↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Cross-modal retrieval using hashing is attractive due to its speed and efficiency, but existing methods often suffer from poor feature representation and difficulty in capturing semantic associations. This limits their accuracy and applicability, particularly in real-world scenarios such as social media search where diverse data types and complexities are involved. Current methods often rely on manually-designed features or struggle with the high dimensionality of data.
To overcome these challenges, this paper introduces EGATH (End-to-End Graph Attention Network Hashing), a novel supervised hashing method. EGATH leverages CLIP for powerful feature extraction, transformers to capture global semantic information, and graph attention networks to model complex relationships between labels, thus enhancing semantic representation. An optimization strategy and loss function ensure hash code compactness and semantic preservation. Extensive experiments demonstrate EGATH’s significant performance improvements over existing state-of-the-art methods on several benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is significant for researchers in cross-modal retrieval due to its novel approach using graph attention networks and CLIP for enhanced semantic understanding and feature representation. It offers a state-of-the-art method, opens avenues for further research in cross-modal hashing, and addresses the limitations of existing hashing techniques. The improved accuracy and efficiency have practical implications for applications like social media search.
Visual Insights#
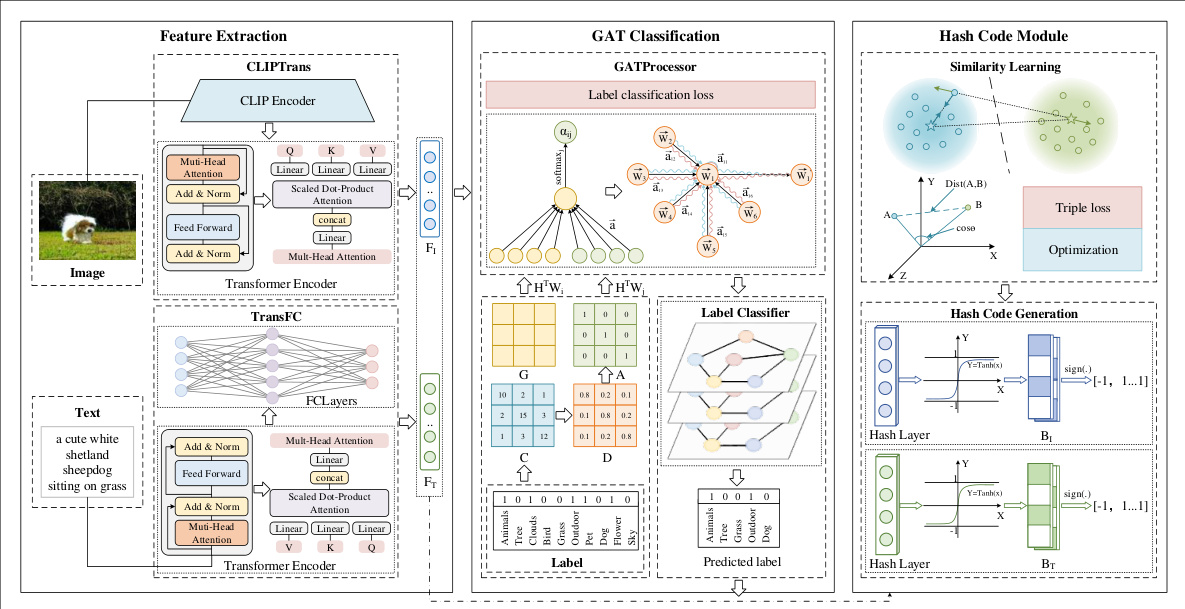
This figure illustrates the EGATH (End-to-End Graph Attention Network Hashing) framework, which is composed of three modules: 1) Feature Extraction, where CLIP and transformers are used to extract image and text features respectively. 2) GAT Classification, using a Graph Attention Network to classify labels and enhance feature representation. 3) Hash Code Module, using similarity learning and a triple loss function to generate compact and semantically informative hash codes. The figure shows the data flow and connections between these three modules.

