↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Audio-visual sound separation models struggle with continual learning, meaning they forget previously learned sounds when learning new ones. This is a significant challenge for real-world applications where new sounds are always appearing. Existing continual learning methods designed for other tasks aren’t ideal for this problem because the nature of the task is different.
The researchers propose ContAV-Sep, a new approach that uses a Cross-modal Similarity Distillation Constraint (CrossSDC) to help the model remember old sounds while learning new ones. This involves maintaining the relationship between audio and visual information for all sounds. Experiments show that ContAV-Sep significantly improves the performance of audio-visual sound separation models, especially when dealing with new sounds and preventing the model from forgetting previously learned sounds. This is a significant advancement in the field of continual learning.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the crucial real-world problem of continual learning in the context of audio-visual sound separation. It introduces a novel approach that significantly improves model robustness and adaptability, addresses the catastrophic forgetting problem, and opens new research directions in this rapidly evolving field. The findings are highly relevant to applications requiring real-time adaptation to dynamically changing auditory environments, such as robotics, virtual/augmented reality and assistive technologies.
Visual Insights#
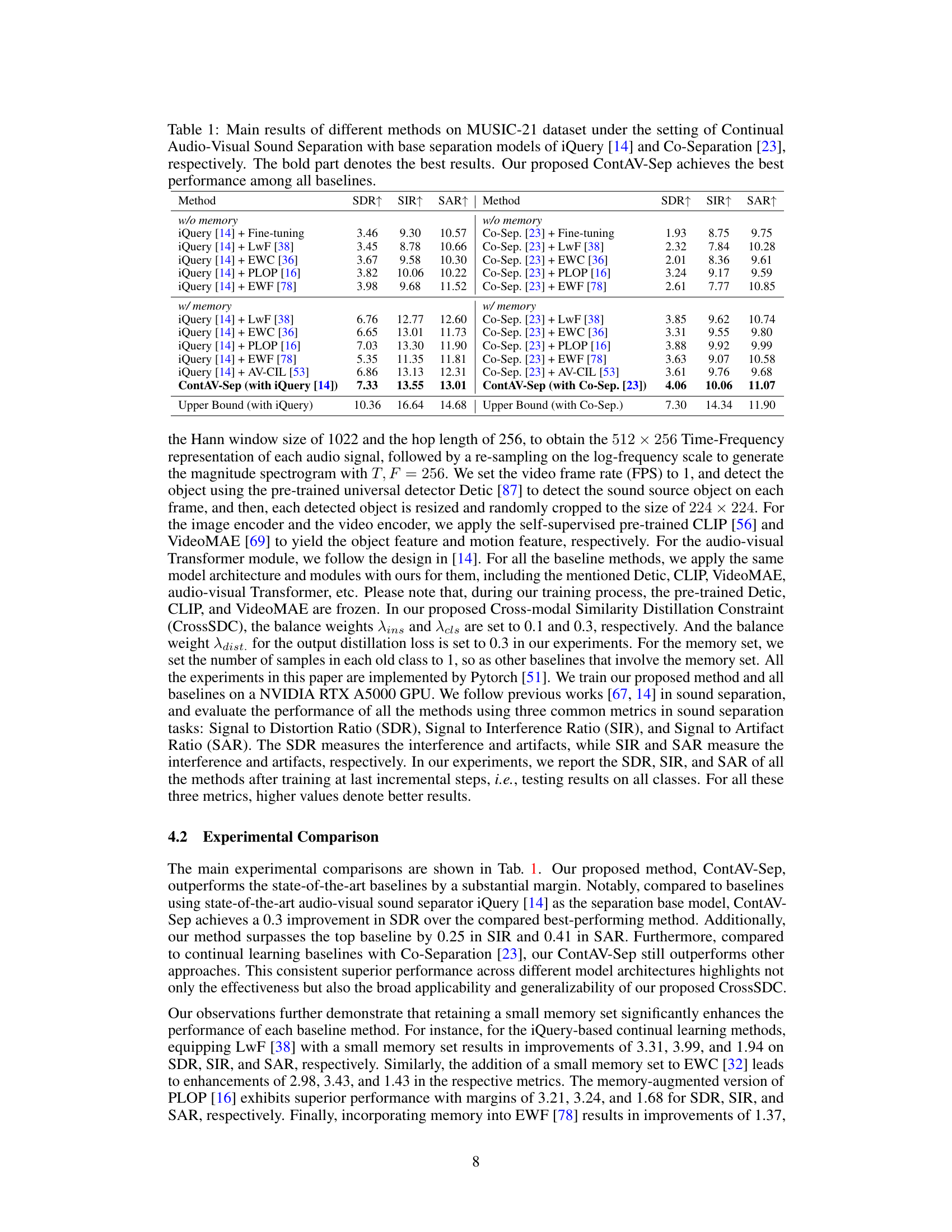
This figure illustrates the continual audio-visual sound separation task. The top panel shows how the model learns from sequential tasks, each with a different set of sound sources, while the bottom panel compares different continual learning approaches to show that the proposed method effectively mitigates catastrophic forgetting in this task.
