TL;DR#
Super-resolution (SR) models struggle with domain adaptation when limited target data is available. Existing methods often require numerous target images, hindering real-world applicability. The lack of diversity in a single target image further limits adaptation effectiveness, causing problems like pattern collapse during training.
IODA addresses these issues by introducing two novel techniques. First, an image-guided domain adaptation method uses pixel-level representations to capture fine-grained texture details, improving the guidance for SR networks. Second, an instance-guided target domain distribution expansion strategy leverages Alpha-CLIP to generate instance-specific features from a single target image, expanding the feature space and improving adaptation. Experimental results across multiple datasets demonstrate IODA’s significant performance improvement in one-shot domain adaptation scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the real-world challenge of limited data availability in super-resolution (SR). By enabling effective domain adaptation with just one unlabeled target image, it opens new avenues for SR research and has practical implications for various applications where obtaining large, labeled datasets is difficult or impossible.
Visual Insights#

🔼 This figure shows the performance improvement achieved by using IODA on three different network architectures (SAFMN, SRFormer, and HAT). The baseline performance represents the results obtained using the original pre-trained weights on the RealSR_Canon dataset. The orange bars indicate the improved performance after adding IODA, showcasing the effectiveness of the method in enhancing super-resolution performance, especially in real-world scenarios.
read the caption
Figure 1: Performance improvement by IODA. The performance of the real-world pre-trained weights (from DF2K dataset [1]) provided in the original paper serves as the baseline on the real-world dataset RealSR_Canon [2].

🔼 This table presents the results of an effectiveness validation experiment for the IODA method. It compares the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) scores obtained using three different methods: a baseline, an image-guided method, and the full IODA method. The source domain dataset used for pre-training is DF2K, while the target domain dataset for testing is RealSR_Canon. The experiment employs the SAFMN network architecture. The table showcases the improvement in PSNR and SSIM achieved by incorporating the proposed techniques, demonstrating the effectiveness of IODA in one-shot domain adaptation for super-resolution.
read the caption
Table 1: Effectiveness validation of IODA. Source domain dataset: DF2K [1]. Target domain dataset: RealSR_Canon [2]. Network architecture: SAFMN [26].
In-depth insights#
One-shot SR Adapt#
The concept of ‘One-shot SR Adapt’ presents a significant challenge and opportunity in super-resolution (SR). It implies adapting an SR model to a new domain using only a single low-resolution (LR) image from that target domain. This differs drastically from traditional domain adaptation which leverages numerous LR images for training. The key difficulty lies in the limited diversity of the target domain’s data representation, making robust adaptation challenging. Successful ‘One-shot SR Adapt’ would require innovative techniques to effectively generalize from a solitary LR image, likely involving techniques like meta-learning, few-shot learning, or other forms of efficient knowledge transfer. A strong emphasis on learning transferable features and robust representations would be crucial. The successful development of such a method could greatly benefit real-world applications where acquiring large amounts of target domain data is impractical or impossible, making SR techniques more versatile and practical in real scenarios.
Image-guided DA#
The proposed Image-guided Domain Adaptation (DA) method offers a novel approach to address the limitations of text-based DA in super-resolution (SR) tasks. Instead of relying on text descriptions, which lack the fine-grained detail needed to capture texture differences critical to SR, this method directly compares pixel-level representations of source and target domain images. This pixel-level comparison allows for a more precise representation of domain differences, enabling more effective guidance for the SR network’s adaptation. This higher granularity is especially beneficial in SR tasks, where accurate reconstruction of fine texture details is crucial for high-quality results. The method leverages the CLIP model to compute cross-domain direction vectors for both LR and SR images, ensuring alignment and improved adaptation. By operating directly on image features, this approach sidesteps the limitations of text-based domain descriptions and provides a more effective solution for one-shot domain adaptation scenarios.
Instance Expansion#
Instance expansion, in the context of single-image domain adaptation for super-resolution, addresses the critical limitation of limited data diversity. Standard domain adaptation techniques rely on numerous target domain images, but real-world applications often provide only one. This scarcity hinders effective adaptation. Instance expansion aims to artificially augment the diversity of the single image’s representation by generating variations. These variations might represent different parts of the image (like individual objects or textures), focusing on granular details, improving the algorithm’s generalization across various aspects. This is crucial for SR, which is extremely sensitive to image detail. Methods like applying occlusion masks or utilizing region-range masks with Alpha-CLIP are employed to generate these varied representations of the image. These techniques are designed to simulate the variability one would encounter with multiple images, thus improving the robustness and performance of the super-resolution model in unseen scenarios. The effectiveness of instance expansion hinges on its ability to sufficiently increase the feature space of a single image without overfitting or generating unrealistic artifacts. The success of this strategy is heavily dependent on the instance selection method, model architecture and loss function.
