↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current action detection struggles with real-time, open-vocabulary scenarios due to reliance on manual annotations and offline processing. Existing methods are limited by their closed-set evaluation and inability to handle novel actions without retraining. This necessitates a new approach.
The researchers introduce OV-OAD, a zero-shot online action detector that uses vision-language models and text supervision to learn from video-text pairs. OV-OAD’s object-centered decoder aggregates semantically similar frames, leading to robust performance on multiple benchmarks. This innovative approach surpasses existing zero-shot methods, showing great promise for scalable, real-time action understanding in open-world settings.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the limitations of existing action detection methods by introducing OV-OAD, a novel zero-shot online action detector. Its success in open-vocabulary online action detection using only text supervision opens new avenues for real-time video understanding in various applications, particularly in open-world scenarios where manual annotation is expensive and time-consuming. This work also establishes a strong baseline for future research on zero-shot transfer in online action detection.
Visual Insights#

This figure compares the closed-set online action detection and open-vocabulary online action detection methods. The left side shows a traditional approach where the model is trained on a limited set of actions and struggles to recognize novel actions. In contrast, the right side showcases the proposed OV-OAD model, which leverages vision-language models and text supervision to detect novel actions in real-time without relying on frame-level labels.
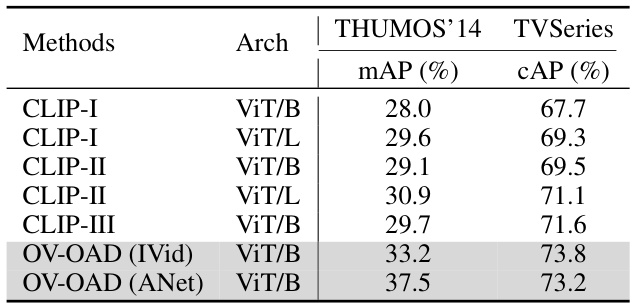
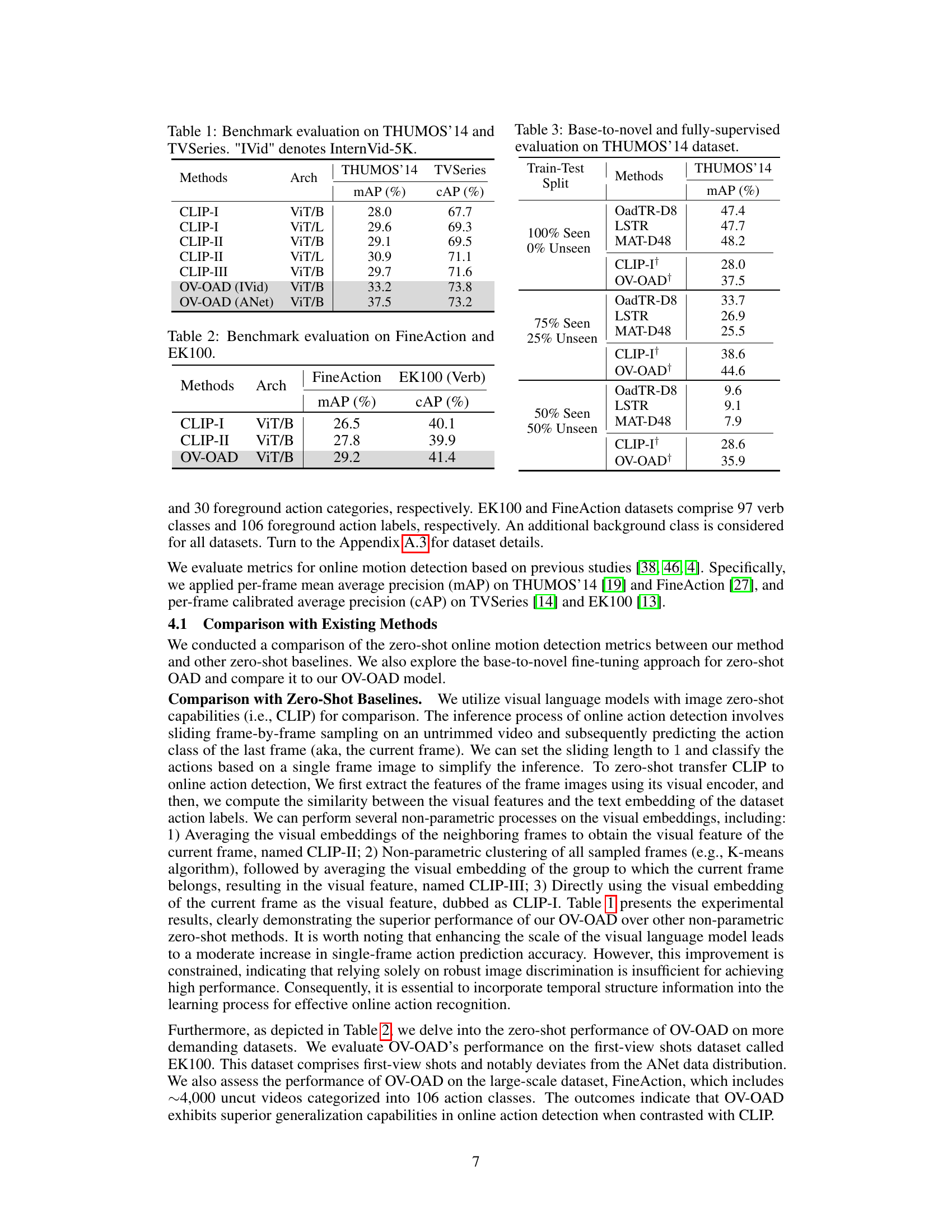
This table presents the benchmark evaluation results of different methods on two datasets: THUMOS'14 and TVSeries. The methods compared include various versions of CLIP and the proposed OV-OAD model, using both InternVid-5K and ANet for pre-training. The evaluation metrics are mean average precision (mAP) for THUMOS'14 and calibrated average precision (cAP) for TVSeries. The results show that OV-OAD significantly outperforms the baseline CLIP methods.
In-depth insights#
Zero-Shot OAD#
