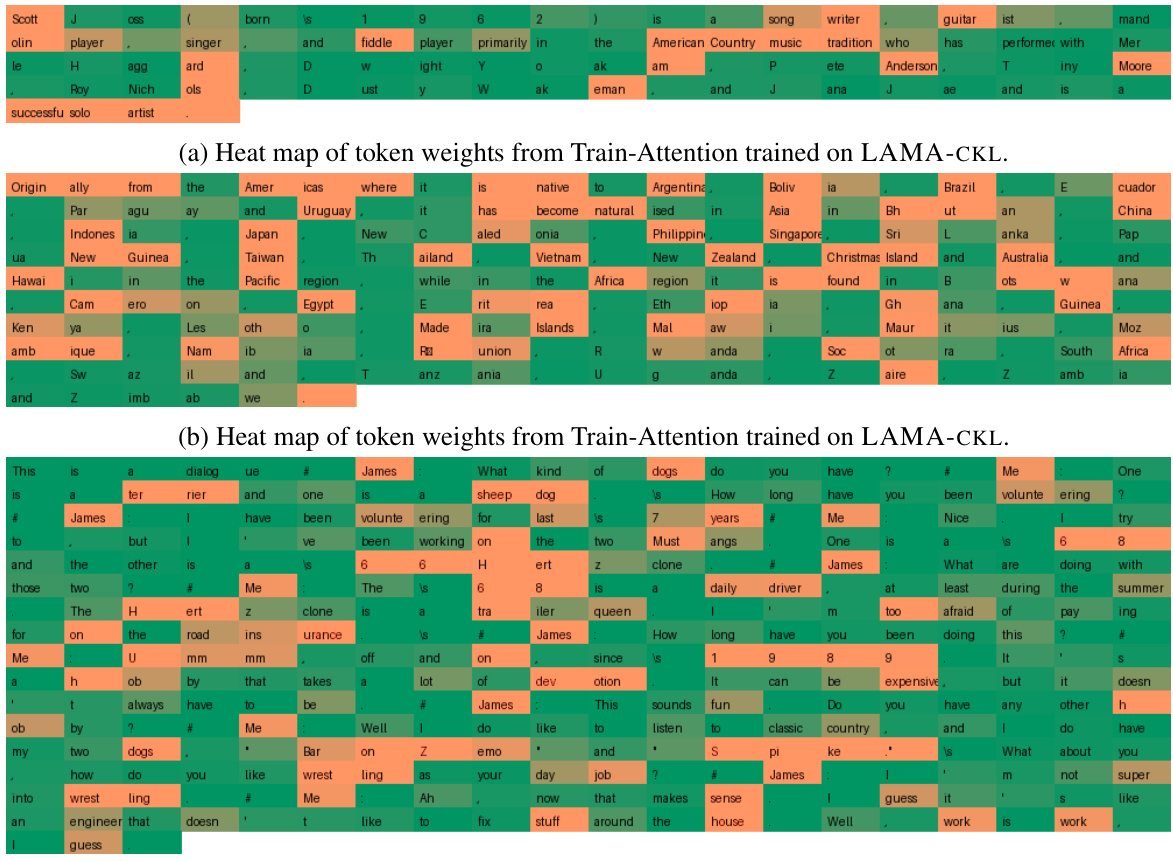
🔼 This figure illustrates the difference between standard causal language models and the proposed Train-Attention model. (a) shows how a causal language model processes text by decomposing it into multiple token sequences, each with varying importance but assigned uniform weights. This can lead to inefficiencies and increased forgetting in continual knowledge learning. (b) introduces the Train-Attention model, which uses meta-learning to predict token weights that approximate importance. This enables targeted knowledge updates and minimizes forgetting.
read the caption
Figure 1: (a) Learning of Causal LM: The document is decomposed into multiple token sequences Sixi x
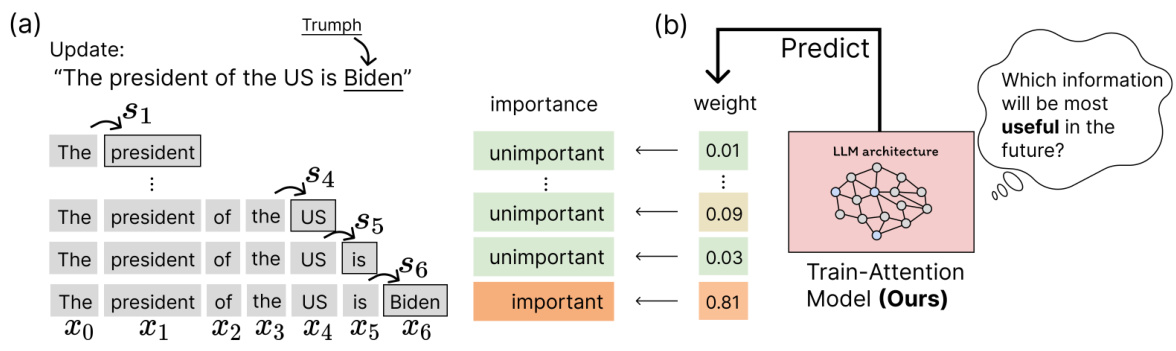
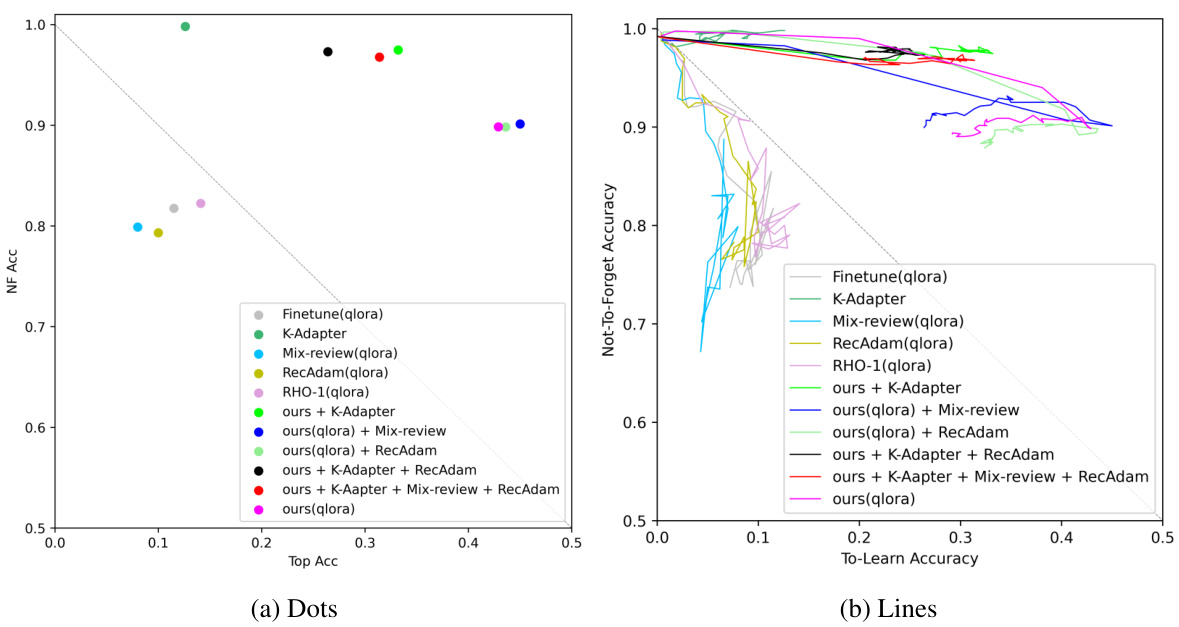
🔼 This table presents the quantitative results of different continual knowledge learning (CKL) methods on the LAMA-CKL benchmark using the Llama2-7B language model. The metrics evaluated are Top Accuracy (Top Acc), the epoch at which the highest accuracy was achieved, Not-To-Forget Accuracy (NF Acc), and Total Knowledge (sum of Top Acc and NF Acc). The table highlights the superior performance of TAALM (Train-Attention-Augmented Language Model) compared to existing baselines, demonstrating its effectiveness in balancing learning new knowledge and retaining old knowledge.
read the caption
Table 1: LAMA-CKL performance of Llama2-7B based baselines. The evaluation indicator of each column is explained on §4.1. The best performance is marked as bold while the second best is underlined.
