TL;DR#
Deep learning models usually require massive datasets for optimal performance. However, many real-world applications suffer from data scarcity, causing issues like overfitting and poor generalization. Existing methods that address this issue often rely on randomly selected parameter subsets and fixed masks, leading to suboptimal results. This research introduces Dynamic Neural Regeneration (DNR), a novel iterative training framework inspired by neurogenesis in the brain.
DNR employs a data-aware dynamic masking scheme to identify and remove redundant connections, dynamically adapting the mask throughout training. By selectively reinitializing weights, DNR increases the model’s learning capacity and enhances generalization. Experimental results on multiple datasets showcase DNR’s superior performance compared to existing methods, highlighting its robustness and potential for solving real-world problems with limited data.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to enhance the generalization of deep learning models trained on small datasets, a critical issue in many real-world applications. It offers a solution to the data scarcity problem, enabling better performance in domains with limited data collection. The introduced methods are robust, and the results demonstrate significant improvement over existing techniques, opening avenues for future research on adaptive and data-efficient learning paradigms.
Visual Insights#
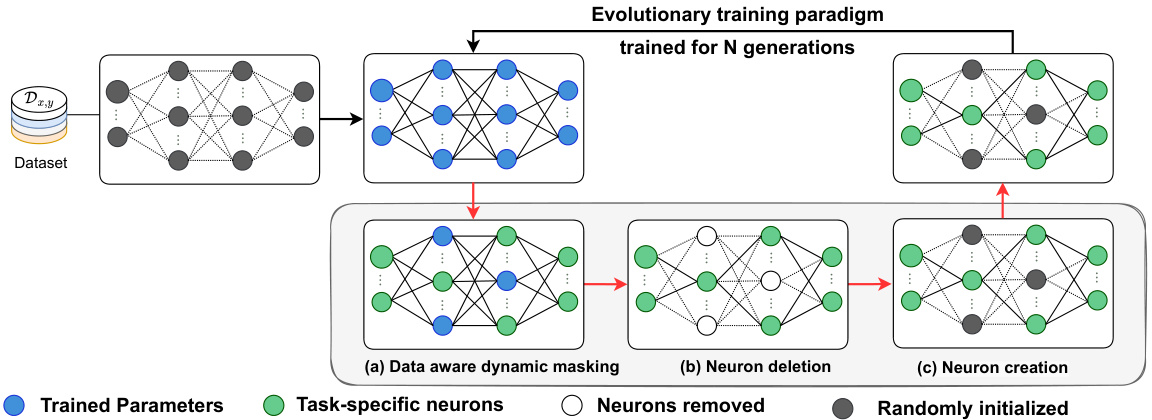
🔼 This figure illustrates the Dynamic Neural Regeneration (DNR) framework, which is an evolutionary training paradigm. The framework consists of three stages: (a) Data-aware dynamic masking, where redundant connections are removed based on their importance; (b) Neuron deletion, where the removed connections are eliminated; and (c) Neuron creation, where new connections are randomly initialized. This process iteratively refines the network, improving performance and generalization on small datasets.
read the caption
Figure 1: Schematics of proposed Dynamic Neural Regeneration (DNR) framework. Our framework utilizes a data-aware dynamic masking scheme to remove redundant connections and increase the network's capacity for further learning by incorporating random weight reinitialization. Thus, effectively improving the performance and generalization of deep neural networks on small datasets.

