↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Recommender systems struggle to accurately model diverse and dynamic user interests. Existing single-point and multi-point representations have limitations in accuracy, diversity, and adaptability. The single-point approach is simple but inaccurate, while the multi-point approach needs manual tuning and doesn’t model uncertainty well. These limitations hinder effective personalized recommendations, especially for users with varied interests.
This research introduces GPR4DUR, which uses Gaussian Process Regression to generate density-based user representations (DURs). DURs effectively capture user interest variability without manual tuning, are uncertainty-aware, and scale well to large user bases. Experiments show GPR4DUR’s superior adaptability and efficiency compared to existing models, demonstrating its ability to handle exploration-exploitation trade-offs in online settings via simulated user tests. The results strongly suggest that DURs provide an effective solution for multi-interest recommendation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in recommender systems. It introduces a novel density-based user representation using Gaussian Process Regression, addressing limitations of existing single-point and multi-point models. The uncertainty-aware approach and adaptability to diverse user interests are highly significant, opening new avenues in multi-interest retrieval and online exploration-exploitation. The proposed method’s superior performance on real-world datasets highlights its practical value and theoretical contributions.
Visual Insights#
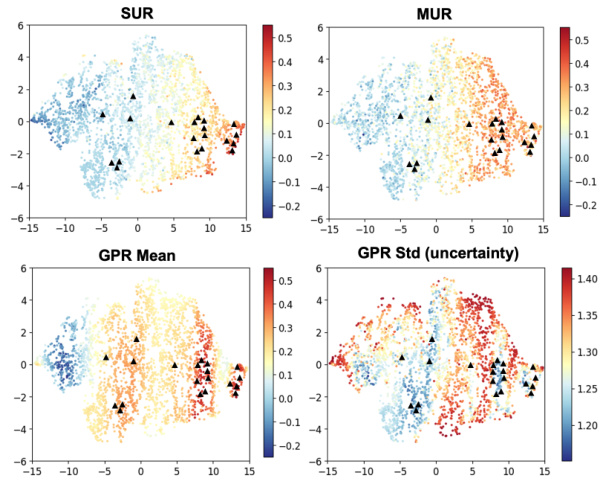
This figure visualizes the prediction scores of a user’s interaction with all items in the MovieLens dataset using t-SNE for dimensionality reduction. The scores are calculated as the inner product of the user’s and item’s embeddings. The triangles show the user’s most recent 20 interactions. The figure compares three user representation methods: SUR, MUR, and the proposed GPR-based DUR. It highlights the ability of the GPR-based DUR to capture multiple user interests and model uncertainty.

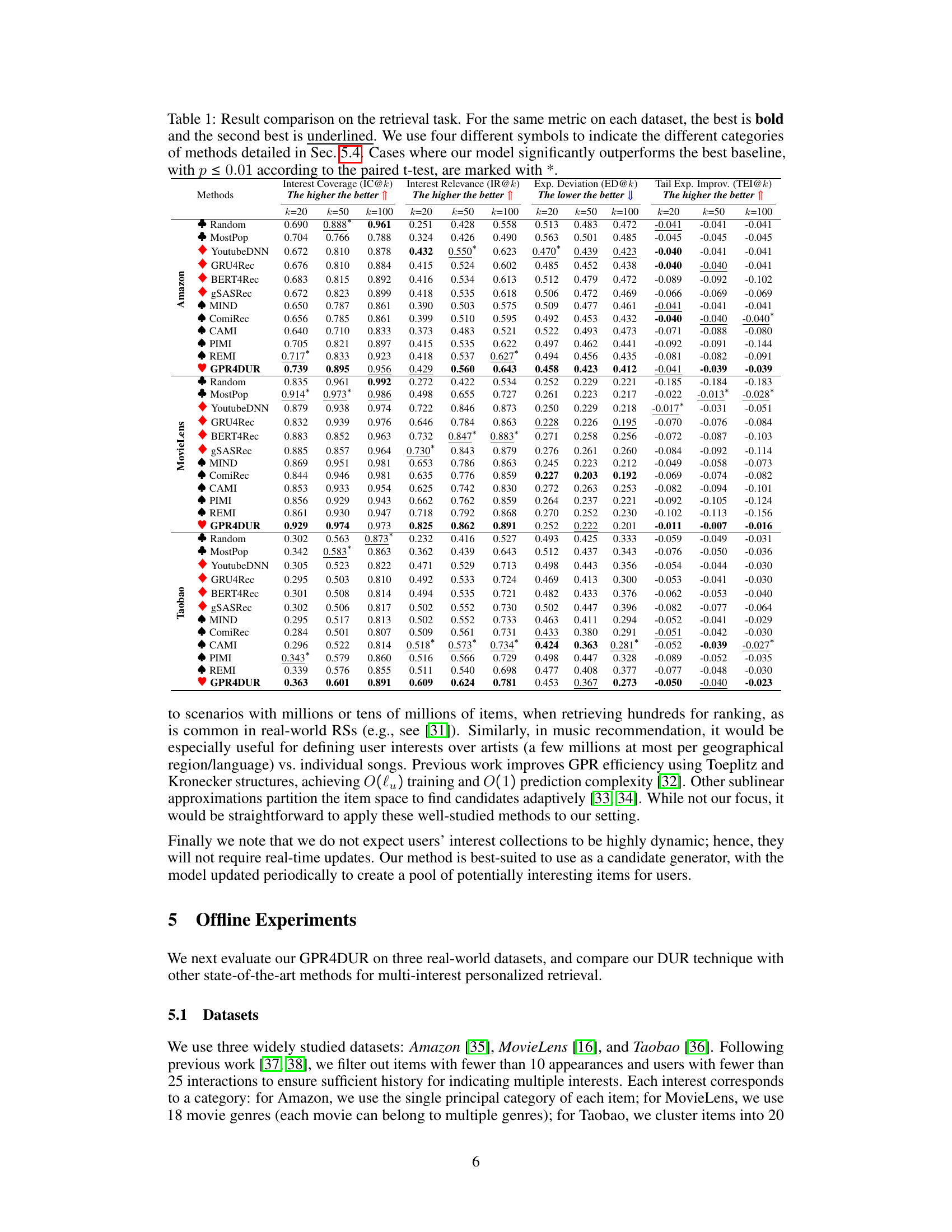
This table presents the performance comparison of different recommendation models on three datasets (Amazon, MovieLens, and Taobao) using four metrics: Interest Coverage, Interest Relevance, Exposure Deviation, and Tail Exposure Improvement. Each metric is evaluated at three different k values (20, 50, 100), showing the effectiveness of each model in retrieving items that satisfy a user’s multiple interests. The best performing model for each metric and dataset is highlighted in bold. The results are statistically significant (p≤0.01) for cases where GPR4DUR outperforms the best baseline.
