↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training effective dense retrievers requires substantial hardware resources due to the InfoNCE loss’s dependence on large batch sizes. Existing memory reduction methods, like GradAccum and GradCache, suffer from slow or unstable training. This creates a bottleneck in applying dense retrievers broadly.
This paper introduces CONTACCUM, a novel memory reduction method. It uses a dual memory bank structure (for queries and passages) to leverage previously generated representations, increasing effective negative sample size. Experiments show CONTACCUM surpasses existing methods and high-resource scenarios. The theoretical analysis validates CONTACCUM’s superior stability by addressing gradient norm imbalance, a key issue in dual-encoder training.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with dense retrievers, especially those facing memory limitations. It introduces CONTACCUM, a novel method showing significant performance improvements while efficiently managing resources. This opens avenues for broader applications of dense retrievers in resource-constrained environments and inspires further research on memory-efficient training strategies for similar models. The improved stability of CONTACCUM training also addresses a long-standing problem, making this work highly impactful.
Visual Insights#
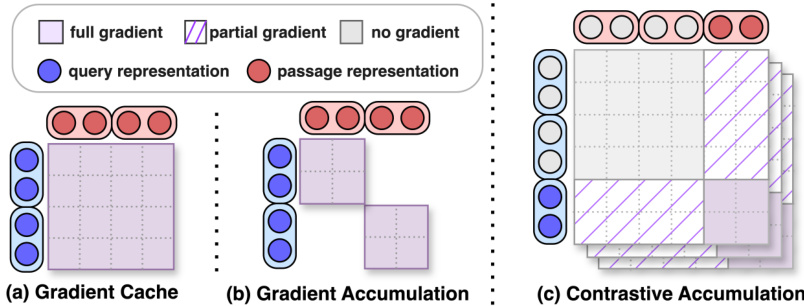
This figure compares three methods for training dense retrievers under memory constraints: Gradient Cache (GradCache), Gradient Accumulation (GradAccum), and Contrastive Accumulation (CONTACCUM). Each panel illustrates how these methods handle a total batch of 4 data points split into local batches of size 2. The key difference lies in how they use negative samples for contrastive learning. GradCache decomposes the backpropagation and uses all available negative samples. GradAccum only uses negative samples within each local batch. CONTACCUM leverages a memory bank to include previously seen negative samples, resulting in a higher number of negative samples than even the full batch size.

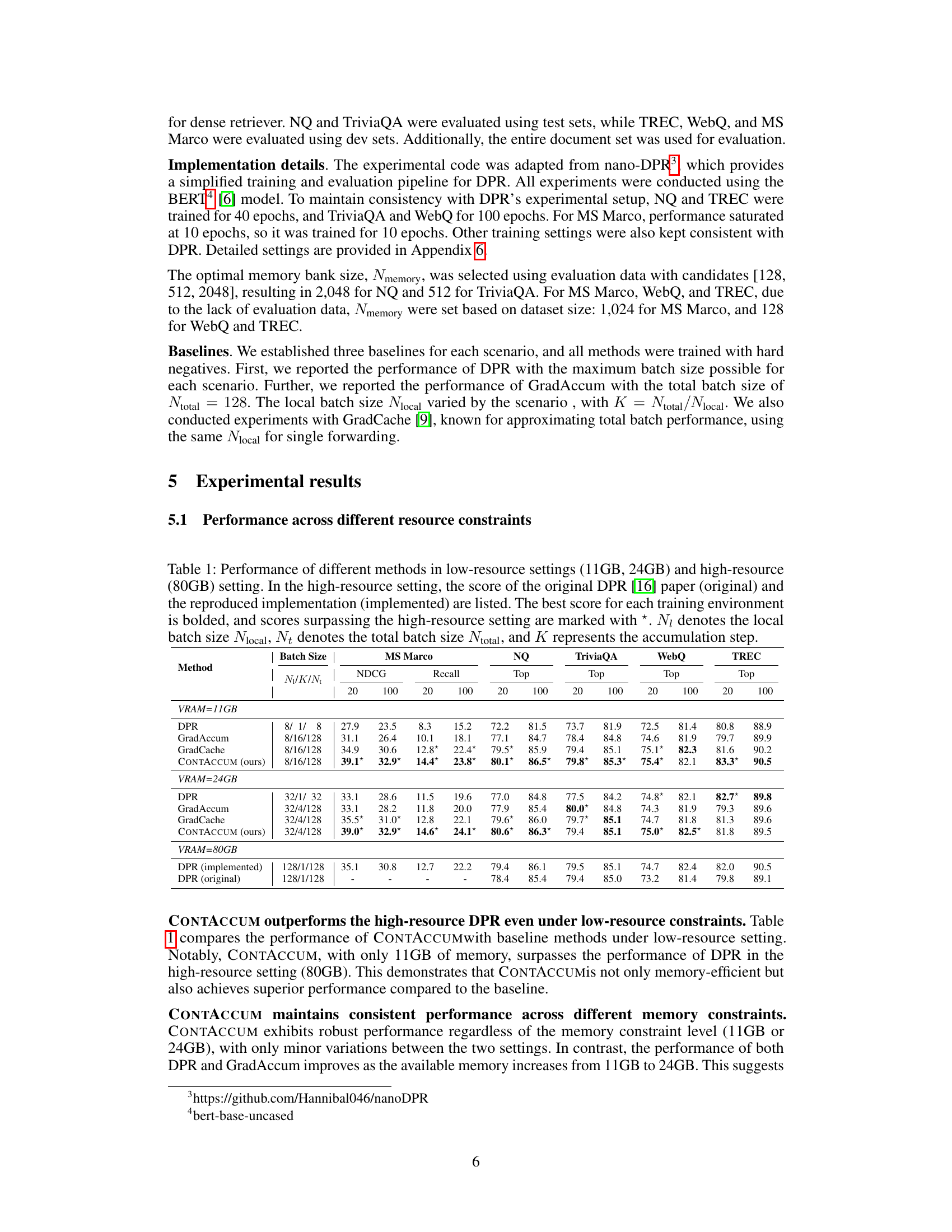
This table presents a comparison of the performance of different dense retrieval methods under various memory constraints. It shows the results for several metrics (NDCG, Recall, Top@20, Top@100) across three different memory settings (11GB, 24GB, and 80GB). The methods compared include DPR, GradAccum, GradCache, and the proposed CONTACCUM. The table highlights the best performance achieved in each setting and indicates when a method surpasses the performance of the original DPR method in the high-resource setting. It also provides details on batch size configurations (Nlocal, Ntotal, K) used for each method.
