↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Transformer models, while powerful, suffer from attention dilution, where longer sequences lead to less focused attention. This is problematic because attention mechanisms are crucial for capturing contextual relationships, and diluted attention hinders effective processing. Existing solutions often involve adding many parameters or are not theoretically well-founded.
The paper proposes Selective Self-Attention (SSA), a lightweight method addressing attention dilution. SSA uses temperature scaling to control contextual sparsity, allowing the model to focus on relevant information. Extensive experiments demonstrate SSA’s effectiveness in improving model accuracy across various benchmarks, showing its superiority in terms of efficiency and performance.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel method called Selective Self-Attention (SSA) to enhance transformer models. SSA addresses the issue of attention dilution in long sequences by using principled temperature scaling on query and value embeddings. This simple change leads to significant performance gains across various language modeling benchmarks, and it’s efficient enough to apply to existing LLMs.
Visual Insights#
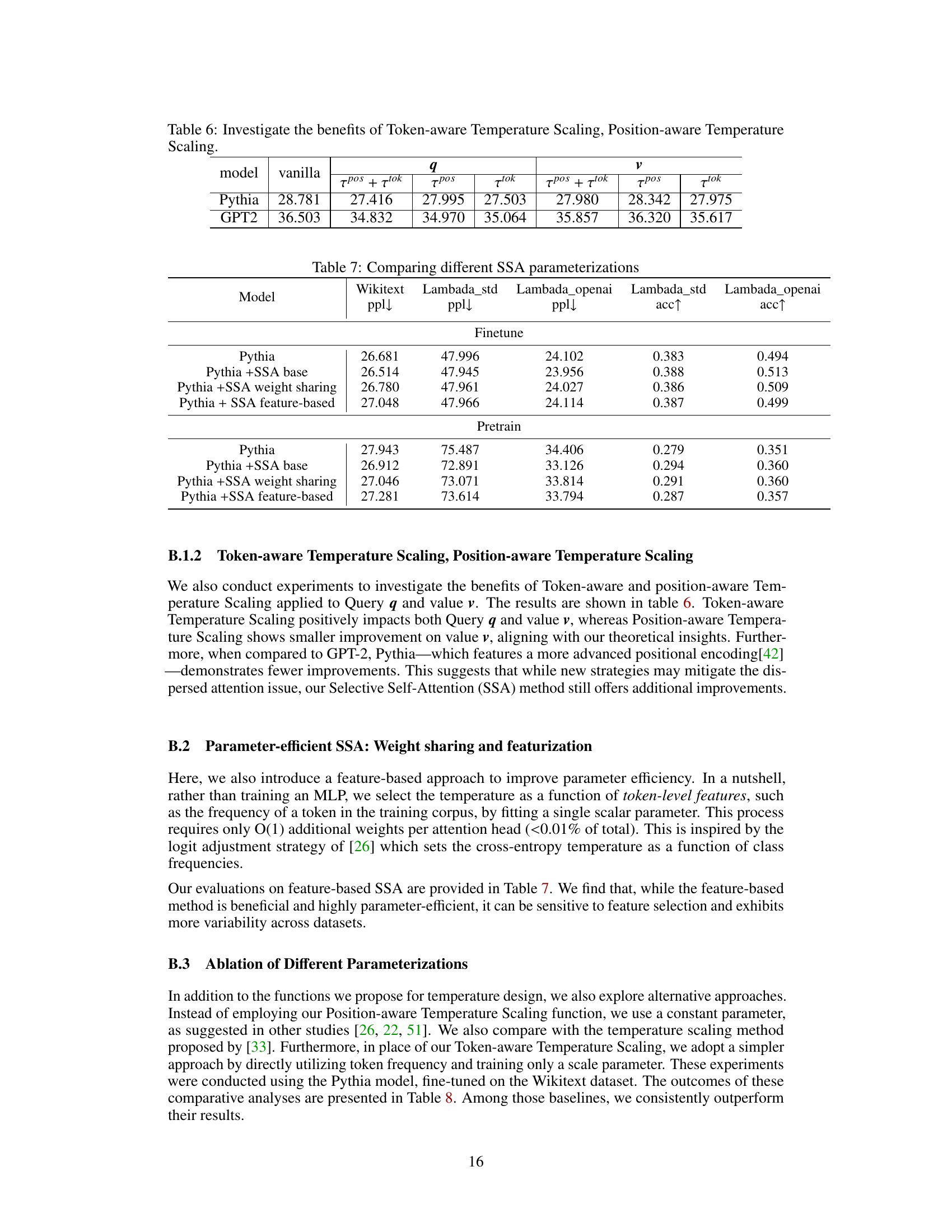
This figure shows the distribution of the operator norm of the combined query-key weight matrix (W) with and without query temperature scaling. The x-axis represents ranges of the norm values, and the y-axis represents the probability of a token having a norm within that range. The dashed lines indicate the average norm for both vanilla attention and SSA. The results show that SSA has a significantly smaller norm than vanilla attention, with a much lower average norm and a higher spikiness (sparsity). The lower average norm and higher spikiness suggest that SSA is more efficient in controlling contextual sparsity.