Zero-shot open-vocabulary online action detection (Zero-Shot OAD) presents a significant challenge in computer vision, demanding the ability to detect actions not seen during training. This necessitates models that generalize well and leverage prior knowledge effectively. A promising approach involves using pre-trained vision-language models (VLMs), transferring knowledge learned from vast text-image datasets to the task of online action detection, without relying on any frame-level action labels. This bypasses the expensive and time-consuming process of manual annotation. The core idea is to exploit the semantic understanding of VLMs to map video frames to action descriptions. A successful Zero-Shot OAD system would require robust video encoding methods that capture temporal dynamics, effective mechanisms to handle the open-vocabulary nature of action classes, and careful consideration of online detection constraints (i.e., limited access to future frames). Furthermore, evaluating and benchmarking Zero-Shot OAD models presents its own challenges, needing to establish robust evaluation metrics that measure generalization capabilities rather than just performance on seen classes. The potential societal impact of a robust Zero-Shot OAD system is considerable, with applications in video surveillance, autonomous systems, and more, but careful consideration of ethical implications and potential biases is crucial.
VLM Transfer#
Vision-Language Models (VLMs) offer a powerful mechanism for transferring knowledge between modalities. In the context of video understanding, VLM transfer involves leveraging pre-trained VLMs to enhance video analysis tasks, such as action detection, without the need for extensive manual annotation of video data. This is particularly advantageous for open-vocabulary scenarios, where the system needs to recognize actions not seen during training. Effective VLM transfer relies on careful consideration of the architecture, including how the visual and textual features are integrated and how the model is adapted to the specific video task. The success of VLM transfer also hinges on the quality and scale of the pre-training data, with larger, more diverse datasets typically leading to improved performance. Challenges remain in handling the noisy nature of web-scale video-text data and ensuring robust generalization to unseen action classes. Further research will likely focus on refining transfer techniques to optimize performance while minimizing computational costs.
