↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training Mixture of Experts (MoE) models from scratch is computationally expensive, hindering their widespread adoption. Existing MoE architectures are also not optimized for incorporating pre-trained models, limiting their effectiveness. This research addresses these issues by introducing MoE Jetpack.
MoE Jetpack introduces two key innovations: 1) checkpoint recycling, which utilizes pre-trained dense models to initialize MoE models and accelerate convergence; and 2) a novel hyperspherical adaptive MoE (SpheroMoE) layer, which optimizes the MoE architecture for efficient fine-tuning. Experiments show that MoE Jetpack significantly speeds up convergence (up to 8x faster) and improves accuracy (up to 30% gains) compared to training MoE models from scratch, demonstrating its effectiveness and efficiency. The open-sourced code further contributes to the broader accessibility and adoption of MoE models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with Mixture of Experts (MoE) models. It presents a novel and efficient method to leverage pre-trained dense models, significantly reducing training time and resource needs. This opens doors for broader MoE adoption and inspires further research into efficient model scaling techniques. The open-sourced code further enhances its impact on the research community.
Visual Insights#
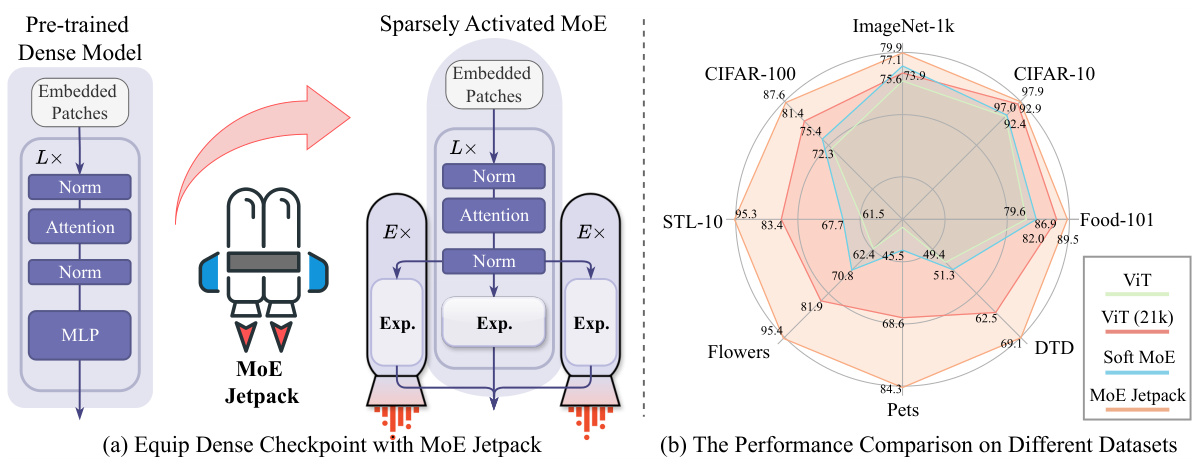
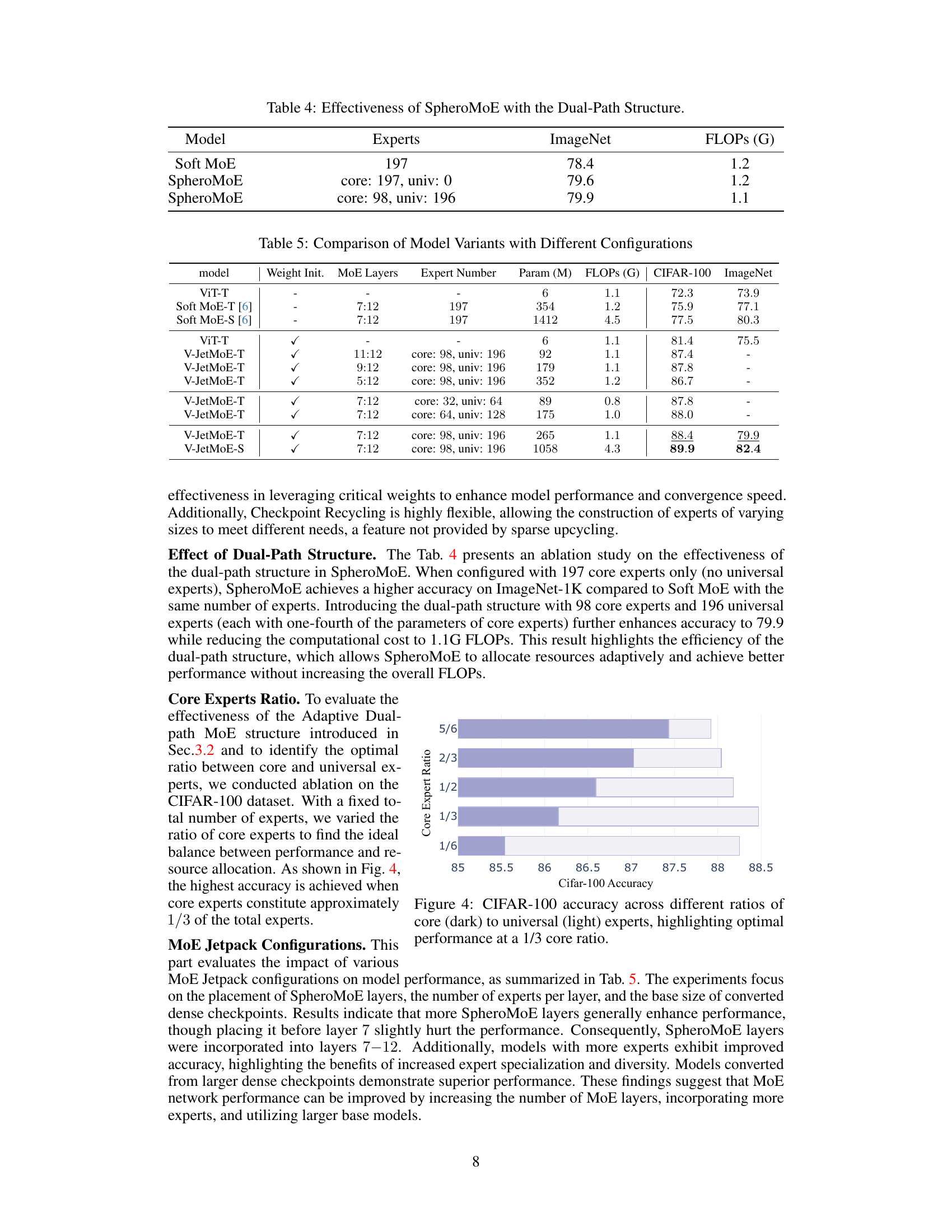
This figure demonstrates the core idea of MoE Jetpack and its performance. (a) shows how MoE Jetpack leverages pre-trained dense models to initialize MoE models efficiently. It replaces some layers of a dense model with MoE layers, initialized using weights from the dense model. (b) compares the performance of models trained using different methods across multiple datasets, showing that MoE Jetpack significantly outperforms training from scratch and achieves better results than Soft MoE.

This table presents a comparison of the performance of different models on various image recognition datasets. The models compared include Dense models (trained from scratch), Dense models initialized with ImageNet-21k pre-trained weights, Soft MoE models (trained from scratch), and MoE Jetpack models. The datasets include ImageNet-1k, Food-101, CIFAR-10, CIFAR-100, STL-10, Flowers, Pets, and DTD. The table shows the accuracy achieved by each model on each dataset, highlighting the improvement achieved by MoE Jetpack compared to other approaches.