In-depth insights#
Meta-CKL Approach#
A meta-CKL approach offers a powerful strategy for addressing the challenges of continual knowledge learning (CKL). By leveraging meta-learning techniques, a meta-CKL approach can dynamically adapt to new knowledge, optimizing learning efficiency and minimizing catastrophic forgetting. This adaptability is crucial for CKL scenarios where models must learn from a continuous stream of data without losing previously acquired information. A key advantage is the potential for targeted knowledge updates. Instead of uniformly updating all parameters, a meta-CKL approach could prioritize updates based on their predicted usefulness, leading to more efficient learning and reduced forgetting. Effective weight assignment to different tokens or data points is another key factor. The meta-learning component can learn to assign appropriate weights, focusing learning on critical aspects while ignoring less relevant information. However, designing and implementing effective meta-CKL approaches presents significant challenges. The need for appropriate benchmark datasets reflecting real-world CKL scenarios is a critical requirement. Furthermore, the computational cost of meta-learning can be high, requiring careful consideration of resource management strategies. Despite these challenges, meta-CKL approaches represent a significant advancement in CKL, offering a more intelligent and adaptive solution.
Train-Attention Model#
The Train-Attention model presents a novel approach to continual knowledge learning (CKL) in large language models (LLMs) by meta-learning token importance. Instead of uniformly updating all tokens during training, it dynamically predicts and applies weights based on each token’s usefulness for future tasks. This targeted approach improves learning efficiency and minimizes catastrophic forgetting. The model uses a meta-learning framework to optimize these importance predictions, focusing updates on crucial information while preserving previously learned knowledge. This innovative method is shown to outperform baseline CKL techniques on various benchmarks, highlighting its effectiveness in balancing plasticity (learning new knowledge) and stability (retaining old knowledge). The core innovation is the Train-Attention component, a meta-learner that predicts token weights, effectively guiding the LLM’s learning process. This approach addresses inherent inefficiencies in standard training procedures of LLMs and offers a more sophisticated, targeted approach to CKL. It significantly enhances learning and retention without the downsides of methods that use generic regularization or naive knowledge rehearsal techniques. The Train-Attention mechanism is highly compatible with other CKL approaches, suggesting a synergistic potential.
LAMA-CKL Benchmark#
The proposed LAMA-CKL benchmark offers a significant advancement in evaluating continual knowledge learning (CKL) for large language models (LLMs). It directly addresses the limitations of existing benchmarks by explicitly measuring both plasticity (the ability to learn new knowledge) and stability (the ability to retain previously learned knowledge) in a more nuanced way. Unlike previous methods that often conflate these two crucial aspects, LAMA-CKL introduces a clear separation and quantitative evaluation by employing the LAMA dataset, tailoring it to assess knowledge acquisition of time-variant relationships and retention of time-invariant ones. This novel approach enables a more precise understanding of the trade-offs inherent in CKL algorithms, leading to a more rigorous and comprehensive assessment of LLM performance and paving the way for improved CKL methodologies.
Synergistic Effects#
The concept of “synergistic effects” in the context of continual knowledge learning (CKL) refers to the improved performance achieved when combining different CKL methods. The core idea is that the strengths of various approaches complement each other, leading to better knowledge retention and acquisition than using any single method alone. This might involve integrating regularization techniques with architectural modifications or incorporating rehearsal strategies alongside attention-based weighting schemes. For example, a model using both regularization and rehearsal might avoid catastrophic forgetting more effectively than one that uses only regularization. The paper likely explores how TAALM interacts with existing CKL methods to create such synergistic effects, demonstrating that its unique contribution is not only independent but also enhances other approaches. The extent of performance improvement serves as a key metric to gauge the extent of synergism, revealing the potential for creating significantly more robust and effective CKL models through strategic combinations of techniques.
Future Work#
Future research could explore several promising avenues. Improving the efficiency and scalability of the Train-Attention model is crucial, particularly given its current resource demands. Investigating alternative meta-learning architectures and training strategies could enhance its performance and reduce its computational burden. A deeper exploration of the optimal definition and quantification of ’token importance’ is needed. While the paper uses usefulness, further research could refine this concept by incorporating other factors. Also, studying the interaction between Train-Attention and different base LLMs is important, as its effectiveness might vary depending on the base model’s architecture and pre-training data. Finally, applying TAALM to a wider range of continual learning tasks, beyond those evaluated in this paper, and comparing its performance against other state-of-the-art methods on different benchmarks will be important. Exploring the potential for transfer learning within TAALM is another promising direction.
More visual insights#
More on figures

🔼 This figure shows the architecture of Train-Attention and Train-Attention-Augmented Language Model (TAALM). Train-Attention is a model that predicts the optimal token weights to improve the efficiency of continual knowledge learning. The left panel (a) shows the architecture of Train-Attention, highlighting how it replaces the standard LM head with a Train-Attention head that outputs a single weight for each token. The right panel (b) illustrates how Train-Attention is integrated with a causal language model (the base model) to create TAALM, where token weights are used during training to focus learning efforts on the most important tokens.
read the caption
Figure 2: (a) depicts the architecture of Train-Attention, which shares the structure of causal LM, while the decoder layer (LM head) of causal LM is replaced from a linear layer of [hidden size × vocab size] dimension to [hidden size × 1] dimension, which is TA (Train-Attention) head. (b) depicts the TAALM, where the Train-Attention (φ) is augmented to the base model (θ).
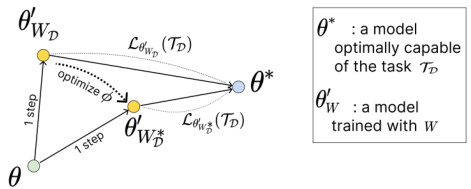
🔼 This figure illustrates the meta-learning process of Train-Attention. The model θ is updated using token weights W predicted by Train-Attention φ. The goal is to find the optimal weights W* that bring θ as close as possible to θ*, which represents the ideal model capable of performing the task TD. The process is iterative, with φ being optimized to minimize the distance between θ’ (the updated model) and θ*. The figure visually represents the steps involved in this iterative optimization, showing the movement of θ towards θ* with each update of the token weights.
read the caption
Figure 3: Optimal W leads θ closer to θ*.
