↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Diffusion models excel in generating high-quality images, but their fine-tuning remains challenging. Supervised methods plateau after processing a certain volume of data, while reinforcement learning (RL) methods require paired “winner” and “loser” images, often unavailable in real-world datasets. This creates limitations in aligning the model with human preferences and achieving optimal performance.
This paper introduces SPIN-Diffusion, a self-play fine-tuning technique. Unlike traditional methods, SPIN-Diffusion iteratively improves a model by competing against its previous versions. This self-competitive training process avoids the need for human preference data or paired images, enhancing both model performance and alignment. Experiments show SPIN-Diffusion outperforms existing supervised fine-tuning and RLHF-based approaches in human preference alignment and visual appeal, particularly with limited datasets. The superior data-efficiency and performance make SPIN-Diffusion a valuable contribution to the field of generative AI.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and efficient method for fine-tuning diffusion models, overcoming limitations of existing supervised and reinforcement learning-based approaches. Its data efficiency and strong performance improvements have significant implications for researchers in generative AI, especially those working with limited datasets. The proposed self-play mechanism offers a new avenue for model improvement, potentially impacting various applications beyond image generation.
Visual Insights#
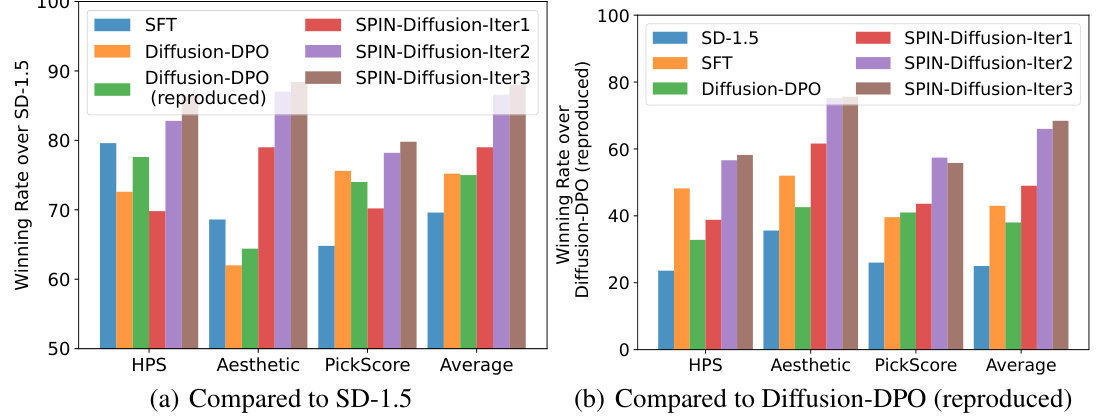
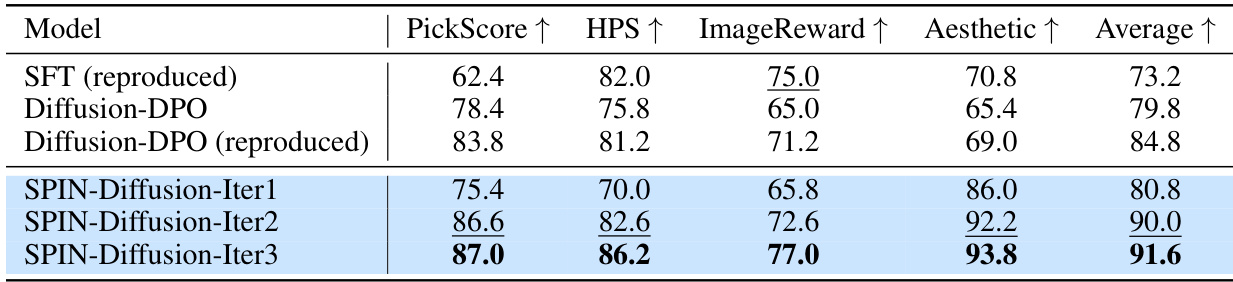
🔼 This figure shows the winning rates of SPIN-Diffusion compared to two baselines, SD-1.5 and Diffusion-DPO, across four metrics: HPS, Aesthetic, PickScore, and Average. The winning rate is calculated as the percentage of prompts for which the model produces images of higher quality than the baseline model. The results clearly demonstrate the superior performance of SPIN-Diffusion, which exhibits significantly higher winning rates than both SFT and Diffusion-DPO, especially in the second and third iterations.
read the caption
Figure 1: Left: winning rate in percentage of SFT, Diffusion-DPO, Diffusion-DPO (reproduced) and SPIN-Diffusion over SD-1.5 checkpoint. Right: winning rate in percentage of SFT, Diffusion-DPO, Diffusion-DPO (reproduced) and SPIN-Diffusion over Diffusion-DPO (reproduced) checkpoint. SPIN-Diffusion shows a much higher winning rate than SFT and Diffusion-DPO tuned models.
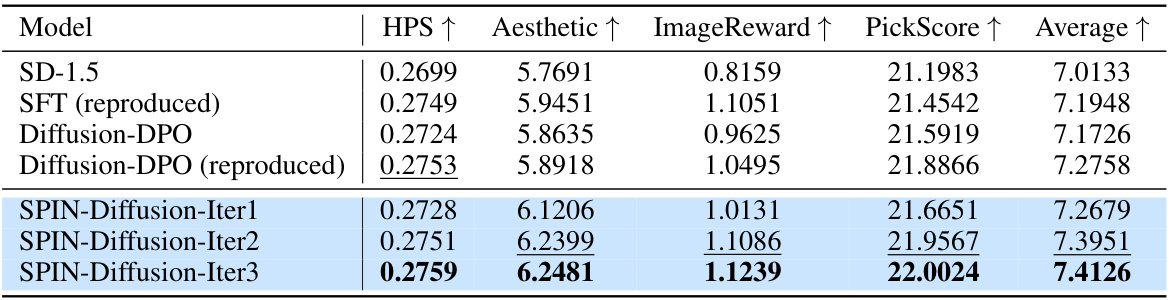
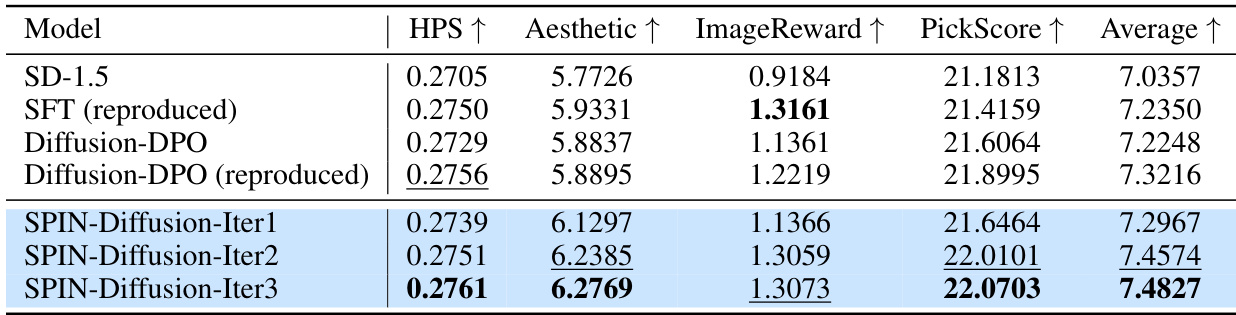
🔼 This table presents the quantitative results of different models on the Pick-a-Pic test set. The models evaluated include the Stable Diffusion baseline (SD-1.5), Supervised Fine-Tuning (SFT), Diffusion-DPO (and a reproduced version), and the proposed SPIN-Diffusion at various iterations. The evaluation metrics employed are PickScore, HPS, ImageReward, and Aesthetic scores. The table shows the mean scores for each metric, as well as the average across all four metrics. The results show that SPIN-Diffusion consistently outperforms the baselines, demonstrating its effectiveness in improving text-to-image generation.
read the caption
Table 1: The results on the Pick-a-Pic test set. We report the mean of PickScore, HPS, ImageReward and Aesthetic over the whole test set. We also report the average score over the three evaluation metrics. SPIN-Diffusion outperforms all the baselines in terms of four metrics. For this and following tables, we use blue background to indicate our method, bold numbers to denote the best and underlined for the second best.
