↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Person re-identification (ReID) aims to match individuals across different camera views. Existing pre-training methods primarily focus on single images or tracklets within a single video, neglecting the valuable information contained in cross-video comparisons of the same person. This limitation hinders the development of highly accurate and robust ReID systems.
The researchers address this by proposing the Cross-video Identity-cOrrelating pre-training (CION) framework. CION models cross-video identity correlation as a multi-level denoising process, enhancing both intra-identity consistency and inter-identity discrimination. This improved pre-training significantly boosts the performance of various ReID models, even with limited training data. Furthermore, they provide ReIDZoo, a publicly available model zoo, promoting reproducibility and facilitating broader research in this field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in person re-identification. It introduces CION, a novel pre-training framework that significantly improves model performance using cross-video identity correlation, surpassing state-of-the-art methods. The open-sourced model zoo (ReIDZoo) further enhances reproducibility and accessibility. This work opens new avenues for large-scale pre-training techniques and model-agnostic research in the field.
Visual Insights#
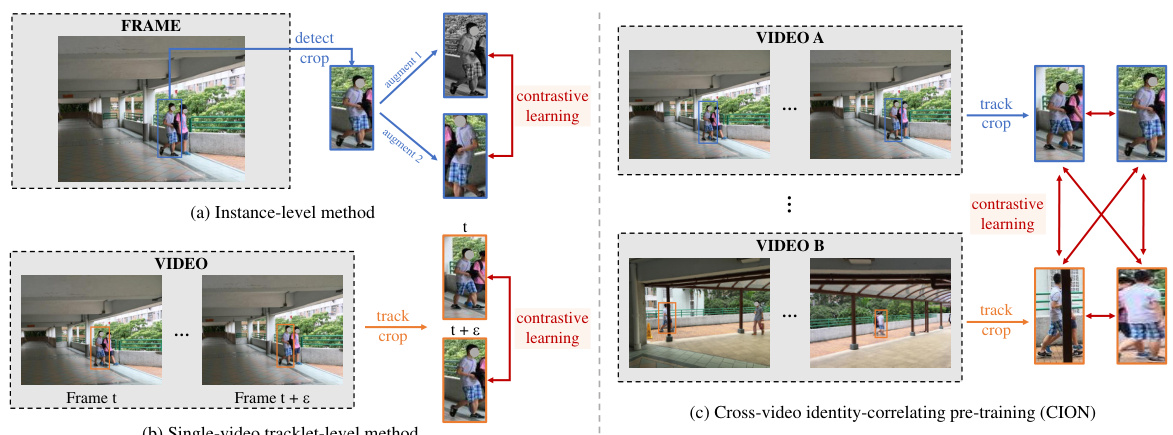
This figure compares three different pre-training methods for person re-identification: instance-level, single-video tracklet-level, and the proposed cross-video identity-correlating pre-training (CION). The instance-level method only considers augmentations of a single image. The single-video tracklet-level method considers temporal information within a single video but ignores cross-video identity consistency. In contrast, CION explicitly correlates images of the same person across different videos to learn identity-invariance, resulting in better representation learning.