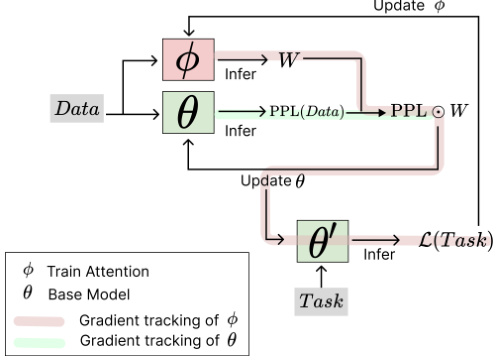
🔼 This figure shows a detailed breakdown of a single step within the Train-Attention model’s training process. It illustrates how the base model (θ) and the Train-Attention model ($ $) interact and update their respective parameters. The process involves predicting token weights (W) using the Train-Attention model, using these weights to update the base model, and then using the updated base model to evaluate task performance and update the Train-Attention model accordingly. The green and pink shading represents gradient tracking for θ and $ $, respectively, emphasizing the meta-learning aspect of the model.
read the caption
Figure 4: One step update of $ $.
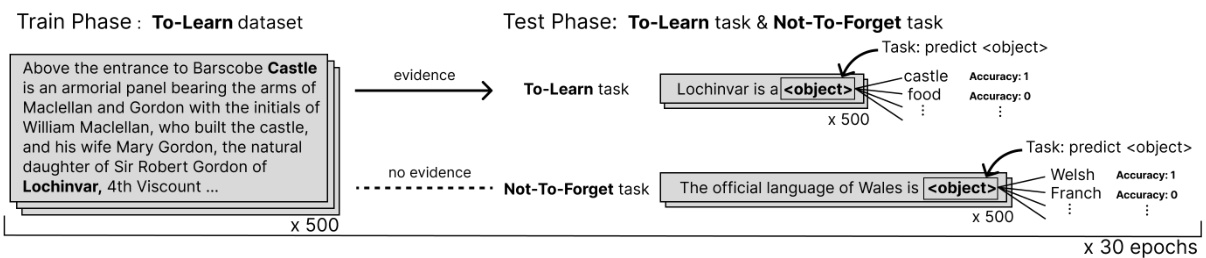
🔼 This figure illustrates the evaluation procedure for the LAMA-CKL benchmark. The process involves two phases: a training phase using the ‘To-Learn’ dataset (500 units from LAMA’s T-Rex, focusing on time-variant relations and zero accuracy in baseline models), and a testing phase assessing both ‘To-Learn’ and ‘Not-To-Forget’ tasks. The ‘To-Learn’ task evaluates plasticity (ability to learn new knowledge) while the ‘Not-To-Forget’ task assesses stability (retention of prior knowledge). This is repeated over 30 epochs.
read the caption
Figure 5: Evaluation procedure of the LAMA-CKL benchmark.

🔼 This figure illustrates the difference between a standard causal language model and the proposed Train-Attention model. (a) shows how a standard causal language model processes text by uniformly weighting all tokens, which can lead to inefficiencies in continual knowledge learning. (b) shows how the Train-Attention model addresses this by dynamically predicting and applying weights to tokens based on their importance. This allows for more targeted knowledge updates and minimizes forgetting.
read the caption
Figure 1: (a) Learning of Causal LM: The document is decomposed into multiple token sequences Sixi x
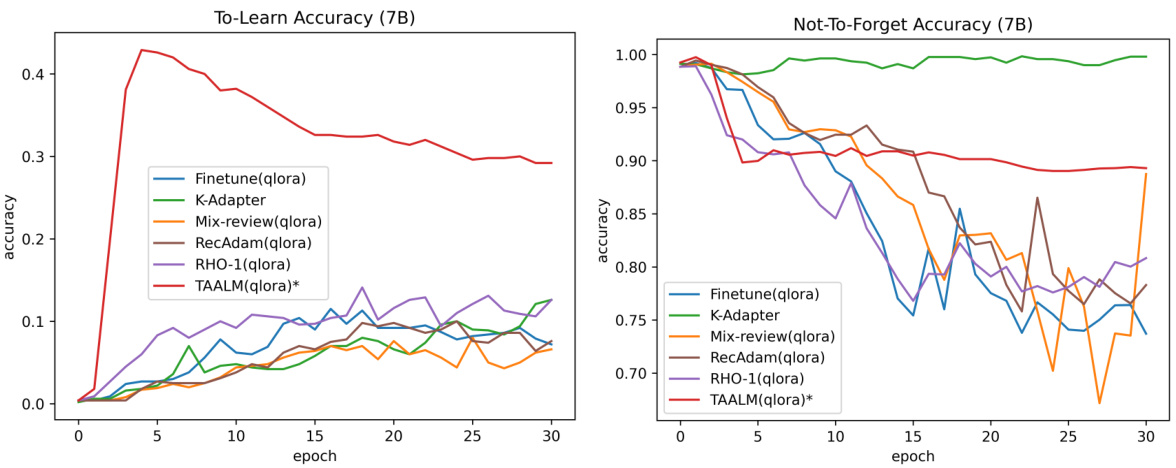
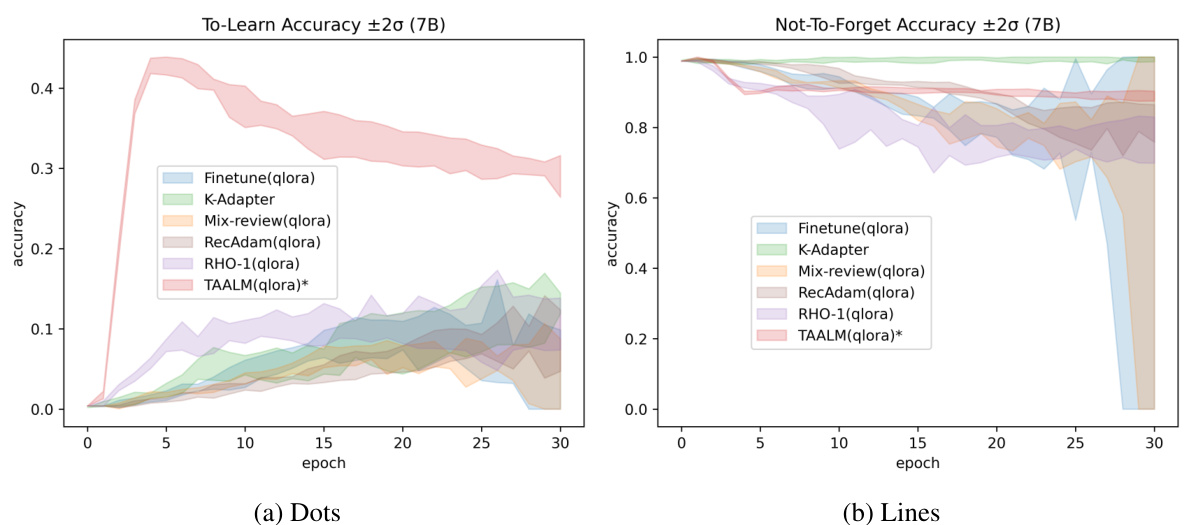
🔼 This figure shows the performance of various baseline models on the LAMA-CKL benchmark using the Llama2-7B model. The left graph displays the ‘TO-LEARN’ accuracy (how well the model learns new knowledge), while the right graph shows the ‘NOT-TO-FORGET’ accuracy (how well the model retains previously learned knowledge). Both graphs plot accuracy against the number of training epochs, illustrating the trade-off between learning new information and forgetting old information for each model.
read the caption
Figure 7: LAMA-CKL performance of large (Llama2-7B) baseline models. The graph on the left represents TO-LEARN task, and the graph on the right represents NOT-TO-FORGET task performance. The x-axis is the learning epoch, and the y-axis is accuracy.