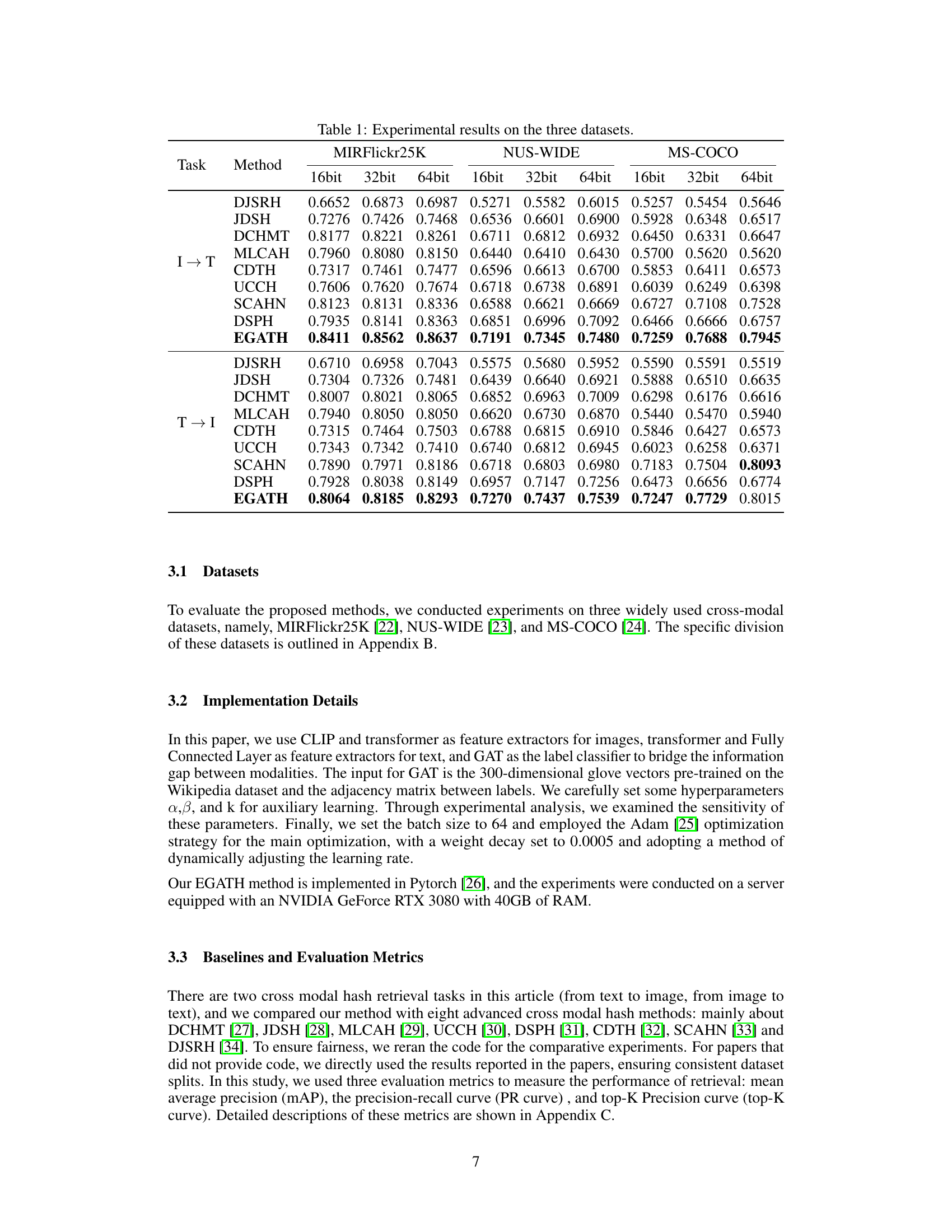
This table presents the quantitative results of the proposed EGATH model and several baseline methods on three benchmark datasets: MIRFlickr25K, NUS-WIDE, and MS-COCO. The results are categorized by the task (image-to-text retrieval (I→T) and text-to-image retrieval (T→I)) and the bit length of the hash code (16-bit, 32-bit, and 64-bit). Each cell shows the performance metric (likely MAP or a similar measure of retrieval accuracy) achieved by each method on each dataset and hash length combination. The table allows for a direct comparison of EGATH against state-of-the-art cross-modal hashing methods in terms of retrieval accuracy across different datasets and hash code lengths.