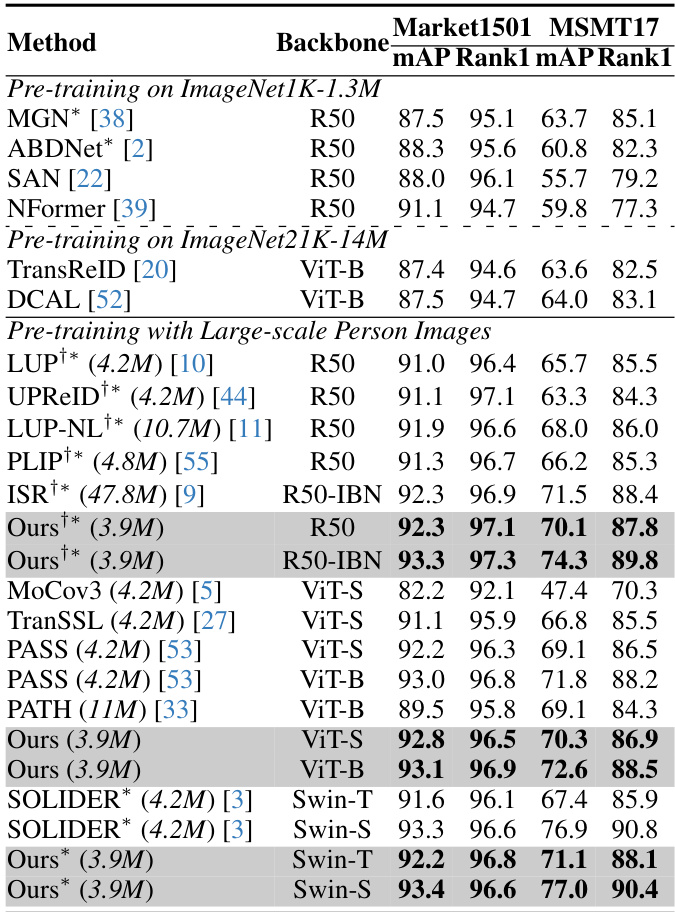
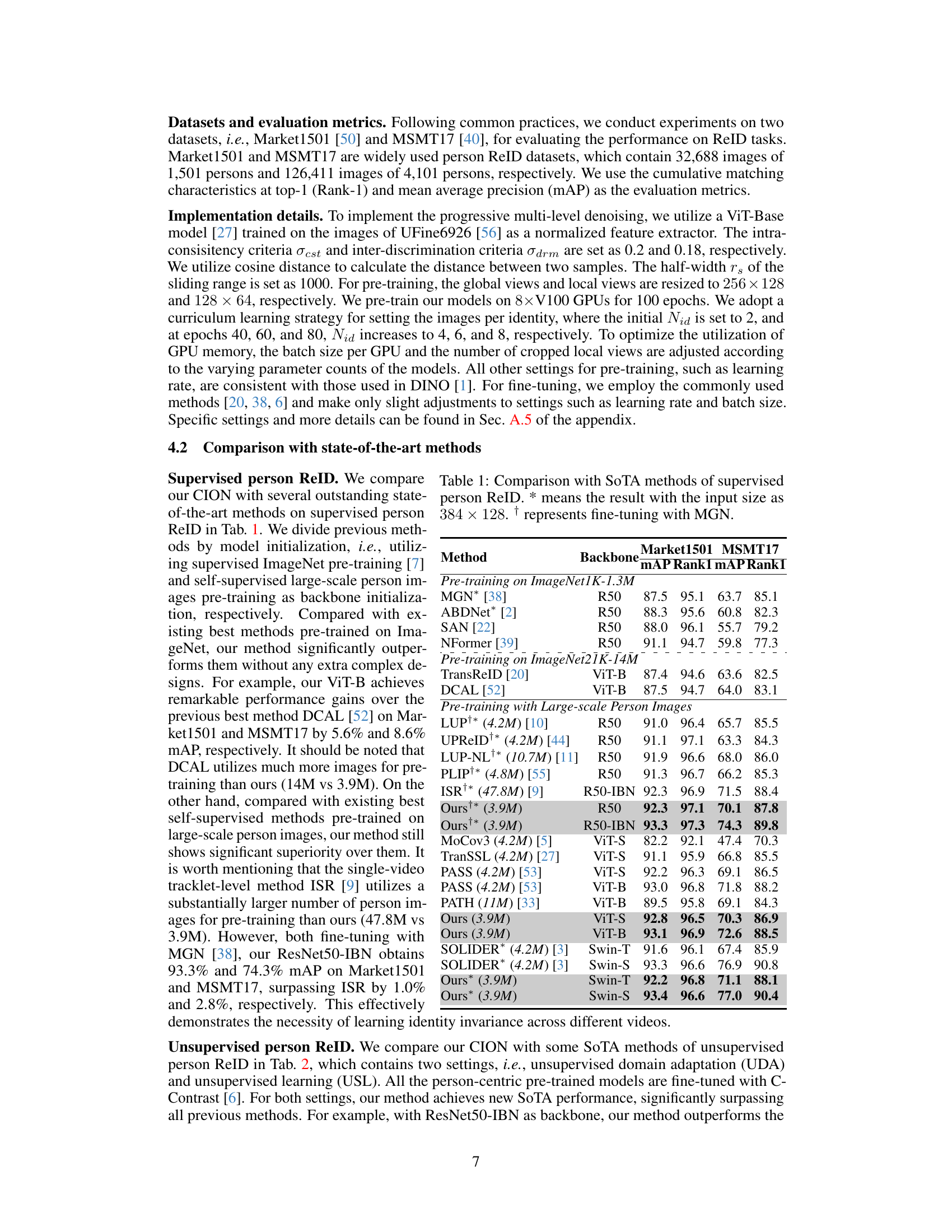
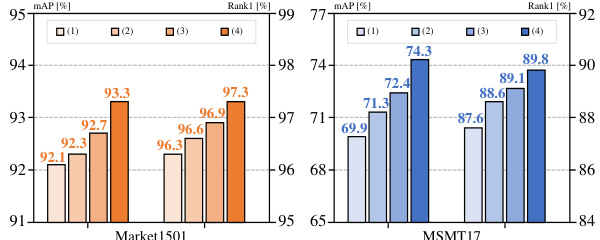
This table compares the proposed CION method with other state-of-the-art (SoTA) methods on supervised person re-identification (ReID) tasks. It shows the mAP and Rank-1 accuracy on Market1501 and MSMT17 datasets. The methods are categorized by their backbone initialization approach (ImageNet pre-training or self-supervised large-scale person image pre-training). The table highlights that CION outperforms other methods, especially those using the same ResNet50-IBN backbone, achieving higher accuracy even with fewer training samples. The asterisk (*) indicates results with a different input image size, and the dagger (†) indicates fine-tuning with the MGN method.
In-depth insights#
Cross-Video ID Correlation#
Cross-video identity correlation tackles a critical challenge in person re-identification by considering the identity consistency and discrimination across different video segments. The core idea is to correlate images of the same person from multiple videos, thus going beyond instance-level or single-video tracklet comparisons. This approach directly addresses the limitation of previous methods that neglect the identity invariance across videos. By explicitly modeling the identity correlation as a multi-level denoising problem, the method aims to refine the representation learning process, achieving improved accuracy and robustness. This cross-video approach significantly enhances intra-identity consistency and inter-identity discrimination, which is crucial for reliable person re-identification. The effectiveness is empirically validated through substantial improvements in performance metrics on standard benchmarks.
Progressive Multi-level Denoising#