In-depth insights#
Gaussian Process User Modeling#
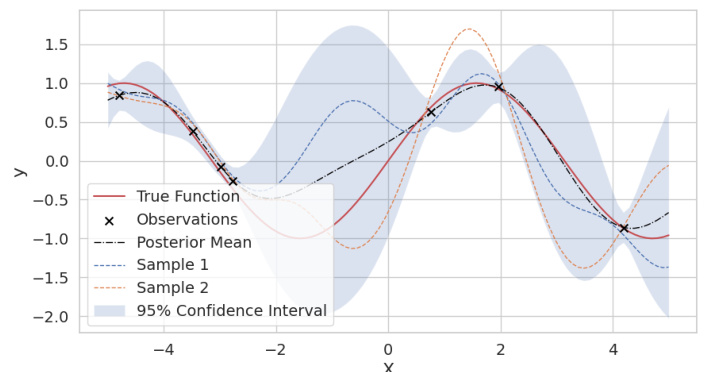
Gaussian Process (GP) user modeling offers a novel approach to capturing user preferences in recommender systems. Unlike traditional methods that rely on single or multi-point representations, GP modeling leverages the power of Bayesian non-parametric regression. This allows for a more flexible and adaptive representation of user interests, naturally accommodating the dynamic and diverse nature of user preferences. By modeling the user-item interaction as a Gaussian process, the approach can explicitly capture uncertainty associated with user preferences. This uncertainty information can be effectively used for exploration-exploitation trade-off in online recommendation scenarios, promoting the discovery of niche interests and less-known items. Adaptability is another key advantage; the model automatically adapts to varying numbers of interests per user, eliminating the need for manual tuning and parameter selection. Overall, GP user modeling promises a more accurate, flexible, and robust approach to personalized recommendation, addressing some limitations of existing single-point and multi-point representation methods.
Multi-Interest Retrieval#
Multi-interest retrieval tackles the challenge of representing and retrieving items relevant to a user’s multiple, potentially evolving interests. Traditional single-interest models often fail to capture the nuanced and dynamic nature of user preferences, resulting in suboptimal recommendations. Effective multi-interest retrieval requires sophisticated user modeling techniques that can accurately identify and weigh multiple interests, handling cases where interests may be conflicting, latent, or context-dependent. Retrieval strategies must also address the computational complexity involved in searching a vast item space based on multiple criteria, often utilizing efficient indexing and scoring methods. A successful approach to multi-interest retrieval needs to balance the exploration-exploitation trade-off, ensuring that the system both satisfies a user’s known preferences and discovers potentially interesting new items aligned with less-known or niche interests. Incorporating uncertainty estimation in user models can significantly benefit online exploration strategies, allowing for a principled approach to balance satisfying current interests with exploring new ones.
Density-Based User Rep.#
Density-based user representation offers a novel approach to user modeling in recommender systems, moving beyond the limitations of traditional single-point and multi-point methods. Instead of representing users as single points or a collection of points in an embedding space, it leverages a density function to capture the distribution of a user’s interests. This approach offers several advantages: it naturally adapts to varying numbers of interests per user without manual tuning, it directly models interest variability, and it incorporates uncertainty in the representation, enabling principled exploration-exploitation strategies. The use of Gaussian process regression (GPR) to learn this density function is particularly appealing, providing not only estimates of user preferences but also associated uncertainty estimates. This uncertainty awareness is crucial for effective online recommendation, allowing the system to balance exploration of new items with exploitation of already known preferences. The density-based representation’s scalability to large user populations and its ability to handle diverse interest profiles make it a promising technique for future advancements in personalized retrieval.
Exploration-Exploitation#
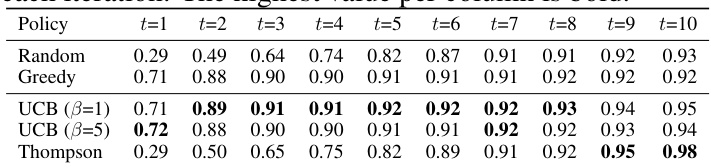
In reinforcement learning and online settings, the exploration-exploitation dilemma is crucial. Balancing exploration (discovering new information about the environment) and exploitation (leveraging current knowledge to maximize rewards) is key to optimal performance. A purely exploitative strategy might miss better opportunities while a purely exploratory one risks low cumulative rewards. The paper’s approach to this problem, using Gaussian Process Regression (GPR) with its uncertainty quantification, is particularly interesting. The GPR4DUR model’s ability to capture uncertainty around user interests provides a natural mechanism for balancing exploration and exploitation. High uncertainty regions represent areas where the model is unsure about user preferences, guiding exploration to those regions. Conversely, low uncertainty areas suggest high confidence, promoting exploitation. The use of bandit algorithms like UCB and Thompson sampling further enhances this process by leveraging model uncertainty to guide the decision-making of which items to recommend to users. This framework allows the system to efficiently learn user preferences while minimizing risks associated with an overly exploratory or exploitative strategy. This adaptive, uncertainty-aware approach is a significant contribution to multi-interest recommendation systems, allowing for more efficient and robust exploration of the interest space.