In-depth insights#
EGATH Framework#
The EGATH framework, an end-to-end graph attention network hashing system for cross-modal retrieval, integrates CLIP and transformer models for robust feature extraction. CLIP processes images, while a transformer handles text, creating semantically consistent representations. A crucial innovation is the incorporation of a graph attention network (GAT) classifier. This module leverages label co-occurrence information to enrich feature representations and improve the discriminative power of the model. The framework employs a unique hash code module, which utilizes both a cosine similarity function and a ternary loss function to ensure compact and semantically preserved hash codes. This combined approach leads to significant improvements in cross-modal retrieval performance, outperforming state-of-the-art methods on benchmark datasets. The optimization strategy within EGATH balances compactness and semantic preservation of the hash code, ensuring effective retrieval. The use of GAT allows for a more sophisticated understanding of label relationships, leading to superior feature representations.
CLIP & GAT Fusion#
A hypothetical “CLIP & GAT Fusion” section in a cross-modal retrieval paper would likely detail the integration of CLIP (Contrastive Language–Image Pre-training) and GAT (Graph Attention Network) for enhanced feature representation and semantic alignment. CLIP’s strength lies in generating rich, multimodal embeddings that capture the semantic relationship between images and their text descriptions. This provides a powerful starting point for cross-modal comparison. However, CLIP alone might miss crucial fine-grained relationships between different elements within a modality. Here, GAT steps in. Its ability to model relationships between nodes in a graph makes it ideal for capturing the intricate structure of image features (e.g., object relationships, scene context) or the complex interactions within a text corpus (e.g., word dependencies, topic modeling). By fusing CLIP’s semantic embeddings with GAT’s relational understanding, the system could achieve a more nuanced and comprehensive representation of both image and text data. This fusion would be critical in addressing the limitations of traditional methods that often rely on simpler feature extractors, potentially leading to improved accuracy and robustness in cross-modal retrieval tasks. The integration strategy could involve concatenating CLIP’s embeddings with GAT’s output, using GAT’s output to modulate CLIP’s embeddings, or other more sophisticated fusion methods. The effectiveness of the chosen fusion would be demonstrated experimentally, showing superior performance compared to methods using CLIP or GAT in isolation.
Hash Code Design#
Designing effective hash codes is crucial for cross-modal retrieval. The ideal hash function should map similar data points to similar hash codes while ensuring dissimilar data points have distinct codes. This balance is critical for efficient search and retrieval. Several factors influence hash code design, including the dimensionality of the feature vectors, the length of the hash codes (bit-length), and the specific hash function used. The choice of hash function often involves a trade-off between computational efficiency and the quality of the hash codes. Some methods employ simple binarization techniques, directly thresholding feature values. More sophisticated methods may incorporate dimensionality reduction techniques like PCA or autoencoders to reduce computation and increase efficiency. Furthermore, the learning process of the hash function should integrate with the overall model architecture, potentially involving loss functions that explicitly encourage similar data points to have similar codes and dissimilar points to have disparate codes. Advanced techniques may also incorporate semantic information in the design, leveraging domain knowledge or learned embeddings to improve retrieval performance. Ultimately, the effectiveness of a hash code design is evaluated by its impact on retrieval accuracy and efficiency.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a detailed comparative analysis of the proposed method against existing state-of-the-art techniques. This would involve using established metrics (like mean Average Precision (mAP), precision-recall curves, F1-scores, etc.) to evaluate performance across multiple benchmark datasets. Crucially, the choice of datasets should be justified, reflecting their diversity and relevance to the problem domain. The results should be presented clearly, perhaps using tables and graphs to compare performance across various parameters (e.g., different bit lengths for hash codes, different dataset sizes). A discussion of statistical significance testing would lend further credence to the findings. Moreover, a thorough analysis should identify strengths and weaknesses of the proposed method relative to benchmarks. For instance, does the new method excel in specific scenarios (e.g., high-dimensional data, imbalanced classes) while underperforming in others? This comparative analysis isn’t just about raw numbers; it necessitates insightful interpretation to highlight the novel contributions and potential limitations of the research. A thoughtful analysis of these results will significantly improve the paper’s overall impact and persuasiveness.
