↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current vision-language models (VLMs) excel at complex image generation and description but surprisingly fail at simple multi-object reasoning tasks like counting or visual analogy. This failure is rooted in the “binding problem,” a fundamental challenge in cognitive science where distinct features of multiple objects need to be correctly associated to avoid confusion. This is similar to limitations observed in fast human visual processing.
This research investigates VLMs’ performance on classic cognitive tasks such as visual search and numerical estimation. The study reveals that VLMs struggle when the likelihood of feature interference is high, even with few objects. A novel scene description benchmark helps quantify this interference, predicting VLM errors better than simply counting objects. By applying these findings to visual analogy, a pre-processing technique to reduce interference improves VLM performance, suggesting that multi-object scene processing itself, rather than abstract reasoning, is the main bottleneck. The results underscore the need for more sophisticated methods, potentially incorporating serial attention or object-centric representations to improve VLM performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers as it highlights limitations in current vision-language models (VLMs), particularly concerning the binding problem. It bridges the gap between cognitive science and AI, offering insights into VLM failures and suggesting potential solutions involving serial processing or object-centric representations. This opens exciting avenues for developing more robust and human-like AI systems.
Visual Insights#
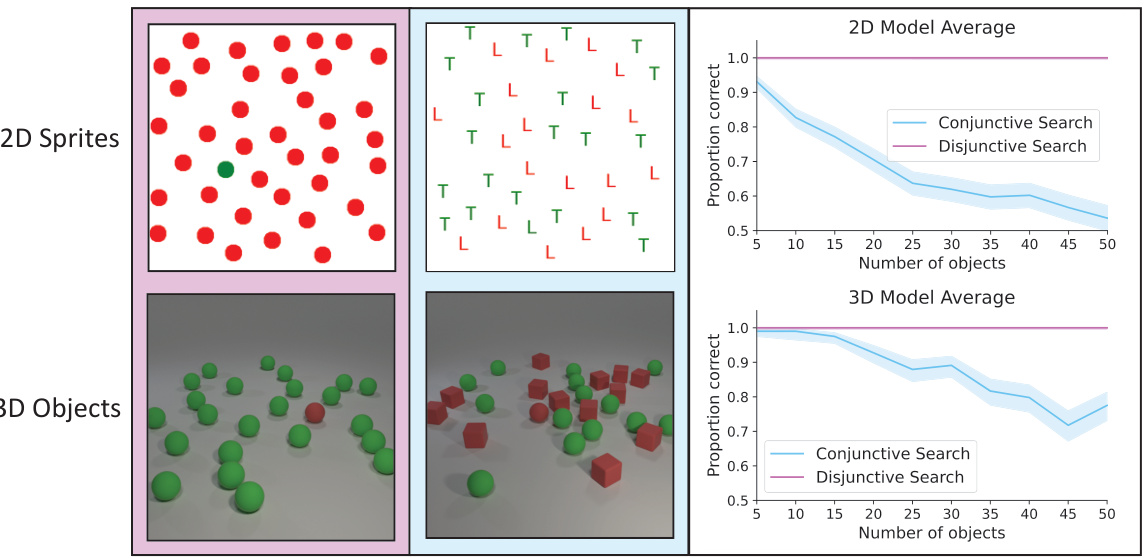
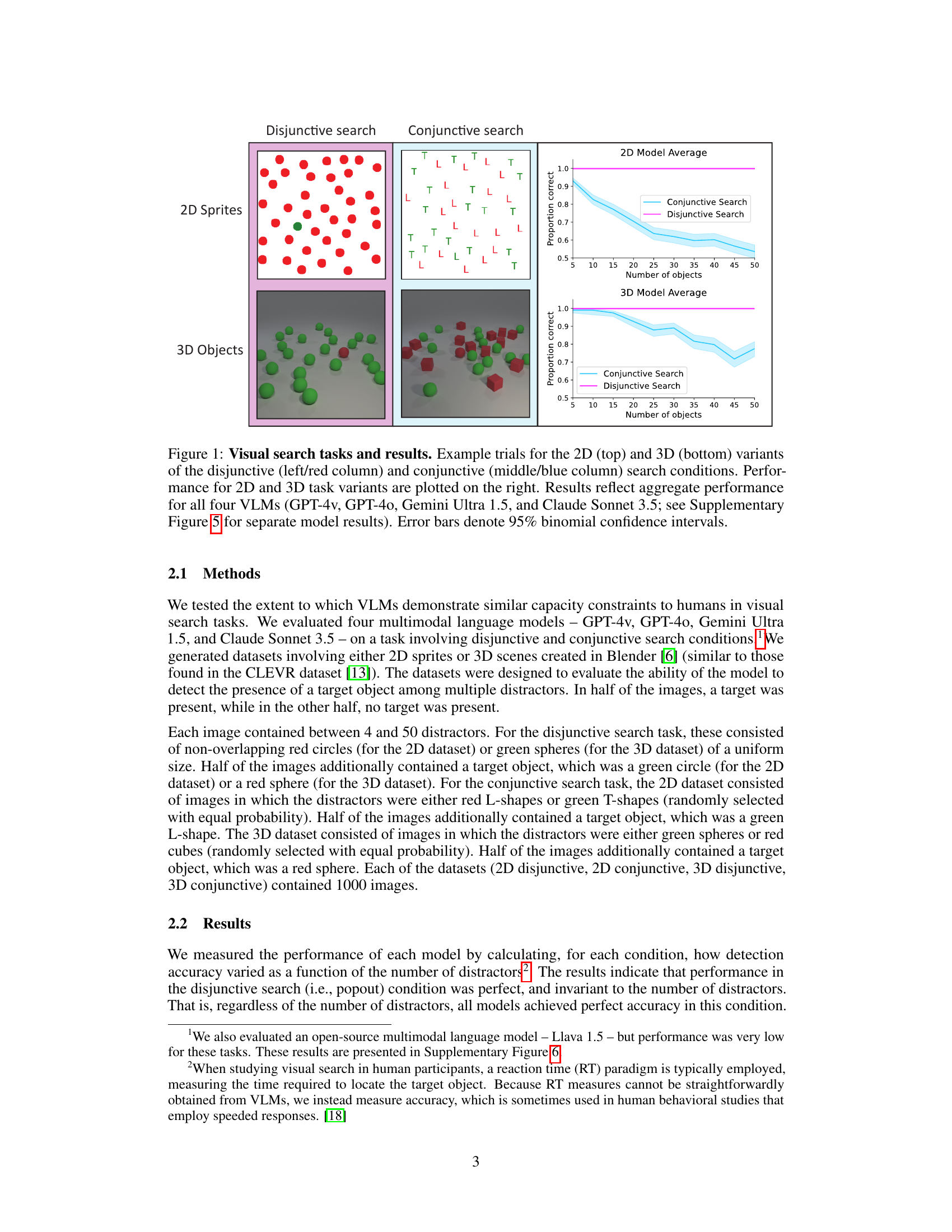
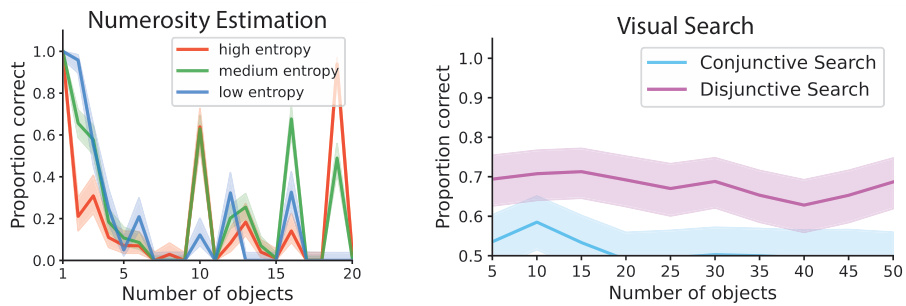
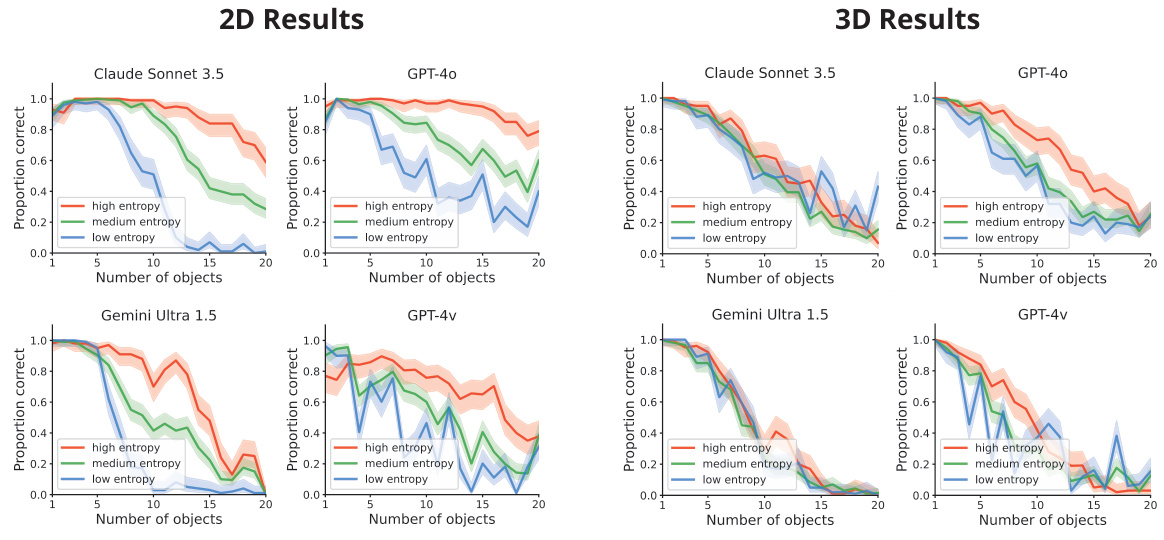
This figure displays example trials and results of a visual search experiment conducted on four different vision-language models (VLMs). The experiment used two types of search tasks: disjunctive (easy, target ‘pops out’) and conjunctive (harder, requires focused attention). Both 2D and 3D versions of each task were tested. The plots show how the accuracy of each VLM decreases as the number of distractor objects increases, particularly in the conjunctive search condition. The results are compared across 2D and 3D datasets, with aggregate performance of the four models displayed.
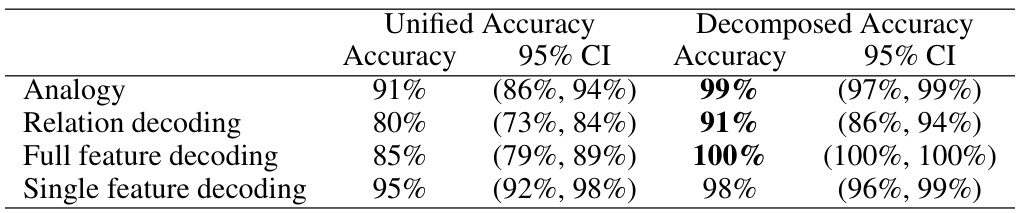
This table presents the results of a visual analogy experiment using the GPT-4v model. It shows the model’s accuracy and 95% confidence intervals for four different tasks: the main analogy task, relation decoding, full feature decoding, and single feature decoding. The results are broken down by two experimental conditions: Unified (all objects presented in one image) and Decomposed (objects presented across multiple images). The comparison highlights how the task’s visual complexity affects the model’s performance.
In-depth insights#
Binding Problem in VLMs#
The paper explores the “binding problem” in Vision-Language Models (VLMs), a phenomenon where VLMs struggle with tasks requiring the association of multiple features to distinct objects, despite excelling in other complex visual tasks. This parallels the binding problem in human cognition, where integrating features of separate objects into coherent percepts is challenging. The authors hypothesize that VLM failures stem from representational interference, an inability to manage binding due to the use of shared representational resources. They support this by showing that VLM performance on visual search and numerical estimation tasks degrades similarly to human performance when interference is high, particularly when there are many objects with overlapping features. A novel scene description benchmark further validates this hypothesis, indicating that error rates directly correlate with the probability of representational interference within a scene. The study suggests that despite VLMs’ capacity for compositional representation, which is crucial for generalization, the lack of mechanisms to address the binding problem limits performance on multi-object tasks, mirroring limitations observed in the human visual system.
