TL;DR#
Current methods for cooperative multi-agent learning often assume restrictive settings where either all agents or only a single agent are controlled. This limits their applicability to real-world scenarios with dynamic team compositions and diverse teammates. This paper introduces the N-agent ad hoc teamwork (NAHT) problem and proposes the Policy Optimization with Agent Modeling (POAM) algorithm to address these limitations.
POAM uses a policy gradient approach that leverages an agent modeling network to learn representations of teammate behaviors, enabling adaptation to diverse and changing teams. The algorithm is evaluated on various tasks from multi-agent particle environments and StarCraft II, showing significant improvements in cooperative task returns and out-of-distribution generalization compared to baseline methods. The study’s findings are crucial for advancing the state-of-the-art in multi-agent reinforcement learning and building more flexible and robust cooperative systems.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in current multi-agent reinforcement learning research: the assumption of fully controlled or single-agent scenarios. By introducing the N-agent ad hoc teamwork (NAHT) problem and proposing the POAM algorithm, the research opens up new avenues for developing more robust and adaptable multi-agent systems that are applicable to real-world scenarios involving dynamic team compositions and unknown teammates. This is highly relevant to the growing field of autonomous systems, where collaboration with diverse and unpredictable agents is crucial.
Visual Insights#

🔼 This figure illustrates the differences between three multi-agent reinforcement learning paradigms: CMARL (Cooperative Multi-Agent Reinforcement Learning), AHT (Ad Hoc Teamwork), and NAHT (N-Agent Ad Hoc Teamwork). In CMARL, all agents are controlled by the learning algorithm. In AHT, only one agent is controlled, and the others have unknown behaviors. NAHT generalizes both, with a variable number (N) of agents being controlled, while the rest (M-N) are uncontrolled. This highlights the increasing complexity and realism moving from CMARL to AHT and finally NAHT.
read the caption
Figure 1: Left: CMARL algorithms assume full control over all M agents in a cooperative scenario. Center: AHT algorithms assume that only a single agent is controlled by the learning algorithm, while the other M − 1 agents are uncontrolled and can have a diverse, unknown set of behaviors. Right: NAHT, the paradigm proposed by this paper, assumes that a potentially varying N agents are controlled by the learning algorithm, while the remaining M − N agents are uncontrolled.

