↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multimodal learning struggles with modality imbalance, where models converge at different rates due to varying label-fitting difficulties across modalities. Existing solutions focus on adjusting learning procedures, but they don’t address the root cause of this inconsistent learning.
This paper identifies the core issue as inconsistent label-fitting ability. It proposes a novel method that dynamically integrates unsupervised contrastive learning with supervised multimodal learning to correct this difference in learning ability and address modality imbalance. Experimental results show significant performance improvements compared to state-of-the-art methods, demonstrating the effectiveness of this novel approach. The method is simple yet effective and easily implemented.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in multimodal learning—modality imbalance—by introducing a novel approach that dynamically integrates contrastive and supervised learning. This offers a potential solution to improve the performance of multimodal models, thus advancing the field and opening new avenues for research in handling heterogeneous data.
Visual Insights#
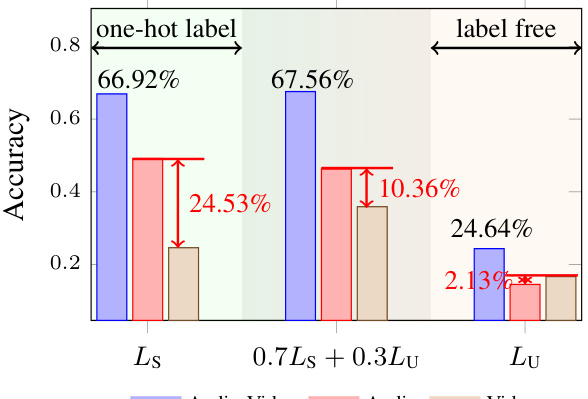