In-depth insights#
MoE Jetpack Intro#
The hypothetical “MoE Jetpack Intro” section would likely introduce the core concept of MoE Jetpack, a framework designed to efficiently transform readily available dense model checkpoints into sparsely activated Mixture of Experts (MoE) models. It would highlight the key challenges of training MoE models from scratch, emphasizing the need for extensive data and computational resources. The introduction would then position MoE Jetpack as a solution, showcasing its ability to leverage pre-trained knowledge from dense models, thereby accelerating convergence and potentially improving accuracy. It would briefly touch upon the two main components of MoE Jetpack: checkpoint recycling and the SpheroMoE layer, setting the stage for a more detailed explanation of these techniques in subsequent sections. A strong introduction would also mention the expected performance gains and the availability of the code, enticing the reader to delve deeper into the intricacies of the proposed methodology.
Checkpoint Recycle#
Checkpoint recycling, a crucial technique in MoE Jetpack, cleverly leverages pre-trained dense model checkpoints to initialize MoE models. This innovative approach bypasses the computationally expensive and data-intensive process of training MoE models from scratch. By repurposing the knowledge embedded in readily available dense checkpoints, MoE Jetpack significantly accelerates convergence and enhances accuracy. The method is flexible, allowing for diverse initialization strategies, including importance-based weight sampling, co-activation graph partitioning, and others. This technique drastically reduces the need for extensive pre-training, especially beneficial when working with smaller datasets, showcasing the framework’s efficiency and wide applicability. The integration of checkpoint recycling with the hyperspherical adaptive MoE layer further optimizes the fine-tuning process, resulting in superior performance. In essence, checkpoint recycling serves as a powerful initialization mechanism, transforming pre-trained weights into high-quality initialization weights for MoE models and substantially boosting their overall efficacy.
SpheroMoE Layer#
The SpheroMoE layer represents a novel contribution for enhancing MoE model performance. Its core innovation lies in hyperspherical routing, employing cross-attention to distribute input tokens to expert slots efficiently. This method improves upon traditional top-k routing by promoting balanced expert utilization and reducing computational overhead. Further enhancements include expert regularization techniques, such as learnable softmax temperatures and expert dropout, to prevent over-specialization and improve model generalization. The integration of an adaptive dual-path structure further optimizes the layer by dynamically allocating tokens based on importance, directing high-impact tokens to a smaller set of larger experts and less critical tokens to a larger number of smaller experts for efficient computation. Overall, the SpheroMoE layer is designed to synergistically work with checkpoint recycling to optimize MoE model fine-tuning, accelerating convergence and increasing accuracy.
Future of MoE#
The future of Mixture of Experts (MoE) models is bright, driven by their ability to scale model capacity without a proportional increase in computational cost. Key areas for advancement include more sophisticated routing mechanisms that dynamically assign tokens to experts based on nuanced contextual information, improving efficiency and accuracy. Research into novel expert architectures beyond simple MLPs, perhaps leveraging specialized neural networks for different tasks, could unlock significant performance gains. Addressing the challenge of expert over-specialization is crucial for improved generalization across diverse datasets and tasks, which may involve innovative regularization techniques or training strategies. Efficient methods for pre-training MoE models or leveraging existing dense checkpoints are critical to reduce training costs and time; MoE-Jetpack represents a significant step in this direction. Finally, further exploration of adaptive and dynamic MoE architectures is needed, where the number of experts or their configurations adjust based on input characteristics or learned features. These advancements will likely lead to more robust, efficient, and powerful MoE models capable of handling increasingly complex tasks.
MoE Limitations#
Mixture-of-Experts (MoE) models, while offering significant advantages in scaling deep learning, face several limitations. Computational overhead during routing can become substantial, especially with a large number of experts and complex routing mechanisms. Imbalanced expert utilization is another issue; some experts might be heavily overloaded while others remain underutilized, impacting overall efficiency and potentially leading to over-specialization. The training complexity of MoE models is also considerable, requiring extensive data and computational resources. Furthermore, the design and optimization of the MoE architecture itself can be challenging, requiring careful consideration of various factors like expert capacity, routing strategies, and regularization techniques to achieve optimal performance. Lack of readily available pre-trained models further hinders their adoption compared to densely activated models. Addressing these limitations remains a key focus for future research and development in MoE.