Offline & Online Eval.#
A robust evaluation methodology for a recommender system necessitates both offline and online evaluations. Offline evaluations, typically using existing datasets, assess metrics such as precision, recall, NDCG, and coverage. These metrics, while informative, have limitations as they don’t fully capture the dynamic user interactions of an online environment. Therefore, online evaluations, using A/B testing or simulations, are crucial. These capture real-time user feedback and behavior, allowing for a more holistic assessment of the recommender’s performance regarding exploration-exploitation trade-offs and long-term user engagement. Combining both offline and online evaluations offers a comprehensive understanding of the model’s strengths and weaknesses, guiding further development and improvement.
More visual insights#
More on figures

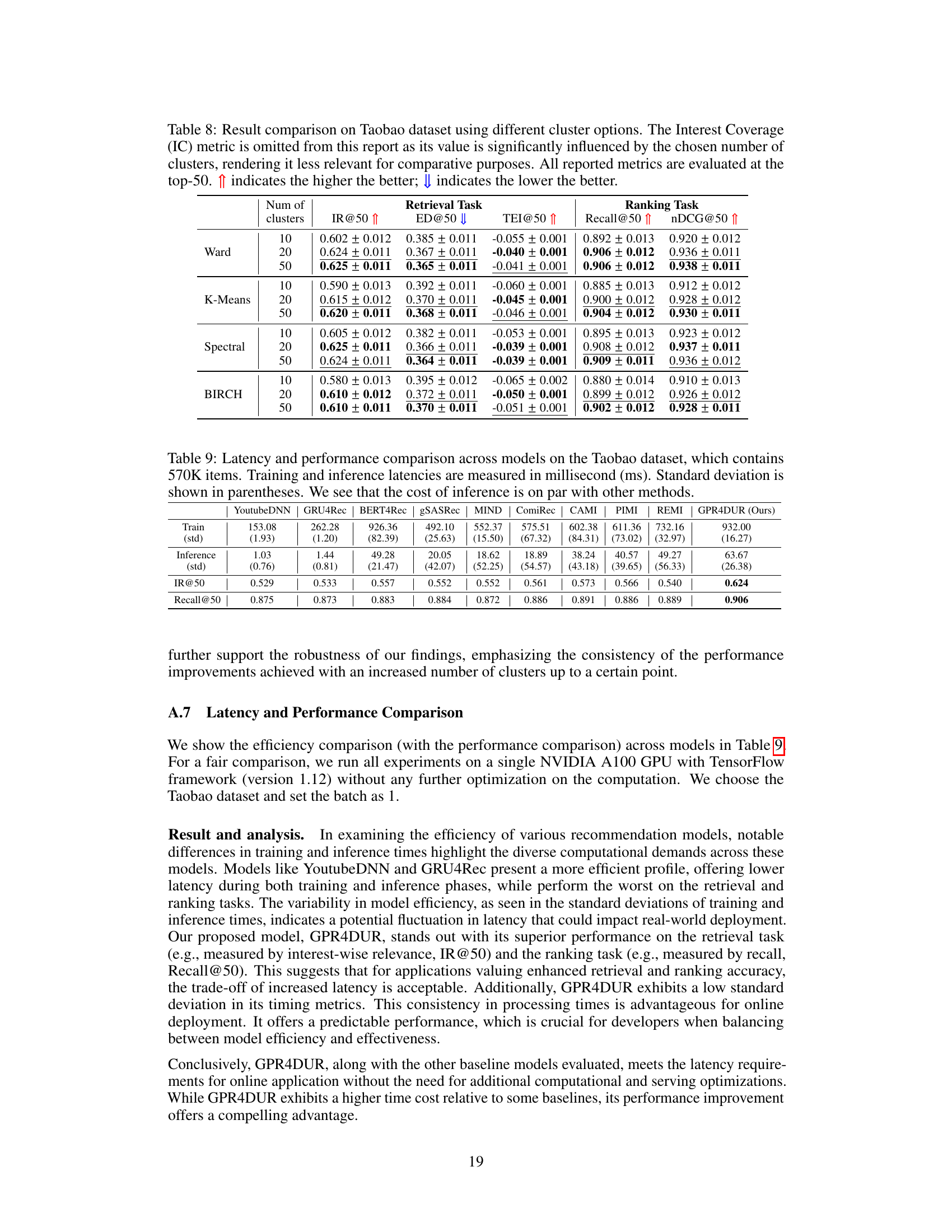
This figure illustrates the GPR4DUR architecture, specifically focusing on a single user’s movie recommendation process. It starts with pre-training to obtain pre-trained item embeddings. The core of the system is GPR4DUR, which takes a user’s observed points (movie interactions) and their corresponding observed values (ratings) as input, utilizing a GPR model to generate predicted scores for all items. Uncertainty is visualized in the predicted scores, representing higher uncertainty for items with fewer interactions. Finally, a retrieval list generation step uses methods like UCB or Thompson sampling to select top-N items based on the predicted scores and associated uncertainties, effectively balancing exploration and exploitation.