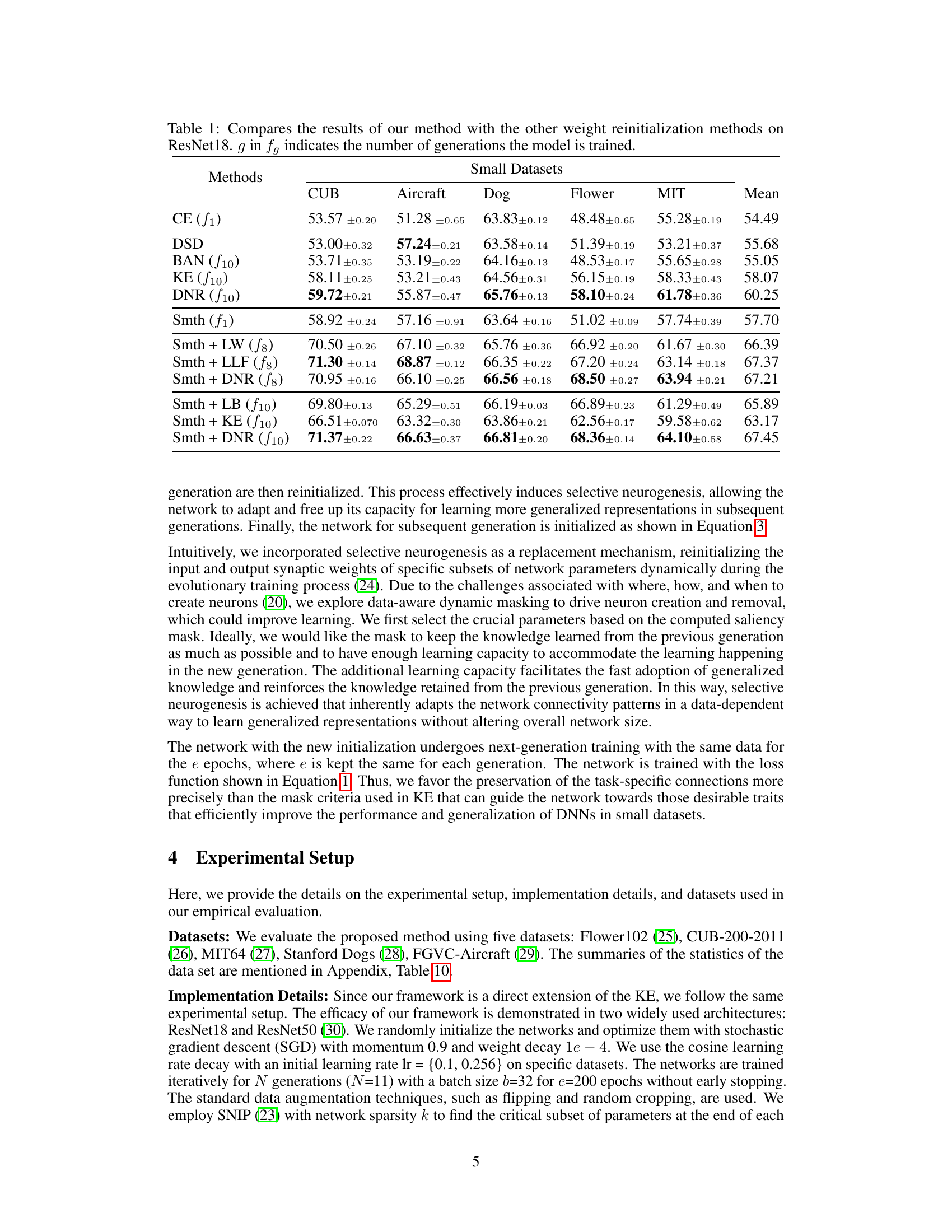
🔼 This table compares the performance of the proposed Dynamic Neural Regeneration (DNR) method against other weight reinitialization methods (DSD, BAN, KE) on the ResNet18 architecture, using five different small datasets (CUB, Aircraft, Dog, Flower, MIT). The results are presented as the mean accuracy ± standard deviation, and the number of generations (g) used for training is specified for each method. The table allows a comparison of DNR’s performance across different datasets and against various baseline methods.
read the caption
Table 1: Compares the results of our method with the other weight reinitialization methods on ResNet18. g in fg indicates the number of generations the model is trained.