IODA Ablation#
The IODA ablation study systematically evaluates the individual contributions of each module within the proposed IODA framework for one-shot domain adaptation in super-resolution. Image-guided domain adaptation, replacing text-based methods with pixel-level comparisons, shows a significant performance boost, highlighting the importance of fine-grained texture detail for SR. The instance-guided target domain distribution expansion, addressing the limited diversity of a single target image, further improves results by generating diverse instance-specific features. Ablation experiments demonstrate that both modules are crucial and complementary; neither alone achieves the same level of success as their combination in IODA. Overall, the ablation study validates the design choices in IODA and underscores the effectiveness of its multi-pronged approach for robust one-shot domain adaptation in challenging super-resolution scenarios.
SR IODA Limits#
The heading ‘SR IODA Limits’ suggests an examination of the boundaries and shortcomings of the Instance-Guided One-shot Domain Adaptation (IODA) method specifically for Super-Resolution (SR) tasks. A thoughtful analysis would explore the method’s reliance on a single, unlabeled target image, limiting the generalizability and potentially leading to overfitting. The effectiveness of IODA’s image-guided domain adaptation might be scrutinized in scenarios with significant texture variations or complex domain shifts exceeding the method’s capacity. Furthermore, the computational efficiency and scalability of the IODA approach should be discussed considering the cost of instance-specific feature generation. The impact of noise and artifacts in the single target LR image on the final SR result needs investigation. Finally, a comparison with alternative one-shot or few-shot domain adaptation techniques for SR could provide further insight into IODA’s strengths and weaknesses. Overall, a comprehensive exploration of ‘SR IODA Limits’ would offer a balanced view of the method’s potential and limitations, enriching the understanding of its practical applicability.
More visual insights#
More on figures
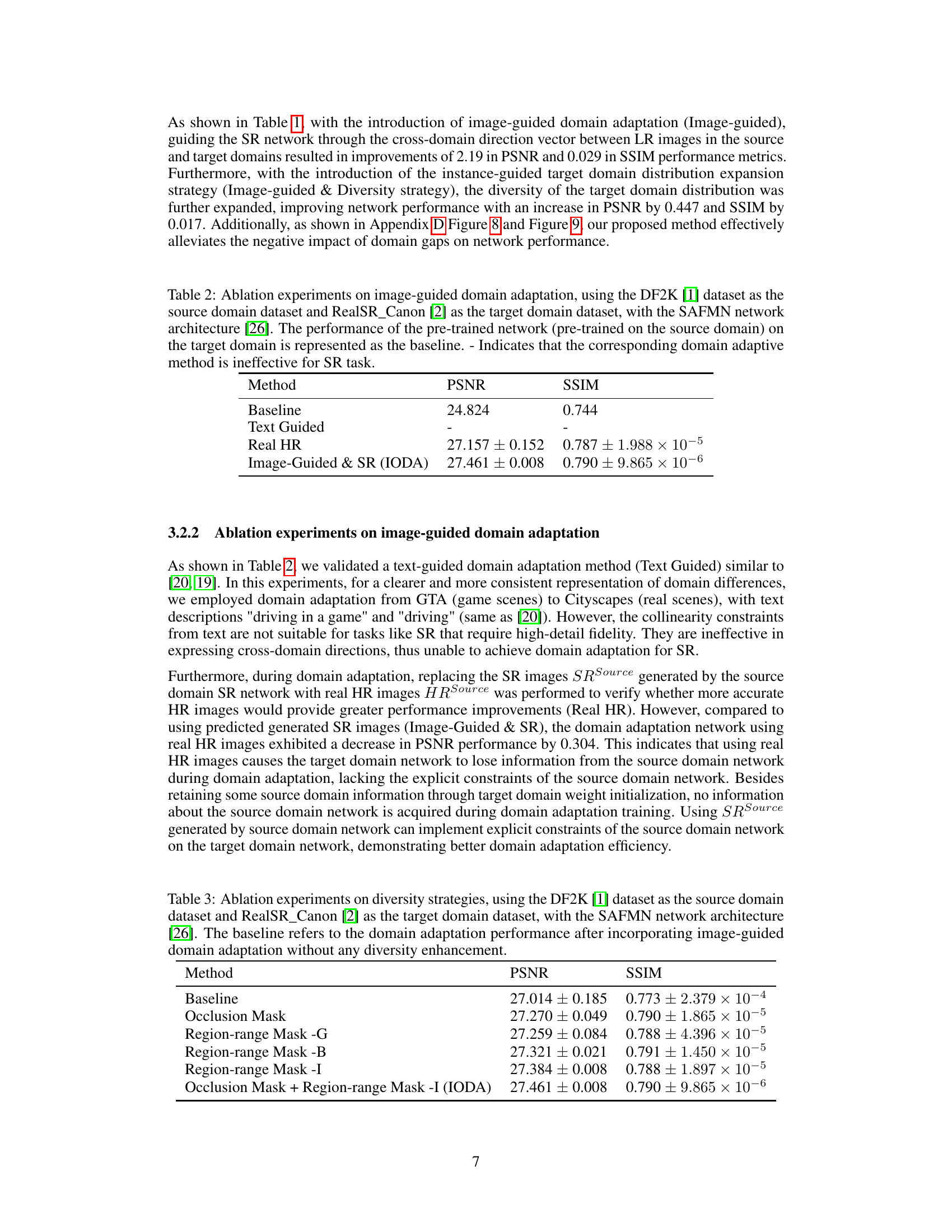
🔼 The figure illustrates the overall framework of IODA, which consists of two stages. In stage one, a source domain SR network (Ms) is pre-trained using the source domain dataset (DSource). In stage two, domain adaptation is performed on the SR network (Ms). The weights of the pre-trained network (Ms) are frozen and used to initialize the target domain SR network (MT). LR and SR images from both source and target domains are used to compute cross-domain direction vectors in the Alpha-CLIP space. The Ldirection loss is calculated to align these two cross-domain direction vectors, enabling domain adaptation training for the target domain SR network (MT).