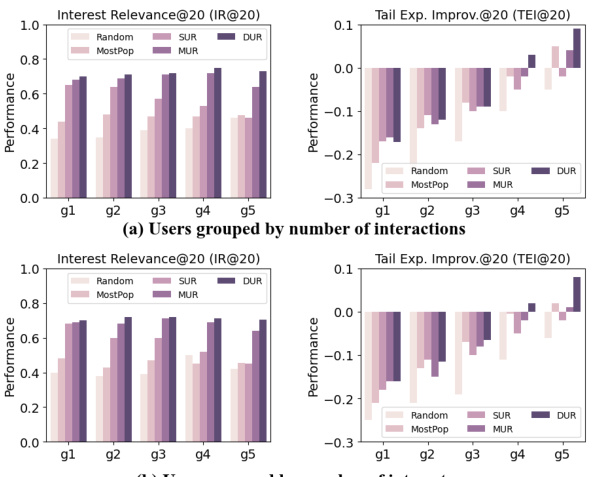
This figure visualizes the prediction scores of a user’s interaction with all items in the MovieLens dataset using t-SNE dimensionality reduction. The scores are calculated as the inner product of user and item embeddings. Triangles mark the user’s 20 most recent interactions. Comparing three user representation methods (SUR, MUR, and GPR), only the density-based GPR method (bottom row) effectively captures multiple user interests and associated uncertainty.

This figure visualizes the prediction scores for a user’s interaction with all items in the MovieLens dataset using t-SNE for dimensionality reduction. The scores represent the inner product of user and item embeddings, with triangles marking the user’s 20 most recent interactions. The visualization highlights that only the density-based method (GPR), shown in the bottom row, effectively captures the user’s multiple interests and their associated uncertainty, unlike single-point (SUR) and multi-point (MUR) representations.
This figure visualizes the prediction scores between a user and all items in the MovieLens dataset using t-SNE for dimensionality reduction. The scores represent the inner product of user and item embeddings, with triangles marking the user’s 20 most recent interactions. The visualization shows that only the density-based method (using Gaussian Process Regression), represented in the bottom row, accurately captures the user’s multiple interests and their associated uncertainty. In contrast, single-point (SUR) and multi-point (MUR) representations fail to capture the diversity of user interests.