In-depth insights#
Memory-Bank Power#
The concept of ‘Memory-Bank Power’ in the context of dense retrieval models centers on the effectiveness of leveraging previously computed query and passage representations to enhance training efficiency and performance. A larger memory bank allows for the inclusion of more negative samples during training, which is crucial for the InfoNCE loss function, a common choice for training dense retrievers. However, the use of a memory bank introduces complexities. A naive implementation might lead to instability and suboptimal performance. The authors address this by proposing a ‘dual memory bank’ strategy that uses separate banks for queries and passages, which helps to achieve more stable and efficient training. This approach carefully manages the gradient updates to avoid the instability associated with utilizing only one memory bank. The effectiveness of this strategy is demonstrated empirically and theoretically, showing that the dual memory bank structure significantly improves the stability and accuracy of dense retriever training, particularly under memory-constrained settings.
Dual-Encoder Stability#
Dual-encoder models, while effective for information retrieval, often suffer from instability during training, particularly when using InfoNCE loss and large batch sizes. The core of the instability problem stems from an imbalance in the gradient norms of the query and passage encoders. Methods like GradAccum, while aiming to reduce memory consumption, exacerbate this issue by reducing effective negative samples. This highlights a crucial design consideration: achieving balanced gradient updates is key to stable training. The proposed CONTACCUM method directly tackles this by employing dual memory banks for both queries and passages, enabling the use of significantly more negative samples and thus mitigating the gradient norm imbalance. The dual memory bank strategy ensures more balanced gradient updates for both encoders, leading to enhanced stability and improved performance, exceeding not only memory-constrained baselines but also high-resource settings. The effectiveness of this approach underscores the importance of considering gradient dynamics when designing efficient training strategies for dual-encoder architectures.
