↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Creating lifelike digital clothing remains challenging due to limitations in 3D modeling and rendering. Current methods struggle with generating realistic textures and often lack controllability. This leads to a significant gap between rendered images and real-world photos, hindering the use of digital assets in e-commerce.
FashionR2R tackles this issue by introducing a novel framework using diffusion models. This method involves two key stages: 1) injecting domain knowledge into a pre-trained model; 2) generating realistic images using a texture-preserving attention mechanism. The framework’s effectiveness is demonstrated through experiments using both existing and a newly created (SynFashion) dataset, showcasing significant improvements in realism and texture preservation compared to existing techniques. The paper thus offers a promising approach to bridge the gap between digital and real-world fashion imagery.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel framework for high-quality rendered-to-real fashion image translation using diffusion models. This addresses a significant challenge in e-commerce and virtual fashion, where realistic rendering of clothing remains difficult. The proposed method, with its two-stage process (domain knowledge injection and realistic image generation), and the introduction of the SynFashion dataset are valuable contributions. It opens avenues for research in improving the realism of rendered images, generating diverse clothing textures, and exploring the potential of diffusion models for more realistic image synthesis.
Visual Insights#
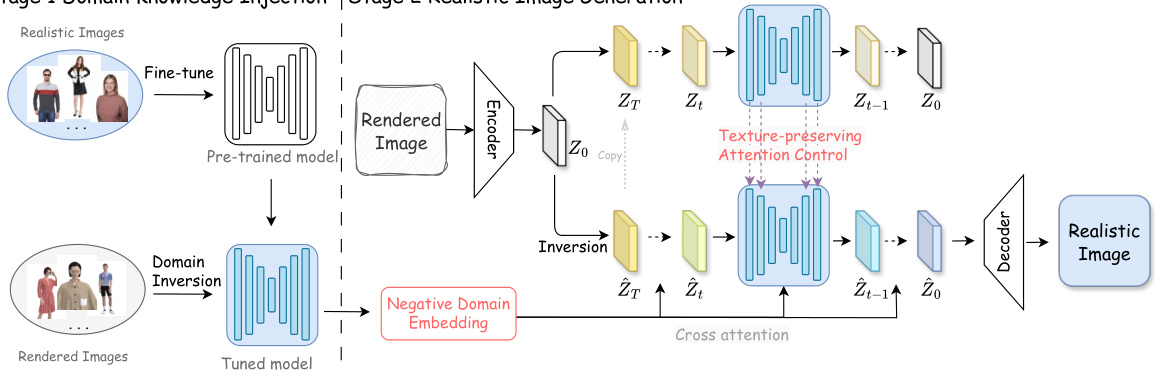
This figure illustrates the two-stage framework for rendered-to-real fashion image translation. Stage 1, Domain Knowledge Injection (DKI), involves fine-tuning a pre-trained text-to-image diffusion model on real fashion photos and then using a negative domain embedding to guide the model away from the characteristics of rendered images. Stage 2, Realistic Image Generation (RIG), employs DDIM inversion to convert the rendered image into latent space, and uses the negative domain embedding and a texture-preserving attention control mechanism to generate a realistic counterpart while maintaining fine-grained clothing textures.
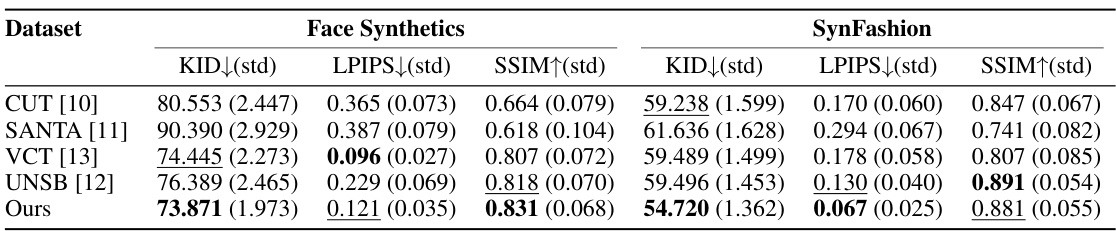
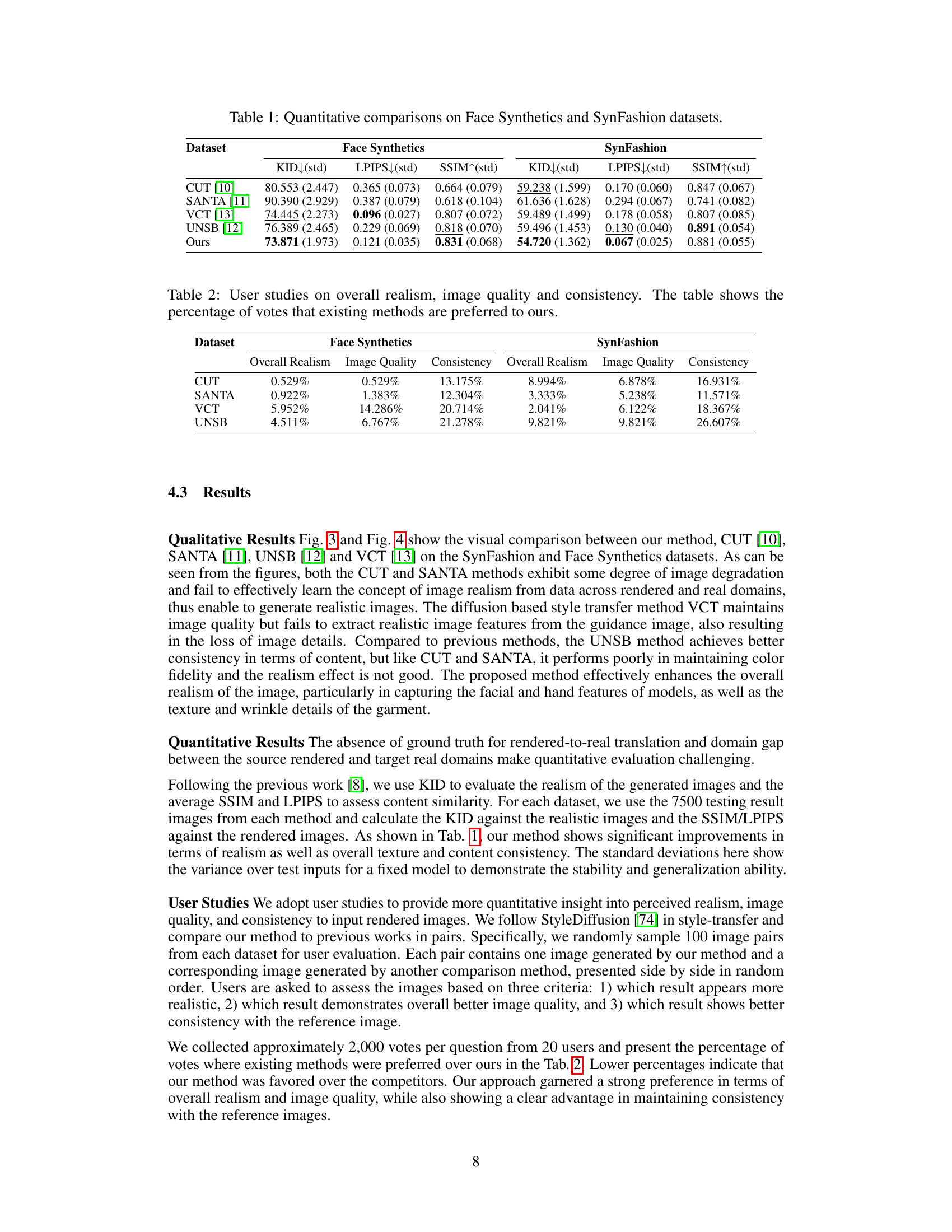
This table presents a quantitative comparison of different image-to-image translation methods on two datasets: Face Synthetics and SynFashion. The metrics used for comparison are: KID (Kernel Inception Distance), LPIPS (Learned Perceptual Image Patch Similarity), and SSIM (Structural Similarity Index). Lower KID values indicate better realism, lower LPIPS values indicate higher perceptual similarity to the ground truth, and higher SSIM values indicate better structural similarity. The table allows for a comparison of the performance of various methods in terms of realism, image quality, and texture preservation.