This figure shows the impact of different label fitting strategies on the performance gap between audio and video modalities in a multimodal learning task. Three label types are compared: one-hot labels (Ls), uniform labels (Lu), and a combination of both (0.7Ls + 0.3Lu, which is a label smoothing technique). The accuracy of the model is shown for each label type, separately for audio and video modalities. The results indicate that using uniform labels (Lu) or a label smoothing strategy reduces the performance gap between the two modalities, suggesting that the process of fitting category labels plays a role in the modality imbalance problem.
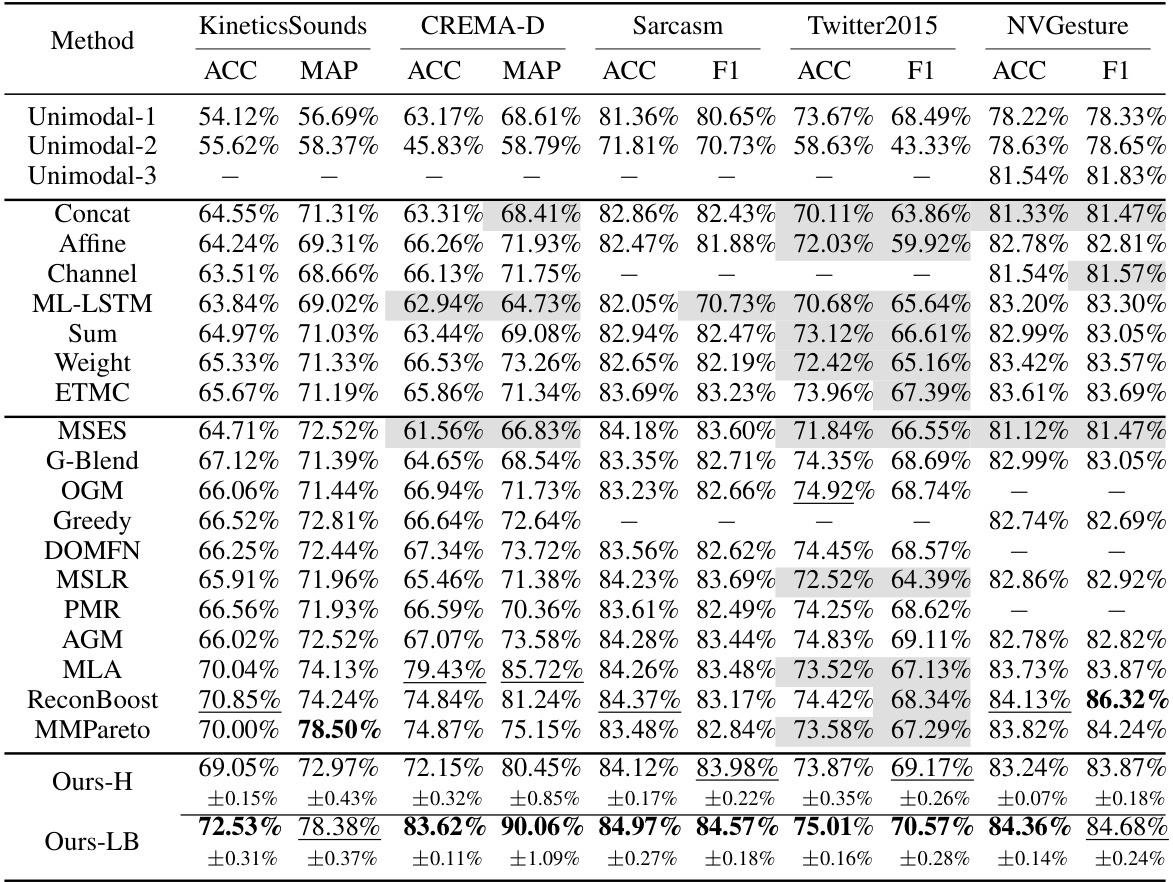
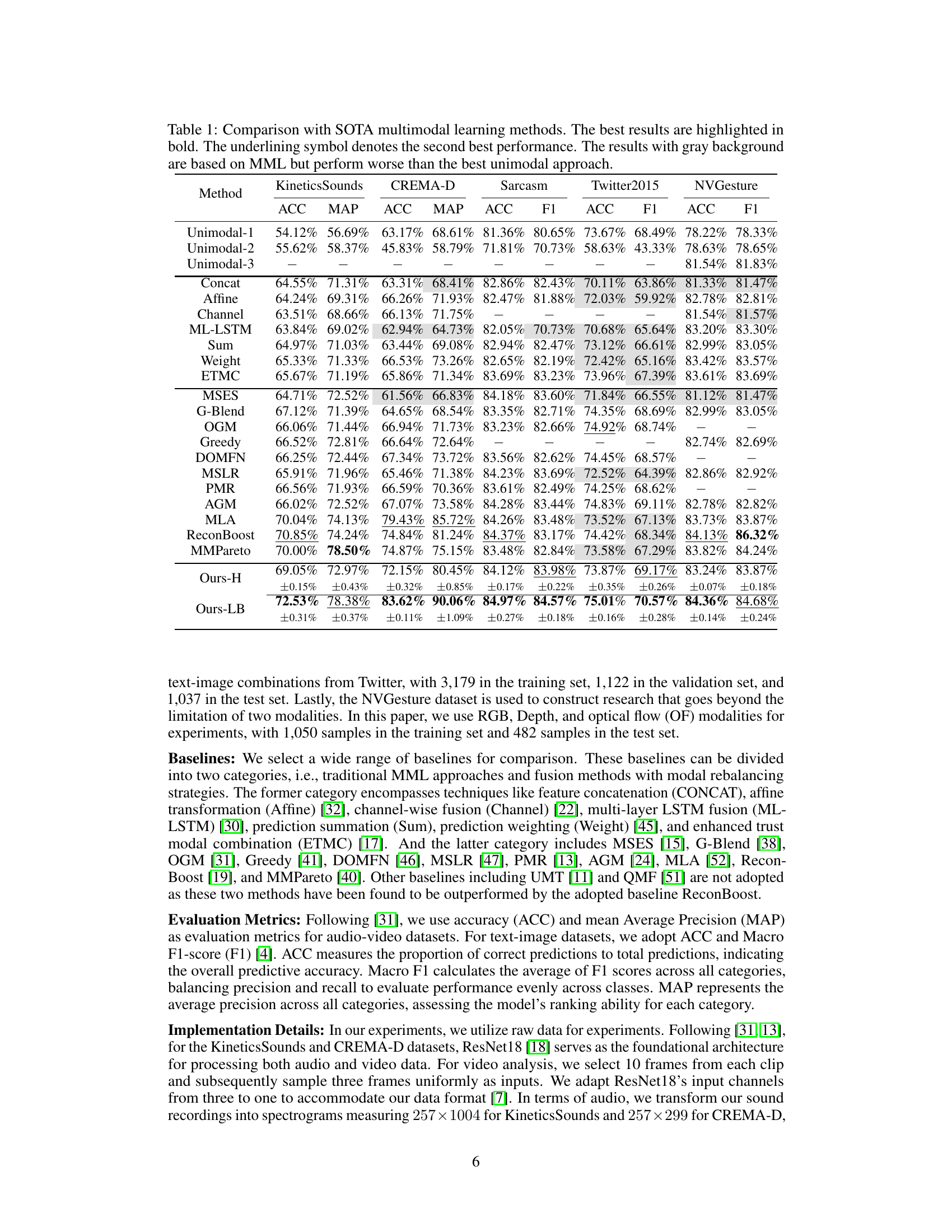
This table compares the performance of the proposed multimodal learning method with several state-of-the-art (SOTA) methods across six different datasets. The datasets vary in the type of modalities used (audio-video, image-text). The table presents accuracy (ACC), mean average precision (MAP), and macro F1-score (F1) as evaluation metrics. The best and second-best results for each dataset and metric are highlighted, and methods that perform worse than the best unimodal approach are shaded gray, illustrating the effectiveness of multimodal learning when properly addressed.