Visual Search & Capacity#
The section on ‘Visual Search & Capacity’ would likely explore the limitations of vision language models (VLMs) in performing visual search tasks, particularly those involving multiple objects. It would probably highlight the surprising finding that while VLMs excel at complex image generation and description, their performance degrades significantly on basic visual search tasks, mirroring human limitations in conditions of high interference. The study would likely contrast ‘disjunctive’ and ‘conjunctive’ visual search, showing that VLMs struggle with conjunctive searches (requiring the integration of multiple features), exhibiting capacity constraints similar to humans. This capacity limitation isn’t simply a matter of object number, but rather reflects the difficulty in managing representational interference; when objects share similar features, errors increase due to the binding problem—the difficulty the brain and, analogously, VLMs have in associating features correctly with specific objects. The experiments would likely measure accuracy and response times under varying conditions, demonstrating the impact of object number and feature similarity on VLM performance, ultimately supporting the hypothesis that limitations arise from the binding problem and related capacity constraints.
Numerosity Estimation Limits#
The study investigates numerosity estimation limits in vision language models (VLMs), revealing human-like capacity constraints. VLMs, like humans, excel at estimating small numbers of objects (subitizing) but struggle as the quantity increases. This limitation isn’t solely due to object number, but is strongly influenced by feature variability. High feature variability (unique shapes and colors) reduces interference and improves accuracy, while low variability (similar features) leads to more errors. This suggests that interference from shared representational resources, a core aspect of the binding problem, underlies these capacity limitations in VLMs. The findings highlight a surprising parallel between VLM limitations and those observed in human visual processing, suggesting that VLM shortcomings may stem from their use of compositional representations and challenges managing representational interference.
Scene Description Benchmark#