GradAccum Limitations#
The core limitation of Gradient Accumulation (GradAccum) in the context of contrastive learning, particularly with InfoNCE loss, stems from its inherent reduction of negative samples per query. GradAccum’s effectiveness relies on dividing a large batch into smaller sub-batches, processed sequentially. While this alleviates memory pressure, it directly diminishes the number of negative examples used during each gradient update. This is detrimental because contrastive learning, and InfoNCE loss specifically, thrives on a large pool of negative samples to effectively push apart irrelevant representations while pulling relevant ones closer. Fewer negatives weaken this crucial aspect of the learning process, resulting in suboptimal model performance and slower convergence compared to training with a large batch size. Furthermore, although GradAccum mitigates memory issues, its sequential processing introduces increased training time and potential instability, which hinder its practicality for training deep dense retrievers effectively. Therefore, methods like CONTACCUM that address the negative sample limitation while maintaining memory efficiency are significant improvements over GradAccum for this specific application.
CONTACCUM Efficiency#
CONTACCUM’s efficiency stems from its clever dual memory bank design and the strategic use of gradient accumulation. By caching both query and passage representations, CONTACCUM avoids redundant computations, significantly reducing training time compared to methods like GradAccum and GradCache. This dual-bank approach also allows for the effective utilization of a larger number of negative samples, improving model performance without the need for high-resource hardware. The method’s computational efficiency is further enhanced by the inherent nature of gradient accumulation; gradients are calculated iteratively from smaller batches, reducing memory demands. While GradCache incurs substantial overhead decomposing the backpropagation process, CONTACCUM elegantly reuses previously generated information, resulting in a more efficient and stable training process overall. The combination of these factors makes CONTACCUM a highly efficient method, particularly advantageous in low-resource scenarios where large batch sizes are otherwise unfeasible.
Future Research#
The paper’s conclusion points toward several promising avenues for future research. Extending CONTACCUM to the pre-training phase using a uni-encoder architecture is a key area, as this would broaden the method’s applicability beyond supervised fine-tuning. Investigating more efficient training strategies to mitigate the computational cost of the softmax operation is also crucial, especially for low-resource settings. Addressing the limitations in handling the gradient norm imbalance problem by exploring alternative memory bank management techniques would improve robustness and stability. Finally, research into addressing the computational cost of the softmax function itself, a major bottleneck in large-scale retrieval tasks, could significantly enhance performance and scalability of the method.
More visual insights#
More on figures
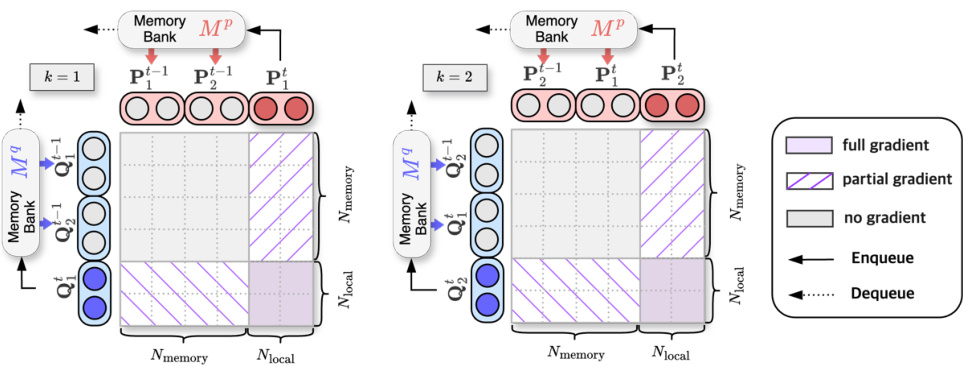
This figure illustrates the training process of the CONTACCUM method at each accumulation step. It uses a total batch size of 4, broken down into 2 accumulation steps (K=2), and a memory bank size of 4. The key feature is the dual memory bank which stores query and passage representations. As new representations are generated in each step, older ones are removed (dequeued), maintaining a constant size for the similarity matrix used in calculating the loss. The diagram visually shows how the memory bank allows the method to effectively leverage past representations.