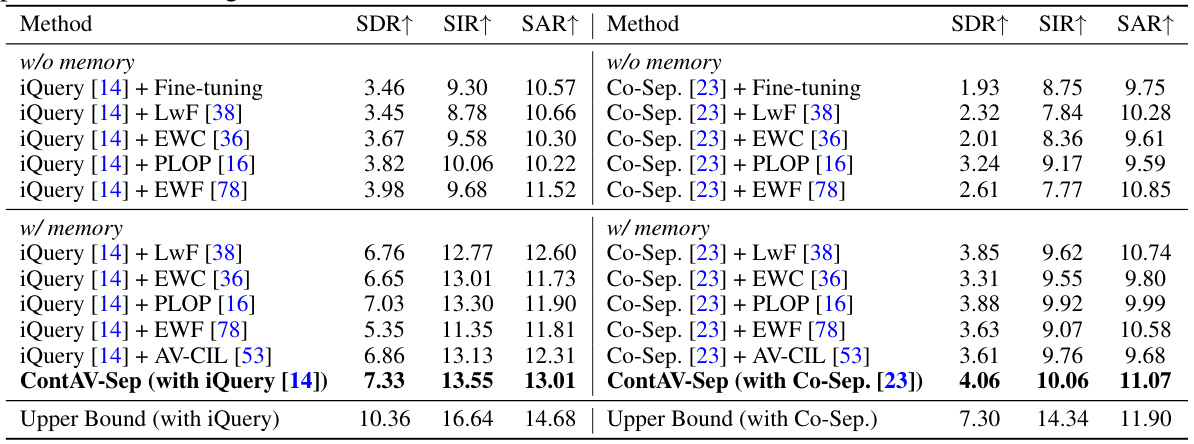
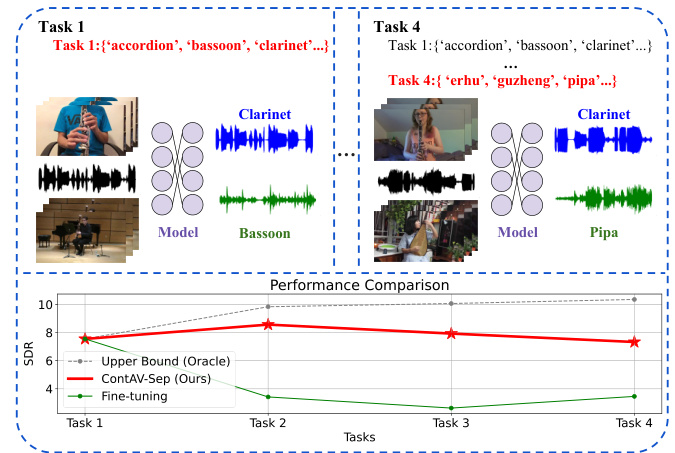
This table presents the main experimental results comparing different methods on the MUSIC-21 dataset for continual audio-visual sound separation. It shows the performance (SDR, SIR, SAR) of various continual learning approaches (Fine-tuning, LwF, EWC, PLOP, EWF, AV-CIL) and the proposed ContAV-Sep, using both iQuery and Co-Separation as base models. The results are split to show performance with and without memory usage. The ‘Upper Bound’ row indicates the best possible performance achievable by training on all available data. The table highlights that ContAV-Sep consistently outperforms other methods.