🔼 This figure shows the performance of various baseline models on the LAMA-CKL benchmark. The left graph displays the ‘To-Learn’ accuracy (ability to learn new knowledge) over 30 epochs, while the right graph shows the ‘Not-To-Forget’ accuracy (ability to retain previously learned knowledge). It compares the performance of standard fine-tuning (Finetune) against other continual knowledge learning (CKL) approaches (K-Adapter, Mix-review, RecAdam, RHO-1) and the proposed TAALM model. The x-axis represents the training epoch, and the y-axis represents the accuracy.
read the caption
Figure 7: LAMA-CKL performance of large (Llama2-7B) baseline models. The graph on the left represents TO-LEARN task, and the graph on the right represents NOT-TO-FORGET task performance. The x-axis is the learning epoch, and the y-axis is accuracy.
🔼 This figure illustrates the difference between traditional causal language models and the proposed Train-Attention model. (a) shows that standard causal language models uniformly weight all tokens during training, which can be inefficient. (b) introduces the Train-Attention model, which uses a meta-learning approach to dynamically predict token weights based on their importance, leading to more efficient continual knowledge updates and minimizing catastrophic forgetting.
read the caption
Figure 1: (a) Learning of Causal LM: The document is decomposed into multiple token sequences Sixi x
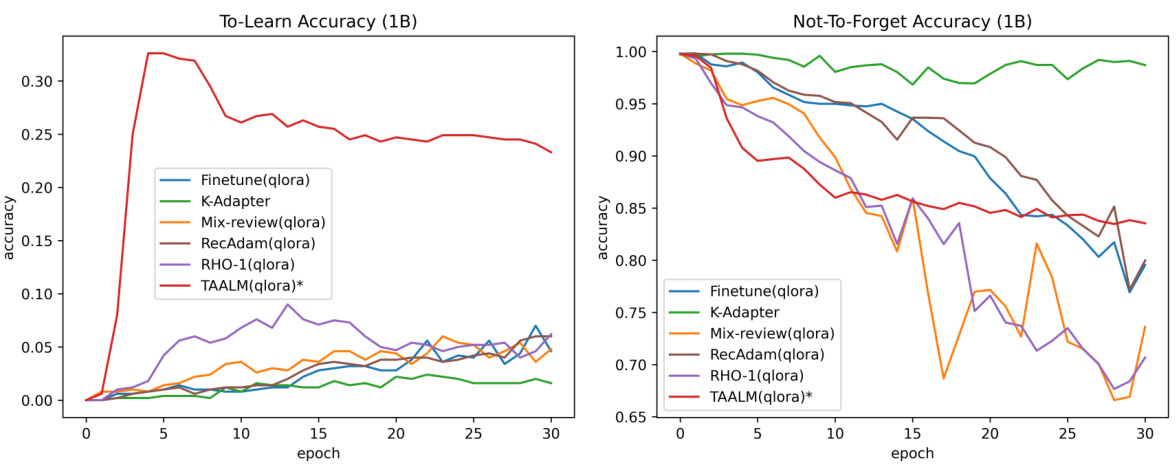
🔼 This figure shows the performance of different continual knowledge learning (CKL) methods on the LAMA-CKL benchmark using the Llama2-7B language model. The left graph displays the accuracy of the ‘To-Learn’ task (learning new knowledge), while the right graph shows the accuracy of the ‘Not-To-Forget’ task (retaining previously learned knowledge). The x-axis represents the number of training epochs, and the y-axis shows the accuracy.
read the caption
Figure 7: LAMA-CKL performance of large (Llama2-7B) baseline models. The graph on the left represents TO-LEARN task, and the graph on the right represents NOT-TO-FORGET task performance. The x-axis is the learning epoch, and the y-axis is accuracy.
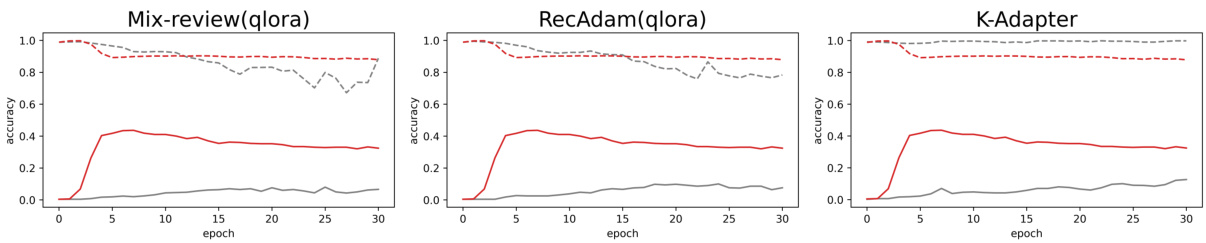
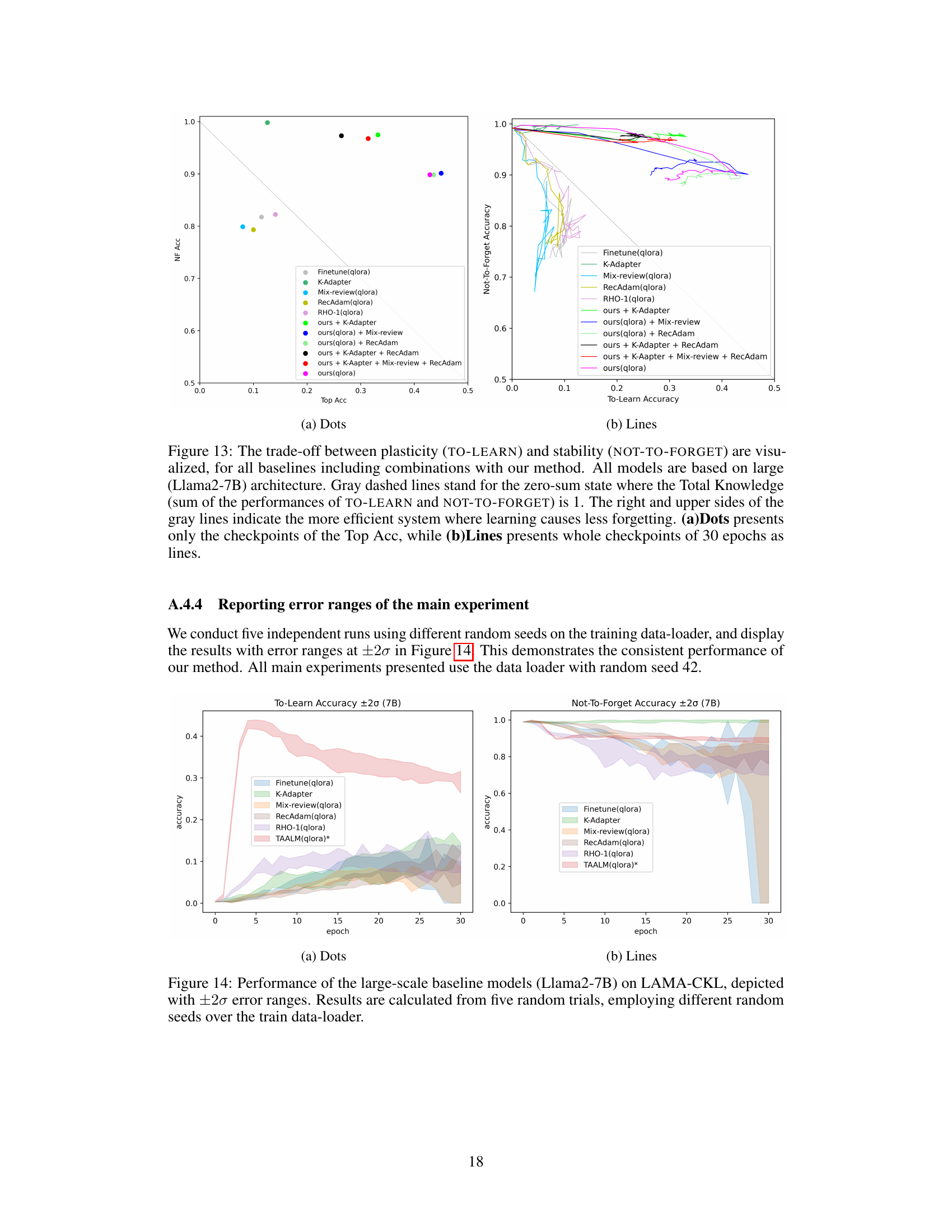
🔼 This figure compares the performance of several continual knowledge learning (CKL) baselines both individually and when combined with the proposed TAALM method. It shows the TO-LEARN (plasticity) and NOT-TO-FORGET (stability) accuracy over 30 epochs for each model. The solid lines represent TO-LEARN accuracy, and the dashed lines represent NOT-TO-FORGET accuracy. The results demonstrate that incorporating TAALM consistently improves both the plasticity and stability of the various CKL approaches.