The proposed “Progressive Multi-level Denoising” strategy is a key innovation for enhancing identity correlation in person re-identification pre-training. It tackles the inherent noise in initially extracted person tracklets from videos, stemming from inaccurate tracking and the omission of cross-video identity consistency. The method proceeds in three progressive levels: Single-tracklet Denoising refines individual tracklets by iteratively removing outliers based on intra-identity consistency. Short-range Single-video Denoising further improves identity correlation within a video by merging similar tracklets and reallocating misidentified samples. Finally, Long-range Cross-video Denoising leverages a ‘Sliding Range’ and ‘Linking Relation’ mechanism to efficiently correlate identity information across multiple videos, effectively addressing the computational challenges of processing ultra-long video sequences. This multi-level approach is crucial for achieving superior identity invariance, ultimately enhancing the quality of person re-identification models. The progressive nature allows for increasingly robust identity correlation mining by addressing noise at different scales and granularities.
Identity-Guided Self-Distillation#
The proposed ‘Identity-Guided Self-Distillation’ method is a crucial component of the Cross-video Identity-cOrrelating pre-traiNing (CION) framework. It leverages the identity correlation established in the preceding multi-level denoising stages to improve the model’s learning of identity-invariant features. Unlike traditional self-distillation, which typically focuses on general image representation learning, this method explicitly incorporates identity information. This is achieved by performing contrastive learning on augmented views of images belonging to the same identity, thereby explicitly enforcing intra-identity consistency. The use of a teacher-student network paradigm allows the student network to learn from a more robust teacher, leading to improved generalization. The method is model-agnostic, meaning it can be readily applied to various network architectures. This adaptability, along with its superior performance using fewer training samples, highlights its potential for broader applications within the field of person re-identification.