read the caption
Figure 2: Overall framework
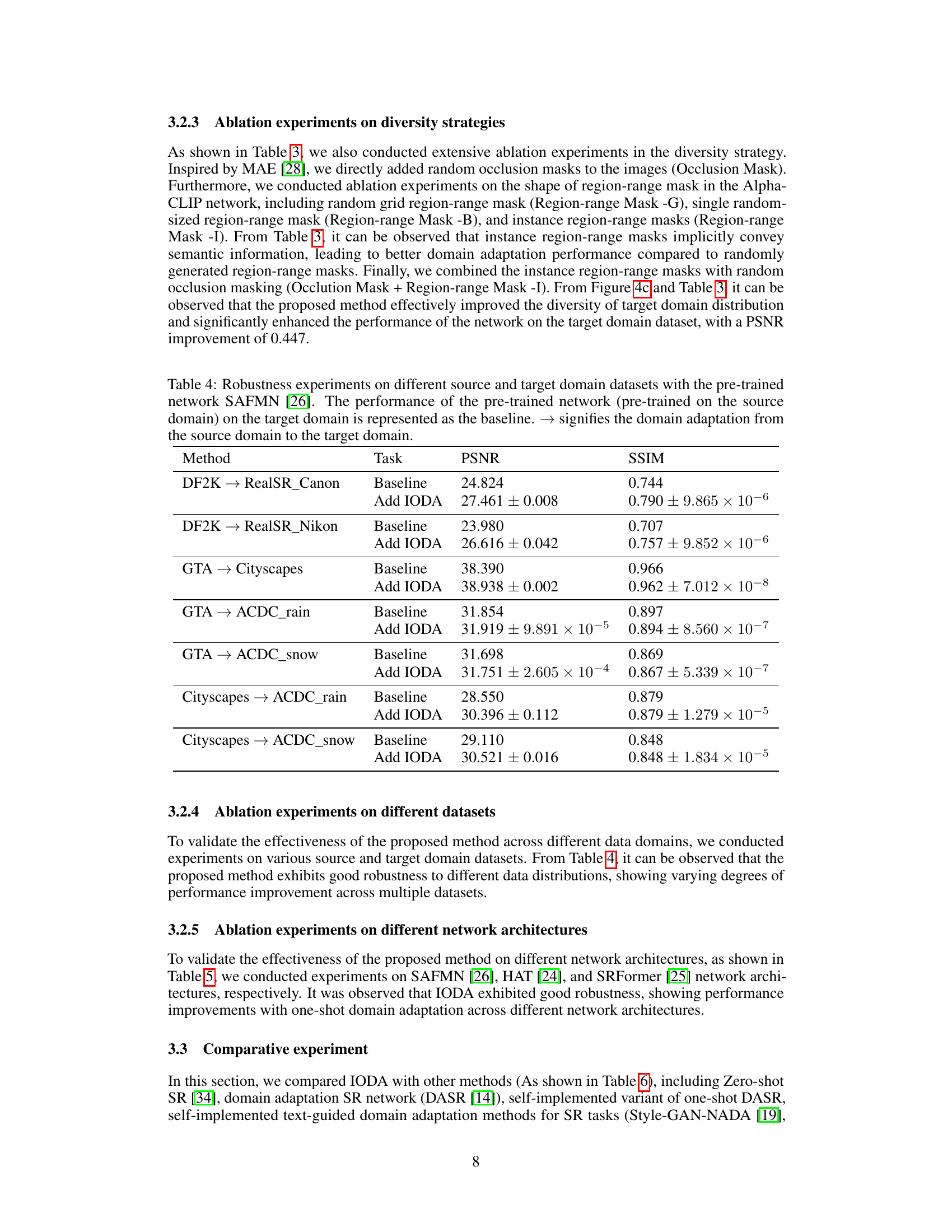
🔼 This figure illustrates the second stage of the IODA framework, focusing on image-guided domain adaptation. It shows how the source domain SR network (Ms) and the target domain SR network (MT) are used. LR and SR images from both source and target domains are inputted into a CLIP model to compute cross-domain direction vectors (ALR and ASR). These vectors represent the difference in features between the domains and are used to guide the adaptation of the target network (MT) to the target domain. The goal is to make the output of the target network (SRTarget) similar to the source network’s output on the target domain (LRTarget).
read the caption
Figure 3: Image-guided domain adaptation method. This figure depicts the second stage of domain adaptation. Ms and MT represent the source domain SR network and the target domain SR network, respectively.