read the caption
Figure 11: Comparison of each baseline alone and combined with our method. Each title on the plot represents the baseline method. The gray line represents the baseline alone, and the red line represents the combination with TAALM. Solid line for TO-LEARN, dashed line for NOT-TO-FORGET. All are based on Llama2-7B, and tested on LAMA-CKL.
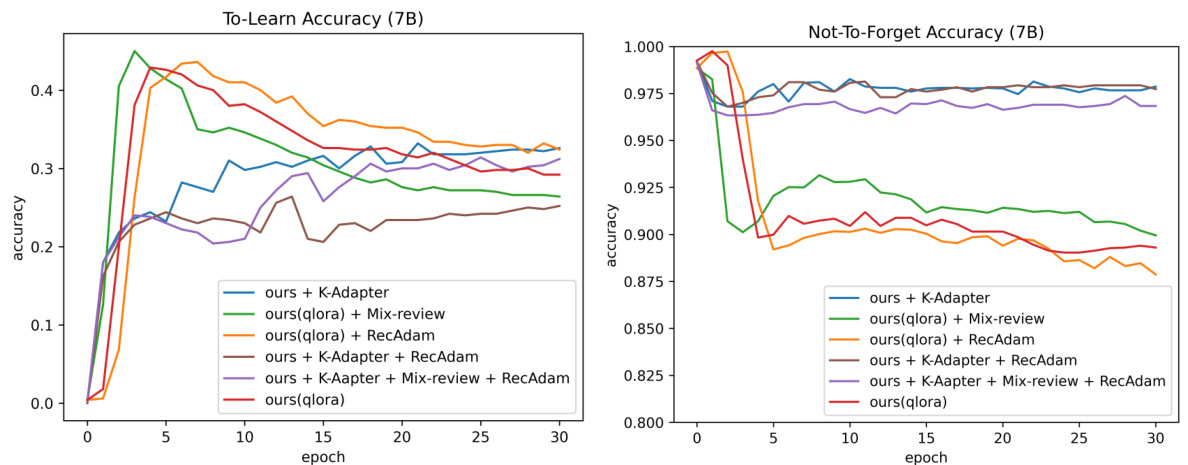
🔼 This figure shows the performance of various baseline models on the LAMA-CKL benchmark using the Llama2-7B language model. The left graph displays the TO-LEARN accuracy (how well the model learns new knowledge) and the right graph shows the NOT-TO-FORGET accuracy (how well the model retains previously learned knowledge) over 30 epochs. The x-axis represents the training epoch, and the y-axis represents the accuracy.
read the caption
Figure 7: LAMA-CKL performance of large (Llama2-7B) baseline models. The graph on the left represents TO-LEARN task, and the graph on the right represents NOT-TO-FORGET task performance. The x-axis is the learning epoch, and the y-axis is accuracy.
🔼 This figure illustrates the difference between standard causal language models and the proposed Train-Attention model. (a) shows how standard models uniformly weight all tokens, leading to inefficiency, while (b) shows the Train-Attention model dynamically predicting weights based on token importance, improving learning efficiency and reducing catastrophic forgetting.
read the caption
Figure 1: (a) Learning of Causal LM: The document is decomposed into multiple token sequences Sixi x
🔼 This figure shows the performance of different continual knowledge learning baselines on the LAMA-CKL benchmark using the Llama2-7B language model. The left graph displays the To-Learn accuracy (plasticity), showing how well the models learn new knowledge. The right graph illustrates the Not-To-Forget accuracy (stability), indicating how well the models retain previously learned knowledge. The x-axis represents the training epoch, while the y-axis represents the accuracy.
read the caption
Figure 7: LAMA-CKL performance of large (Llama2-7B) baseline models. The graph on the left represents TO-LEARN task, and the graph on the right represents NOT-TO-FORGET task performance. The x-axis is the learning epoch, and the y-axis is accuracy.
🔼 This figure illustrates the difference between the standard causal language model training and the proposed Train-Attention method. (a) shows how a standard causal language model processes text by uniformly weighting all tokens regardless of their importance. This leads to inefficiencies and unnecessary parameter updates. (b) introduces the Train-Attention model, which dynamically predicts token importance and applies weights accordingly. This targeted approach improves learning efficiency and minimizes forgetting in continual knowledge learning (CKL).
read the caption
Figure 1: (a) Learning of Causal LM: The document is decomposed into multiple token sequences Sixi x
🔼 This figure shows the performance of different large language models on the LAMA-CKL benchmark. The left graph displays the accuracy of the models in learning new knowledge (TO-LEARN), while the right graph illustrates their ability to retain previously learned knowledge (NOT-TO-FORGET) over 30 epochs. It highlights the trade-off between learning new information and forgetting old information in continual knowledge learning.
read the caption
Figure 7: LAMA-CKL performance of large (Llama2-7B) baseline models. The graph on the left represents TO-LEARN task, and the graph on the right represents NOT-TO-FORGET task performance. The x-axis is the learning epoch, and the y-axis is accuracy.
🔼 This figure shows the performance of different large language models (LLMs) on the LAMA-CKL benchmark. The left graph displays the ‘To-Learn’ accuracy, measuring the model’s ability to learn new knowledge. The right graph shows the ‘Not-To-Forget’ accuracy, representing the model’s ability to retain previously learned knowledge. Both graphs plot accuracy against the number of training epochs.
read the caption
Figure 7: LAMA-CKL performance of large (Llama2-7B) baseline models. The graph on the left represents TO-LEARN task, and the graph on the right represents NOT-TO-FORGET task performance. The x-axis is the learning epoch, and the y-axis is accuracy.