Future Research#
Future research directions stemming from this cross-modal hashing method could explore several promising avenues. Extending the model to handle diverse data modalities beyond images and text, such as audio and video, is a natural next step. This would involve designing appropriate feature extraction methods for these modalities and adapting the graph attention mechanism to effectively integrate the resulting representations. Addressing the computational complexity associated with the graph attention network (GAT) is crucial for scalability. Exploring more efficient graph neural network architectures or approximation techniques could improve performance with significantly larger datasets and more numerous labels. Investigating the robustness of the model to noisy or incomplete data is vital for real-world applications, especially with unstructured social media data. This might involve incorporating data augmentation strategies or exploring more resilient loss functions. The sensitivity to hyperparameter tuning could be improved through more sophisticated optimization techniques, automatic hyperparameter search algorithms, or theoretical analysis to guide the selection of optimal values. Finally, a thorough evaluation of the model’s fairness and ethical implications is necessary, particularly regarding potential biases in the training data or discriminatory outcomes in retrieval results.
More visual insights#
More on figures

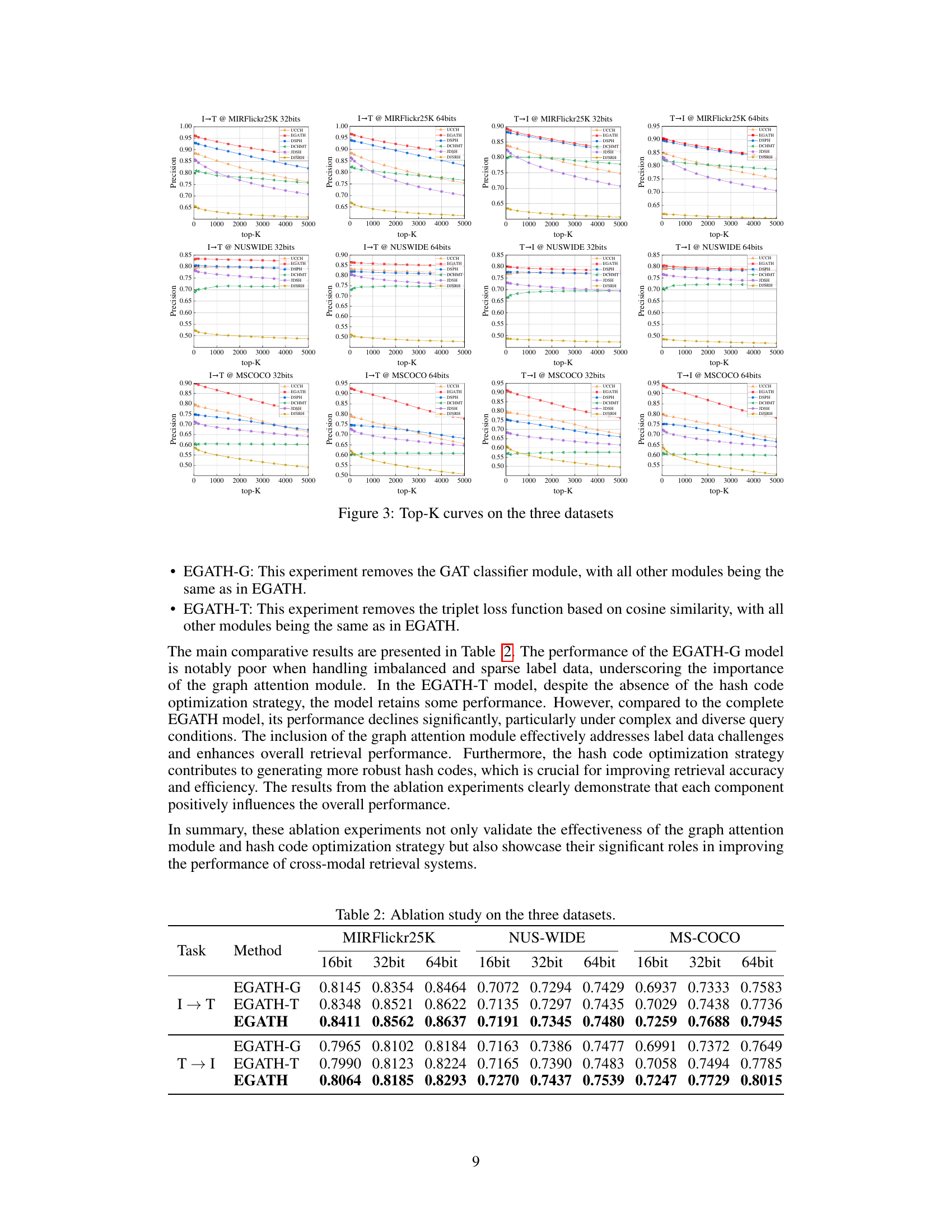
This figure presents the Precision-Recall (PR) curves for the image-to-text (I→T) and text-to-image (T→I) retrieval tasks across three datasets: MIRFlickr25K, NUS-WIDE, and MS-COCO. Each dataset is shown with curves for 32-bit and 64-bit hash codes. The curves visually compare the performance of the proposed EGATH method against several state-of-the-art baselines (UCCH, EGATH, DSPH, DCHMT, JDSH, DJSRH). The curves illustrate the trade-off between precision and recall at various threshold settings for each method, allowing for a visual comparison of retrieval effectiveness.
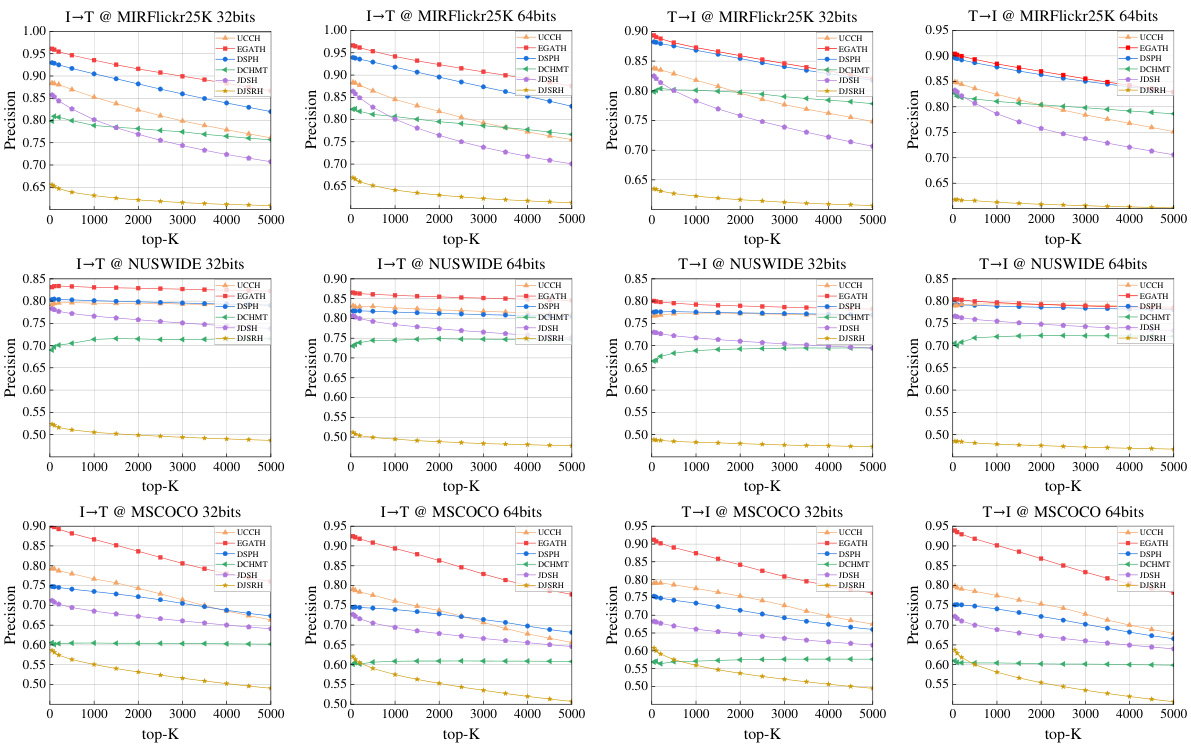
This figure presents the precision-recall (PR) curves for image-to-text and text-to-image retrieval tasks across three datasets (MIRFlickr25K, NUS-WIDE, and MS-COCO) using different bit lengths (32-bit and 64-bit). The curves compare the proposed EGATH method against several state-of-the-art cross-modal hashing methods. The PR curves visually demonstrate the trade-off between precision and recall at different threshold settings for each method on the three datasets, providing a comprehensive view of model performance across various thresholds.

