↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Machine unlearning, the process of removing the effect of specific training data from a model, is a challenging task. Existing methods often struggle, especially when dealing with complex relationships between the data to be forgotten and the data to be retained. This paper investigates factors affecting unlearning difficulty and algorithm performance.
The researchers introduce RUM, a refined unlearning meta-algorithm, that addresses these challenges. RUM involves refining the forget set into more homogenous subsets based on entanglement and memorization scores, then employing a meta-algorithm to strategically apply suitable unlearning algorithms to each subset. Their experiments show that RUM substantially improves the accuracy and efficiency of existing unlearning algorithms across various datasets and architectures.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in machine learning and data privacy. It deepens our understanding of the unlearning process, identifies key factors affecting its difficulty, and proposes a novel meta-algorithm (RUM) for substantial performance improvements. This research directly addresses critical concerns regarding data deletion requests and user privacy in machine learning systems, opening up avenues for more robust and efficient data handling methods.
Visual Insights#

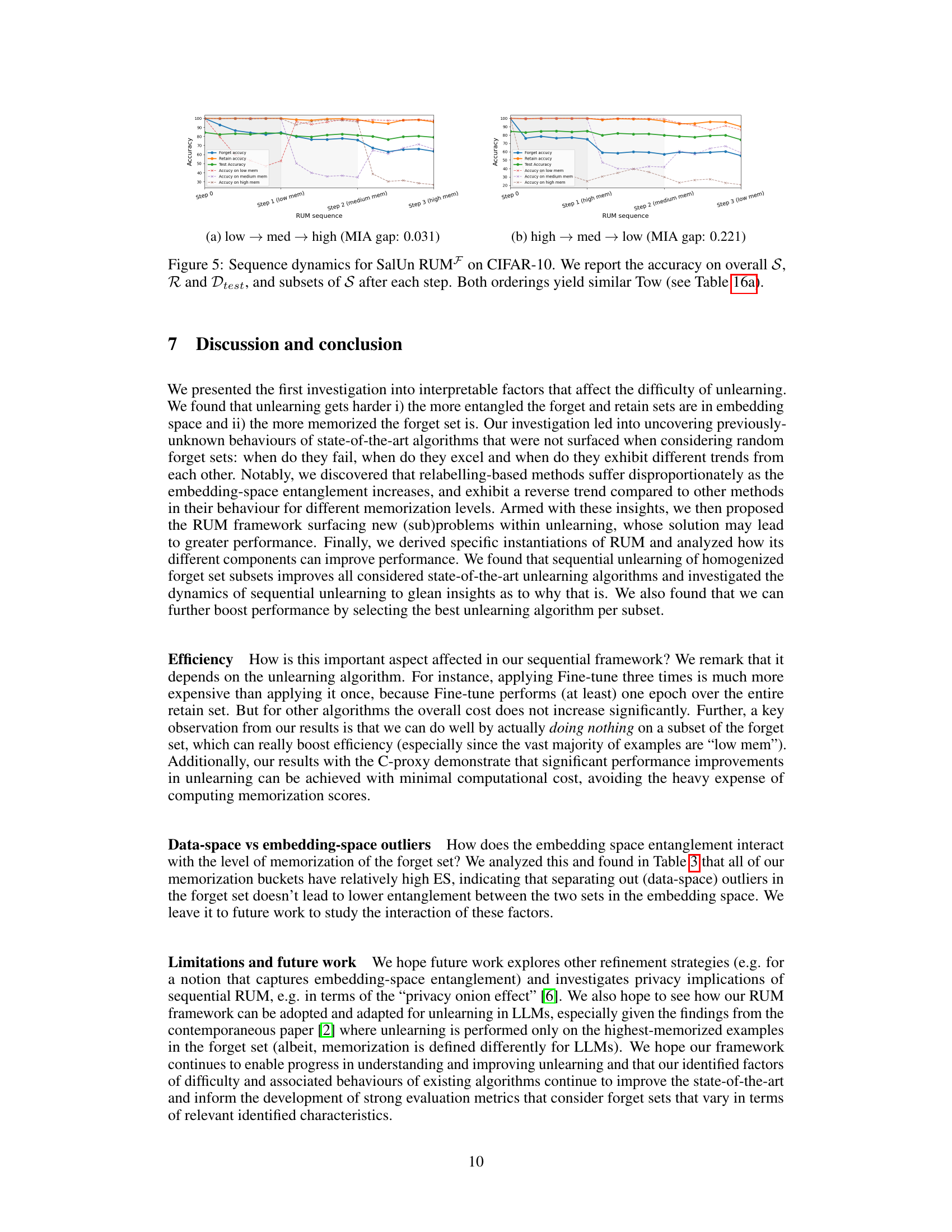
This figure demonstrates the impact of two key factors on unlearning difficulty: entanglement and memorization. The left subplot shows that higher entanglement between retain and forget sets (measured by Entanglement Score) results in greater difficulty in unlearning, whereas the right subplot illustrates that less memorized forget sets (lower memorization score) make unlearning easier. The results are presented using the ’tug-of-war’ (ToW) metric, and error bars represent 95% confidence intervals.
This table shows the results of applying different unlearning algorithms to datasets with varying degrees of entanglement between the retain and forget sets. The results are measured by the Tug-of-War (ToW) metric, which balances forgetting performance on the forget set with retention performance on the retain set. Lower ToW scores indicate more difficult unlearning problems. The table demonstrates that as entanglement increases (moving from low to high ES), unlearning becomes more challenging for all algorithms.
In-depth insights#
Unlearning Factors#
Analyzing the factors that influence the success or failure of machine unlearning reveals two key elements: data entanglement and memorization. High entanglement between the data retained and the data to be forgotten makes unlearning extremely challenging. This is because the model’s learned representations for the two sets are highly intertwined; removing one inevitably impacts the other. High memorization of the data to be forgotten presents a second obstacle. The model has more strongly encoded these data points into its weight structure; hence, removing their influence requires more sophisticated techniques and results in a greater chance of harming model performance on retained data. Understanding these competing forces is crucial for developing effective and efficient unlearning algorithms. Future research should focus on creating algorithms which intelligently disentangle these two factors to improve unlearning while minimizing negative impacts to model performance.
RUM Framework#
The RUM (Refined-Unlearning Meta-algorithm) framework is a novel approach to machine unlearning that addresses the limitations of existing methods. It tackles the heterogeneity of forget sets by first refining them into homogeneous subsets based on key factors affecting unlearning difficulty, such as data entanglement and memorization. This refinement process allows for a more nuanced and effective unlearning process. Then, RUM employs a meta-algorithm to strategically apply different unlearning algorithms to each refined subset, selecting the most appropriate technique for each subset’s characteristics, leveraging the strengths of various state-of-the-art techniques. This two-step process significantly improves the overall unlearning performance, enabling a more precise removal of unwanted data and mitigating the negative consequences often associated with standard methods. The RUM framework enhances understanding of unlearning by explicitly addressing previously under-explored aspects, improving the current state of the art.
Memorization Impact#
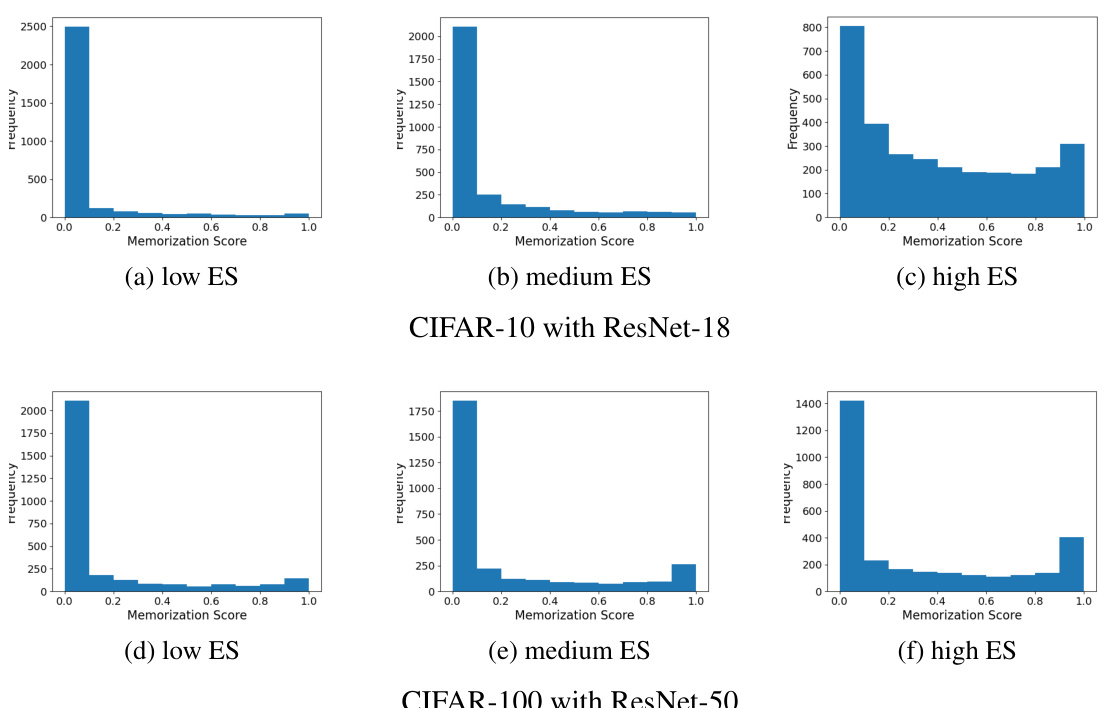
The concept of memorization in deep learning models, and its impact on the difficulty of machine unlearning, is a critical focus. Highly memorized examples, where the model’s predictions strongly depend on the presence of that specific training instance, significantly hinder unlearning. Algorithms struggle to remove the effect of such examples without negatively affecting performance on the remaining data. In contrast, examples that are not memorized pose less of a challenge for unlearning, as their effect is more diffuse and their removal has a smaller impact on the overall model. This memorization effect isn’t uniformly distributed; the level of memorization for a specific data point can vary greatly based on factors such as its position in data space and its inherent characteristics. Thus, the impact of memorization must be considered in algorithm design and is a valuable aspect in assessing the success of a machine unlearning approach. The degree of memorization strongly correlates with the difficulty in removing a data point from a model, highlighting it as a core challenge in machine unlearning. Furthermore, the effect of memorization is heavily influenced by the entanglement of the retain and forget sets, leading to complex interactions that require further investigation.
Entanglement Effects#
The concept of “Entanglement Effects” in the context of machine unlearning describes the phenomenon where the learned representations of data points in the retain set and forget set become intertwined. High entanglement makes unlearning significantly harder because attempting to remove the influence of the forget set inevitably affects the retain set, impacting model utility. This is because the model’s internal representations don’t cleanly separate these sets; their features are deeply interconnected within the model’s learned latent space. This entanglement is not readily apparent when using random forget sets; instead, it is a crucial factor in determining the success and failure of unlearning algorithms. The degree of entanglement varies depending on characteristics of the data and the training process. Measuring entanglement requires analyzing the learned representations, and understanding this relationship is a key step towards developing more robust and effective unlearning techniques. Further research into quantifying and mitigating entanglement is crucial for advancing the field of machine unlearning.
Future of Unlearning#
The future of unlearning hinges on several key advancements. Improving the efficiency of unlearning algorithms is crucial, moving beyond retraining which is computationally expensive. This necessitates developing more sophisticated methods that selectively remove the impact of forgotten data without significantly affecting the model’s performance on retained data. Understanding and mitigating the inherent trade-offs between forgetting quality, utility, and efficiency requires further research. A deeper understanding of how different data characteristics (e.g., memorization, entanglement) influence unlearning difficulty will enable the design of more robust and adaptable algorithms. The development of interpretable metrics for evaluating unlearning effectiveness is also critical. Finally, integrating unlearning into the design and development of machine learning systems from the ground up, rather than as an afterthought, will be vital in ensuring responsible and ethical use of these powerful technologies.
More visual insights#
More on figures