In-depth insights#
Self-Play’s Promise#
Self-play, as a training paradigm, offers a compelling alternative to traditional supervised learning methods. Its core strength lies in its ability to generate diverse and challenging training data without relying on expensive or potentially biased human annotation. By pitting a model against previous versions of itself, it fosters continuous improvement and adaptation, leading to potentially more robust and innovative solutions. This self-improvement process also addresses the problem of data scarcity, a common issue in many AI domains, as it effectively bootstraps itself from limited initial data. However, the effectiveness of self-play is dependent on proper algorithm design to prevent stagnation or undesirable outcomes. Careful consideration of the objective function and the exploration-exploitation balance is crucial to ensure the generated training data leads to beneficial improvements, rather than overfitting or unexpected biases. The application of self-play across diverse AI tasks holds significant promise, particularly where large, labeled datasets are unavailable or difficult to acquire. Future research should focus on refining self-play techniques to enhance efficiency, reliability, and scalability, thereby unlocking its full potential for accelerating AI progress.
SPIN-Diffusion Model#
The SPIN-Diffusion model presents a novel self-play fine-tuning approach for diffusion models, eliminating the need for paired comparison data often required by reinforcement learning methods. Instead, it leverages a competition between the current model iteration and its previous versions, fostering iterative self-improvement. This approach is theoretically shown to reach a stationary point where the model aligns with the target data distribution, and empirically outperforms standard supervised fine-tuning and existing RLHF methods in text-to-image generation tasks on metrics such as human preference alignment and visual appeal. Its data efficiency is a key advantage, as it achieves superior results even with less data than RLHF-based methods. However, it’s important to note that the success of SPIN-Diffusion relies on the availability of high-quality image-text pairs for initial supervised fine-tuning and may not directly address bias inherent in such datasets. Further investigation into the robustness and scalability of the algorithm for diverse prompt styles and dataset compositions is warranted.
Empirical Validation#
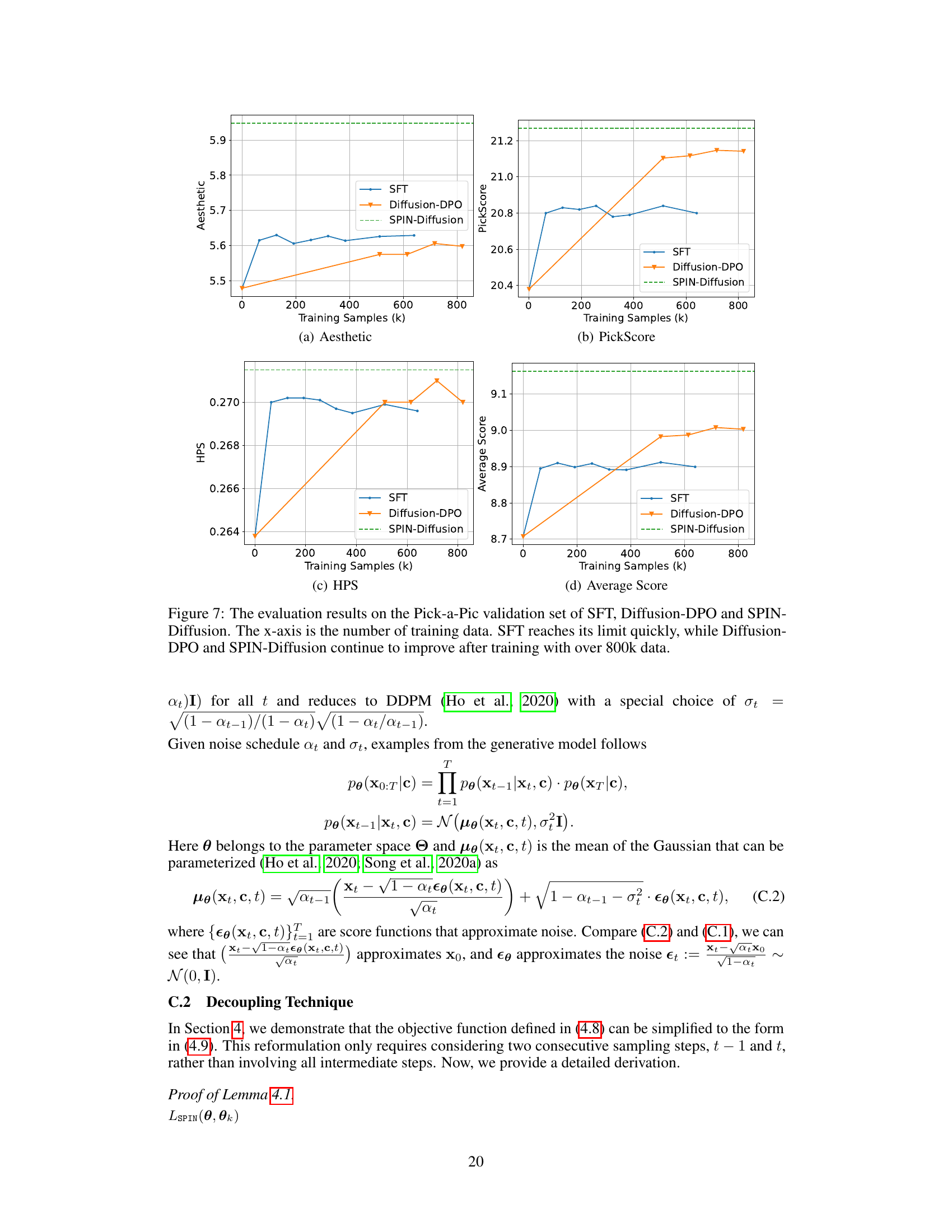
An Empirical Validation section in a research paper would rigorously test the study’s hypotheses using real-world data. It should detail the methods used, including the datasets, metrics, and statistical analyses. Crucially, it must present the results clearly and transparently, acknowledging any limitations or potential biases. A strong section would compare the results to existing literature, highlighting novel findings and their implications. Visualizations, such as graphs and tables, are essential for effective communication of complex results. The discussion should focus on the significance of the findings, their robustness, and potential directions for future research. A comprehensive validation bolsters the paper’s credibility and impact, providing strong evidence for the claims made.
Theoretical Analysis#
A theoretical analysis section in a research paper would ideally delve into the mathematical underpinnings of the proposed method. It should rigorously establish the correctness and efficiency of the approach, potentially leveraging established theorems and mathematical frameworks. Key aspects to cover would include proofs of convergence, analyses of computational complexity (time and space), and discussions of the algorithm’s stability and robustness. A strong theoretical analysis not only validates the proposed method but also provides insights into its limitations, guiding future research directions. The analysis might involve simplifying assumptions to make the problem tractable, but it should clearly articulate those assumptions and discuss their potential impact on the overall results. Ideally, the theoretical findings should align with and complement the experimental results, demonstrating a holistic understanding of the method’s behavior. For a self-play approach, proving that the self-play mechanism converges to a desired outcome would be crucial. The theoretical analysis should provide guarantees, or at least bounds, on the performance of the self-play process. Overall, a comprehensive theoretical analysis significantly enhances the credibility and impact of a research paper by providing a firm foundation for the empirical findings.
