TL;DR#
Current vision-language-to-image (VL2I) models, especially diffusion models, can generate images with harmful content. This raises serious ethical and legal issues. Existing solutions, like dataset filtering or adversarial methods, have limitations in terms of effectiveness and scalability. There’s a need for a more precise and adaptable approach that can address the issues caused by the diffusion model itself, not just the input data.
This paper introduces Causal Representation Editing (CRE), a novel framework that tackles the problem. CRE works by identifying and editing specific parts of the model’s internal representation that are causally linked to unsafe concepts, at the right diffusion timestep. This method successfully removes unwanted content while maintaining image quality and scalability. Experiments show CRE outperforms other approaches in accuracy and efficiency, making it a promising solution for building safer and more responsible AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on safe AI and image generation. It directly addresses the critical problem of harmful content generation in diffusion models, a significant concern in the rapidly evolving field of AI. The proposed method, Causal Representation Editing (CRE), offers a novel and effective solution with broad implications for ethical AI development and deployment. CRE’s plug-and-play nature and scalability make it highly relevant to current research trends in safe AI, opening up new avenues for research on improving the safety and controllability of generative models.
Visual Insights#

🔼 This figure illustrates the Causal Representation Editing (CRE) framework. Users provide a prompt (text and/or image) which may include unsafe concepts. CRE operates in two phases: offline training of a discriminator to identify unsafe concepts and determination of causal periods for their removal; and online inference where, if unsafe concepts are detected, CRE edits the latent representation within the U-Net of a VL2I diffusion model during specific timesteps (causally linked to the unsafe concepts). This results in the generation of safe images while preserving other aspects of the original prompt.
read the caption
Figure 1: Method Overview of CRE. Users of VL2I models (U-Net) might input/query images containing unsafe concepts as reference images (objects or styles), here taking the 'Van Gogh' style as an example. CRE consists of two main phases. Phase 1 involves discriminator training and causal period search for each unsafe concept category, which can be performed offline (omitted from this figure, see section 3.3 for details). During inference (phase 2, i.e., the right side of this figure), if the reference image contains unsafe concepts, the editing function of CRE is applied within the U-Net layers. Otherwise, the generated content is faithful to the user-specified prompts without modification.

🔼 This table presents a quantitative comparison of the accuracy of safe object transfer using Kosmos-G and four different safe generation methods (Kosmos-G-Neg, SLD, ProtoRe, and CRE). The accuracy represents the percentage of times the target object (considered an unsafe concept) was successfully transferred to new images. Lower accuracy indicates better safety, as it means the unsafe concept was less frequently transferred. The table shows that CRE significantly outperforms the other methods in reducing the presence of unsafe objects.
read the caption
Table 1: Quantitative results of safe object transfer.
In-depth insights#
Causal Editing#
Causal editing, in the context of this research paper, presents a novel approach to safe concept transfer within multi-modal diffusion models. It leverages the inherent temporal dynamics of the diffusion process, identifying “causal periods” directly linked to the generation of unsafe concepts. This temporal precision allows for targeted intervention, modifying the latent representations only during the timesteps where unsafe content emerges, thereby minimizing unwanted alterations to the overall image generation. The method demonstrates superior effectiveness and precision compared to existing techniques by ensuring the removal of harmful elements without compromising the acceptable content. This causal approach offers enhanced efficiency and scalability, especially when dealing with complex scenarios, such as incomplete or obscured representations of unsafe concepts, promising a more robust and effective solution for safeguarding generative AI.
Safe Transfer#
The concept of “Safe Transfer” in the context of multi-modal diffusion models centers on the challenge of preventing the unintended or malicious propagation of harmful content. Existing methods, such as dataset filtering and adversarial training, often lack effectiveness or scalability. The core issue is the model’s ability to learn and generate unsafe concepts, even without explicit training examples. A novel approach, causal representation editing, directly addresses this issue by identifying and selectively removing harmful content within the model’s latent representation. This targeted approach enhances precision and efficiency, as it avoids interfering with safe elements and scales better than previous methods. The framework leverages a discriminator to detect unsafe concepts and strategically edits the diffusion process during timesteps directly linked to harmful features. The ability to manage complex scenarios, such as incomplete representations of unsafe concepts, further demonstrates the robustness and potential of causal representation editing for ensuring safe and responsible generative AI.
Multi-modal Focus#
A hypothetical research paper section on “Multi-modal Focus” would delve into the integration and synergistic interplay of different modalities, such as text, images, and audio, for improved model performance and understanding. It would likely explore how these modalities complement each other’s limitations, providing richer context and robustness than any single modality could offer alone. A key consideration would be the effective fusion of these diverse data streams, examining methods for aligning, weighting, and combining information from different sources to avoid redundancy and enhance accuracy. The discussion might also cover challenges related to data scarcity and bias across modalities, proposing strategies to address imbalanced datasets and mitigate potential inaccuracies stemming from these biases. Finally, the paper might analyze the ethical implications of multi-modal approaches, emphasizing the potential for misuse or bias amplification, and suggesting solutions to ensure responsible and equitable applications of the technology.
Method Limits#
A hypothetical ‘Method Limits’ section for a research paper on safe concept transfer in multi-modal diffusion models would likely discuss several key limitations. Scalability would be a major concern; while the proposed causal representation editing (CRE) method shows promise, its effectiveness might decrease as the number of unsafe concepts increases, potentially impacting the quality of generated images. The reliance on a pre-trained discriminator introduces another limitation; inaccurate or incomplete discriminator training could lead to misidentification of unsafe concepts. Computational overhead is another relevant consideration; although CRE is designed to efficiently focus on specific timesteps, it could still present an increased inference time compared to conventional models. Finally, the framework’s generalizability across different diffusion models should be thoroughly addressed, as its success hinges on effective manipulation of the underlying model’s latent representation; this may not universally transfer. Therefore, future research could focus on improving discriminator accuracy, exploring more efficient editing techniques, and rigorously assessing CRE’s performance in diverse multi-modal diffusion scenarios.
Future Works#
Future work in safe concept transfer within multi-modal diffusion models could explore several promising avenues. Improving the causal period identification process is crucial; more sophisticated methods, perhaps incorporating attention mechanism analysis or uncertainty estimation, could enhance accuracy and efficiency. Further research into more robust and generalizable editing functions is needed, moving beyond simple projection to incorporate more advanced techniques from representation learning. The current methodology relies on pre-trained discriminators; investigating alternative approaches for identifying and classifying unsafe concepts, such as using zero-shot classifiers or incorporating human-in-the-loop validation, warrants further investigation. Finally, a key area for future work lies in extending the framework to handle diverse modalities, beyond images and text, and in assessing the broader societal implications of such technology, ensuring responsible development and deployment.
More visual insights#
More on figures