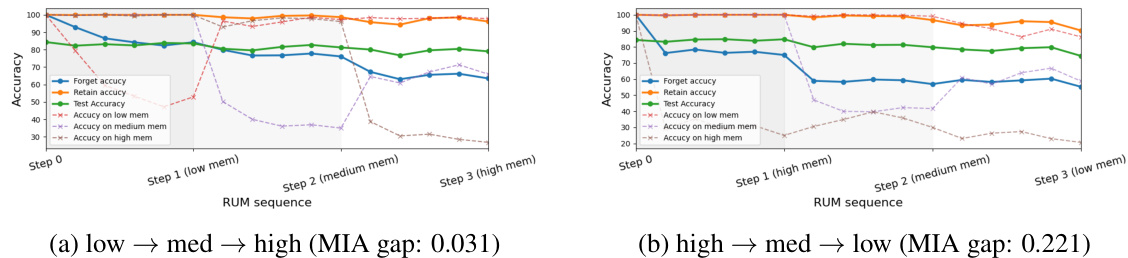
This figure illustrates the Refined-Unlearning Meta-algorithm (RUM). It consists of two main steps: refinement and meta-unlearning. In the refinement step, the forget set S is divided into K homogeneous subsets. Then, in the meta-unlearning step, the algorithm selects the best unlearning algorithm for each subset and executes them sequentially to obtain a model that has unlearned the entire forget set. The order of execution is determined by the meta-algorithm to maximize the unlearning performance.
This figure shows the results of an investigation into two factors affecting unlearning difficulty: entanglement and memorization. The left panel shows that higher entanglement scores (ES) correlate with lower ToW scores, indicating that more entangled retain and forget sets make unlearning more difficult. The right panel shows that lower memorization scores correlate with higher ToW scores, indicating that less memorized forget sets are easier to unlearn. Error bars show the 95% confidence intervals from multiple runs of each unlearning algorithm.

This figure shows the results of an investigation into two factors affecting unlearning difficulty: entanglement between retain and forget sets and memorization of forget sets. The left panel shows that higher entanglement (measured by an entanglement score) correlates with harder unlearning (lower ToW score). The right panel shows that lower memorization (measured by memorization score) of the forget set leads to easier unlearning (higher ToW score). Error bars represent 95% confidence intervals.
This figure shows the results of experiments designed to investigate two factors affecting unlearning difficulty: entanglement between retain and forget sets and memorization of the forget set. The left subplot shows that higher entanglement (measured by the Entanglement Score) correlates with lower ToW scores (indicating harder unlearning), while the right subplot shows that lower memorization correlates with higher ToW scores (easier unlearning). Error bars represent 95% confidence intervals.
This figure shows two key factors affecting the difficulty of unlearning: entanglement between retain and forget sets and memorization of the forget set. The left plot demonstrates that higher entanglement (measured by the Entanglement Score, ES) leads to harder unlearning, as indicated by lower ToW scores. The right plot shows that less memorized forget sets (having less influence on the model) result in easier unlearning (higher ToW). Error bars represent 95% confidence intervals, calculated from multiple runs of each algorithm.

This figure shows the results of an investigation into two factors affecting unlearning difficulty: entanglement between retain and forget sets and memorization of the forget set. The left plot shows that higher entanglement (measured by an entanglement score) correlates with lower ToW (tug-of-war) scores, indicating increased unlearning difficulty. The right plot shows that less memorized forget sets are easier to unlearn (for most algorithms). The error bars represent 95% confidence intervals, based on multiple algorithm runs.
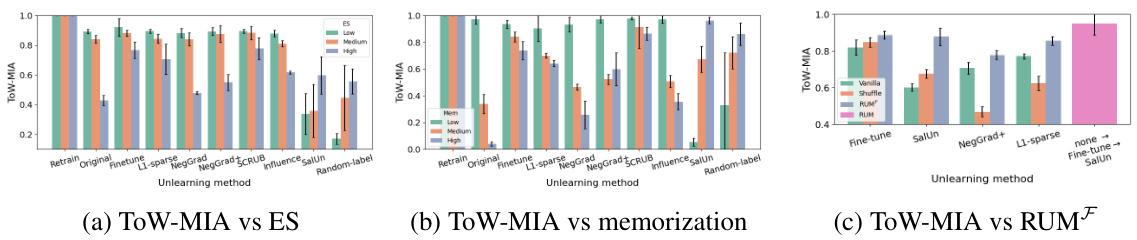
This figure shows two key factors that affect unlearning difficulty: entanglement and memorization. The left panel demonstrates that higher entanglement between retain and forget sets (measured by Entanglement Score) correlates with harder unlearning (lower ToW). The right panel shows that a less memorized forget set (lower memorization score) results in easier unlearning (higher ToW) for most algorithms. The error bars show the 95% confidence intervals based on multiple runs of each algorithm.
This figure shows the results of an experiment designed to identify factors affecting unlearning difficulty. The experiment measured the ’tug-of-war’ (ToW) score, which balances forgetting quality and model utility, for various state-of-the-art unlearning algorithms across different forget and retain sets. The left panel shows that unlearning difficulty increases as the entanglement between the retain and forget sets in the model’s embedding space increases. The right panel shows that unlearning difficulty decreases as the level of memorization of the forget set decreases.
This figure presents a two-part investigation into the factors affecting unlearning difficulty, using the ’tug-of-war’ (ToW) metric where higher values indicate better unlearning performance. The left subplot shows a strong correlation between the entanglement score (ES) of retain and forget sets (higher ES means more entanglement) and unlearning difficulty (higher ToW is easier to unlearn). The right subplot shows that the memorization score of the forget set is also strongly correlated with unlearning difficulty; lower memorization makes unlearning easier. Error bars represent 95% confidence intervals.

This figure shows the results of an investigation into two factors affecting unlearning difficulty: entanglement and memorization. The left panel demonstrates that higher entanglement between retain and forget sets (measured by the Entanglement Score, ES) correlates with lower ToW scores, indicating harder unlearning. The right panel shows that lower memorization scores (less memorization of the forget set) correlate with higher ToW scores, indicating easier unlearning. Error bars represent 95% confidence intervals, showing variability across multiple runs of the experiments.
This figure shows the results of an investigation into two factors affecting unlearning difficulty: entanglement and memorization. The left subplot shows that higher entanglement between retain and forget sets (measured by the Entanglement Score) correlates with harder unlearning (lower ToW). The right subplot shows that a less memorized forget set (lower memorization score) results in easier unlearning (higher ToW). Error bars represent 95% confidence intervals. The results are based on multiple runs of different unlearning algorithms.

This figure demonstrates two key factors that influence the difficulty of unlearning: entanglement and memorization. The left subplot shows that higher entanglement between retain and forget sets leads to harder unlearning. The right subplot shows that less memorized forget sets are easier to unlearn. Error bars indicate confidence intervals for the results.