More visual insights#
More on figures
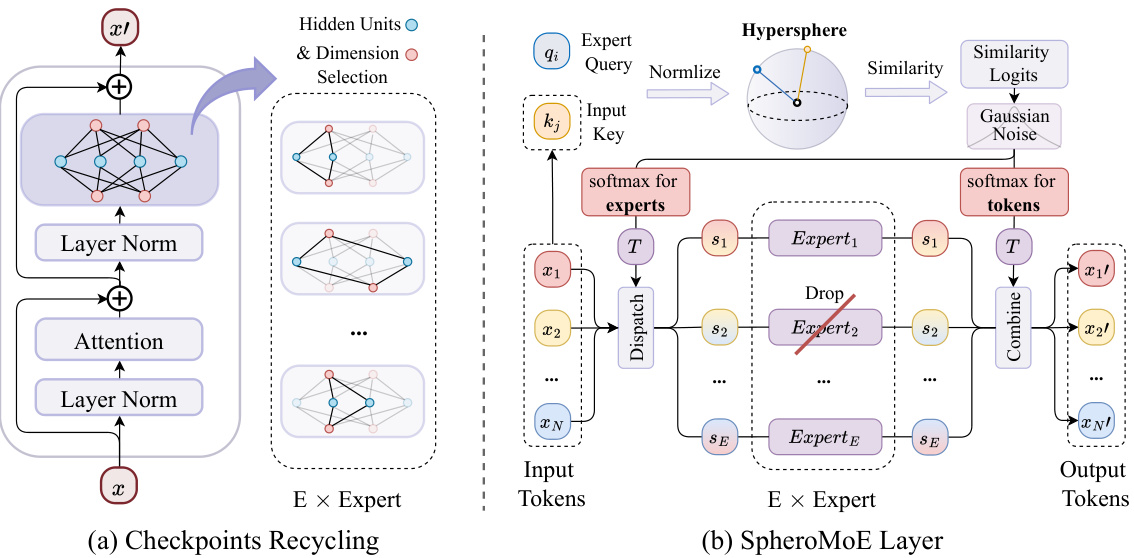
This figure shows two parts: (a) illustrates the architecture of MoE Jetpack. It converts dense checkpoints into initialization weights for MoE models to speed up convergence and improve performance while keeping FLOPs same. (b) shows the performance comparison of different model architectures across various datasets, including ImageNet-1k, CIFAR-10, CIFAR-100, STL-10, and more, highlighting the advantages of MoE Jetpack over training from scratch and pre-trained and fine-tuned ViT.

This figure illustrates the Adaptive Dual-path MoE, a key component of the SpheroMoE layer. It shows how input tokens are processed through two distinct pathways: a ‘core’ path for high-impact tokens and a ‘universal’ path for less critical ones. The core path uses fewer, larger experts, while the universal path utilizes more, smaller experts, optimizing computational efficiency and performance.
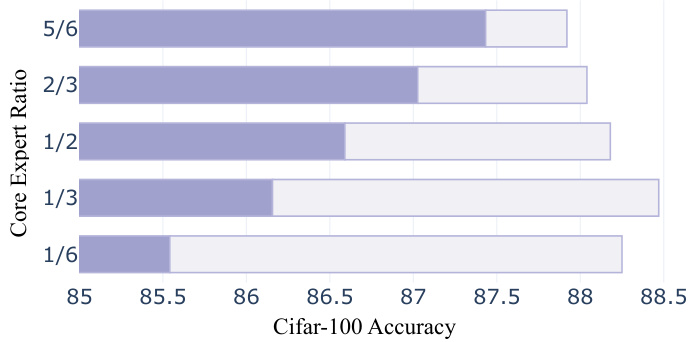
This figure shows the performance of the MoE Jetpack model on the CIFAR-100 dataset with varying ratios of core experts to universal experts. The x-axis represents the CIFAR-100 accuracy, and the y-axis represents the ratio of core experts to universal experts. The figure demonstrates that the optimal performance is achieved when the ratio of core experts to universal experts is approximately 1:3. This suggests that a balanced combination of specialized (core) and generalized (universal) experts is crucial for maximizing the model’s effectiveness.

