TL;DR#
Large language and vision models are often fine-tuned using Low-Rank Adaptation (LoRA) for efficiency. However, LoRA suffers from issues like data copying and distribution collapse, especially when dealing with smaller datasets and higher adapter ranks. This leads to a lack of diversity and reduced quality in generated images.
The paper introduces FouRA, a new low-rank adaptation method that tackles these challenges. FouRA operates in the Fourier domain, learning projections in this space to generate richer representations. It also employs an adaptive rank selection strategy, dynamically adjusting the rank based on input data and diffusion time steps. This adaptive approach prevents both underfitting (at lower ranks) and overfitting (at higher ranks), resulting in improved image quality and diversity. Experiments demonstrate that FouRA significantly outperforms LoRA, solving the data copying and distribution collapse problems while yielding superior image generation results. The method’s effectiveness extends beyond vision tasks and shows promise for language models as well.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of Low-Rank Adaptation (LoRA), a popular technique for efficiently fine-tuning large models. By introducing FouRA, which operates in the frequency domain and incorporates adaptive rank selection, the research offers a significant improvement in the quality and diversity of generated images in diffusion models and enhances generalization capabilities. This work opens new avenues for research in parameter-efficient fine-tuning methods and has significant implications for various applications that utilize large language and vision models.
Visual Insights#

🔼 This figure shows the results of using LoRA and FouRA to fine-tune a text-to-image diffusion model. The top row shows images generated with LoRA, which exhibit a lack of diversity and a tendency to repeat the same images. The bottom row shows images generated with FouRA, which are more diverse and show a greater variety of styles.
read the caption
Figure 1: Distribution collapse with LoRA. Visual results generated by the Realistic Vision 3.0 model trained with LoRA and FouRA, for 'Blue Fire' and 'Origami' style adapters across four seeds. While LoRA images suffer from distribution collapse and lack diversity, we observe diverse images generated by FouRA.