This table shows the temperature assigned to each node in a graph based on the number of neighbors it has. Nodes with the same number of neighbors receive the same temperature. This is part of the Selective Self-Attention (SSA) layer’s mechanism and its effect on the sparsity of the attention map.
In-depth insights#
Query Selectivity#
The concept of ‘Query Selectivity’ in the context of attention mechanisms within transformer models centers on the ability to control the sparsity and relevance of the attention map for each individual query. Traditional self-attention treats all queries uniformly, potentially leading to an inefficient allocation of attention resources, a problem exacerbated with longer sequences. Query selectivity aims to address this by decoupling semantic similarity from contextual sparsity. This is achieved through a principled approach of temperature scaling applied to query embeddings, allowing the model to independently control how much weight is given to different parts of the input sequence, depending on the specific query’s needs. This approach offers significant benefits by improving the model’s ability to focus on relevant information, suppress noise, and enhance expressivity, ultimately leading to better performance on downstream tasks. A key insight is that temperature scaling allows for independent control of semantic similarity (handled by projection matrices) and contextual sparsity (handled by temperature scaling). This disentanglement of objectives helps overcome the inherent tradeoff between the two, leading to a more efficient and effective attention mechanism. The theoretical results provide a strong foundation for the method, backed by empirical findings that show consistent improvements in model performance.
Value Selectivity#
The concept of ‘Value Selectivity’ in the context of attention mechanisms centers on enhancing the model’s ability to discern and prioritize relevant information within the ‘value’ embeddings. Standard attention mechanisms uniformly weigh all values, potentially leading to dilution and hindering performance. Value selectivity addresses this by introducing mechanisms to modulate the contribution of individual values, allowing the model to selectively emphasize or suppress specific values based on their relevance to the query. This is achieved using techniques such as temperature scaling or gating, which introduce a learnable scaling factor for each value embedding. By controlling these factors, the model can effectively amplify the impact of critical values while attenuating the influence of irrelevant or noisy ones. This selective weighting leads to improved accuracy and robustness, especially in scenarios with imbalanced or noisy data. Furthermore, it allows the model to achieve a more focused and contextualized understanding, thereby enhancing overall performance on various downstream tasks.
Positional Temp#
The concept of “Positional Temp” in the context of attention mechanisms suggests a refinement of temperature scaling. Instead of applying a uniform temperature across all tokens, positional temperature scaling adapts the temperature based on the token’s position within the input sequence. This is motivated by the observation that attention mechanisms in long sequences tend to suffer from “attention dilution,” where attention scores become flatter and less focused as the sequence length increases. Positional temperature scaling directly addresses this by adjusting the softmax sharpness of attention scores at different positions. Tokens earlier in the sequence might receive a lower temperature (sharper attention), emphasizing their relative importance in the context window, while later tokens could have higher temperature, allowing for more nuanced consideration of later contextual information. This approach promises improved model expressivity and better handling of long-range dependencies by decoupling semantic similarity from contextual sparsity, which are often conflicting objectives in traditional self-attention.
SSA Efficiency#
The efficiency of Selective Self-Attention (SSA) is a crucial aspect of its practical applicability. SSA’s core design incorporates a weight-sharing strategy, reducing the number of new parameters introduced to less than 0.5%. This minimizes the computational overhead and makes it easily adaptable to existing large language models (LLMs) without significant increases in model size or training time. The parameter efficiency is further improved by a feature-based approach, reducing the overhead even further. Although the paper notes a negligible impact on inference latency, this efficiency is a significant advantage, particularly when integrating SSA into already large models. Further research could explore the trade-off between the level of parameter sharing and the performance gains achieved by SSA, potentially leading to even more efficient implementations. The overall efficiency considerations highlight SSA’s practicality for deployment in resource-constrained environments or large-scale applications.
Future Scope#
The “Future Scope” section of this research paper on enhancing Transformer networks through selective self-attention (SSA) would naturally explore extending SSA’s benefits to other domains and architectures. Linear attention mechanisms, currently less computationally expensive than standard attention, would be a prime target for integration. The paper’s theoretical insights into SSA’s effects on sparsity and attention map expressivity suggest that adapting SSA to these alternate attention mechanisms could yield significant improvements in efficiency and performance. Furthermore, research could delve into the interpretability of SSA’s learned temperature parameters, aiming to better understand how these parameters relate to model performance and potential biases. Visualizing and analyzing these temperatures across different layers and contexts could be crucial for unveiling deeper insights into SSA’s inner workings. Finally, exploring the integration of SSA with other sparsity-inducing techniques is another promising avenue of research. Combining SSA with methods like sparse attention or pruning could lead to even greater computational efficiency and better performance on resource-constrained devices. The authors should also consider the application of SSA to specific domains beyond language modeling, such as computer vision or time-series analysis, where contextual control plays a vital role. A rigorous exploration of these avenues would solidify SSA’s position as a foundational component for optimizing attention mechanisms in various machine learning applications.
More visual insights#
More on figures