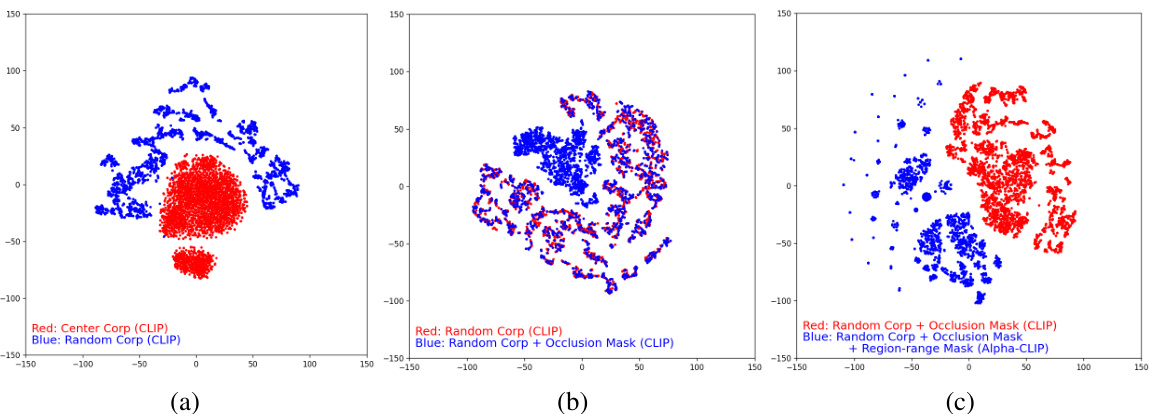
🔼 This figure compares feature distribution visualizations using t-SNE after inputting a single target domain LR image to CLIP and Alpha-CLIP encoders. The results show that using Alpha-CLIP with instance-specific features (Region-range Mask) significantly increases the dispersion of the feature distribution compared to using just CLIP or CLIP with occlusion masks. A more dispersed distribution indicates a more diverse representation of the target domain, which is beneficial for domain adaptation.
read the caption
Figure 4: Feature distribution comparison. Inputting a single target domain LR image into the image encoders of the CLIP model (a, b) and the Alpha-CLIP model (c), visualizing the output features after dimension reduction using T-SNE [27] (repeated 1000 times). It's worth noting that the more dispersed the scatter plot distribution, the more diverse the target domain feature distribution.
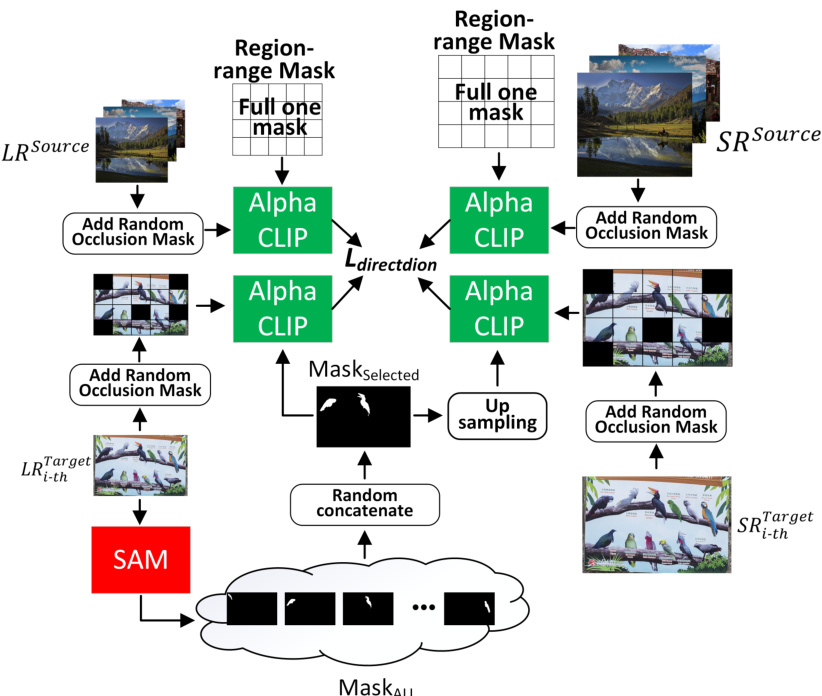
🔼 This figure illustrates the Instance-guided target domain distribution expansion strategy. It shows how the source and target domain low-resolution (LR) images are processed through their respective super-resolution (SR) networks to generate high-resolution (HR) images. The strategy involves using the Segment Anything Model (SAM) to generate region-range masks, then using Alpha-CLIP with these masks to generate instance-specific features, which expand the diversity of the target domain feature distribution. This is crucial for one-shot domain adaptation where only one LR target image is available for training.
read the caption
Figure 5: Instance-guided target domain distribution expansion strategy. The source domain and target domain SR images SRSource, SRTarget are generated from the corresponding LR images LRSource, LRTarget through their respective domain-specific SR networks Ms and MT.