🔼 This table presents the quantitative results of LoRA and FouRA on text-to-image style transfer tasks. It shows the LPIPS diversity and HPSv2 scores for both methods across different adapter strengths (α = 1, 0.8, 0.6) and for two base models (Stable Diffusion-v1.5 and Realistic Vision-v3.0). The results are averages over 30 random seeds and demonstrate that FouRA generally outperforms LoRA in terms of both image diversity and perceived quality.
read the caption
Table 2: Evaluation of LoRAs on Text-to-Image tasks. Adapters are rank 64. Results are averaged over 30 seeds.
In-depth insights#
FouRA: Core Idea#
FouRA’s core idea centers on adapting large language models efficiently by leveraging the Fourier transform. Unlike Low-Rank Adaptation (LoRA), which performs low-rank updates in the feature space, FouRA operates in the frequency domain. This offers advantages in terms of compact representation, as the Fourier transform decorrelates features, and improved generalization by reducing sensitivity to the rank parameter. The adaptive rank selection mechanism, controlled by a learned mask in the Fourier domain, ensures that the model dynamically adapts its rank depending on the input, mitigating both underfitting (with low rank) and overfitting (with high rank). Crucially, this allows for a more flexible and robust approach to multi-adapter merging and enhances generalization performance across diverse tasks, showing clear benefits over LoRA.
Freq. Domain Adapt.#
The heading ‘Freq. Domain Adapt.’ strongly suggests a research focus on adapting models within the frequency domain, rather than the typical time or spatial domains. This approach likely leverages the properties of Fourier transforms or similar techniques to modify model parameters. A key advantage might be improved generalization, as frequency representations often capture underlying patterns more efficiently and compactly than raw data. This could lead to more robust models, especially when training data is limited. The method likely involves transforming input data into the frequency domain, performing adaptation operations (e.g., low-rank updates), and then transforming back to the original domain. A potential challenge is the computational cost of these transformations, although efficient algorithms exist and might be utilized. The research likely evaluates the performance of frequency domain adaptation against traditional methods, demonstrating superior generalization, efficiency or both in specific applications.
Adaptive Rank Gating#
Adaptive rank gating, in the context of low-rank adaptation for large language models, is a crucial technique for enhancing model efficiency and performance. It addresses the limitations of fixed-rank adapters by dynamically adjusting the rank of the adapter during inference, allowing the model to adapt to varying levels of complexity in the input. This dynamic rank adjustment is particularly useful for tasks involving varying input lengths, or where the complexity of the task changes during inference, such as in diffusion models. A well-designed adaptive rank gating mechanism can significantly improve the performance of the model while reducing computational cost. The gating mechanism needs to balance between reducing computational cost and avoiding underfitting or overfitting. The effectiveness of adaptive rank gating is highly dependent on the choice of gating function and the strategy for selecting the optimal rank for a given input. Careful consideration of the trade-off between model efficiency, accuracy, and the overall complexity of the gating mechanism is necessary for achieving optimal performance. Future work in this area could focus on developing more sophisticated gating mechanisms that leverage advanced techniques from machine learning to further enhance the efficiency and effectiveness of low-rank adaptation.
Multi-adapter Fusion#
The concept of ‘Multi-adapter Fusion’ in the context of large language models (LLMs) and other deep learning models, such as diffusion models, involves combining multiple specialized adapters to enhance model capabilities. Each adapter is trained to specialize in a specific task or style, and the fusion process aims to seamlessly integrate these individual specializations into a unified, more robust model. This approach stands in contrast to simply training a single, monolithic model to handle all tasks, offering advantages in terms of efficiency and scalability. By combining smaller, specialized adapters, the fusion method reduces the overall computational burden and memory footprint required for training and inference. Furthermore, fusion techniques offer greater flexibility, allowing for easy adaptation and the integration of new adapters, which is crucial in the rapidly evolving landscape of AI models where new tasks and styles continually emerge. The effectiveness of multi-adapter fusion hinges on how well the individual adapters’ contributions are integrated, ideally without introducing conflicts or negative interference. Successful methods prioritize creating disentangled representations, where the various adapter styles are learned in orthogonal subspaces, facilitating straightforward combination without significant performance degradation.
Future Work#
The ‘Future Work’ section of a research paper on FouRA (Fourier Low Rank Adaptation) would ideally explore several promising avenues. Extending FouRA’s capabilities to other modalities beyond vision, such as audio or video, would demonstrate its broader applicability and potential. Investigating more sophisticated adaptive rank selection strategies and different gating mechanisms could significantly improve its flexibility and efficiency, leading to better generalization. Direct token masking in the frequency domain, hinted at in the paper, warrants further research to understand its impact on efficiency and model performance. Exploring how FouRA interacts with other parameter-efficient fine-tuning methods is also essential for identifying potential synergies and optimizing the overall training process. Finally, conducting extensive comparative studies against other state-of-the-art methods across diverse datasets and tasks would solidify FouRA’s position and uncover potential limitations or areas needing further refinement.
More visual insights#
More on figures
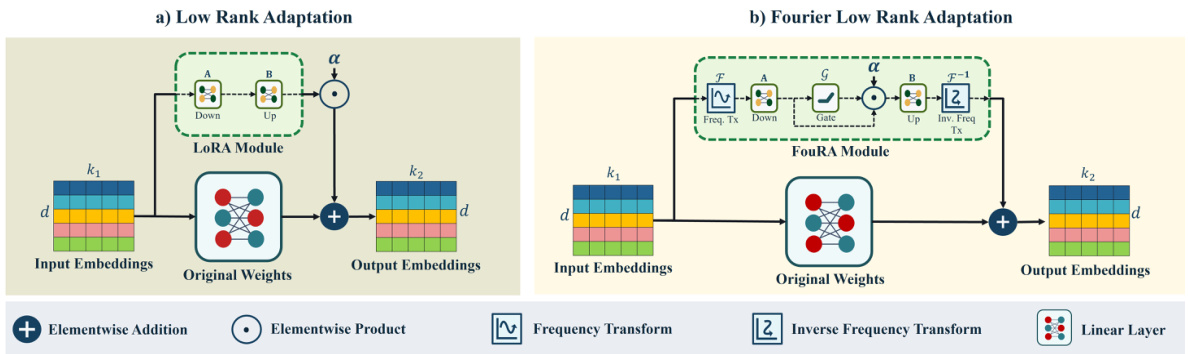
🔼 This figure compares the architecture of the Low Rank Adaptation (LoRA) module with the proposed Fourier Low Rank Adaptation (FouRA) module. LoRA performs low-rank matrix decomposition in the feature space, while FouRA performs this decomposition in the frequency domain using a Discrete Fourier Transform (DFT) or Discrete Cosine Transform (DCT). FouRA also incorporates an adaptive rank gating mechanism which dynamically adjusts the rank of the adapter based on the input, allowing for greater flexibility and preventing mode collapse. The figure clearly illustrates the addition of the frequency transform and inverse frequency transform steps before and after the core low-rank adaptation in FouRA.
read the caption
Figure 2: LoRA v/s FouRA. For FouRA, we transform feature maps to frequency domain, where we learn up and down adapter projections along-with our proposed adaptive rank gating module.
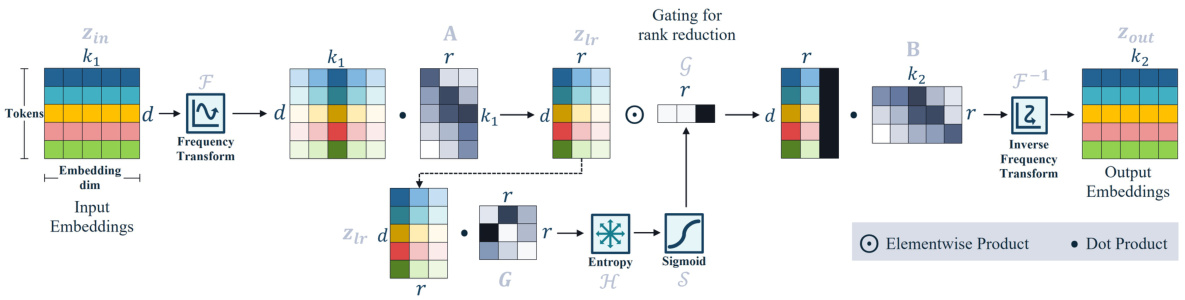
🔼 This figure compares the architectures of LoRA and FouRA. LoRA performs low-rank adaptation in the feature space, while FouRA performs this adaptation in the frequency domain. FouRA also incorporates an adaptive rank gating module that dynamically adjusts the rank of the adapter based on the input. The figure highlights the key differences in their approach.
read the caption
Figure 2: LoRA v/s FouRA. For FouRA, we transform feature maps to frequency domain, where we learn up and down adapter projections along-with our proposed adaptive rank gating module.