Future Directions#
Future research could explore extending SPIN-Diffusion to other generative models, beyond diffusion models, to determine its broader applicability and effectiveness. Investigating the impact of different loss functions and architectures within the SPIN framework is crucial for optimizing performance and stability. A deeper analysis into the theoretical properties and convergence behavior of SPIN-Diffusion under various conditions would enhance our understanding of its effectiveness. Furthermore, a key area for improvement lies in developing more efficient training methods to reduce computational cost and data requirements, making it suitable for broader applications. Finally, exploring methods for addressing potential biases inherent in the training data and mitigating the risk of generating unsafe or harmful content is vital for responsible AI development.
More visual insights#
More on figures

🔼 This figure compares image generation results from six different models: Stable Diffusion 1.5 (SD-1.5), Supervised Fine-Tuning (SFT), Diffusion-DPO, and SPIN-Diffusion (iterations 1, 2, and 3). Three different prompts are used, and for each prompt, images generated by each model are shown side-by-side. The figure visually demonstrates the improvement in image quality achieved by SPIN-Diffusion, particularly in iterations 2 and 3. Table 5 provides quantitative support for this visual assessment by presenting the aesthetic scores for the images.
read the caption
Figure 2: We show the images generated by different models. The prompts are “a very cute boy, looking at audience, silver hair, in his room, wearing hoodie, at daytime, ai language model, 3d art, c4d, blender, pop mart, blind box, clay material, pixar trend, animation lighting, depth of field, ultra detailed”, “painting of a castle in the distance” and “red and green eagle”. The models are: SD-1.5, SFT, Diffusion-DPO (reproduced), SPIN-Diffusion-Iter1, SPIN-Diffusion-Iter2, SPIN-Diffusion-Iter3 from left to right. SPIN-Diffusion demonstrates a notable improvement in image quality. The quantitative evaluation of the aesthetic score of the above images is in Table 5.
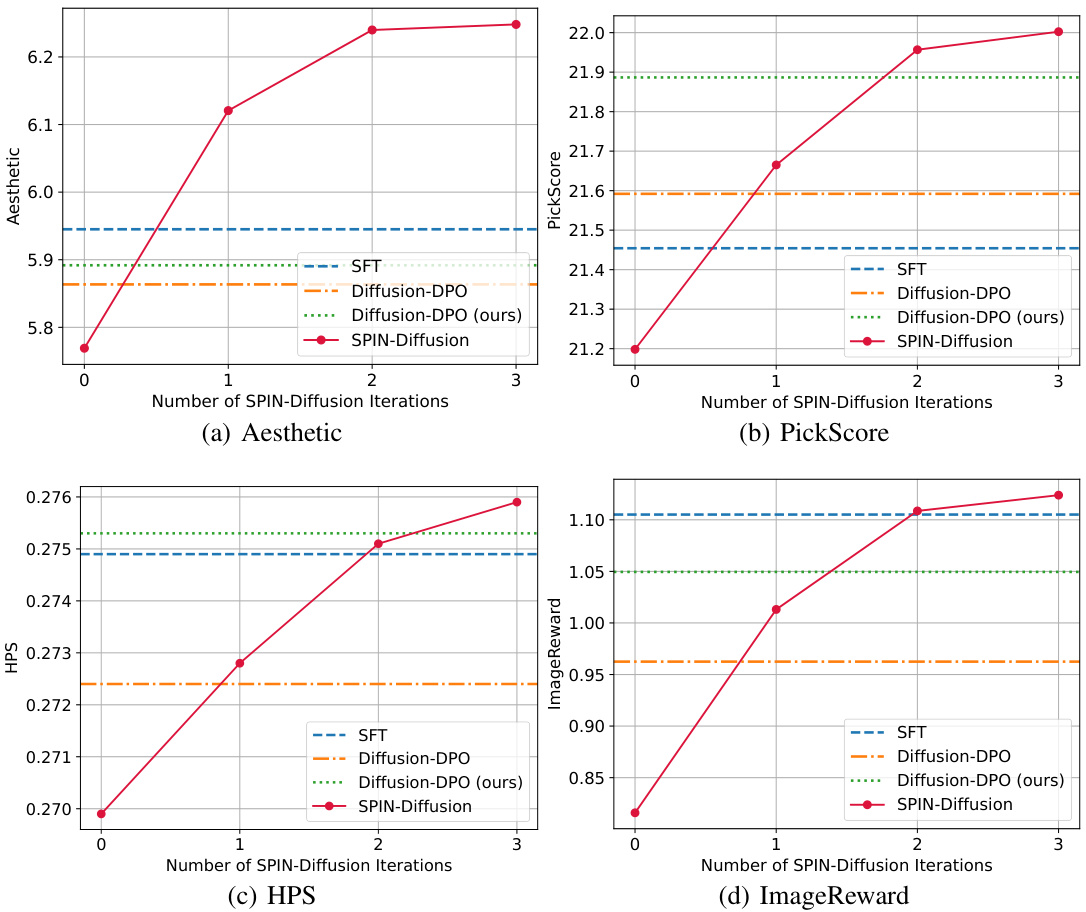
🔼 This figure compares the performance of SPIN-Diffusion across different iterations (1, 2, and 3) against three baseline methods: SD-1.5 (Stable Diffusion), SFT (Supervised Fine-Tuning), and Diffusion-DPO (Diffusion Direct Preference Optimization). The performance is measured using four metrics: Aesthetic score, PickScore, HPS (Human Preference Score), and ImageReward. The results show that SPIN-Diffusion surpasses SFT after the first iteration and outperforms all baselines after the second iteration, highlighting its superior performance in aligning with human preferences and generating visually appealing images.
read the caption
Figure 3: Comparison between SPIN-Diffusion at different iterations with SD-1.5, SFT and Diffusion-DPO. SPIN-Diffusion outperforms SFT at iteration 1, and outperforms all the baselines after iteration 2. In the legend, Diffusion-DPO (ours) denotes our reproduced version of Diffusion-DPO.
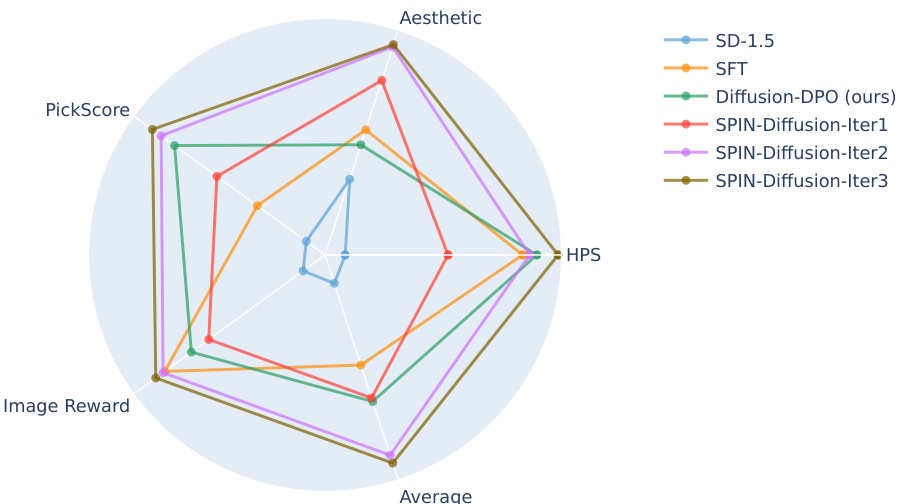
🔼 This radar chart compares the performance of SPIN-Diffusion (at various iterations) against baseline methods (SD-1.5, SFT, and Diffusion-DPO) across four evaluation metrics: PickScore, HPS, ImageReward, and Aesthetic. SPIN-Diffusion consistently outperforms the baselines in all metrics, demonstrating its superior performance in terms of human preference alignment and visual appeal.
read the caption
Figure 4: The main result is presented in radar chart. The scores are adjusted to be shown on the same scale. Compared with the baselines, SPIN achieves higher scores in all the four metrics and the average score by a large margin. In the legend, Diffusion-DPO (ours) denotes our reproduced version of Diffusion-DPO.
