↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Lifelong reinforcement learning faces a significant challenge: the loss of plasticity, where past learning hinders adaptation to new tasks. Existing solutions often involve hyperparameter tuning, which can be difficult and environment-specific. This paper introduces TRAC, a parameter-free optimizer designed to address this problem. It builds upon the principled theory of online convex optimization, requiring no tuning or prior knowledge about environment shifts.
TRAC’s performance was evaluated across a diverse set of environments, including Procgen, Atari, and Gym Control. Results consistently demonstrated TRAC’s ability to mitigate plasticity loss, adapting rapidly to new tasks and distribution shifts. This performance held true despite the underlying nonconvex and nonstationary nature of the optimization problem, offering a significant improvement in mitigating the well-known issue of plasticity loss in lifelong reinforcement learning.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces TRAC, a novel parameter-free optimizer for lifelong reinforcement learning, directly addressing the critical issue of plasticity loss. It offers a principled solution based on online convex optimization and demonstrates remarkable empirical success across various challenging environments. This work opens up new avenues for developing more robust and adaptable AI agents and improves current methods. The parameter-free nature is especially important as it removes the need for potentially environment-dependent hyperparameter tuning, a significant advancement for lifelong RL.
Visual Insights#
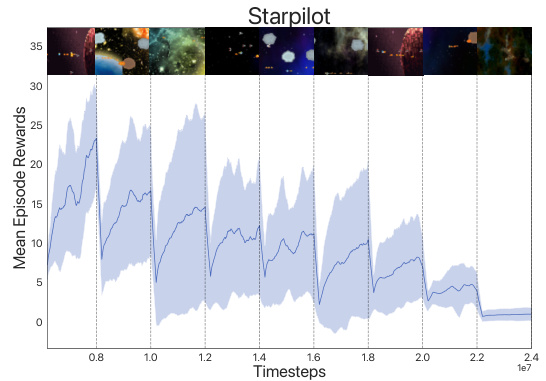
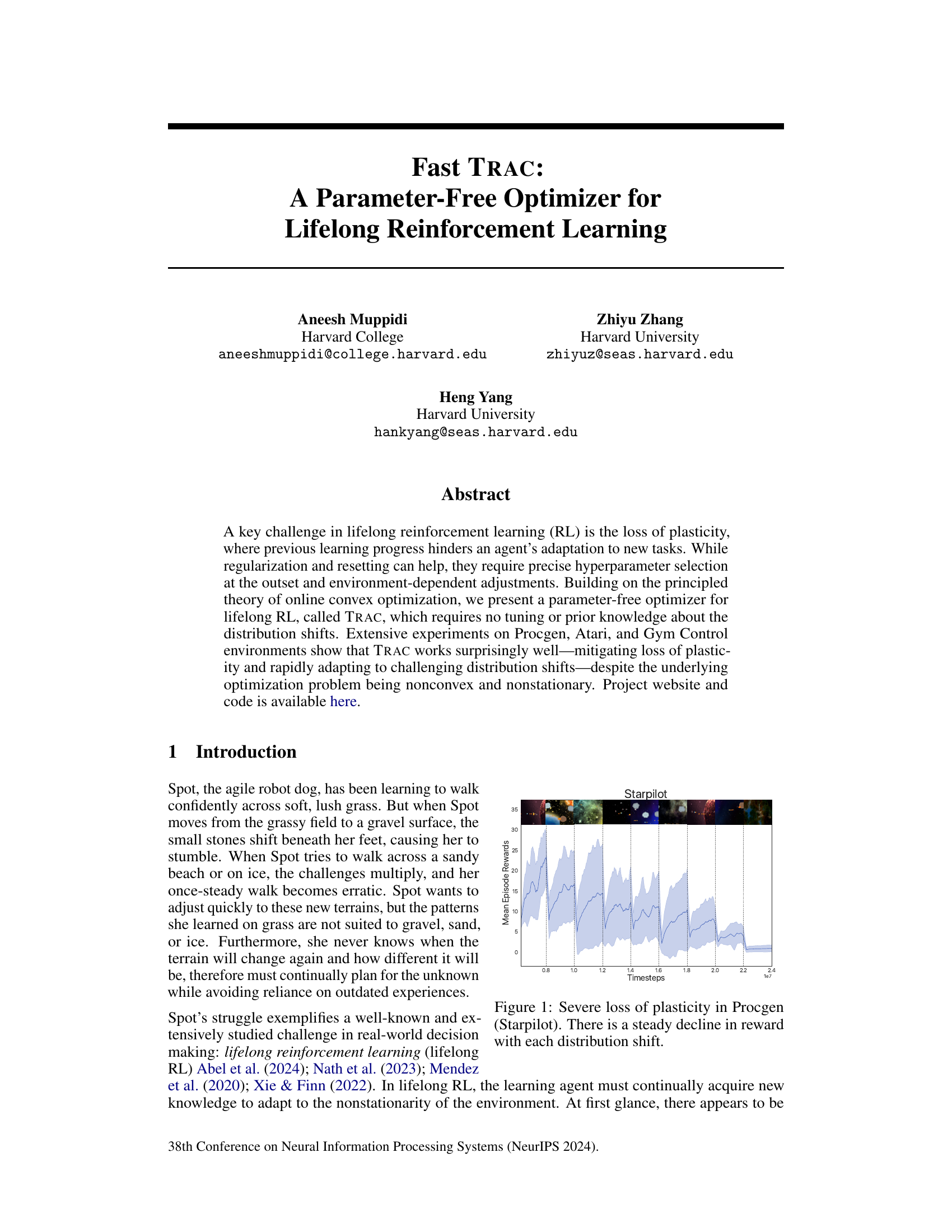
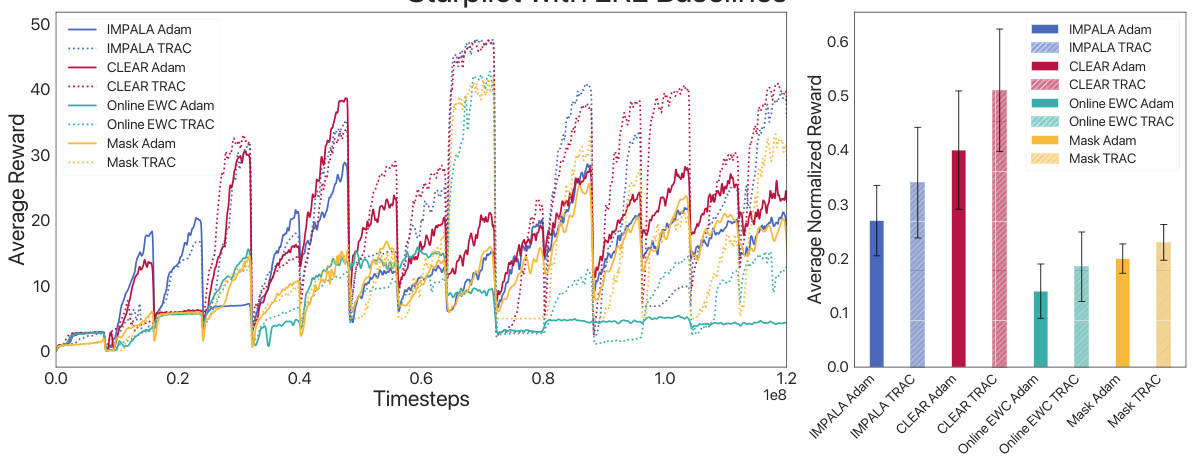
This figure shows the performance of an agent trained using a standard reinforcement learning algorithm on the Starpilot environment from the Procgen benchmark. The x-axis represents the number of timesteps, and the y-axis represents the average reward obtained per episode. The plot shows that the agent’s performance steadily decreases with each distribution shift (change in the game’s environment), indicating a significant loss of plasticity. The agent struggles to adapt to the new environments after initial training, suggesting a limitation in its ability to retain previously learned knowledge and apply it to new scenarios. This highlights the key challenge of lifelong reinforcement learning: maintaining the ability to learn new tasks without forgetting previously acquired skills.