🔼 This figure displays qualitative results of the proposed CRE method on the COCO-30k dataset. It shows a comparison between the results generated by Kosmos-G, CRE with a cassette player as a reference, and CRE with Mickey Mouse as a reference. The images demonstrate how the CRE method effectively removes or transfers the specified objects (cassette player or Mickey Mouse) from the input image while maintaining the overall quality and context of the generated images.
read the caption
Figure 2: Qualitative results on COCO-30k dataset.
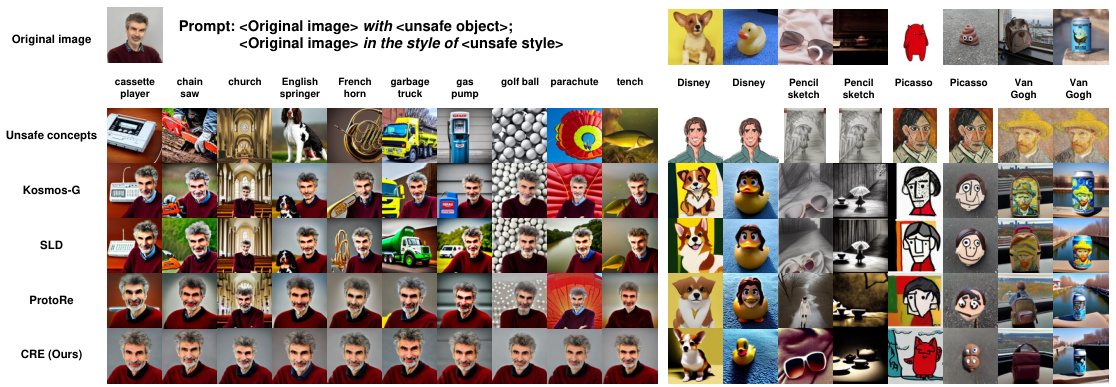
🔼 This figure shows a qualitative comparison of the results obtained using Kosmos-G, SLD, ProtoRe, and the proposed CRE method for both object and style transfer tasks. The left side demonstrates object removal from generated images, while the right side shows style transfer with the removal of an undesired style. The images illustrate the effectiveness of CRE in precisely removing unsafe concepts while preserving the overall quality and coherence of the generated images. Kosmos-G without any safety mechanism is provided as a baseline for comparison.
read the caption
Figure 3: Qualitative safe generation results on object transfer (left) and style transfer (right).