This figure displays the results of an experiment to identify factors affecting unlearning difficulty. The left panel shows that the entanglement between retain and forget sets in the embedding space is correlated with unlearning difficulty. The right panel shows that the memorization level of the forget set is negatively correlated with unlearning difficulty. Error bars represent 95% confidence intervals calculated from multiple runs of each algorithm.
More on tables
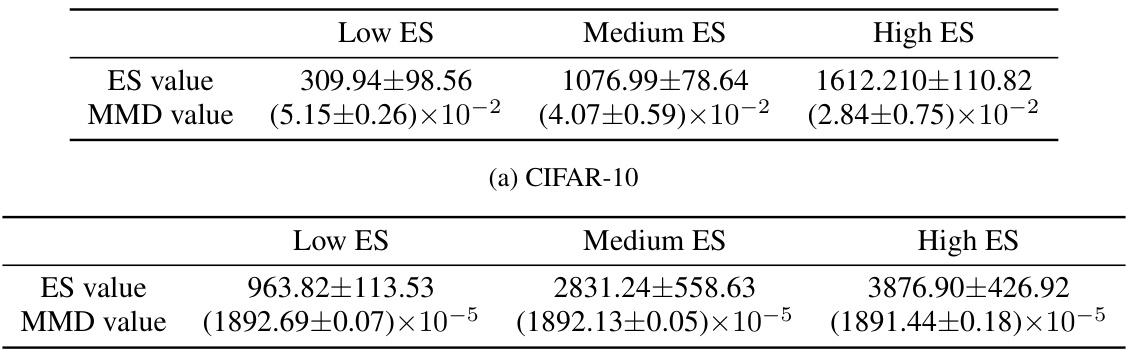
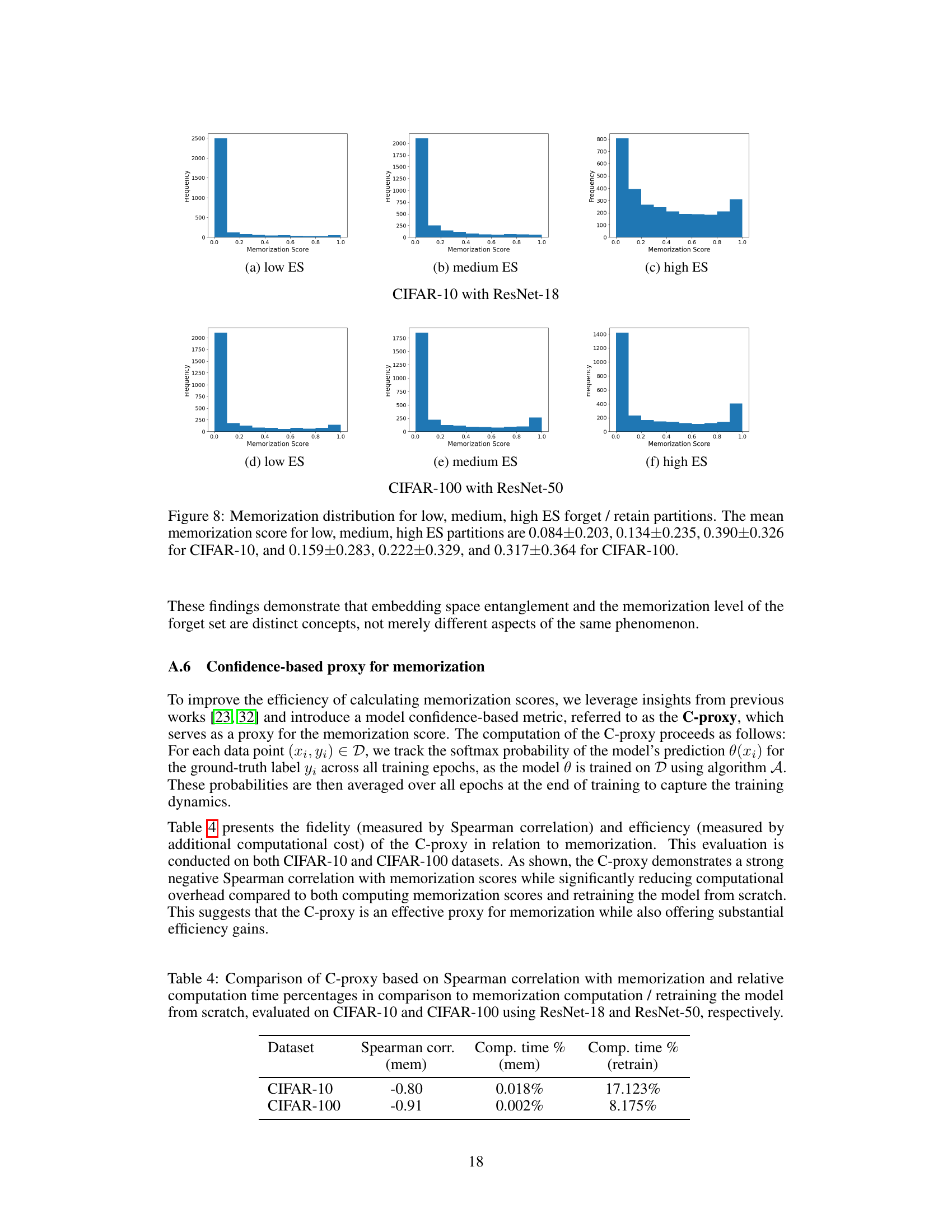
This table presents the Entanglement Score (ES) and Maximum Mean Discrepancy (MMD) values for different forget/retain set partitions created for CIFAR-10 and CIFAR-100 datasets. These partitions were designed to have varying levels of entanglement between the retain and forget sets, categorized as low, medium, and high. The ES measures the entanglement in the embedding space, while the MMD quantifies the distributional difference between the embeddings of the retain and forget sets. Lower MMD values indicate higher similarity, and thus lower entanglement. The table shows that the ES values increase from low to high, confirming the success of the partition creation method. The negative correlation between ES and MMD further supports the validity of this method for creating controlled entanglement.
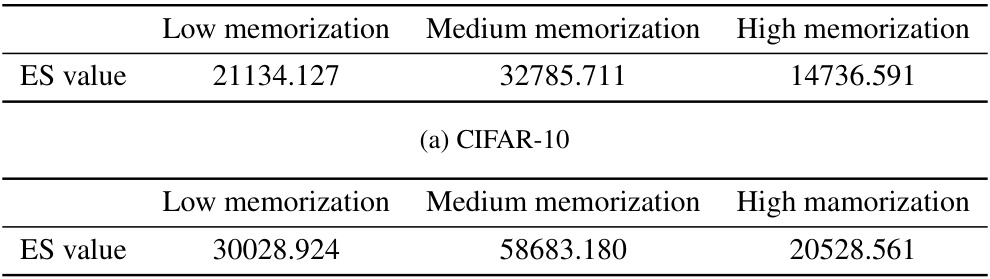
This table presents the entanglement scores (ES) calculated for different forget-retain set partitions based on memorization levels. It shows the ES values for low, medium, and high memorization levels for both CIFAR-10 and CIFAR-100 datasets. The ES measures the entanglement between the retain and forget sets in the embedding space. Higher ES values indicate greater entanglement, implying more difficulty in unlearning.
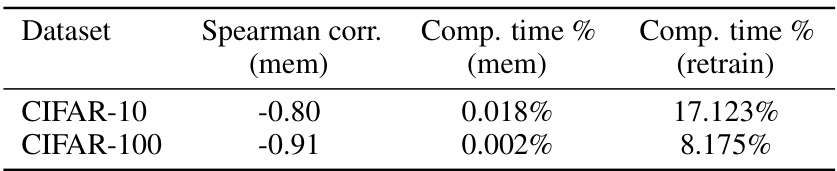
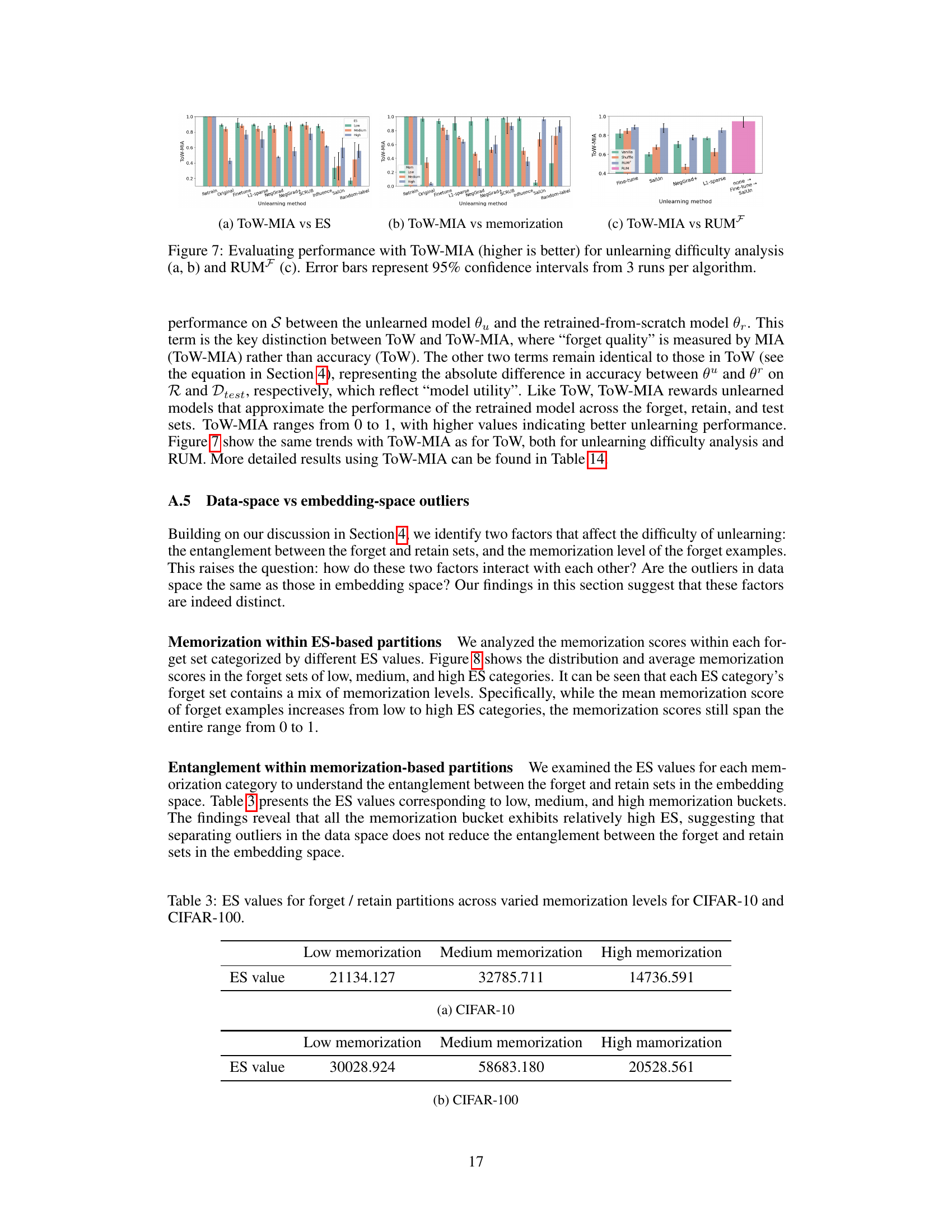
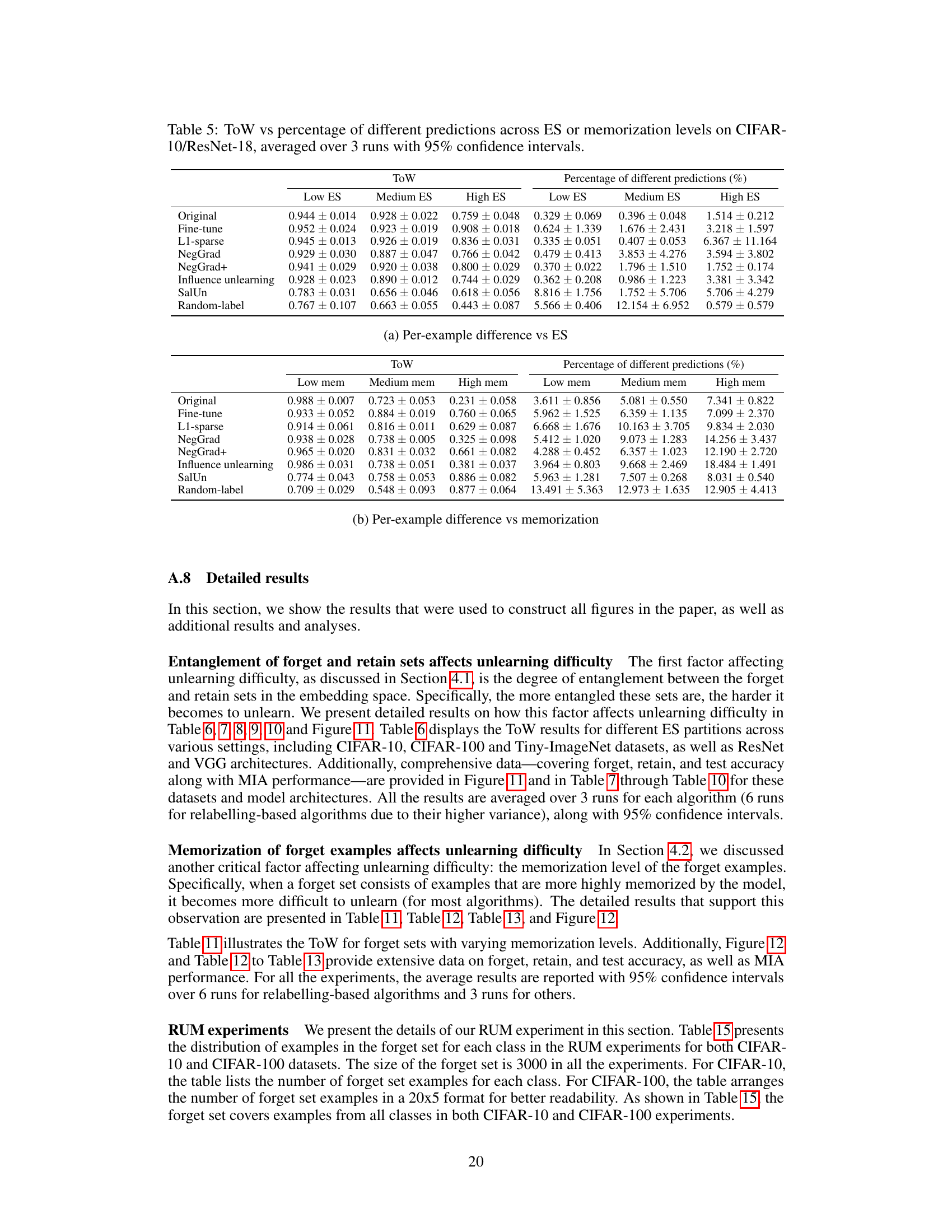
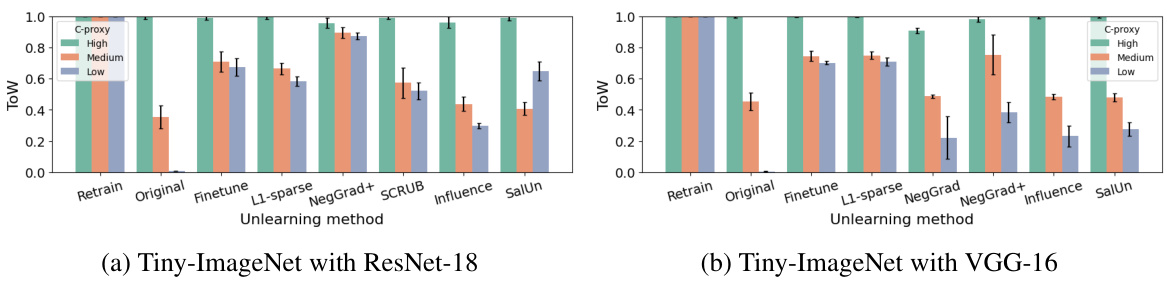
This table presents the effectiveness of C-proxy as a replacement for memorization scores. It shows that C-proxy has a strong negative correlation with memorization scores, indicating its suitability as a proxy. Additionally, it highlights the significant computational efficiency gains achieved by using C-proxy compared to calculating memorization scores or retraining the model from scratch.