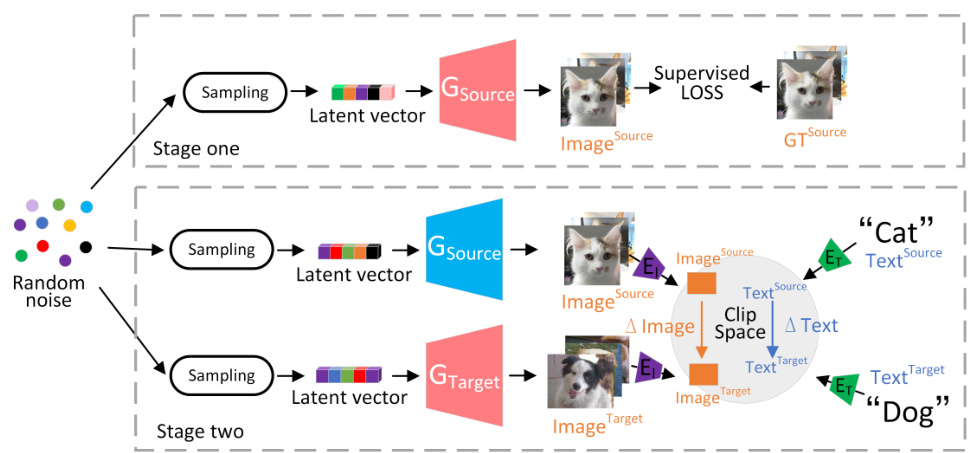
🔼 This figure illustrates the typical approach of text-guided domain adaptation used in image generation. In stage one, the source domain generation network (GSource) is pre-trained. In stage two, the network is adapted to the target domain. Random noise is sampled to produce latent vectors, which are input to both the source and target domain generation networks (GSource and GTarget respectively). The generated images are then compared using CLIP. Text descriptions guide the adaptation by constraining the direction vectors (ΔImage and ΔText) in the CLIP embedding space. The goal is for the images generated to shift based on the text change (e.g., from ‘cat’ to ‘dog’).
read the caption
Figure 6: Text-guided domain adaptation. Existing generative networks typically sample from random noise to generate latent vectors, which are then input into the generator network to produce images. Red indicates adjustable weights, while blue indicates frozen weight.
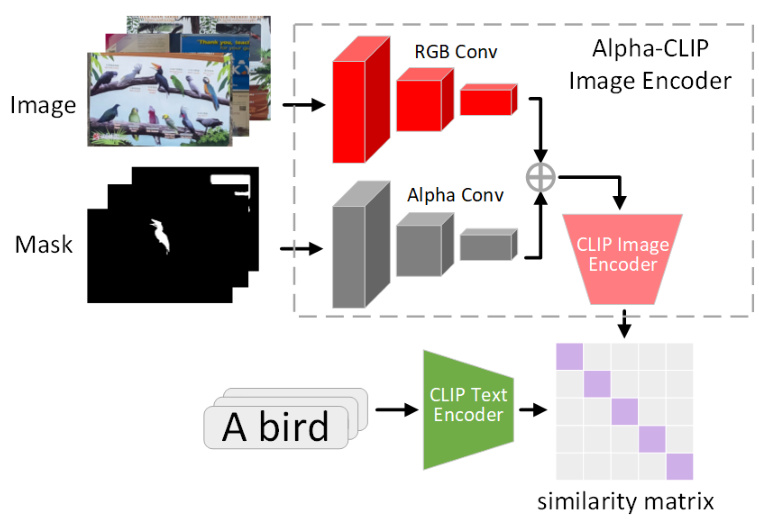
🔼 This figure shows the architecture of Alpha-CLIP. It takes an image and a mask as input. The image is processed by an RGB convolutional branch, while the mask is processed by an Alpha convolutional branch. The outputs of both branches are combined and fed into the Alpha-CLIP image encoder. The CLIP image encoder’s output is then compared with the output of the CLIP text encoder, which processes a text description of the image (e.g., ‘A bird’), generating a similarity matrix. Alpha-CLIP leverages region-range masking to improve performance by directing attention to specific regions within the image.
read the caption
Figure 7: Alpha-CLIP

🔼 This figure shows a visual comparison of super-resolution results on images from the ACDC dataset (rain, night, and snow scenes) using the proposed IODA method and a baseline method. The source domain data for training was the GTA dataset (daytime scenes). The figure demonstrates that IODA significantly improves the visual quality of super-resolution images, especially in challenging conditions like rain, night, and snow, where the baseline method struggles to produce clear results.
read the caption
Figure 8: Visual comparisons.The source domain dataset is the GTA [30] daytime scene dataset, and the target domain dataset includes various scene branches from the ACDC [32] dataset, such as rain, night, and snow. The network architecture used is the SAFMN [26] network.