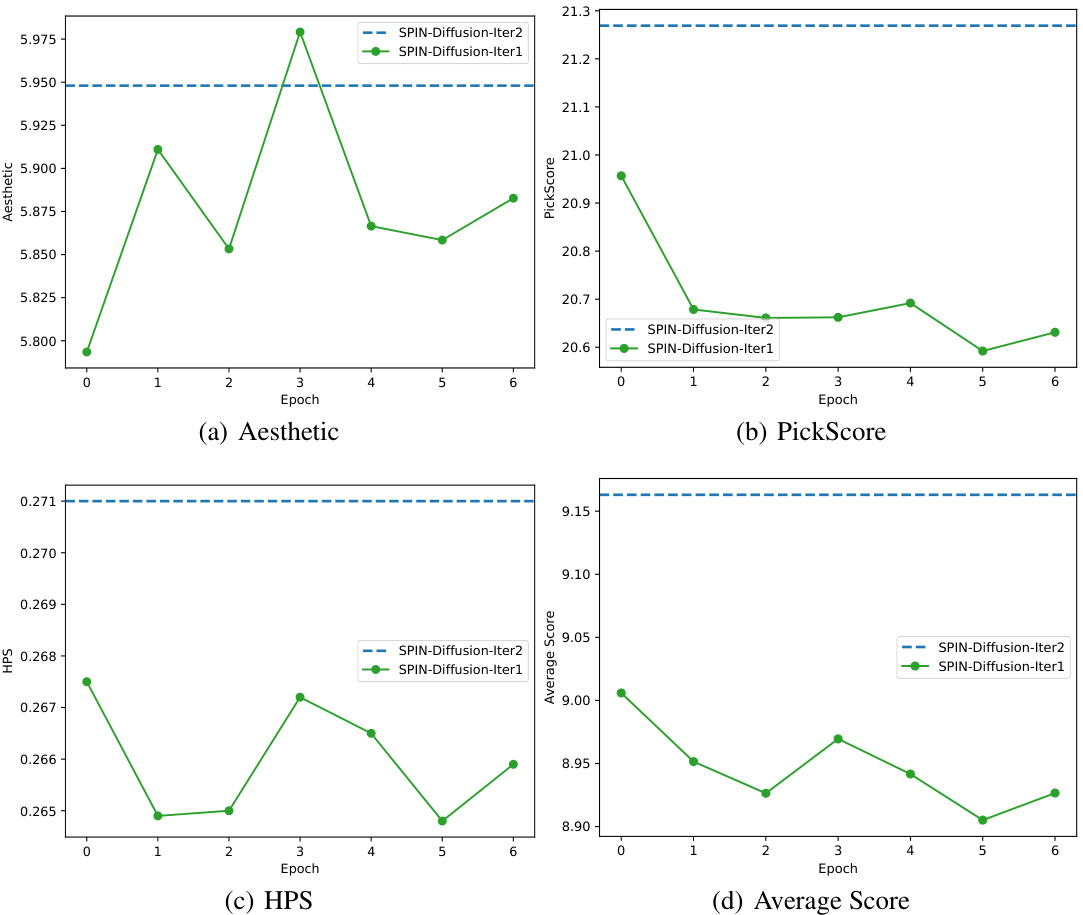
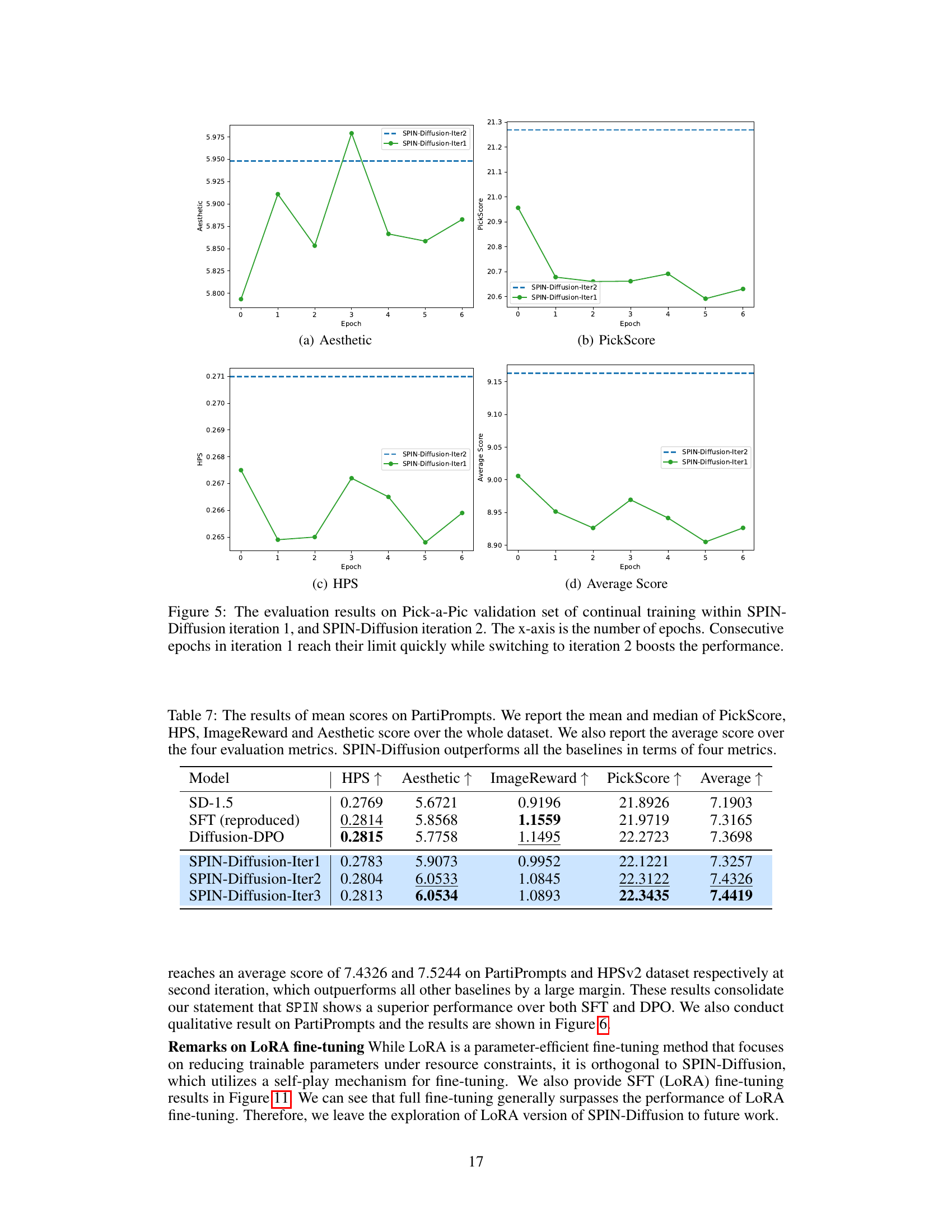
🔼 This figure shows the results of continual training within SPIN-Diffusion. The x-axis represents the number of epochs. Two separate continual training experiments are shown: one for iteration 1 and one for iteration 2. The key takeaway is that continual training in iteration 1 shows diminishing returns, while starting over in iteration 2 significantly improves performance. This demonstrates the effectiveness of the self-play mechanism in SPIN-Diffusion. The plot includes four metrics: Aesthetic score, PickScore, HPS, and the average of the three.