CION’s Superiority#
The paper highlights CION’s superiority through extensive experiments demonstrating significantly improved performance with fewer training samples. CION’s cross-video identity correlating approach outperforms instance-level and single-video tracklet-level methods by explicitly modeling identity invariance across different videos. This leads to superior representation learning, as evidenced by higher mAP scores on benchmark datasets such as Market1501 and MSMT17. The model-agnostic nature of CION is further validated by its successful application to diverse model architectures, showcased in the ReIDZoo. These results collectively establish CION as a leading pre-training framework for person re-identification, offering both efficiency and effectiveness. The paper’s contribution extends to the creation of a publicly available model zoo, furthering research and applications in this field. CION’s superior performance, particularly with limited data, signifies a crucial advancement for practical person re-identification tasks.
ReIDZoo Model Zoo#
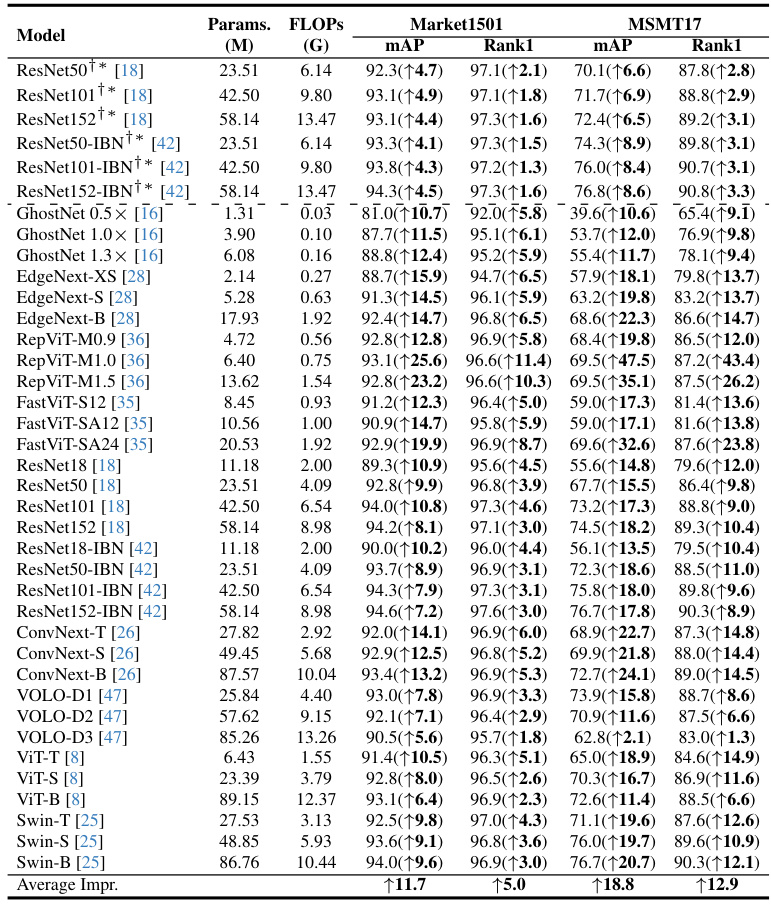
The proposed ReIDZoo Model Zoo represents a significant contribution to the field of person re-identification (ReID). By offering a collection of 32 pre-trained models spanning diverse architectures (GhostNet, ConvNext, RepViT, etc.), ReIDZoo democratizes access to high-performing ReID models, removing a significant barrier to entry for researchers with limited computational resources. The zoo’s model-agnostic nature showcases the generality and effectiveness of the underlying Cross-video Identity-cOrrelating pre-training (CION) framework, highlighting CION’s ability to improve performance across different model backbones. This readily available resource accelerates research progress, enabling quicker exploration of novel ReID techniques and facilitating broader adoption of ReID technology in various applications. The comprehensive nature of ReIDZoo, including models with varying parameters and structures, makes it a powerful tool for both academic research and practical deployment, fostering innovation and wider accessibility within the ReID community.
More visual insights#
More on figures

This figure illustrates the Sliding Range and Linking Relation concepts used in the CION framework for cross-video identity correlation. A long video sequence is conceptually divided into smaller segments (tracklets) represented by the boxes. The Sliding Range (blue dashed lines) moves across the entire video, considering a window of tracklets at each position. Inside the Sliding Range, the algorithm identifies linking relations (green dashed lines) between tracklets that likely correspond to the same person across different segments, thus correlating images of the same person across different videos.