In-depth insights#
ContAV-Sep#
ContAV-Sep, as a novel approach for continual audio-visual sound separation, tackles the challenging problem of mitigating catastrophic forgetting. It cleverly leverages visual guidance to continuously separate new sound sources without compromising performance on previously learned ones. The core innovation lies in the Cross-modal Similarity Distillation Constraint (CrossSDC), which effectively preserves cross-modal semantic similarity across incremental learning steps. By seamlessly integrating into existing audio-visual sound separation frameworks, ContAV-Sep demonstrates significant performance gains over traditional continual learning baselines. This addresses a crucial limitation of current models, enhancing their robustness and adaptability in dynamic, real-world scenarios where new sounds are constantly encountered. The proposed approach is particularly impactful for practical visually guided auditory perception, showing promise for improving the overall adaptability and robustness of audio-visual sound separation systems.
CrossSDC#
The proposed Cross-modal Similarity Distillation Constraint (CrossSDC) tackles the challenge of catastrophic forgetting in continual audio-visual sound separation. CrossSDC cleverly preserves cross-modal semantic similarity across incremental tasks by integrating contrastive loss and knowledge distillation. This dual approach, focusing on both instance-aware and class-aware similarity, is crucial. Instance-aware similarity ensures consistent cross-modal correlations within tasks. Class-aware similarity maintains high semantic correlation between classes across tasks preventing knowledge degradation of old classes as new ones are learned. This innovative approach seamlessly integrates into existing audio-visual separation frameworks enhancing robustness and adaptability in dynamic, real-world scenarios.
Catastrophic forgetting#
Catastrophic forgetting, a significant challenge in continual learning, describes the phenomenon where a machine learning model trained on a new task loses its ability to perform well on previously learned tasks. This is especially problematic in real-world scenarios where models must adapt to a continuous stream of new information. The core issue lies in the model’s parameter updates during the learning of new tasks, which can overwrite or disrupt the knowledge acquired in previous learning phases. Mitigation strategies often focus on either regularization techniques to constrain parameter updates, or memory-based methods that retain information from previous tasks, or on dynamic architectural changes allowing for expansion of the network capacity. The trade-off between preserving old knowledge and learning new information is crucial, and many continual learning strategies strive to achieve a balance. Overcoming catastrophic forgetting is a vital step towards building truly robust and adaptable AI systems capable of continuous learning in ever-changing environments.
Continual learning#
Continual learning, a crucial aspect of artificial intelligence, focuses on developing systems that can continuously learn and adapt from new data streams without catastrophic forgetting of previously acquired knowledge. The challenge lies in balancing stability (retaining old knowledge) and plasticity (acquiring new knowledge). The paper highlights the significance of continual learning in audio-visual sound separation, a task where the model must continuously adapt to new sound sources while maintaining performance on previously learned ones. This is particularly challenging because the model needs to leverage cross-modal information (audio and visual cues) effectively, both for new and old sound classes. The authors address this by proposing novel techniques such as cross-modal similarity distillation to maintain semantic relationships across modalities and tasks. This ensures that the model retains important relationships between audio and visual input, preventing catastrophic forgetting as new tasks are introduced. This is a significant advancement in addressing the limitations of traditional sound separation models which often struggle with real-world dynamic environments where new sounds constantly appear.
Future works#
Future research directions stemming from this work could explore more sophisticated continual learning techniques to further enhance the model’s ability to adapt to new sound sources without catastrophic forgetting. Investigating the impact of different memory management strategies and exploring the use of more advanced architectural designs specifically tailored for continual learning would be beneficial. Further exploration of the role of visual information and its interaction with auditory processing within continual learning is warranted, perhaps employing more robust visual feature extraction methods. The robustness of the approach across different sound datasets and real-world noisy environments needs to be more extensively tested. Finally, addressing the computational limitations of the method to make it more feasible for real-time applications would be a valuable contribution.
More visual insights#
More on figures

This figure illustrates the architecture of the ContAV-Sep model. It shows three main components: the base audio-visual sound separation model (using iQuery [14] as an example), an output mask distillation module, and the Cross-modal Similarity Distillation Constraint (CrossSDC). The base model takes mixed audio and visual input (video and object features) to generate separated audio. The Output Mask Distillation uses the output masks from the previous task to guide training on new tasks. CrossSDC aims to maintain cross-modal semantic similarity across tasks using contrastive loss, ensuring that information from both audio and visual modalities is effectively retained during continual learning.