The proposed Scene Description Benchmark is a novel approach to evaluating vision-language models (VLMs) by focusing on the binding problem. It cleverly quantifies interference through the number of “feature triplets” present in a scene. A feature triplet represents a set of three objects where two share one feature and another pair shares a different feature; this systematically assesses the likelihood of binding errors, moving beyond simple object counts. This benchmark is crucial because it addresses the limitation of existing VLM evaluation methods, which often fail to capture the nuanced challenges of multi-object scene understanding. The use of both 2D and 3D scenes, along with varying feature distributions, ensures the benchmark’s generalizability and robustness. Its systematic variation of interference likelihood provides a more precise measure of VLM performance and offers insights into their inherent capacity limitations related to the binding problem.
Visual Analogy & Binding#
The concept of visual analogy, involving recognizing relational correspondences between images, presents a significant challenge for vision-language models (VLMs). This difficulty is deeply intertwined with the binding problem, which describes the computational hurdles of associating features belonging to distinct objects within a scene. VLMs frequently fail in visual analogy tasks not due to a lack of abstract reasoning, but because of their struggle with the core challenge of disentangling and relating features from multiple objects simultaneously. This points to a fundamental limitation in how VLMs represent and process multi-object scenes, mirroring the limitations of rapid, parallel processing in the human visual system. Addressing the binding problem in VLMs is therefore crucial for improving performance in visual analogy tasks and other complex visual reasoning abilities.
More visual insights#
More on figures
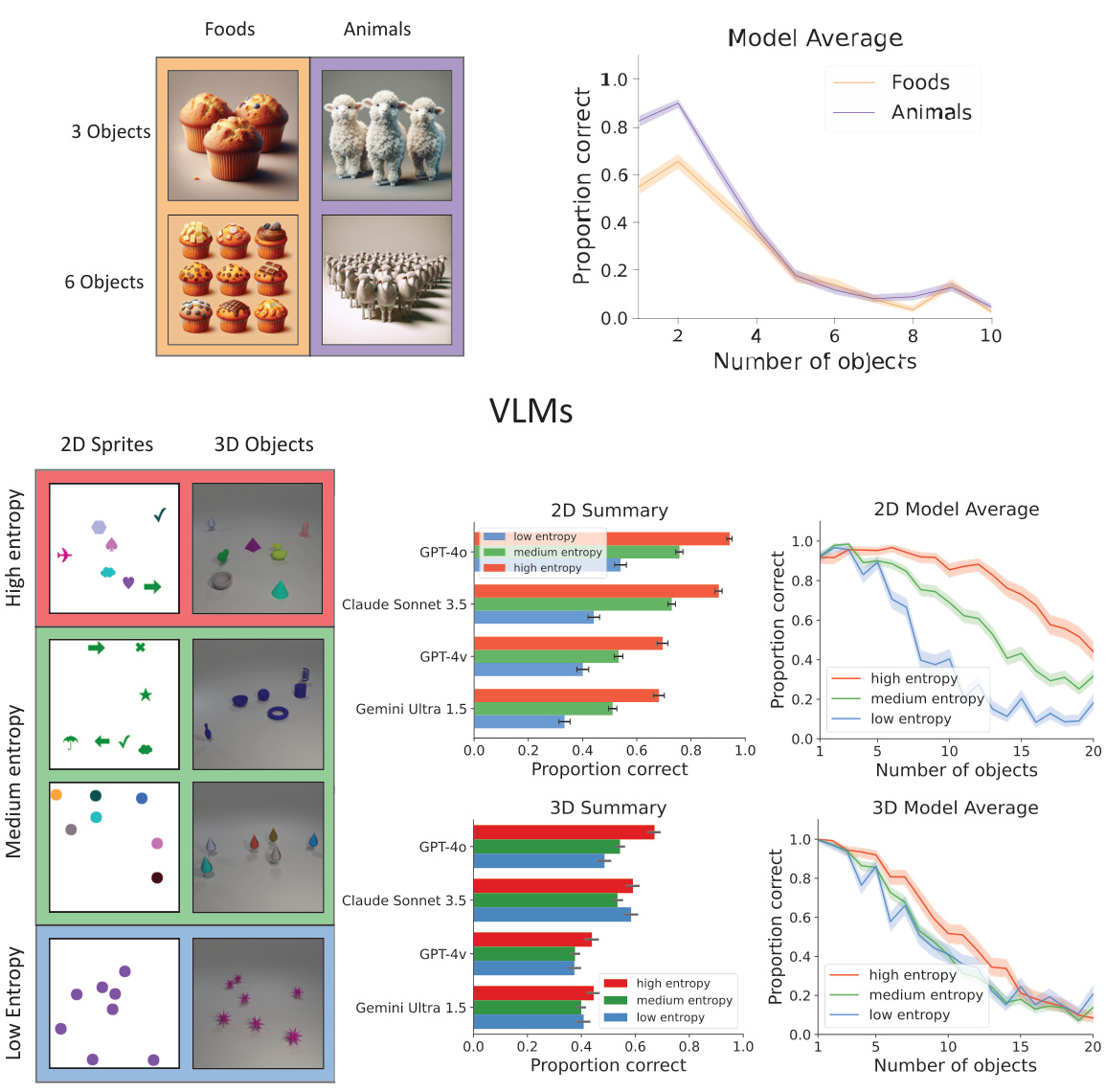
This figure presents results from numerical estimation tasks performed on both text-to-image and multimodal language models. The top shows examples of generated images and the overall performance of text-to-image models in relation to the number and category of objects. The bottom shows examples of the stimuli used in the numerosity estimation task, the performance of multimodal models in 2D and 3D settings, and the overall performance of the models in relation to the number of objects and feature entropy.

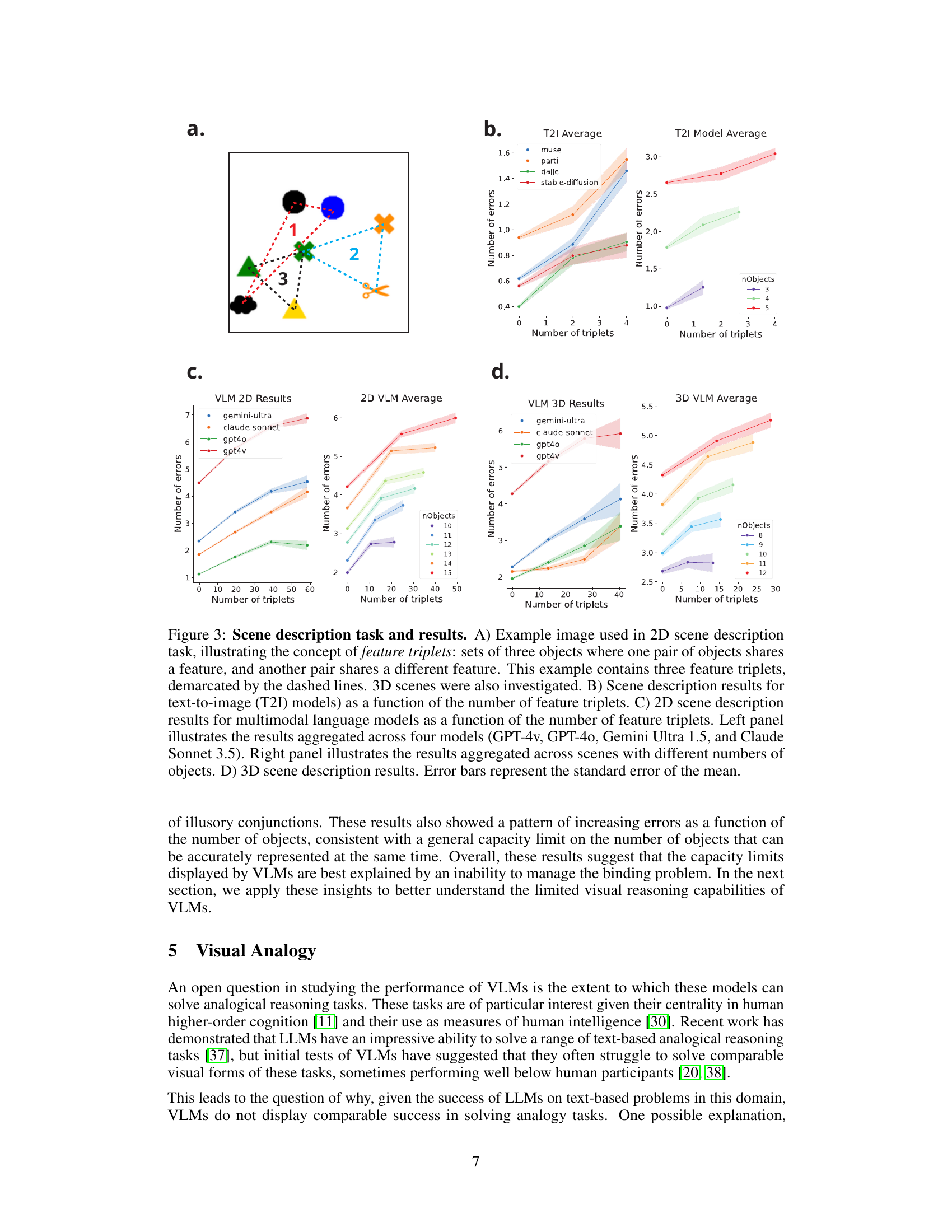
This figure demonstrates the results of a novel scene description task designed to test the impact of representational interference on Vision Language Models (VLMs). The task involves describing scenes with varying numbers of objects and feature triplets (sets of three objects where pairs share features). Panels (B-D) show how the number of errors in scene descriptions increases with both the number of objects and feature triplets, supporting the hypothesis that representational interference due to the binding problem hinders VLMs’ performance.