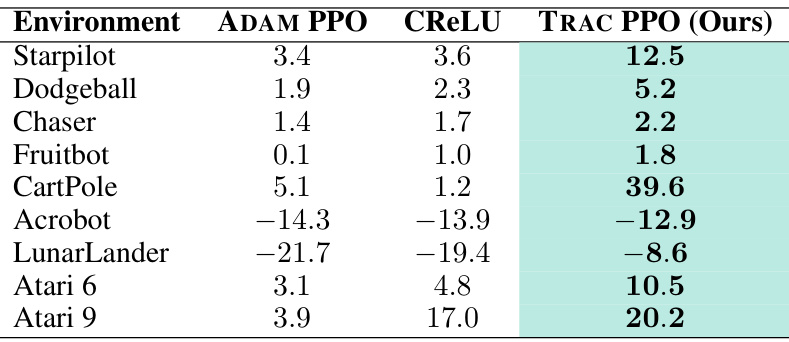
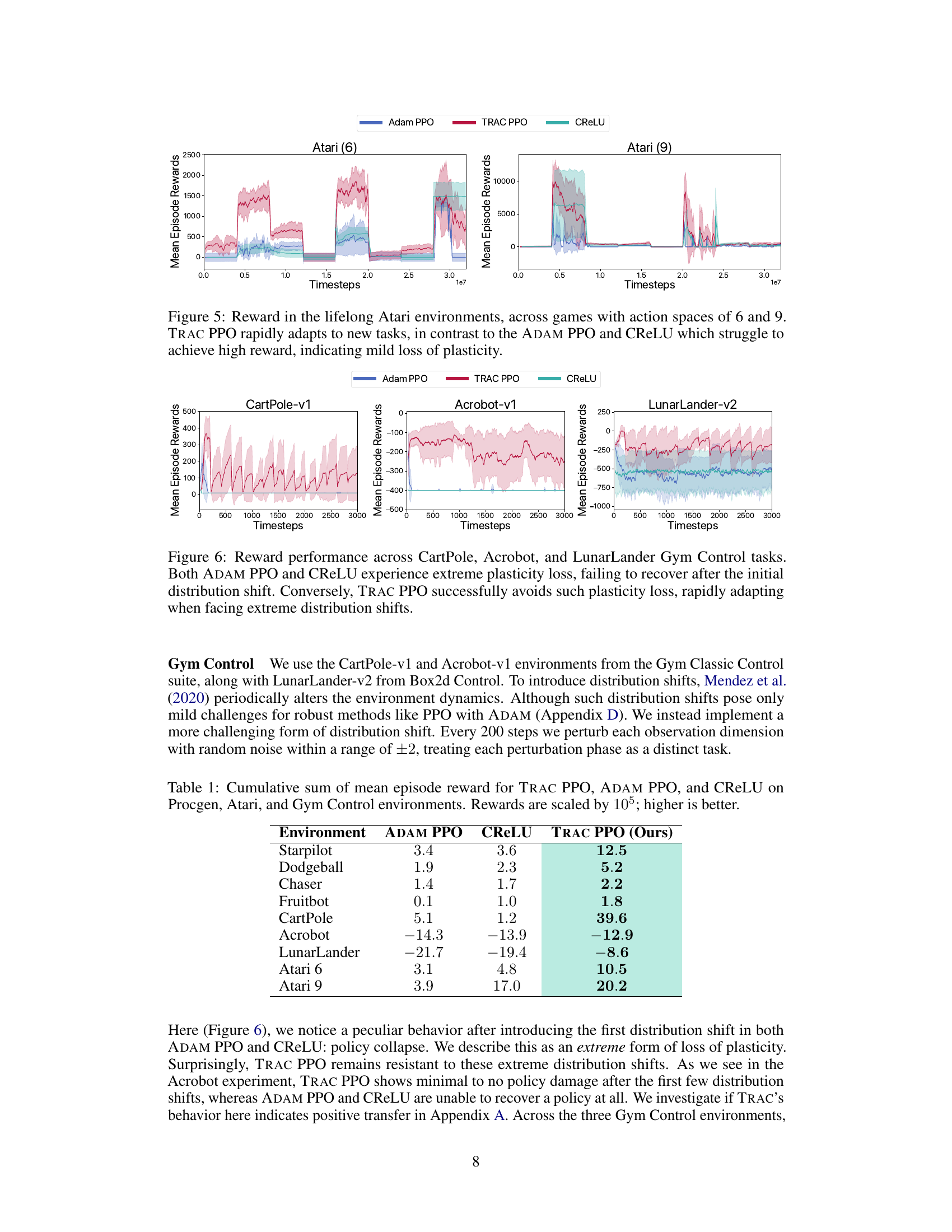
This table presents a quantitative comparison of the cumulative sum of mean episode rewards achieved by three different algorithms (TRAC PPO, ADAM PPO, and CReLU) across various reinforcement learning environments. The environments are categorized into Procgen, Atari, and Gym Control. The cumulative reward is a measure of overall performance, and it’s scaled by a factor of 105 for easier interpretation. Higher values indicate better performance.
In-depth insights#
TRAC: Core Algorithm#
The core of TRAC hinges on a principled, parameter-free approach to online convex optimization (OCO). Three key techniques drive its efficacy: direction-magnitude decomposition, which leverages a one-dimensional tuner to manage weight drift; the erfi potential function, which balances proximity to both the origin and empirical optimum; and additive aggregation, enabling automatic selection of optimal discount factors. TRAC’s strength lies in its ability to mitigate the loss of plasticity in lifelong RL without requiring hyperparameter tuning, unlike traditional regularization or resetting methods. By adapting the regularization strength in an online, data-dependent manner, TRAC effectively navigates the nonconvex and nonstationary nature of the lifelong RL optimization problem, allowing for rapid adaptation to new tasks and distribution shifts. Its parameter-free nature is a significant advantage for lifelong RL where a one-shot approach is necessary, ensuring adaptability without prior knowledge of the environment.
Plasticity & Shifts#
The concept of “Plasticity & Shifts” in lifelong reinforcement learning (RL) highlights the crucial tension between an agent’s ability to adapt to new situations (plasticity) and the disruptive effects of prior experience on this adaptation. Loss of plasticity, where past learning hinders the learning of new tasks, is a major challenge. The paper likely investigates how different distribution shifts in the environment affect the agent’s plasticity. Distribution shifts represent changes in the environment’s dynamics, rewards, or state representations, forcing the agent to adapt. Successful lifelong RL demands maintaining sufficient plasticity to navigate these shifts while avoiding catastrophic forgetting of previously acquired skills. The authors probably explore methods for mitigating negative transfer—when previous knowledge impairs subsequent learning—and for promoting positive transfer—where previous experience facilitates learning in new contexts. This might involve analysis of different optimization techniques and algorithmic approaches designed to enhance plasticity and robust adaptation.
Procgen Experiments#
The Procgen experiments section would likely detail the application of the parameter-free optimizer, TRAC, to a suite of procedurally generated game environments. The experiments would aim to demonstrate TRAC’s effectiveness in mitigating the loss of plasticity in lifelong reinforcement learning. Key aspects of the experimental design would include a clear definition of the lifelong learning scenario, such as how tasks (Procgen game levels) are sequentially introduced and how distribution shifts occur. Results would be presented to showcase TRAC’s ability to rapidly adapt to new tasks and avoid catastrophic forgetting, likely by showing improvement in cumulative reward compared to baseline algorithms (like standard gradient descent or other continual learning approaches). The discussion would emphasize TRAC’s parameter-free nature, highlighting its advantage over methods requiring hyperparameter tuning and its robustness to environment-specific adjustments. Quantitative analyses of plasticity loss and adaptation speed would further support the claims. Finally, the section may include ablation studies to isolate the contribution of different components within TRAC or comparisons with other state-of-the-art lifelong reinforcement learning algorithms.
Parameter-Free OCO#
Parameter-free online convex optimization (OCO) offers a compelling approach to lifelong reinforcement learning by mitigating the challenges of hyperparameter tuning. Traditional OCO methods often rely on carefully chosen parameters, such as regularization strength or learning rates, which are difficult to set optimally beforehand, especially in non-stationary environments. Parameter-free OCO algorithms elegantly sidestep this issue by adaptively determining these parameters online, based on the observed data and the learning process itself. This data-driven approach eliminates the need for prior knowledge about the task distribution, making it particularly well-suited for the dynamic nature of lifelong RL. A key advantage is the increased robustness and adaptability to unforeseen changes in the environment, thereby reducing the risk of catastrophic forgetting and enhancing the agent’s ability to swiftly adapt to new tasks. However, parameter-free OCO’s reliance on online adjustments might introduce additional computational overhead; thus, efficient implementations are essential for practical applications. The theoretical guarantees of parameter-free OCO, while typically proven under assumptions of convexity, can provide insights even when applied to the non-convex scenarios common in RL, hinting at the potential for robust and adaptable learning strategies.
Future of TRAC#
The future of TRAC hinges on addressing its limitations and exploring its potential. Extending TRAC’s applicability to more complex RL environments beyond those tested (Procgen, Atari, Gym) is crucial. This requires investigating its performance with diverse architectures, reward functions, and levels of nonstationarity. Improving the theoretical understanding of TRAC’s efficacy in non-convex and non-stationary settings is needed, potentially through connections with advanced optimization techniques. Research into adapting TRAC to handle catastrophic forgetting more robustly could further enhance its value in lifelong learning. The parameter-free nature of TRAC is a strength, but exploring methods for potentially incorporating limited hyperparameter tuning to optimize performance in specific scenarios could be beneficial. Finally, applications in robotics and real-world systems would showcase TRAC’s practical utility and pave the way for broader adoption.
More visual insights#
More on figures

The figure illustrates the core concept of TRAC, a parameter-free optimizer for lifelong reinforcement learning. It shows how TRAC uses a data-dependent regularizer to control the extent to which the iterates deviate from their initialization, thereby minimizing loss of plasticity. The ’tuner’ (Algorithm 2) dynamically decides the strength of regularization, adapting to each task’s distribution shifts and managing the drift of weights. The black curve represents the loss function, and the arrows show how the updated weights move to the new optimum after the distribution shift.
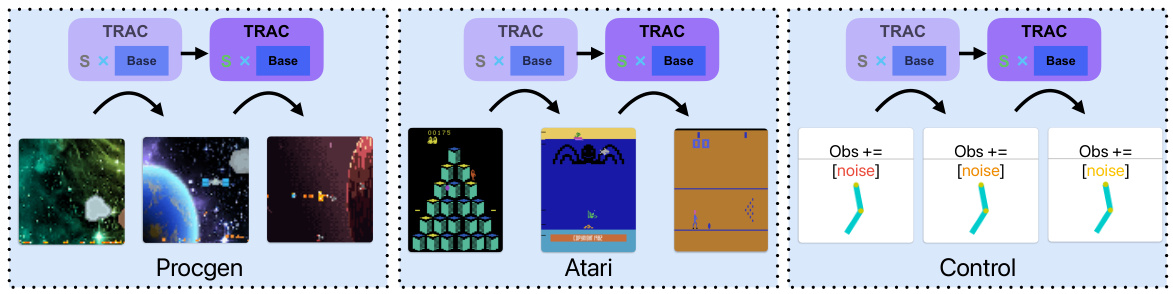
This figure illustrates the experimental setup for lifelong reinforcement learning (RL) across three different environments: Procgen, Atari, and Control. In each environment, the agent is trained using the TRAC algorithm, which is the focus of the paper. The figure visually represents how distribution shifts are introduced (new levels in Procgen, new games in Atari, and noise added to observations in Control) and how the TRAC optimizer helps the agent adapt to these shifts. The images show examples of the visual inputs the agent receives in each environment.