In-depth insights#
Modality Imbalance#
The phenomenon of modality imbalance in multimodal learning is a significant challenge, where some modalities dominate the learning process while others are underrepresented. This imbalance arises because different modalities may have varying levels of difficulty in predicting the target variable. Dominant modalities often overshadow weaker ones, leading to suboptimal performance. The paper investigates this by proposing a novel approach to address the problem through dynamic integration of unsupervised contrastive learning and supervised multimodal learning. This integration aims to reduce the disparity in the learning ability of different modalities by correcting the difference in the learning ability. This approach suggests that the core issue of modality imbalance may lie in the differences in how category labels are fit in each modality, which contrastive learning helps mitigate. The effectiveness of this approach is demonstrated experimentally, showing improvements in performance across multiple datasets. Ultimately, understanding and addressing modality imbalance is critical for realizing the full potential of multimodal learning models.
Contrastive Learning#
Contrastive learning, in the context of multimodal learning, plays a crucial role in bridging the gap between different modalities by learning similar representations for data pairs from different sources. It helps align multimodal representations, mitigating the effects of modality imbalance which often hinders performance. The core idea is to push embeddings of data points from the same entity closer together (similar pairs), while simultaneously separating them from embeddings of different entities (dissimilar pairs). This approach helps to learn features that are robust across various modalities and generalize well. Incorporating contrastive learning dynamically with supervised learning allows for a more balanced training process, avoiding situations where dominant modalities overshadow weaker ones. This is achieved through the careful design and weighting of different loss functions, ensuring that the model learns both discriminative category features and consistent inter-modal relationships. The paper’s methodology highlights the importance of integrating contrastive learning dynamically into multimodal learning architecture to significantly improve model performance and address the limitations of traditional methods.
Dynamic Integration#
The proposed method dynamically integrates unsupervised contrastive learning and supervised multimodal learning using two strategies: heuristic and learning-based. The heuristic strategy uses a monotonically decreasing function to adjust the impact of category labels over training epochs, automatically balancing the two losses. The learning-based approach uses bi-level optimization, dynamically determining the optimal weight between the classification and modality matching losses, allowing for a more adaptive balance throughout the training process. This dynamic integration is crucial because it addresses the modality imbalance problem, a core challenge in multimodal learning where models converge at different rates due to varying label-fitting difficulties. By dynamically adjusting the weight of the two losses, the approach ensures that neither loss dominates, leading to more robust and accurate models capable of better integrating heterogeneous information from various modalities.