This table presents a comparison of the ’tug-of-war’ (ToW) metric and the percentage of different predictions between the unlearned and retrained models for various unlearning algorithms across different levels of entanglement (ES) and memorization. The ToW metric measures the overall unlearning performance, balancing forgetting quality, retain performance and generalization. The percentage of different predictions provides a finer-grained assessment at the example level. This comparison allows for a detailed analysis of how different algorithms handle the tradeoffs between forgetting the forget set and retaining information about the retain set. The table shows that as entanglement (ES) or memorization increase, the percentage of different predictions also tends to increase indicating that unlearning becomes harder.
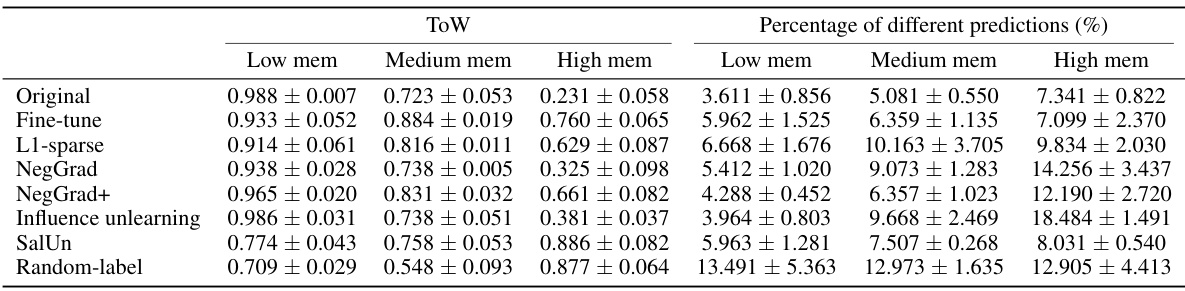
This table shows the results of evaluating unlearning algorithms using two metrics: ToW (Tug-of-War) and the percentage of different predictions between the unlearned and retrained models for various levels of entanglement (ES) and memorization. It provides a detailed breakdown of performance for different algorithms under varying levels of unlearning difficulty, enabling a comparison of the effectiveness of each approach based on both overall accuracy and the level of per-example disagreement between the unlearned and retrained models.

