TL;DR#
Accurately predicting object motion in dynamic environments is crucial for computer vision applications like autonomous driving. Traditional methods struggle with complex scenes and subtle variations. Event cameras provide high temporal resolution data, offering an opportunity to improve motion prediction. However, integrating this data effectively with existing models is challenging.
This paper introduces E-Motion, a novel motion simulation framework that combines event-based data with the powerful learning capacity of video diffusion models. The method initially adapts pre-trained video diffusion models to event data, then incorporates a reinforcement learning mechanism for trajectory alignment. Experiments showed improved performance and accuracy in various scenarios, proving the potential for significant advancements in motion flow prediction and computer vision systems.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes a novel framework for future motion prediction by integrating event cameras’ high temporal resolution data with video diffusion models. This approach has the potential to significantly improve the accuracy and detail of motion prediction in various applications, such as autonomous driving and robotics. The release of source code also fosters reproducibility and encourages further research.
Visual Insights#

🔼 This figure shows a comparison of motion prediction using event cameras and traditional RGB cameras. The x-axis represents time, and the y-axis represents the state of motion. The blue line represents the ground truth motion, the brown dashed line shows the motion prediction from RGB data, and the dark blue dashed line shows the motion prediction from event data. The circles along the lines represent the sampling points in time. Event cameras capture motion with exceptional temporal granularity, which is highlighted by the figure, demonstrating the potential of event-based vision for accurate prediction of future motion.
read the caption
Figure 1: Illustration that the exceptional temporal resolution afforded by event cameras, alongside their distinctive event-driven sensing paradigm, presents a significant opportunity for advancing the precision in predicting future motion trajectories.
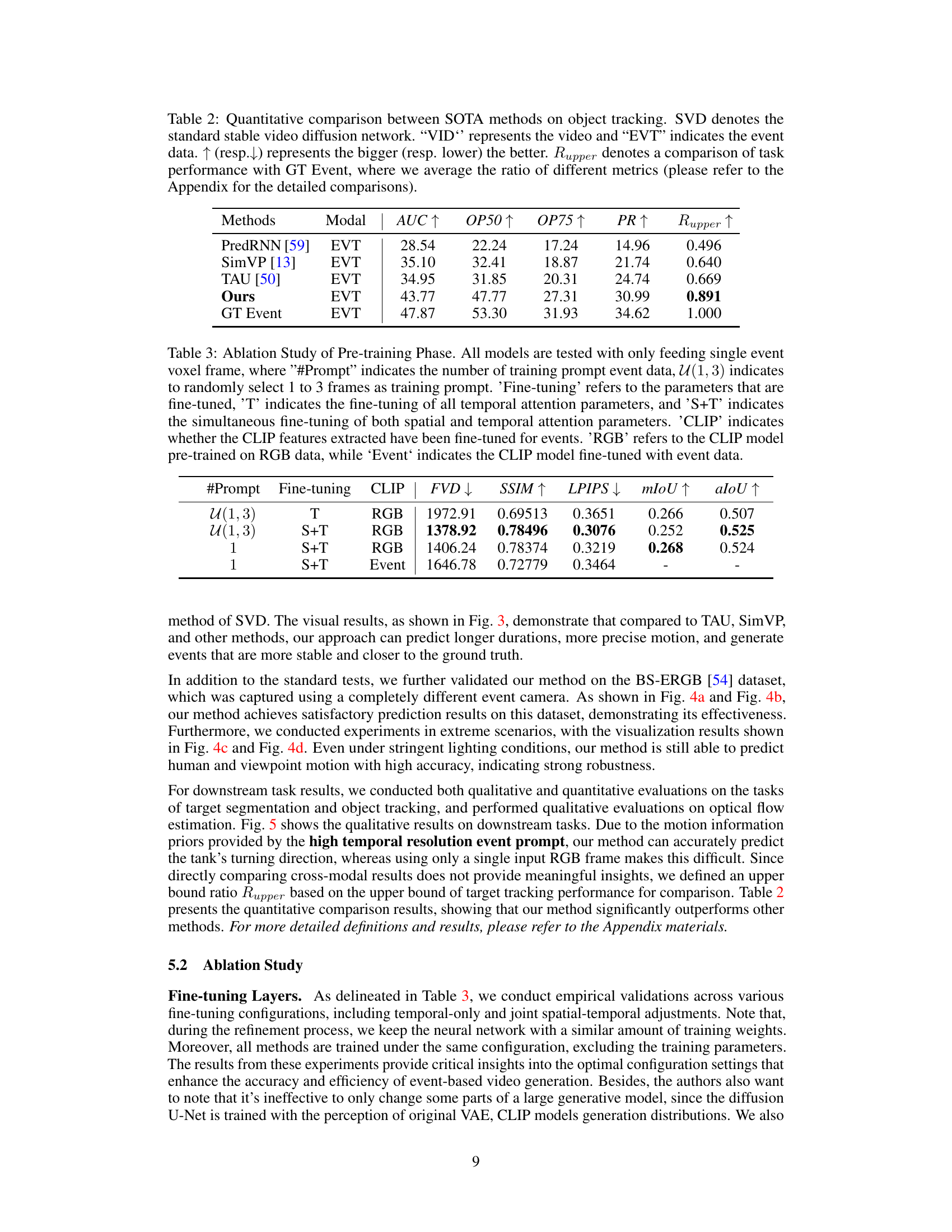
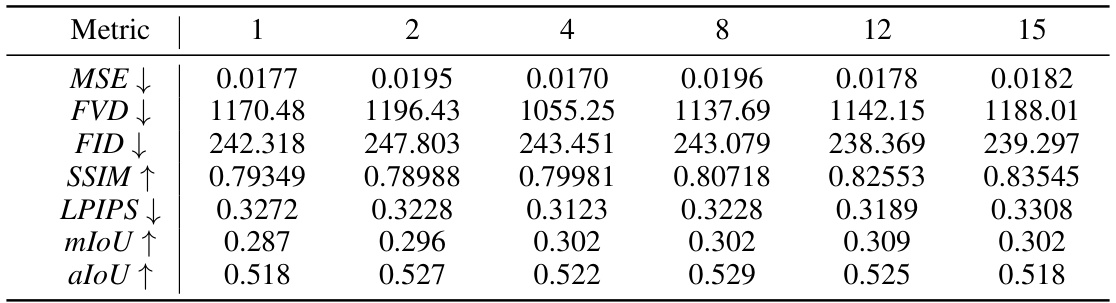
🔼 This table presents a quantitative comparison of the proposed method against state-of-the-art (SOTA) methods for video and event-based data. It compares several metrics including Fréchet Video Distance (FVD), Mean Squared Error (MSE), Structural Similarity Index Measure (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), mean Intersection over Union (mIoU), and average Intersection over Union (aIoU). Lower FVD, MSE, and LPIPS scores are better, while higher SSIM, mIoU, and aIoU scores are better. The table shows that the proposed method (‘Ours’) generally outperforms the other methods, particularly in the event-based scenario (‘EVT’).
read the caption
Table 1: Quantitative comparison between SOTA methods, where SVD denotes the standard stable video diffusion network. “VID” represents the video and “EVT” indicates the event data. ↑ (resp.↓) represents the bigger (resp. lower) the better.
In-depth insights#
Event Seq Diffusion#
The concept of ‘Event Seq Diffusion’ blends event-based vision with diffusion models for motion prediction. Event cameras offer high temporal resolution, capturing changes as events, rather than frames. This high-frequency data is ideal for diffusion models which excel at generating temporally coherent sequences. However, directly using raw event streams poses challenges, including sparse data and lack of inherent visual texture. The proposed approach likely addresses these by first pre-training the model on a combination of event and RGB data for knowledge transfer. This facilitates learning complex motion patterns from the richer RGB data while leveraging the temporal precision of events. Subsequently, an alignment mechanism (perhaps reinforcement learning-based) refines the reverse diffusion process, ensuring generated event sequences accurately reflect real-world motion. The effectiveness is likely demonstrated through quantitative metrics assessing prediction accuracy and qualitative visualizations showcasing predictions in various scenarios. The key innovation lies in fusing the strengths of event-based sensing with the generative power of diffusion models, pushing beyond traditional frame-based approaches to achieve more accurate and detailed motion prediction.
Motion Prior Learning#
