↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) are memory-intensive, making deployment challenging. Quantization, reducing parameter precision, offers a solution but may significantly reduce accuracy. Existing research has shown surprising robustness to quantization, which is not fully understood. The paper investigates this robustness by exploring parameter heterogeneity - the uneven impact of different parameters on performance. Some parameters (“cherry” parameters) significantly impact accuracy, while most have minimal effect.
To address this, the authors introduce CherryQ, a new mixed-precision quantization method. CherryQ cleverly identifies and maintains the high precision of “cherry” parameters while aggressively quantizing others. Experiments demonstrate CherryQ’s superior performance on various LLMs and benchmarks, achieving surprisingly good results even with 3-bit quantization. This provides insights into why quantization works better than expected and suggests a new direction for improving efficiency and reducing computational costs of LLM deployment.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals the parameter heterogeneity in LLMs, explaining their robustness to quantization and paving the way for more efficient mixed-precision quantization methods. This significantly impacts LLM deployment by reducing memory needs and improving inference speed, opening avenues for research in efficient LLM optimization and deployment strategies.
Visual Insights#
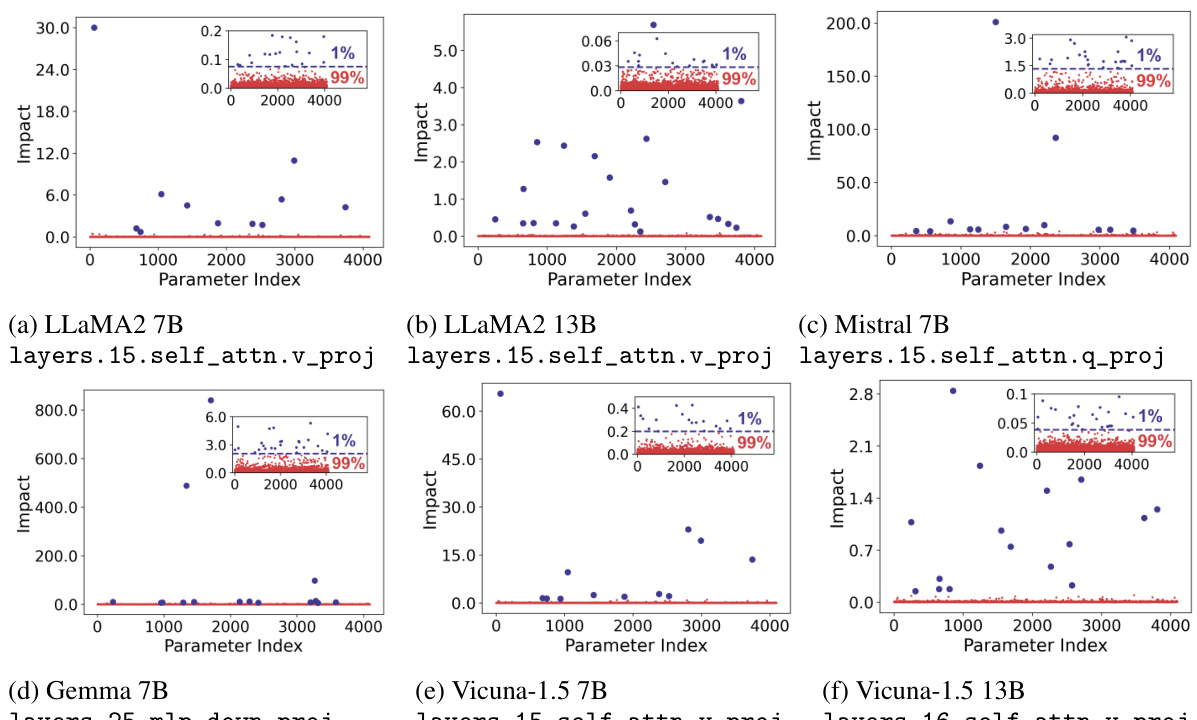
This figure shows scatter plots visualizing the impact of individual parameter perturbations on model loss for six different large language models (LLMs). Each plot represents a specific LLM and layer, showcasing the distribution of parameter impacts. The insets zoom in on the y-axis to highlight the small subset of ‘cherry’ parameters with disproportionately large impacts. The figure demonstrates the prevalence of parameter heterogeneity across various LLMs, scales, families, and model types.