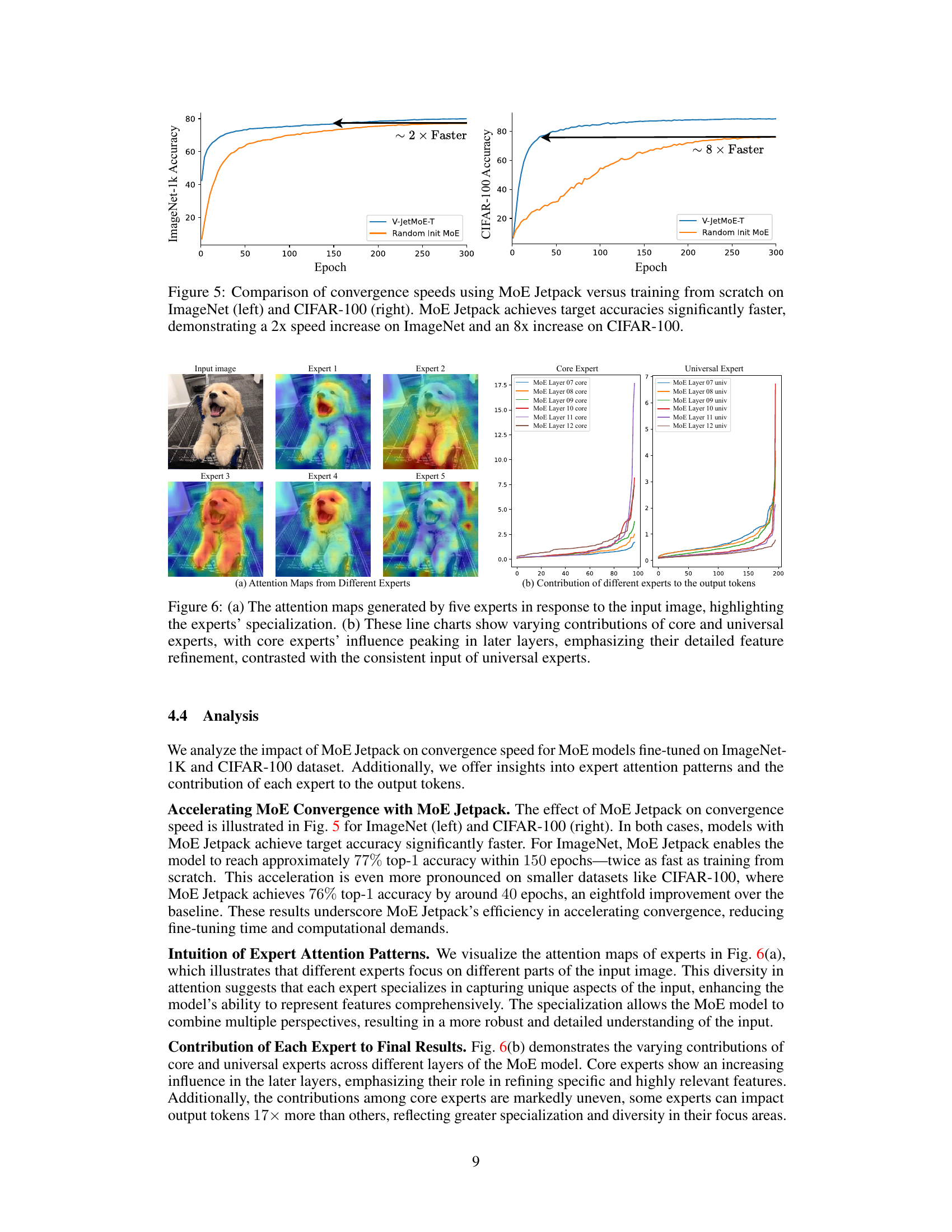
This figure compares the convergence speed of MoE Jetpack against training MoE models from scratch. The left panel shows the results for ImageNet-1k, demonstrating that MoE Jetpack achieves the target accuracy roughly twice as fast. The right panel shows the results for CIFAR-100, illustrating that MoE Jetpack is about eight times faster. The significant speedup highlights one of the key advantages of MoE Jetpack.