🔼 This table shows the hyperparameters that were evaluated for the policy gradient algorithms IPPO and MAPPO. The hyperparameters listed include buffer size, epochs, minibatches, entropy, clip, clip value, and whether or not a clip value loss was used. For each hyperparameter, a range of values was tested and the selected values (those that yielded the best results) are shown in bold.
read the caption
Table 1: Hyperparameters evaluated for the policy gradient algorithms. Selected values are bolded
In-depth insights#
NAHT Formalism#
A formalism for N-Agent Ad Hoc Teamwork (NAHT) would need to carefully model the dynamic and partially observable nature of the multi-agent environment. Key aspects would include: 1) A formal representation of the agents, distinguishing between controlled agents (trained by the learning algorithm) and uncontrolled agents (with potentially unknown or varying behaviors). 2) A model of the task or reward function, emphasizing the cooperative aspect of teamwork. 3) A mechanism for modeling the dynamic team composition, which could involve probabilistic models to handle the varying numbers and types of agents that may be encountered. 4) A suitable representation of the agent’s information state (partially observable), which would likely incorporate a history of interactions and observations. Defining a suitable performance metric that captures the overall cooperative success, taking into account the uncertainty and dynamicity of the environment is crucial. Such a metric might incorporate elements such as team reward, individual agent contributions and the adaptability of the team to changing circumstances. Successfully formalizing NAHT would pave the way for a deeper theoretical understanding of cooperative multi-agent learning and facilitate the development of more efficient and robust algorithms to address real-world challenges.
POAM Algorithm#
The core of the research paper revolves around the proposed POAM (Policy Optimization with Agent Modeling) algorithm, a novel approach designed to address the challenges of N-Agent Ad Hoc Teamwork (NAHT). POAM uniquely tackles the problem of learning cooperative behaviors in dynamic, open environments where the number and types of teammates change unpredictably. Unlike existing CMARL (Cooperative Multi-Agent Reinforcement Learning) and AHT (Ad Hoc Teamwork) algorithms, POAM does not assume full control over all agents, enabling robust adaptation to diverse and unseen teammates. Central to POAM’s effectiveness is its agent modeling component, which learns representations of teammate behaviors through an encoder-decoder network. This learned representation is then used to condition the policy and value networks of the controlled agents, facilitating effective adaptation and coordination. The integration of data from uncontrolled agents for training the critic, while keeping the policy network on-policy, further enhances POAM’s sample efficiency and generalization capabilities. Experimental results demonstrate POAM’s superior performance compared to baseline methods, highlighting its ability to coordinate effectively in various multi-agent environments while demonstrating improved generalization to unseen teammates.
Empirical Studies#
An ‘Empirical Studies’ section in a research paper would detail the experiments conducted to validate the proposed methods. It would likely involve a description of the experimental setup, including datasets used, metrics employed, and baselines for comparison. Crucially, this section should present a clear analysis of results, highlighting both successes and limitations. This might involve statistical significance testing and error analysis to demonstrate the reliability of findings. A robust empirical study would also address potential confounding factors and biases in the experimental design, while discussing the generalizability of the results to different settings or contexts. The inclusion of visualizations such as graphs and tables is essential to present the findings clearly and effectively. A strong emphasis on reproducibility is also critical, with sufficient detail provided to allow other researchers to replicate the experiments. Finally, a thoughtful discussion should interpret the results in relation to the paper’s hypotheses and the broader research field. Overall, the effectiveness of the paper hinges on the strength and rigor of its empirical studies; they must convincingly support the claims made.
OOD Generalization#
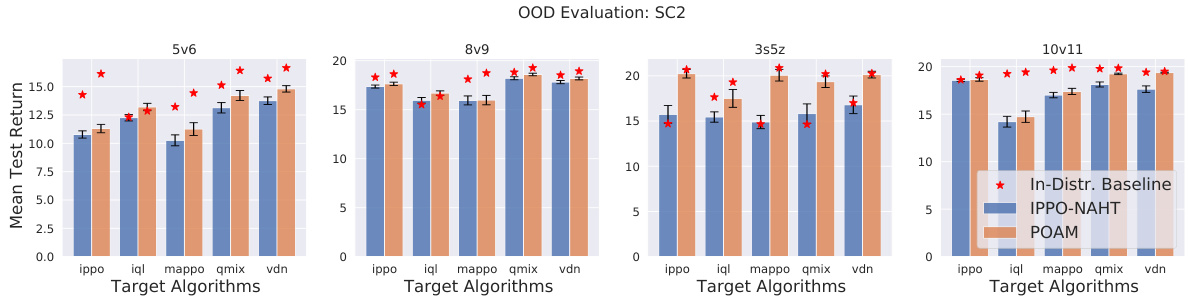
The section on “OOD Generalization” is crucial for evaluating the robustness and real-world applicability of the proposed NAHT algorithm, POAM. It directly addresses the challenge of generalizing to unseen teammates whose behaviors may differ significantly from those encountered during training. The experiments focus on evaluating the performance of POAM when interacting with teammates trained using different MARL algorithms or different random seeds, representing a diverse set of out-of-distribution (OOD) scenarios. Successful OOD generalization is vital for showcasing the practicality and reliability of the algorithm in dynamic, real-world settings. This section highlights the significance of the agent modeling component within POAM, as it enables adaptation to varied teammate strategies, which enhances out-of-distribution performance. The results demonstrate the effectiveness of the agent modeling module and the algorithm’s ability to leverage information from both controlled and uncontrolled agents during training. A comparison with baseline approaches is critical, showing the superiority of POAM’s approach to OOD generalization. Ultimately, this analysis provides a comprehensive assessment of POAM’s capability to handle the complexities and uncertainties of real-world collaborative tasks. The findings from this section directly impact the practical value and deployment potential of the algorithm.
Future of NAHT#
The future of N-agent ad hoc teamwork (NAHT) research is promising, with several avenues for exploration. Improving generalization to unseen teammates remains crucial, possibly through more advanced agent modeling techniques such as those incorporating hierarchical or relational representations of teammate behavior. Addressing heterogeneous agent scenarios is another key area, requiring methods that can handle diverse communication styles and coordination conventions. Incorporating communication directly into the NAHT framework is a potentially high-impact direction, as it could significantly enhance the adaptability and efficiency of ad hoc teams. Developing robust algorithms that can cope with dynamic team compositions—agents joining or leaving the team during operation—will be critical for real-world applications. Finally, applying NAHT to more complex, real-world tasks beyond the current benchmark problems (multi-agent particle environments and StarCraft II) will be needed to truly assess its capabilities and applicability in diverse domains such as autonomous driving and robotics.
More visual insights#
More on figures
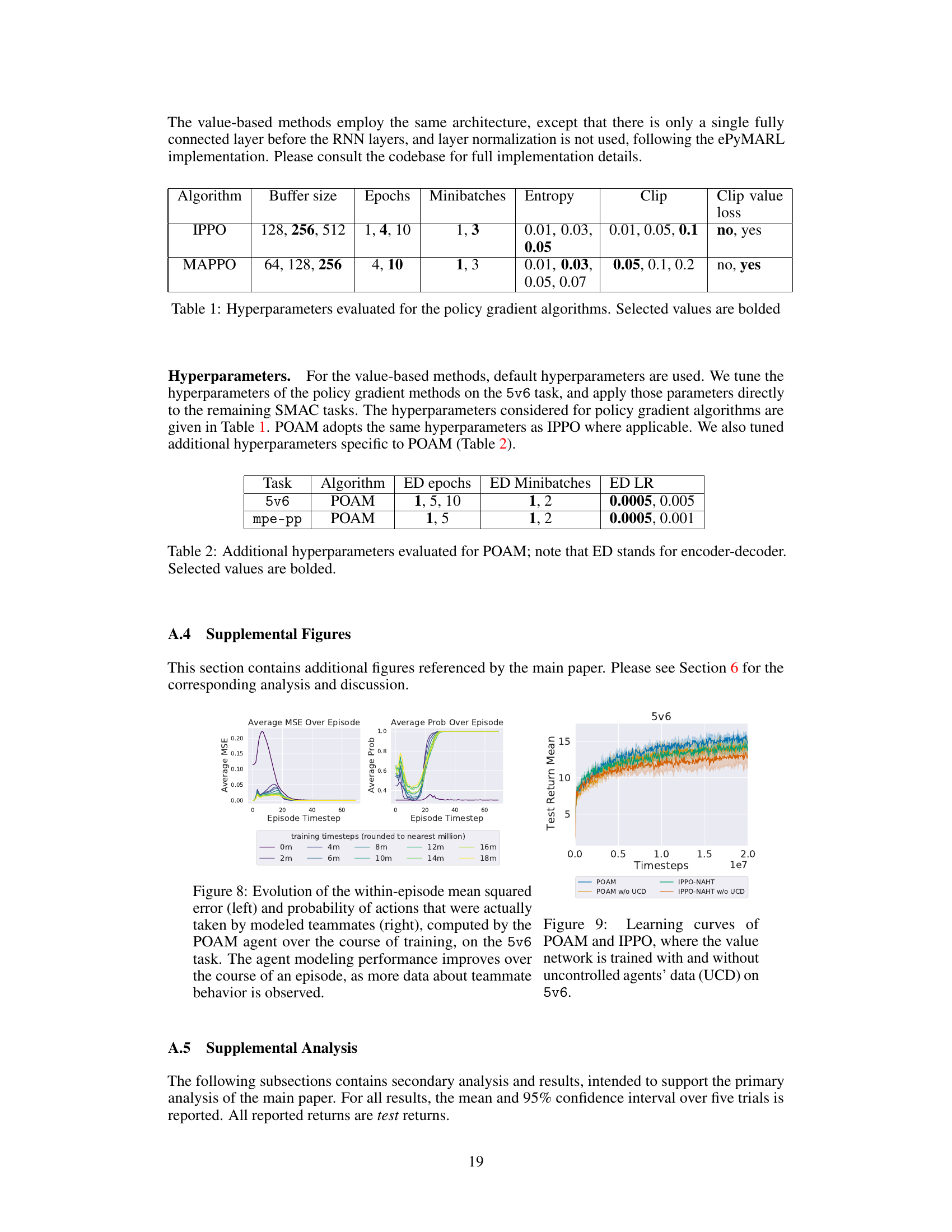
🔼 The figure illustrates the architecture of the Policy Optimization with Agent Modeling (POAM) algorithm. POAM trains a single policy network (πθρ) for all controlled agents, using a learned embedding vector (et) representing the observed behaviors of both controlled and uncontrolled teammates. This embedding vector is generated by an agent modeling network (encoder-decoder). A value network (Ve) is trained using data from both controlled and uncontrolled agents, providing a baseline for policy gradient updates. Importantly, the policy network is only trained using data from controlled agents, making it adaptable to varying numbers and types of uncontrolled teammates.
read the caption
Figure 2: POAM trains a single policy network πθρ, which characterizes the behavior of all controlled agents (green), while uncontrolled agents (yellow) are drawn from U. Data from both controlled and uncontrolled agents is used to train the value network, Ve, while the policy is trained on data from the controlled agents only. The policy and value function are both conditioned on a learned team embedding vector, et.