Motion prior learning, in the context of video prediction using event cameras, focuses on leveraging the temporal dynamics inherent in event data to improve the accuracy and efficiency of diffusion models. The core idea is to pre-train a diffusion model on event sequences, allowing it to learn the temporal patterns and correlations present in event data, which captures motion with high temporal granularity. This pre-training process serves as a crucial step, creating a powerful motion prior that significantly influences the subsequent video generation. By using this prior knowledge, the model can more effectively predict future motion trajectories compared to using only image data or relying on general-purpose models. The key benefit is that event-based sensors can resolve motion events with much greater precision and temporal accuracy than frame-based cameras, making them particularly valuable for this task. Consequently, the diffusion model, enriched with this motion prior, generates video sequences that more accurately reflect the real-world dynamics of movement, particularly in challenging scenarios such as rapid motion or fluctuating illumination conditions.
Reinforcement Alignment#
The concept of “Reinforcement Alignment” in the context of a video diffusion model trained on event sequences suggests a sophisticated approach to refining the model’s generated outputs. The core idea is to leverage reinforcement learning to bridge the gap between the model’s internal representation of motion and the complexities of real-world dynamics. The model, pre-trained on event data, likely generates diverse samples due to the inherent stochasticity of diffusion processes. Reinforcement learning, through a reward mechanism, guides the model towards generating sequences that more accurately reflect real-world motion patterns. This implies a process where an agent interacts with the model’s output, evaluates it against ground truth data (or a suitable proxy), and provides a feedback signal (reward) shaping subsequent generations. Success in this approach hinges on the design of an effective reward function that captures nuanced aspects of motion fidelity. This might encompass temporal consistency, spatial accuracy, and adherence to physical constraints. Challenges could arise in balancing exploration and exploitation, preventing the agent from converging to suboptimal motion predictions, and ensuring efficient training despite the computational costs associated with video diffusion models.
Downstream Tasks#
The ‘Downstream Tasks’ section of a research paper is crucial for demonstrating the practical applicability and impact of the proposed method. It assesses the model’s performance on various downstream tasks, showcasing its generalization capabilities beyond its primary objective. A robust evaluation across diverse tasks provides strong evidence of the model’s potential impact. The choice of downstream tasks should align with the paper’s core contributions and reflect real-world scenarios. Careful selection and a detailed analysis are essential to strengthen the paper’s claims. Metrics employed for evaluating each downstream task must be appropriate and well-justified. The overall results should be clearly presented and discussed, highlighting both strengths and weaknesses. Finally, comparison with state-of-the-art techniques on similar tasks is needed to establish the advancement made by the proposed method. A comprehensive downstream task analysis enhances the credibility and significance of the research. If the proposed method only performs well in restricted settings, these limitations should be openly acknowledged and discussed.
Future Work#
The paper’s “Future Work” section suggests several promising avenues. Extending the model to handle more complex scenarios like those with significant occlusions, shaky camera motion, or rapidly changing lighting conditions is crucial. Improving the model’s ability to interpret texture and fine details within event data is key to enhancing accuracy and realism in prediction. The authors rightly highlight the need for a more comprehensive dataset encompassing a wider range of scenarios, object types, and lighting conditions to further validate and improve the model’s generalizability. Exploring data fusion techniques that integrate event data with other modalities such as RGB video or depth information could significantly enhance prediction performance and robustness. Finally, research into optimizing the model for real-time applications, possibly via hardware acceleration or model compression techniques, is vital for deployment in practical computer vision systems such as autonomous driving or robotics.
More visual insights#
More on figures
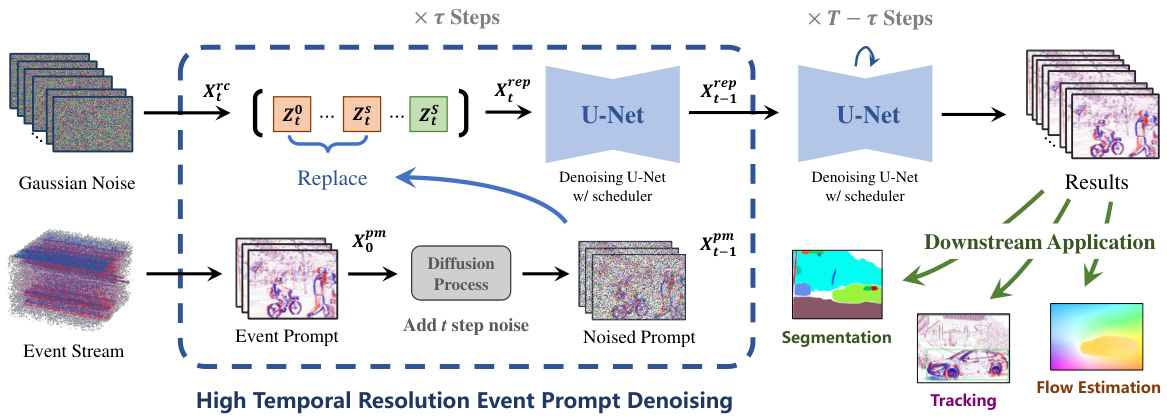
🔼 This figure illustrates the inference workflow of the proposed Event-Sequence Diffusion Network. It shows how the model processes an event sequence (high temporal resolution event prompt) and combines it with a pre-trained video diffusion model to predict future motion. The process involves adding Gaussian noise to the input, then using a U-Net to perform denoising steps, incorporating the event sequence information at a specific step (τ). The final output is a prediction of future motion, which can then be used for downstream tasks such as segmentation, flow estimation, and tracking.
read the caption
Figure 2: Inference workflow of the proposed method, where the left upper one indicates the random Gaussian noise, left lower one represents the prompted event sequence. We perform 7 steps forward diffusion processing on the event prompt and substitute a portion of the diffusion input noise, followed by T − τ Steps of conventional denoising.