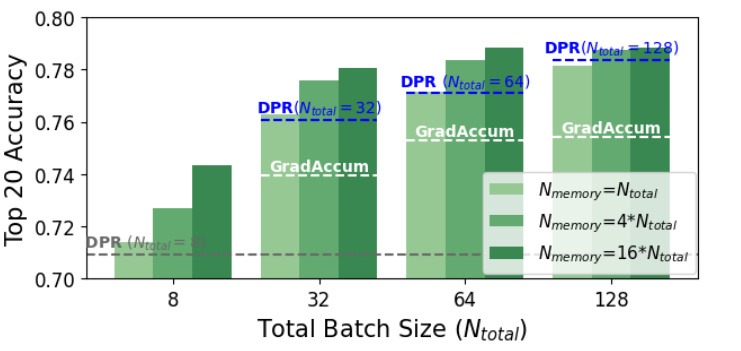
This figure displays the impact of the memory bank size and accumulation steps on the performance of CONTACCUM, compared to DPR and GradAccum baselines. The x-axis shows different total batch sizes, while the y-axis represents the Top 20 accuracy. Different shades of green bars depict varying memory bank sizes (N_memory) relative to the total batch size. The figure demonstrates that CONTACCUM consistently outperforms GradAccum, and its performance improves as N_memory increases, regardless of the accumulation step.

This figure compares the training speed of CONTACCUM with several baseline methods under various memory constraints. The x-axis represents the total batch size (Ntotal), and the y-axis represents the time (in seconds) required for a single training iteration (one weight update). Different methods and memory bank configurations are compared, demonstrating how CONTACCUM maintains relatively fast iteration times even when using large memory banks, unlike GradCache, which shows significantly slower speeds as the total batch size grows.
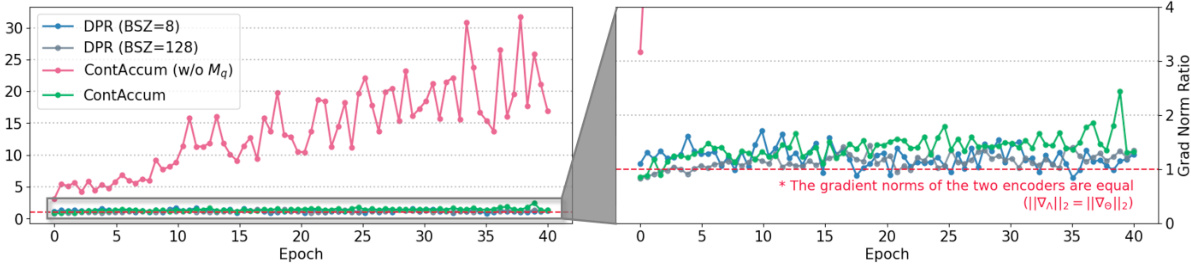
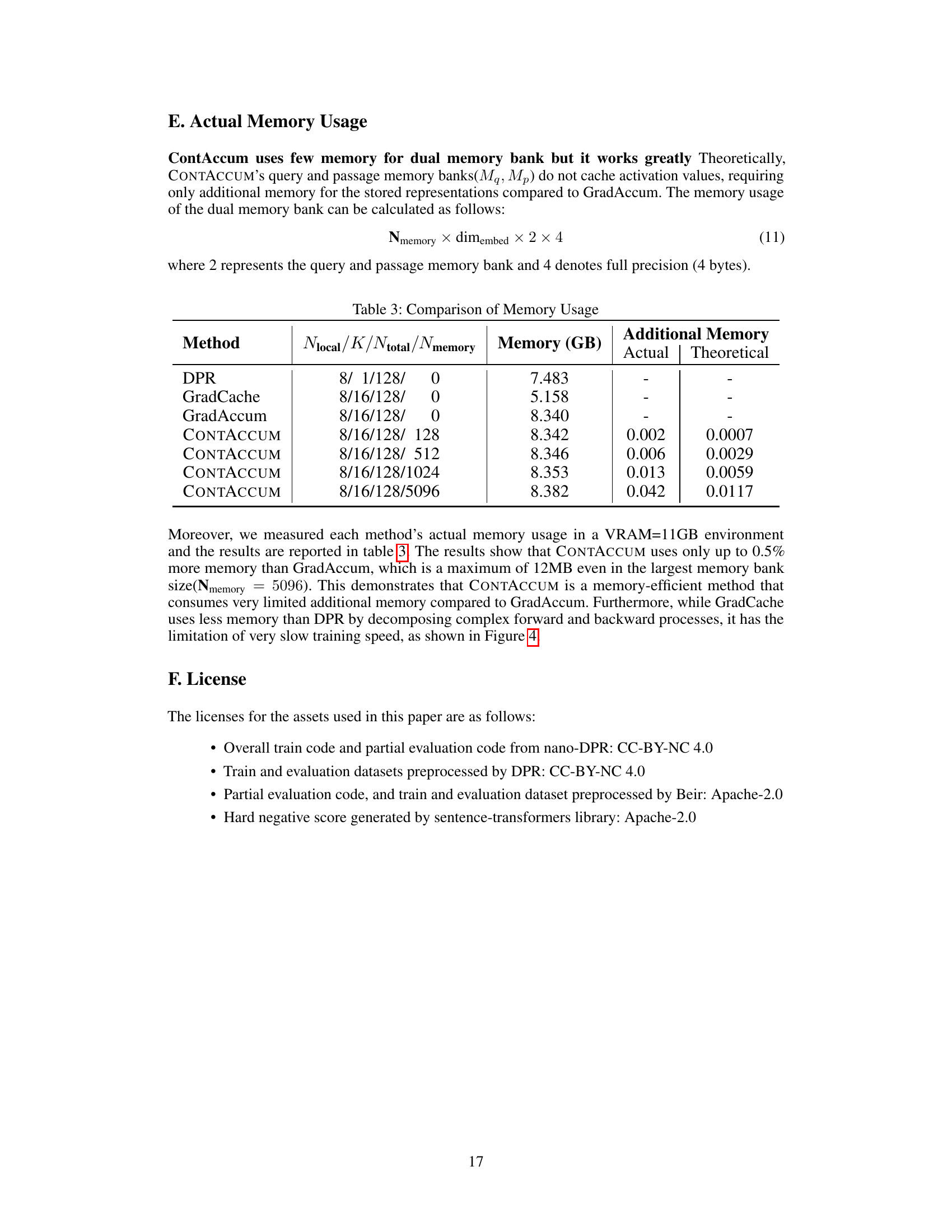
The figure shows the gradient norm ratio (||∇A||2/||∇θ||2) during the training of the NQ dataset. The left panel displays the ratio over epochs, comparing the performance of DPR (with batch sizes of 8 and 128), ContAcum (without the query memory bank Mq), and ContAcum (with the dual memory banks Mq and Mp). The right panel provides a zoomed-in view of the ratio, highlighting that CONTACCUM maintains a ratio close to 1 (indicating balanced gradient norms between