This figure visualizes the prediction scores for user-item pairs in the MovieLens dataset using t-SNE dimensionality reduction. It compares three different user representation methods: SUR (single-point), MUR (multi-point), and GPR (Gaussian Process Regression) which is the proposed method. The plot shows that SUR and MUR struggle to capture the diversity of a user’s interests (represented by the location of recently interacted items, marked by triangles), while the GPR method more accurately represents these diverse interests and their uncertainty.
More on tables
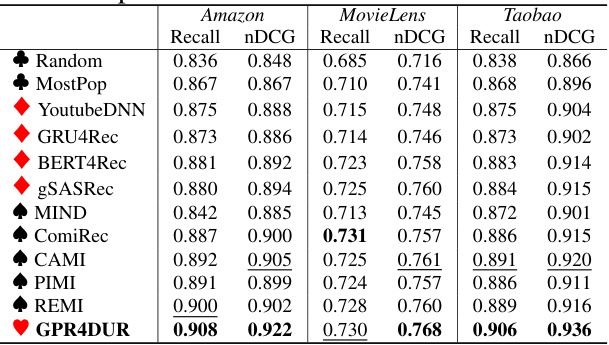
This table presents the results of the retrieval task, comparing different recommendation methods across three datasets (Amazon, MovieLens, Taobao). Metrics include Interest Coverage (IC@k), Interest Relevance (IR@k), Exposure Deviation (ED@k), and Tail Exposure Improvement (TEI@k). The best performing model for each metric on each dataset is shown in bold, with the second-best underlined. Statistical significance (p ≤ 0.01) is indicated with an asterisk (*). The table helps to assess the performance of the proposed GPR4DUR model in comparison to various baseline models.
This table presents the results of the retrieval task experiments, comparing the performance of GPR4DUR against various baselines across three datasets (Amazon, MovieLens, Taobao). Metrics include Interest Coverage (IC@k), Interest Relevance (IR@k), Exposure Deviation (ED@k), and Tail Exposure Improvement (TEI@k) for k=20, 50, and 100. The best and second-best results for each metric and dataset are highlighted, and statistically significant improvements of GPR4DUR over the best baseline (p≤0.01) are indicated by asterisks (*).

This table presents a comparison of different recommendation models on three datasets (Amazon, MovieLens, Taobao) using four metrics to evaluate retrieval performance: Interest Coverage, Interest Relevance, Exposure Deviation, and Tail Exposure Improvement. Each metric is evaluated at different k values (20, 50, 100). The table highlights the performance of the proposed GPR4DUR model compared to various baselines, indicating its superiority in several cases.
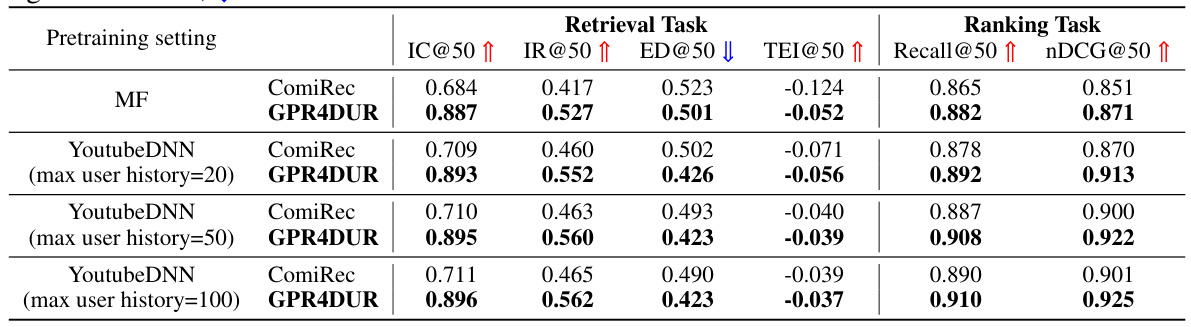
This table presents a comparison of different recommendation models on three datasets (Amazon, MovieLens, Taobao) using four metrics to evaluate retrieval performance: Interest Coverage, Interest Relevance, Exposure Deviation, and Tail Exposure Improvement. Each metric is calculated at three different values of k (20, 50, 100). The table highlights the superior performance of the proposed GPR4DUR model compared to other existing methods across the various datasets and metrics. The significance of the outperformance is indicated using a paired t-test.