This figure illustrates the visual analogy task used in the experiment. It shows two versions of the task: a unified condition where all pairs are shown in a single image, and a decomposed condition where the source pair and target pairs are shown in separate images. The goal is to identify the target pair that shares the same relationships (in this case, shape and color) as the source pair. The decomposed condition aims to reduce the potential interference from multiple objects in a single image.

This figure shows example trials and results for 2D and 3D visual search tasks. The left columns show examples of disjunctive search (where the target object differs from distractors by a single feature), and the middle columns show examples of conjunctive search (where the target shares features with distractors). The right-hand side presents the results for four different vision-language models on these search tasks, showing the relationship between accuracy and the number of objects presented. The figure demonstrates how the performance of these models on the conjunctive search task is negatively impacted by the increasing number of objects, similar to human performance, suggesting that the models struggle to manage interference between objects.
This figure presents results from numerical estimation tasks using both text-to-image (T2I) and multimodal language models. The top section shows examples of T2I generated images and model performance based on object count and category. The bottom section displays results from multimodal language models tested with varied image complexity (feature entropy) and object counts. Both sections highlight accuracy decreases as object number increases and demonstrate human-like capacity constraints.

The figure displays the performance of the Claude Sonnet 3.5 model on three different visual search tasks: disjunctive search, conjunctive search, and a control disjunctive search. The control condition was designed to isolate the effect of target-distractor color similarity by varying the colors of targets and distractors between trials. The x-axis represents the number of objects present in the search array, while the y-axis represents the model’s accuracy. The results show that the model performed well in disjunctive searches but had difficulty in conjunctive searches, especially as the number of objects increased. The control condition further demonstrates the importance of feature similarity in affecting search performance.
