TL;DR#
Large Language Models (LLMs) often struggle with complex, long-form text inputs, limiting their performance on sophisticated NLP tasks. Simply increasing model size is resource-intensive and not always effective. This paper addresses these limitations by focusing on improving how LLMs process information.
The researchers propose “context structurization,” a novel method that transforms unstructured text into a well-organized, hierarchical structure before feeding it to the LLM. Their experiments, conducted across various LLMs and NLP tasks, reveal significant and consistent performance improvements with this single-round structurization. They also demonstrate the feasibility of distilling this structurization ability from large LLMs into smaller, more efficient models. This offers a resource-efficient way to improve LLM comprehension and opens up new research directions.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs because it introduces a novel approach to enhance their cognitive abilities without increasing model size, a significant hurdle in current research. The proposed method, context structurization, offers a practical solution for improving LLM comprehension of complex information, impacting diverse NLP tasks. This opens new avenues for investigating efficient LLM enhancement and knowledge distillation techniques.
Visual Insights#
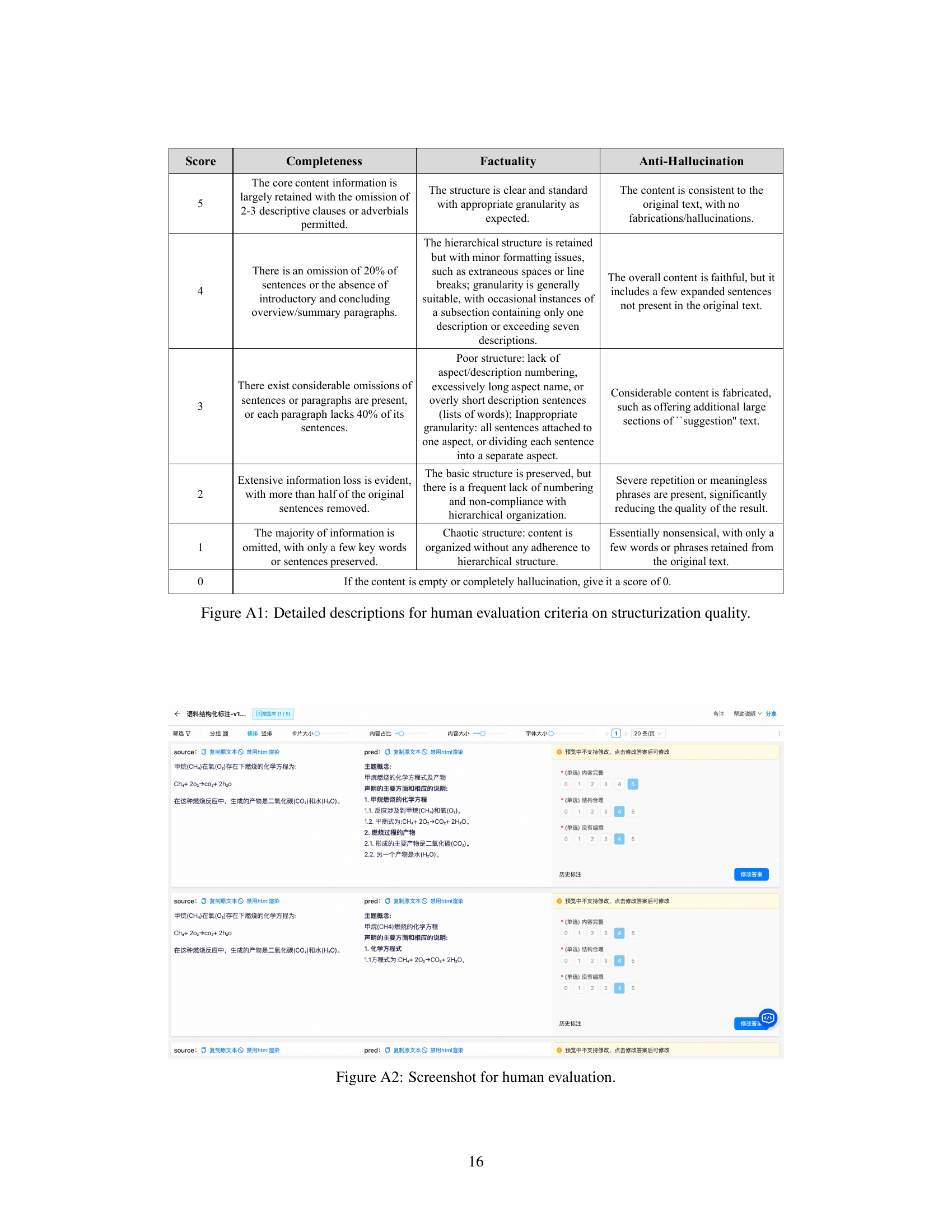
🔼 This figure illustrates the human process of understanding a text. It shows how humans don’t just read sequentially, but rather organize information into a hierarchical structure. Starting with the overall topic (Scope), they then break it down into key aspects, each supported by detailed descriptions. This structured understanding allows for efficient information retrieval and comparison.
read the caption
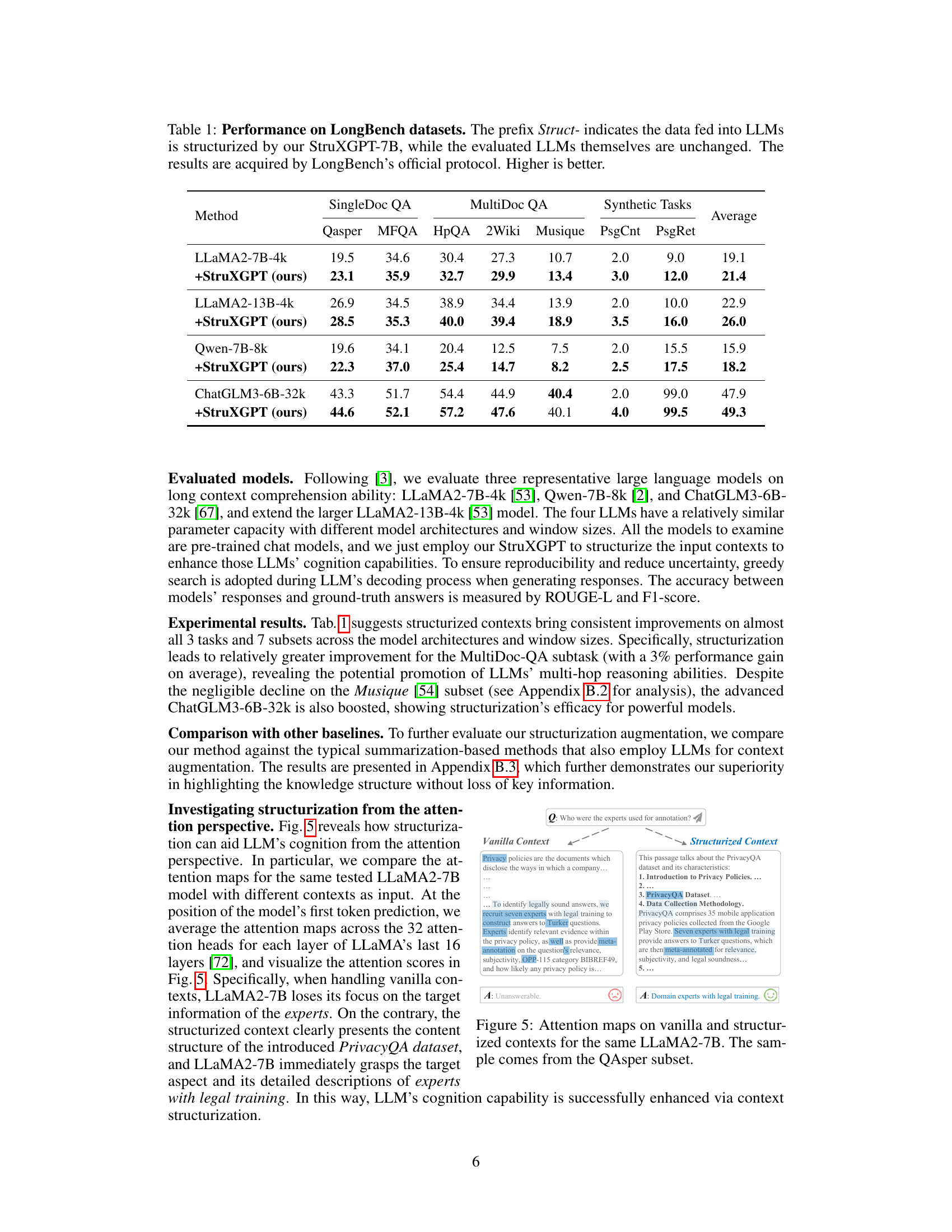
Figure 1: Structured cognition on sequential contexts. Humans may easily identify a given passage's topic/scope, break down the text sentences into several aspect points with detailed descriptions, and form a tree-like knowledge structure.