Ablation Experiments#
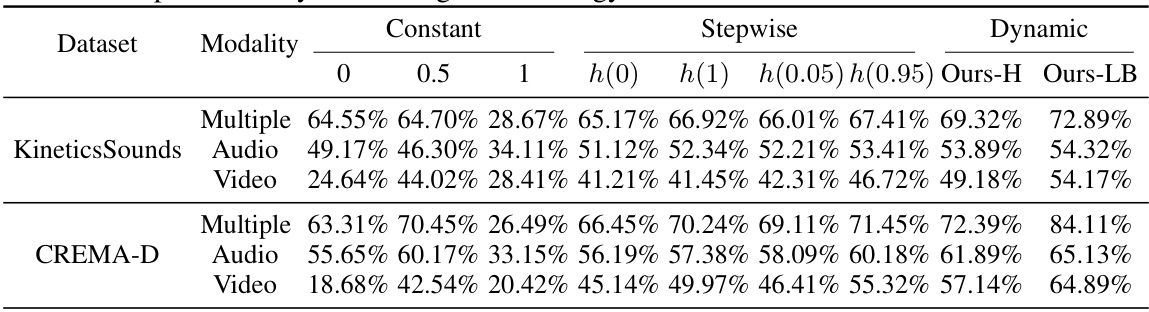
Ablation experiments systematically remove components of a model to determine their individual contributions. In the context of a multimodal learning paper, this would involve successively disabling or altering different modalities or parts of the architecture (e.g., removing a specific fusion method, or altering the weight assigned to different modalities). The results reveal the importance of each component and help establish causality. For example, if removing a specific modality significantly degrades performance, it highlights that modality’s crucial role. Similarly, analyzing the effect of removing different fusion techniques helps in selecting the most effective approach. A well-designed ablation study is critical for establishing the effectiveness of a proposed methodology and isolating the specific contributions of various components. By carefully observing changes in performance following these removals or alterations, a comprehensive understanding can be built for how different parts of the system work together or individually, providing valuable insights and possibly leading to optimizations or modifications for improved performance. It helps determine whether the improvements seen are due to a single key aspect or a synergistic effect of multiple components.
Future Directions#
Future research could explore more sophisticated integration strategies beyond the heuristic and learning-based methods presented, potentially leveraging reinforcement learning or meta-learning to dynamically adjust the balance between contrastive and supervised learning. Investigating the specific reasons why certain categories are more difficult to fit for certain modalities is crucial. This would involve analyzing feature spaces and label distributions to identify sources of modality imbalance at a deeper level, possibly using techniques from explainable AI. Extending this framework to more diverse and complex multimodal datasets with a greater number of modalities and more nuanced interdependencies between them would further test the robustness and generalizability of the approach. Finally, exploring applications beyond classification, such as multimodal generation or retrieval tasks, would showcase the potential of dynamically integrating contrastive and supervised learning more broadly.
More visual insights#
More on figures

This figure shows the impact of different label fitting strategies on the performance gap between audio and video modalities in a multimodal learning task. Three label strategies were used: one-hot labels (Ls), uniform labels (Lu), and a mix of one-hot and uniform labels (0.7Ls + 0.3Lu). The results demonstrate that using uniform labels reduces the performance gap, suggesting that the difference in learning ability between modalities is partly due to the difficulty of fitting category labels.

This figure visualizes the modality gap distance for four different multimodal learning methods: CONCAT, G-Blend, MLA, and the proposed method. Each subplot shows a scatter plot of audio and image feature vectors projected onto a two-dimensional space. The lines connecting points represent the distance between audio and image representations of the same sample. The ‘Gap Distance’ value quantifies the overall separation between audio and image features. The figure demonstrates that the proposed method achieves a larger modality gap than the other methods, suggesting a more effective separation of features and potentially improved performance.
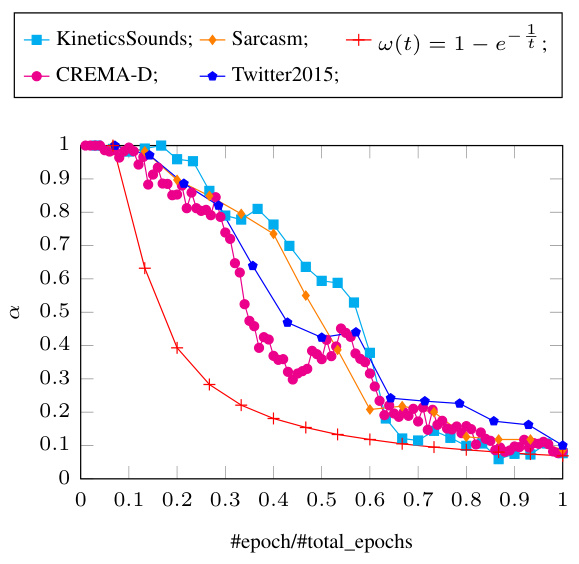
This figure shows the change of the weighting parameter α over the course of training for different datasets using two dynamic integration strategies: learning-based and heuristic. The x-axis represents the normalized epoch number (#epoch/#total_epochs), and the y-axis shows the value of α. Each line represents a different dataset (KineticsSounds, CREMA-D, Sarcasm, Twitter2015), with the heuristic strategy’s α change shown for comparison. The figure demonstrates how the optimal α value for balancing the classification loss and modality matching loss varies depending on the dataset and the chosen strategy. The learning-based strategy dynamically adjusts α to improve performance, while the heuristic strategy uses a predefined decreasing function.