This table presents the Tug-of-War (ToW) metric for various unlearning algorithms across different entanglement levels (Low, Medium, High ES). The ToW metric is a single score reflecting the balance between forgetting quality, utility, and generalization. The results show that as entanglement increases (ES increases), the ToW score decreases for most algorithms, indicating increased unlearning difficulty.

This table presents the results of the Tug-of-War (ToW) metric for different unlearning algorithms across various datasets and model architectures. The ToW metric measures the effectiveness of unlearning by considering the balance between forgetting the forget set and retaining information from the retain set. The experiments were performed with varying degrees of entanglement (ES) between the forget and retain sets. The results demonstrate that as the entanglement (ES) increases, the ToW score decreases, indicating that unlearning becomes more difficult when the two sets are more entangled in the embedding space.
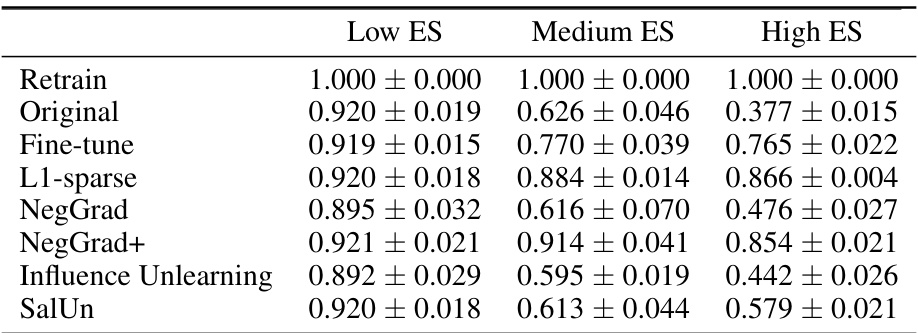
This table presents the Tug-of-War (ToW) metric for different unlearning algorithms under varying levels of entanglement (ES) between the retain and forget sets. The ToW metric balances forgetting quality and model utility. The results are shown for four different dataset and model architectures, comparing various unlearning techniques (Fine-tune, L1-sparse, NegGrad, NegGrad+, SCRUB, Influence Unlearning, SalUn, Random-label) against a baseline (Original) of not performing any unlearning. Higher ToW values indicate better unlearning performance. The table demonstrates that higher entanglement levels (High ES) lead to lower ToW scores across all algorithms, indicating increased unlearning difficulty.
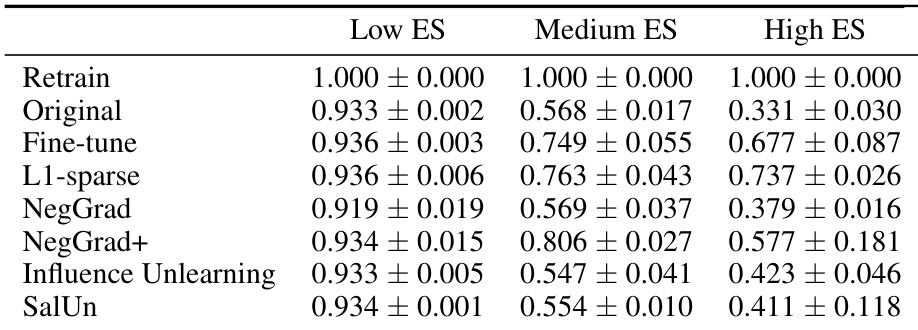
This table presents the results of applying different unlearning algorithms to forget/retain sets with varying degrees of entanglement (measured by Entanglement Score or ES). The results are reported as Tug-of-War (ToW) scores, a metric that balances forgetting performance on the forget set with retention and generalization on the retain and test sets. The table shows that as entanglement increases (from Low ES to High ES), the ToW score generally decreases, indicating that unlearning becomes more challenging when the forget and retain sets are more intertwined in the model’s embedding space. This trend holds for several state-of-the-art unlearning algorithms.

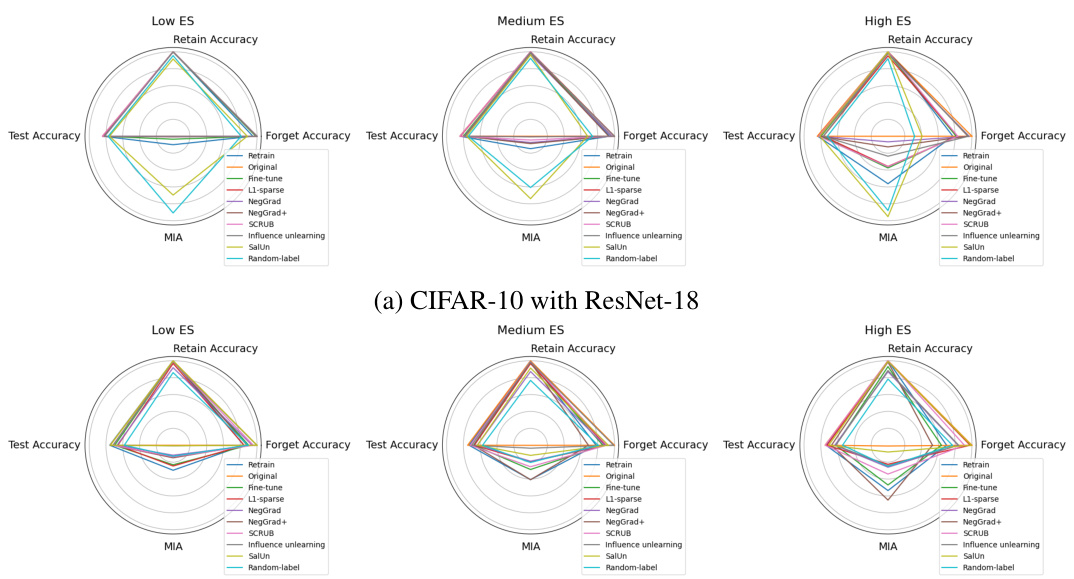
This table presents the results of applying various unlearning algorithms to CIFAR-10 dataset using ResNet-18. It shows the accuracy on the forget set, retain set, and test set, as well as the Membership Inference Attack (MIA) performance for each algorithm under three different levels of entanglement between the forget and retain sets (low, medium, high). The results provide insights into how the entanglement level affects the effectiveness of different unlearning algorithms.
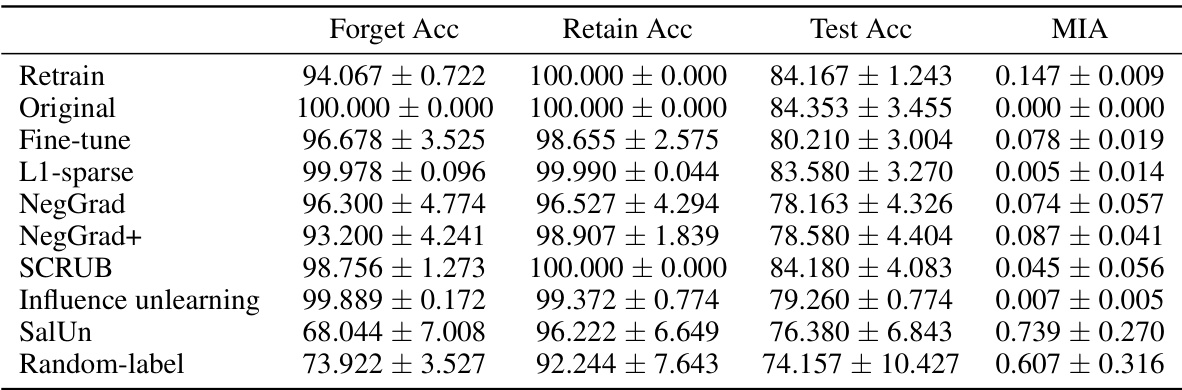
This table presents the accuracy and membership inference attack (MIA) performance for various unlearning algorithms on CIFAR-10 dataset using ResNet-18. The experiment is conducted for different levels of entanglement between retain and forget sets (measured by Entanglement Score - ES). The results are divided into low, medium and high ES groups. For each group, the table shows the forget accuracy, retain accuracy, test accuracy and MIA score. The table helps understand how the entanglement between sets affects the unlearning performance of different algorithms.
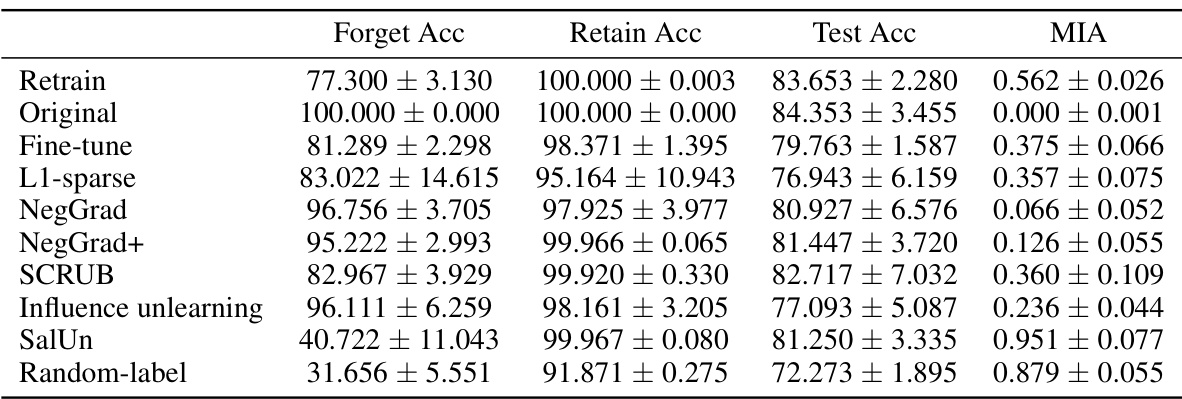
This table presents the results of applying different unlearning algorithms on CIFAR-10 dataset with ResNet-18 architecture. The forget and retain sets were created by varying the entanglement score (ES), a measure reflecting the degree of entanglement between the two sets. The table shows the forget accuracy, retain accuracy, test accuracy, and membership inference attack (MIA) results for each algorithm and each ES level. Higher values of ToW indicate better unlearning performance, while lower values of MIA gap (the absolute difference between MIA score of the unlearning method and that of re-training from scratch) mean better unlearning performance. The table allows for analysis of how different unlearning algorithms perform under varying levels of data entanglement.