🔼 This figure illustrates the difference between traditional causal language models and the proposed Train-Attention model. (a) shows how a standard causal language model processes text by uniformly weighting all tokens, which can lead to inefficiencies in continual knowledge learning. (b) introduces the Train-Attention model, which dynamically predicts and applies weights to tokens based on their importance, leading to more efficient knowledge updates and reduced forgetting.
read the caption
Figure 1: (a) Learning of Causal LM: The document is decomposed into multiple token sequences Sixi x
More on tables
🔼 This table presents the results of several continual knowledge learning (CKL) methods on the LAMA-CKL benchmark using the Llama2-7B language model. It compares the performance of different approaches including fine-tuning, K-Adapter, Mix-review, RecAdam, RHO-1, and the proposed TAALM method. The metrics used for comparison are Top Accuracy (Top Acc), the epoch at which Top Acc was achieved (Epoch), Not-To-Forget Accuracy (NF Acc), and Total Knowledge (sum of Top Acc and NF Acc). The table highlights the superior performance of TAALM in terms of both learning speed and overall knowledge retention.
read the caption
Table 1: LAMA-CKL performance of Llama2-7B based baselines. The evaluation indicator of each column is explained on §4.1. The best performance is marked as bold while the second best is underlined.
🔼 This table presents the performance of different baselines on the LAMA-CKL benchmark using the Llama2-7B language model. The metrics used to evaluate the performance are Top Accuracy (Top Acc), the epoch at which the top accuracy was achieved, Not-To-Forget Accuracy (NF Acc), and Total Knowledge (sum of Top Acc and NF Acc). The best performing model for each metric is highlighted in bold, and the second-best model is underlined.
read the caption
Table 1: LAMA-CKL performance of Llama2-7B based baselines. The evaluation indicator of each column is explained on §4.1. The best performance is marked as bold while the second best is underlined.

🔼 This table presents the results of several continual knowledge learning (CKL) baselines on the LAMA-CKL benchmark using the Llama2-7B language model. The metrics used to evaluate the performance are Top Accuracy (Top Acc), the epoch at which this top accuracy is reached (Epoch), Not-To-Forget Accuracy (NF Acc), and Total Knowledge (a sum of Top Acc and NF Acc). The table highlights the best performing model in bold and the second-best in italics, providing a comparison of various CKL approaches.
read the caption
Table 1: LAMA-CKL performance of Llama2-7B based baselines. The evaluation indicator of each column is explained on §4.1. The best performance is marked as bold while the second best is underlined.

🔼 This table presents the results of different continual knowledge learning (CKL) methods on the LAMA-CKL benchmark using the Llama2-7B language model. The metrics evaluated include Top Accuracy (the highest accuracy achieved during the 30 epochs of training), Epoch (the epoch at which the Top Accuracy was achieved), Not-To-Forget Accuracy (accuracy on the tasks not meant to be forgotten), and Total Knowledge (sum of Top and Not-To-Forget Accuracies). The table allows for comparison of the performance of various CKL methods, highlighting the best and second-best performers.
read the caption
Table 1: LAMA-CKL performance of Llama2-7B based baselines. The evaluation indicator of each column is explained on §4.1. The best performance is marked as bold while the second best is underlined.
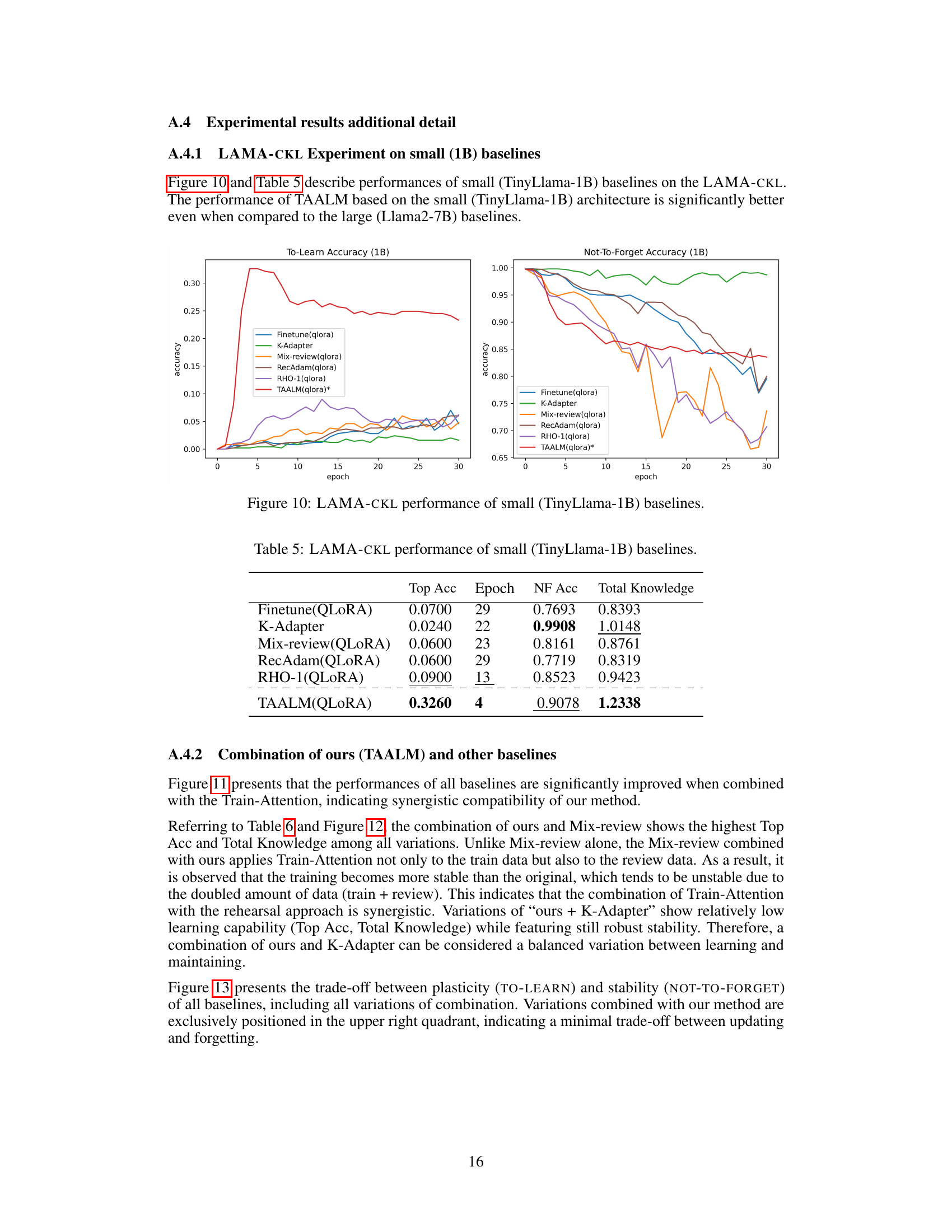
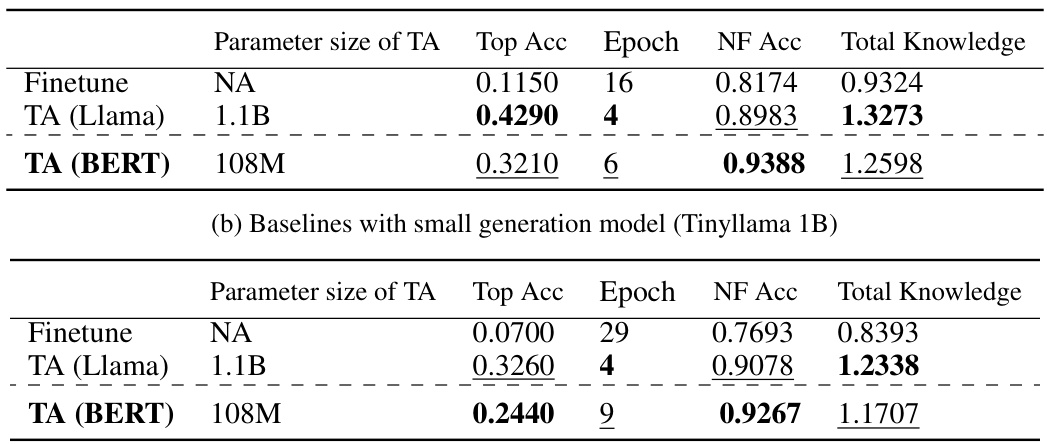
🔼 This table presents the results of the LAMA-CKL experiment using the smaller TinyLlama-1B language model. It shows the Top Accuracy (Top Acc) achieved by each method, the epoch at which this top accuracy was reached, the Not-To-Forget Accuracy (NF Acc), which measures the model’s ability to retain previously learned knowledge, and the Total Knowledge, which is the sum of Top Acc and NF Acc. This allows for comparison of different continual knowledge learning methods in terms of both learning new knowledge and retaining old knowledge when using a smaller model.