🔼 This figure compares the learning curves of POAM and several baseline methods across five different multi-agent tasks. The x-axis represents training timesteps, and the y-axis shows the mean test return. POAM consistently outperforms all baselines either in terms of sample efficiency (how quickly it reaches a high return) or asymptotic return (the highest return achieved after sufficient training). The baselines include a naive MARL approach (using various well-known multi-agent RL algorithms), IPPO-NAHT (Independent PPO in the NAHT setting), and POAM-AHT (POAM applied to the AHT setting). The results indicate POAM’s superior ability to learn effective cooperative strategies in the presence of uncontrolled teammates.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.
🔼 This figure compares the performance of POAM against three baselines across five different tasks. The x-axis represents training timesteps, and the y-axis represents mean test return. POAM consistently outperforms the baselines (IPPO-NAHT, POAM-AHT, and the best naive MARL) in terms of either sample efficiency (reaching higher return sooner) or asymptotic return (achieving a higher final return). Each plot shows the performance on a single task: mpe-pp, 5v6, 8v9, 3s5z, and 10v11.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.
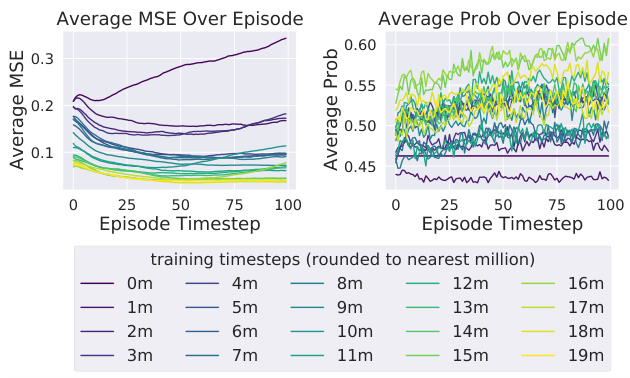
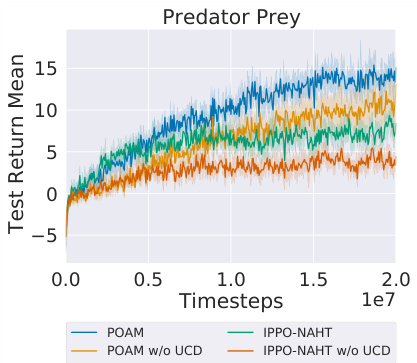
🔼 This figure shows the evolution of a POAM agent’s performance in predicting the actions and observations of its teammates over the course of training. The left panel shows the mean squared error (MSE) of the agent’s predictions for its teammates’ observations, while the right panel shows the probability of the agent correctly predicting its teammates’ actions. The results show that the agent’s ability to predict its teammates’ behavior improves significantly over time, suggesting that the agent is learning to model its teammates’ behavior effectively. The results are presented for the mpe-pp task.
read the caption
Figure 5: Evolution of a POAM agent's within-episode mean squared error (left) and within-episode probability of actions of modeled teammates (right), over the course of training on mpe-pp.
🔼 The figure shows learning curves for four algorithms across four different tasks. The x-axis represents training timesteps and the y-axis represents the mean test return. POAM consistently outperforms other algorithms (IPPO-NAHT, POAM-AHT, and Naive MARL) across all four tasks, showing superior sample efficiency and/or asymptotic return. The shaded areas represent 95% confidence intervals.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.