🔼 This figure compares the distribution of singular values for rank-r approximations of LoRA and FouRA adapters (without adaptive masking) for the last layer of a trained U-Net model. FouRA exhibits a more compact spread of singular values than LoRA. This suggests that using a low-rank approximation, FouRA will have lower accumulated error than LoRA.
read the caption
Figure 4: Singular value spread for FouRA v/s LoRA.

🔼 This figure displays the average effective rank of FouRA across different layers of the UNet (downsampling and upsampling blocks) at various resolutions and diffusion timesteps. Subfigure (a) and (b) show that the effective rank decreases with increasing resolution and timestep. This indicates that FouRA dynamically adapts the rank based on the input and progress of the diffusion process, suggesting efficiency. Subfigure (c) compares FouRA’s adaptive rank with the fixed rank of the SORA method, highlighting FouRA’s flexibility.
read the caption
Figure 5: Average Effective Rank of FouRA. Figure a. and b. shows plots for the average effective rank for various layers of the FouRA U-Net (Darker lines correspond to higher resolutions) and Figure c. compares the average effective rank of FouRA to SORA. FouRA's effective rank reduces with the feature resolution, and it also reduces as the diffusion process proceeds, owing to lesser changes required towards the end.

🔼 This figure compares the image generation results of FouRA and LoRA for two different prompts. The left-hand side shows a football, and the right-hand side shows a man. Both methods use the ‘Blue Fire’ and ‘Painting’ style adapters. As the adapter strength (α) increases, LoRA shows artifacts while FouRA maintains better visual quality.
read the caption
Figure 6: FouRA v/s LoRA: The prompt on the left is 'a football in a field' and on the right is 'man in a mythical forest'. While staying more faithful to the adapter style, FouRA outputs look aesthetically better than LoRA, which have obvious artifacts at high values of α. Additional results are in Appendix E.

🔼 This figure compares the results of multi-adapter fusion in LoRA and FouRA models for style transfer tasks. It shows example images generated using different prompts (bird, car, fox) and combinations of three styles (Paintings, Bluefire, and 3D). The highlighted merged images illustrate FouRA’s superior ability to preserve both styles compared to LoRA, which often loses one of the concepts or produces artifacts.
read the caption
Figure 7: Multi-Adapter Fusion in LoRA v/s FouRA. Sample images for style transfer on various prompts (e.g., bird, car, fox) for Paintings, Bluefire, 3D and Merged adapters. Observe the highlighted merged images. FouRA does a much better job in preserving both styles, compared to LoRA.

🔼 This figure shows the results of concept editing experiments using LoRA and FouRA. Two concepts, ‘Age’ and ‘Hair’, were tested. As the strength of the concept increases, the images generated by FouRA exhibit better disentanglement than LoRA. LoRA shows artifacts such as changing the gender of a person (Age concept) or distorting facial features (Hair concept) at higher strength values.
read the caption
Figure 8: LORA v/s FouRA. Age (Left) and Hair (right) concept slider examples where as the scale increases the effect of disentanglement in FouRA is more prominent. For larger scales the gender of the person changes in Age LoRA, and the structure of the face changes in Hair LoRA.

🔼 This figure compares different rank selection methods: LoRA, SORA, LoRA + Adaptive Mask, and FouRA. It shows the HPS-v2.1 scores plotted against different alpha (adapter strength) values. This illustrates the performance of each method across different adapter strength settings and highlights the effectiveness of FouRA’s inference-adaptive rank selection strategy for vision tasks, which dynamically varies the rank during inference, improving performance and generalization compared to fixed-rank methods.
read the caption
Figure 9: Comparison of different rank selection methods.