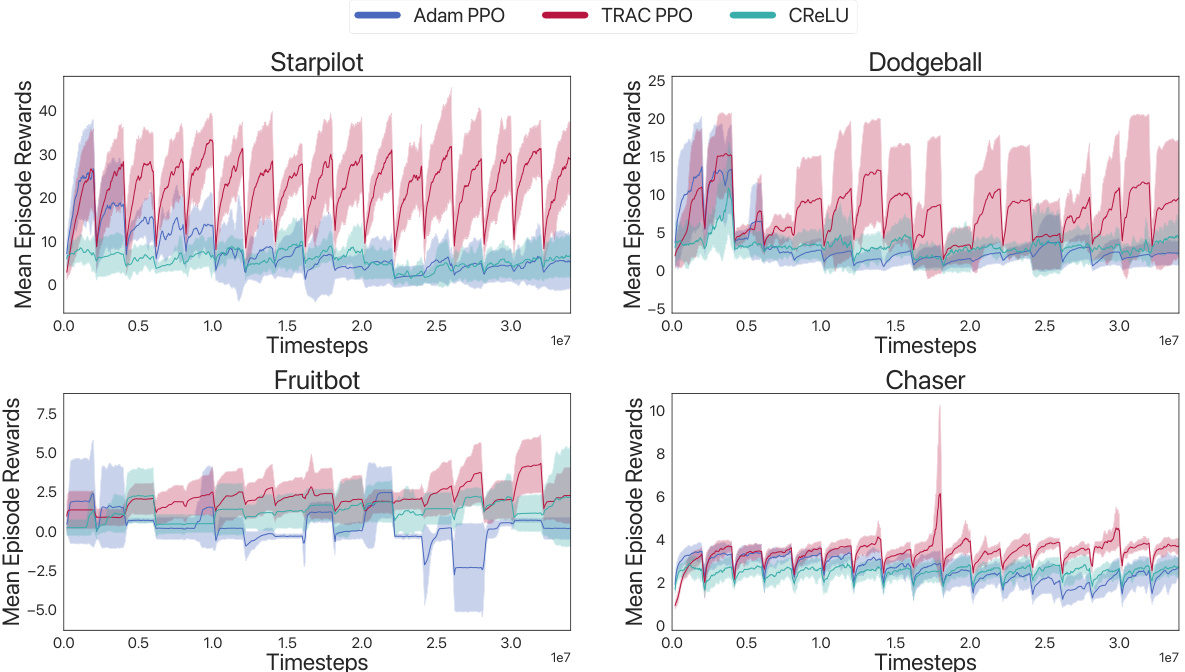
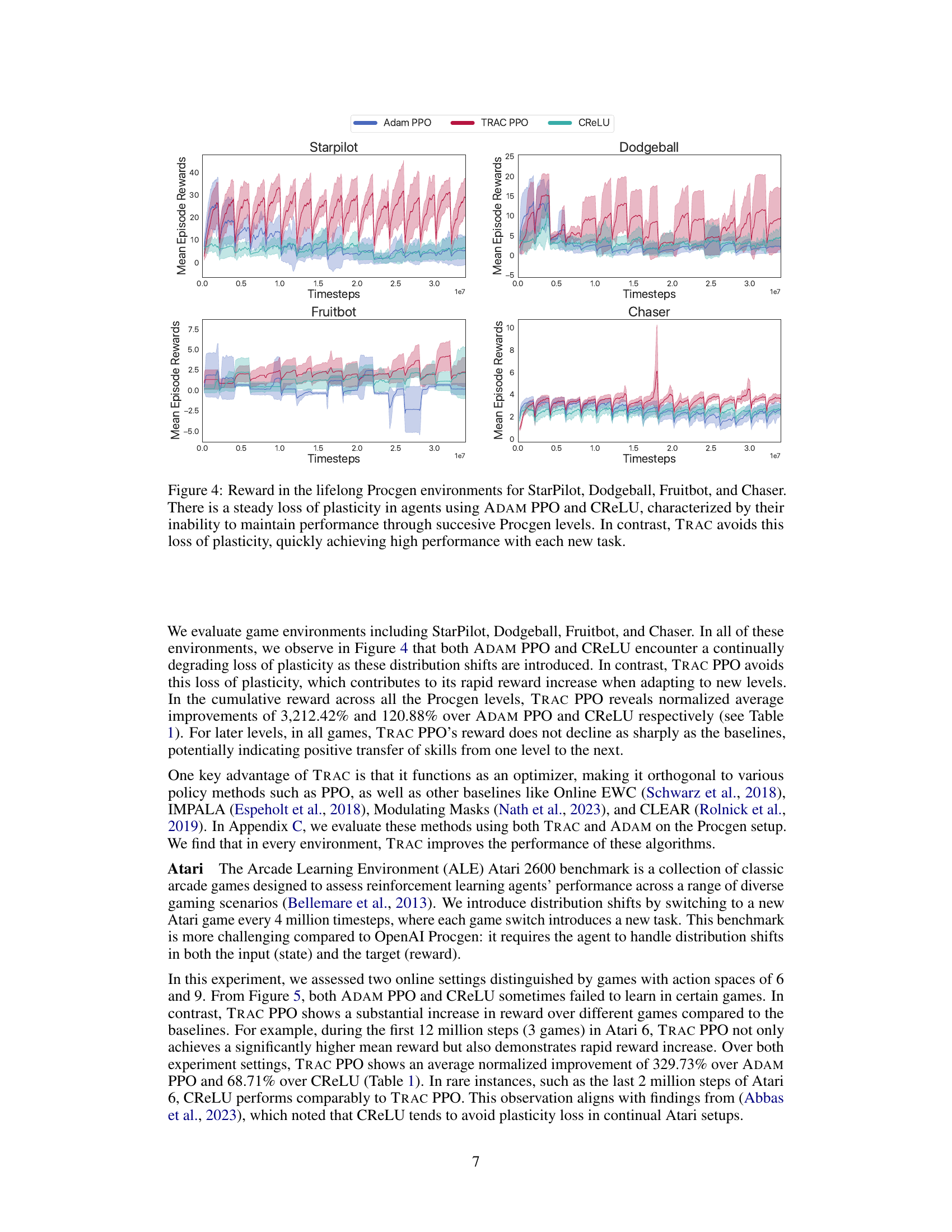
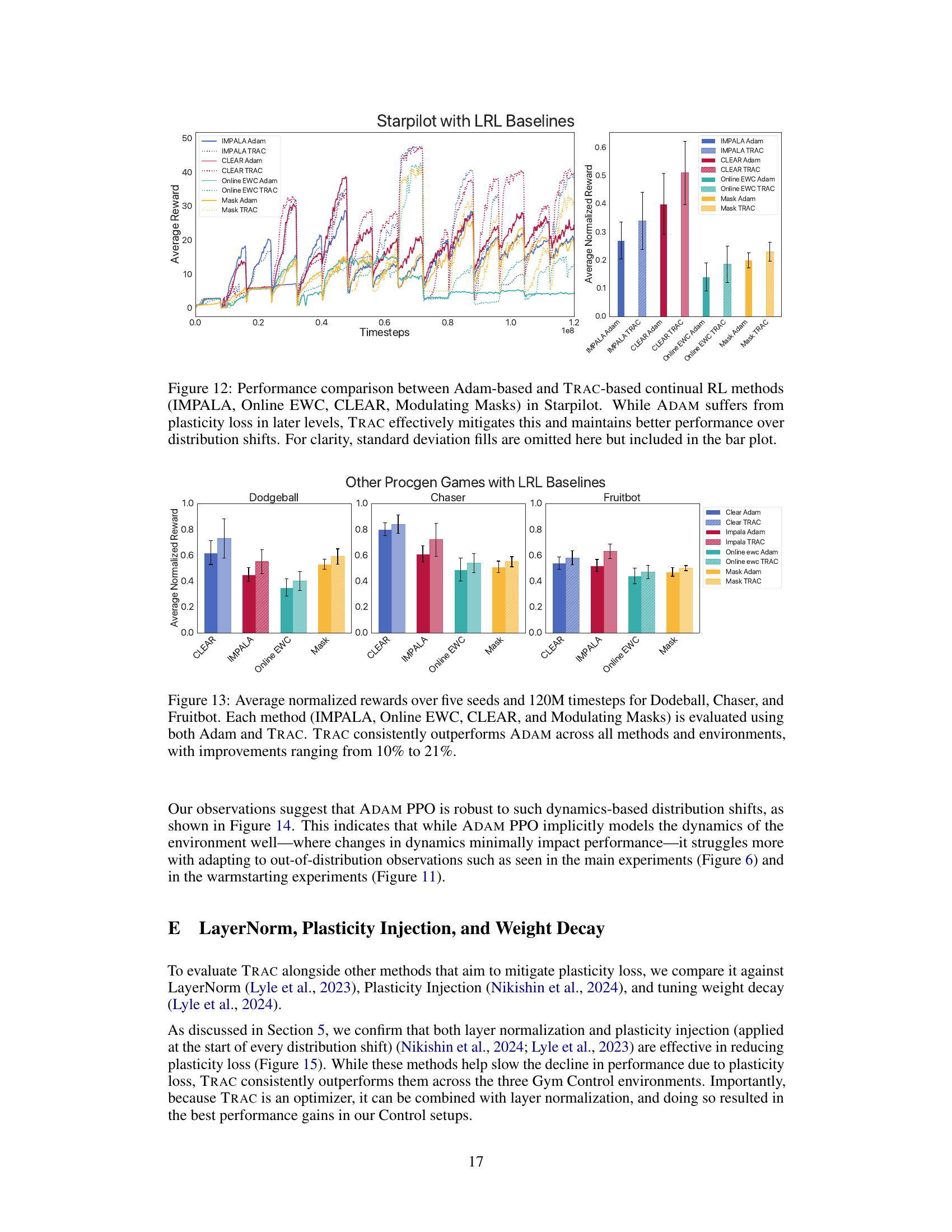
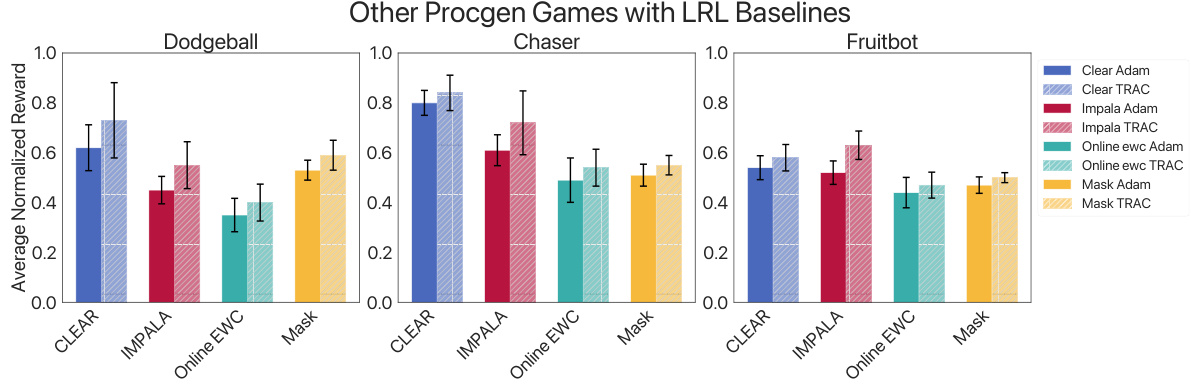
This figure compares the performance of three different algorithms (ADAM PPO, TRAC PPO, and CReLU) across four different Procgen environments (StarPilot, Dodgeball, Fruitbot, and Chaser) in a lifelong learning setting. Each environment presents a sequence of levels representing distribution shifts. The graph shows the mean episode rewards over time for each algorithm in each environment. ADAM PPO and CReLU exhibit a steady decline in performance as new levels are introduced, indicating a loss of plasticity. In contrast, TRAC PPO maintains or improves performance across levels, demonstrating its ability to adapt to distribution shifts and mitigate the loss of plasticity.