🔼 This figure illustrates the team sampling procedure used in the N-agent ad hoc teamwork (NAHT) problem. It shows two sets of agents: controlled agents (C) and uncontrolled agents (U). A sampling process (X) selects a subset of agents (N) from the controlled set and the remaining agents (M-N) from the uncontrolled set to form a team. The number of controlled agents (N) is sampled uniformly from 1 to M-1. The figure clearly shows the process of assembling a team of M agents for a task, where the algorithm controls N of them, while the rest are uncontrolled and have potentially unknown behaviors.
read the caption
Figure 7: A practical instantiation of the NAHT problem.
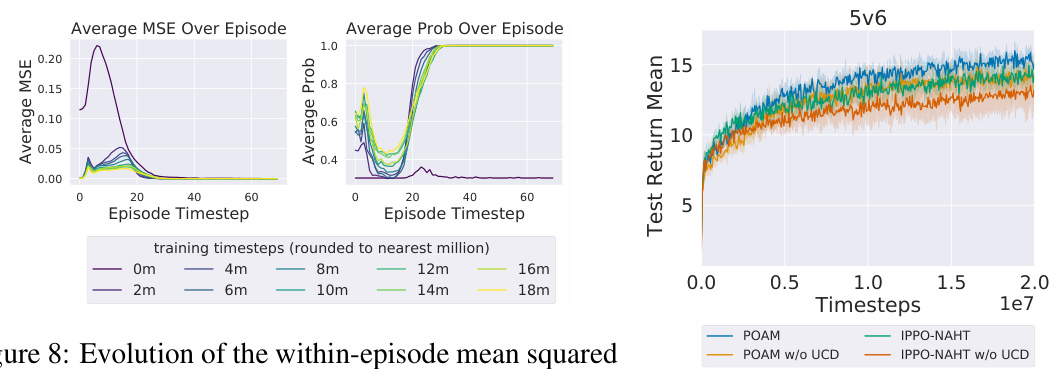
🔼 This figure shows the evolution of the within-episode mean squared error (MSE) and the within-episode probability of actions predicted by POAM’s agent modeling network for the multi-agent particle environment (MPE) predator-prey task. The left plot shows how the average MSE decreases over the course of training, while the right plot shows how the average probability of actions increases. The plots show that the average MSE decreases within the episode and the average probability increases as the agent modeling network becomes more confident in its predictions. These results suggest that POAM is able to learn accurate teammate models and adapt to their behavior.
read the caption
Figure 8: Evolution of the within-episode mean squared error (left) and within-episode probability of actions of modeled teammates (right), over the course of training on mpe-pp.
🔼 This figure shows the learning curves for the proposed POAM algorithm and its baseline algorithms (IPPO-NAHT, POAM-AHT, and the best naive MARL baseline) on different tasks (mpe-pp, 5v6, 8v9, 3s5z, 10v11). The x-axis represents the number of training timesteps, and the y-axis represents the mean test return across five trials with 95% confidence intervals shown as shaded regions. The figure demonstrates that POAM generally outperforms the baselines in terms of either sample efficiency or asymptotic return, indicating its effectiveness in handling uncontrolled teammates in various cooperative scenarios.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.