🔼 This figure compares the proposed E-Motion method against state-of-the-art (SOTA) methods, SimVP and TAU, for future event estimation. Each column shows a different sequence. The top row displays the ground truth event sequence, while the second, third, and bottom rows show the results generated by SimVP, TAU, and the proposed E-Motion method, respectively. The figure highlights the qualitative differences in the accuracy and detail of future motion prediction across the three methods. A more complete set of sequences is available in Figure 9.
read the caption
Figure 3: Qualitative comparison between SOTA methods. The first row of each sequence represents the ground truth of the event sequence. The second and third rows respectively depict the results of future event estimation by SimVP [14] and TAU [50]. The final row represents the results obtained by our method. The complete sequence is shown in Fig.9.
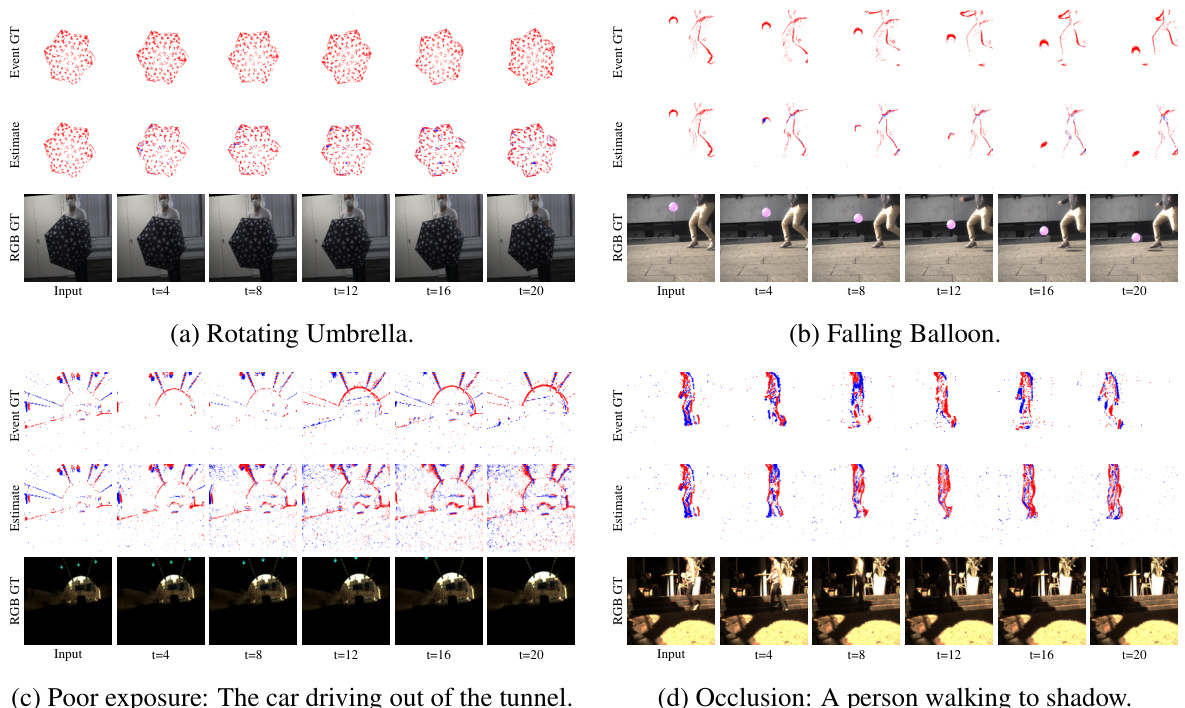
🔼 This figure visualizes the results of the proposed method’s motion prediction in four different scenarios: rotating umbrella, falling balloon, a car driving out of a tunnel (poor exposure), and a person walking into a shadow (occlusion). For each scenario, the ground truth, the model’s predictions, and the predictions of two other methods (SimVP and TAU) are shown. The visualization shows that the proposed method better handles scenarios with low lighting, occlusion, and complex motion.
read the caption
Figure 4: More visualization of our method's prediction in various scenarios. The results of the complete sequence along with other methods are presented in Fig. 12 and Fig. 13.

🔼 This figure compares the results of three downstream tasks (tracking, segmentation, and optical flow estimation) using ground truth event and RGB frames (a), estimated events from the proposed method (b), and estimated frames from a standard stable video diffusion model (c). Subfigure (a) provides the ceiling performance achievable with perfect input data. The other subfigures demonstrate how well the proposed method and the baseline model perform on these tasks using their respective estimations of event and video data, respectively.
read the caption
Figure 5: Visualization results on downstream tasks, where we show the tasks of tracking, segmentation, and flow estimation. (a) denotes the ceiling performance of settings (b) and (c).
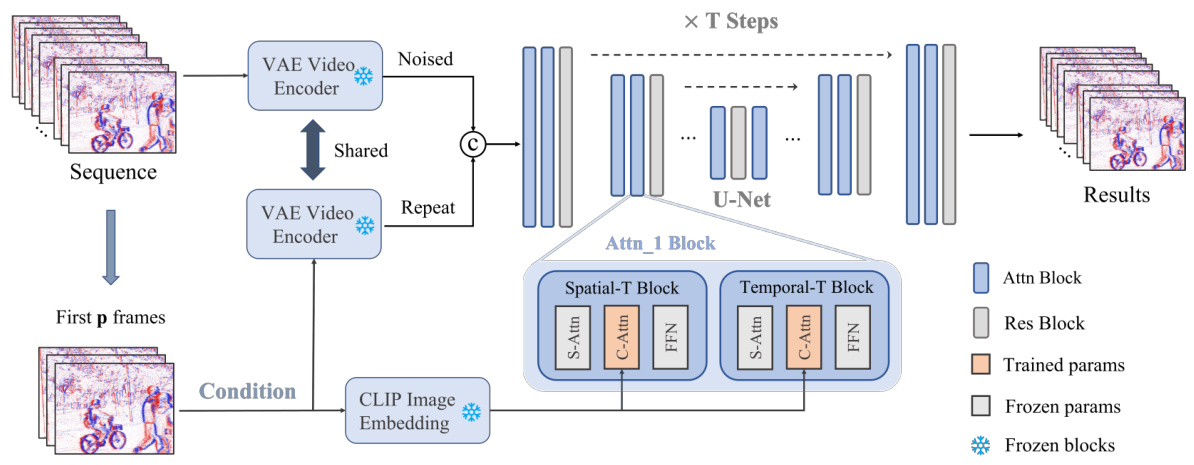
🔼 This figure illustrates the training workflow of the proposed Event-Sequence Diffusion Network. The process begins with a sequence of event data, which is preprocessed and used as a conditional input. This input is combined with noised latent data from the video diffusion model. The model’s U-Net architecture processes this combined input using a cross-attention mechanism, integrating the event information with the diffusion model’s learned knowledge. This architecture comprises both trained and frozen parameters. The CLIP image embeddings are also injected into the U-Net, improving the overall performance. The output is a sequence of generated events, reflecting the model’s learned capacity to simulate object motion from event data.
read the caption
Figure 6: Training workflow of the proposed method, where the left upper one indicates the target noised latent and the left lower one represents the prompted event sequence. We concatenate the prompt information with denoising latent for noise learning. Moreover, the feature from the CLIP model is also injected into the diffusion U-Net.