This table shows the overlap of cherry parameters (the top 1/256 most impactful parameters) across different datasets and models. The ‘Within dataset’ row indicates the overlap when selecting cherry parameters from multiple random subsets within the same dataset. The ‘Across datasets’ row shows the overlap of cherry parameters identified from different datasets (C4, WikiText-2, ShareGPT). This demonstrates the consistency and data-independence of cherry parameters across different model families and data sources.
In-depth insights#
Parameter Heterogeneity#
The concept of ‘Parameter Heterogeneity’ in large language models (LLMs) reveals a crucial insight into their behavior and robustness. The core idea is that not all parameters contribute equally to model performance; a small subset, termed “cherry” parameters, exhibit a disproportionately large influence, while the vast majority have minimal impact. This uneven distribution of influence has significant implications for model compression techniques like quantization. Understanding this heterogeneity allows for the development of more efficient quantization methods, such as CherryQ, which strategically preserves high-precision for critical parameters, enabling aggressive quantization of less important ones. This approach leverages the inherent robustness of LLMs to quantization errors, significantly improving efficiency without compromising accuracy. The identification and utilization of this parameter heterogeneity are key advancements in optimizing LLM deployment.
CherryQ Quantization#
CherryQ is a novel quantization method designed for large language models (LLMs) that leverages the concept of parameter heterogeneity. It addresses the challenge of quantization errors by identifying and preserving a small subset of crucial parameters—the “cherry” parameters—in high precision while aggressively quantizing the remaining parameters to lower precision. This mixed-precision approach is shown to be highly effective, significantly outperforming existing methods in various experiments. The method is data-independent, meaning it can be applied consistently across different datasets. CherryQ’s success stems from its ability to address the disproportionate impact of a small number of highly influential parameters on model performance, highlighting a crucial insight into the architecture of LLMs.
Impact Metric Analysis#
An impact metric analysis in a research paper investigating parameter heterogeneity in large language models (LLMs) would critically assess how different methods of quantifying parameter influence affect the identification of ‘cherry’ parameters. The choice of metric significantly impacts the results, as highlighted by comparing impact, weight, and activation-based approaches. A superior metric would demonstrate a clear distinction between ‘cherry’ parameters (with high influence) and normal parameters, leading to more effective mixed-precision quantization strategies. Robustness of the metric across various LLMs and datasets is essential. A deep dive into the mathematical foundation of the chosen metric, its computational efficiency, and the reasons behind its superior discriminative power would be integral. Ultimately, the analysis should justify the selection of a specific metric for optimizing the quantization process, with strong evidence of its effectiveness in improving model performance while reducing resource consumption.
Mixed-Precision Optim.#
Mixed-precision optimization in deep learning models, particularly large language models (LLMs), is a crucial technique to improve training efficiency and reduce memory footprint. The core idea is to utilize different numerical precisions (e.g., FP16, BF16, INT8) for various model parameters or activations during training. Parameters identified as critical (‘cherry’ parameters) to model performance are often kept at higher precision, while less influential ones are quantized to lower precision. This approach balances accuracy and computational cost, enabling the training of larger and more complex models than what would be feasible with uniform high-precision arithmetic. Effective mixed-precision strategies require careful parameter selection. Methods for identifying ‘cherry’ parameters include analyzing gradients, Hessian matrices, or the impact of parameter perturbation on the model’s loss function. The optimal approach depends on the specific model architecture and training data. Further research should investigate adaptive mixed-precision methods that dynamically adjust precision during training based on the model’s learning progress and the importance of different parameters, optimizing for performance and efficiency.