read the caption
Figure 5: The evaluation results on Pick-a-Pic validation set of continual training within SPIN-Diffusion iteration 1, and SPIN-Diffusion iteration 2. The x-axis is the number of epochs. Consecutive epochs in iteration 1 reach their limit quickly while switching to iteration 2 boosts the performance.

🔼 This figure compares the image generation capabilities of six different models (Stable Diffusion 1.5, Supervised Fine-Tuning, Diffusion-DPO, and three iterations of SPIN-Diffusion) on three different prompts. The results visually demonstrate that SPIN-Diffusion produces superior image quality, especially in terms of detail and overall aesthetic appeal compared to the baseline models.
read the caption
Figure 2: We show the images generated by different models. The prompts are “a very cute boy, looking at audience, silver hair, in his room, wearing hoodie, at daytime, ai language model, 3d art, c4d, blender, pop mart, blind box, clay material, pixar trend, animation lighting, depth of field, ultra detailed”, “painting of a castle in the distance” and “red and green eagle”. The models are: SD-1.5, SFT, Diffusion-DPO (reproduced), SPIN-Diffusion-Iter1, SPIN-Diffusion-Iter2, SPIN-Diffusion-Iter3 from left to right. SPIN-Diffusion demonstrates a notable improvement in image quality. The quantitative evaluation of the aesthetic score of the above images is in Table 5.
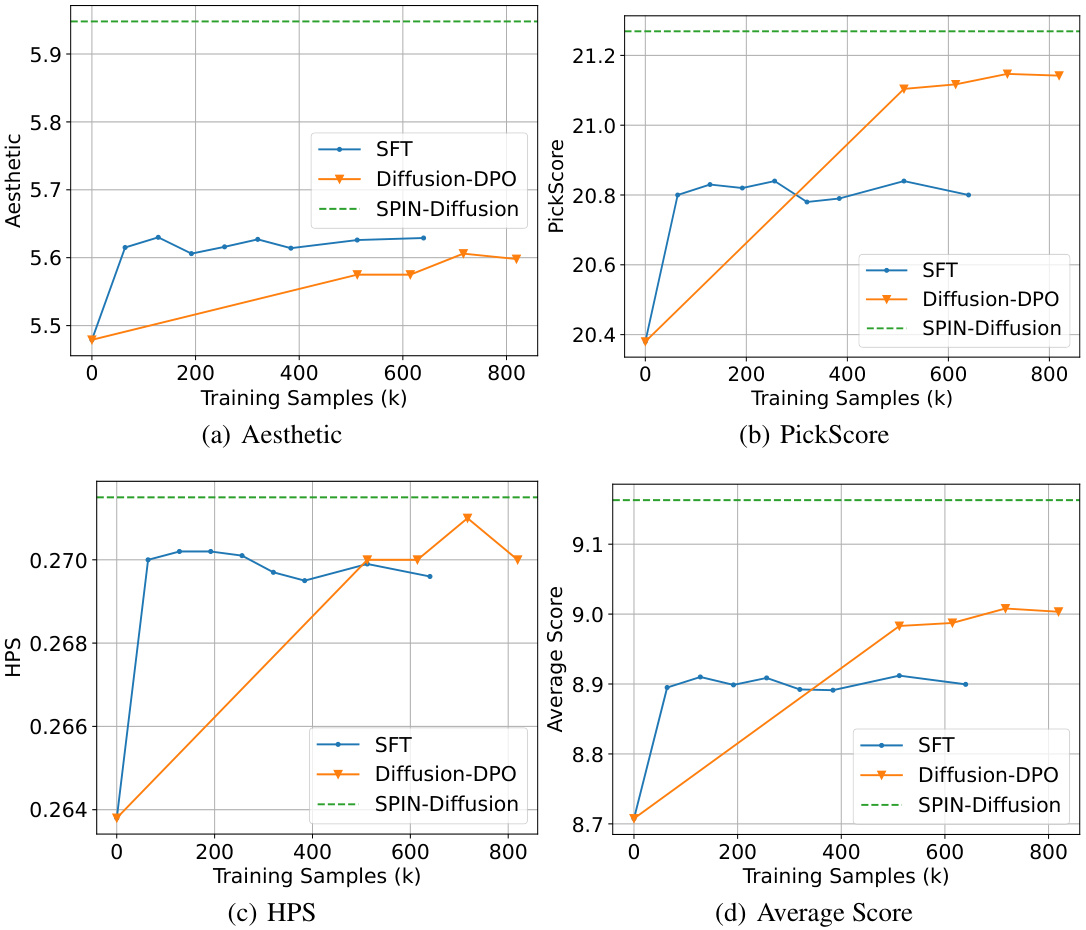
🔼 This figure compares the performance of SPIN-Diffusion across three iterations against three baseline methods: SD-1.5, SFT, and Diffusion-DPO (both the original and a reproduced version). The four metrics shown (Aesthetic score, PickScore, HPS, and Average Score) demonstrate that SPIN-Diffusion surpasses SFT after just one iteration, and outperforms all baselines after two iterations. The improvements continue into the third iteration.
read the caption
Figure 3: Comparison between SPIN-Diffusion at different iterations with SD-1.5, SFT and Diffusion-DPO. SPIN-Diffusion outperforms SFT at iteration 1, and outperforms all the baselines after iteration 2. In the legend, Diffusion-DPO (ours) denotes our reproduced version of Diffusion-DPO.

🔼 This figure compares image generation results from different models (SD-1.5, SFT, Diffusion-DPO, and SPIN-Diffusion across iterations) using three different prompts. It visually demonstrates the improved image quality produced by the SPIN-Diffusion method, particularly in later iterations. Table 5 provides quantitative support for this visual assessment by showing aesthetic scores.
read the caption
Figure 2: We show the images generated by different models. The prompts are “a very cute boy, looking at audience, silver hair, in his room, wearing hoodie, at daytime, ai language model, 3d art, c4d, blender, pop mart, blind box, clay material, pixar trend, animation lighting, depth of field, ultra detailed”, “painting of a castle in the distance” and “red and green eagle”. The models are: SD-1.5, SFT, Diffusion-DPO (reproduced), SPIN-Diffusion-Iter1, SPIN-Diffusion-Iter2, SPIN-Diffusion-Iter3 from left to right. SPIN-Diffusion demonstrates a notable improvement in image quality. The quantitative evaluation of the aesthetic score of the above images is in Table 5.