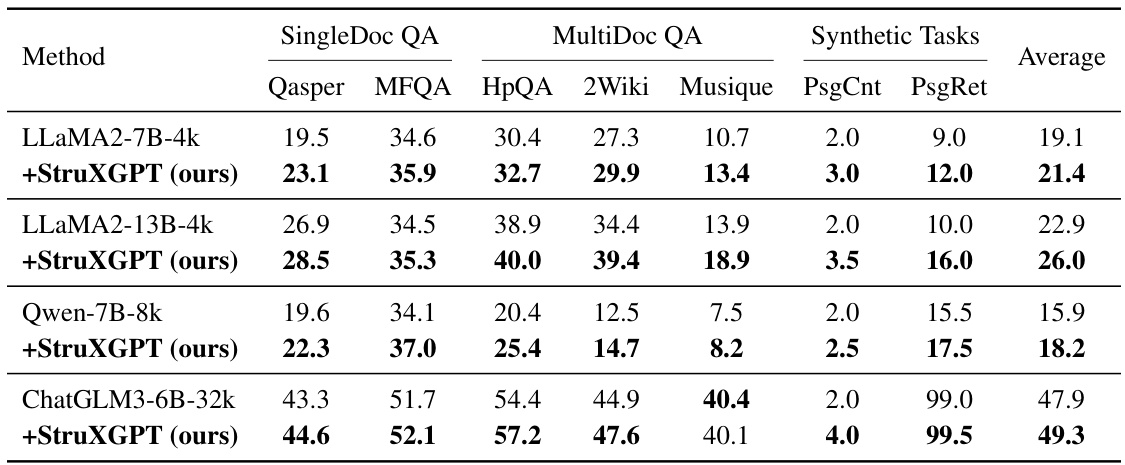
🔼 This table presents the performance of several LLMs on the LongBench dataset for question answering. The performance is measured before and after applying the StruXGPT structurization technique. Higher scores indicate better performance. The table shows results across different LLMs and variations of the LongBench dataset, allowing for comparison of the method’s impact across model architectures, sizes, and task types.
read the caption
Table 1: Performance on LongBench datasets. The prefix Struct- indicates the data fed into LLMs is structurized by our StruXGPT-7B, while the evaluated LLMs themselves are unchanged. The results are acquired by LongBench's official protocol. Higher is better.
In-depth insights#
LLM Cognition Boost#
Enhancing Large Language Model (LLM) cognition is a crucial area of research. A potential approach, structurization, involves transforming unstructured text into a hierarchical format mimicking human cognitive processes. This allows LLMs to process information more effectively, leading to a significant cognitive boost. The effectiveness of structurization has been shown across diverse LLM architectures and sizes, demonstrating consistent performance gains on various NLP tasks, including question answering and hallucination detection. Structurization’s core strength lies in its capacity to improve comprehension of complex and lengthy contexts, a weakness often highlighted in current LLMs. This approach does not require altering the underlying LLM architecture, making it a practical and resource-efficient method to enhance cognitive abilities. The benefits extend beyond simple performance improvements, potentially fostering more human-like understanding and reasoning within LLMs. While still an emerging concept, structurization provides a promising avenue to unlock the full potential of LLMs, potentially bridging the gap between current capabilities and human-level intelligence. Further research is needed to fully explore its potential and address any limitations.
Structurization Method#
The hypothetical ‘Structurization Method’ section of a research paper would delve into the specific techniques used to transform unstructured text data into a structured format. This process likely involves several key steps, beginning with natural language processing techniques to identify key entities, relationships, and semantic structures within the text. Information extraction methods would then be applied to isolate relevant facts and assertions. A crucial aspect would be the design of the knowledge representation schema, defining how extracted information is organized into a structured format, potentially employing ontologies, knowledge graphs, or hierarchical tree structures to model relationships and context. The chosen representation would significantly impact the effectiveness of downstream tasks. The method would also need to address challenges like handling ambiguities and inconsistencies inherent in unstructured text and ensuring the accuracy and completeness of the structured representation. Finally, the section should detail the algorithm or system architecture that automates the transformation process, specifying implementation choices (e.g., specific NLP libraries, database systems, etc.) and evaluating the method’s efficiency, scalability, and overall performance. Crucially, the paper should discuss potential limitations and considerations for different types of text and applications.
Multi-task Evaluation#
A multi-task evaluation framework is crucial for assessing the robustness and generalizability of a machine learning model, especially large language models (LLMs). Instead of focusing on a single, isolated task, a multi-task approach evaluates performance across a diverse range of tasks. This holistic approach reveals strengths and weaknesses that might be missed with single-task evaluations. For LLMs, a diverse set of tasks—including question answering, text summarization, translation, and common sense reasoning—is vital to establish a model’s overall capability. The selection of tasks should consider various levels of complexity and types of reasoning. A comprehensive evaluation must also account for biases across different tasks and datasets. This helps to understand if the model exhibits consistent performance or is prone to biases toward specific tasks. Analyzing performance across various tasks provides a more nuanced and reliable assessment of the model, revealing its true capabilities and potential limitations. By using this framework, developers can pinpoint areas for improvement and work towards building more robust and reliable models that perform well in real-world applications.