🔼 This figure displays the learning curves for POAM, IPPO-NAHT, POAM-AHT and the best naive MARL baseline across five different tasks (mpe-pp, 5v6, 8v9, 3s5z, 10v11). The results show that POAM outperforms baselines across all tasks, either in terms of sample efficiency or asymptotic return. The x-axis represents training timesteps, and the y-axis represents the mean test return.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.

🔼 The figure shows the learning curves of different algorithms (POAM, IPPO-NAHT, POAM-AHT, and the best naive MARL baseline) on four different tasks (mpe-pp, 5v6, 8v9, 3s5z). The x-axis represents training timesteps, and the y-axis represents the mean test return. Error bars representing the 95% confidence interval are included. The results demonstrate that POAM generally outperforms the baselines in terms of sample efficiency and/or asymptotic return, indicating its effectiveness in learning cooperative multi-agent behaviors in the presence of unknown teammates.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.

🔼 This figure shows the learning curves for the different methods (POAM, IPPO-NAHT, POAM-AHT, and Naive MARL) on four different tasks (mpe-pp, 5v6, 8v9, 3s5z). It demonstrates that POAM generally outperforms the baseline methods in terms of either sample efficiency or asymptotic return. The shaded areas represent 95% confidence intervals. The x-axis represents training timesteps (in millions), and the y-axis represents the average test return.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.

🔼 This figure displays the learning curves for the mpe-pp, 5v6, 8v9, 10v11, and 3s5z tasks. It compares the performance of the proposed POAM algorithm against three baselines: IPPO-NAHT (Independent PPO in the NAHT setting), POAM-AHT (POAM in the AHT setting), and the best-performing naive MARL algorithm. The x-axis represents training timesteps, and the y-axis represents the mean test return. The figure shows that POAM generally outperforms the baselines in terms of both sample efficiency and asymptotic return, demonstrating its effectiveness in handling uncontrolled teammates.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.