In-depth insights#
Diffusion Model Power#
Diffusion models demonstrate remarkable generative power in image synthesis, enabling the creation of high-quality, realistic images. Their strength lies in the ability to iteratively refine noisy data, gradually recovering intricate details and textures. This process is particularly effective for tasks like rendered-to-real image translation where the goal is to enhance the photorealism of synthetically generated images. Controllability remains a challenge, though techniques like classifier-free guidance and textual inversion offer improved control over the generation process. By leveraging pretrained models and incorporating domain-specific knowledge, photorealism can be significantly improved, while preserving fine-grained details like clothing textures. This approach leverages the strengths of diffusion models while mitigating their limitations, paving the way for realistic image generation in various applications.
DKI & RIG Stages#
The paper introduces a novel framework for rendered-to-real image translation using diffusion models, which consists of two key stages: Domain Knowledge Injection (DKI) and Realistic Image Generation (RIG). DKI focuses on adapting a pre-trained text-to-image diffusion model to the specific domain of fashion images. This is achieved through fine-tuning on real fashion photos and embedding negative (rendered) examples to guide the model away from the artifacts of rendered images, effectively bridging the gap between the source and target domains. The RIG stage leverages the refined diffusion model to generate realistic images from rendered inputs, utilizing a texture-preserving mechanism to maintain fine-grained details crucial for fashion imagery. The incorporation of both positive (real) and negative (rendered) domain knowledge during DKI is a key innovation, enhancing the model’s ability to synthesize highly realistic images. The thoughtful design of RIG ensures that the process is not only realistic but also preserves the key characteristics that define the fashion images.
TAC Texture Control#