🔼 This figure shows a comparison of image generation results using different methods for safe object and style transfer. The ‘Original image’ row displays the input images. The ‘Unsafe concepts’ row shows examples of unsafe concepts such as specific objects or artistic styles. The ‘Kosmos-G’ row demonstrates the results of the Kosmos-G model without any safety mechanisms, showing the transfer of unsafe concepts. The subsequent rows (SLD, ProtoRe, and CRE) illustrate the results from different safe generation methods, highlighting their effectiveness in removing or mitigating the unsafe concepts while preserving the overall image quality. The left side focuses on object transfer, and the right side focuses on style transfer. The figure visually demonstrates the superior performance of the proposed CRE method in achieving safer image generation.
read the caption
Figure 3: Qualitative safe generation results on object transfer (left) and style transfer (right).

🔼 This figure demonstrates the effectiveness of the proposed Causal Representation Editing (CRE) method in handling complex scenarios and achieving precise mitigation of unsafe concepts. The left panel showcases CRE’s ability to remove unsafe concepts from images even when they are blurred, taken with mobile phones, cropped, overexposed, or oversaturated. The right panel highlights the precision of CRE by showing how it selectively removes specific unsafe styles (Van Gogh, hat) while preserving other aspects of the generated image.
read the caption
Figure 5: Safe generation under complex scenarios (left); with precise mitigation (right).

🔼 This figure illustrates the Causal Representation Editing (CRE) framework. It shows how CRE processes user inputs (including potentially unsafe content) during two phases. Phase 1 (offline) trains a discriminator to identify unsafe concepts and determines the causal period for their removal. Phase 2 (inference) applies representation editing within the U-Net layers of a Vision-Language-to-Image model only if unsafe concepts are detected, thus ensuring safe content generation.
read the caption
Figure 1: Method Overview of CRE. Users of VL2I models (U-Net) might input/query images containing unsafe concepts as reference images (objects or styles), here taking the 'Van Gogh' style as an example. CRE consists of two main phases. Phase 1 involves discriminator training and causal period search for each unsafe concept category, which can be performed offline (omitted from this figure, see section 3.3 for details). During inference (phase 2, i.e., the right side of this figure), if the reference image contains unsafe concepts, the editing function of CRE is applied within the U-Net layers. Otherwise, the generated content is faithful to the user-specified prompts without modification.

🔼 This figure shows examples of the final style dataset used to train the classifier for the style transfer task. The dataset is divided into three groups based on variance and bias: High Variance & High Bias, Medium Variance & Medium Bias, and Low Variance & Low Bias. Each group contains images representing the ‘Normal’ class and four unsafe styles (Disney, Pencil Sketch, Picasso, and Van Gogh). The High Variance & High Bias images are from Style Dataset 1, the Medium Variance & Medium Bias images are from Style Dataset 2, and the Low Variance & Low Bias images are from Style Dataset 3. The image shows a grid of images for each style and variance/bias combination.
read the caption
Figure 6: Examples of Style Dataset Final. This dataset is used for training the classifier. For “Disney”, “Pencil Sketch”, “Picasso”, and “Van Gogh”, High Variance & High Bias means the images are selected from Style Dataset 1, Medium Variance & Medium Bias means the images are selected from Style Dataset 2, Ligh Variance & Ligh Bias means the images are selected from Style Dataset 3.

🔼 This figure shows a qualitative comparison of object transfer results using Kosmos-G and Kosmos-G-Neg. Kosmos-G-Neg appends a negative prompt to the Kosmos-G prompt in an attempt to prevent the generation of unsafe concepts. The left column displays example images of the 10 object categories used as unsafe concepts. The middle and right columns display the results generated using Kosmos-G and Kosmos-G-Neg respectively. By visually inspecting the results, one can qualitatively assess the effectiveness of the negative prompt approach in mitigating the generation of unsafe concepts. This figure supports the paper’s claim that simply adding a negative prompt is not effective for preventing the transfer of harmful concepts.
read the caption
Figure 7: Object transfer with Kosmos-G and Kosmos-G-Neg.

🔼 This figure displays a comparison of style transfer results between Kosmos-G and Kosmos-G-Neg. Kosmos-G-Neg uses negative prompts to try to prevent the transfer of unsafe styles. Each row represents a different unsafe style (Disney, Pencil Sketch, Picasso, Van Gogh), and each column shows the style transfer results for Kosmos-G and Kosmos-G-Neg respectively, using the same base image each time. The results illustrate the differences in style transfer capability and safety between the two approaches.
read the caption
Figure 8: Style transfer with Kosmos-G and Kosmos-G-Neg.