This figure shows the performance comparison of different continual learning methods (Fine-tuning, LwF, EWC, PLOP, EWF, and ContAV-Sep) using iQuery [14] as the base model for audio-visual sound separation. The results are presented for each incremental step across 20 classes, showing SDR (Signal-to-Distortion Ratio), SIR (Signal-to-Interference Ratio), and SAR (Signal-to-Artifacts Ratio). It demonstrates ContAV-Sep’s consistent superior performance across all incremental steps compared to other methods, highlighting its ability to effectively mitigate catastrophic forgetting.
This figure displays the performance of various continual learning methods, including the proposed ContAV-Sep, on the tasks of separating sound sources. The results are shown across different incremental steps and are evaluated based on three metrics: Signal to Distortion Ratio (SDR), Signal to Interference Ratio (SIR), and Signal to Artifact Ratio (SAR). Each subplot represents one of these metrics. The figure illustrates how the performance of different models changes as the number of tasks increases (on the x-axis), showing the impact of continual learning on maintaining performance on previous tasks while learning new ones. The goal is to see which approach mitigates catastrophic forgetting most effectively.
More on tables

This table presents the ablation study of the proposed ContAV-Sep method. It shows the impact of each component of the CrossSDC (Cross-modal Similarity Distillation Constraint) on the final performance. By removing different components of the CrossSDC, the experiment evaluates the contribution of each component to the overall performance. The results demonstrate that the full model (with all components) achieves the best performance, highlighting the effectiveness of the proposed CrossSDC in improving the continual audio-visual sound separation.
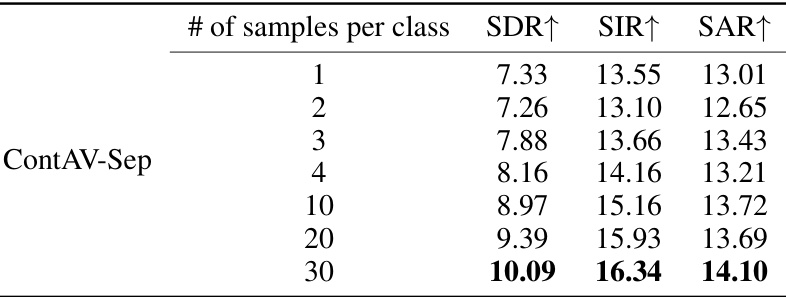
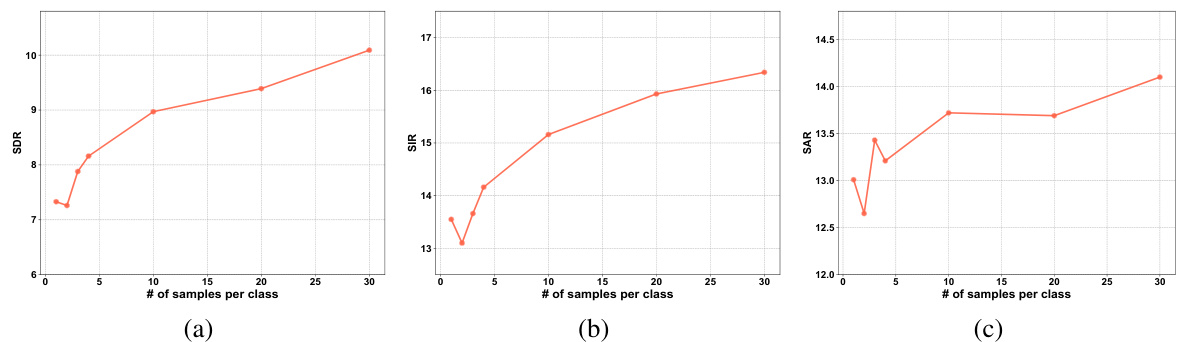
This table presents the experimental results of the proposed ContAV-Sep model with varying memory sizes. The memory size refers to the number of samples per class stored in the memory set. The table shows how the model’s performance, measured by SDR, SIR, and SAR, changes as the memory size increases from 1 to 30 samples per class. The results demonstrate the impact of memory size on the model’s ability to mitigate catastrophic forgetting and maintain performance on previously seen classes during continual learning.
Full paper#