Online Detection#
Online detection systems, unlike their offline counterparts, process data sequentially, making real-time predictions crucial. This constraint necessitates efficient algorithms and architectures that can make predictions without relying on future data. A core challenge lies in handling the inherent uncertainty and variability in online streams. Effective online detectors must be robust to noise, missing data, and concept drift, adapting dynamically to changing patterns. Furthermore, the ability to detect novel or unseen events in an open vocabulary setting is a significant requirement. This necessitates models that can generalize well beyond the training data and handle unexpected inputs. Existing methods often address closed-set scenarios, where the set of detectable events is predefined. Developing open-vocabulary online detection approaches is key to broader applications, but the need for real-time performance adds considerable complexity.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would ideally present a comprehensive evaluation of the proposed method against existing state-of-the-art techniques. This would involve selecting appropriate benchmark datasets, relevant metrics, and a clear presentation of the results. Key aspects to include would be a comparison of performance across different datasets to assess generalizability, highlighting any strengths and weaknesses of the proposed method under varying conditions. The selection of metrics should be justified and tailored to the specific task. Error bars or confidence intervals should be included to demonstrate the statistical significance of the results. Furthermore, an in-depth analysis comparing the performance against various baselines would illuminate the contributions of the novel approach and guide future research directions. Discussion of potential limitations and reasons for any performance gaps is crucial for a comprehensive analysis. Finally, a well-structured table or figure effectively summarizing the quantitative findings would enhance readability and aid comprehension. Presenting results this way allows for easier cross-comparison, allowing readers to easily understand the contribution of the paper.