LLM Quantization Limits#
LLM quantization, aiming to reduce model size and computational cost, faces inherent limitations. The primary challenge lies in balancing accuracy with reduced precision. While LLMs exhibit surprising robustness to quantization noise, a small subset of critical parameters (‘cherry’ parameters) disproportionately impacts performance if aggressively quantized. Existing mixed-precision methods attempt to mitigate this by preserving high-precision for these key parameters, but efficient and effective identification of these ‘cherry’ parameters remains a significant hurdle. Further research is needed to explore more sophisticated methods for parameter selection and to investigate the underlying reasons for the observed parameter heterogeneity. This includes understanding the interaction between quantization and the LLM’s architecture and training dynamics. Successfully navigating these limitations is crucial for enabling the widespread deployment of efficient and performant LLMs on resource-constrained devices.
More visual insights#
More on figures

This figure displays the heterogeneity scores for different metrics (impact, weight, activation) across various LLMs (LLaMA-2 7B, LLaMA-2 13B, Mistral 7B, Gemma 7B, Vicuna-1.5 7B, Vicuna-1.5 13B). Each sub-figure shows a scatter plot where the x-axis represents the index of the parameter matrix, and the y-axis represents the heterogeneity score for each metric. The impact-based metric consistently shows higher heterogeneity scores compared to weights and activations, indicating its effectiveness in distinguishing between normal and cherry parameters. The higher heterogeneity scores suggest a more significant disparity in parameter importance, with a small subset of parameters exhibiting significantly higher impacts than the majority.

This figure shows scatter plots visualizing the impact of individual parameter perturbations on model loss across six different large language models (LLMs). Each plot displays the impact for a subset of 4096 randomly selected parameters from a layer of each model. The plots highlight the parameter heterogeneity, showing that a small percentage of parameters (the ‘cherry’ parameters) have a disproportionately large effect on the loss compared to the vast majority of parameters. This heterogeneity is consistent across different model sizes, families, and types (base vs. chat models).
More on tables

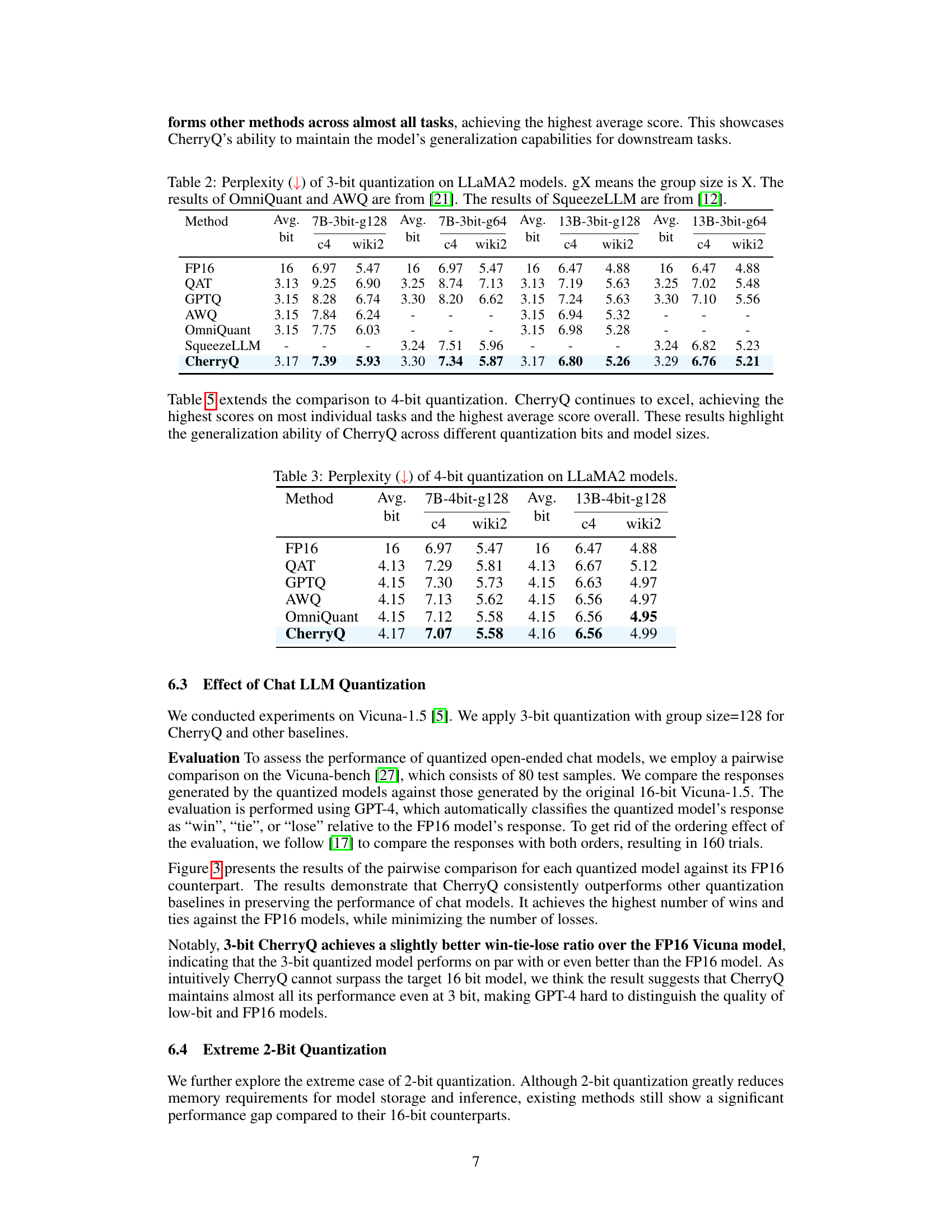