🔼 This figure shows the image generation results of different models (SD-1.5, SFT, Diffusion-DPO, and SPIN-Diffusion with iterations 1, 2, and 3) for three different prompts. It visually demonstrates the improved image quality and detail achieved by the proposed SPIN-Diffusion method compared to the baseline models. Table 5 provides a quantitative comparison of the aesthetic scores for these images.
read the caption
Figure 2: We show the images generated by different models. The prompts are “a very cute boy, looking at audience, silver hair, in his room, wearing hoodie, at daytime, ai language model, 3d art, c4d, blender, pop mart, blind box, clay material, pixar trend, animation lighting, depth of field, ultra detailed”, “painting of a castle in the distance” and “red and green eagle”. The models are: SD-1.5, SFT, Diffusion-DPO (reproduced), SPIN-Diffusion-Iter1, SPIN-Diffusion-Iter2, SPIN-Diffusion-Iter3 from left to right. SPIN-Diffusion demonstrates a notable improvement in image quality. The quantitative evaluation of the aesthetic score of the above images is in Table 5.

🔼 This figure compares the image generation results of different models (SD-1.5, SFT, Diffusion-DPO, and SPIN-Diffusion with iterations 1, 2, and 3) on three different prompts. Each row shows the same prompt interpreted by each model. The results show the superior visual quality generated by the SPIN-Diffusion model, especially in the details and overall aesthetic appeal.
read the caption
Figure 2: We show the images generated by different models. The prompts are “a very cute boy, looking at audience, silver hair, in his room, wearing hoodie, at daytime, ai language model, 3d art, c4d, blender, pop mart, blind box, clay material, pixar trend, animation lighting, depth of field, ultra detailed”, “painting of a castle in the distance” and “red and green eagle”. The models are: SD-1.5, SFT, Diffusion-DPO (reproduced), SPIN-Diffusion-Iter1, SPIN-Diffusion-Iter2, SPIN-Diffusion-Iter3 from left to right. SPIN-Diffusion demonstrates a notable improvement in image quality. The quantitative evaluation of the aesthetic score of the above images is in Table 5.

🔼 This figure compares image generation results from different models (SD-1.5, SFT, Diffusion-DPO, SPIN-Diffusion) using five prompts focusing on cartoon-style images. Each row shows the results for a different prompt, and the columns show the different models. The goal is to visually demonstrate the improved image quality and style consistency of SPIN-Diffusion, especially compared to the base model (SD-1.5).
read the caption
Figure 11: We show the figures generated by different models based on prompts from PartiPrompts. The prompts are “A cartoon house with red roof”, “a cartoon of an angry shark”, “a cartoon of a bear birthday party”, “a cartoon of a house on a mountain” and “a cartoon of a boy playing with a tiger”. The models are: SD-1.5, SFT, Diffusion-DPO, Diffusion-DPO (reproduced), SPIN-Diffusion-Iter2 from left to right, all utilizing the same random seed for fair comparison

🔼 This figure showcases a gallery of images generated using SPIN-Diffusion, a novel self-play fine-tuning method for diffusion models. The images highlight the model’s ability to generate high-quality, visually appealing, and contextually relevant outputs, even when trained with only one image per text prompt. The results demonstrate SPIN-Diffusion’s superiority over other fine-tuning methods.
read the caption
Figure 12: Image galary generated by SPIN-Diffusion, a self-play fine-tuning algorithm for diffusion models. The results are fine-tuned from Stable Diffusion v1.5 on the winner images of the Pick-a-Pic dataset. The prompts used for generating the above images are chosen from the Pick-a-Pic test set. The generated images demonstrate superior performance in terms of overall visual attractiveness and coherence with the prompts. SPIN-Diffusion is featured by its independence from paired human preference data, offering a useful tool for fine-tuning on custom datasets with only single image per text prompt provided.
More on tables
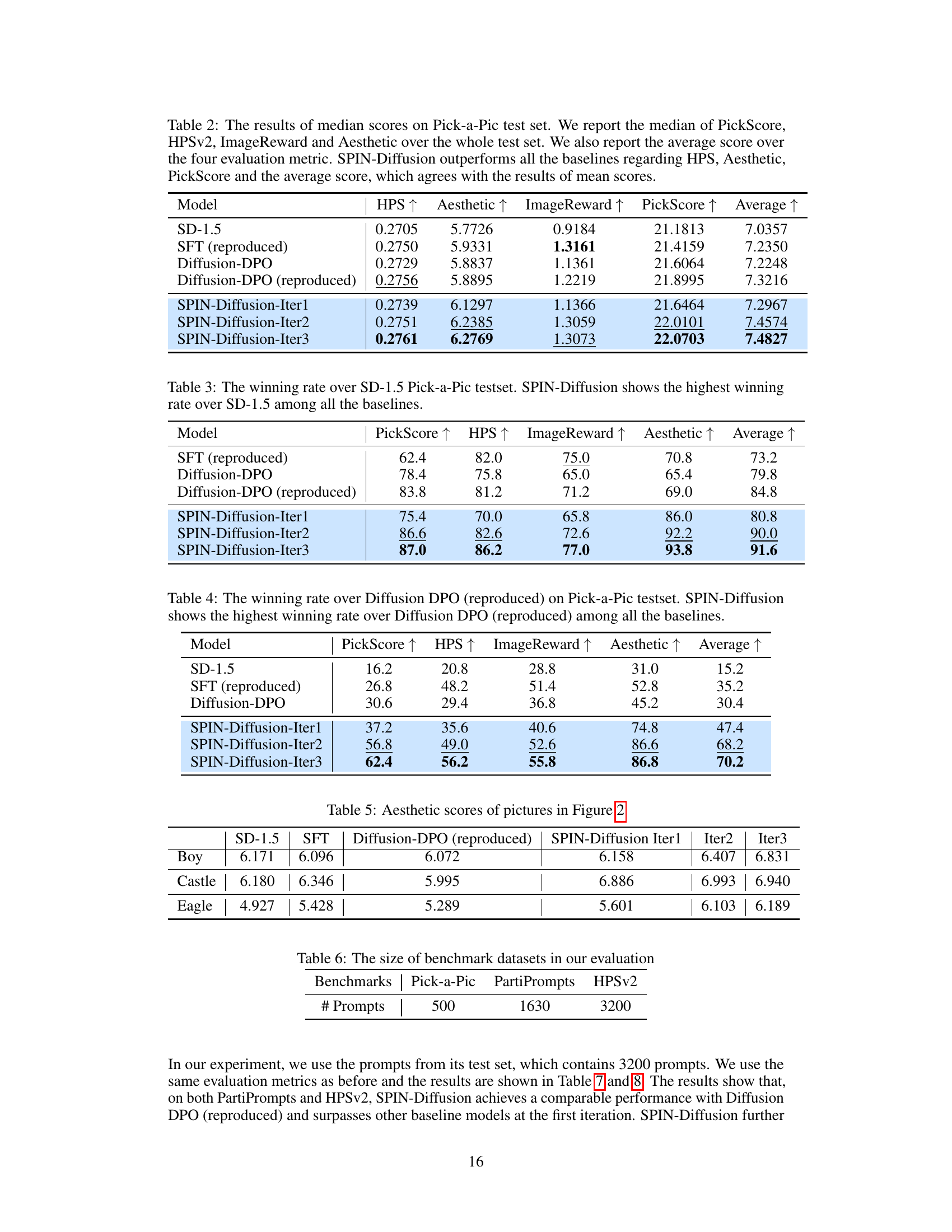
🔼 This table presents the median scores across four metrics (HPS, Aesthetic, ImageReward, PickScore) and their average for different models on the Pick-a-Pic test set. The models compared include SD-1.5 (baseline), SFT (reproduced), Diffusion-DPO, Diffusion-DPO (reproduced), and SPIN-Diffusion at various iterations (1, 2, 3). The results show SPIN-Diffusion consistently outperforms other methods, particularly in later iterations.
read the caption
Table 2: The results of median scores on Pick-a-Pic test set. We report the median of PickScore, HPSv2, ImageReward and Aesthetic over the whole test set. We also report the average score over the four evaluation metric. SPIN-Diffusion outperforms all the baselines regarding HPS, Aesthetic, PickScore and the average score, which agrees with the results of mean scores.