This figure visualizes the attention maps of five different experts (three core experts and two universal experts) responding to the same input image and their contributions to the final output tokens across different layers of the MoE model. The attention maps show that each expert focuses on specific regions of the input image which indicates specialization. The line charts demonstrate the different contributions made by core and universal experts across twelve layers of the MoE. Core experts show increasing influence in later layers, highlighting their role in detailed feature refinement. Conversely, universal experts maintain a relatively consistent level of contribution across all layers, indicating a more uniform integration of broader contextual information.

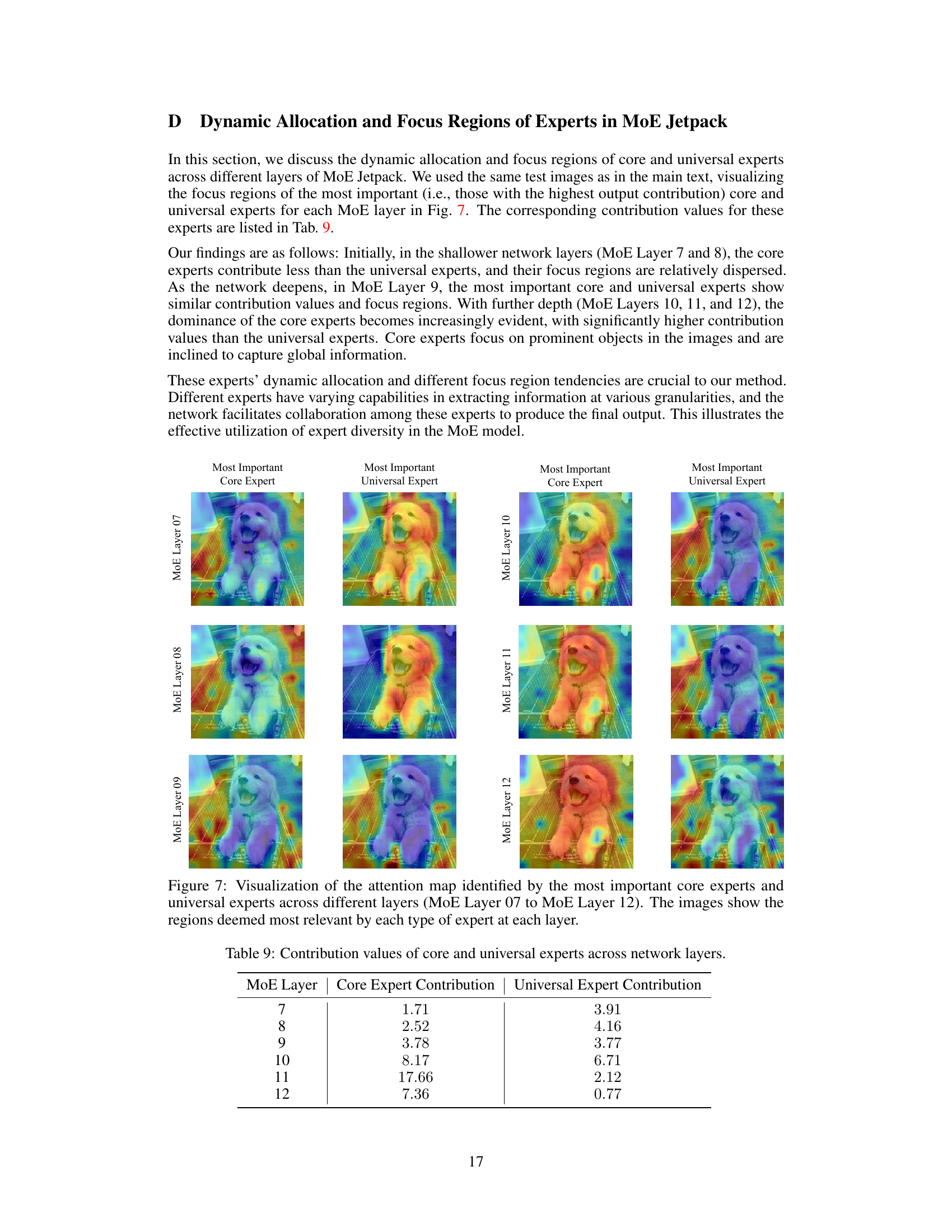
This figure visualizes the attention maps generated by the most important core and universal experts across different layers of the MoE Jetpack model. It shows how these experts focus on different regions of the input image, with core experts focusing on more detailed features and universal experts providing broader contextual information. The visualization highlights the dynamic allocation and specialization of experts within the model, illustrating how their contributions evolve across different layers.