🔼 This figure shows the results of three downstream tasks (tracking, segmentation, and optical flow estimation) using events estimated by the proposed method and compares them to using ground truth events and events estimated by a standard stable video diffusion model. The top row shows the results using ground truth events and RGB frames as input, demonstrating the ceiling performance achievable with perfect event and frame information. The middle row displays the results using events generated by the proposed method, showcasing the method’s ability to effectively improve downstream tasks. The bottom row presents the results using a standard stable video diffusion model which serves as a baseline for comparison and highlights the improvement offered by the approach.
read the caption
Figure 5: Visualization results on downstream tasks, where we show the tasks of tracking, segmentation, and flow estimation. (a) denotes the ceiling performance of settings (b) and (c).

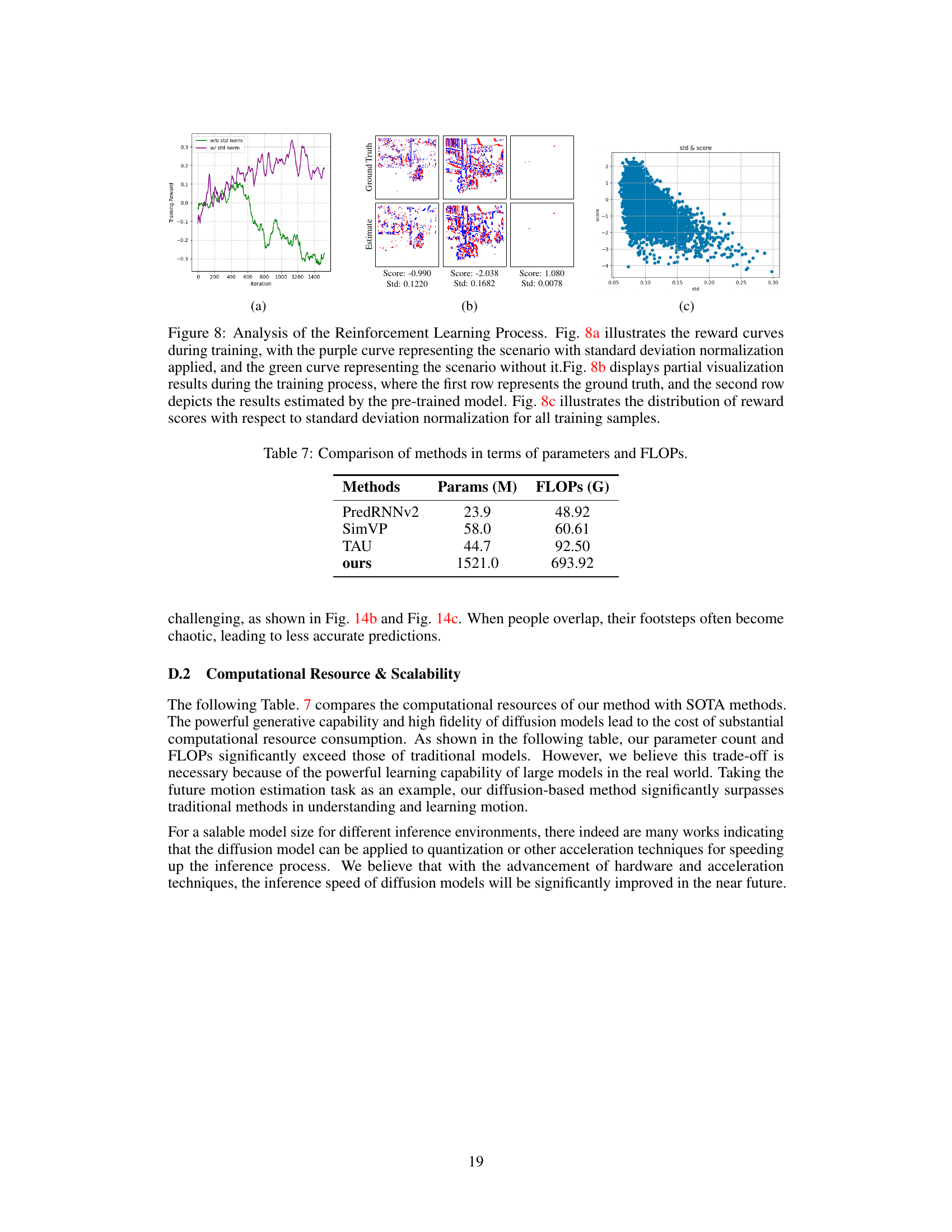
🔼 This figure analyzes the reinforcement learning process. It shows the reward curves with and without standard deviation normalization during training, partial visualization results comparing ground truth and pre-trained model estimations, and the distribution of reward scores against standard deviation. The standard deviation normalization is demonstrated to improve the training process and result quality.
read the caption
Figure 8: Analysis of the Reinforcement Learning Process. Fig. 8a illustrates the reward curves during training, with the purple curve representing the scenario with standard deviation normalization applied, and the green curve representing the scenario without it.Fig. 8b displays partial visualization results during the training process, where the first row represents the ground truth, and the second row depicts the results estimated by the pre-trained model. Fig. 8c illustrates the distribution of reward scores with respect to standard deviation normalization for all training samples.

🔼 This figure compares the performance of the proposed E-Motion method against two state-of-the-art (SOTA) methods, SimVP and TAU, for future event estimation. Each sequence shows the ground truth events alongside the predictions of SimVP, TAU and the proposed method. The figure demonstrates a qualitative comparison across different complex scenarios. The results show that the proposed method generally achieves a more accurate and realistic prediction of future events compared to the other two methods.
read the caption
Figure 9: Qualitative comparison between SOTA methods. The first row of each sequence represents the ground truth of the event sequence. The second and third rows respectively depict the results of future event estimation by SimVP [14] and TAU [50]. The final row represents the results obtained by our method.