🔼 This figure compares the image generation results of FouRA and LoRA for two different prompts. It demonstrates that FouRA produces aesthetically pleasing images that are more faithful to the intended style, unlike LoRA, which shows noticeable artifacts at higher values of the adapter strength (α). The appendix contains additional results.
read the caption
Figure 6: FouRA v/s LoRA: The prompt on the left is 'a football in a field' and on the right is 'man in a mythical forest'. While staying more faithful to the adapter style, FouRA outputs look aesthetically better than LoRA, which have obvious artifacts at high values of α. Additional results are in Appendix E.
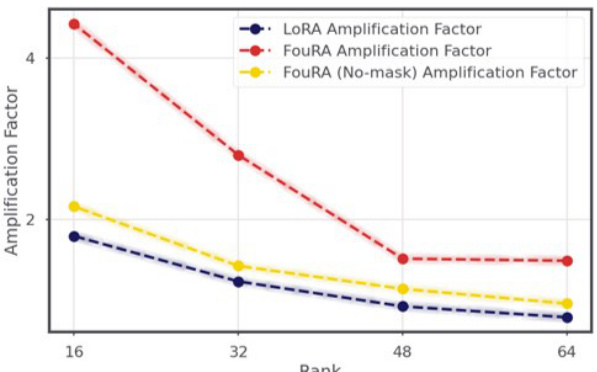
🔼 This figure shows the amplification factors for LoRA and FouRA at different ranks. The amplification factor measures how much the learned adapter subspaces emphasize certain directions in the original model’s weight space. Higher values suggest that the learned subspaces are more distinct from the original model. FouRA consistently shows higher amplification factors than LoRA, indicating that FouRA learns more decorrelated subspaces, improving generalization and reducing the risk of overfitting.
read the caption
Figure B.1: Amplification Factor of FouRA v/s LoRA: As the computed Amplification Factor referred to in B.3 is higher in case of FouRA, we justify the learnt representations are more de-correlated from the base weights.
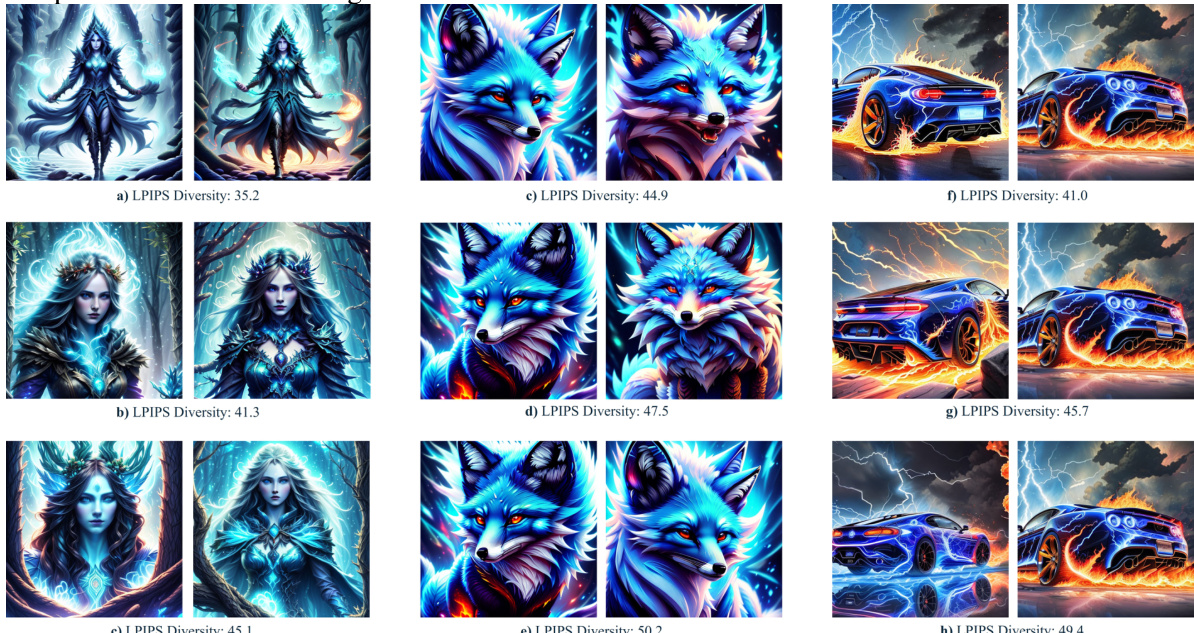
🔼 This figure shows a comparison of image generation results between LoRA and FouRA, two methods for fine-tuning large vision models. Four different images are shown for each method, using two different style adapters (‘Blue Fire’ and ‘Origami’) and four different random seeds. LoRA’s outputs show a lack of diversity and tend to be very similar across seeds, demonstrating a phenomenon known as ‘distribution collapse.’ In contrast, FouRA’s outputs are more varied and diverse, suggesting that it successfully addresses the distribution collapse problem.
read the caption
Figure 1: Distribution collapse with LoRA. Visual results generated by the Realistic Vision 3.0 model trained with LoRA and FouRA, for 'Blue Fire' and 'Origami' style adapters across four seeds. While LoRA images suffer from distribution collapse and lack diversity, we observe diverse images generated by FouRA.