More on tables

This table compares the performance of four different checkpoint recycling strategies (Random Sampling, Uniform Selection, Graph Partitioning, Importance-based Sampling) against the Sparse Upcycling method [16] on the ImageNet dataset. The results demonstrate the superior performance of Importance-based Sampling, achieving an accuracy of 79.9 compared to the other methods and Sparse Upcycling, which only achieves 79.1.

This table presents the ablation study results on the MoE Jetpack components. It compares the performance of different model configurations on ImageNet, CIFAR-100, and Flowers datasets. The configurations include the baseline ViT-T model, Soft MoE with Checkpoints Recycling, Soft MoE with Checkpoints Recycling and SpheroMoE, demonstrating the contribution of each component to the model’s performance. The mean accuracy across all datasets is shown for each configuration, illustrating the performance improvements from incorporating each component.

This table presents a comparison of the performance of different model configurations on ImageNet. The models compared include SoftMoE with 197 experts, SpheroMoE with 197 core experts and 0 universal experts, and SpheroMoE with 98 core experts and 196 universal experts. The table shows the ImageNet accuracy and FLOPs (floating point operations) for each model configuration. The results highlight the effectiveness of the SpheroMoE architecture, particularly when using the dual-path structure with a combination of core and universal experts, in improving accuracy while maintaining computational efficiency.

This table compares the performance of different models on visual recognition tasks using two different architectures, ViT-T and ConvNeXt-F. It shows the accuracy achieved by dense models trained from scratch, dense models initialized with ImageNet-21K pre-trained weights and fine-tuned on the target dataset, Soft MoE models trained from scratch, and MoE Jetpack models. The MoE Jetpack models are initialized using checkpoint recycling with pre-trained dense checkpoints from ImageNet-21K and then fine-tuned. The table highlights the superior performance of MoE Jetpack across various datasets compared to the baseline models.