🔼 This figure compares the results of future event estimation from three state-of-the-art (SOTA) methods (SimVP, TAU) and the proposed method. For each of three example scenarios, the ground truth event sequence is shown, along with the predictions from the three methods. This visualization allows for a qualitative comparison of the accuracy and robustness of each method in predicting future events.
read the caption
Figure 9: Qualitative comparison between SOTA methods. The first row of each sequence represents the ground truth of the event sequence. The second and third rows respectively depict the results of future event estimation by SimVP [14] and TAU [50]. The final row represents the results obtained by our method.
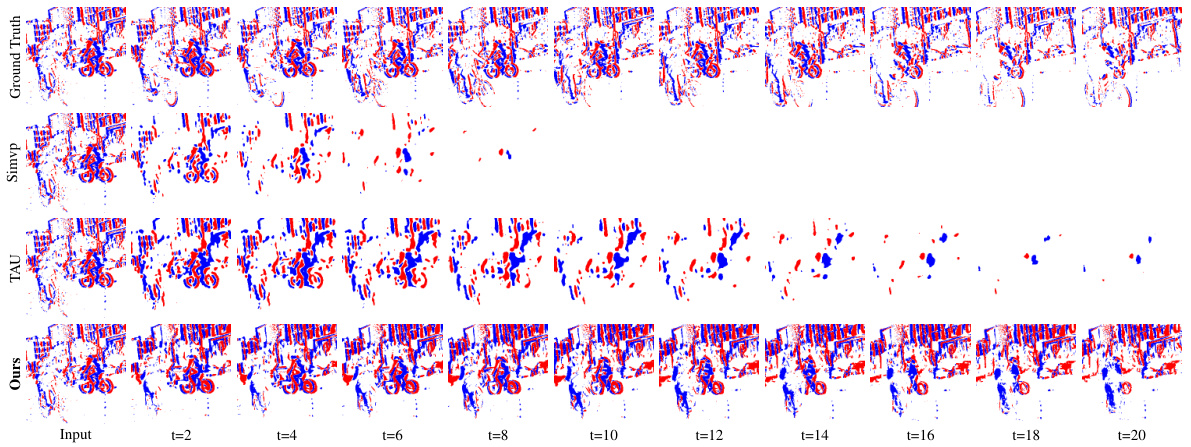
🔼 This figure compares the performance of the proposed E-Motion model against two state-of-the-art (SOTA) methods, SimVP and TAU, in predicting future events. The top row shows the ground truth event sequences for three different scenarios. Subsequent rows show the predictions made by SimVP, TAU and the proposed E-Motion model respectively for each scenario. This provides a visual comparison of the accuracy and detail in the prediction of future events by the different methods.
read the caption
Figure 9: Qualitative comparison between SOTA methods. The first row of each sequence represents the ground truth of the event sequence. The second and third rows respectively depict the results of future event estimation by SimVP [14] and TAU [50]. The final row represents the results obtained by our method.

🔼 This figure shows a qualitative comparison of segmentation results. The top row displays the ground truth segmentation for multiple sequences. The second row shows the segmentation results obtained using the proposed method. The third and fourth rows show the segmentation results using two state-of-the-art methods (TAU and SimVP), for comparison. The figure highlights the effectiveness of the proposed method in accurately segmenting objects in complex scenes, showcasing its superior performance compared to existing methods.
read the caption
Figure 10: Additional results of Segmentation. The first row of each sequence represents the ground truth of the events, and the second row shows the segmentation results. The last two rows respectively display the results estimated by our method and the corresponding segmentation results.

🔼 This figure compares the motion estimation results with and without motion alignment. The top row (11a) displays the ground truth. The middle row (11b) shows the results of a pre-trained model without motion alignment, revealing several instances of failure due to the inherent randomness of the model. The bottom row (11c) presents the results with motion alignment, highlighting the improved stability and accuracy achieved by applying reinforcement learning.
read the caption
Figure 11: Visualization results of Motion Alignment. Fig. 11a shows the ground truth of the car sequence; Fig. 11b presents the estimated results using a pre-trained model with 9 different random seeds, where several instances resulted in failures; Fig. 11c illustrates the motion alignment results generated by applying reinforcement learning, yielding more stable estimation.

🔼 This figure compares the results of motion estimation using a pre-trained model without and with motion alignment. The ground truth of a car sequence is displayed in (a). (b) Shows the results of the pre-trained model using 9 different random seeds, illustrating that the model sometimes fails. (c) Shows the results of the model after reinforcement learning motion alignment, indicating more stable results.
read the caption
Figure 11: Visualization results of Motion Alignment. Fig. 11a shows the ground truth of the car sequence; Fig. 11b presents the estimated results using a pre-trained model with 9 different random seeds, where several instances resulted in failures; Fig. 11c illustrates the motion alignment results generated by applying reinforcement learning, yielding more stable estimation.
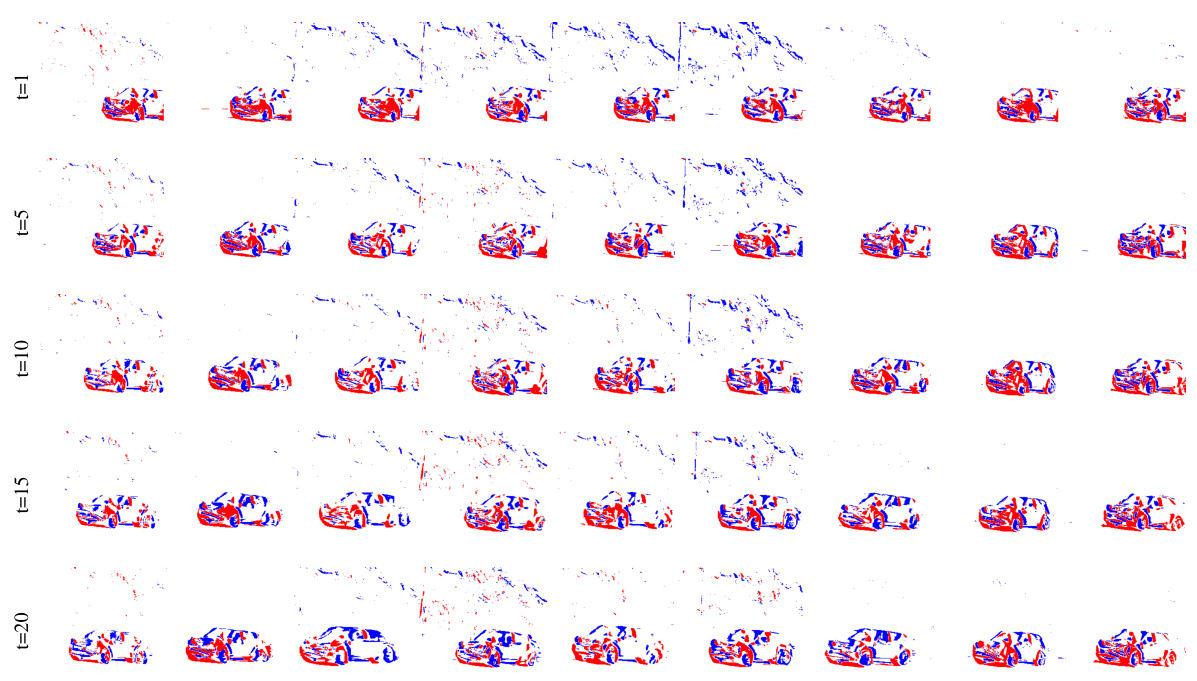
🔼 This figure compares the proposed method’s performance against two state-of-the-art methods (SimVP and TAU) for predicting future events. It visually shows the ground truth event sequence and the predictions made by each method at different time steps (t=2, t=10, t=20). The results demonstrate the superior performance of the proposed method compared to SimVP and TAU in predicting the future event sequences accurately.
read the caption
Figure 3: Qualitative comparison between SOTA methods. The first row of each sequence represents the ground truth of the event sequence. The second and third rows respectively depict the results of future event estimation by SimVP [14] and TAU [50]. The final row represents the results obtained by our method. The complete sequence is shown in Fig.9.