In-depth insights#
Neurogenesis Inspired#
The concept of ‘Neurogenesis Inspired’ in the context of a research paper likely refers to the biological process of neurogenesis, where new neurons are generated in the brain, as a source of inspiration for developing novel machine learning techniques. The paper probably draws parallels between the brain’s ability to adapt and learn through neurogenesis and the potential to enhance the adaptability and generalization capabilities of artificial neural networks. This could involve exploring methods that mimic the dynamic growth and pruning of neural connections observed in neurogenesis, potentially leading to architectures that are more robust, efficient, and better at handling small datasets or non-stationary environments. The core idea revolves around dynamically adjusting the network’s architecture and parameters during training to better adapt to new data and improve generalization performance, mirroring the brain’s adaptive learning process. The paper likely presents a novel algorithm or training paradigm that incorporates these principles, demonstrating its advantages compared to existing methods. A key aspect would likely be showing how the method improves model performance or robustness in tasks where traditional neural networks struggle, suggesting the practical significance of the neurogenesis-inspired approach.
Dynamic Masking#
Dynamic masking, in the context of deep learning, represents a powerful technique for enhancing model adaptability and generalization, particularly valuable when training data is scarce. It involves creating a mask that selectively enables or disables network connections or parameters during training, thereby dynamically shaping the model’s architecture. Unlike static masking, which uses a pre-defined and unchanging mask throughout training, dynamic masking adapts the mask over time based on factors such as data characteristics or model performance. This adaptive nature allows the model to learn more effectively by focusing on relevant information and mitigating overfitting, leading to improved generalization on unseen data. Data-aware dynamic masking leverages insights from the data itself, directly informing the mask’s evolution. For example, a saliency-based approach might identify important connections based on their contribution to performance on a subset of training data. By selectively retaining crucial connections and reinitializing less important ones, dynamic masking improves model efficiency and learning capacity, preventing redundant computations while promoting generalization. However, implementing dynamic masking presents computational challenges, as it requires continuous reevaluation and adjustment of the mask, hence its effectiveness needs to be balanced against computational costs.
Small Data Focus#
The focus on small data is critical due to the limitations of traditional deep learning approaches that demand massive datasets. This research directly addresses this challenge by proposing novel methods to improve the generalization capabilities of deep neural networks when trained on limited data. The methodology is particularly relevant for domains where acquiring large labeled datasets is expensive, difficult, or ethically problematic (e.g., medical imaging). Data-aware dynamic masking emerges as a key innovation, enabling the model to selectively retain crucial information while discarding redundant connections. This iterative training paradigm, inspired by neurogenesis, shows promise in enhancing model robustness and mitigating overfitting in resource-constrained scenarios. The evolutionary approach employed enables adaptive learning and addresses the limitations of fixed masking strategies that hinder generalization.
Generalization Gains#
The concept of “Generalization Gains” in a deep learning research paper likely refers to improvements in a model’s ability to perform well on unseen data after employing specific training techniques. This is a crucial aspect of machine learning, as a model’s ultimate value lies in its capacity to generalize beyond the training data. The paper likely explores methods that enhance generalization, such as regularization, data augmentation, or architectural modifications. Analysis of “Generalization Gains” would involve comparing performance metrics (accuracy, precision, recall, F1-score, etc.) on a held-out test set versus the training set. Significant gains indicate the effectiveness of the approach in mitigating overfitting and improving the model’s robustness. The discussion might involve evaluating generalization under various conditions, such as different dataset sizes or noise levels, which would reveal the technique’s limitations and strengths. A key aspect of the analysis would be to attribute the generalization improvements to specific aspects of the proposed method, such as its handling of feature interactions, parameter sharing or weight decay mechanisms. The magnitude of the gains would then help gauge the approach’s practical value, especially in scenarios with limited data. Ultimately, understanding generalization is paramount for reliable and robust deep learning models.