This figure illustrates the identity-guided self-distillation process used in the CION framework. It shows how a student network learns to match the output probability distribution of a teacher network by minimizing the cross-entropy between them. The key difference from existing self-distillation methods is the introduction of identity information; contrastive learning is performed on augmented views from images of the same person. The figure highlights the use of a teacher network (fθt), a student network (fθs), and different random transformations (Tt and Ts) applied to the input images.
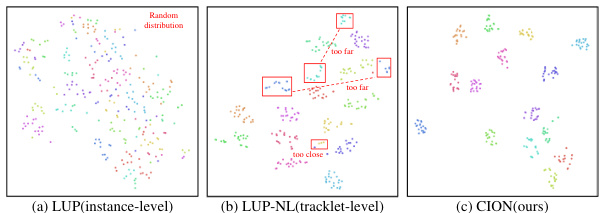
This figure compares three different person re-identification pre-training methods: instance-level, single-video tracklet-level, and the proposed cross-video identity-correlating pre-training (CION). It highlights the limitations of the previous methods, which fail to fully capture the identity invariance across different videos. CION is shown to address this issue by correlating images of the same person from multiple videos, enabling better representation learning.
This figure compares three different person re-identification pre-training methods: instance-level, single-video tracklet-level, and the proposed cross-video identity-correlating pre-training (CION). The instance-level method only considers variations within a single image, neglecting cross-image consistency for the same person. The single-video tracklet-level method considers consistency within a single video but ignores cross-video consistency. CION, in contrast, explicitly focuses on learning identity-invariance by correlating images of the same person across different videos.

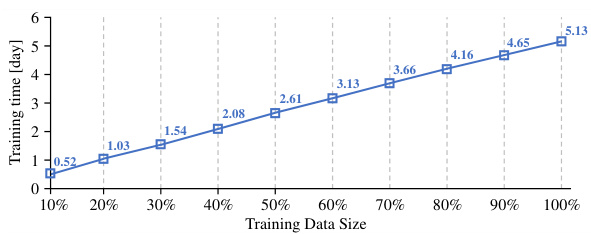
This figure shows the scalability of the CION model to large-scale training data. The x-axis represents the percentage of the training data used (from 10% to 100%), while the y-axis shows the mAP (mean Average Precision) achieved on the Market1501 and MSMT17 datasets. Both datasets show a consistent increase in mAP as the training data size increases, indicating that the model benefits from more data and that there is potential for even better results with even more training data. This demonstrates the scalability and robustness of the CION pre-training method.
This figure compares three different pre-training methods for person re-identification: instance-level, single-video tracklet-level, and the proposed cross-video identity-correlating pre-training (CION). The instance-level method only considers augmentations of single images, ignoring cross-image consistency for the same person. The single-video tracklet method compares images within a single video tracklet but ignores the identity invariance across different videos. In contrast, CION explicitly models the identity correlation across different videos to learn better identity-invariant representations.

This figure compares three different pre-training methods for person re-identification: instance-level, single-video tracklet-level, and the proposed cross-video identity-correlating (CION) method. The instance-level method only considers variations within a single image, neglecting cross-image consistency for the same person. The single-video tracklet method considers consistency within a video but ignores cross-video identity invariance. The CION method, however, explicitly correlates images of the same person across different videos to learn identity-invariance, leading to improved representation learning.