read the caption
Table 5: LAMA-CKL performance of small (TinyLlama-1B) baselines.
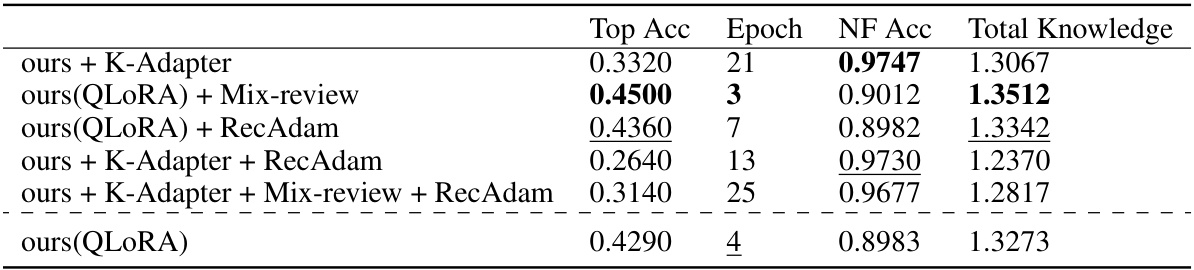
🔼 This table presents the results of experiments combining the proposed Train-Attention (TAALM) method with other continual knowledge learning (CKL) baselines on the LAMA-CKL benchmark. It shows the Top Accuracy (Top Acc), the epoch at which the top accuracy was achieved (Epoch), the Not-to-Forget Accuracy (NF Acc), and the total knowledge (sum of Top Acc and NF Acc) for each combination. The goal is to evaluate the synergistic effect of combining TAALM with existing CKL approaches and to determine if this improves performance on both learning new information (plasticity) and retaining old information (stability).
read the caption
Table 6: Combination of ours (TAALM) and other baselines. Based on Llama2-7B, tested on LAMA-CKL.
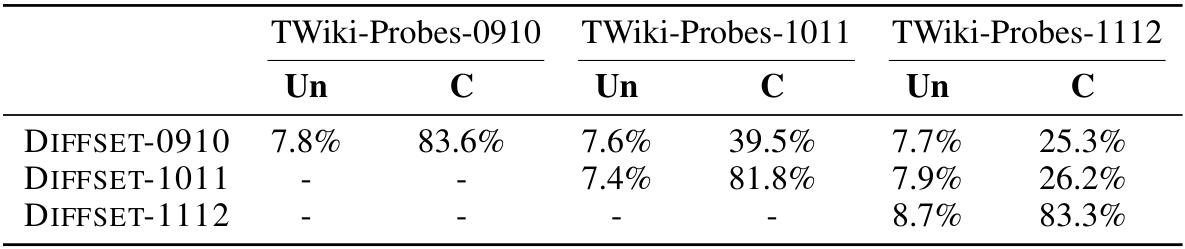
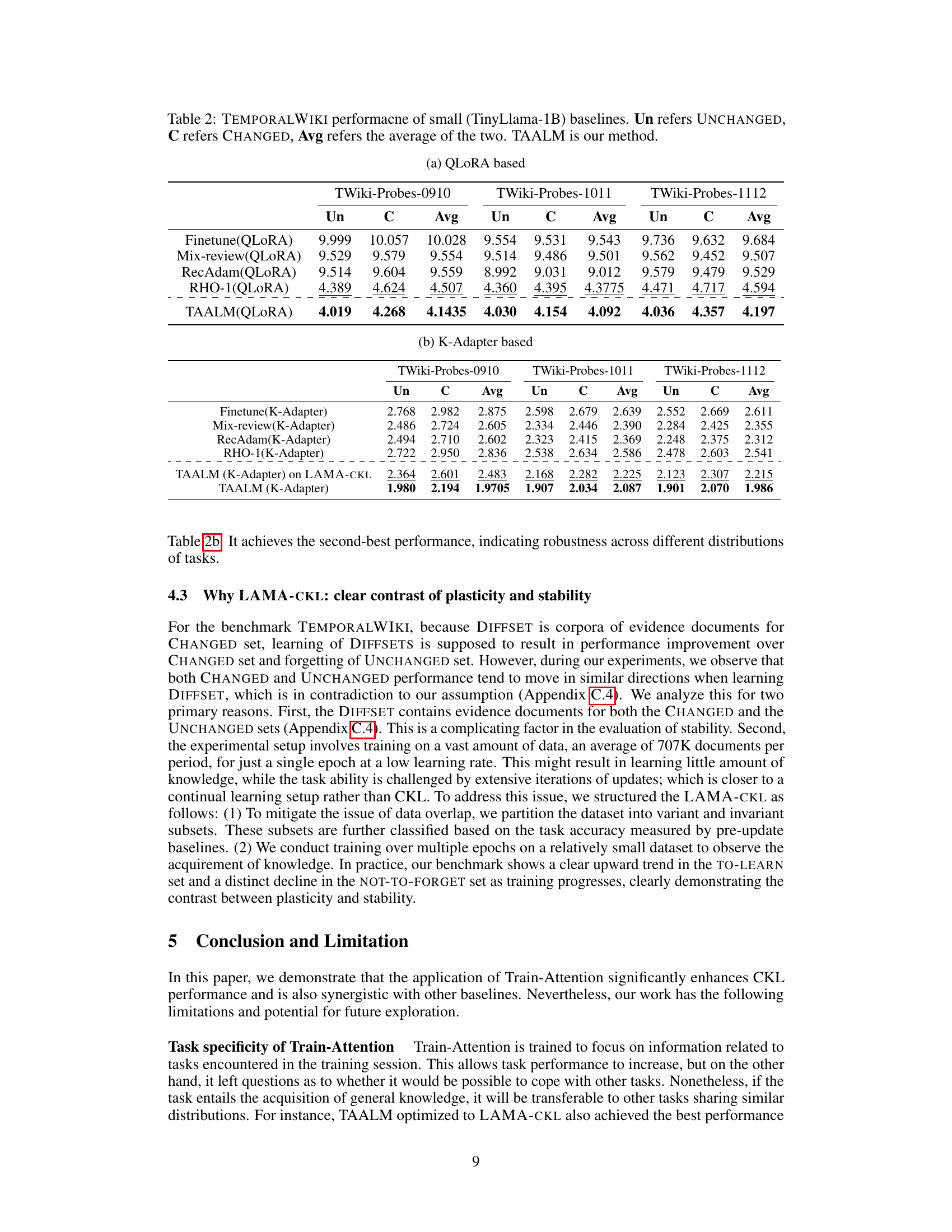
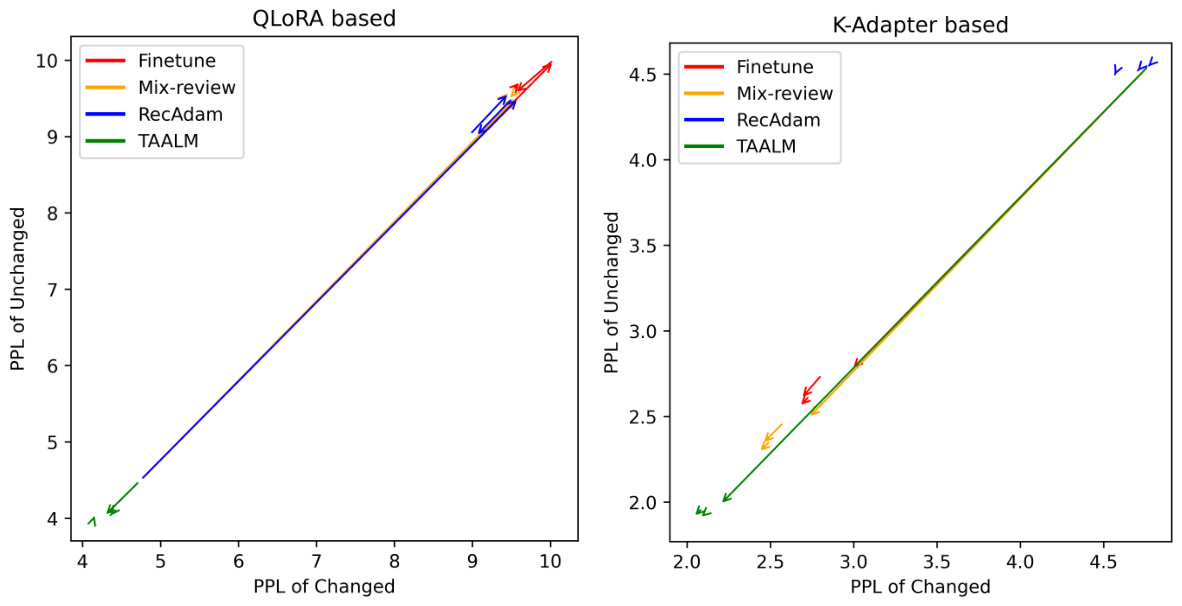
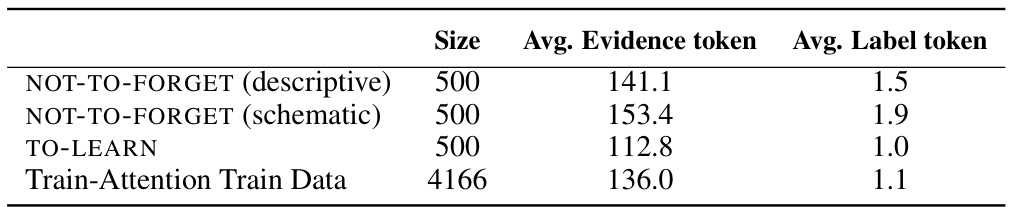
🔼 This table shows the performance of different continual knowledge learning (CKL) methods on the TEMPORALWIKI benchmark using a small language model (TinyLlama-1B). The benchmark consists of four periods (0809, 0910, 1011, 1112). For each period, the results are presented separately for unchanged (Un) and changed (C) knowledge. The average performance is also calculated. The table compares several baselines against the proposed TAALM method. The results are presented in terms of perplexity, demonstrating the ability of each method to retain previously learned knowledge while learning new knowledge.