Future Extensions#
The paper’s core contribution is a novel iterative training framework, Dynamic Neural Regeneration (DNR), designed to enhance deep learning generalization on small datasets. Future extensions could focus on several key aspects. First, exploring alternative dynamic masking strategies beyond the data-aware approach used in DNR would be valuable. This could involve incorporating biologically-inspired mechanisms more directly, or investigating other methods for identifying and prioritizing important connections within the neural network. Second, a thorough investigation into the optimal hyperparameter settings for DNR across a broader range of datasets and network architectures is warranted to establish its robustness and wider applicability. Further research should address computational efficiency, as iterative training methods can be computationally expensive. Exploring techniques to accelerate the training process, perhaps through parallel processing or optimized algorithm design, would significantly improve DNR’s practicality. Finally, extending DNR to other challenging scenarios such as semi-supervised learning, transfer learning, or continual learning, would showcase its versatility and potential to address a wider range of real-world problems. Integrating DNR with other techniques like neural architecture search could also lead to interesting new avenues for research and enhance its capabilities.
More visual insights#
More on figures
🔼 This figure illustrates the Dynamic Neural Regeneration (DNR) framework, which uses a data-aware dynamic masking scheme. The scheme identifies and removes redundant connections, increasing the network’s capacity for learning. This is achieved through random weight reinitialization during an iterative training process, ultimately enhancing the model’s performance and generalization capabilities, especially on small datasets. The figure visually depicts the process, showing the evolution of the network across generations, highlighting the dynamic masking and neuron addition/deletion steps.
read the caption
Figure 1: Schematics of proposed Dynamic Neural Regeneration (DNR) framework. Our framework utilizes a data-aware dynamic masking scheme to remove redundant connections and increase the network's capacity for further learning by incorporating random weight reinitialization. Thus, effectively improving the performance and generalization of deep neural networks on small datasets.
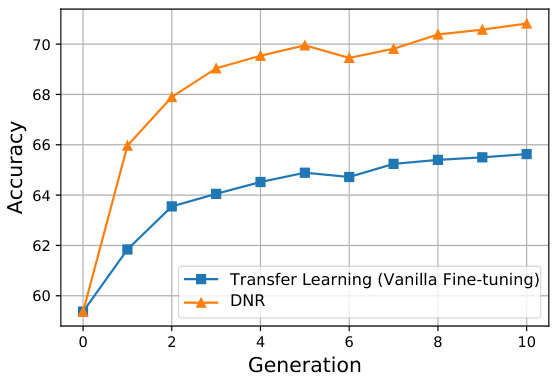
🔼 The figure compares the convergence behavior of Dynamic Neural Regeneration (DNR) and vanilla transfer learning using the ResNet18 architecture on the CUB dataset. The x-axis represents the generation number, while the y-axis shows the accuracy. The plot illustrates that DNR achieves a higher accuracy with fewer generations, indicating faster convergence and potentially better generalization.
read the caption
Figure 3: Convergence behavior: evaluating performance across generations in DNR and transfer learning with ResNet18 architecture trained on CUB dataset.
🔼 This figure illustrates the Dynamic Neural Regeneration (DNR) framework, which uses data-aware dynamic masking to remove unnecessary connections in a neural network. By doing this, it increases the network’s capacity for further learning, as weights are randomly reinitialized, leading to improved performance and generalization, particularly with small datasets. The figure shows the evolutionary training paradigm used, highlighting the dynamic masking, neuron deletion, and creation processes.
read the caption
Figure 1: Schematics of proposed Dynamic Neural Regeneration (DNR) framework. Our framework utilizes a data-aware dynamic masking scheme to remove redundant connections and increase the network's capacity for further learning by incorporating random weight reinitialization. Thus, effectively improving the performance and generalization of deep neural networks on small datasets.