This table presents the perplexity results of different 3-bit quantization methods on LLaMA2 models with varying group sizes (g64 and g128). It compares the performance of CherryQ against several baselines including QAT, GPTQ, AWQ, OmniQuant, and SqueezeLLM, using the C4 and WikiText-2 datasets. Lower perplexity scores indicate better performance.
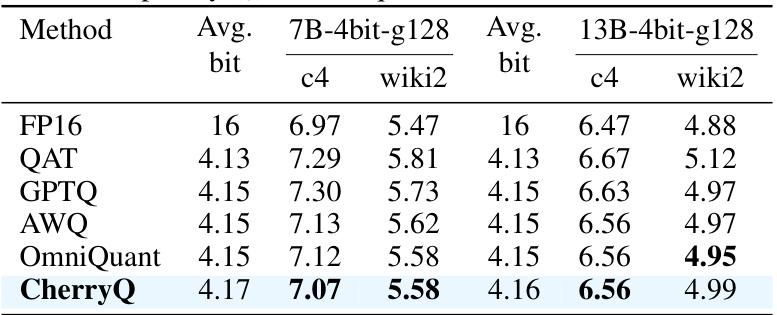
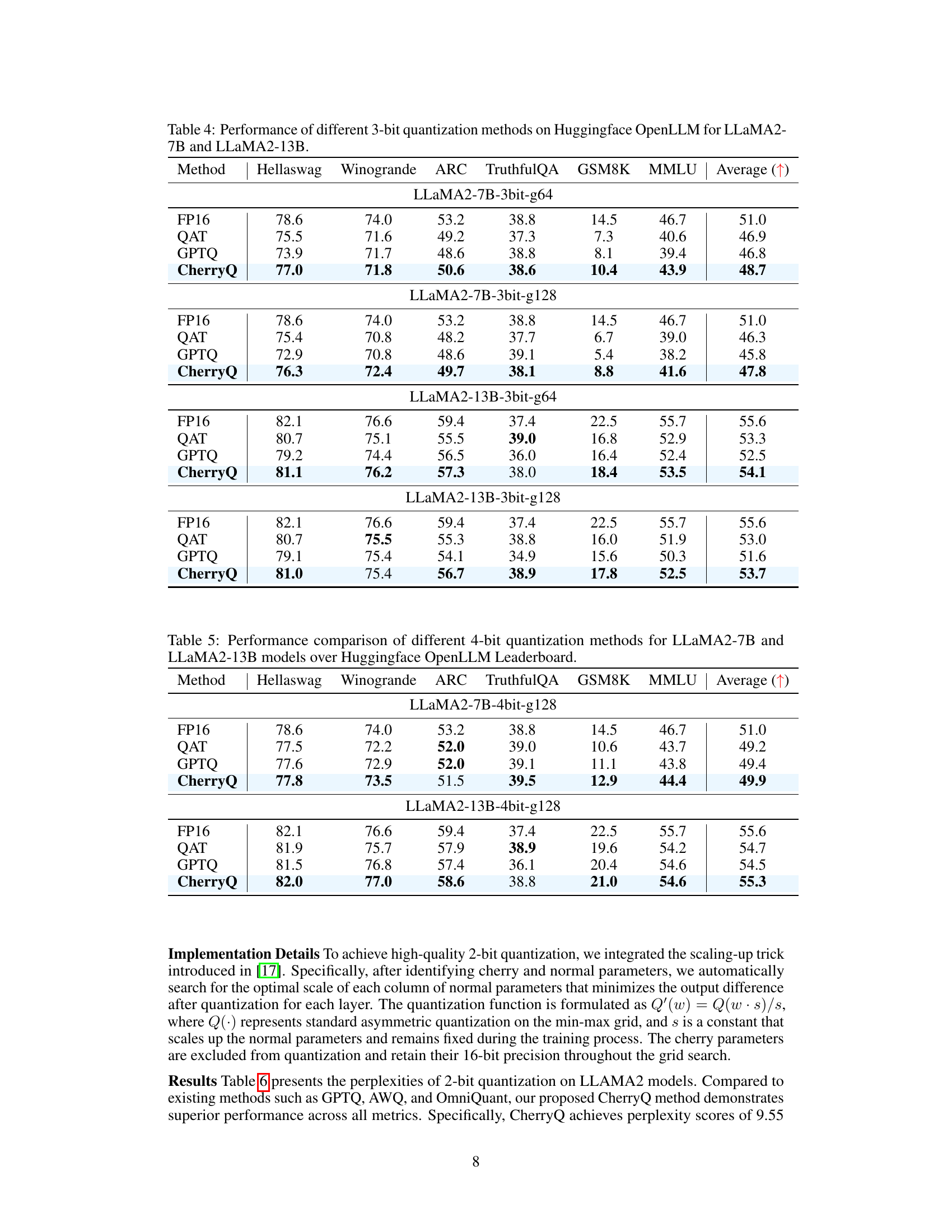
This table presents the perplexity scores achieved by different 4-bit quantization methods on the LLaMA2 model. It compares the performance of CherryQ against baselines such as QAT, GPTQ, AWQ, and OmniQuant across two datasets (c4 and wiki2) and two model sizes (7B and 13B parameters). Lower perplexity indicates better performance. The results demonstrate the superior performance of CherryQ.

This table compares the performance of different 3-bit quantization methods (FP16, QAT, GPTQ, and CherryQ) on various downstream tasks from the HuggingFace OpenLLM Leaderboard, using LLaMA2-7B and LLaMA2-13B models. The results show the average scores across multiple tasks for different group sizes (g64 and g128) to demonstrate the effectiveness of the CherryQ quantization approach.