StruXGPT Efficiency#
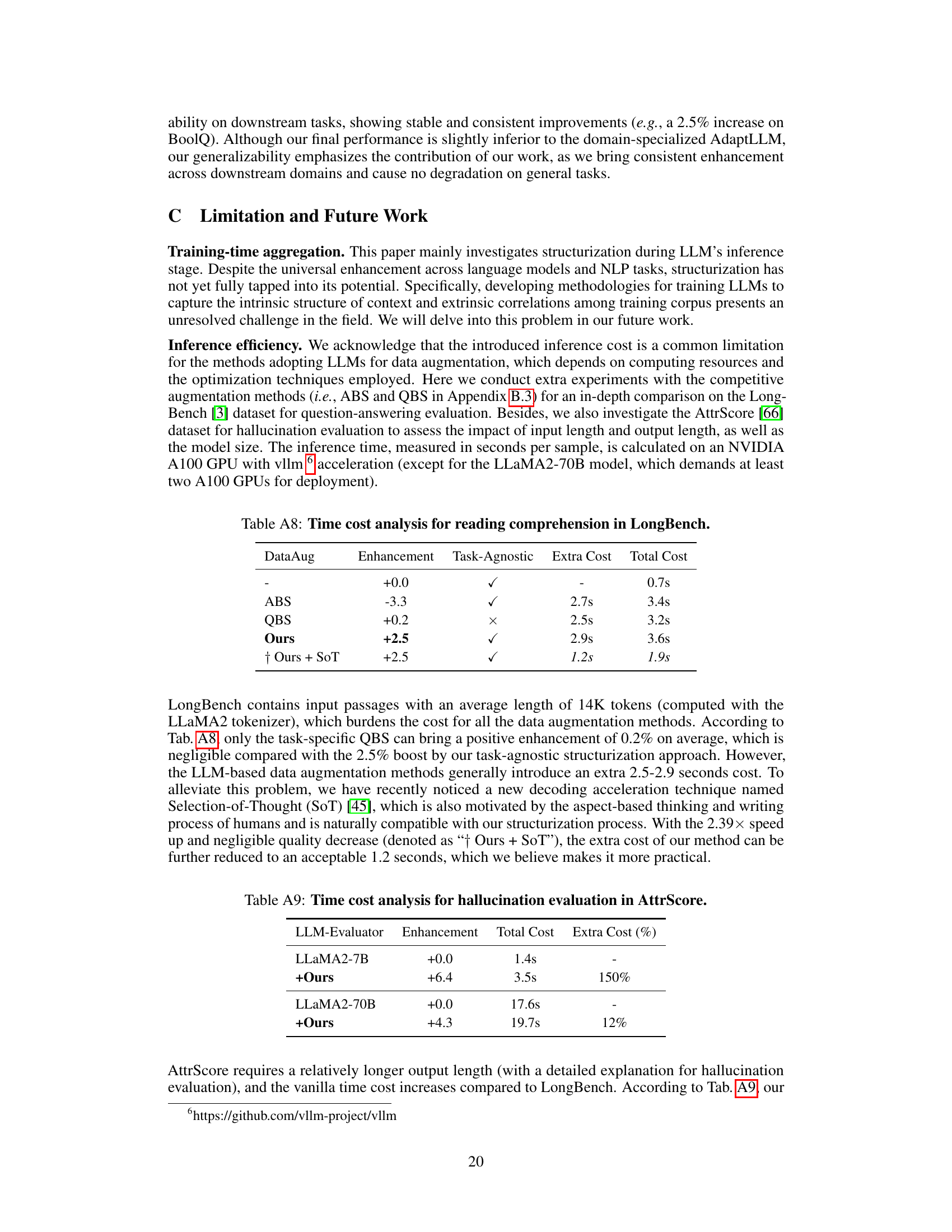
Analyzing StruXGPT efficiency requires a multifaceted approach. Data quality significantly influences performance; using only a few high-quality examples for few-shot learning proves surprisingly effective. While increasing examples might improve results, it also increases computational costs. Model size presents a trade-off: smaller models are more efficient but may not fully capture the nuances of structurization, while larger models, though more accurate, demand greater resources. The choice of base model (LLaMA vs. Qwen) also impacts efficiency and performance, potentially due to differences in architectural design. Distillation from a large model to a smaller StruXGPT proves a valuable strategy for balancing accuracy and efficiency, although some performance loss is inevitable. Finally, the efficiency of StruXGPT can be further enhanced by techniques such as Selection-of-Thought (SoT), which speeds up inference without significantly sacrificing accuracy. Therefore, optimizing StruXGPT efficiency involves carefully considering these interconnected factors to achieve the desired balance between accuracy and resource consumption.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the efficiency of the structurization process is key; this could involve exploring more efficient algorithms or leveraging model compression techniques to reduce computational costs associated with large language models. Investigating the generalizability of structurization across diverse NLP tasks and languages is another important area, requiring evaluation across a wider range of datasets and language families. Furthermore, research should delve deeper into the interplay between structurization and various LLMs, investigating the impact of model architecture and size on the effectiveness of structurization. The integration of structurization with other LLM enhancement techniques such as chain-of-thought prompting or retrieval-augmented generation warrants investigation. Finally, a more comprehensive exploration of the ethical implications and societal impacts of structurization, addressing potential misuse and bias, is crucial before widespread deployment.
More visual insights#
More on figures

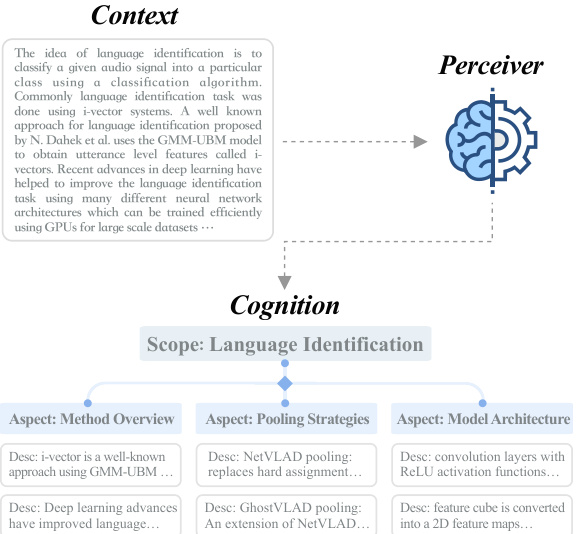
🔼 This figure illustrates the core idea of the paper: context structurization. It shows how Large Language Models (LLMs) struggle to answer questions accurately when presented with long and complex (vanilla) contexts. The proposed solution is to pre-process the context using the StruXGPT model, organizing it into a structured format (structurized context) that highlights the main points and aspects. This allows the LLMs to better understand the context and provide more accurate responses. The diagram visually represents the improvement in the LLM’s ability to generate accurate answers using the structurized version of the context.
read the caption
Figure 2: Framework overview. When instructed to generate responses based on vanilla long-form and sophisticated contexts, LLMs often lose their focus and give unreliable answers due to their limited cognition capability. In contrast, we structurize the vanilla context by using our StruXGPT to identify its main scope and aspect points, facilitating the original LLMs to comprehend the context and generate accurate responses.

🔼 This figure illustrates the human cognitive process of understanding sequential contexts. It shows how humans naturally organize information hierarchically, starting with identifying the main topic or scope. Then, they break down the text into key aspects and further elaborate on each aspect with detailed descriptions. This creates a structured representation of the information, which is more easily processed and remembered than a linear sequence of sentences. This figure motivates the paper’s core concept of context structurization, which aims to replicate this human cognitive process in LLMs.
read the caption
Figure 1: Structured cognition on sequential contexts. Humans may easily identify a given passage's topic/scope, break down the text sentences into several aspect points with detailed descriptions, and form a tree-like knowledge structure.