🔼 This figure shows a qualitative comparison of the proposed method’s performance on the hs-ergb dataset for two different scenarios: rotating umbrella and falling balloon. For each scenario, it displays the ground truth event sequence, the ground truth RGB sequence, predictions from SimVP and TAU methods, and finally the predictions generated by the proposed method. The visualizations allow for a comparison of the accuracy and detail in predicting future motion across the different methods.
read the caption
Figure 12: Visualization of our method’s prediction in hs-ergb dataset.
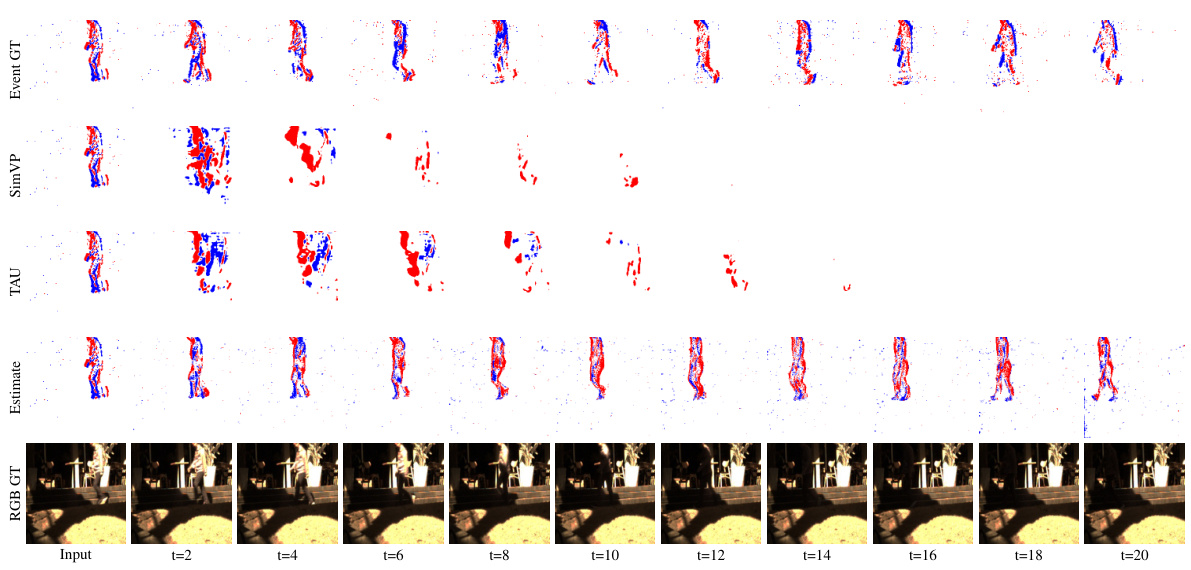
🔼 This figure compares the proposed E-Motion model’s performance against two state-of-the-art (SOTA) methods, SimVP and TAU, for future event estimation. The top row displays the ground truth event sequences for three different scenarios. Each subsequent row shows the predictions made by SimVP, TAU, and the proposed E-Motion model, respectively. The visualization allows for a qualitative assessment of the models’ accuracy in predicting future object motion based on event sequences.
read the caption
Figure 9: Qualitative comparison between SOTA methods. The first row of each sequence represents the ground truth of the event sequence. The second and third rows respectively depict the results of future event estimation by SimVP [14] and TAU [50]. The final row represents the results obtained by our method.
🔼 This figure shows a qualitative comparison of the proposed method’s performance against two state-of-the-art (SOTA) methods, SimVP and TAU, in predicting future events. Each column displays a sequence of events; the top row is the ground truth. The middle two rows show the results from SimVP and TAU, respectively. The bottom row displays the predictions produced by the proposed method. The figure demonstrates the relative accuracy and fidelity of the different approaches in simulating future object motion using event data.
read the caption
Figure 9: Qualitative comparison between SOTA methods. The first row of each sequence represents the ground truth of the event sequence. The second and third rows respectively depict the results of future event estimation by SimVP [14] and TAU [50]. The final row represents the results obtained by our method.