the two encoders), while omitting the query memory bank leads to a significant imbalance, especially in later training epochs.
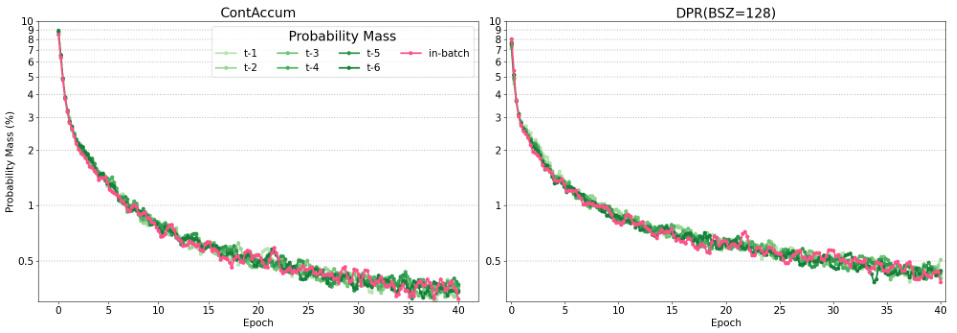
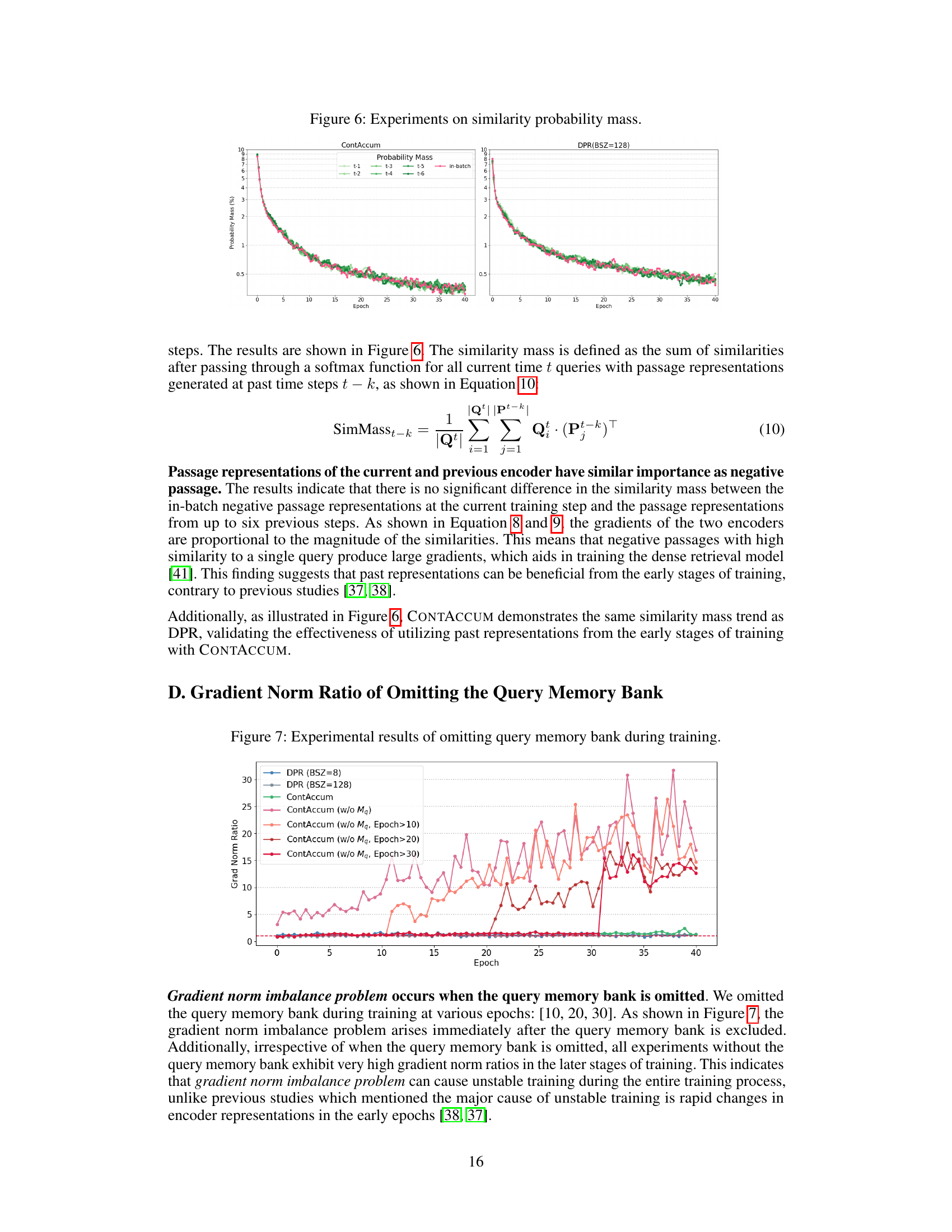
This figure visualizes the similarity probability mass over training epochs for both CONTACCUM and DPR (with a batch size of 128). The similarity mass represents the sum of similarities between current-epoch queries and passage representations generated in past epochs (t-1 to t-6). It shows the relative importance of negative passages from previous steps for both methods, illustrating that CONTACCUM maintains similar behavior to a full-batch DPR, indicating that leveraging previous representations is beneficial, contrary to some previous work. The in-batch negative samples are also included for comparison.