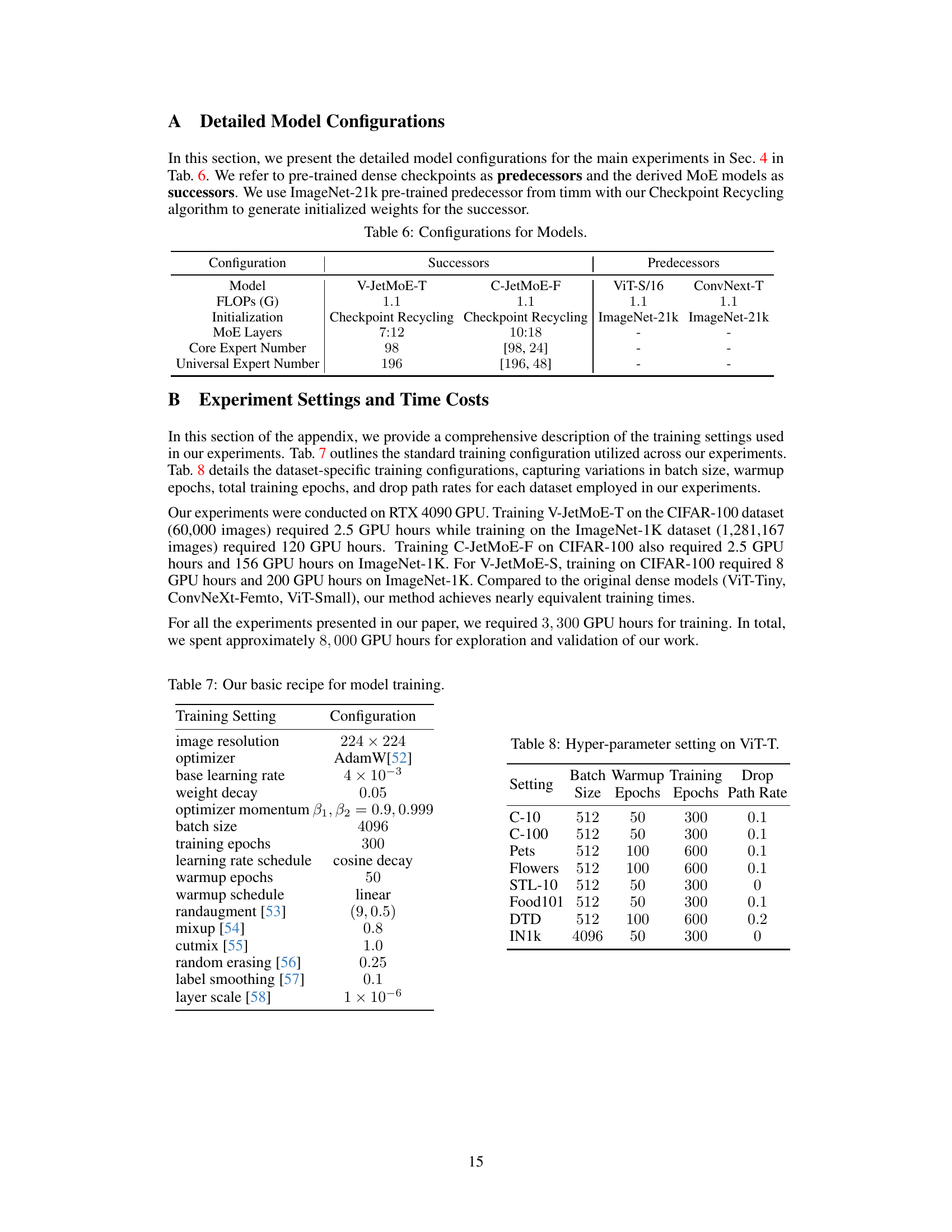
This table presents the detailed model configurations for the main experiments. It shows the model, FLOPs (floating point operations per second), initialization method, MoE (Mixture of Experts) layers, number of core experts, and number of universal experts for both successors (V-JetMoE-T and C-JetMoE-F) and predecessors (ViT-S/16 and ConvNeXt-T). The predecessors are pre-trained dense checkpoints used to initialize the successor MoE models via checkpoint recycling. The table clarifies the architectural differences between the dense models and the resulting MoE models.
This table presents a performance comparison of visual recognition tasks using two different model architectures, ViT-T and ConvNeXt-F. It compares the performance of Dense models (trained from scratch and with ImageNet-21k pre-trained weights), Soft MoE models (trained from scratch), and MoE Jetpack models (initialized using checkpoint recycling with ImageNet-21k pre-trained checkpoints and then fine-tuned). The results are shown for various datasets, including ImageNet-1k, Food-101, CIFAR-10, CIFAR-100, STL-10, Flowers, Pets, and DTD. The table highlights the improvements in accuracy achieved by MoE Jetpack compared to the other methods.
This table lists the hyperparameter settings used for training the Vision Transformer (ViT-T) model on eight different image classification datasets. The hyperparameters include batch size, warmup epochs, total training epochs, and drop path rate. These settings were adjusted for each dataset to optimize performance.

This table shows the contribution values of core and universal experts across different layers (MoE Layer 7 to 12) of the MoE Jetpack model. The contribution values indicate the relative importance of core and universal experts in producing the final output of each layer. The values demonstrate that the importance of core experts generally increases as the network goes deeper, while the contribution of universal experts decreases.
Full paper#