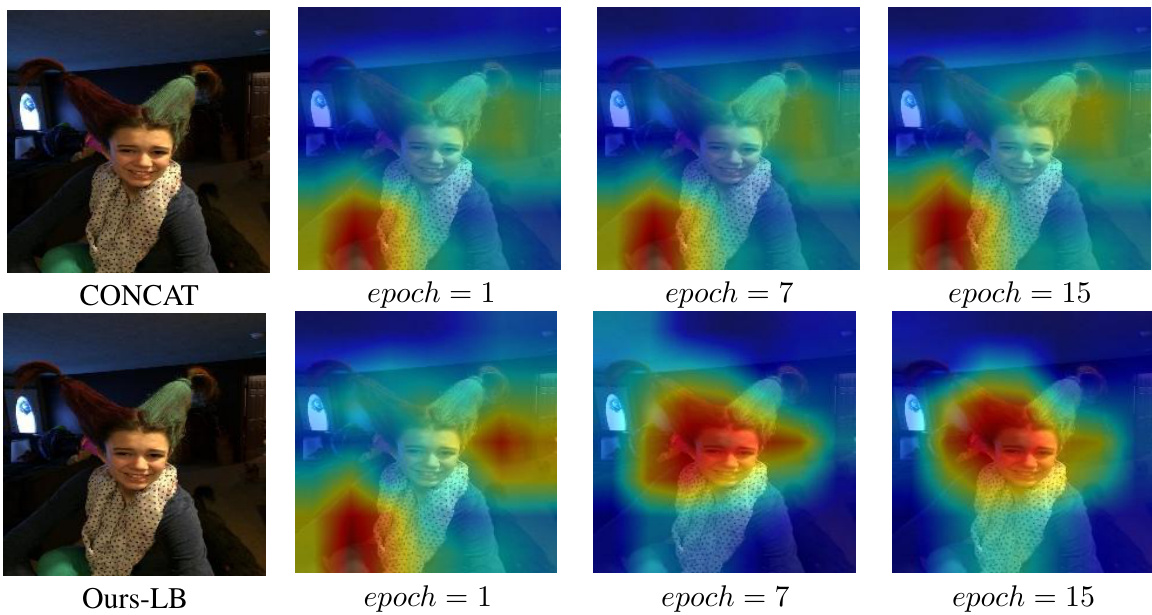
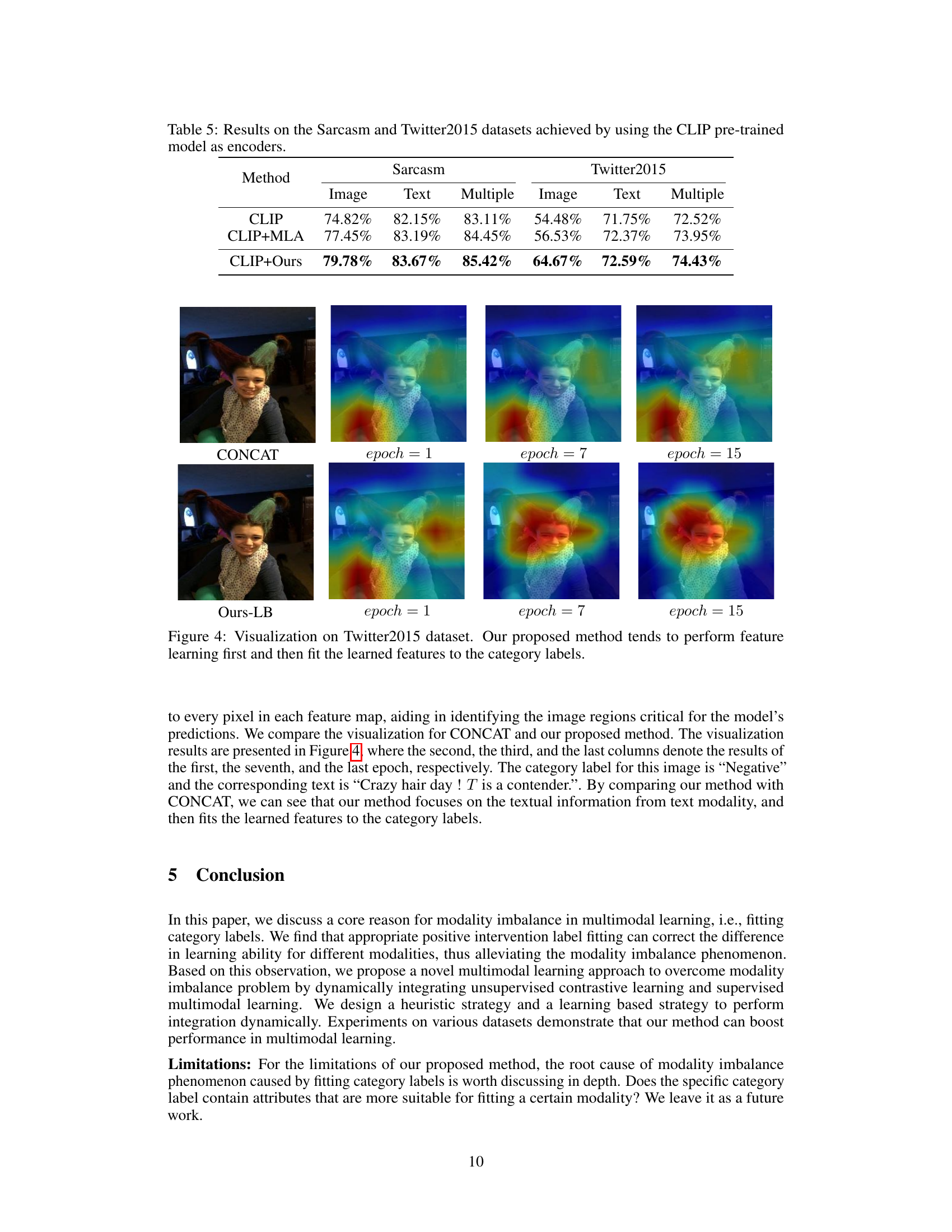
The figure visualizes the attention maps generated by GradCAM for the CONCAT and Ours-LB methods on the Twitter2015 dataset at epochs 1, 7, and 15. It shows how the models focus on different aspects of the image during training. CONCAT shows less focused attention throughout the epochs, whereas Ours-LB demonstrates a more focused attention that evolves over time, suggesting a learning process that prioritizes feature extraction before classification.
More on tables

This table presents the results of the proposed method and several baselines on the VGGSound dataset, focusing on the Accuracy (ACC) and Mean Average Precision (MAP) metrics. The results show a comparison between the proposed heuristic (Ours-H) and learning-based (Ours-LB) dynamic integration strategies and other state-of-the-art multimodal learning methods (AGM, MLA, ReconBoost, MMPareto).

This table compares the performance of the proposed multimodal learning approach with state-of-the-art (SOTA) methods on six benchmark datasets. It shows accuracy, mean average precision (MAP), and F1-score across various datasets and different modalities, highlighting the