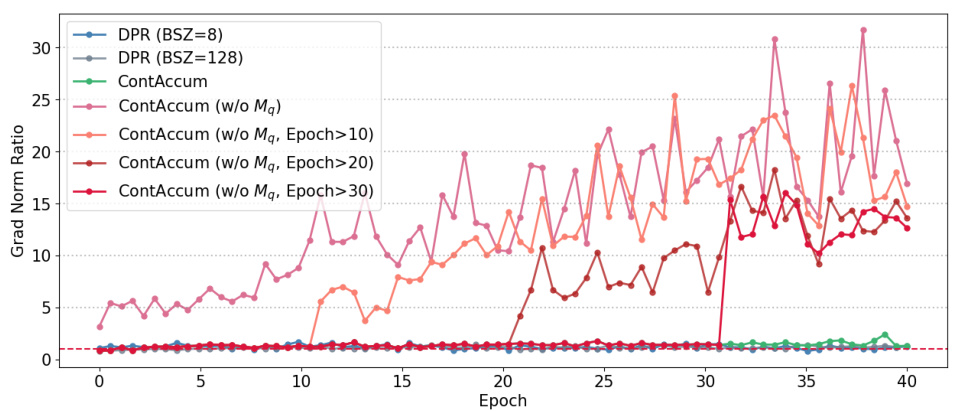
This figure presents the gradient norm ratio (||∇A||2/||∇Θ||2) during the training of the Natural Questions (NQ) dataset. The gradient norm ratio is a measure of the balance between the gradients of the query and passage encoders. A ratio close to 1 indicates balanced gradients, while deviations suggest an imbalance. The figure shows the gradient norm ratio over epochs for different training scenarios: standard DPR (with small and large batch sizes), Contrastive Accumulation (CONTACCUM) and CONTACCUM variants where the query memory bank (Mq) is removed at different epochs (10, 20, 30). The plot helps illustrate the effect of the query memory bank on maintaining balanced gradients and the impact on training stability.
More on tables
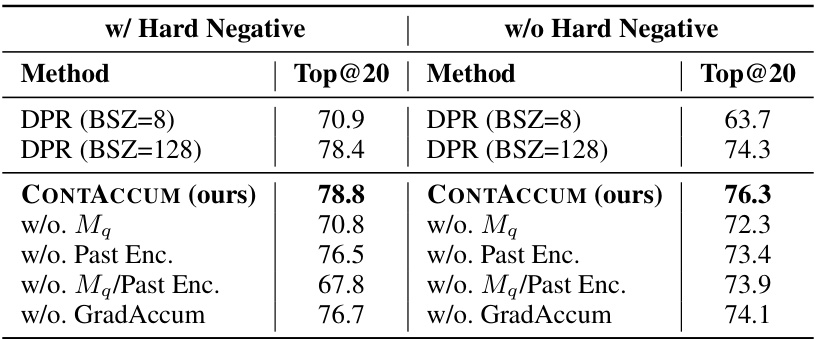
This table presents the ablation study results of the CONTACCUM model. It shows the impact of removing individual components (query memory bank, passage memory bank, GradAccum) on the model’s performance, both with and without hard negatives. The baseline performances of DPR with batch sizes 8 and 128 are also included for comparison. The best-performing configuration in each condition is highlighted in bold.
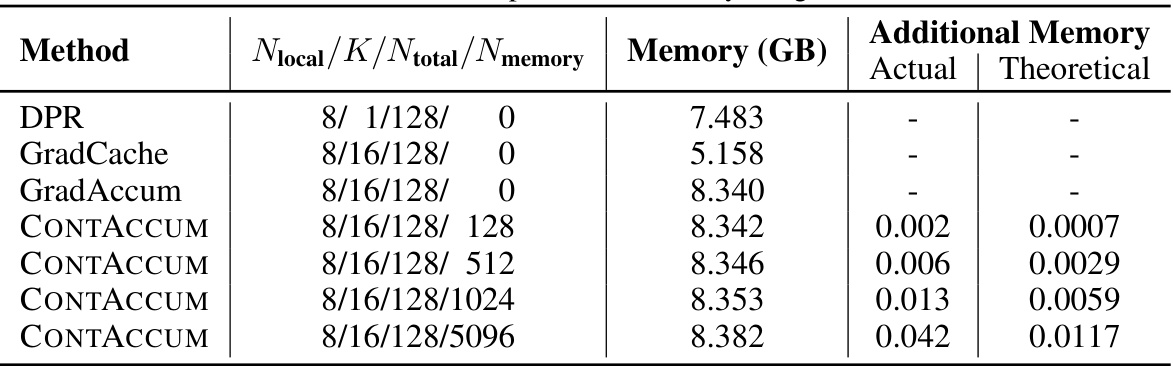
This table compares the actual memory usage (in GB) of different methods (DPR, GradCache, GradAccum, and CONTACCUM) under a low resource setting (11GB VRAM). It shows that CONTACCUM has a minimal increase in memory usage compared to GradAccum, while significantly improving performance. The additional memory used by CONTACCUM is attributed to its dual memory banks. The theoretical additional memory usage is also provided for comparison.
Full paper#