🔼 This figure demonstrates two different methods of transforming structured data back into natural language for LLMs to process. The left side shows general templates to maintain the structured knowledge hierarchy using specific linguistic markers. The right side provides examples of these templates applied to reading comprehension and hallucination detection tasks. This transformation helps LLMs better understand the information in long-form text by presenting it in a clear and structured format.
read the caption
Figure 4: Left: templates to transform structurization results into natural languages, with special linguistic markers to preserve and highlight the extracted knowledge structure. Right: transformed context examples with clear information structure for long-form reading comprehension (upper) and hallucination detection (lower) tasks.

🔼 This figure illustrates the core idea of the paper: context structurization. It shows how LLMs, when given unstructured long-form text, struggle to generate accurate responses because of their limited ability to grasp complex, multifaceted information. The framework proposes using StruXGPT to transform the unstructured context into a structured representation (highlighting scope and aspects). This structured input helps LLMs to focus, understand the context, and consequently generate more accurate and reliable answers.
read the caption
Figure 2: Framework overview. When instructed to generate responses based on vanilla long-form and sophisticated contexts, LLMs often lose their focus and give unreliable answers due to their limited cognition capability. In contrast, we structurize the vanilla context by using our StruXGPT to identify its main scope and aspect points, facilitating the original LLMs to comprehend the context and generate accurate responses.