This figure compares the performance of Selective Self-Attention (SSA) and standard self-attention in a next-token prediction task using a small vocabulary. Subfigure (a) shows the graph representing the token transition dynamics. Subfigure (b) displays the ground-truth token transition matrix (P*). Subfigures (c) and (d) show the learned transition matrices using SSA and standard self-attention, respectively. The results demonstrate that SSA learns a transition matrix that is sharper, closer to the ground truth, and has lower cross-entropy loss and L1 approximation error than standard self-attention.

This figure shows a comparison of the training curves for vanilla attention and SSA (Selective Self-Attention) when fine-tuning the Llama model on the Wikitext dataset. The x-axis represents the number of tokens processed (in millions), and the y-axis represents the perplexity (ppl), a measure of the model’s performance. The graph shows that SSA achieves comparable perplexity scores to vanilla attention but in fewer training steps, demonstrating the training speedup offered by SSA. The red arrow emphasizes the speedup by highlighting the reduced number of tokens required by SSA to reach a similar perplexity level to the vanilla model.
More on tables
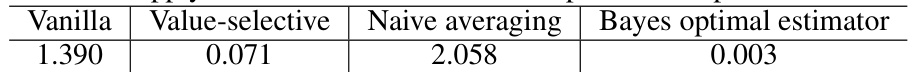
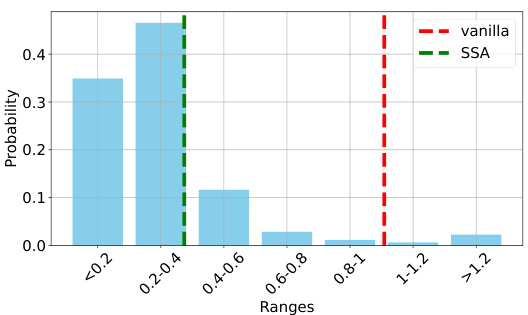
This table presents the Mean Squared Error (MSE) risk for different methods in a denoising task. The task involves predicting a target vector using attention mechanisms. The table compares the MSE risk achieved by four different methods: Vanilla attention, Value-selective attention (the proposed method), Naive averaging, and Bayes optimal estimator. The results highlight the superior performance of Value-selective attention in achieving a significantly lower MSE compared to the other methods, demonstrating its effectiveness in denoising.

This table presents the results of experiments evaluating the performance of models with and without Selective Self-Attention (SSA) on various NLP benchmarks. The experiments involve both pre-training (training models from scratch) and fine-tuning (fine-tuning pre-trained models on downstream tasks). The table shows the perplexity (ppl) and accuracy (acc) scores for several models (GPT-2, Pythia-160m, Pythia-410m, Llama, Llama3-8b) across multiple datasets (Wikitext, Lambada, Piqa, Hella, Winogrande, Arc-E, Arc-C). Results are shown for the baseline models and models with SSA (both with and without weight sharing). Lower perplexity indicates better performance on language modeling, while higher accuracy indicates better performance on downstream classification tasks. The results demonstrate that SSA consistently improves model performance, even when using a weight-sharing strategy for parameter efficiency.
This table presents the results of passkey retrieval experiments using different models. It shows the original performance of two models (Pythia-160m and Llama) on a passkey retrieval task, then compares those results to the performance of the same models after incorporating the proposed Selective Self-Attention (SSA) layer, both with and without a weight-sharing strategy. The passkey retrieval task measures a model’s ability to locate a specific five-digit number within a larger body of text. The results demonstrate a significant improvement in performance after incorporating SSA.