The paper introduces a novel texture-preserving attention control mechanism, termed TAC, to enhance the realism of generated images while maintaining fine-grained details. TAC leverages the attention maps within the UNet architecture of a diffusion model. By selectively injecting query and key from the rendered image inversion and generation pipeline into the rendered-to-real generation process, TAC successfully preserves intricate clothing textures. This method is particularly effective in handling fine-grained details that are often lost in other image-to-image translation approaches. The use of attention maps, specifically in the shallow UNet layers, proves crucial in decoupling texture information from broader semantic features. This careful control is key to preventing the loss of texture details which frequently occurs in other image translation methods. The effectiveness of TAC is empirically demonstrated through comparisons with other state-of-the-art methods, highlighting its superiority in preserving high-quality textures during the image translation process.
SynFashion Dataset#
The creation of the SynFashion dataset represents a significant contribution to the field of fashion image research. Its high-quality images, featuring diverse textures and garment categories, address a crucial gap in existing resources. The use of professional design software (Style3D Studio) ensures a level of realism and detail not readily available in publicly accessible datasets. This commitment to quality is vital as it directly impacts the reliability and generalizability of research findings. The dataset’s detailed annotations and metadata provide researchers with structured information, facilitating precise analysis and training of models. While the current size might be considered modest, its carefully curated nature makes it a valuable tool, especially for fine-grained analysis of clothing textures and styles. The public availability of this dataset, once released, will foster collaboration and accelerate progress in computer vision applications, particularly those focused on fashion and virtual try-on technologies.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the efficiency of the current model is crucial, potentially through exploring more efficient diffusion model architectures or optimizing the inversion process. Expanding the dataset to include a wider variety of clothing styles, poses, and lighting conditions would significantly enhance the model’s generalizability. Furthermore, investigating the potential for incorporating additional modalities, such as 3D garment information, into the process could lead to even more realistic image translations. A key area of investigation could be the development of techniques for fine-grained control over the generated images, allowing users to selectively adjust specific aspects of clothing textures and appearances. Finally, exploring applications beyond fashion, such as creating realistic renderings in other domains like movie production or virtual try-on tools, offers exciting potential.
More visual insights#
More on figures