🔼 This figure illustrates the concept of structured cognition in humans when processing sequential contexts. It shows how humans don’t just read text linearly but instead identify the main topic (scope), break it down into key aspects, and then elaborate on each aspect with detailed descriptions. This creates a hierarchical understanding of the text, similar to a tree structure. This is in contrast to how LLMs typically process text sequentially, which the paper argues limits their understanding of complex information.
read the caption
Figure 1: Structured cognition on sequential contexts. Humans may easily identify a given passage's topic/scope, break down the text sentences into several aspect points with detailed descriptions, and form a tree-like knowledge structure.

🔼 This figure illustrates the core concept of the paper, which is to enhance LLMs’ ability to understand complex text by first structuring it using StruXGPT. The left side shows the process of transforming a vanilla context into a structured format, and the right side shows the subsequent processing by the LLM, which results in accurate responses compared to processing the vanilla text.
read the caption
Figure 2: Framework overview. When instructed to generate responses based on vanilla long-form and sophisticated contexts, LLMs often lose their focus and give unreliable answers due to their limited cognition capability. In contrast, we structurize the vanilla context by using our StruXGPT to identify its main scope and aspect points, facilitating the original LLMs to comprehend the context and generate accurate responses.
More on tables
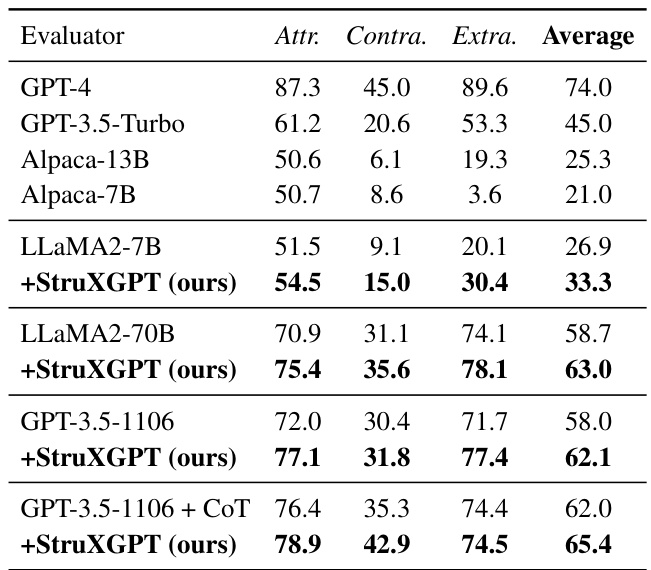
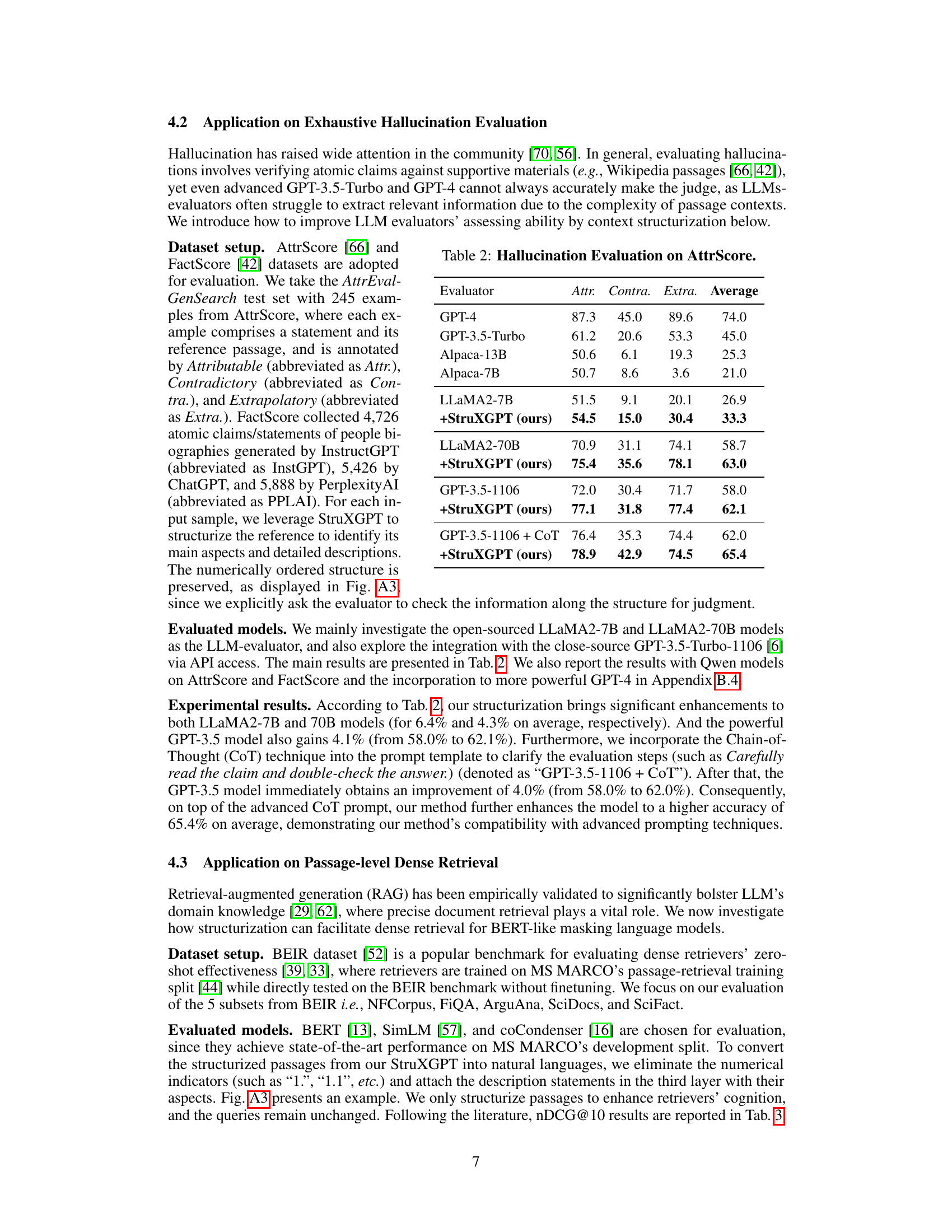
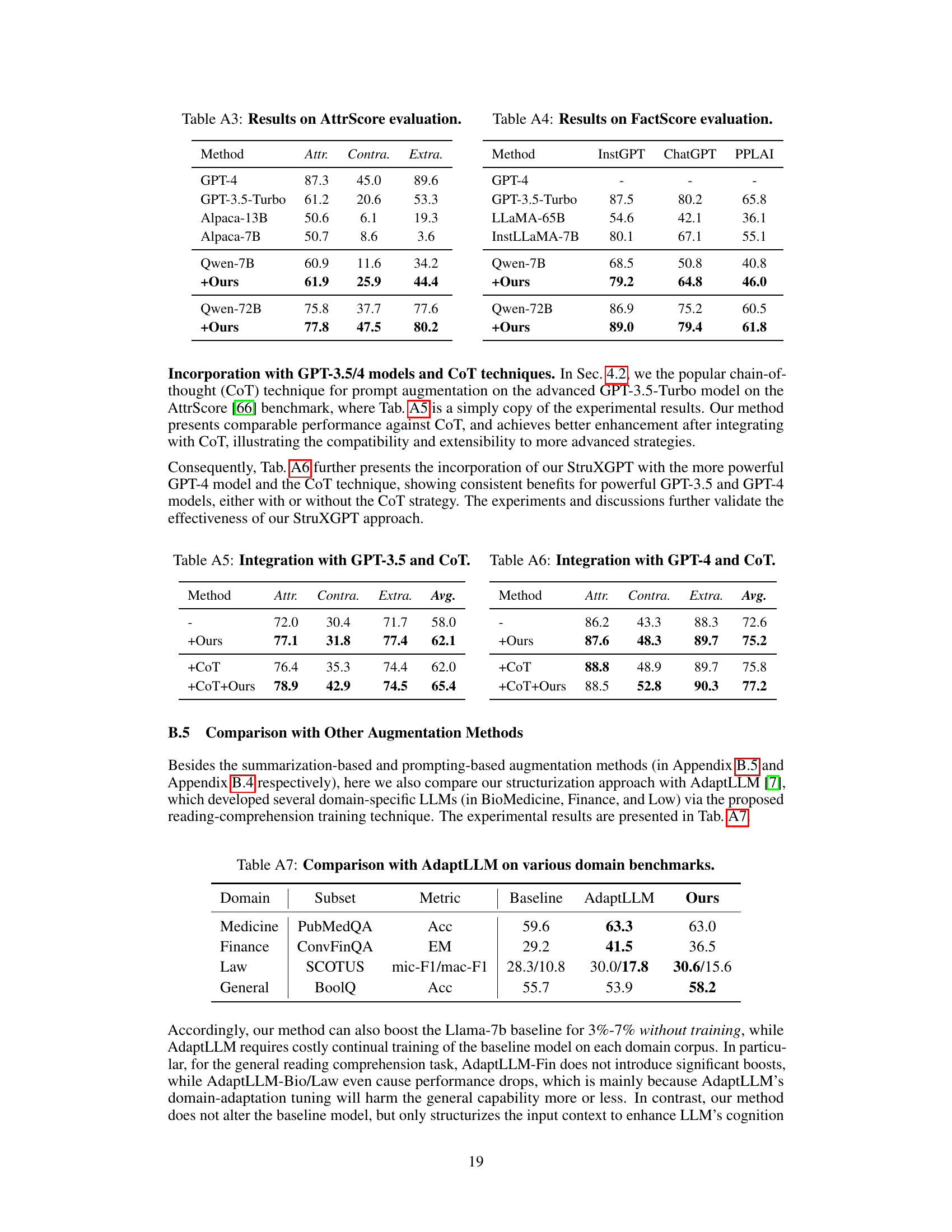
🔼 This table presents the results of evaluating hallucination on the AttrScore dataset. Several large language models (LLMs), both with and without the proposed structurization method, were used as evaluators. The table shows the performance of each model in terms of precision for three types of hallucinations: Attributable (Attr.), Contradictory (Contra.), and Extrapolatory (Extra.). The average performance across all three hallucination types is also shown. The results demonstrate the effectiveness of the structurization technique in improving the accuracy of hallucination detection by LLMs.