🔼 This figure shows a comparison of image generation results using LoRA and FouRA, two different low-rank adaptation methods for fine-tuning large language models. Four different image prompts were used with two different styles (‘Blue Fire’ and ‘Origami’). The figure demonstrates that LoRA suffers from distribution collapse (lack of diversity in generated images, with multiple generations showing nearly identical results), while FouRA produces more diverse and visually appealing results.
read the caption
Figure 1: Distribution collapse with LoRA. Visual results generated by the Realistic Vision 3.0 model trained with LoRA and FouRA, for 'Blue Fire' and 'Origami' style adapters across four seeds. While LoRA images suffer from distribution collapse and lack diversity, we observe diverse images generated by FouRA.
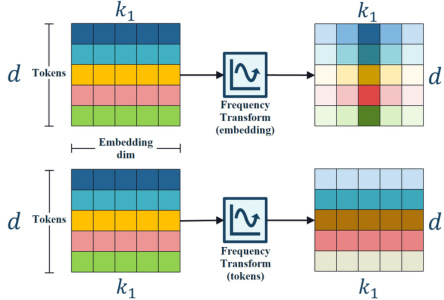
🔼 This figure compares the architecture of LoRA and FouRA. LoRA has a simple down-projection and up-projection in the feature space. FouRA, in contrast, performs these projections in the frequency domain. Additionally, FouRA incorporates an adaptive rank gating module that dynamically adjusts the rank of the adapter during inference. This gating allows FouRA to balance between overfitting and underfitting more effectively than LoRA.
read the caption
Figure 2: LoRA v/s FouRA. For FouRA, we transform feature maps to frequency domain, where we learn up and down adapter projections along-with our proposed adaptive rank gating module.
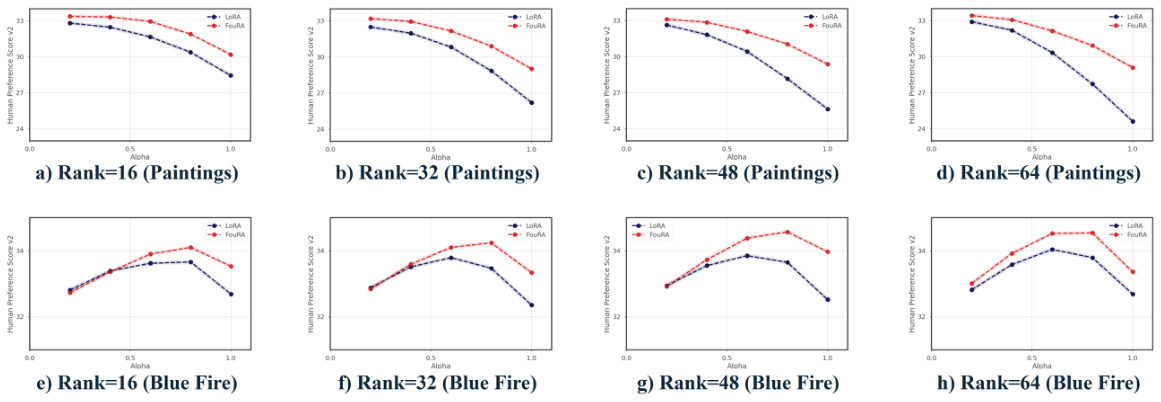
🔼 This figure compares the image generation results of FouRA and LoRA for two different prompts. It visually demonstrates FouRA’s improved aesthetic quality and its ability to remain faithful to the adapter style, even at high values of the adapter strength parameter (α), unlike LoRA, which shows noticeable artifacts at high α values. The appendix contains more detailed results.
read the caption
Figure 6: FouRA v/s LoRA: The prompt on the left is 'a football in a field' and on the right is 'man in a mythical forest'. While staying more faithful to the adapter style, FouRA outputs look aesthetically better than LoRA, which have obvious artifacts at high values of α. Additional results are in Appendix E.
🔼 This figure shows the average effective rank of FouRA across different layers of the U-Net for different resolutions. It demonstrates how the effective rank decreases as the resolution decreases and as the diffusion process progresses, implying that the model requires fewer parameters as it refines the image.
read the caption
Figure 5: Average Effective Rank of FouRA. Figure a. and b. shows plots for the average effective rank for various layers of the FouRA U-Net (Darker lines correspond to higher resolutions) and Figure c. compares the average effective rank of FouRA to SORA. FouRA's effective rank reduces with the feature resolution, and it also reduces as the diffusion process proceeds, owing to lesser changes required towards the end.