This figure illustrates the Texture-preserving Attention Control (TAC) mechanism. It shows how queries (Q), keys (K), and values (V) from both the rendered image (cg) and the generated image (r) are used in the self-attention process. Specifically, the self-attention features from the rendered image are injected into the shallow layers of the UNet, decoupling texture details from general characteristics to preserve fine-grained textures during image generation. The process involves projection, softmax calculation, and the use of queries and keys from both the rendered and real domains to guide attention.

This figure compares the results of different image translation methods on the SynFashion dataset. The dataset consists of high-quality rendered fashion images, which the authors created. The ‘Source Image’ column shows the original rendered image. The other columns display the results produced by CUT, SANTA, VCT, UNSB, and the authors’ proposed method. The figure highlights the ability of the authors’ method to generate more realistic and detailed images compared to the other approaches, particularly regarding fine-grained clothing textures.

This figure shows a comparison of image translation results on the SynFashion dataset between the proposed method and four existing methods: CUT, SANTA, VCT, and UNSB. Each row represents a different input rendered image, and each column shows the result of a different method. The proposed method’s outputs generally exhibit higher realism and better preservation of fine-grained textures in the clothing compared to the other methods.

This figure shows the ablation study of the proposed method by removing one component at a time. The top row shows the results on images with a person wearing a headscarf, and the bottom row shows the results on images with a person wearing a dress. The first column shows the source image, the second column shows the result without source domain knowledge injection, the third column shows the result without target domain knowledge injection, the fourth column shows the result without texture-preserving attention control, and the fifth column shows the result with all components.

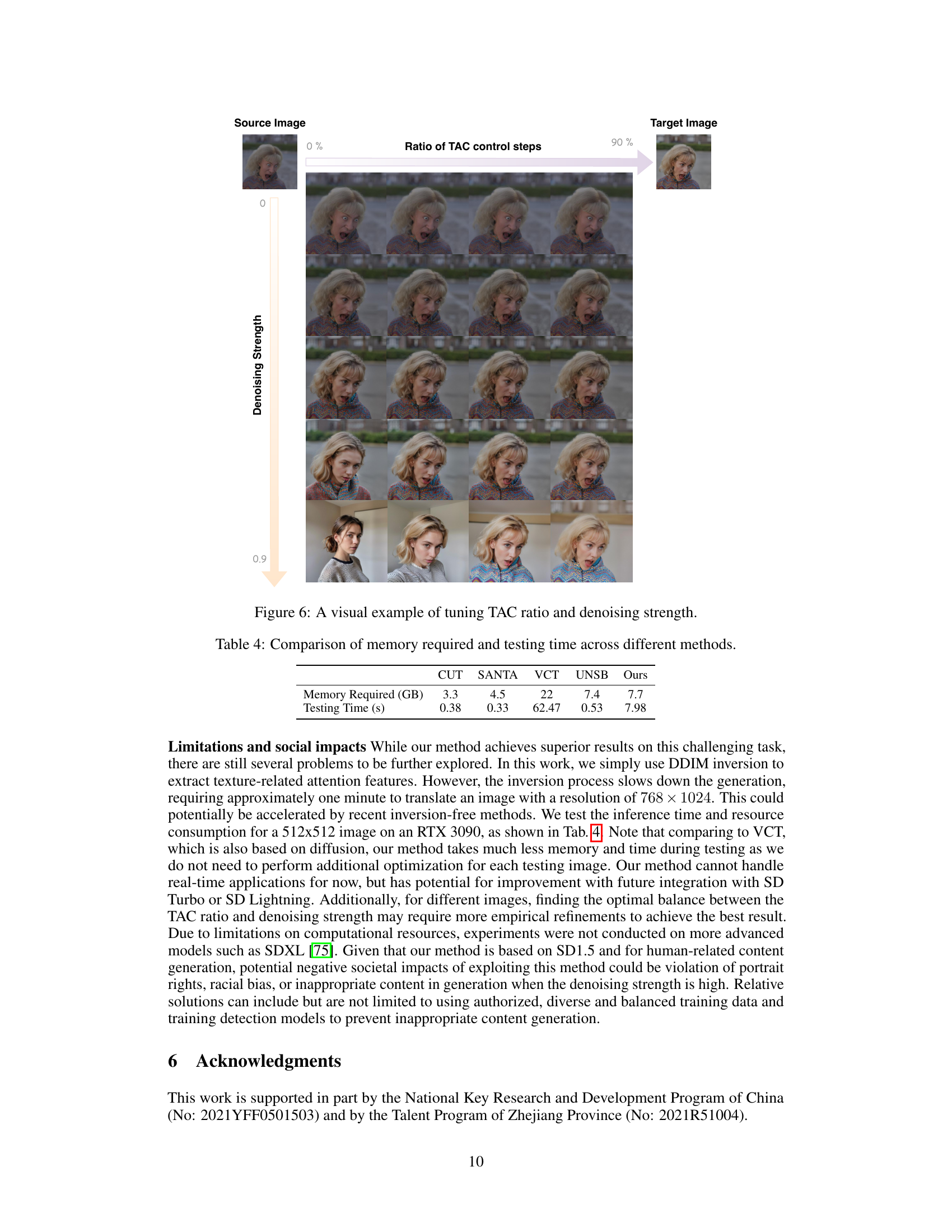
This figure shows the impact of the TAC ratio and denoising strength on the generated images. Different rows represent various denoising strengths, ranging from 0 to 0.9. Each row shows a series of images, with each column representing increasing TAC control steps (0% to 90%). As the denoising strength increases, the images become more realistic, but finer details might be lost. At the same time, increasing the TAC ratio (more self-attention control) better preserves details. The figure demonstrates the trade-off between realism and texture detail preservation by adjusting these two parameters.