This figure shows the experimental setup used in the paper for lifelong reinforcement learning. It illustrates how distribution shifts are introduced in three different environments: Procgen, Atari, and Gym Control. In Procgen, distribution shifts are created by changing levels of the game. In Atari, distribution shifts occur by switching between different games. Finally, in Gym Control, distribution shifts are introduced by adding noise to observations during specific time intervals. The figure highlights the varied nature of distribution shifts across different environments used for the lifelong RL experiment in the paper.

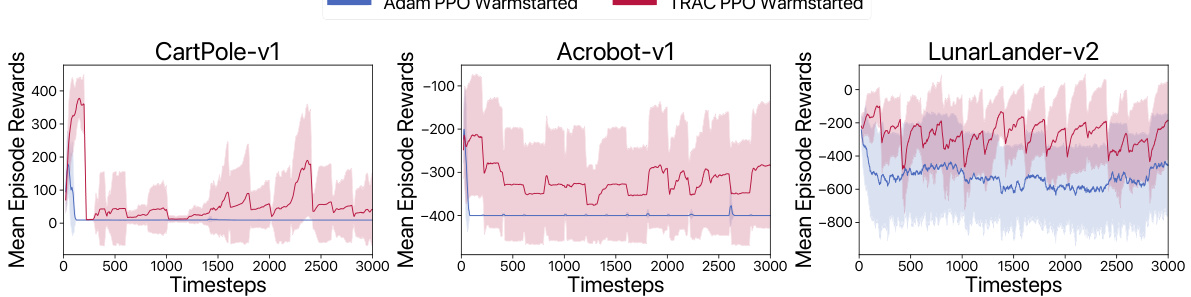
This figure compares the performance of ADAM PPO, CReLU, and TRAC PPO on three Gym Control environments: CartPole-v1, Acrobot-v1, and LunarLander-v2. Each environment is subjected to extreme distribution shifts. The results demonstrate that ADAM PPO and CReLU suffer significant plasticity loss, failing to recover after the initial shift. In contrast, TRAC PPO successfully avoids this loss and rapidly adapts to the new distribution. This highlights TRAC’s ability to mitigate the negative impact of prior learning on new tasks.

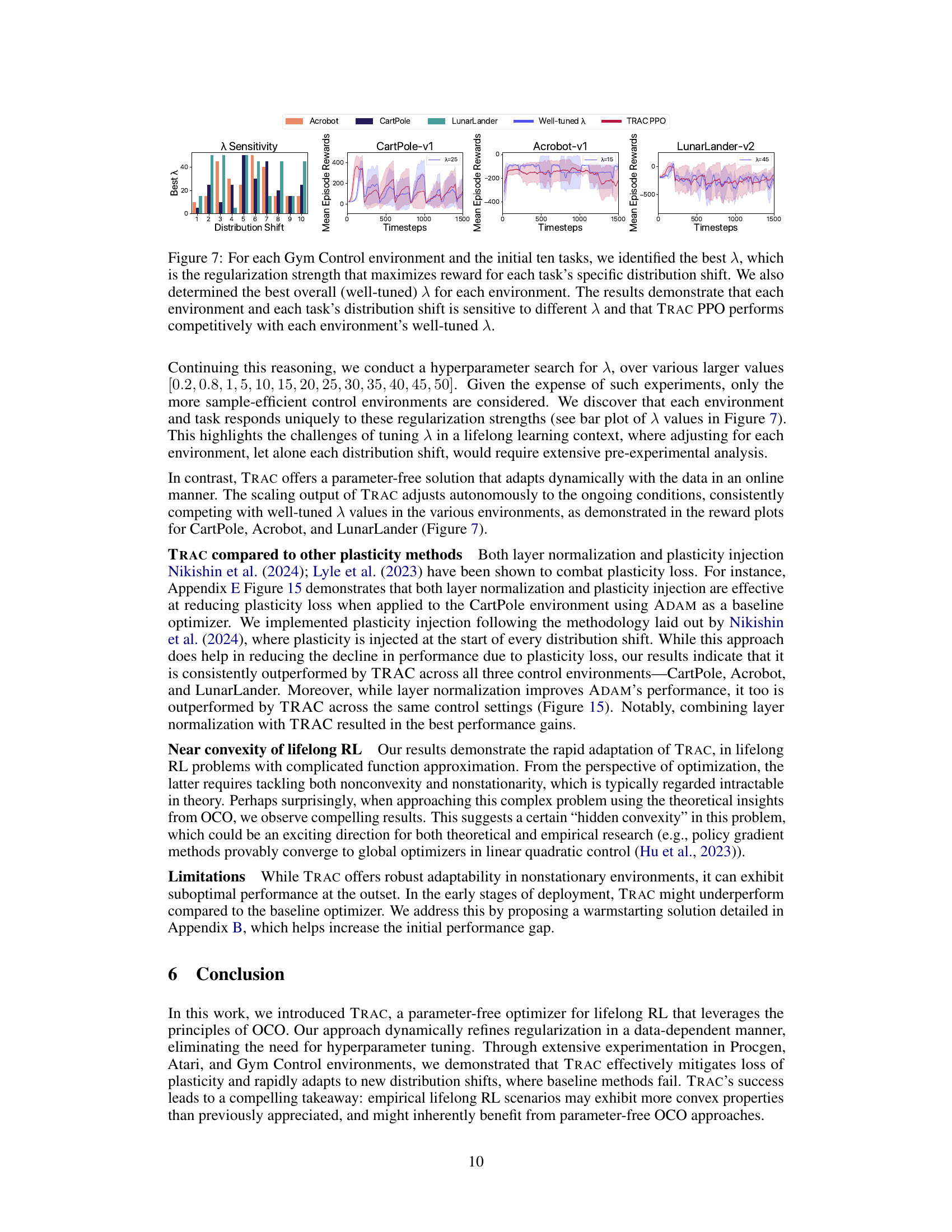
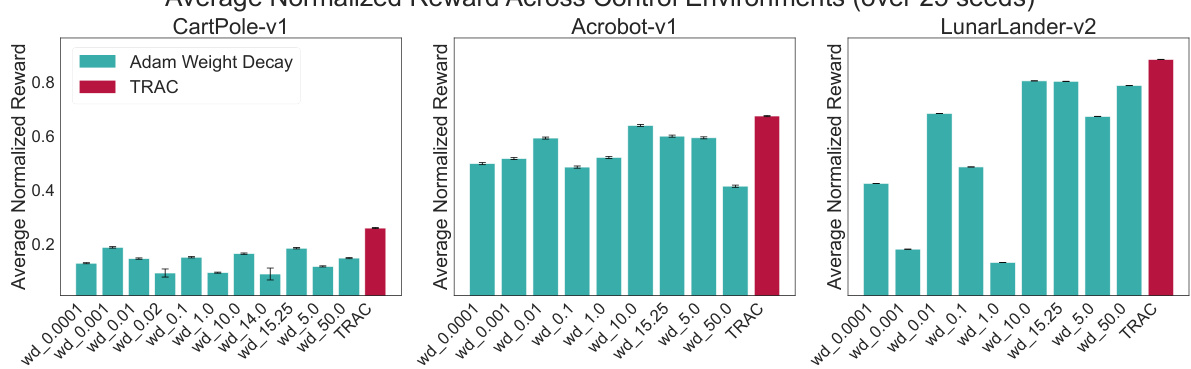
This figure visualizes the sensitivity of hyperparameter λ (regularization strength) in the L2 regularization approach across different Gym Control environments (CartPole, Acrobot, LunarLander) and distribution shifts (tasks). The bar chart shows the optimal λ values for each task within each environment, highlighting that the optimal λ significantly varies depending on both the environment and the specific task. The line plots further illustrate the performance of TRAC PPO in comparison to the well-tuned λ for each environment. This comparison demonstrates TRAC PPO’s ability to achieve competitive performance without the need for hyperparameter tuning.