This table presents the results of fine-tuning various language models (Pythia and GPT2) on the Wikitext dataset. The ‘Baseline’ row shows the performance of the standard model. Subsequent rows show the impact of selectively applying temperature scaling to different components of the attention mechanism: the queries (Q), keys (K), and values (V). Each row indicates the model’s performance after modifying the specified components. The table helps to demonstrate the individual and combined effects of applying temperature scaling to these components on the models’ performance.

This table presents the results of an ablation study investigating the impact of token-aware and position-aware temperature scaling on the Pythia and GPT-2 language models. The ‘vanilla’ column shows the baseline performance without temperature scaling. Subsequent columns show the performance when applying only position-aware scaling (τpos), only token-aware scaling (τtok), both position-aware and token-aware scaling (τpos + τtok), and various combinations thereof, applied separately to the query (q) and value (v) components of the self-attention mechanism. The perplexity (ppl) scores are reported for the Wikitext dataset.
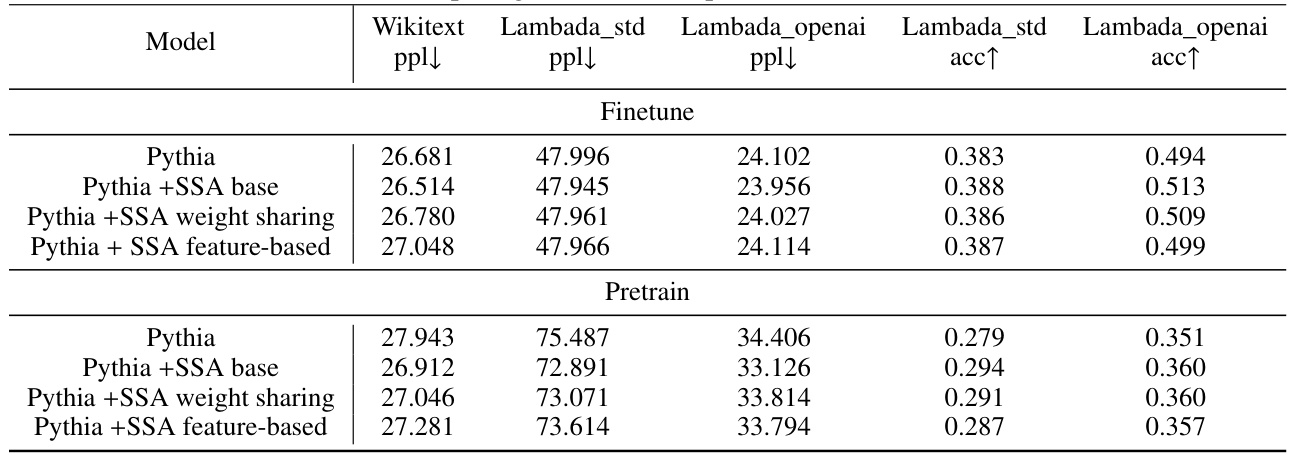
This table presents the results of experiments conducted on various language models (GPT-2, Pythia-160m, Pythia-410m, Llama, Llama3-8b) for both fine-tuning and pre-training tasks. The models were evaluated on several benchmarks (Wikitext, Lambada, Piqa, Hella, Winogrande, Arc-E, Arc-C), and the performance is measured using perplexity (ppl) and accuracy (acc). Lower perplexity values indicate better performance in language modeling, while higher accuracy indicates better performance in downstream tasks. The table also includes results for variants of the models incorporating the Selective Self-Attention (SSA) mechanism and those employing a weight-sharing strategy to reduce computational overhead.

This table compares the performance of different temperature scaling strategies on the Pythia model, including the vanilla self-attention mechanism, Yarn’s method, Constant, Frequency, and SSA. The results are perplexity scores on the Wikitext dataset, showing that SSA achieves the lowest perplexity.
Full paper#