This figure shows the results of applying the proposed method to images with different textures and rendering methods (rasterization vs. ray tracing). It demonstrates the method’s ability to generate realistic images regardless of the input’s rendering technique and texture complexity. The results highlight the method’s robustness and effectiveness in preserving fine-grained clothing textures, achieving a high level of realism in the generated images.

This figure presents a comparison of image translation results on the Face Synthetics dataset using different methods. The methods compared are CUT, SANTA, VCT, UNSB, and the proposed method. Each row represents a different input rendered image, with the leftmost column showing the source image and subsequent columns showing the results from each method. The figure highlights the differences in realism and detail preservation achieved by each technique. The caption advises zooming in to see details clearly.

This figure compares the results of five different methods (CUT, SANTA, VCT, UNSB, and the proposed method) on the SynFashion dataset. Each row shows the results for a different input rendered image. The ‘Source Image’ column shows the original rendered image. The subsequent columns display the results generated by each method. The figure visually demonstrates the superiority of the proposed method in generating realistic images compared to existing state-of-the-art approaches, especially in terms of preserving fine-grained clothing textures and enhancing overall realism.

This figure shows examples of the SynFashion dataset, a high-quality rendered fashion image dataset created using Style3D Studio. It presents various clothing items (pants, t-shirts, lingerie, skirts, hoodies) rendered with different textures and poses. The images demonstrate the diversity and high quality of the dataset used to train and evaluate the proposed rendered-to-real image translation method.

The figure shows the overall pipeline of the proposed method for rendered-to-real fashion image translation. It consists of two stages: Domain Knowledge Injection (DKI) and Realistic Image Generation (RIG). In DKI, a pre-trained Text-to-Image (T2I) diffusion model is fine-tuned on real fashion photos and then uses a negative domain embedding to guide image generation towards realistic counterparts. In RIG, a rendered image is inverted into a latent noise map, and a Texture-preserving Attention Control (TAC) mechanism is used to generate a realistic image while preserving fine-grained textures. The TAC leverages the attention maps in shallow layers of the UNet to improve texture consistency.

This figure shows examples from part 3 of the collected SynFashion dataset. The dataset contains various types of clothing items rendered in different textures and colors. Each row represents a different clothing category (Hanfu, Jeans, Shorts, Down Jacket, Vest and Camisole), with multiple images showing different textures for each category. The images are presented in four different views of each garment (front, back and two other random views).

The figure illustrates the overall pipeline of the proposed method for rendered-to-real fashion image translation. It consists of two main stages: Domain Knowledge Injection (DKI) and Realistic Image Generation (RIG). In the DKI stage, a pre-trained Text-to-Image (T2I) diffusion model is fine-tuned on real fashion photos and then uses negative domain embedding to inject knowledge. The RIG stage uses a texture-preserving attention control mechanism to generate realistic images from rendered images. The pipeline shows the flow of data from rendered images through the two stages, to the final realistic output.
More on tables

This table presents the results of a user study comparing the proposed method to existing methods in terms of overall realism, image quality and consistency. For each criterion, the percentage of participants who preferred the existing methods over the proposed method is shown. Lower percentages indicate that the proposed method is preferred. The study was conducted on two datasets, Face Synthetics and SynFashion, using 100 image pairs per dataset and about 2000 votes in total.

This table presents the quantitative results of an ablation study performed on the Face Synthetics and SynFashion datasets. The study investigates the impact of removing one component at a time from the proposed method: source domain knowledge injection (DKI), target domain knowledge injection (DKI), and texture-preserving attention control (TAC). The results are measured using KID (Kernel Inception Distance), LPIPS (Learned Perceptual Image Patch Similarity), and SSIM (Structural Similarity Index). Lower KID values indicate better realism, lower LPIPS values indicate higher perceptual similarity to real images, and higher SSIM values indicate better structural similarity. The table allows one to assess the contribution of each component to the overall performance of the method.