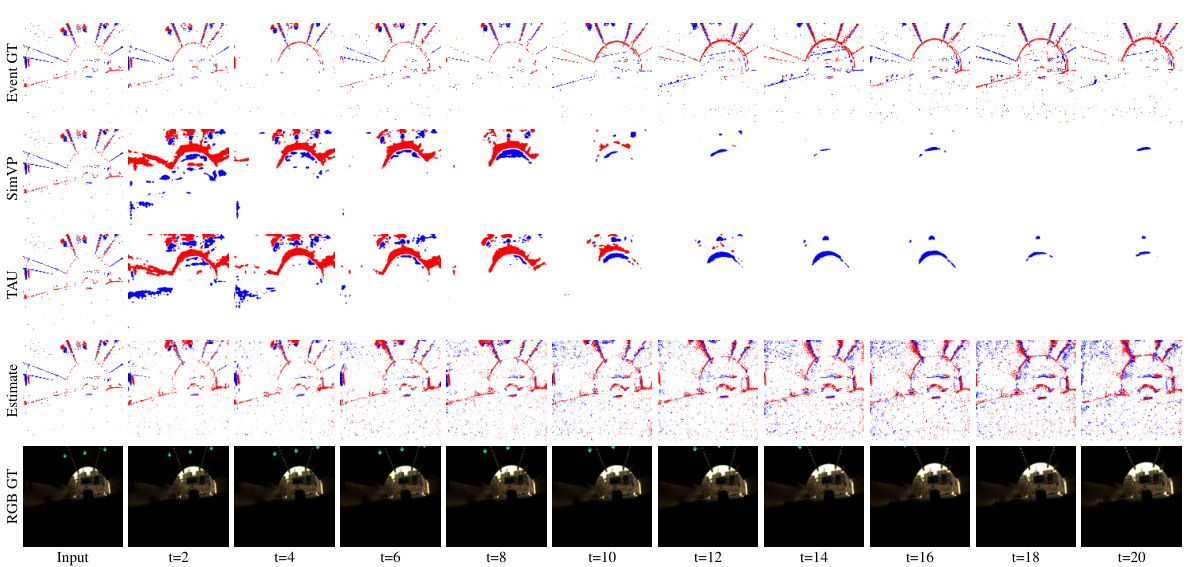
🔼 This figure shows a qualitative comparison of the proposed E-Motion method against state-of-the-art (SOTA) methods, SimVP and TAU, for future event estimation. The top row displays the ground truth event sequences for three different scenarios (a bicycle approaching an obstacle, a car moving left with a rotating camera, and two bicycles intersecting). Subsequent rows illustrate the predictions generated by SimVP, TAU, and the proposed E-Motion method for each scenario. This allows for a visual assessment of the relative performance of each model in predicting future events, with a focus on accuracy and capturing the subtleties of motion.
read the caption
Figure 9: Qualitative comparison between SOTA methods. The first row of each sequence represents the ground truth of the event sequence. The second and third rows respectively depict the results of future event estimation by SimVP [14] and TAU [50]. The final row represents the results obtained by our method.

🔼 The figure illustrates how event cameras’ high temporal resolution and event-driven sensing offer advantages for predicting future motion compared to traditional RGB cameras. It shows a comparison of the temporal sampling and prediction capabilities of event cameras versus RGB cameras, highlighting the superior temporal granularity of event data. This granularity allows for more precise motion prediction. The figure shows ground truth motion alongside predicted motion from both event data and RGB camera data.
read the caption
Figure 1: Illustration that the exceptional temporal resolution afforded by event cameras, alongside their distinctive event-driven sensing paradigm, presents a significant opportunity for advancing the precision in predicting future motion trajectories.
More on tables
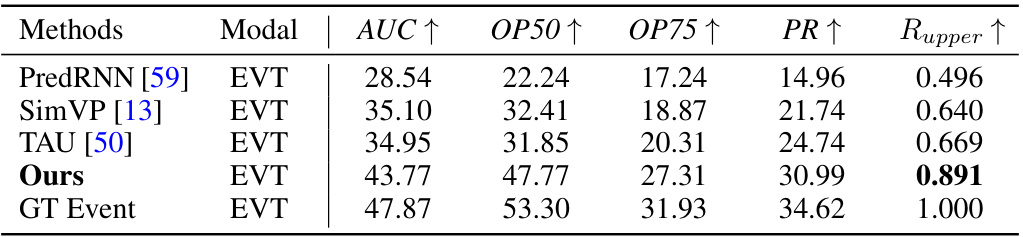
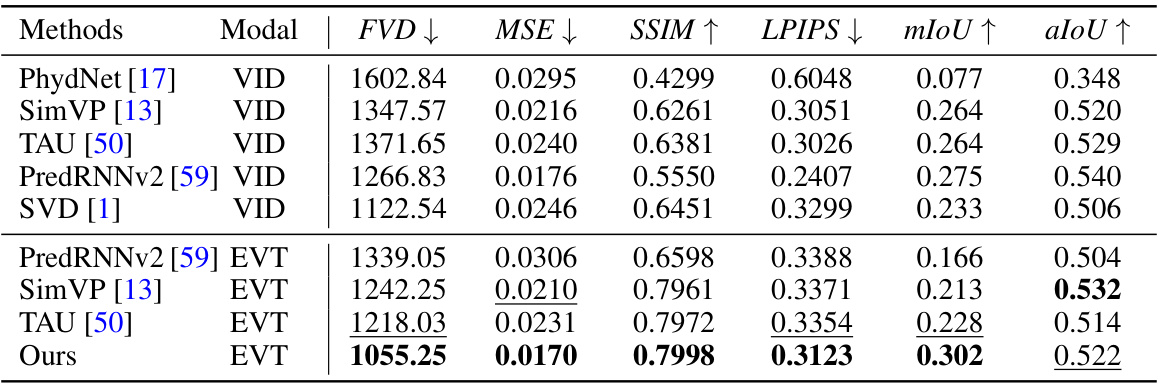
🔼 This table presents a quantitative comparison of the proposed method against other state-of-the-art (SOTA) methods for video and event data. It shows the performance of each method in terms of FVD (Fréchet Video Distance), MSE (Mean Squared Error), SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity), mIoU (mean Intersection over Union), and aIoU (average Intersection over Union). Lower values are better for FVD, MSE, and LPIPS, while higher values are better for SSIM, mIoU, and aIoU.
read the caption
Table 1: Quantitative comparison between SOTA methods, where SVD denotes the standard stable video diffusion network. “VID” represents the video and “EVT” indicates the event data. ↑ (resp. ↓) represents the bigger (resp. lower) the better.

🔼 This table presents the results of an ablation study on the pre-training phase of the proposed Event-Sequence Diffusion Network. It shows how different configurations (number of training prompts, fine-tuning of temporal and/or spatial attention parameters, and whether CLIP features were fine-tuned for events or not) impact the model’s performance as measured by FVD, SSIM, LPIPS, mIoU, and aIoU. The results highlight the optimal configuration for achieving the best model performance.
read the caption
Table 3: Ablation Study of Pre-training Phase. All models are tested with only feeding single event voxel frame, where '#Prompt' indicates the number of training prompt event data, U(1, 3) indicates to randomly select 1 to 3 frames as training prompt. 'Fine-tuning' refers to the parameters that are fine-tuned, 'T' indicates the fine-tuning of all temporal attention parameters, and 'S+T' indicates the simultaneous fine-tuning of both spatial and temporal attention parameters. 'CLIP' indicates whether the CLIP features extracted have been fine-tuned for events. 'RGB' refers to the CLIP model pre-trained on RGB data, while 'Event' indicates the CLIP model fine-tuned with event data.