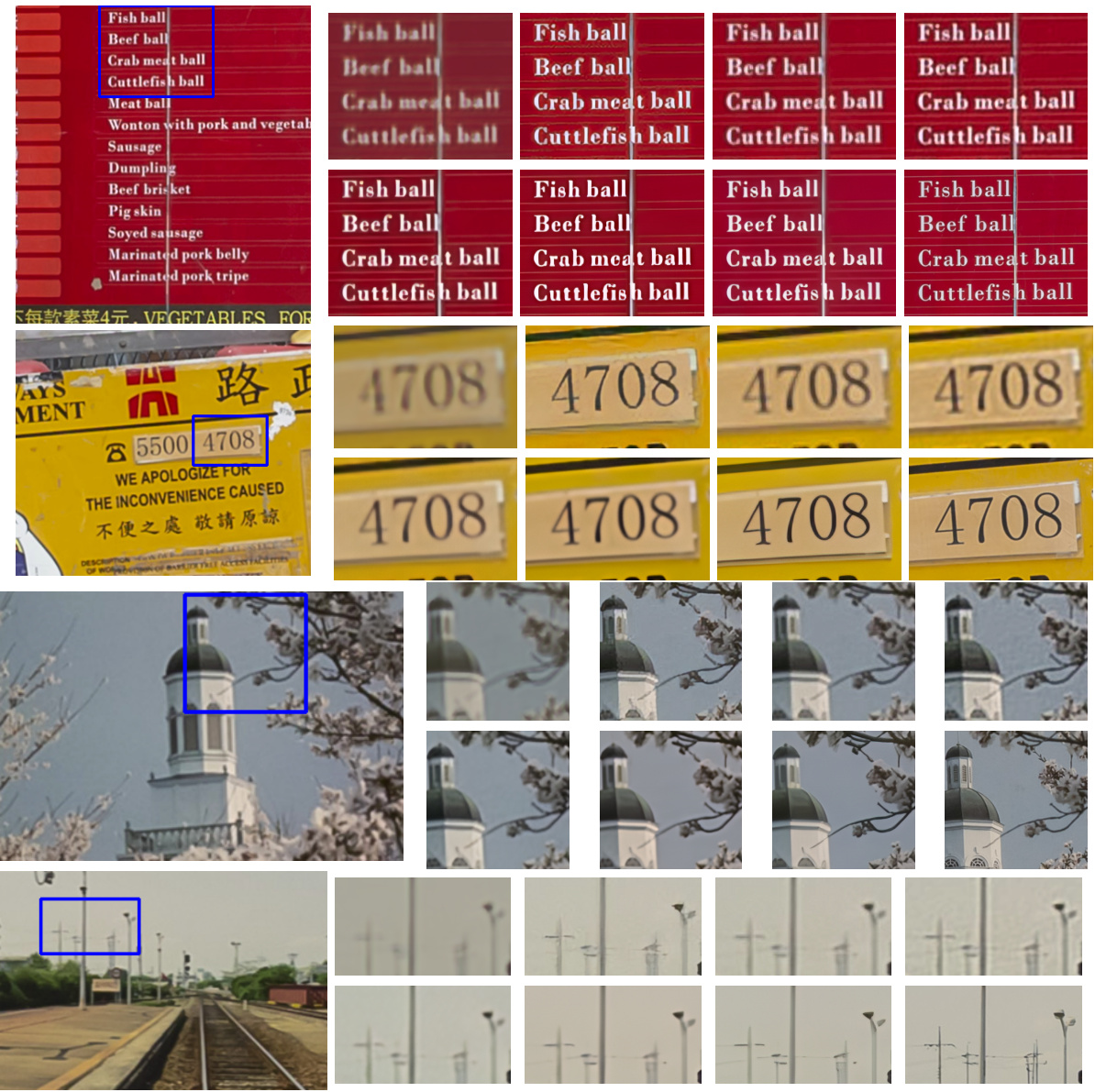
🔼 This figure shows the visual comparison of different super-resolution methods on a low-resolution (LR) image. The first row contains the results of four existing methods (DADA, DASR, ZSSR, SRTTA), and the second row shows the results of three methods in the proposed work (SAFMN+IODA, SRFormer+IODA, HAT+IODA) along with the ground truth (GT) image. This aims to showcase the visual improvement achieved by the proposed IODA method.
read the caption
Figure 9: The large image on the left is the LR image, and the sub-images on the right are DADA [56], DASR [15], ZSSR [34], SRTTA [48] (first row), SAFMN [26] +IODA, SRFormer [25] +IODA, HAT [24] +IODA, and GT images (second row). Please zoom-in on screen.