🔼 This figure shows the average effective rank of FouRA across different layers of the U-Net and across different resolutions for upsampling and downsampling blocks. It also compares the adaptive rank selection strategy of FouRA to the fixed rank selection strategy of SORA. The results show that FouRA’s effective rank decreases with increasing resolution and decreases as the diffusion process progresses, indicating improved efficiency in learning the data distribution during the diffusion process.
read the caption
Figure 5: Average Effective Rank of FouRA. Figure a. and b. shows plots for the average effective rank for various layers of the FouRA U-Net (Darker lines correspond to higher resolutions) and Figure c. compares the average effective rank of FouRA to SORA. FouRA's effective rank reduces with the feature resolution, and it also reduces as the diffusion process proceeds, owing to lesser changes required towards the end.

🔼 This figure compares the image generation results of FouRA and LoRA for two different prompts. The results show that FouRA produces aesthetically pleasing images that are more faithful to the specified adapter style, while LoRA’s images exhibit noticeable artifacts at higher values of the adapter strength parameter (α).
read the caption
Figure 6: FouRA v/s LoRA: The prompt on the left is 'a football in a field' and on the right is 'man in a mythical forest'. While staying more faithful to the adapter style, FouRA outputs look aesthetically better than LoRA, which have obvious artifacts at high values of α. Additional results are in Appendix E.

🔼 This figure compares the image generation results of FouRA and LoRA for two different prompts. It shows that FouRA generates images that are more faithful to the requested style and aesthetically pleasing, while LoRA’s images exhibit artifacts at higher adapter strength values (α).
read the caption
Figure 6: FouRA v/s LoRA: The prompt on the left is 'a football in a field' and on the right is 'man in a mythical forest'. While staying more faithful to the adapter style, FouRA outputs look aesthetically better than LoRA, which have obvious artifacts at high values of α. Additional results are in Appendix E.

🔼 This figure shows the results of using the FouRA adapter for age manipulation with concept sliders. The top row shows results for the prompt ‘Portrait of a doctor’, and the bottom row shows results for the prompt ‘Photo of an Hispanic man’. Each row shows images generated with increasing positive strength of the ‘Age’ slider, demonstrating the effect of age manipulation.
read the caption
Figure F.2: Age FouRA Slider, 'Portrait of a doctor' (top) and 'Photo of an Hispanic man' (bottom).

🔼 This figure shows the results of using FouRA’s age slider on two different images. The top row shows the results on a portrait of a doctor, while the bottom row shows the results on a photo of a Hispanic man. The images show how the age slider can be used to change the age of a person in an image, while keeping other attributes such as gender and race relatively consistent. The figure demonstrates the ability of FouRA to achieve a smooth transition between different ages, as well as its ability to maintain the overall quality and coherence of the image. This is in contrast to LoRA, which tends to introduce artifacts or distort the face when adjusting age.
read the caption
Figure F.2: Age FouRA Slider, 'Portrait of a doctor' (top) and 'Photo of an Hispanic man' (bottom).

🔼 This figure shows the results of using a ‘Curly Hair’ slider with varying strengths. The top row shows results using the LoRA model, while the bottom row shows results using the FouRA model. The images demonstrate how the level of ‘curliness’ in the hair increases with increasing adapter strength. The FouRA model shows less variation in other facial features compared to the LoRA model, which shows some changes in facial features along with the change in hair.
read the caption
Figure F.3: Hair Slider: We find that as the strength of the adapter increases the curls increase. In the top image we also see minor variations in the facial details of the person.

🔼 This figure compares the image generation results of LoRA and FouRA, two low-rank adaptation methods, when fine-tuning a text-to-image diffusion model. Four different image prompts were used with two distinct style adapters (‘Blue Fire’ and ‘Origami’). Each combination was run with four different random seeds. The results demonstrate that LoRA suffers from a lack of diversity and a tendency to copy data from the training set (distribution collapse), especially when using higher-rank adapters. FouRA, on the other hand, produces diverse and high-quality images, effectively addressing LoRA’s limitations.
read the caption
Figure 1: Distribution collapse with LoRA. Visual results generated by the Realistic Vision 3.0 model trained with LoRA and FouRA, for 'Blue Fire' and 'Origami' style adapters across four seeds. While LoRA images suffer from distribution collapse and lack diversity, we observe diverse images generated by FouRA.

🔼 This figure shows the results of using concept sliders for age and hair editing using LoRA and FouRA. As the strength of the slider increases, LoRA produces increasingly distorted results, changing the gender or facial structure, while FouRA maintains a more realistic appearance with less artifact.
read the caption
Figure 8: LORA v/s FouRA. Age (Left) and Hair (right) concept slider examples where as the scale increases the effect of disentanglement in FouRA is more prominent. For larger scales the gender of the person changes in Age LoRA, and the structure of the face changes in Hair LoRA.