This table presents the accuracy and membership inference attack (MIA) performance for various unlearning algorithms on the CIFAR-10 dataset using the ResNet-18 architecture. The results are broken down by different levels of entanglement score (ES) between the retained and forgotten sets. Each row represents an algorithm and shows its performance on the forget set, retain set, and test set (forget accuracy, retain accuracy, and test accuracy, respectively), along with the MIA score. The MIA score measures the success of an attacker in determining whether an example was part of the training data. A lower MIA score indicates better privacy protection.

This table presents the performance of various unlearning algorithms on the CIFAR-10 dataset using a ResNet-18 model. The performance is evaluated based on three metrics: forget accuracy, retain accuracy, test accuracy, and MIA. The table shows the results for three different levels of entanglement (ES) between the retain and forget sets: low, medium, and high. Each row represents a different unlearning algorithm, showing the performance of that algorithm for each of the three ES levels. The results highlight the impact of entanglement on unlearning effectiveness, showing that higher entanglement leads to lower accuracy and higher MIA scores.
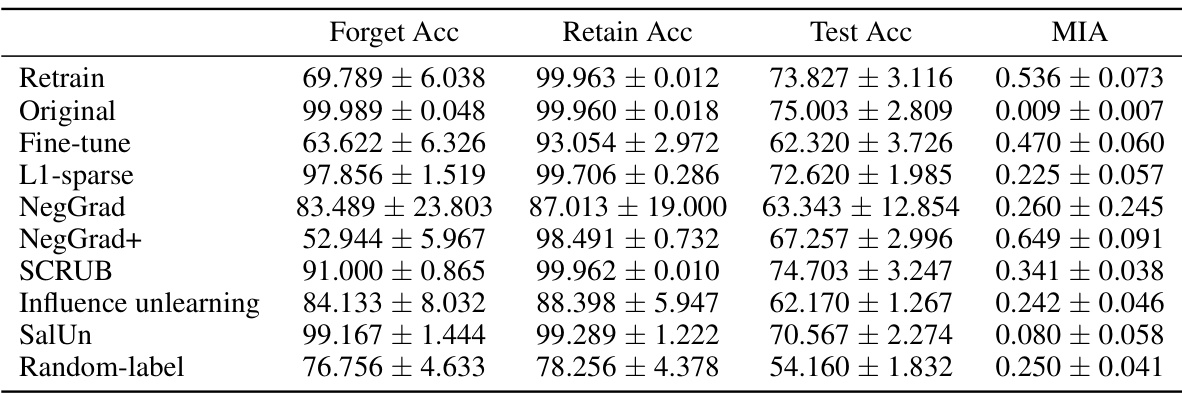
This table presents the accuracy and membership inference attack (MIA) results for various unlearning algorithms on the CIFAR-10 dataset using ResNet-18. The results are broken down by three levels of entanglement score (ES): low, medium, and high. For each ES level and algorithm, the table shows the forget accuracy (how well the model forgets the forget set), retain accuracy (how well the model retains information about the retain set), test accuracy (how well the model generalizes to unseen data), and the MIA score (a measure of how well the model hides the presence of the forget set examples). The results highlight the impact of data entanglement on the effectiveness of different unlearning algorithms.

This table presents the accuracy and membership inference attack (MIA) results for various unlearning algorithms on the CIFAR-10 dataset using a ResNet-18 model. The results are broken down by three different levels of entanglement scores (ES): low, medium, and high. For each ES level and algorithm, the table shows the forget accuracy, retain accuracy, test accuracy, and MIA score. This allows for a comparison of how well each algorithm performs under varying degrees of data entanglement and provides insight into the relationship between algorithm performance and ES.

This table presents the accuracy and membership inference attack (MIA) performance for several unlearning algorithms on the CIFAR-10 dataset using a ResNet-18 model. The experiments were conducted on forget/retain sets with varying degrees of entanglement (ES). The table displays the accuracy achieved on the forget set, retain set, and test set for each algorithm. Additionally, it reports the MIA score, which indicates the ability of the unlearning algorithm to prevent membership inference attacks. Higher accuracy on the retain and test sets and lower MIA scores indicate better unlearning performance.

This table shows the trade-off between forgetting quality and utility in unlearning algorithms for different entanglement and memorization levels of forget sets on CIFAR-10 dataset with ResNet-18 model. It compares the ToW (Tug-of-War) metric with the percentage of different predictions between the unlearned and retrained models for each example. Higher ToW indicates better overall unlearning performance, while a lower percentage of different predictions suggests better forgetting quality. The table is broken down by the entanglement score (ES) and memorization levels of the forget sets to show how those factors relate to unlearning performance.

This table presents the results of applying various unlearning algorithms to CIFAR-10 data using ResNet-18. It shows the accuracy on the forget set, retain set, and test set, along with the membership inference attack (MIA) score for different levels of entanglement scores (ES). The results demonstrate the impact of data entanglement on unlearning algorithm performance.
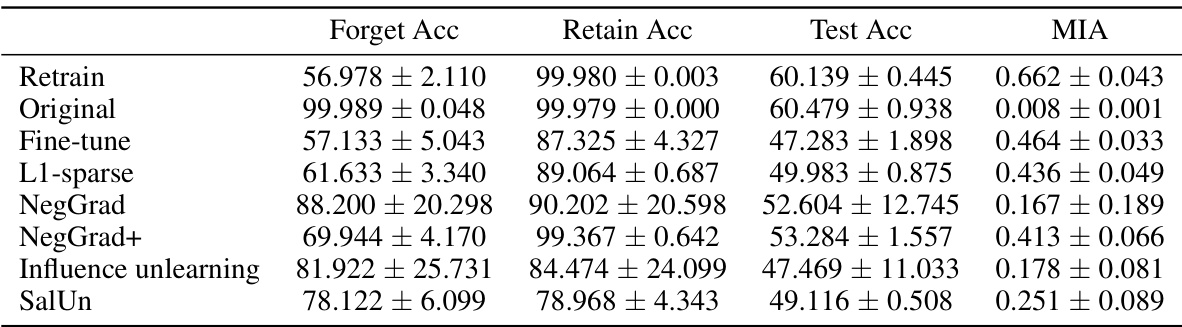
This table presents the performance of various unlearning algorithms on the CIFAR-10 dataset using the ResNet-18 architecture. The performance is evaluated across three different levels of entanglement between the retain and forget sets (low, medium, and high). The metrics used to evaluate performance include forget accuracy, retain accuracy, test accuracy, and the membership inference attack (MIA) gap. The MIA gap measures the difference between the MIA score of an unlearning algorithm and the MIA score obtained by retraining the model from scratch, where a smaller value indicates better privacy preservation.

This table presents the results of the Tug-of-War (ToW) metric and the percentage of differing predictions between the unlearned and retrained models for various unlearning algorithms. It shows the performance across different levels of entanglement (ES) and memorization, indicating how these factors affect unlearning difficulty. Lower ToW scores indicate harder unlearning problems.

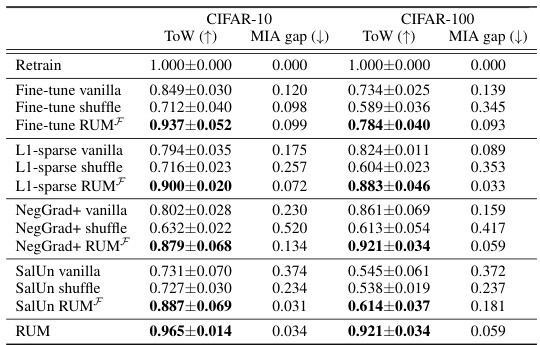
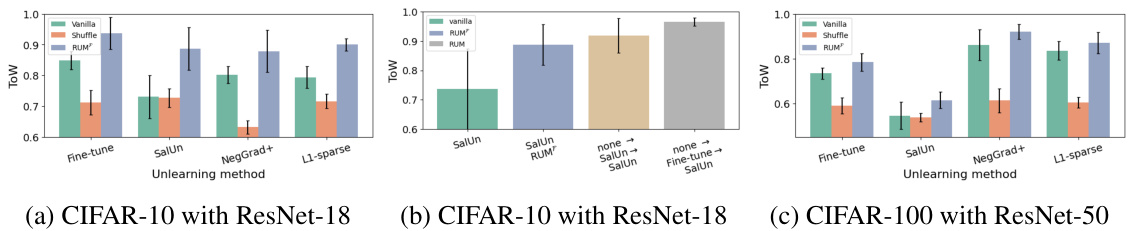
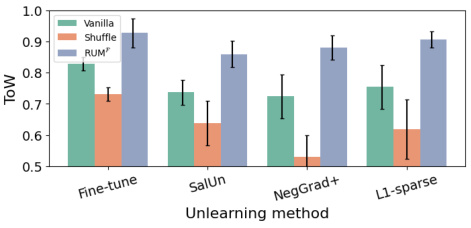
This table presents the results of the Tug-of-War (ToW) metric for different unlearning algorithms applied to forget sets with varying memorization levels. The ToW metric measures the trade-off between forgetting the forget set and maintaining performance on the retain set and test set. The results are shown separately for CIFAR-10 and CIFAR-100 datasets, with ResNet-18 and ResNet-50 architectures respectively. The table demonstrates how the difficulty of unlearning increases as the examples in the forget set become more memorized.