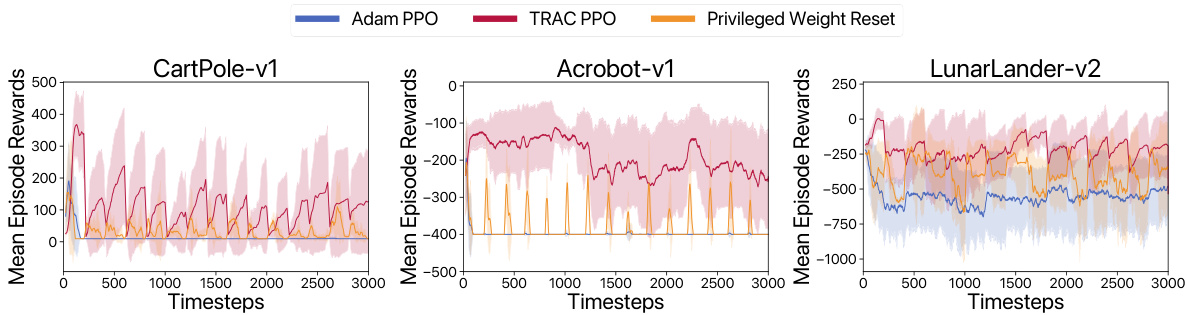
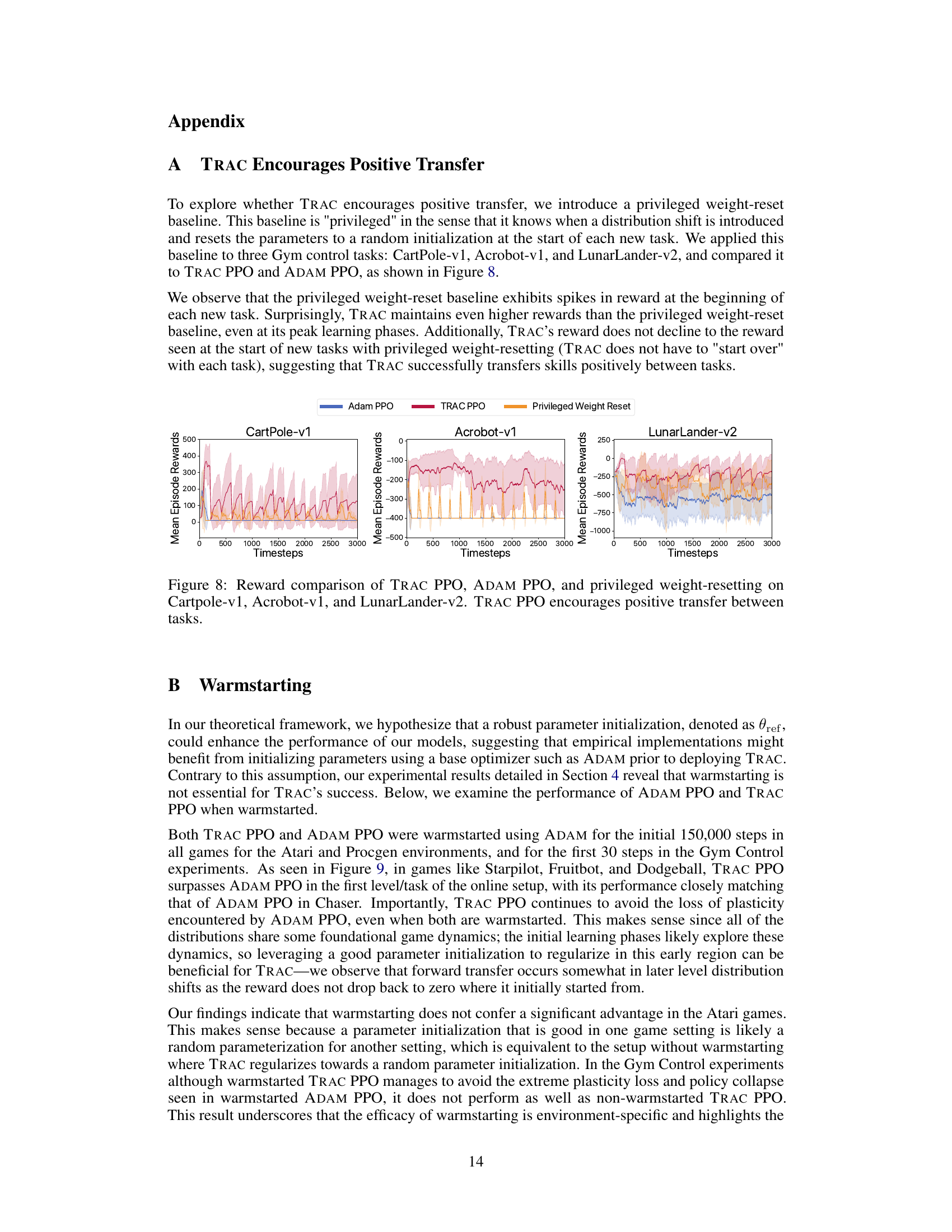
This figure compares the performance of TRAC PPO, ADAM PPO, and a privileged weight-reset baseline across three Gym control tasks: CartPole-v1, Acrobot-v1, and LunarLander-v2. The privileged weight-reset baseline represents an agent that knows when a distribution shift occurs and resets its parameters to random values at the start of each new task. The figure shows that TRAC PPO consistently achieves higher rewards than both ADAM PPO and the privileged weight-reset baseline, even at the peak learning phases of the privileged approach. Importantly, TRAC PPO’s reward does not decline to the reward level observed at the start of new tasks with the privileged weight-resetting baseline, indicating that TRAC effectively transfers skills positively between tasks.
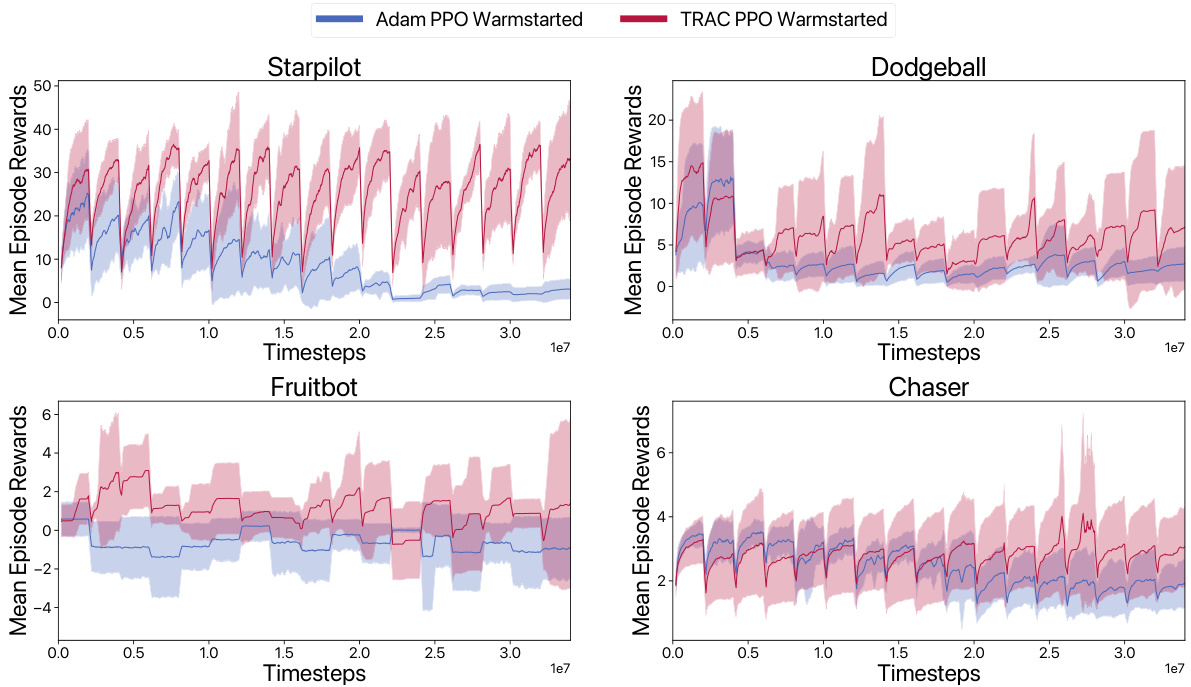
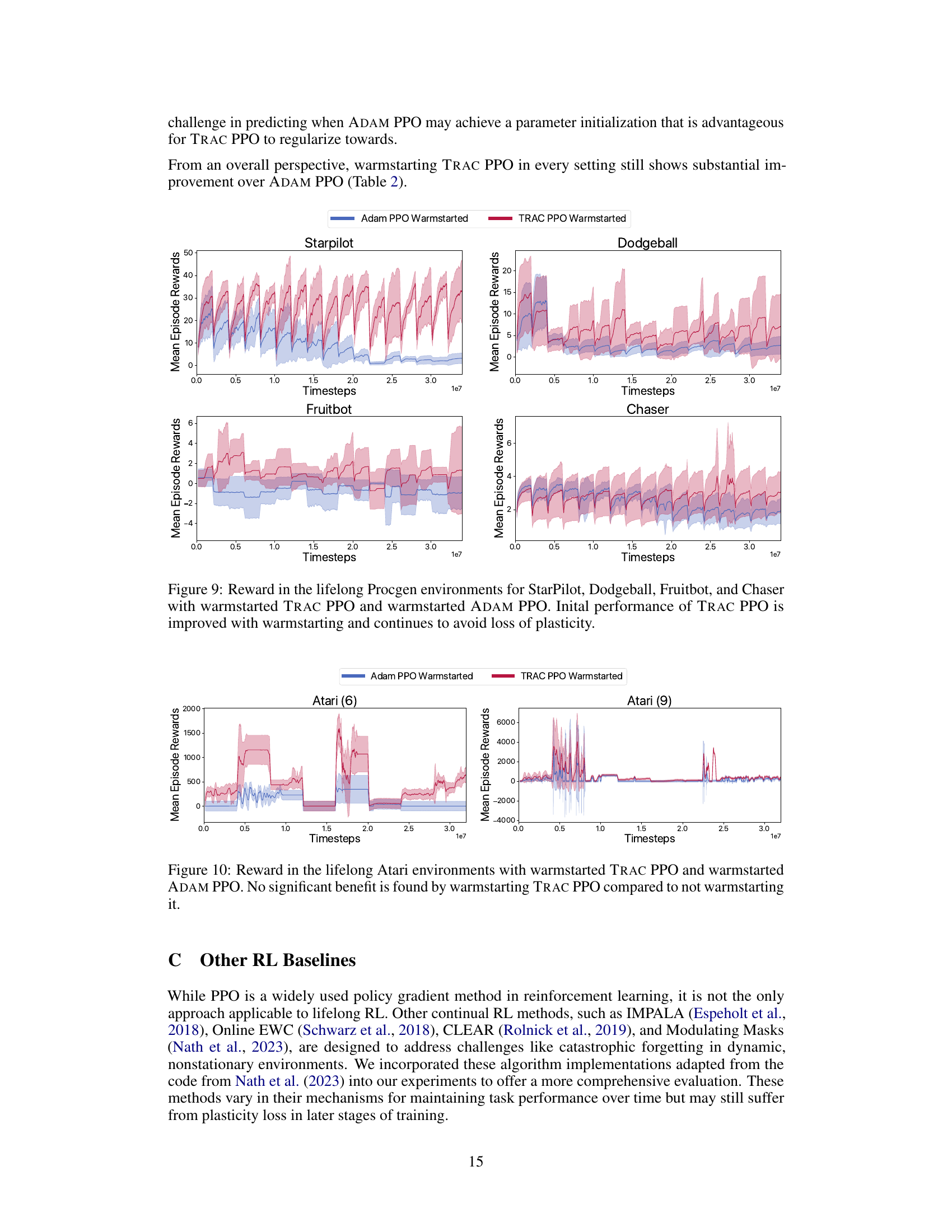
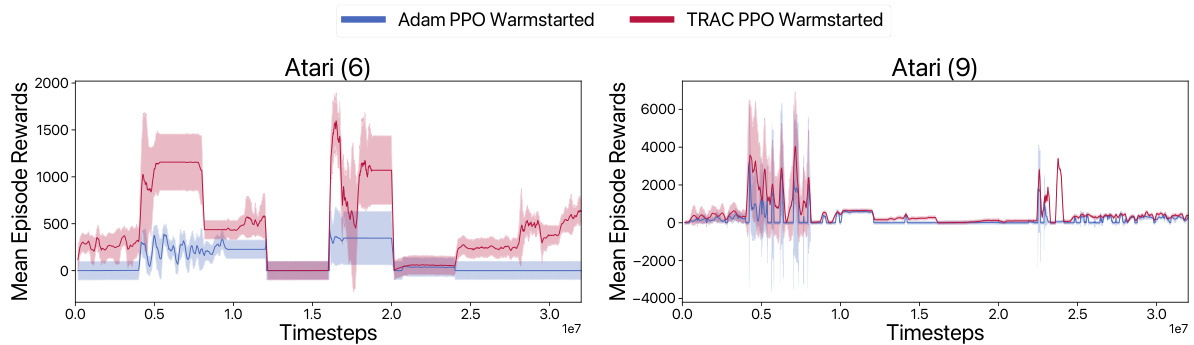
The figure shows the results of a lifelong reinforcement learning experiment on four Procgen environments: StarPilot, Dodgeball, Fruitbot, and Chaser. Two different optimization methods are compared: ADAM PPO (a baseline) and TRAC PPO (the proposed method). Both methods are tested with and without warmstarting. The graphs plot mean episode reward over time. The main observation is that TRAC PPO, especially when warmstarted, consistently outperforms ADAM PPO and maintains high performance across multiple distribution shifts, showing resilience to the common problem of loss of plasticity (where previous learning hinders adaptation to new tasks). Warmstarting provides a slight initial performance boost for both methods, but TRAC PPO’s advantage remains significant.
This figure shows the experimental setup used in the paper for lifelong reinforcement learning. It includes three different environments: Procgen, Atari, and Control. Each environment has a different way of introducing distribution shifts. Procgen introduces distribution shifts by generating new levels after every 2 million time steps. Atari introduces distribution shifts by switching to a new game every 4 million time steps. Control introduces distribution shifts by perturbing each observation dimension with random noise every 200 steps. The figure also shows that TRAC PPO is used in all three environments.