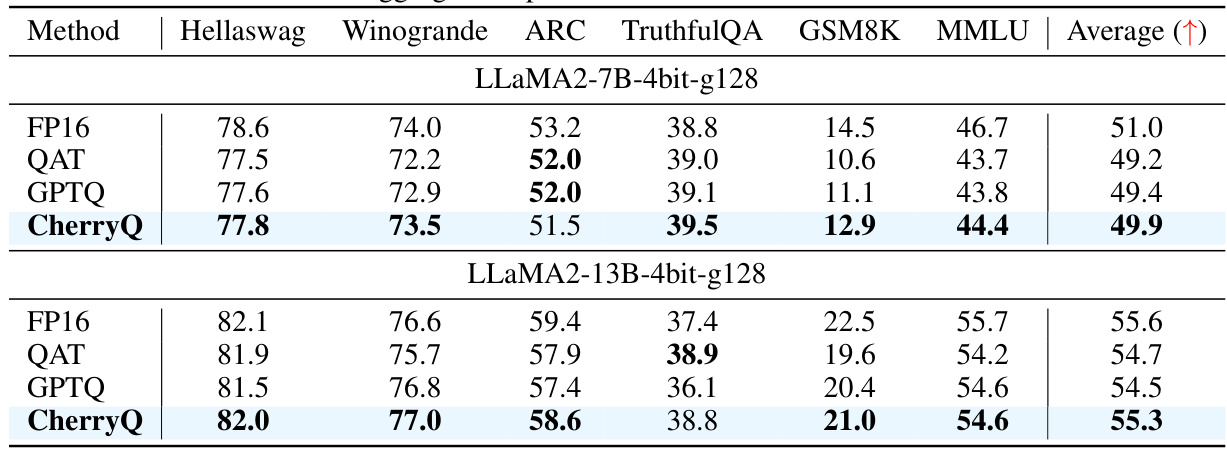
This table compares the performance of different 3-bit quantization methods (FP16, QAT, GPTQ, and CherryQ) on various downstream tasks from the HuggingFace OpenLLM Leaderboard for two different sizes of LLaMA2 models (7B and 13B parameters). The results are presented as average scores across multiple tasks, illustrating the relative effectiveness of each quantization technique in maintaining model performance after reducing the precision of the model parameters.
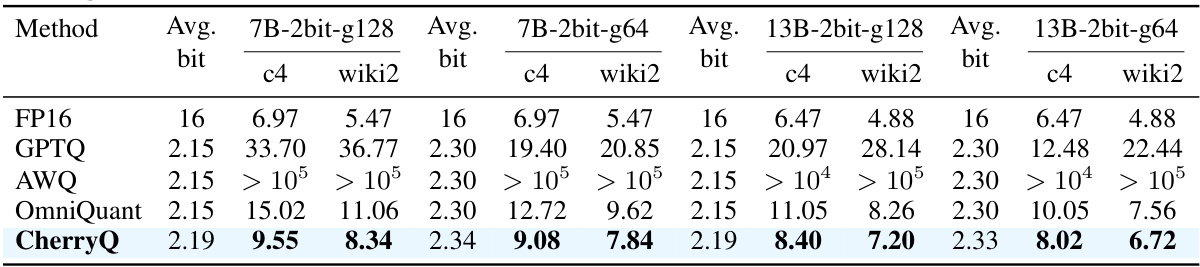
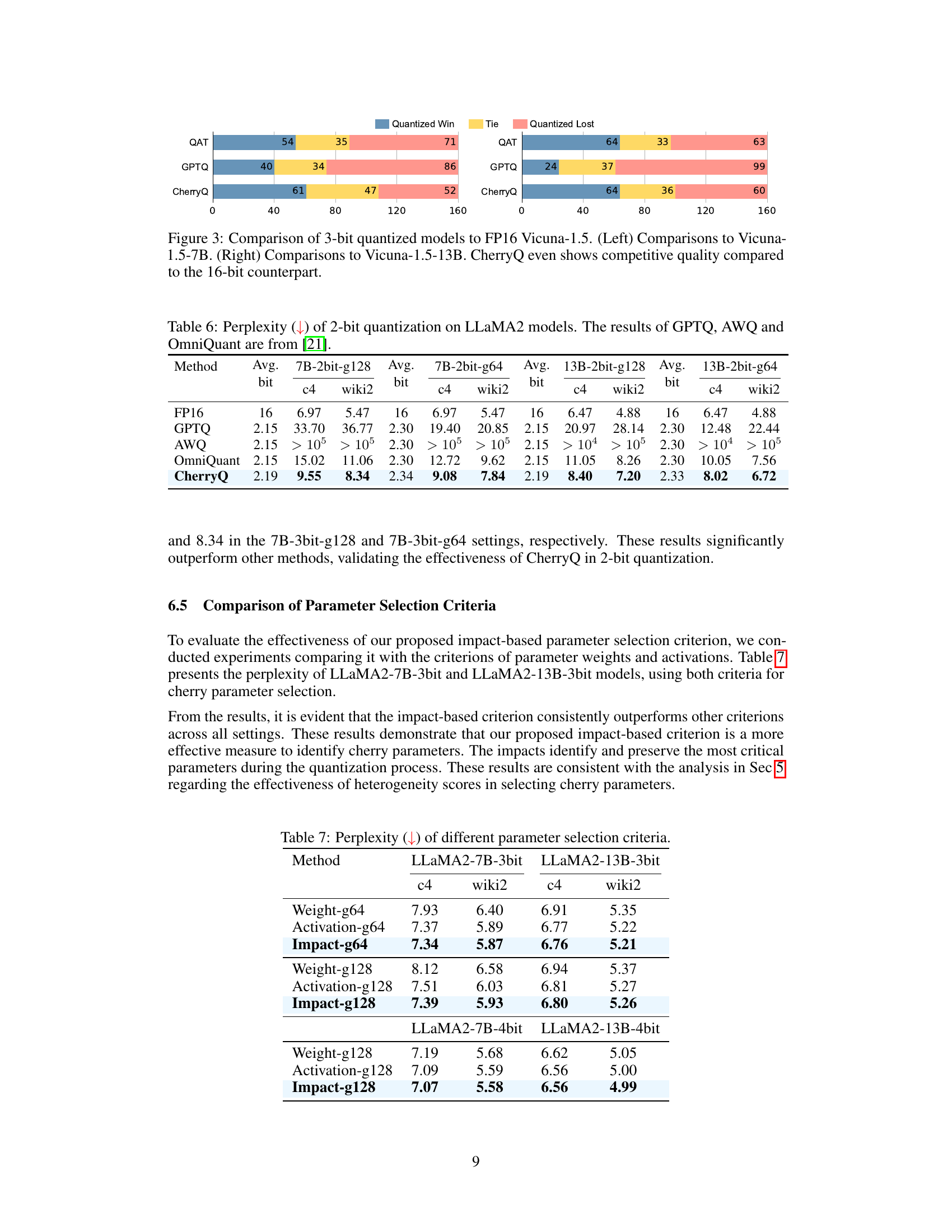
This table presents the perplexity results of 2-bit quantization on LLaMA2 models using different methods. It compares the performance of CherryQ against GPTQ, AWQ, and OmniQuant, showing perplexity scores for both 7B and 13B parameter models with different group sizes (g64 and g128). The results demonstrate CherryQ’s superior performance in 2-bit quantization across various settings.

This table compares the perplexity results of using different parameter selection criteria (Weight, Activation, Impact) for 3-bit and 4-bit quantization of LLaMA2 models with group sizes of 64 and 128. It demonstrates the superiority of the Impact-based criterion for identifying cherry parameters.

This table presents the results of a comparison of different 3-bit quantization methods on the zero-shot MMLU (Massive Multitask Language Understanding) accuracy for Vicuna-1.5, a large language model. The methods compared include FP16 (full precision), QAT (quantization-aware training), GPTQ (quantized GPT), and CherryQ (the proposed method). The accuracy is broken down by category (Humanities, STEM, Social Sciences, Other) and also shown as an average across all categories for both the 7B and 13B parameter versions of the model. The table highlights the performance of CherryQ in comparison to existing methods.
Full paper#