This table presents the results of the Tug-of-War (ToW) metric for various unlearning algorithms on CIFAR-10 and CIFAR-100 datasets. The ToW metric measures the difficulty of unlearning by considering the balance between forgetting the forget set and maintaining performance on the retain set. The table is organized by memorization level (Low, Medium, High) of the forget set examples. Each row represents a different unlearning algorithm, and each column represents a different memorization level. The values indicate the ToW scores. Lower scores imply greater difficulty in unlearning.

This table presents the results of applying various unlearning algorithms to datasets with varying entanglement scores (ES). It shows the forget accuracy, retain accuracy, test accuracy, and membership inference attack (MIA) scores for each algorithm. The results are broken down for low, medium, and high entanglement scores. Retraining from scratch is also included as a baseline for comparison.
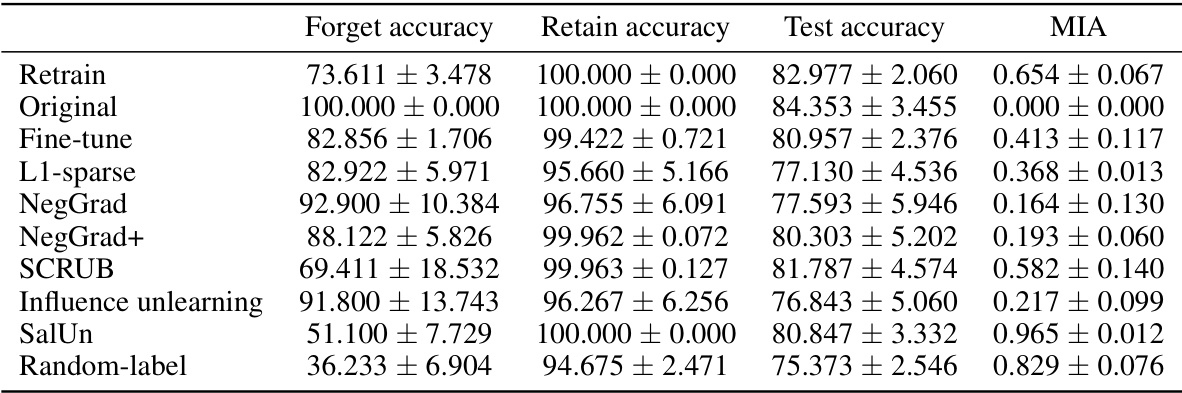
This table presents the performance of several unlearning algorithms on the CIFAR-10 dataset using a ResNet-18 model. The experiment varied the entanglement score (ES) of the forget and retain sets. The table shows the forget accuracy, retain accuracy, test accuracy, and membership inference attack (MIA) score for each algorithm and ES level. Higher ToW values indicate better performance, lower MIA values indicate better forgetting.

This table presents a comparison of the ’tug-of-war’ (ToW) metric and the percentage of different predictions between the unlearned and retrained models for various unlearning algorithms. The comparison is done across different levels of entanglement (ES) and memorization in the forget set. The ToW metric measures the overall performance of the unlearning algorithm, balancing forgetting quality, retain set accuracy, and test set accuracy. The percentage of different predictions offers a granular insight into how well each model matches the predictions of the retrained model at the individual example level. The table shows that generally, higher ToW scores (better unlearning performance) are associated with lower percentages of different predictions (better similarity to the retrained model).

This table presents the accuracy and membership inference attack (MIA) results for various unlearning algorithms applied to different forget/retain sets with varying entanglement scores (ES). It shows how the performance of each algorithm varies depending on the level of entanglement between the forget and retain sets. Lower ES indicates less entanglement, and higher ES indicates more entanglement.

This table presents a comparison of the ‘Tug-of-War’ (ToW) metric with the percentage of differing predictions between the unlearned and retrained models for various forget/retain set partitions categorized by entanglement score (ES) and memorization levels. The ToW metric captures the balance between forgetting the forget set and maintaining performance on the retain and test sets. The percentage of differing predictions provides a granular view of model behavior at the example level. The results are averaged over multiple runs and include 95% confidence intervals to indicate the statistical significance.

This table presents the comparison of ToW metric and the percentage of different predictions between the unlearned and retrained models on CIFAR-10 dataset with ResNet-18 architecture. The comparison is done for different levels of entanglement (ES) and memorization. For each level, the table shows the ToW values and the percentage of examples where the predictions of the unlearned and retrained models differ. The results are averages over 3 runs with 95% confidence intervals.
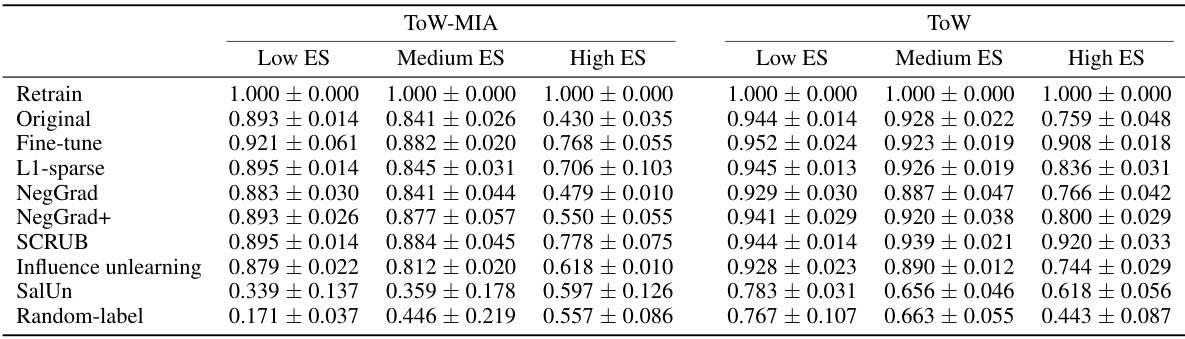
This table shows the results of the Tug-of-War (ToW) metric for different unlearning algorithms applied to forget sets with varying levels of memorization, using CIFAR-10 with ResNet-18 and CIFAR-100 with ResNet-50. The ToW metric measures the difficulty of unlearning, balancing the need to forget the forget set while maintaining performance on the retain set. The memorization level is a key factor determining the unlearning difficulty, as the table demonstrates that higher memorization levels lead to lower ToW scores, indicating harder unlearning.

This table presents the results of the Tug-of-War (ToW) metric for different unlearning algorithms applied to forget sets with varying levels of memorization. The ToW metric measures the trade-off between forgetting the forget set and retaining the ability to perform well on the retain and test sets. The table shows that, for most algorithms, as the memorization level of the forget set increases (meaning the model has memorized those examples more strongly), the ToW score decreases, indicating that unlearning becomes more difficult.

This table presents the results of the Refined-Unlearning Meta-algorithm (RUM) on CIFAR-10 and CIFAR-100 datasets. It compares the performance of applying unlearning algorithms in three different ways: vanilla (applying the algorithm once on the entire forget set), shuffle (applying the algorithm sequentially on three randomly chosen subsets), and RUMF (applying the algorithm sequentially on three homogeneous subsets obtained by refinement using memorization scores). It further explores the effect of selecting different unlearning algorithms for each subset and evaluates the impact of different execution orders for the subsets.