More on tables
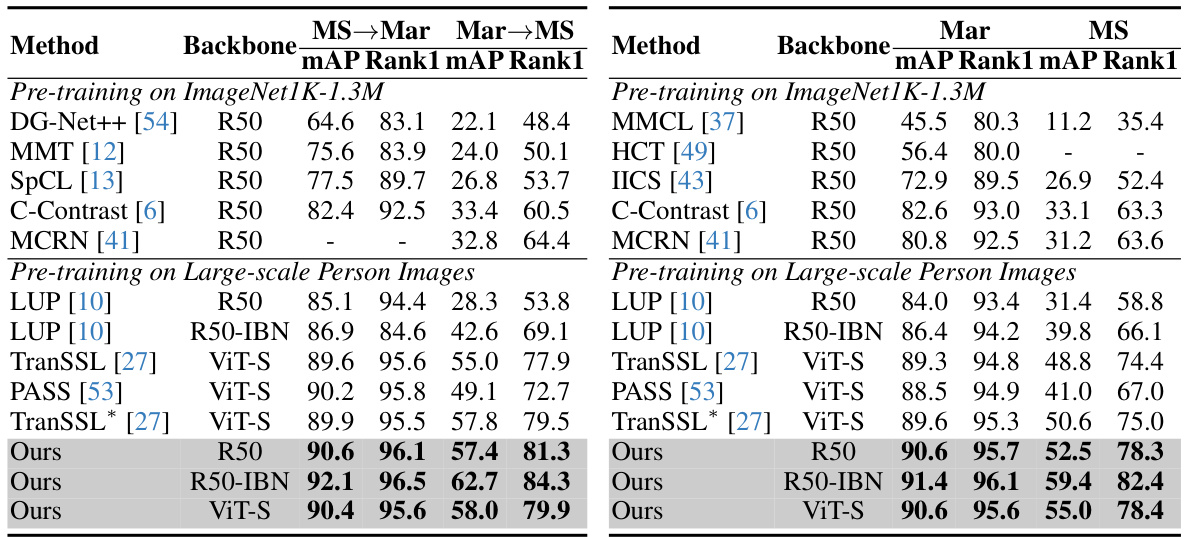
This table compares the performance of the proposed CION method with other state-of-the-art (SoTA) methods on supervised person re-identification tasks. It is divided into methods using ImageNet pre-training and those using self-supervised large-scale person image pre-training. The results are presented in terms of mean Average Precision (mAP) and Rank-1 accuracy on two benchmark datasets, Market1501 and MSMT17. The table highlights CION’s superior performance, especially when using fewer training samples, showcasing its efficiency and effectiveness.
This table compares the proposed CION model’s performance with other state-of-the-art (SOTA) methods on supervised person re-identification (ReID) tasks using two benchmark datasets, Market1501 and MSMT17. The models are categorized by their initialization method: using supervised ImageNet pre-training or self-supervised large-scale person image pre-training. The table shows the mAP (mean Average Precision) and Rank-1 accuracy for each method on each dataset. The asterisk (*) indicates results obtained with an input image size of 384x128, and the dagger (†) indicates that the results were obtained after fine-tuning with the MGN model. This comparison highlights CION’s superior performance, especially when using fewer training samples.
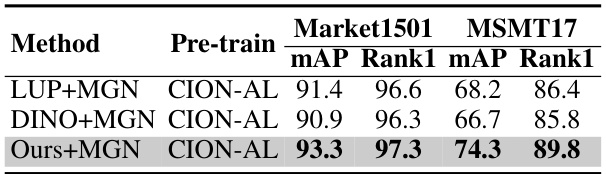
This table compares the performance of the proposed CION method against two other pre-training methods: LUP+MGN and DINO+MGN. All models were fine-tuned using MGN on the Market1501 and MSMT17 datasets. The results show that CION achieves significantly better mAP and Rank-1 accuracy, demonstrating the superiority of the identity-level correlating approach.

This table compares the proposed CION method with other state-of-the-art (SoTA) methods on supervised person re-identification. It breaks down the results by different model backbones (e.g., ResNet50, ViT-B) and pre-training methods (ImageNet 1K/21K, large-scale person images). The table highlights the superior performance of CION, particularly when using fewer training samples, as indicated by the mAP and Rank-1 metrics on the Market1501 and MSMT17 datasets.
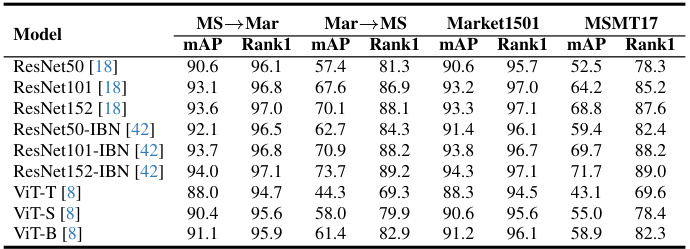
This table compares the proposed CION method with state-of-the-art (SoTA) methods on supervised person re-identification. It shows the mean average precision (mAP) and Rank-1 accuracy on Market1501 and MSMT17 datasets. The methods are categorized by their backbone initialization: ImageNet pre-training and self-supervised large-scale person images pre-training. The table highlights that CION achieves superior performance, especially when using fewer training samples, demonstrating the effectiveness of cross-video identity-correlating pre-training.
Full paper#