This table presents a comparison of different recommendation models on three datasets (Amazon, MovieLens, Taobao) using four evaluation metrics: Interest Coverage (IC@k), Interest Relevance (IR@k), Exposure Deviation (ED@k), and Tail Exposure Improvement (TEI@k). The metrics assess the ability of the models to capture multiple user interests, the relevance of recommendations, the evenness of category exposure, and the exposure of less popular interests. The best performing model for each metric and dataset is shown in bold, highlighting the superior performance of GPR4DUR in many cases.
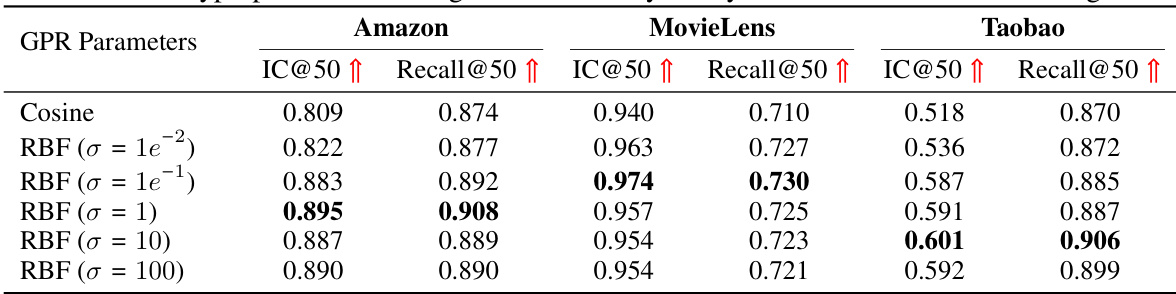
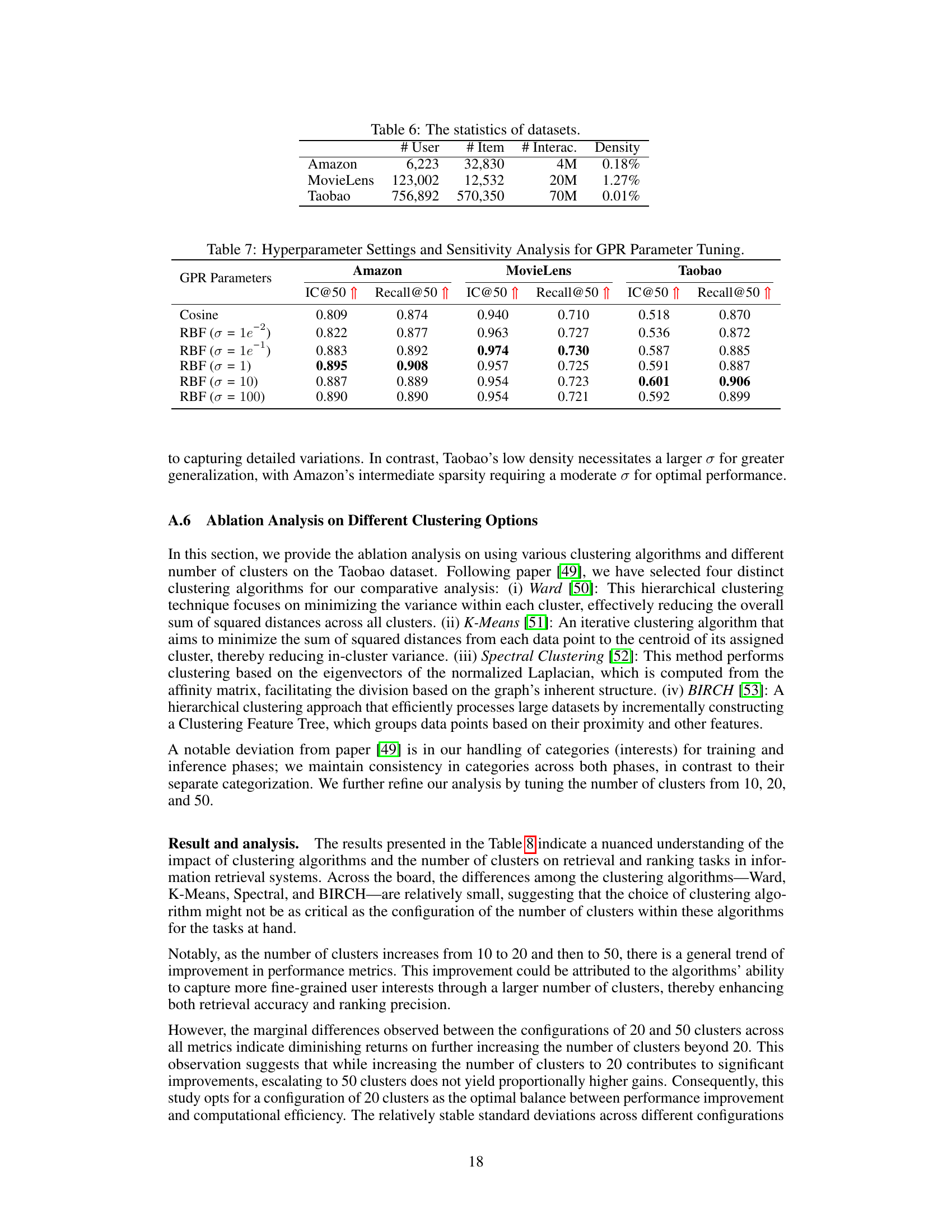
This table presents the results of a sensitivity analysis performed to determine optimal hyperparameter settings for the Gaussian Process Regression (GPR) model used in GPR4DUR. The analysis focuses on the impact of different kernel functions (Cosine and RBF with varying standard deviations σ) on the retrieval and ranking performance metrics (IC@50 and Recall@50). The results are shown separately for the three datasets used in the study: Amazon, MovieLens, and Taobao. This helps to understand how different kernel functions and their parameters affect the model’s ability to accurately capture and predict user interests for multi-interest retrieval and ranking tasks.