🔼 This figure demonstrates the impact of using projection in representation editing. The left side shows object transfer, while the right shows style transfer. Each side compares results with and without projection. The results show that projection significantly improves image quality while maintaining the integrity of safe elements like backgrounds, striking a balance between creative generation and safety.
read the caption
Figure 9: Ablation study on representation editing with projection. Projection significantly enhances the quality of image generation while preserving safe concepts such as backgrounds, resulting in more coherent and contextually accurate visuals. Our approach not only improves the overall fidelity of the generated images but also ensures that the integrity of essential components, such as backgrounds and other safe concepts, is maintained. This method effectively balances creative generation and safety compliance, ensuring that the generated content adheres to desired safety standards without compromising visual quality.

🔼 This figure compares the attention maps of Kosmos-G and CRE during the diffusion process. The comparison highlights that while initially similar, the attention maps diverge quickly, demonstrating CRE’s ability to remove unsafe concepts early in the generation process.
read the caption
Figure 10: Attention map comparison between the process of normal Kosmos-G and CRE. Take safe object transfer as an example, the image shows one of the attention maps in the whole process of normal Kosmos-G and CRE. We can find that at the very beginning (i.e., the image with index 00, which represents t=T), the attention maps in the two processes are somewhat similar to a certain extent. But just after a few timesteps, the attention maps are quite different. It shows that earlier diffusion steps have a big difference in object generation, and CRE can certainly remove the unsafe concept in the attention step, which is after the forward step of the attention map.

🔼 This figure illustrates the overall framework of Causal Representation Editing (CRE). It shows how CRE intervenes in the process of vision-language-to-image (VL2I) generation using a U-Net model to remove unsafe concepts from the generated images. The figure is divided into two phases. Phase 1 includes discriminator training and causal period search for unsafe concepts, which can be done offline. Phase 2 shows how CRE works during inference time by applying the editing function to remove unsafe concepts from the latent representations within the U-Net layers, ensuring the generated images are safe while maintaining fidelity to user prompts.
read the caption
Figure 1: Method Overview of CRE. Users of VL2I models (U-Net) might input/query images containing unsafe concepts as reference images (objects or styles), here taking the 'Van Gogh' style as an example. CRE consists of two main phases. Phase 1 involves discriminator training and causal period search for each unsafe concept category, which can be performed offline (omitted from this figure, see section 3.3 for details). During inference (phase 2, i.e., the right side of this figure), if the reference image contains unsafe concepts, the editing function of CRE is applied within the U-Net layers. Otherwise, the generated content is faithful to the user-specified prompts without modification.

🔼 This figure illustrates the Causal Representation Editing (CRE) framework proposed in the paper. It shows how CRE works in two phases: an offline phase for discriminator training and causal period search, and an online inference phase where the model identifies and removes unsafe concepts from the generated images by editing the latent representations within the U-Net layers. The example uses Van Gogh’s style as a reference to highlight the process of identifying and removing unsafe concepts.
read the caption
Figure 1: Method Overview of CRE. Users of VL2I models (U-Net) might input/query images containing unsafe concepts as reference images (objects or styles), here taking the “Van Gogh” style as an example. CRE consists of two main phases. Phase 1 involves discriminator training and causal period search for each unsafe concept category, which can be performed offline (omitted from this figure, see section 3.3 for details). During inference (phase 2, i.e., the right side of this figure), if the reference image contains unsafe concepts, the editing function of CRE is applied within the U-Net layers. Otherwise, the generated content is faithful to the user-specified prompts without modification.

🔼 This figure presents a qualitative comparison of image generation results using Kosmos-G with and without Causal Representation Editing (CRE), focusing on the impact of selecting different timesteps for applying the CRE method. The top row shows the prompt and the timestep range used for CRE. The subsequent rows show the generated images from Kosmos-G without CRE, Kosmos-G with CRE applied to the specified timesteps, and Kosmos-G with CRE applied to a different timestep range. Each column represents a different prompt, allowing for observing the effect of different timestep ranges across various prompts. It helps to illustrate how the choice of timesteps influences the effectiveness of CRE in removing unsafe concepts while preserving the overall image quality.
read the caption
Figure 13: Qualitative results on timestep selection.