Future of OV-OAD#
The future of OV-OAD hinges on addressing its current limitations, particularly its reliance on pre-trained visual encoders which may not fully capture temporal dynamics. Integrating more sophisticated temporal modeling techniques, such as those employing recurrent networks or advanced transformer architectures, could significantly boost performance. Furthermore, exploring alternative data sources beyond web-scraped video-text pairs is crucial to improve robustness and reduce biases inherent in such data. This might involve utilizing more carefully curated datasets or leveraging synthetic data for training. Addressing noisy and inconsistent web captions remains a challenge; incorporating advanced natural language processing methods for caption cleaning and standardization would be highly beneficial. Finally, while OV-OAD’s zero-shot capability is impressive, exploring few-shot or fine-tuning scenarios could significantly improve accuracy on specific action detection tasks. Investigating the effectiveness of domain adaptation techniques in transferring knowledge learned from one video domain to another would further enhance its generalizability. Future research should focus on these improvements, enhancing OV-OAD’s ability to handle unseen actions and complex real-world scenarios more effectively.
More visual insights#
More on figures

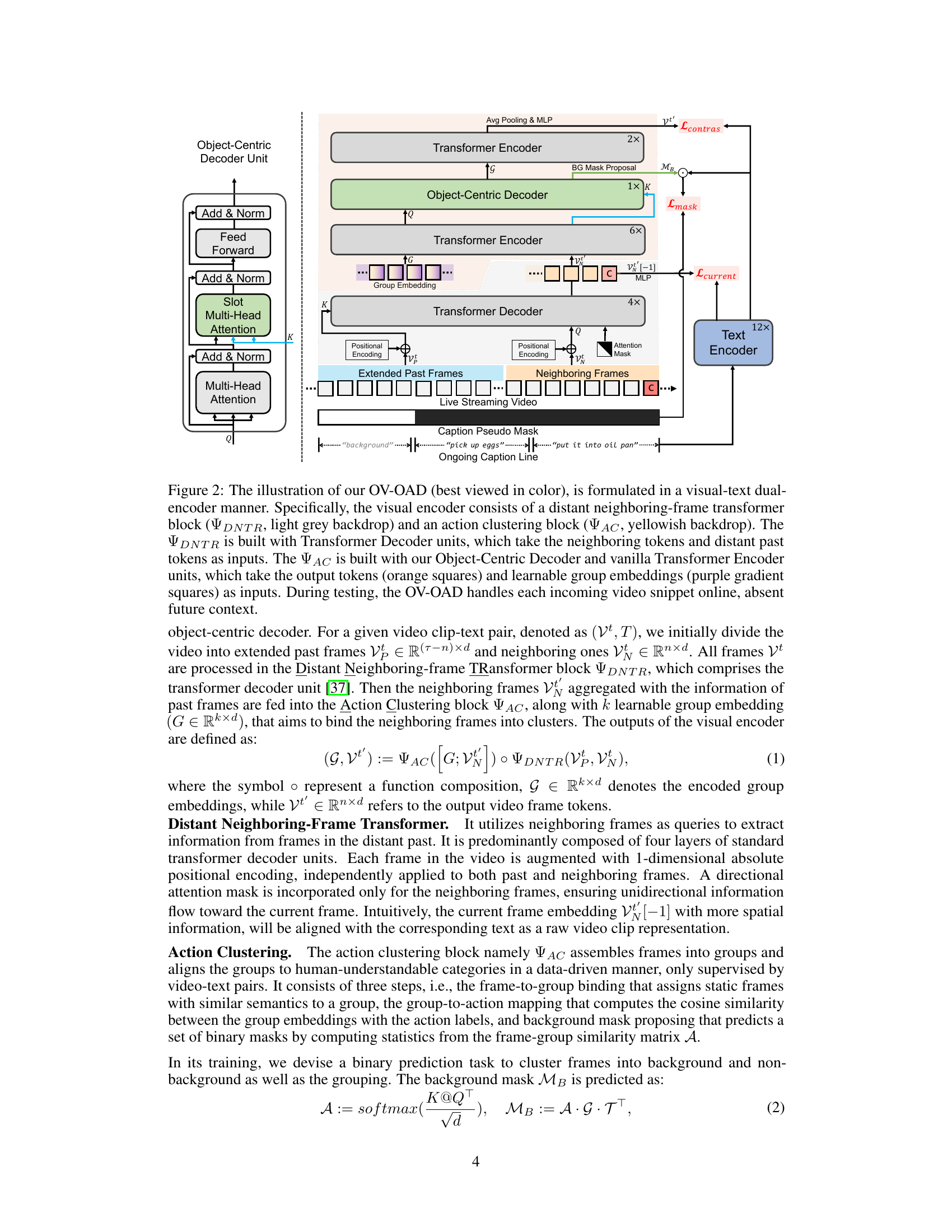
This figure illustrates the architecture of the proposed Open-Vocabulary Online Action Detection (OV-OAD) model. The model uses a dual-encoder approach, with separate visual and text encoders. The visual encoder processes video frames, using a distant neighboring-frame transformer to leverage information from both neighboring and past frames and an object-centric decoder to group similar frames. The