This figure displays the results of numerical estimation experiments performed on both text-to-image and multimodal language models. The top section shows examples of images generated by T2I models and their performance in estimating object counts, showing a decline in accuracy as the number of objects increases. The bottom section presents similar experiments performed on multimodal language models, again showing a decrease in accuracy with more objects. The impact of feature variability (entropy) is also explored, demonstrating that higher entropy (more visual distinctions between objects) leads to better performance. The results highlight the limitation of both model types in tasks involving numerosity estimations and their similarities to human limitations.

This figure shows the results of a novel scene description task designed to test the impact of representational interference on vision-language models (VLMs). The task systematically varies the likelihood of interference by changing the number of feature triplets in the scene. The results demonstrate that performance decreases as the number of feature triplets and objects increase, supporting the hypothesis that representational interference, a manifestation of the binding problem, underlies the limitations of VLMs in multi-object scene description.
More on tables
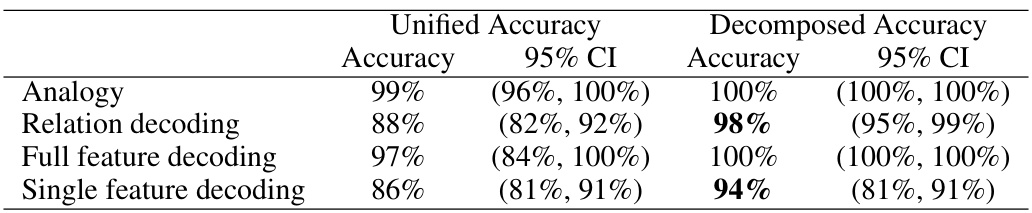
This table presents the results of a visual analogy experiment using the GPT-40 model. It shows the accuracy and 95% confidence intervals for four different tasks: Analogy (solving the main analogy problem), Relation decoding (identifying relations between objects), Full feature decoding (identifying all features of objects), and Single feature decoding (identifying a single feature of an object). The results are shown separately for two conditions: Unified (all objects presented in one image) and Decomposed (objects presented across multiple images to reduce potential interference).
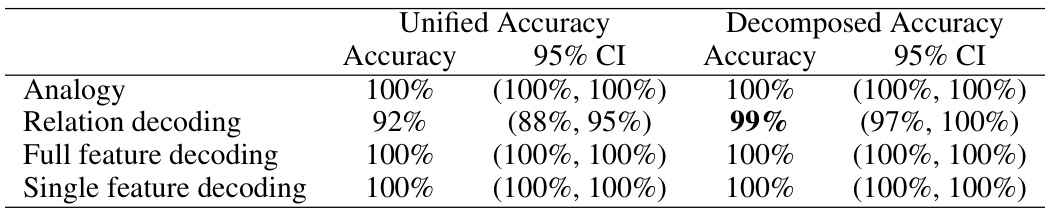
This table presents the results of a visual analogy experiment using the Claude Sonnet 3.5 model. It shows the model’s accuracy in solving analogy tasks under two conditions: unified and decomposed. The unified condition presents all the visual information in a single image, while the decomposed condition breaks this information into multiple images. The results are presented for the overall analogy task and for sub-tasks focused on relation decoding, full feature decoding, and single feature decoding. 95% confidence intervals are provided for all accuracy scores.
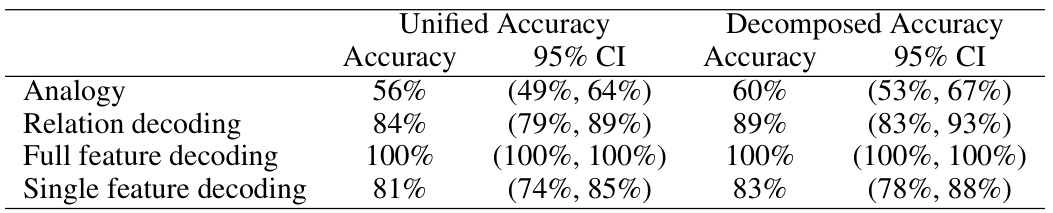
This table presents the results of a visual analogy task performed by the Gemini Ultra 1.5 language model. It shows the model’s accuracy (and 95% confidence intervals) for four different subtasks: the main analogy task, relation decoding, full feature decoding, and single feature decoding. The results are separated into two conditions: unified (source and target pairs in a single image) and decomposed (source and target pairs in separate images). The table highlights the performance differences between the two conditions, indicating how the decomposition of the task affects the model’s ability to solve different aspects of the analogy problem.
Full paper#