🔼 This figure shows the results of using FouRA for composite editing. Two sliders, ‘surprise’ and ‘age’, are used to modify a base image. The figure displays a grid of images showing how the combined effect of both sliders changes the image as their individual strengths vary from -6 to 6. The captions provide the prompt used for the surprised face.
read the caption
Figure F.5: Composite FouRA. Composite surprised, age slider. Here we show the combined adapter as the strengths of each adapter are jointly incremented in each step in the image. The adapter strengths are (-6 6) for left most image and (6,6) for the right most image. The positive prompt for surprised face prompt: 'looking surprised, wide eyes, open mouth'

🔼 This figure shows the results of using a composite adapter with two sliders: ‘Surprise’ and ‘Age’. The figure demonstrates how FouRA handles the combination of these two sliders at various strength levels, ranging from strongly negative to strongly positive. Each row represents a fixed ‘Surprise’ slider strength, while each column represents a fixed ‘Age’ slider strength. The figure highlights FouRA’s ability to smoothly transition between the different styles and maintain image quality even at high strength values.
read the caption
Figure F.5: Composite FouRA. Composite surprised, age slider. Here we show the combined adapter as the strengths of each adapter are jointly incremented in each step in the image. The adapter strengths are (-6 6) for left most image and (6,6) for the right most image. The positive prompt for surprised face prompt: 'looking surprised, wide eyes, open mouth'
More on tables
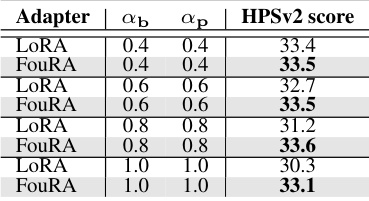
🔼 This table shows the results of merging two adapters (Blue Fire and Paintings) using both LoRA and FouRA methods. The HPSv2 score, a metric measuring image quality, alignment with the prompt, and aesthetic coherence, is presented for various combinations of adapter strengths (αb and αp). It demonstrates that FouRA consistently achieves higher HPSv2 scores than LoRA, indicating better image quality and style preservation even when merging multiple adapters.
read the caption
Table 1: Merging two adapters for Blue Fire and Paintings with strengths ab and ap.

🔼 This table presents the results of the Commonsense Reasoning benchmark evaluation. It compares the performance of LoRA and FouRA adapters, at different ranks (16 and 32), when fine-tuned on an Llama-3(8B) model. The results are shown for eight different commonsense reasoning tasks (BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC-e, ARC-c, and OBQA). The ‘Average’ column provides an overall performance score.
read the caption
Table 3: Performance on Commonsense Reasoning benchmarks: Evaluation on eight Commonsense Reasoning benchmarks with the Llama-3(8B) model.

🔼 This table presents the quantitative results of LoRA and FouRA models on text-to-image style transfer tasks. The results are averaged across 30 different random seeds, ensuring statistical robustness. The key metrics reported are LPIPS Diversity (higher is better, indicating more diverse generated images) and HPSv2 score (higher is better, indicating higher image quality and better alignment with the prompt/style). The table is broken down by the adapter strength (α) and dataset used. The comparison allows for a direct assessment of FouRA’s performance relative to the established LoRA baseline.
read the caption
Table 2: Evaluation of LoRAs on Text-to-Image tasks. Adapters are rank 64. Results are averaged over 30 seeds.

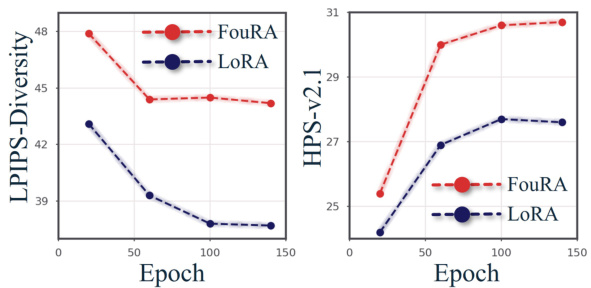
🔼 This table shows the ablation study results for different components of FouRA, comparing the performance with LoRA. It demonstrates the individual contribution of each component (Fourier transform, frozen dynamic mask, inference-adaptive mask) to the overall performance improvement in terms of HPS and LPIPS diversity metrics. The results highlight the importance of each component in achieving the final performance gain of FouRA over LoRA.
read the caption
Table 5: Individual gain with FouRA components. Gains from each individual component of FouRA. All results are with rank 64 and a = 0.8 on the paintings adapter.

🔼 This table compares the performance of LoRA and FouRA on text-to-image style transfer tasks using different base models (Stable Diffusion v1.5 and Realistic Vision 3.0) and adapter strengths (α = 1, 0.8, 0.6). The metrics used for comparison are LPIPS diversity (higher is better, indicating more diverse image generation) and HPSv2 score (higher is better, representing better image quality and prompt alignment). The results highlight FouRA’s superior performance in generating more diverse and higher-quality images across all settings.
read the caption
Table 2: Evaluation of LoRAs on Text-to-Image tasks. Adapters are rank 64. Results are averaged over 30 seeds.