text encoder processes captions. The model is trained using three proxy tasks: video-text alignment, current frame-text matching, and background frame mask prediction to improve zero-shot performance on unseen actions. The diagram visually represents the flow of information and the various components, highlighting key elements like attention mechanisms and group embeddings.

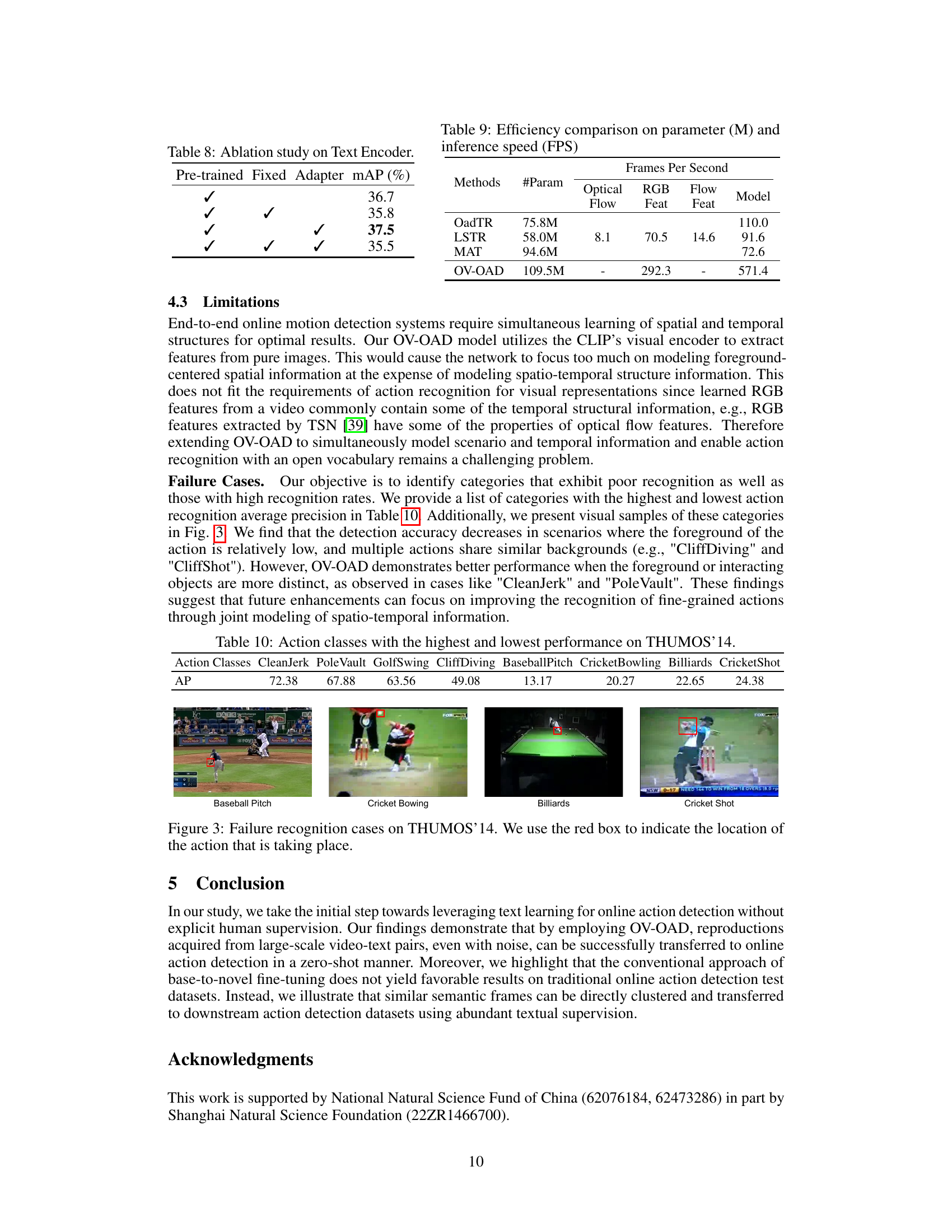
This figure shows four examples of failure cases from the THUMOS'14 dataset where the model’s action recognition performance was poor. The red boxes highlight the locations of the actions that the model failed to correctly identify. These failures are likely due to challenges such as subtle actions, similar backgrounds, and cluttered scenes. The examples illustrate limitations in distinguishing between similar actions that are visually close, particularly when the foreground and background are indistinct. This highlights the need for further model improvements, potentially incorporating a more robust representation of spatio-temporal information.
More on tables
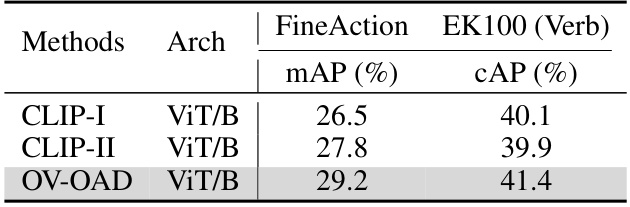
This table presents the benchmark evaluation results of the proposed OV-OAD model and the baseline CLIP model on two action detection datasets: FineAction and EK100. The results show the mean average precision (mAP) and calibrated average precision (cAP) for both models on each dataset, allowing for a comparison of their performance on different scales and complexities of action data.

This table presents the results of experiments conducted on the THUMOS’14 dataset to evaluate the performance of various methods, including base-to-novel and fully supervised approaches. It compares the mean average precision (mAP) achieved by different models under three train-test split scenarios: 100% seen (0% unseen), 75% seen (25% unseen), and 50% seen (50% unseen). The table highlights how the OV-OAD model performs comparatively to other existing methods under these different data conditions.