This figure shows the precision-recall (PR) curves for the three datasets (MIRFlickr25K, NUS-WIDE, and MS-COCO) for both image-to-text (I→T) and text-to-image (T→I) retrieval tasks. The curves compare the performance of the proposed EGATH method against several state-of-the-art methods (DSPH, DCHMT, JDSH, DJSRH, UCCH). The PR curves illustrate the trade-off between precision and recall at various threshold levels for each method, providing a comprehensive view of their performance across different retrieval scenarios. The results visually demonstrate the superiority of EGATH across different datasets and retrieval tasks.
More on tables
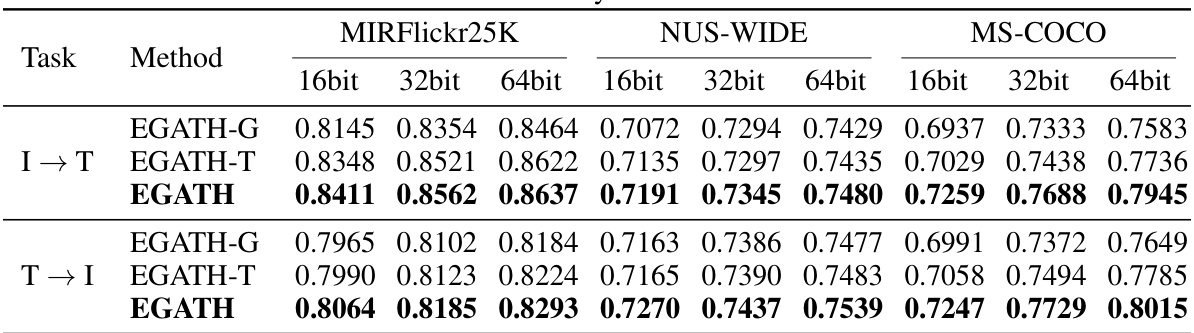
This table presents the quantitative performance comparison of the proposed EGATH model against several state-of-the-art cross-modal hashing methods. The results are broken down by dataset (MIRFlickr25K, NUS-WIDE, MS-COCO), hashing code length (16-bit, 32-bit, 64-bit), and retrieval task (image-to-text (I→T) and text-to-image (T→I)). Higher values indicate better performance.
This table presents the quantitative results of the proposed EGATH model and other state-of-the-art cross-modal hashing methods on three benchmark datasets (MIRFlickr25K, NUS-WIDE, and MS-COCO). The results are broken down by dataset, hash code length (16-bit, 32-bit, and 64-bit), and retrieval task (image-to-text (I→T) and text-to-image (T→I)). The table allows for a comparison of the performance of EGATH against existing methods, demonstrating its superior performance across various settings.
Full paper#