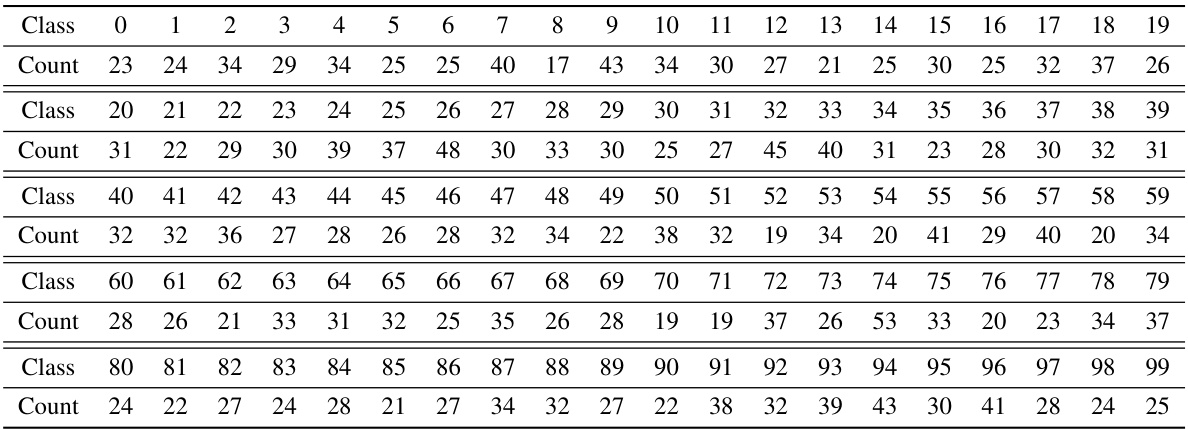
This table shows the distribution of classes within the forget sets used in the RUM (Refined-Unlearning Meta-algorithm) experiments for CIFAR-10 and CIFAR-100 datasets. A total of 3000 examples were selected for the forget set in each experiment, and this table details how many examples from each class were included in those 3000. This information is important for understanding how representative the forget sets are of the overall datasets and for interpreting the results of the RUM experiments, as the algorithms’ performance may vary depending on the composition of the forget set.
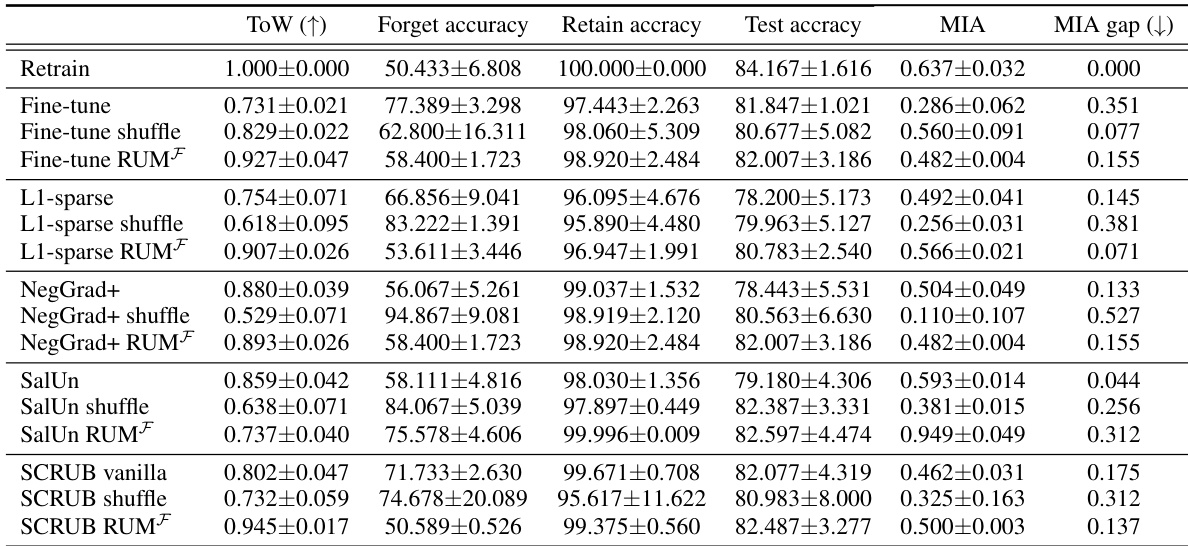
This table presents the performance of various unlearning algorithms on the CIFAR-10 dataset using ResNet-18, categorized by the entanglement score (ES) of the forget and retain sets. For each algorithm and ES level, the table provides the forget accuracy, retain accuracy, test accuracy, and membership inference attack (MIA) score. The results show how the performance of each algorithm changes depending on the level of entanglement between the forget and retain sets. Lower ES values indicate less entanglement and easier unlearning. The metrics reported are average values with 95% confidence intervals across multiple runs of each experiment.

This table presents the performance of various unlearning algorithms on the CIFAR-10 dataset using a ResNet-18 model. The performance is evaluated based on three metrics: forget accuracy, retain accuracy, and test accuracy. Additionally, the Membership Inference Attack (MIA) gap is provided to assess the ability of the model to prevent inference of membership from the forget set. The results are broken down for three levels of entanglement between the retain and forget sets (Low, Medium, High ES). This allows for a comparison of algorithm effectiveness at different levels of entanglement.

This table presents the results of the tug-of-war (ToW) metric for different unlearning algorithms across various datasets and model architectures. The ToW metric measures the balance between forgetting the forget set and retaining the ability to perform well on the retain set and generalize to a test set. The results are shown for three levels of entanglement (low, medium, high) of the forget and retain sets in embedding space. A high ToW score indicates better unlearning performance, so lower ToW values in this table show that unlearning is harder when the entanglement between sets is higher.
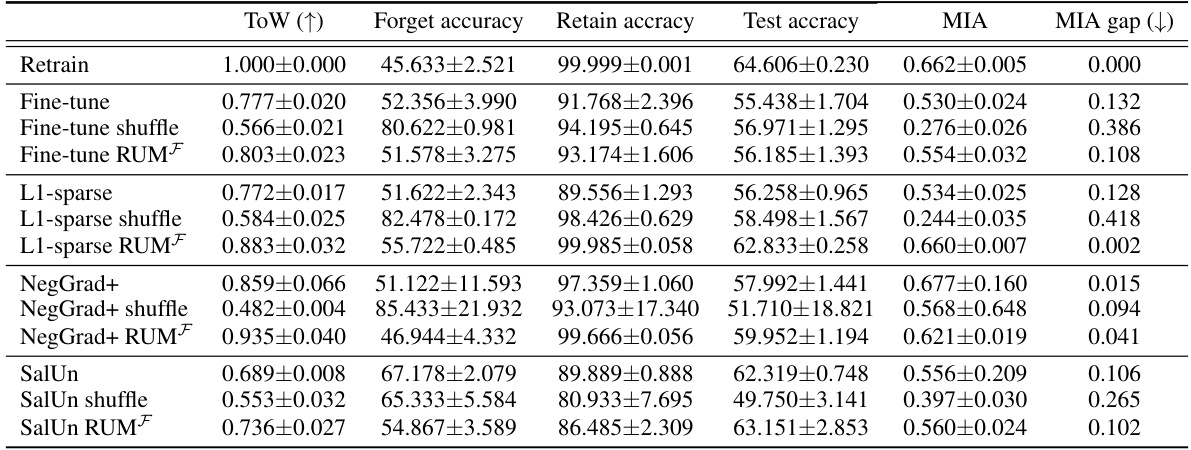
This table shows the performance of various unlearning algorithms on the CIFAR-10 dataset using a ResNet-18 model. The performance is measured using accuracy on the forget set, retain set, and test set, and also using a membership inference attack (MIA). The table is organized by different levels of entanglement (ES) between the retain and forget sets, demonstrating how the entanglement affects unlearning performance. The results highlight the trade-offs between forgetting quality and model utility, and show how different algorithms perform across various levels of entanglement.
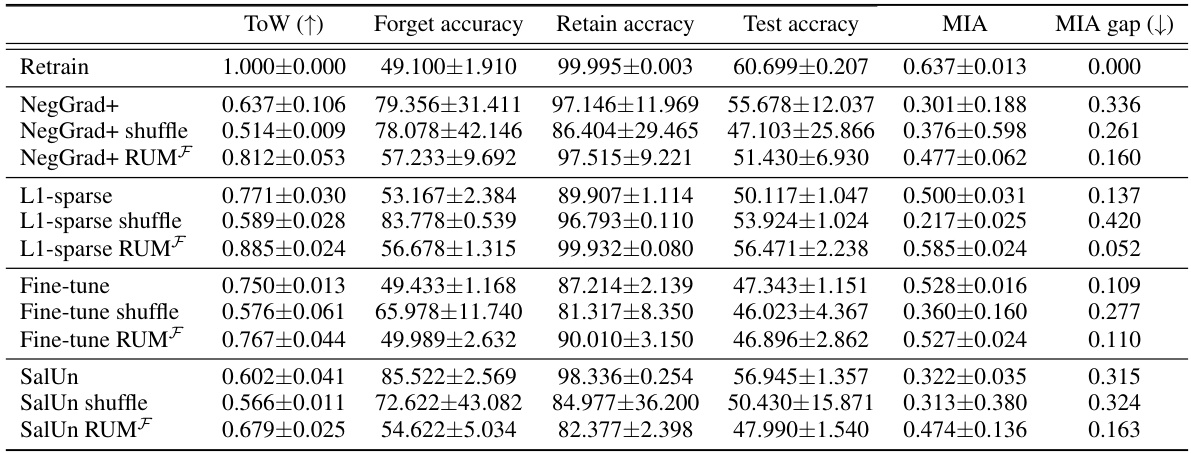
This table presents the performance of various unlearning algorithms on the CIFAR-10 dataset using a ResNet-18 model. The performance is measured using accuracy on the forget set, retain set, and test set, as well as the Membership Inference Attack (MIA) gap. The table is broken down by different levels of entanglement score (ES) between the forget and retain sets, showing how this factor affects the ability of different unlearning algorithms to remove the effect of the forget set while preserving the model’s performance on the retain and test sets. Higher accuracy on the retain and test set, and a lower MIA gap are considered better.
This table presents the results of applying various unlearning algorithms on the CIFAR-10 dataset using ResNet-18. It shows the performance across three different levels of entanglement score (ES) - low, medium, and high. The metrics reported include Forget Accuracy, Retain Accuracy, Test Accuracy, and Membership Inference Attack (MIA) scores. The MIA score indicates how well the unlearning algorithm protects user privacy by preventing an attacker from determining whether specific examples have been removed from the model’s training data. Each algorithm’s performance is compared against the baseline ‘Retrain’ scenario, which entails retraining the model from scratch without the forget set.
Full paper#