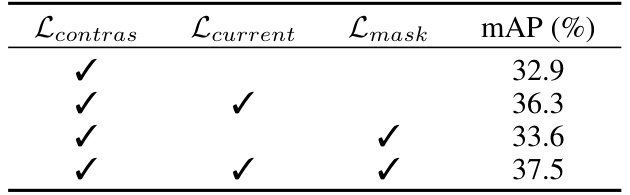
This table presents the ablation study results on the three proxy tasks used in the OV-OAD model: multi-label video-text contrastive loss (Lcontras), current frame-text contrastive loss (Lcurrent), and background mask loss (Lmask). The table shows the mean average precision (mAP) achieved with different combinations of these loss functions, demonstrating the contribution of each component to the overall performance.

This table presents the results of experiments conducted to determine the optimal number of Transformer units for both the Action Clustering block (AC) and the Distant Neighboring-frame Transformer block (DNTR) within the OV-OAD model. The table shows how different configurations of layers impacted the model’s performance, measured by mean Average Precision (mAP). The results indicate an optimal configuration leading to the highest mAP.
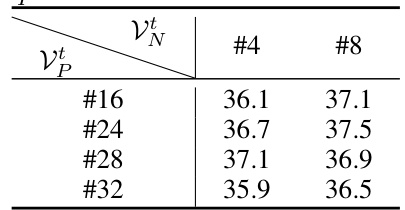
This table presents the results of experiments conducted to determine the optimal number of frame tokens to use for both neighboring frames (V) and past frames (Vp) in the OV-OAD model. Different numbers of tokens were tested (‘4’, ‘8’, ‘16’, ‘24’, ‘28’, ‘32’), and the resulting mean average precision (mAP) values are shown in the table. The goal was to find the balance between incorporating enough contextual information from previous and neighboring frames while maintaining computational efficiency.
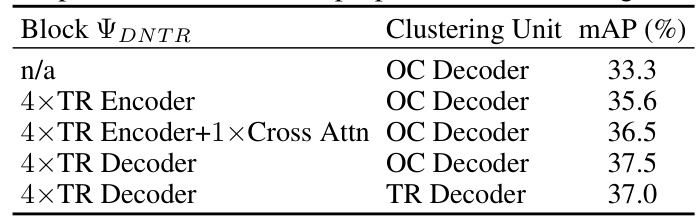
This table presents the ablation study on the design of the Distant Neighboring-Frame Transformer (DNTR) block within the OV-OAD model. It compares different architectures for the DNTR block, including using Transformer encoders and decoders, with and without cross-attention mechanisms. The results show the mean average precision (mAP) achieved by each architecture, demonstrating the effectiveness of the chosen design of 4xTR Decoder with an Object-Centric Decoder.
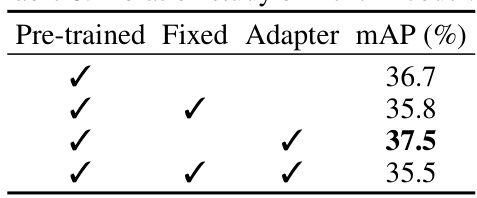
This table presents the ablation study on the Text Encoder, showing the performance (mAP) with different configurations: pre-trained weights used or not, fixed weights or fine-tuned, and adapter used or not. The results indicate that using pre-trained weights with an adapter yields the best performance.

This table compares the model parameters and inference speed (frames per second) of four different online action detection models: OadTR, LSTR, MAT, and OV-OAD. The comparison is broken down into the number of parameters (in millions), the speed of optical flow computation, the speed of RGB feature extraction, the speed of flow feature extraction, and the overall model inference speed. OV-OAD shows significantly faster inference speed compared to the others, demonstrating its efficiency for real-time applications.