read the caption
Table 2: TEMPORALWIKI performacne of small (TinyLlama-1B) baselines. Un refers UNCHANGED, C refers CHANGED, Avg refers the average of the two. TAALM is our method.
🔼 This table presents the results of the LAMA-CKL experiment using the Llama2-7B language model. It compares the performance of different continual knowledge learning (CKL) methods. The metrics used for comparison are Top Accuracy (Top Acc), the epoch at which the top accuracy was achieved (Epoch), Not-Forgotten Accuracy (NF Acc), and the total knowledge retained (Total Knowledge). The table highlights the best-performing method by bolding its results and the second-best by underlining them.
read the caption
Table 1: LAMA-CKL performance of Llama2-7B based baselines. The evaluation indicator of each column is explained on §4.1. The best performance is marked as bold while the second best is underlined.

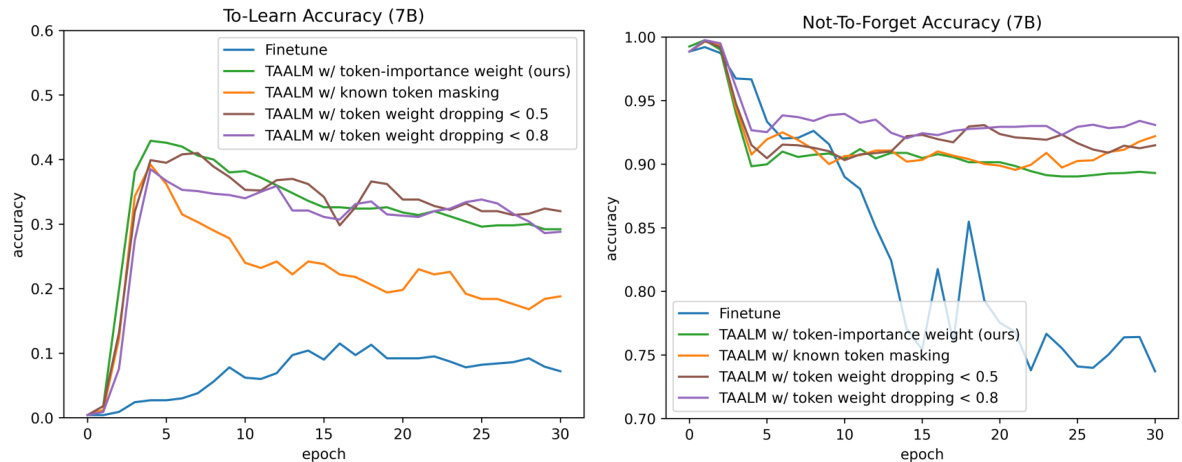
🔼 This table presents the results of the LAMA-CKL experiment using Llama2-7B baselines. It compares the performance of the proposed TAALM model with several variants (different token weighting strategies) against a standard finetune baseline. The metrics reported include Top Acc (the highest TO-LEARN accuracy), Epoch (the epoch where the Top Acc occurs), NF Acc (NOT-TO-FORGET accuracy), and Total Knowledge (sum of Top Acc and NF Acc), allowing for a comprehensive evaluation of the continual knowledge learning performance.
read the caption
Table 9: LAMA-CKL performance of Llama2-7B based baselines.
Full paper#