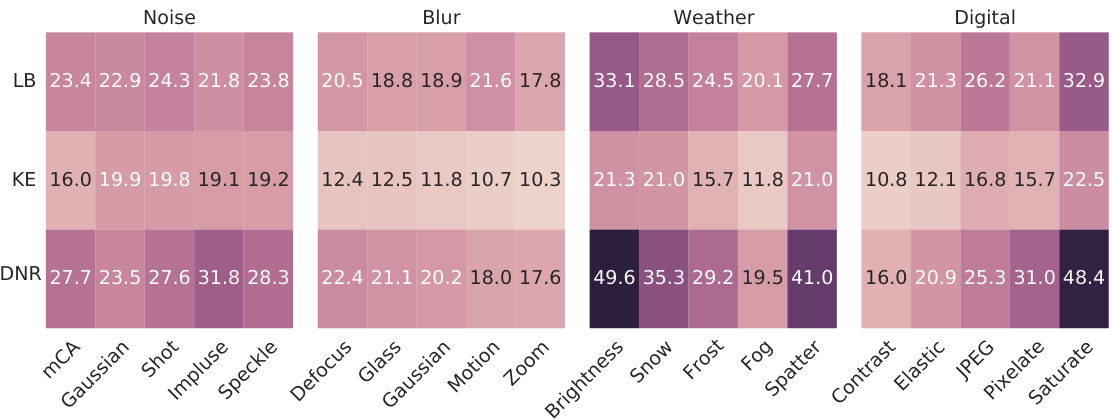
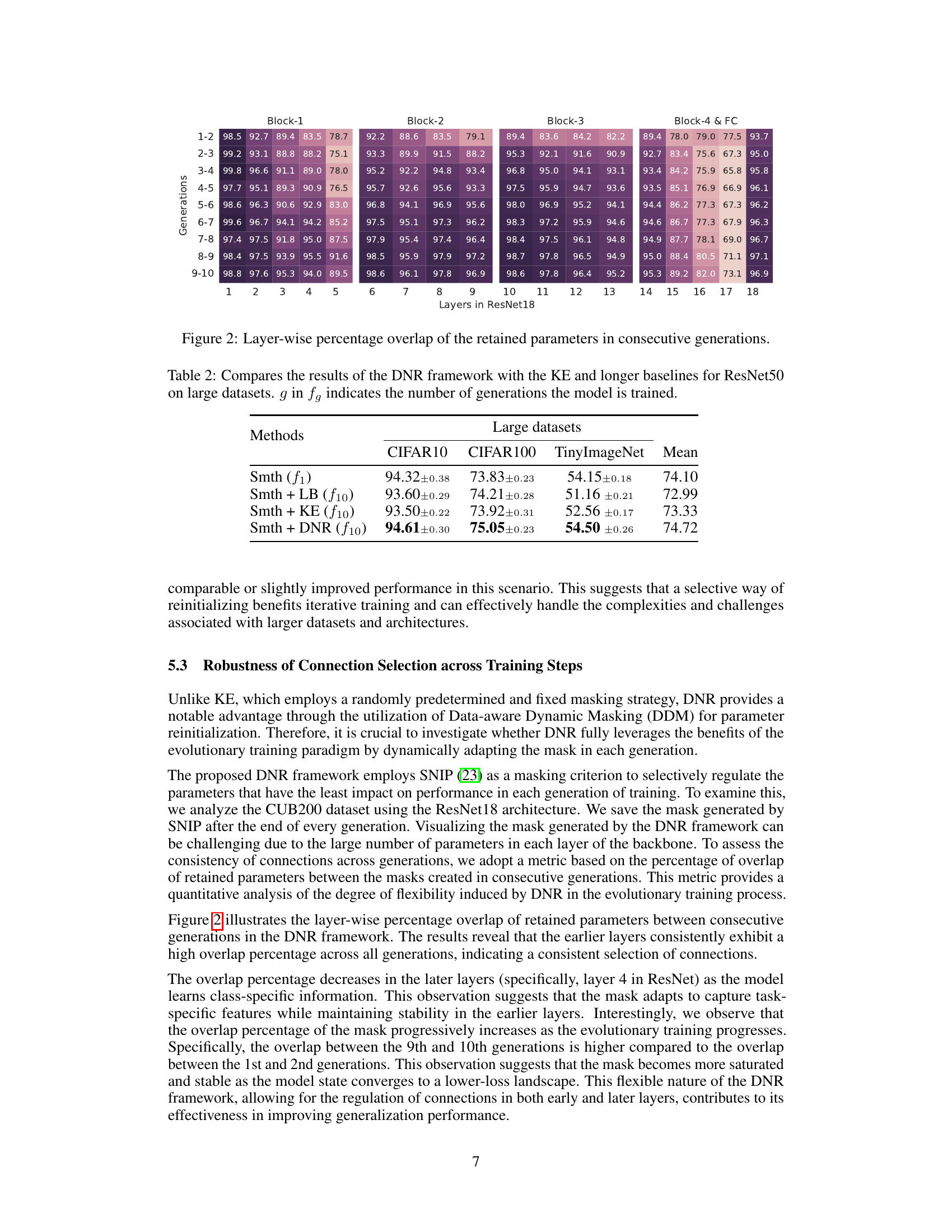
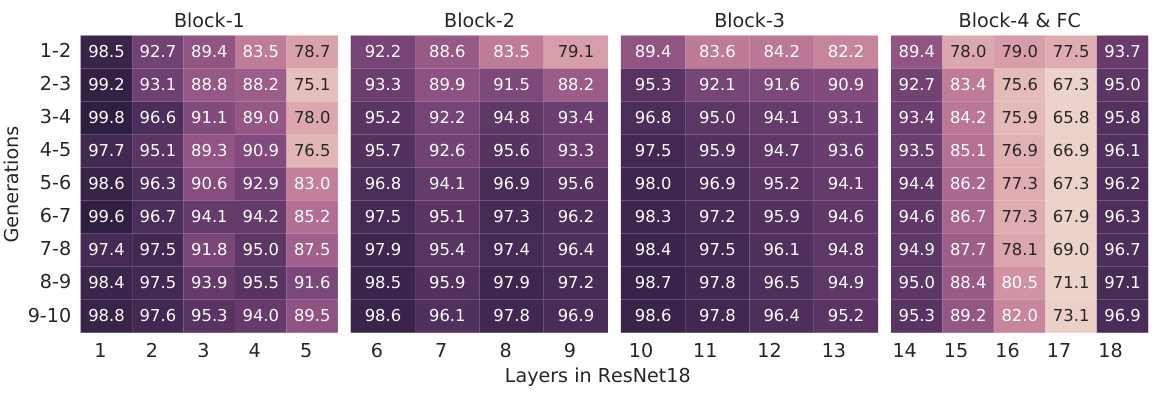
🔼 This figure displays the Mean Corruption Accuracy (MCA) for three different methods (LB, KE, and DNR) across various types of image corruptions (Gaussian Noise, Shot Noise, Impulse Noise, Speckle Noise, Defocus Blur, Gaussian Blur, Motion Blur, Zoom Blur, Brightness, Snow, Frost, Fog, Spatter, Contrast, Elastic, JPEG Compression, Pixelate, and Saturation). Each corruption type has five levels of severity. The heatmap visualizes the MCA for each method and corruption, demonstrating that DNR generally exhibits higher accuracy across multiple corruption types and severities, indicating superior robustness.
read the caption
Figure 5: Robustness to natural corruptions on CIFAR-10-C (37). DNR is more robust against the majority of corruptions compared to the baselines.