This figure compares the performance of TRAC PPO, ADAM PPO, and a privileged weight-resetting baseline across three Gym control tasks: CartPole-v1, Acrobot-v1, and LunarLander-v2. The privileged baseline represents a scenario where the agent is given the advantage of knowing when a distribution shift will occur and resets its parameters to a random initialization at the start of each new task. The results demonstrate that TRAC PPO consistently maintains higher rewards than the privileged baseline, even at its peak learning phases, avoiding the sharp drops in reward observed at the beginning of new tasks for the privileged approach. This suggests that TRAC successfully transfers skills positively between the tasks.
The figure shows the experimental setup for lifelong reinforcement learning using three different environments: Procgen, Atari, and Gym Control. Each environment presents unique challenges for an RL agent. Procgen provides procedurally generated games with distribution shifts introduced by changing game levels. Atari presents classic arcade games, where distribution shifts are introduced by switching between games. Gym Control provides physics-based control tasks, where distribution shifts are introduced through changes in environment dynamics. This setup allows for a comprehensive evaluation of the TRAC algorithm’s ability to handle diverse types of distribution shifts in lifelong RL.
The figure shows the experimental setup for lifelong reinforcement learning. It displays three different environments: Procgen, Atari, and Control. Each environment has a series of tasks with varying observation noise. The figure illustrates how distribution shifts are introduced in each environment and that TRAC-PPO is used as the proposed method compared to the baseline. It also shows that each level represents a distinct task.
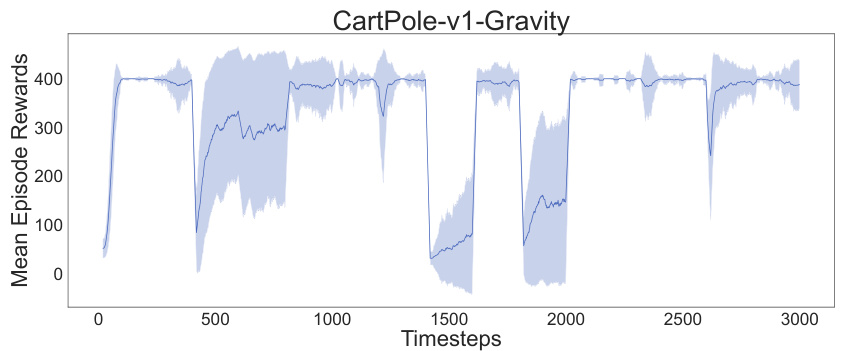
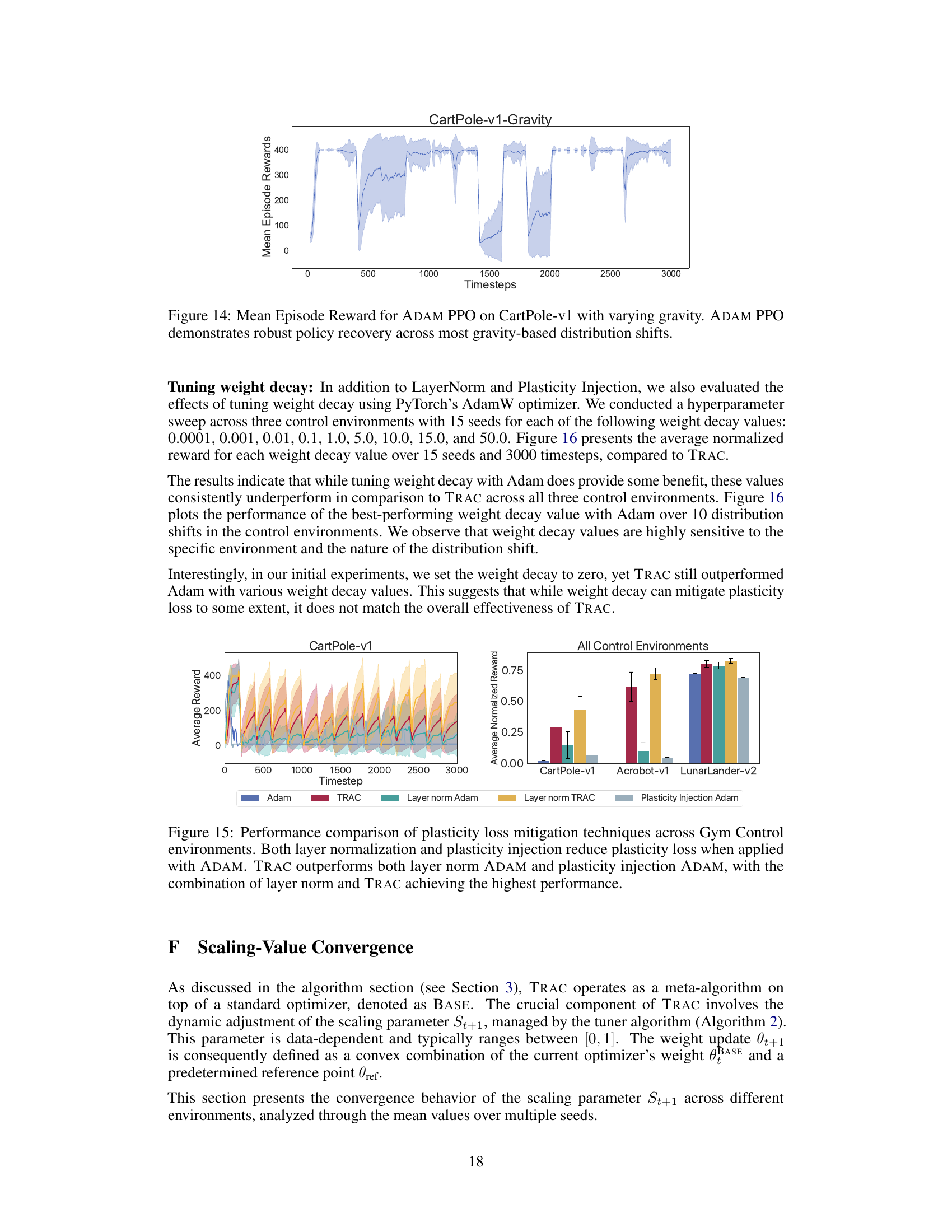
The figure shows the mean episode rewards for ADAM PPO in the CartPole-v1 environment with varying gravity. The gravity is manipulated periodically, introducing distribution shifts. ADAM PPO demonstrates a remarkable ability to quickly adapt to and recover from these changes in gravity. The shaded area represents the standard deviation.