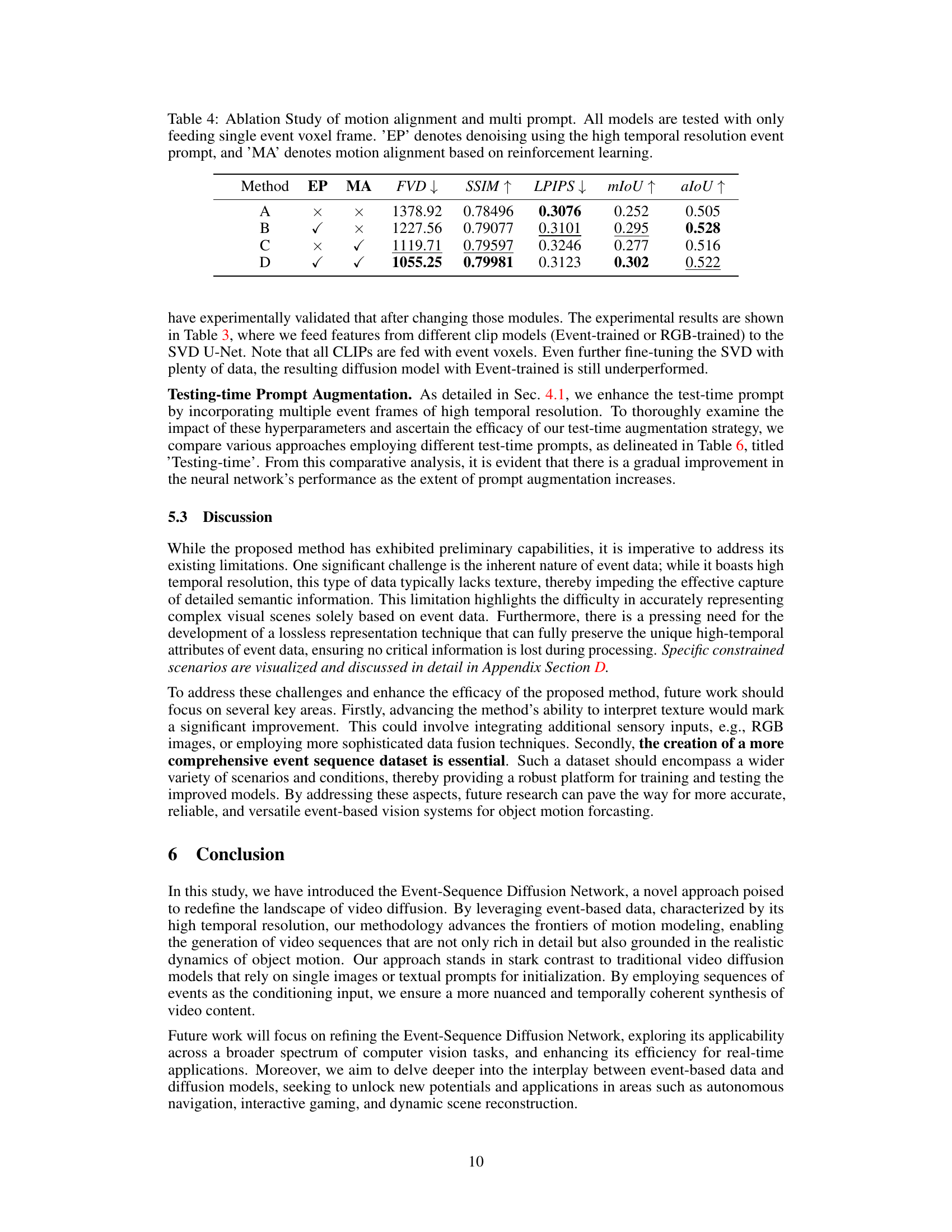
🔼 This table presents the ablation study results of the proposed method. It compares the performance of the model with and without motion alignment (MA) and high temporal resolution event prompt (EP). Each row represents a different configuration, and the columns show the FVD, SSIM, LPIPS, mIoU, and aIoU metrics. The results demonstrate the individual and combined effects of MA and EP on the model’s performance.
read the caption
Table 4: Ablation Study of motion alignment and multi prompt. All models are tested with only feeding single event voxel frame. ‘EP’ denotes denoising using the high temporal resolution event prompt, and ‘MA’ denotes motion alignment based on reinforcement learning.

🔼 This table presents a quantitative comparison of the proposed method against several state-of-the-art (SOTA) methods for video and event data. It compares the methods across various metrics, including Fréchet Video Distance (FVD), Mean Squared Error (MSE), Structural Similarity Index Measure (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), mean Intersection over Union (mIoU), and average Intersection over Union (aIoU). The table helps to illustrate the performance gains achieved by the proposed method, particularly when using event data as input.
read the caption
Table 1: Quantitative comparison between SOTA methods, where SVD denotes the standard stable video diffusion network. “VID” represents the video and “EVT” indicates the event data. ↑ (resp.↓) represents the bigger (resp. lower) the better.
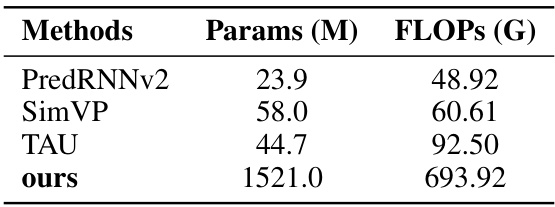
🔼 This table compares the performance of the proposed Event-Sequence Diffusion Network with several state-of-the-art (SOTA) methods for video and event data. The metrics used for comparison include Fréchet Video Distance (FVD), Mean Squared Error (MSE), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), mean Intersection over Union (mIoU), and average Intersection over Union (aIoU). Lower values are better for FVD, MSE, and LPIPS, while higher values are better for SSIM, mIoU, and aIoU. The table shows that the proposed method outperforms SOTA methods, particularly in event data.
read the caption
Table 1: Quantitative comparison between SOTA methods, where SVD denotes the standard stable video diffusion network. “VID” represents the video and “EVT” indicates the event data. ↑ (resp.↓) represents the bigger (resp. lower) the better.
🔼 This table presents a quantitative comparison of the proposed method against state-of-the-art (SOTA) methods for video and event-based motion prediction. It compares various metrics, including Fréchet Video Distance (FVD), Mean Squared Error (MSE), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), mean Intersection over Union (mIoU), and average Intersection over Union (aIoU). The results are shown for both video (VID) and event-based (EVT) data. Lower values are better for FVD, MSE, and LPIPS; higher values are better for SSIM, mIoU, and aIoU.
read the caption
Table 1: Quantitative comparison between SOTA methods, where SVD denotes the standard stable video diffusion network. “VID” represents the video and “EVT” indicates the event data. ↑ (resp.↓) represents the bigger (resp. lower) the better.
Full paper#