🔼 This table presents the winning rates of different models compared against the Stable Diffusion 1.5 model on the Pick-a-Pic test dataset. The winning rate is calculated as the percentage of prompts where a model’s generated images surpass the quality of those generated by SD-1.5, as measured across four metrics: PickScore, HPS, ImageReward, and Aesthetic. The table shows that SPIN-Diffusion consistently outperforms the other models, especially in later iterations.
read the caption
Table 3: The winning rate over SD-1.5 Pick-a-Pic testset. SPIN-Diffusion shows the highest winning rate over SD-1.5 among all the baselines.
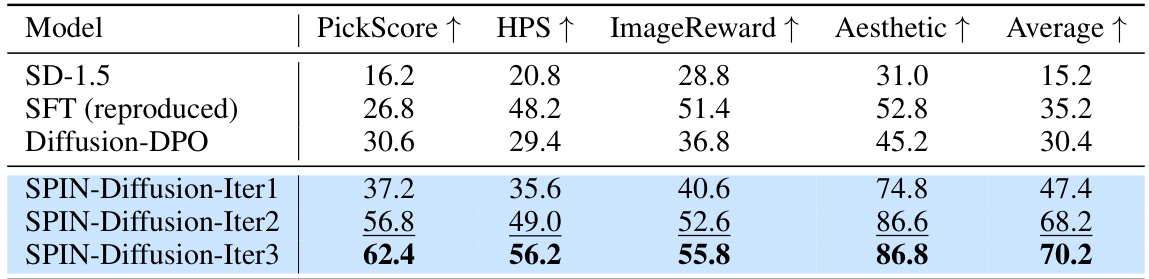
🔼 This table presents the winning rates of different models against the Diffusion-DPO (reproduced) model on the Pick-a-Pic test dataset. The winning rate is calculated as the percentage of prompts where a given model’s generated images surpass those generated by the Diffusion-DPO (reproduced) model in terms of quality. The metrics used for comparison are PickScore, HPS, ImageReward, and Aesthetic, and an average winning rate across these four metrics is also provided. The table shows how SPIN-Diffusion consistently outperforms other methods, particularly as the number of iterations increases, indicating its superior performance in image generation quality.
read the caption
Table 4: The winning rate over Diffusion DPO (reproduced) on Pick-a-Pic testset. SPIN-Diffusion shows the highest winning rate over Diffusion DPO (reproduced) among all the baselines.

🔼 This table shows the aesthetic scores assigned to the images produced by different models for three specific prompts in Figure 2. The scores provide a quantitative assessment of the visual appeal of the generated images, comparing the performance of SD-1.5, SFT, Diffusion-DPO (reproduced), and SPIN-Diffusion at various iterations.
read the caption
Table 5: Aesthetic scores of pictures in Figure 2

🔼 This table presents the quantitative results of the SPIN-Diffusion model and its baselines on the Pick-a-Pic test set. Four metrics are used to evaluate the generated images: PickScore, HPS, ImageReward, and Aesthetic score. The mean of each metric is reported for each model, along with an average score across the four metrics. The table highlights that SPIN-Diffusion outperforms the baselines (SD-1.5, SFT, and Diffusion-DPO) across all metrics.
read the caption
Table 1: The results on the Pick-a-Pic test set. We report the mean of PickScore, HPS, ImageReward and Aesthetic over the whole test set. We also report the average score over the three evaluation metrics. SPIN-Diffusion outperforms all the baselines in terms of four metrics. For this and following tables, we use blue background to indicate our method, bold numbers to denote the best and underlined for the second best.
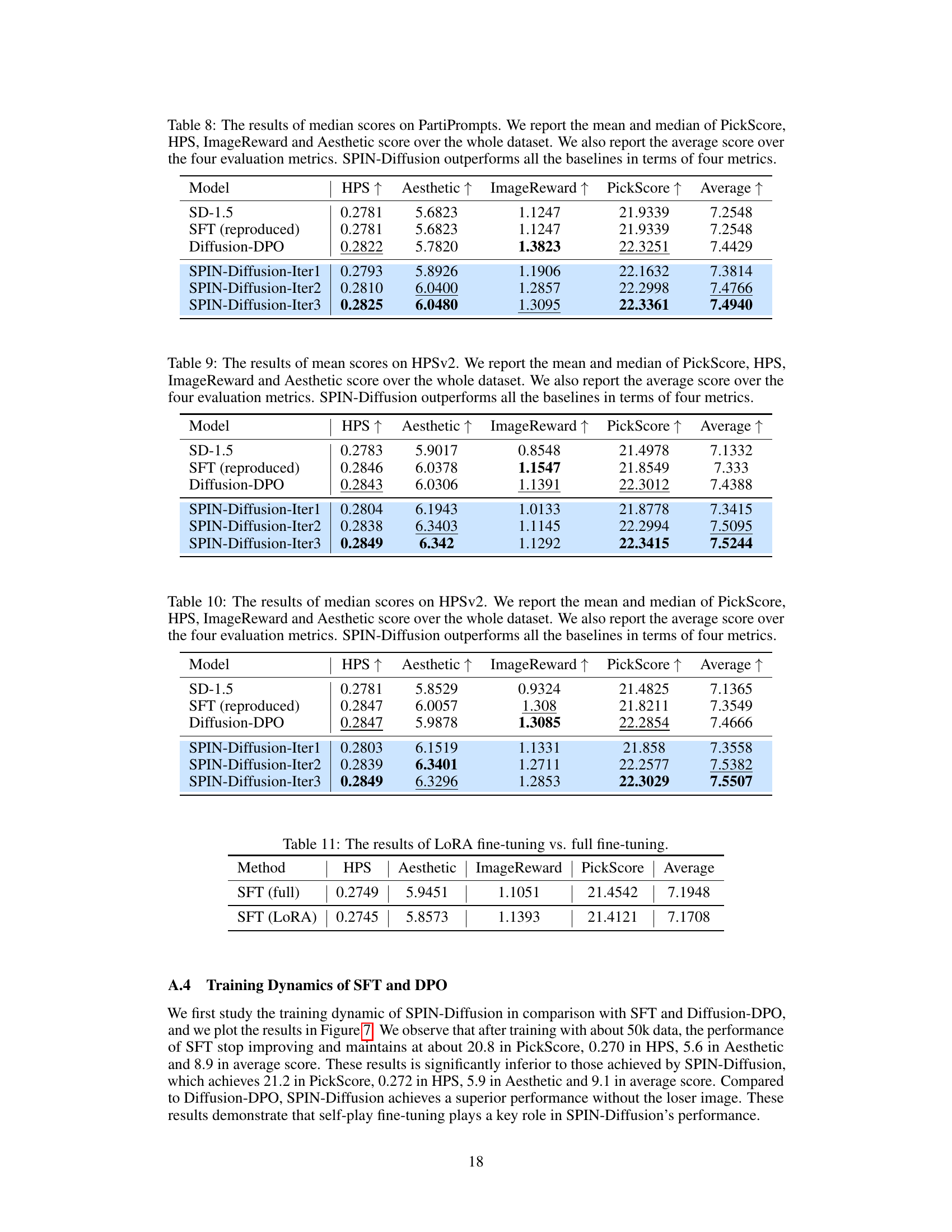
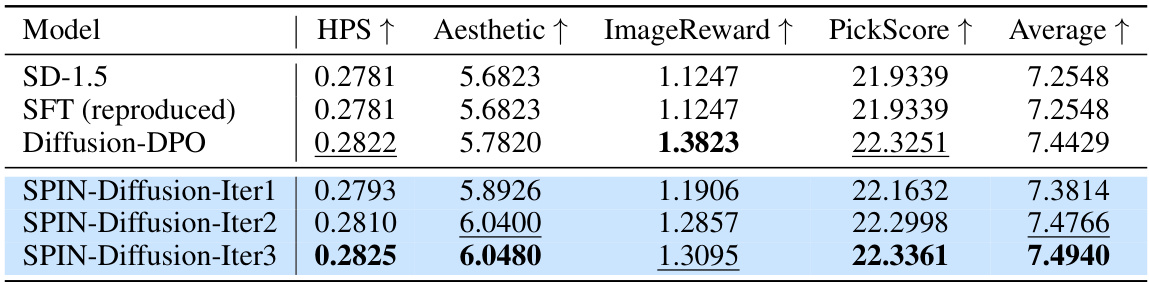
🔼 This table presents the average and median scores across four metrics (PickScore, HPS, ImageReward, and Aesthetic) for different models on the PartiPrompts dataset. The models compared include SD-1.5 (the baseline), SFT (supervised fine-tuning), Diffusion-DPO (Diffusion-Direct Preference Optimization), and SPIN-Diffusion at iterations 1, 2, and 3. The table demonstrates SPIN-Diffusion’s superior performance compared to the baselines across all metrics.