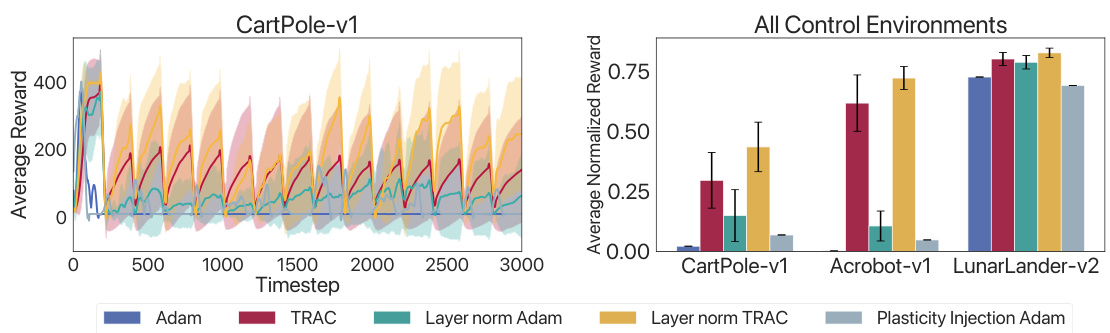
This figure compares the performance of different methods for mitigating plasticity loss in three Gym Control environments: CartPole-v1, Acrobot-v1, and LunarLander-v2. It shows that while Layer Normalization and Plasticity Injection (both used with the ADAM optimizer) help reduce the performance decline caused by plasticity loss, TRAC consistently outperforms these methods. The best performance is achieved when TRAC is combined with Layer Normalization. The graph visually shows the average reward over multiple runs for each method in each environment. The bar chart summarizes the average normalized rewards across all environments.
The figure shows the experimental setup used for lifelong reinforcement learning (RL). It depicts three different environments: Procgen, Atari, and Gym Control. In each environment, distribution shifts are introduced by changing the game level (Procgen), game (Atari), or adding noise to observations (Gym Control). This setup allows for evaluating the performance of lifelong RL algorithms in diverse settings and under different types of distribution shifts. The figure highlights the non-stationary nature of the problem and the need for algorithms that can adapt quickly to changes in the environment.
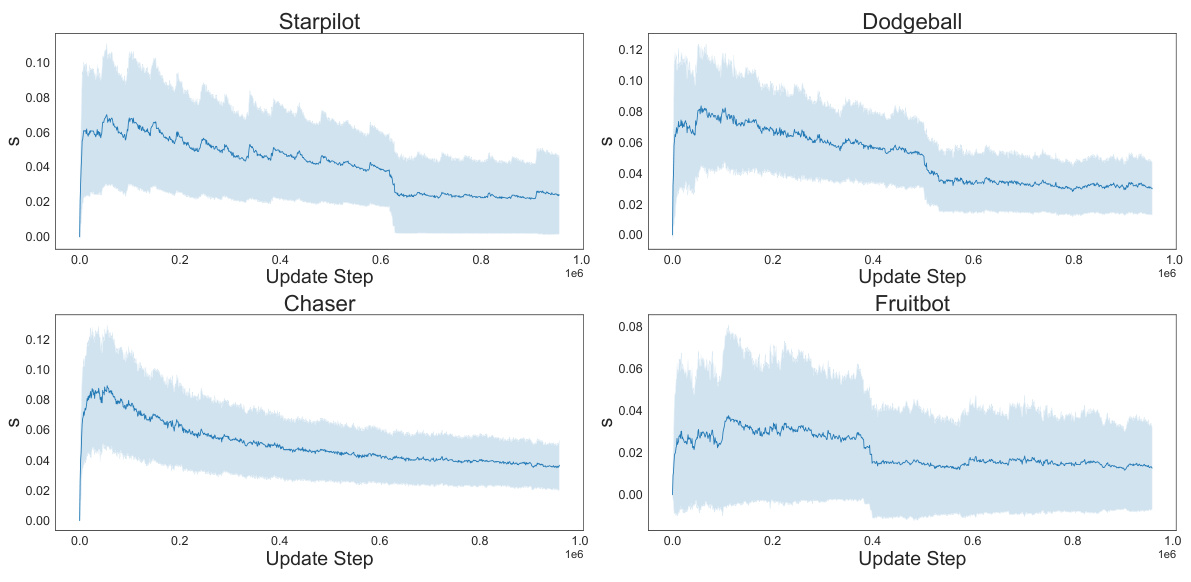
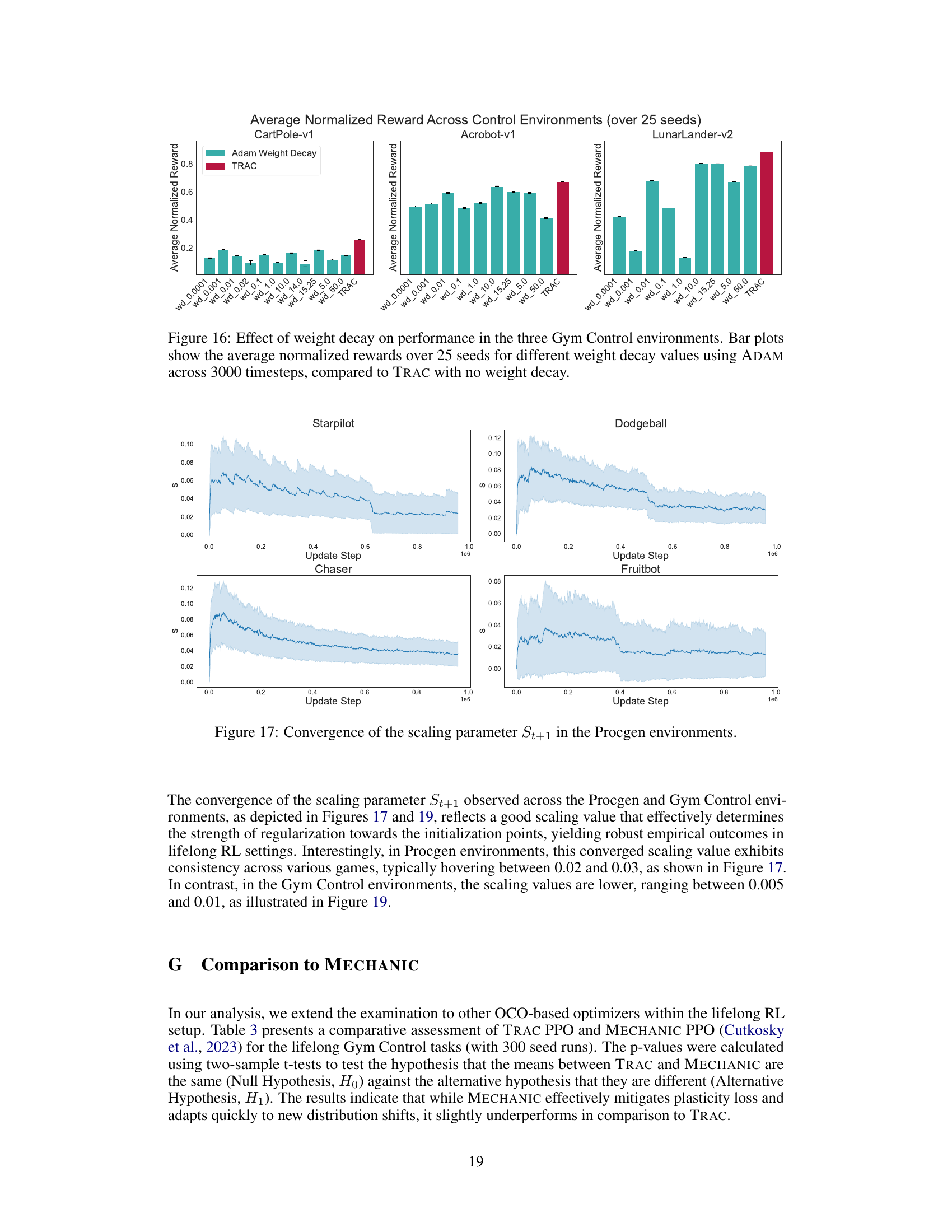
The figure visualizes the convergence behavior of the scaling parameter St+1 across four different Procgen environments: Starpilot, Dodgeball, Chaser, and Fruitbot. The x-axis represents the update step, and the y-axis represents the value of St+1. The shaded area indicates the standard deviation across multiple runs. The plots show that the scaling parameter generally converges to a relatively stable value within a range of 0.02 to 0.03 across all four environments, suggesting that the strength of regularization towards the initialization point is consistently maintained during the training process.