More on tables
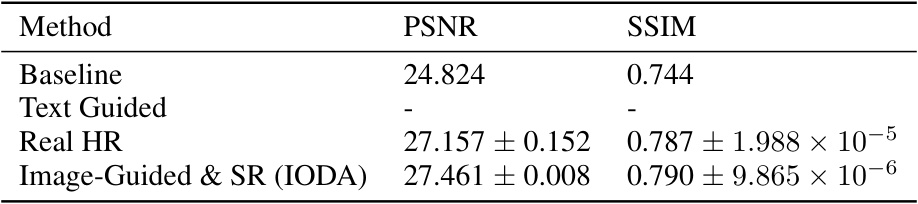
🔼 This table presents ablation study results on image-guided domain adaptation for super-resolution (SR). It compares the performance of different methods on the RealSR_Canon dataset using the SAFMN network architecture. The baseline represents the performance of the network pre-trained only on the source domain (DF2K). The table shows that using real high-resolution (HR) images during adaptation slightly improves performance, whereas text-guided adaptation fails to improve performance at all. The proposed Image-Guided & SR method provides the best performance among those studied.
read the caption
Table 2: Ablation experiments on image-guided domain adaptation, using the DF2K [1] dataset as the source domain dataset and RealSR_Canon [2] as the target domain dataset, with the SAFMN network architecture [26]. The performance of the pre-trained network (pre-trained on the source domain) on the target domain is represented as the baseline. - Indicates that the corresponding domain adaptive method is ineffective for SR task.
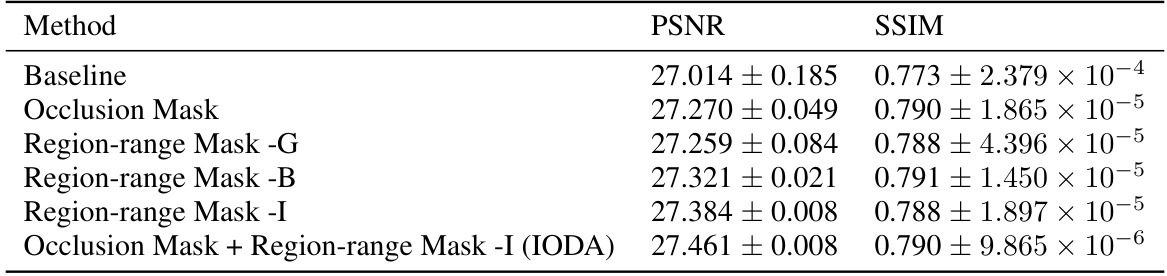
🔼 This table presents ablation study results on different diversity strategies used in the IODA method. It shows the PSNR and SSIM values achieved using various approaches: a baseline without any diversity strategy, using only occlusion masks, using region-range masks with different generation methods (grid, box, instance), and a combination of occlusion and instance-based region-range masks (IODA). The results demonstrate the effectiveness of the instance-guided target domain distribution expansion strategy in improving the performance of one-shot domain adaptation.
read the caption
Table 3: Ablation experiments on diversity strategies, using the DF2K [1] dataset as the source domain dataset and RealSR_Canon [2] as the target domain dataset, with the SAFMN network architecture [26]. The baseline refers to the domain adaptation performance after incorporating image-guided domain adaptation without any diversity enhancement.
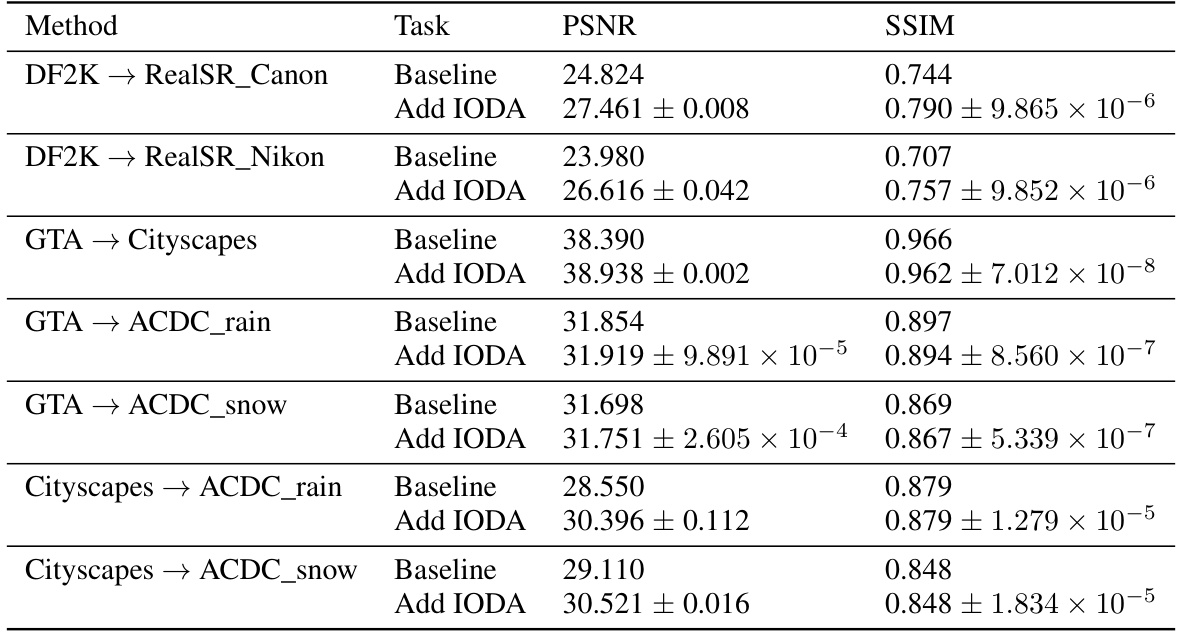
🔼 This table presents the results of experiments evaluating the robustness of the IODA method across various source and target domain datasets. The baseline represents the performance of the pre-trained SAFMN network without domain adaptation, and ‘Add IODA’ shows the performance after applying the IODA method. The results are shown in terms of PSNR and SSIM metrics. The table demonstrates how well IODA generalizes across different datasets.