read the caption
Table 7: The results of mean scores on PartiPrompts. We report the mean and median of PickScore, HPS, ImageReward and Aesthetic score over the whole dataset. We also report the average score over the four evaluation metrics. SPIN-Diffusion outperforms all the baselines in terms of four metrics.
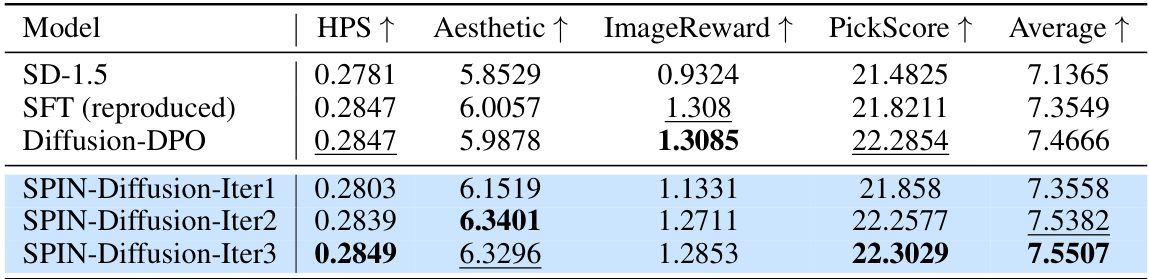
🔼 This table presents the median scores achieved by different models (SD-1.5, SFT, Diffusion-DPO, and SPIN-Diffusion across iterations 1-3) on the PartiPrompts benchmark. The metrics used are PickScore, HPS, ImageReward, and Aesthetic, reflecting various aspects of image quality and alignment with human preferences. The average score across the four metrics is also reported. The table highlights SPIN-Diffusion’s superior performance compared to the baseline models.
read the caption
Table 8: The results of median scores on PartiPrompts. We report the median of PickScore, HPS, ImageReward and Aesthetic score over the whole dataset. We also report the average score over the four evaluation metrics. SPIN-Diffusion outperforms all the baselines in terms of four metrics.

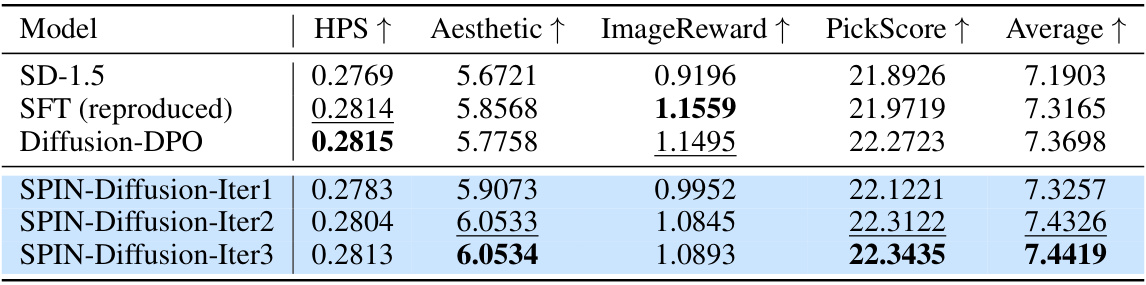
🔼 This table presents the mean scores achieved by different models on the HPSv2 benchmark. The metrics include HPS, Aesthetic score, ImageReward, and PickScore. The average of these four scores is also reported. The results show that SPIN-Diffusion consistently outperforms the baseline models (SD-1.5, SFT, and Diffusion-DPO) across all metrics, demonstrating its superior performance in aligning with human preferences and generating visually appealing images.
read the caption
Table 9: The results of mean scores on HPSv2. We report the mean and median of PickScore, HPS, ImageReward and Aesthetic score over the whole dataset. We also report the average score over the four evaluation metrics. SPIN-Diffusion outperforms all the baselines in terms of four metrics.
🔼 This table presents the quantitative results of the proposed SPIN-Diffusion model and baseline methods (SD-1.5, SFT, and Diffusion-DPO) on the Pick-a-Pic test set. The metrics used are PickScore, HPS, ImageReward, and Aesthetic. The table shows the mean scores for each metric across all prompts in the test set and also calculates the average across all four metrics. The superior performance of SPIN-Diffusion is highlighted by bolding the best-performing model for each metric and underlining the second-best model. This demonstrates SPIN-Diffusion’s superiority across multiple aspects of image generation quality.
read the caption
Table 1: The results on the Pick-a-Pic test set. We report the mean of PickScore, HPS, ImageReward and Aesthetic over the whole test set. We also report the average score over the three evaluation metrics. SPIN-Diffusion outperforms all the baselines in terms of four metrics. For this and following tables, we use blue background to indicate our method, bold numbers to denote the best and underlined for the second best.

🔼 This table presents the quantitative results of the SPIN-Diffusion model and several baseline models on the Pick-a-Pic test set. Four metrics are used to evaluate the models: PickScore, HPS, ImageReward, and Aesthetic. The table shows the mean score for each metric for each model, as well as the average of the three evaluation metrics. The results show that the SPIN-Diffusion model consistently outperforms the baseline models across all metrics.
read the caption
Table 1: The results on the Pick-a-Pic test set. We report the mean of PickScore, HPS, ImageReward and Aesthetic over the whole test set. We also report the average score over the three evaluation metrics. SPIN-Diffusion outperforms all the baselines in terms of four metrics. For this and following tables, we use blue background to indicate our method, bold numbers to denote the best and underlined for the second best.
Full paper#