read the caption
Table 2: Hallucination Evaluation on AttrScore.
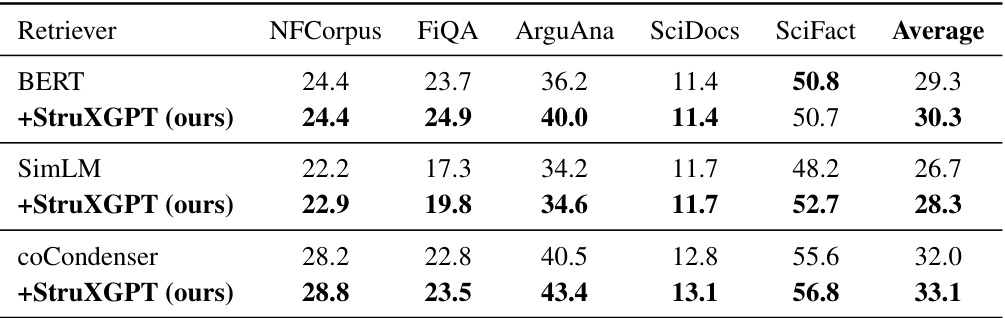
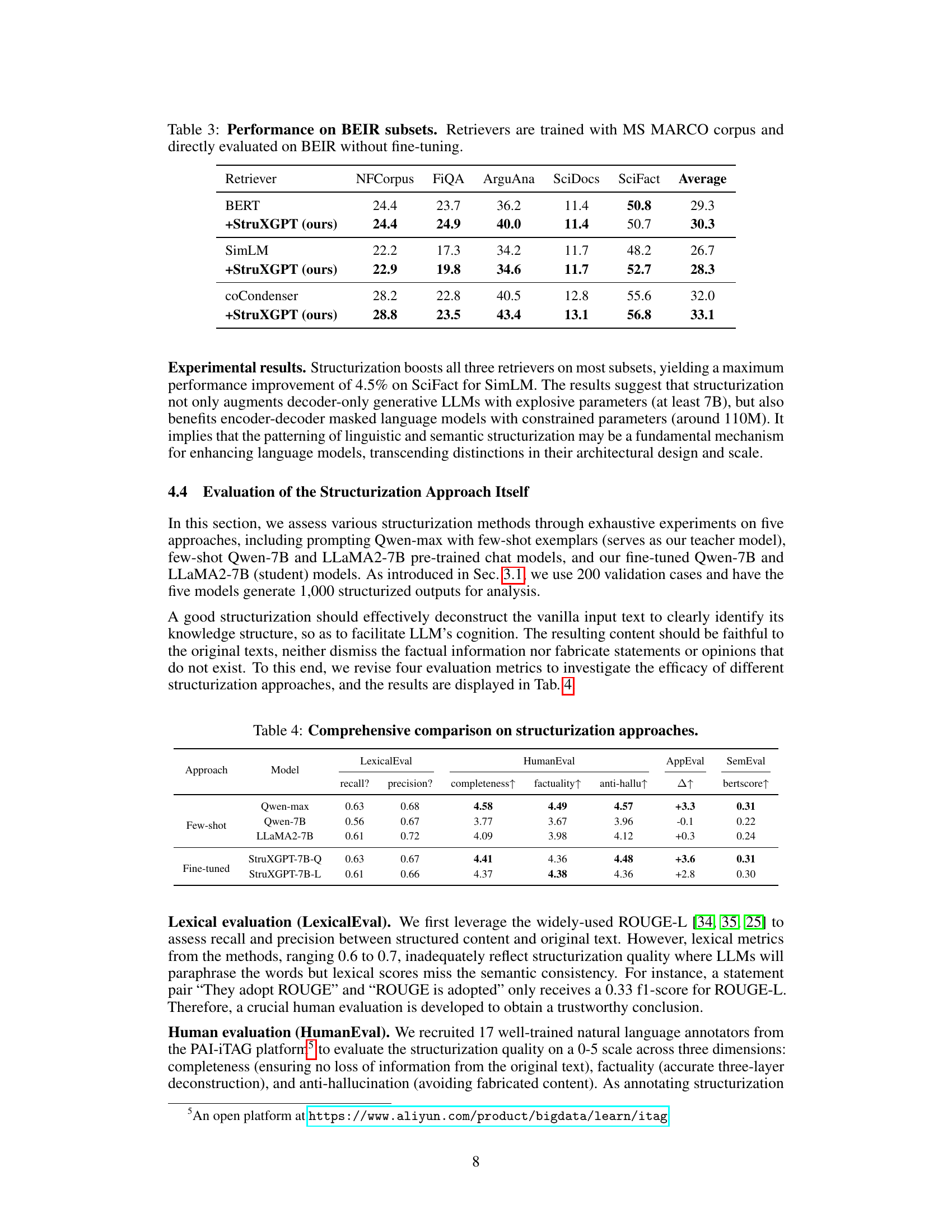
🔼 This table presents the performance of three different retrievers (BERT, SimLM, and coCondenser) on five subsets of the BEIR benchmark (NFCorpus, FiQA, ArguAna, SciDocs, and SciFact). The retrievers were initially trained on the MS MARCO corpus and then directly evaluated on the BEIR benchmark without any fine-tuning. The table shows the nDCG@10 scores for each retriever on each subset, with an average score across all subsets also provided. The rows labeled ‘+StruXGPT (ours)’ show the performance improvement obtained when the passages in the BEIR datasets were structurized using the proposed StruXGPT model before being input to the retrievers.
read the caption
Table 3: Performance on BEIR subsets. Retrievers are trained with MS MARCO corpus and directly evaluated on BEIR without fine-tuning.
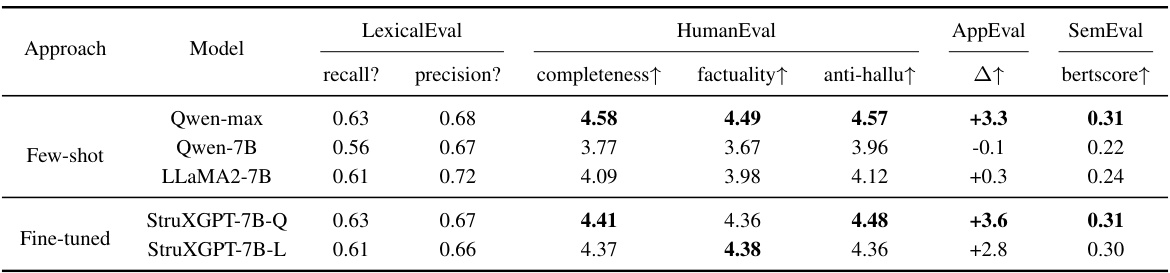
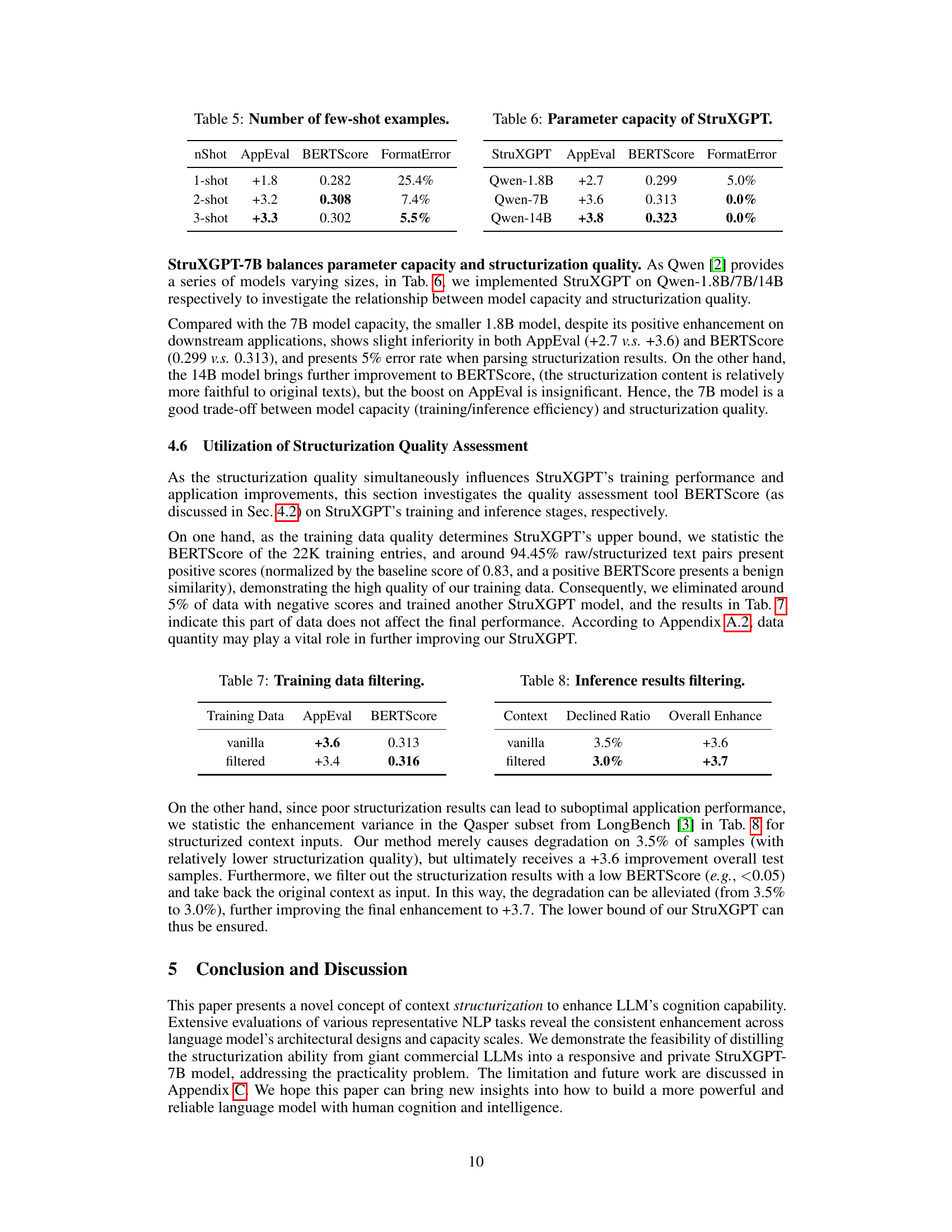
🔼 This table compares several approaches to structurization, evaluating their performance across different metrics. The approaches include using a few-shot commercial LLM (Qwen-max), few-shot smaller LLMs (Qwen-7B and LLaMA2-7B), and fine-tuned smaller LLMs (StruXGPT-7B-Q and StruXGPT-7B-L). The metrics used for evaluation include recall, precision, completeness, factuality, and anti-hallucination. The table also shows the improvement in downstream applications (AppEval) and the semantic similarity (SemEval) score for each approach. The results show that the fine-tuned StruXGPT models perform better than the few-shot models.