🔼 The figure shows the learning curves for four different algorithms across four different tasks (mpe-pp, 5v6, 8v9, and 3s5z). Each curve represents the average test return over five trials, with shaded regions representing the 95% confidence intervals. The algorithms compared are POAM (the proposed algorithm), IPPO-NAHT (a baseline using IPPO adapted for the NAHT problem), POAM-AHT (using the POAM algorithm with only a single agent to represent the controlled agents), and the best performing baseline among several naive MARL algorithms. The figure demonstrates that POAM outperforms the other three methods in terms of sample efficiency and asymptotic return across these experiments.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.

🔼 The figure shows the learning curves of POAM and IPPO-NAHT across four different tasks (mpe-pp, 5v6, 8v9, 3s5z). It also displays the asymptotic test returns achieved by the best naive MARL baseline and POAM-AHT across these tasks. The results demonstrate that POAM generally outperforms all the baseline methods in either sample efficiency or asymptotic return.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.

🔼 The figure shows the learning curves of POAM and IPPO-NAHT, and the test returns achieved by the best naive MARL baseline and POAM-AHT, on various tasks (mpe-pp, 5v6, 8v9, 10v11, 3s5z). It visually demonstrates that POAM outperforms the baselines in terms of sample efficiency and/or asymptotic return across multiple multi-agent cooperative tasks. The y-axis represents the mean test return, and the x-axis represents the number of training timesteps. Shaded regions indicate 95% confidence intervals.
read the caption
Figure 3: POAM consistently improves over the baselines of IPPO-NAHT, POAM-AHT, and the best naive MARL baseline in all tasks, in either sample efficiency or asymptotic return.

🔼 This figure shows two plots that visualize how the performance of the agent modeling module within POAM changes over time during training. The left plot displays the mean squared error (MSE) between the actual observations of the teammates and the predictions made by POAM’s agent modeling network. The right plot shows the average probability that the actions predicted by POAM’s model for the teammates actually match the actions that the teammates choose. The plots illustrate that, as the training progresses, the MSE decreases, and the probability of accurate predictions increases, indicating that POAM’s agent modeling module improves its ability to predict the behavior of the teammates over time.
read the caption
Figure 5: Evolution of a POAM agent's within-episode mean squared error (left) and within-episode probability of actions of modeled teammates (right), over the course of training on mpe-pp.

🔼 This figure shows how the performance of POAM and POAM-AHT changes as the number of controlled agents varies. The x-axis represents the number of controlled agents, and the y-axis represents the mean test return. The different lines represent different tasks (mpe-pp, 5v6, 8v9, 10v11, 3s5z). The horizontal dashed lines show the self-play performance of each algorithm (i.e., when all agents are controlled). POAM consistently outperforms POAM-AHT when more than one agent is controlled. The performance of POAM-AHT decreases as the number of controlled agents increases, because its evaluation setting becomes further from the training setting (N=1).
read the caption
Figure 14: Comparing the performance of POAM versus POAM-AHT, as the number of controlled agents varies. POAM and POAM-AHT agents are evaluated with the following set of uncontrolled agents: QMIX, VDN, IQL, MAPPO, IPPO.
More on tables

🔼 This table shows the additional hyperparameters that were evaluated for the POAM algorithm. The hyperparameters control aspects of the encoder-decoder model used within POAM. The values shown in bold represent the values that were ultimately selected for use in the experiments.
read the caption
Table 2: Additional hyperparameters evaluated for POAM; note that ED stands for encoder-decoder. Selected values are bolded.

🔼 This table presents the results of an experiment comparing the performance of two algorithms, POAM-AHT and POAM, on a simple game with varying numbers of controlled agents (N). POAM-AHT is an algorithm designed for the Ad Hoc Teamwork (AHT) setting (N=1), while POAM is designed for the N-Agent Ad Hoc Teamwork (NAHT) setting (N>1). The results show that both algorithms perform optimally when only one agent is controlled (N=1), but POAM significantly outperforms POAM-AHT when more agents are controlled (N=2), highlighting the limitations of using an AHT algorithm in a NAHT setting.
read the caption
Table 3: Returns of POAM-AHT versus POAM on the three agent bit matrix game, in the N=1 (AHT) and N=2 (NAHT) setting. POAM and POAM-AHT both achieve the optimal return for the N = 1 case, but POAM has a much higher return on the N = 2 case.
Full paper#