🔼 This figure displays the robustness of different models (LB, KE, and DNR) against adversarial attacks of varying strengths (epsilon values). The y-axis represents the adversarial accuracy, showing the percentage of correctly classified examples even under adversarial perturbations. The x-axis indicates the strength of the adversarial attack (epsilon). The figure shows how the adversarial accuracy decreases as the attack strength increases for all three models, but DNR demonstrates significantly better robustness compared to LB and KE, maintaining higher accuracy even under stronger attacks.
read the caption
Figure 6: Robustness to adversarial attacks
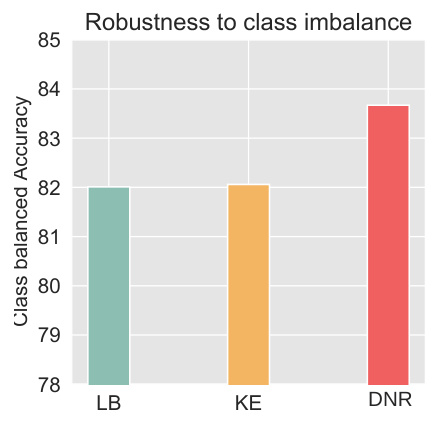
🔼 The figure shows the class balanced accuracy for three different methods (LB, KE, and DNR) under class imbalanced conditions. The results illustrate that DNR significantly outperforms the baselines (LB and KE) in handling class imbalance, suggesting its robustness and effectiveness in addressing this common challenge in real-world datasets.
read the caption
Figure 7: Robustness to class imbalance
More on tables
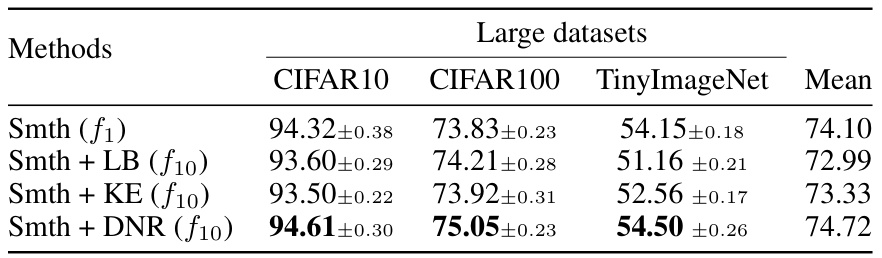
🔼 This table compares the performance of Dynamic Neural Regeneration (DNR) against Knowledge Evolution (KE) and a Long Baseline (LB) on three large-scale image classification datasets: CIFAR10, CIFAR100, and TinyImageNet. The model used is ResNet50. The results show the accuracy achieved after 10 generations (f10) of training, using label smoothing (Smth). The comparison highlights the improved generalization performance of DNR compared to existing methods on these large datasets.
read the caption
Table 2: Compares the results of the DNR framework with the KE and longer baselines for ResNet50 on large datasets. g in fg indicates the number of generations the model is trained.

🔼 This table compares the performance of Dynamic Neural Regeneration (DNR) with transfer learning on several datasets. It shows the accuracy of using a smoothing regularizer with transfer learning and with DNR, demonstrating DNR’s superior performance across multiple datasets.
read the caption
Table 3: Comparative analysis of DNR and transfer learning across diverse datasets.
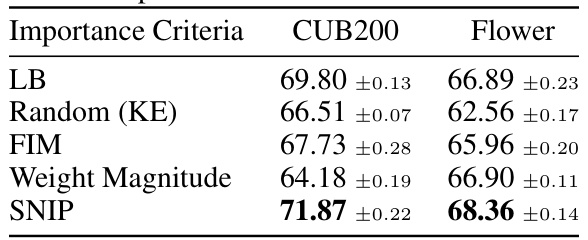
🔼 This table compares the performance of the Dynamic Neural Regeneration (DNR) method using different criteria for estimating the importance of parameters: Long Baseline (LB), Random (KE - Knowledge Evolution), Fisher Information Matrix (FIM), Weight Magnitude, and SNIP (Single-shot Network Pruning). The results are shown for the CUB200 and Flower datasets, indicating the accuracy achieved by each method. This table helps to demonstrate the superiority of the SNIP method for data-aware dynamic masking in the DNR framework.
read the caption
Table 4: Evaluating the performance of DNR with different importance estimation.