🔼 This figure illustrates the Causal Representation Editing (CRE) framework proposed in the paper. It shows how CRE intervenes in the image generation process of vision-language-to-image (VL2I) diffusion models to remove unsafe concepts from the generated images while preserving the quality of the acceptable content. The framework involves two phases: an offline phase (discriminator training and causal period search) and an online phase (inference-time intervention). The figure highlights the process of the online phase, showing how the editing function of CRE modifies the latent representation within the U-Net layers to remove unsafe concepts from the generated images.
read the caption
Figure 1: Method Overview of CRE. Users of VL2I models (U-Net) might input/query images containing unsafe concepts as reference images (objects or styles), here taking the “Van Gogh” style as an example. CRE consists of two main phases. Phase 1 involves discriminator training and causal period search for each unsafe concept category, which can be performed offline (omitted from this figure, see section 3.3 for details). During inference (phase 2, i.e., the right side of this figure), if the reference image contains unsafe concepts, the editing function of CRE is applied within the U-Net layers. Otherwise, the generated content is faithful to the user-specified prompts without modification.
More on tables
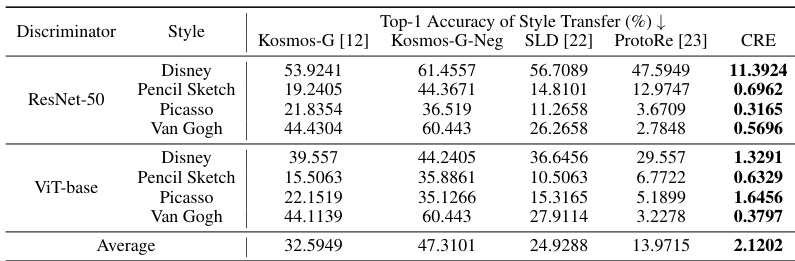
🔼 This table presents a quantitative comparison of the accuracy of safe style transfer using different methods. Four styles (Disney, Pencil Sketch, Picasso, and Van Gogh) were used as unsafe concepts, and the accuracy is measured using two different classifiers (ResNet-50 and ViT-base). The table compares the performance of Kosmos-G, Kosmos-G-Neg (Kosmos-G with negative prompts), SLD, ProtoRe, and the proposed CRE method. Lower accuracy values indicate better performance in preventing unsafe style transfer.
read the caption
Table 2: Quantitative results of safe style transfer.

🔼 This table presents a quantitative comparison of the accuracy of safe style transfer using Kosmos-G and four other methods (Kosmos-G-Neg, SLD, ProtoRe, and CRE). Four styles (Disney, Pencil Sketch, Picasso, and Van Gogh) were used as unsafe concepts. Two different classifiers (ResNet-50 and ViT-base) were used to evaluate the performance of each method. The table shows the top-1 accuracy of style transfer for each style and classifier, broken down by method. Lower accuracy indicates better safety in style transfer, meaning the unwanted style is less likely to be transferred. The Δ column shows the change in accuracy between the single unsafe concept and multiple unsafe concept scenarios.
read the caption
Table 2: Quantitative results of safe style transfer.

🔼 This table presents a quantitative comparison of the average performance of three different methods (SLD, ProtoRe, and CRE) in addressing seven categories of unsafe content within the I2P dataset. Each cell represents the average rate of unsafe content generation for each method across multiple trials and for each I2P category. Lower values indicate better performance in mitigating the generation of unsafe content.
read the caption
Table 4: Quantitative results of I2P.

🔼 This table presents a quantitative comparison of the accuracy of safe object transfer using Kosmos-G and four different safe generation methods (Kosmos-G-Neg, SLD, ProtoRe, and CRE). The accuracy represents the percentage of times the unsafe object was successfully removed from the generated images. Lower accuracy indicates better safety, meaning that the unsafe concept was less frequently present in the generated output. The results are averaged across ten different ImageNet object categories used as unsafe concepts.
read the caption
Table 1: Quantitative results of safe object transfer.

🔼 This table presents a quantitative comparison of the accuracy of safe object transfer using Kosmos-G and four other methods (Kosmos-G-Neg, SLD, ProtoRe, and CRE). The accuracy is measured as the percentage of times the unsafe object is successfully removed. Lower percentages indicate better performance in removing unsafe objects. Ten object categories were used as unsafe concepts, and the results are shown per category and as an average across all categories.
read the caption
Table 1: Quantitative results of safe object transfer.

🔼 This table presents a quantitative comparison of the accuracy of safe object transfer using Kosmos-G and four different safe generation methods (Kosmos-G-Neg, SLD, ProtoRe, and CRE). The accuracy is measured as the percentage of times the unsafe object (from a set of ten ImageNet classes) appeared in the images generated by each method. Lower accuracy indicates better safety, meaning the unsafe object was less frequently present in the generated images. The results show that CRE outperforms existing methods in reducing the appearance of the unsafe objects.
read the caption
Table 1: Quantitative results of safe object transfer.
Full paper#



