read the caption
Table 4: Comprehensive comparison on structurization approaches.
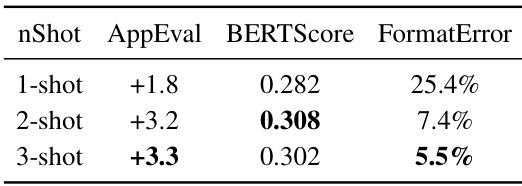
🔼 This table presents the results of ablation studies on the number of few-shot examples used for training the StruXGPT model. It shows the impact of using 1, 2, or 3 examples on the model’s performance, as measured by AppEval, BERTScore, and FormatError. AppEval measures the improvement in question answering on the Qasper subset of the LongBench benchmark. BERTScore measures the semantic similarity between the original and the structurized texts. FormatError measures the percentage of incorrectly formatted structurization results.
read the caption
Table 5: Number of few-shot examples.
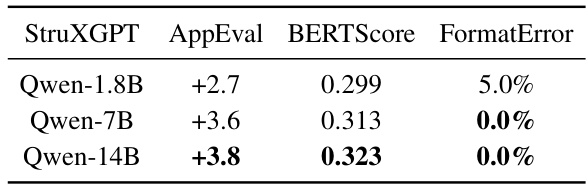
🔼 This table presents the results of experiments conducted to investigate the relationship between model capacity and structurization quality using different sizes of Qwen models (1.8B, 7B, and 14B parameters). The results are evaluated using AppEval, BERTScore, and FormatError metrics. It shows the trade-off between model size (and thus training/inference efficiency) and structurization quality.
read the caption
Table 6: Parameter capacity of StruXGPT.
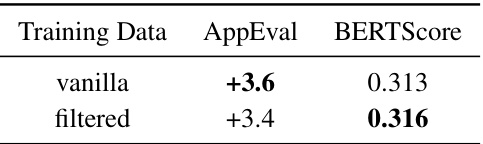
🔼 This table shows the ablation study on training data filtering. The first row shows the result of using vanilla training data, while the second row shows the result after filtering out 5% of low-quality training data. The ‘AppEval’ column shows the improvement in downstream question-answering performance on the Qasper subset of the LongBench benchmark. The ‘BERTScore’ column indicates the semantic similarity between the original and structurized texts. The table demonstrates that filtering out low-quality data slightly reduces the performance but has little effect on the overall enhancement.
read the caption
Table 7: Training data filtering.
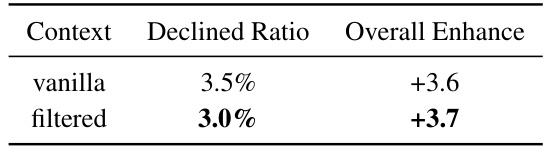
🔼 This table presents the results of filtering inference results based on the quality of structurization. The ‘vanilla’ row shows the overall enhancement and declined ratio before filtering, while the ‘filtered’ row shows the results after removing low-quality structurization results. Filtering improved the overall enhancement slightly while reducing the declined ratio.
read the caption
Table 8: Inference results filtering.
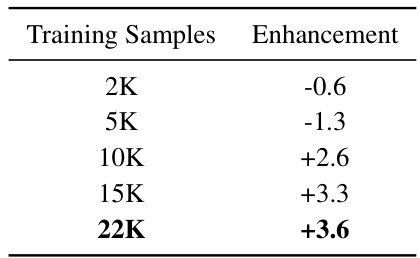
🔼 This table presents the results of ablation studies conducted to investigate the impact of training sample size on the performance of StruXGPT. The experiment varied the number of training samples (2K, 5K, 10K, 15K, 22K) and measured the resulting enhancement in question-answering performance on the LongBench’s Qasper subset using the LLaMA2-7B-Chat model. The results show an initial decrease in performance with smaller sample sizes, followed by a steady increase as the sample size grows, indicating that an adequate amount of training data is crucial for effective structurization.
read the caption
Table A1: Ablation on training samples.
🔼 This table presents the performance of various LLMs on the LongBench dataset. It compares the performance of LLMs using vanilla contexts against LLMs using contexts that have been processed using the StruXGPT-7B model for structurization. The results are broken down by task type within the LongBench benchmark (SingleDoc QA, MultiDoc QA, and Synthetic Tasks), and an average performance across all tasks is also provided. Higher scores indicate better performance.
read the caption
Table 1: Performance on LongBench datasets. The prefix Struct- indicates the data fed into LLMs is structurized by our StruXGPT-7B, while the evaluated LLMs themselves are unchanged. The results are acquired by LongBench's official protocol. Higher is better.
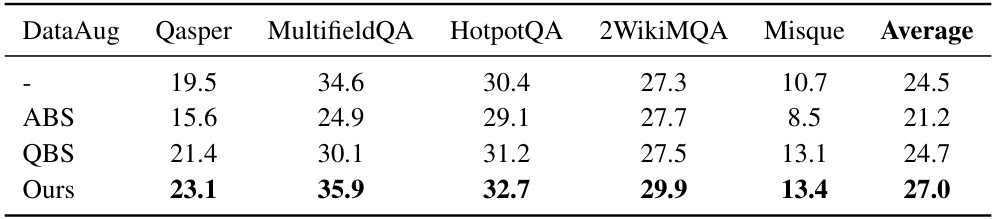
🔼 This table presents the performance of different LLMs on the LongBench dataset for various question answering tasks. It compares the performance of LLMs when given the original text versus when given text that has been preprocessed using the StruXGPT-7B model. Higher scores indicate better performance. The table shows improvements across several LLMs and tasks after structurization.
read the caption
Table 1: Performance on LongBench datasets. The prefix Struct- indicates the data fed into LLMs is structurized by our StruXGPT-7B, while the evaluated LLMs themselves are unchanged. The results are acquired by LongBench's official protocol. Higher is better.