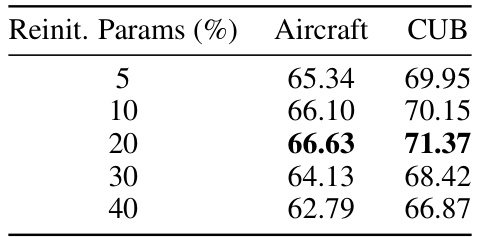
🔼 This table compares the performance of the proposed Dynamic Neural Regeneration (DNR) method against several other weight reinitialization methods (CE, DSD, BAN, KE) on the ResNet18 architecture. The results are presented for several small datasets (CUB, Aircraft, Dog, Flower, MIT). The table shows the accuracy achieved by each method, with the number of generations (g) used in the training indicated in parentheses. The inclusion of label smoothing (Smth) as a regularizer is also explored, showing its impact on performance.
read the caption
Table 1: Compares the results of our method with the other weight reinitialization methods on ResNet18. g in fg indicates the number of generations the model is trained.

🔼 This table compares the performance of the proposed Dynamic Neural Regeneration (DNR) method with other weight reinitialization methods (DSD, BAN, KE) and a long baseline (LB) on five different small datasets using ResNet18. The results are reported in terms of mean accuracy and standard deviation across different datasets. The number of generations used for the iterative training is also specified. The table shows that the DNR method consistently outperforms other methods in terms of accuracy and generalization.
read the caption
Table 1: Compares the results of our method with the other weight reinitialization methods on ResNet18. g in fg indicates the number of generations the model is trained.

🔼 This table presents the results of the Dynamic Neural Regeneration (DNR) method using different numbers of data samples for importance estimation. It shows the test accuracy achieved after 10 generations on two datasets (Aircraft and CUB) when using either 20% of the entire dataset or only 128 samples for estimating the importance of parameters using the SNIP method. The results demonstrate the robustness of the DNR method to variations in the amount of data used for importance estimation.
read the caption
Table 7: Evaluation with varying the quantity of data for importance estimation. Test accuracy at the end of 10 generations is shown on Aircraft and CUB datasets.

🔼 This table compares the performance of the proposed Dynamic Neural Regeneration (DNR) method with other weight reinitialization methods (CE, DSD, BAN, KE) on the ResNet18 architecture using small datasets. It shows the mean accuracy across five different datasets (CUB, Aircraft, Dog, Flower, MIT) for each method, and indicates how many generations the model was trained for (g in fg). The results demonstrate that DNR generally outperforms other methods.
read the caption
Table 1: Compares the results of our method with the other weight reinitialization methods on ResNet18. g in fg indicates the number of generations the model is trained.

🔼 This table shows the accuracy achieved by the Dynamic Neural Regeneration (DNR) method on the Flower dataset across different numbers of generations (iterations of training). It demonstrates how the model’s accuracy improves as the number of generations increases, indicating the efficacy of the iterative training paradigm.
read the caption
Table 9: Performance of DNR across generations on the Flower dataset

🔼 This table compares the performance of the proposed Dynamic Neural Regeneration (DNR) method with other weight reinitialization methods (CE, DSD, BAN, KE) on five different datasets using the ResNet18 architecture. The results are shown for different numbers of generations (g), indicating the iterative nature of the training process. The table helps illustrate the improvement in performance achieved by DNR compared to existing methods, highlighting its efficacy in improving the generalization of deep neural networks on small datasets.
read the caption
Table 1: Compares the results of our method with the other weight reinitialization methods on ResNet18. g in indicates the number of generations the model is trained.
Full paper#