🔼 This table presents a comparison of LoRA and FouRA performance on text-to-image style transfer tasks using the Stable Diffusion v1.5 and Realistic Vision 3.0 models. The results are averaged across 30 different random seeds. The table shows LPIPS Diversity and HPSv2 scores for different adapter strengths (α) and models (LoRA and FouRA) on two datasets (Paintings and Blue Fire). LPIPS diversity measures the diversity of generated images, while HPSv2 assesses image quality and alignment with the prompt. The rank of the adapter is fixed at 64.
read the caption
Table 2: Evaluation of LoRAs on Text-to-Image tasks. Adapters are rank 64. Results are averaged over 30 seeds.
🔼 This table presents the results of the Commonsense Reasoning benchmark experiments. It compares the performance of LoRA and FouRA adapters on eight different commonsense reasoning tasks using the Llama-3(8B) model. The table shows the number of trainable parameters for each model along with performance metrics on each task (BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC-e, ARC-c, OBQA), and a final average score across all tasks. This allows for a direct comparison of the effectiveness of LoRA and FouRA approaches for this specific task.
read the caption
Table 3: Performance on Commonsense Reasoning benchmarks: Evaluation on eight Commonsense Reasoning benchmarks with the Llama-3(8B) model.

🔼 This table presents the details of the GLUE benchmark datasets used in the paper’s experiments. It shows the number of training and validation samples for each of the six tasks (CoLA, SST-2, MRPC, STS-B, MNLI, and QNLI) and specifies the evaluation metric used for each task. The table provides essential information for understanding and reproducing the experimental results related to the GLUE benchmark evaluations.
read the caption
Table C.2: GLUE Benchmark

🔼 This table presents the results of experiments comparing LoRA and FouRA on text-to-image style transfer tasks. The experiments used adapters with a rank of 64, and results are averaged across 30 different random seeds to ensure reliability. The table shows LPIPS Diversity and HPSv2 scores for both LoRA and FouRA across different adapter strengths (α = 1, 0.8, 0.6) and for two different base models (Stable Diffusion-v1.5 and Realistic Vision-v3.0). It allows for a comparison of the performance of the two methods in terms of image diversity and overall image quality.
read the caption
Table 2: Evaluation of LoRAs on Text-to-Image tasks. Adapters are rank 64. Results are averaged over 30 seeds.

🔼 This table presents the performance of LoRA and FouRA on unseen classes from the Bluefire and Paintings datasets. The results are measured using the HPSv2 score (higher is better) at different adapter strengths (α = 1.0, 0.8, 0.6). The table shows that FouRA consistently outperforms LoRA on unseen data, demonstrating its superior generalization capability.
read the caption
Table E.1: Performance on unseen classes. Shows that on unseen classes FouRA generalizes better on unseen categories.

🔼 This table presents the quantitative results of LoRA and FouRA on text-to-image style transfer tasks. The results are averaged over 30 different random seeds and show the LPIPS diversity and HPSv2 scores for each model and adapter strength (α). LPIPS diversity measures the diversity of generated images while HPSv2 evaluates image quality and alignment with the prompt and style. The table shows that FouRA significantly outperforms LoRA on both metrics across different adapter strengths. All adapters used were rank 64.
read the caption
Table 2: Evaluation of LoRAs on Text-to-Image tasks. Adapters are rank 64. Results are averaged over 30 seeds.

🔼 This table presents the results of evaluating LoRA and FouRA on text-to-image style transfer tasks. The experiments used adapters with a rank of 64 and the results are averaged across 30 different random seeds. The table shows LPIPS Diversity and HPSv2 scores for different adapter strengths (α) across two datasets and two different base models. Higher LPIPS Diversity indicates greater diversity in generated images, while higher HPSv2 scores suggest better image quality and better alignment with the prompt and style.
read the caption
Table 2: Evaluation of LoRAs on Text-to-Image tasks. Adapters are rank 64. Results are averaged over 30 seeds.

🔼 This table presents the performance comparison between LoRA and FouRA for text-to-image style transfer tasks. It shows LPIPS Diversity and HPSv2 scores for both methods across different adapter strengths (α) and datasets (Paintings and Blue-Fire). Higher LPIPS Diversity indicates greater image diversity, while higher HPSv2 scores signify better image quality and alignment with the prompts and styles. The results are averaged over 30 random seeds to ensure statistical reliability.
read the caption
Table 2: Evaluation of LoRAs on Text-to-Image tasks. Adapters are rank 64. Results are averaged over 30 seeds.

🔼 This table presents the performance comparison of three different adapters (LoRA, SORA, and FouRA) on six GLUE benchmark tasks. The results are averaged across three random seeds, providing a measure of the models’ performance on each task. The table shows the accuracy for each model on the respective GLUE tasks.
read the caption
Table G.1: Evaluation of DeBERTa-V3 on the GLUE benchmarks, averaged over 3 seeds.
Full paper#



