This table presents a comparison of different recommendation models on three datasets (Amazon, MovieLens, and Taobao) using four metrics: Interest Coverage (IC@k), Interest Relevance (IR@k), Exposure Deviation (ED@k), and Tail Exposure Improvement (TEI@k). Higher values are better for IC@k and IR@k, while lower values are better for ED@k. The results show the performance of GPR4DUR against baselines such as MostPop, YoutubeDNN, and others across different values of k (20, 50, and 100). The * indicates that GPR4DUR’s performance is statistically significantly better than the best baseline for that metric.

This table presents the results of the retrieval task comparing the proposed GPR4DUR model against other existing methods across three different datasets (Amazon, MovieLens, Taobao). Metrics used include Interest Coverage, Interest Relevance, Exposure Deviation, and Tail Exposure Improvement. The best performing model for each metric in each dataset is highlighted in bold, and the second-best is underlined. Asterisks indicate statistically significant improvements over the best baseline (p≤0.01).

The table presents a comparison of different recommendation models on three datasets (Amazon, MovieLens, Taobao) across four metrics (Interest Coverage, Interest Relevance, Exposure Deviation, Tail Exposure Improvement) for different top-k values (20, 50, 100). The best performing model for each metric and dataset is highlighted in bold, with the second-best underlined. Statistically significant improvements (p≤0.01) by GPR4DUR compared to the best baseline are marked with an asterisk (*).
Full paper#