This table compares the memory required (in GB) and testing time (in seconds) for five different methods: CUT, SANTA, VCT, UNSB, and the authors’ proposed method. The comparison highlights the computational efficiency of different approaches for rendered-to-real image translation. Note that the testing time for VCT is significantly longer than the others.

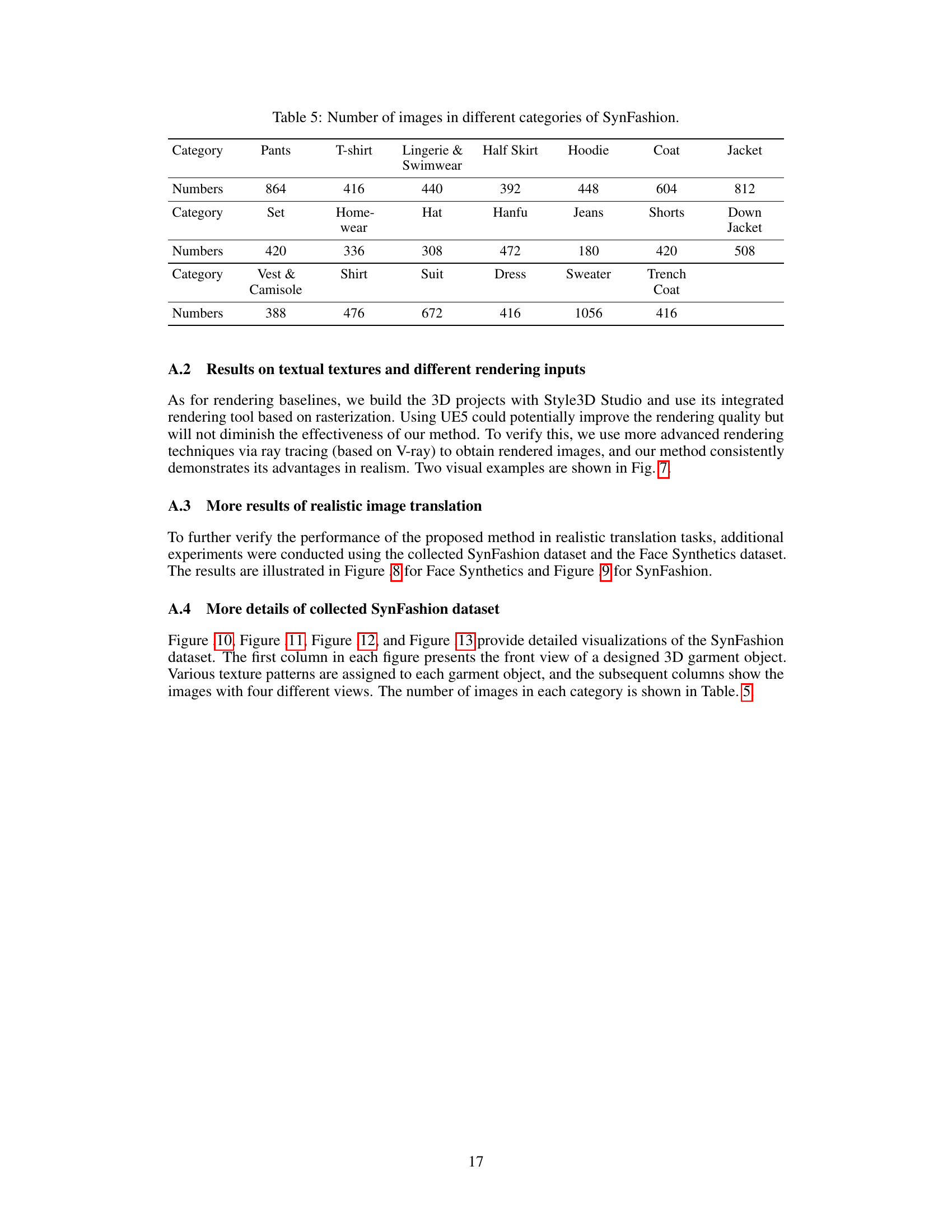
This table shows the number of images available in the SynFashion dataset for each of the 20 clothing categories. The categories are broken down into three rows for better readability.
Full paper#