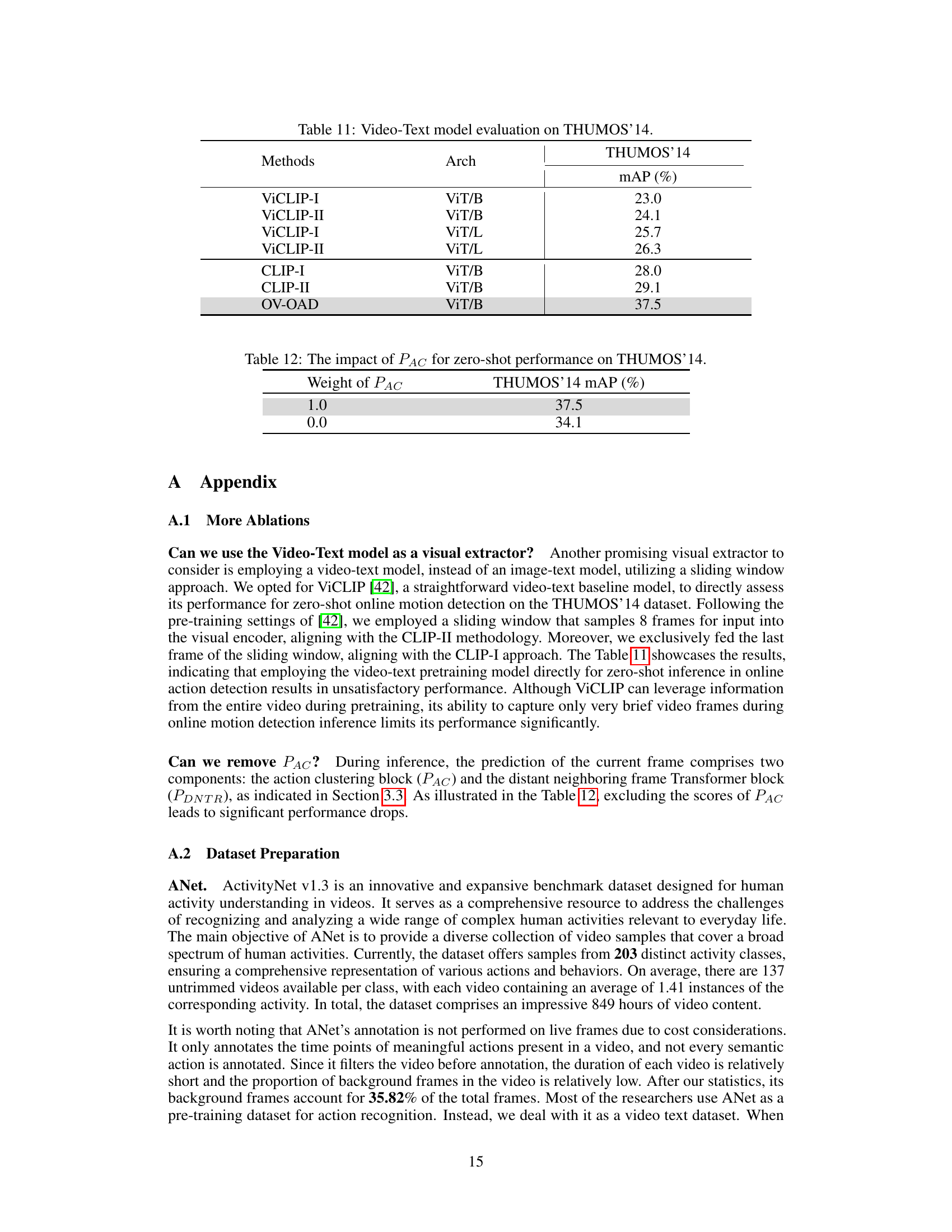
This table presents the benchmark results of various video-text models on the THUMOS’14 dataset. The models tested include ViCLIP (with both ViT/B and ViT/L architectures) and CLIP (also with ViT/B). The table compares the mean average precision (mAP) achieved by each model, demonstrating the superior performance of the proposed OV-OAD model compared to existing video-text models.

This table shows the impact of the Action Clustering block’s output (PAC) on the zero-shot performance of the OV-OAD model on the THUMOS'14 dataset. The results demonstrate that including PAC significantly improves performance compared to excluding it.
Full paper#