read the caption
Table 4: Robustness experiments on different source and target domain datasets with the pre-trained network SAFMN [26]. → signifies the domain adaptation from the source domain to the target domain.
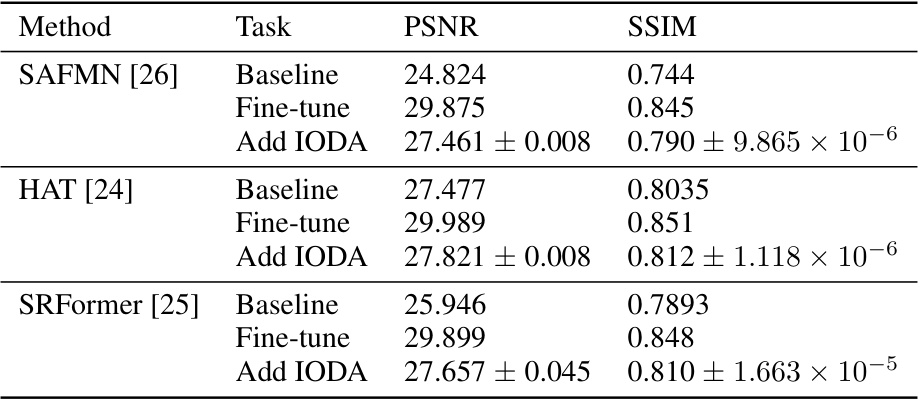
🔼 This table shows the performance of three different super-resolution (SR) networks (SAFMN, HAT, and SRFormer) on the RealSR_Canon dataset. It compares the baseline performance (using only pre-trained weights from the DF2K dataset), the performance after fine-tuning on the full RealSR_Canon dataset, and the performance after applying the proposed IODA method. The results demonstrate the robustness of IODA across different network architectures.
read the caption
Table 5: Robustness experiments on different networks architectures, with the source domain dataset: DF2K and target domain dataset: RealSR_Canon. The performance of the pre-trained network (pre-trained on the source domain) on the target domain is represented as the baseline. Fine-tune refers to the network utilizing all samples from the target domain HRTarget to fine-tune the pre-trained weights from the souce domain (Same as the original papers).
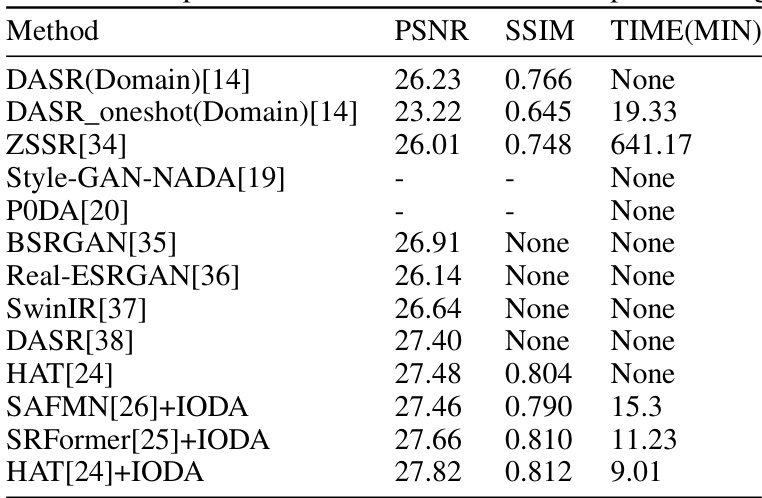
🔼 This table compares the performance of IODA with other state-of-the-art super-resolution (SR) methods on the RealSR_Canon dataset. It shows the PSNR and SSIM values achieved by each method, as well as the training time. The results demonstrate that IODA achieves competitive performance while requiring significantly less training time compared to many existing methods.
read the caption
Table 6: Performance comparison on the RealSR_Canon [2] real-world dataset. - Indicates that the corresponding domain adaptive method is ineffective for SR task. None indicates that the results are temporarily unavailable. Time represents the duration of domain adaptive training.
Full paper#