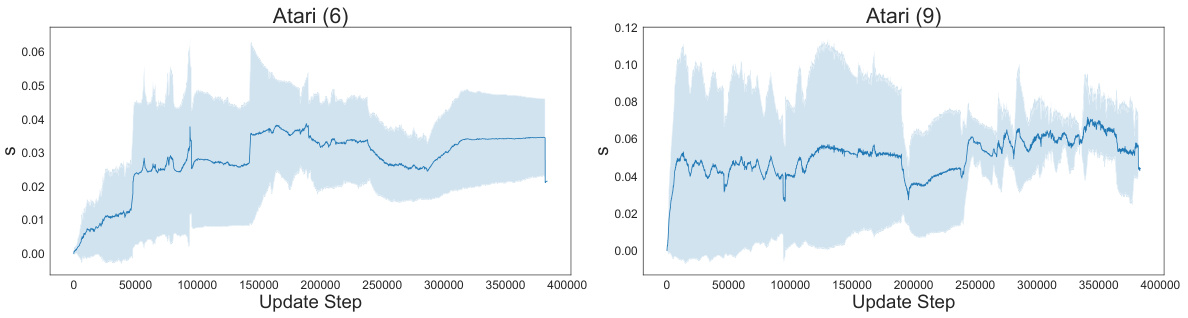
This figure visualizes the convergence behavior of the scaling parameter (St+1) within the TRAC algorithm across four different Procgen environments (Starpilot, Dodgeball, Chaser, and Fruitbot). The x-axis represents the update step, and the y-axis shows the value of St+1. The plots illustrate the convergence of St+1 toward a relatively stable value within each environment, indicating the stability of the regularization mechanism implemented by TRAC. These stable values generally fall within the range of [0.02, 0.03], indicating the effective strength of regularization.

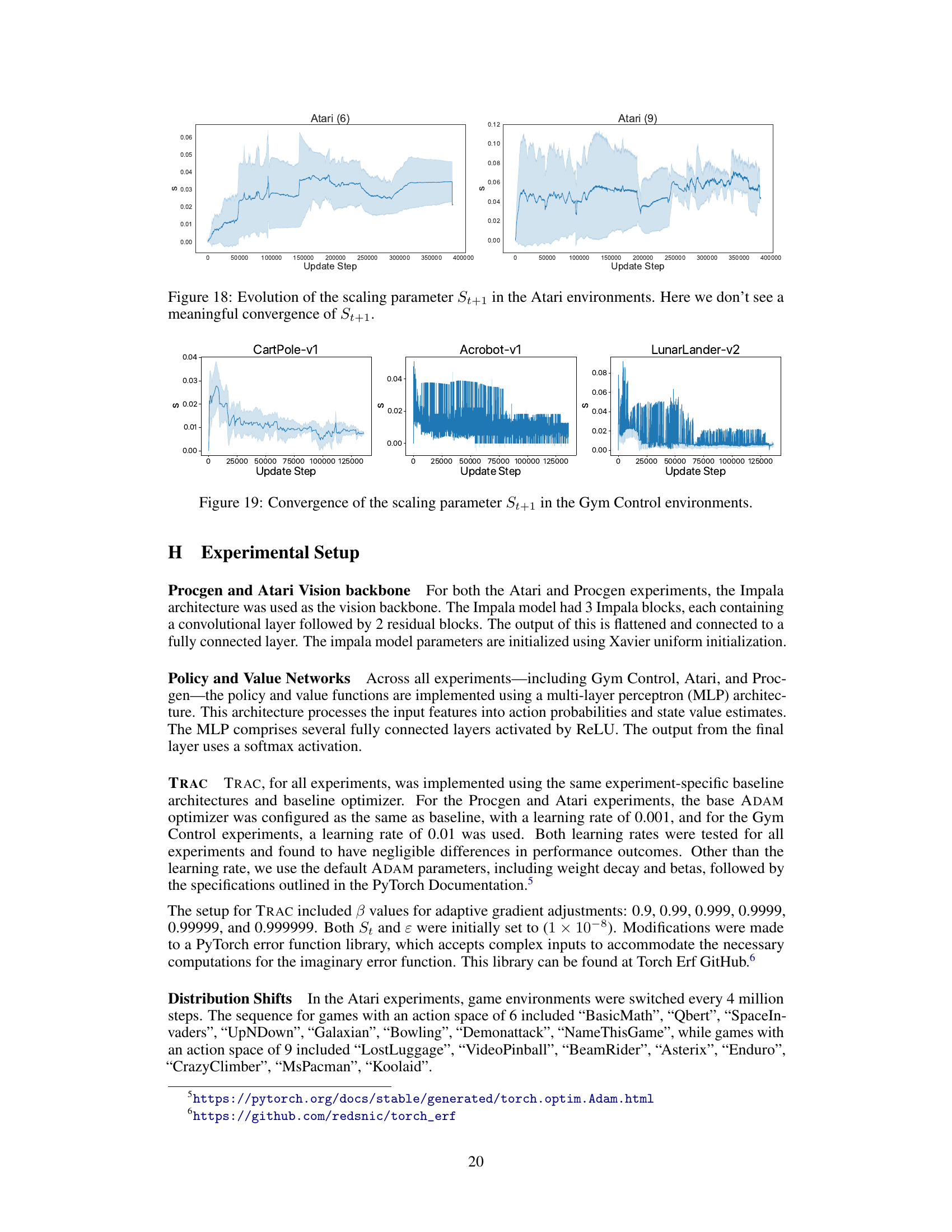
The figure shows the convergence behavior of the scaling parameter (St+1) across three different Gym Control environments: CartPole-v1, Acrobot-v1, and LunarLander-v2. The x-axis represents the update step, while the y-axis shows the value of St+1. The plots illustrate how this crucial parameter, which regulates the strength of regularization toward the initialization points, behaves across the various control environments. In essence, it visually demonstrates the parameter’s convergence during the optimization process within each environment.
More on tables
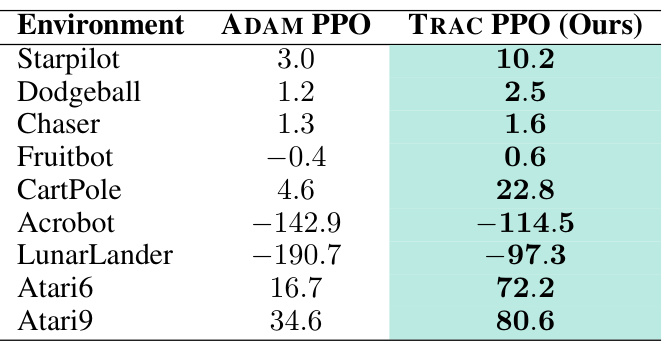
This table presents a comparison of the cumulative sum of mean episode rewards achieved by three different methods: TRAC PPO, ADAM PPO, and CReLU, across various reinforcement learning environments. The environments are categorized into Procgen (vision-based games), Atari (classic arcade games), and Gym Control (physics-based control tasks). Higher values indicate better performance. The rewards are scaled by a factor of 105 for easier interpretation.
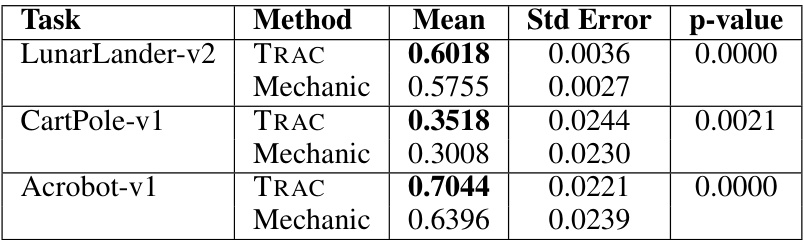
This table presents a comparison of TRAC and MECHANIC, two optimization algorithms, across three Gym Control environments: LunarLander-v2, CartPole-v1, and Acrobot-v1. The table shows the mean reward achieved by each algorithm in each environment, along with the standard error and the p-value from a statistical test comparing the two. The bolded values indicate where TRAC significantly outperforms MECHANIC.

This table summarizes the cumulative sum of mean episode rewards achieved by three different methods (TRAC PPO, ADAM PPO, and CReLU) across three sets of reinforcement learning environments: Procgen, Atari, and Gym Control. The rewards are scaled by a factor of 105 for easier comparison. Higher values indicate better performance.
Full paper#