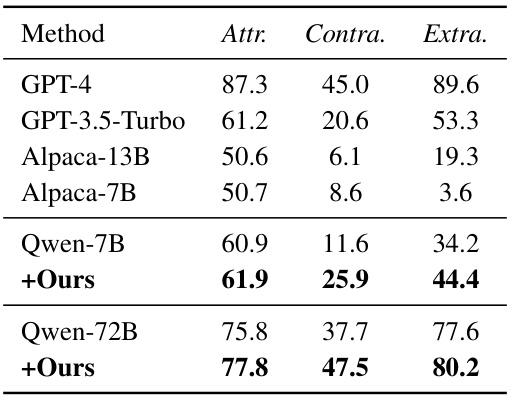
🔼 This table presents the results of hallucination evaluation on the AttrScore dataset. It compares the performance of several large language models (LLMs) in identifying whether a statement is Attributable (Attr.), Contradictory (Contra.), or Extrapolatory (Extra.) based on a reference passage. The models evaluated include GPT-4, GPT-3.5-Turbo, Alpaca-13B, Alpaca-7B, and LLaMA2-7B. The ’ +Ours’ row shows the results when the context structurization approach is used with each model to enhance performance.
read the caption
Table 2: Hallucination Evaluation on AttrScore.
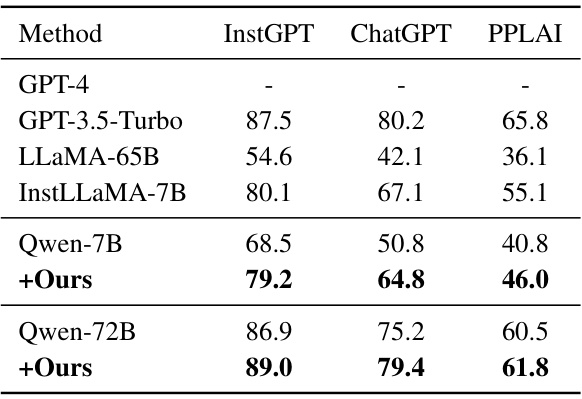
🔼 This table presents the results of hallucination evaluation on the AttrScore dataset. It compares the performance of several LLMs (GPT-4, GPT-3.5-Turbo, Alpaca-13B, Alpaca-7B, LLaMA2-7B, LLaMA2-70B, and GPT-3.5-1106) with and without the application of the proposed structurization method. The metrics used are the percentage accuracy of correctly identifying attributable, contradictory, and extrapolatory statements. The table shows that structurization consistently improves the performance of the evaluated LLMs.
read the caption
Table 2: Hallucination Evaluation on AttrScore.
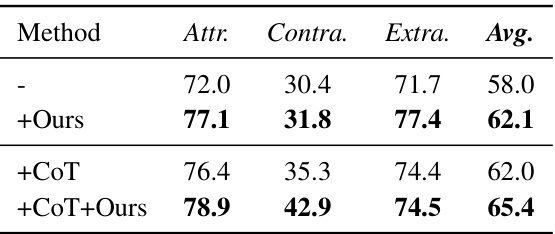
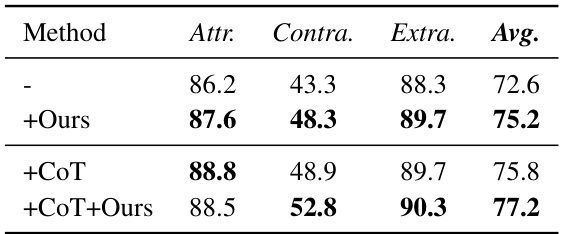
🔼 This table presents the results of hallucination evaluation on the AttrScore dataset. It compares the performance of different language models (GPT-4, GPT-3.5-Turbo, Alpaca-13B, Alpaca-7B, LLaMA2-7B, LLaMA2-70B, GPT-3.5-1106, and GPT-3.5-1106 + CoT) in identifying attributable, contradictory, and extrapolatory claims. The ‘+StruXGPT (ours)’ rows show the performance improvement achieved by incorporating the authors’ proposed structurization technique. Higher scores indicate better performance.
read the caption
Table 2: Hallucination Evaluation on AttrScore.
🔼 This table presents the performance of various LLMs on the LongBench dataset for three question-answering tasks. The results show the performance improvements achieved by using the StruXGPT-7B model to structurize the input context before feeding it to the LLMs. The ‘Struct-’ prefix indicates that the input data has been processed by the Structurization model. The table demonstrates that consistent improvements were observed across different LLMs and task types after structurization. Higher scores indicate better performance.
read the caption
Table 1: Performance on LongBench datasets. The prefix Struct- indicates the data fed into LLMs is structurized by our StruXGPT-7B, while the evaluated LLMs themselves are unchanged. The results are acquired by LongBench's official protocol. Higher is better.

🔼 This table presents the performance of different retrieval models on the BEIR benchmark. The models were initially trained on the MS MARCO corpus and then directly evaluated on BEIR without any further fine-tuning. The table shows the nDCG@10 scores for each retriever on five different subsets of the BEIR benchmark (NFCorpus, FiQA, ArguAna, SciDocs, and SciFact), as well as the average score across all five subsets. The ’ +StruXGPT (ours)’ rows show the performance of the same retrievers when using the text that is structurized by StruXGPT.
read the caption
Table 3: Performance on BEIR subsets. Retrievers are trained with MS MARCO corpus and directly evaluated on BEIR without fine-tuning.

🔼 This table presents the performance of several LLMs on the LongBench dataset, both with and without the application of structurization using the StruXGPT-7B model. It shows the average scores across various subtasks within LongBench (SingleDoc QA, MultiDoc QA, and Synthetic Tasks) for different LLMs, allowing for a comparison of performance gains achieved through structurization.
read the caption
Table 1: Performance on LongBench datasets. The prefix Struct- indicates the data fed into LLMs is structurized by our StruXGPT-7B, while the evaluated LLMs themselves are unchanged. The results are acquired by LongBench's official protocol. Higher is better.

🔼 This table presents the performance of different LLMs on the LongBench dataset. It compares the performance of several LLMs on various question answering tasks, both with and without the context structurization technique. The ‘Struct-’ prefix indicates that the input data was processed by the StruXGPT-7B model before being fed to the LLMs. The table shows the average performance across multiple subsets of the LongBench dataset, providing a comprehensive view of the structurization method’s effectiveness across different model architectures and scales.
read the caption
Table 1: Performance on LongBench datasets. The prefix Struct- indicates the data fed into LLMs is structurized by our StruXGPT-7B, while the evaluated LLMs themselves are unchanged. The results are acquired by LongBench's official protocol. Higher is better.
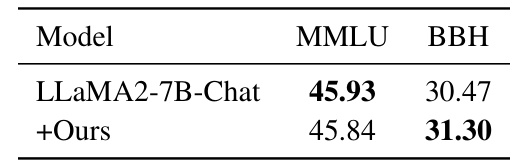
🔼 This table presents the performance of LLaMA2-7B-Chat with and without structurization on two general benchmarks: MMLU and BBH. It shows that structurization slightly improves performance on BBH but has a negligible impact on MMLU, highlighting that structurization primarily benefits tasks with long-form or logically complex contexts, while MMLU relies more on the model’s inherent knowledge without context.
read the caption
Table A10: Evaluation on general benchmarks.
Full paper#