superiority of the proposed approach. The results are broken down by dataset and modality (audio-video or image-text) showing the improvements achieved by each of the methods. The grey background indicates methods that perform worse than the best unimodal results on the same dataset.
This table compares the performance of the proposed multimodal learning approach with state-of-the-art (SOTA) methods on six benchmark datasets. It shows the accuracy (ACC), mean average precision (MAP), and F1-score (F1) for each method and dataset. The results highlight the superior performance of the proposed approach, especially when compared to unimodal baselines and other multimodal methods that don’t address modality imbalance.
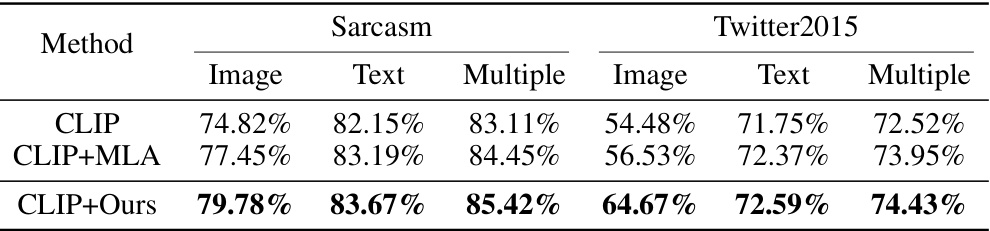
This table compares the performance of the proposed multimodal learning method with state-of-the-art (SOTA) methods on six benchmark datasets. It shows accuracy, mean average precision (MAP), and macro F1-score (F1) for each dataset and method. The best results are highlighted in bold, and the second-best results are underlined. Results worse than the best unimodal method are shaded gray, highlighting the benefit of the proposed approach.
Full paper#