TL;DR#
Resolving issues in large software repositories like GitHub is challenging. Large Language Models (LLMs), while promising in code generation, struggle with the complexity of repository-level issue resolution. Existing methods often fail to adequately address this challenge, leaving a significant gap in automating software maintenance and evolution.
To tackle this, the researchers introduce MAGIS, a multi-agent framework designed to resolve GitHub issues. MAGIS uses four specialized agents (Manager, Repository Custodian, Developer, and QA Engineer) that collaborate using LLMs to locate relevant files, plan code changes, generate code, and conduct quality assurance. The framework significantly improves the resolved ratio compared to using individual LLMs and demonstrates the advantages of a collaborative, multi-agent approach for complex software tasks. This work is a considerable step towards automating software evolution and maintenance tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on Large Language Models (LLMs) and software engineering. It directly addresses the limitations of LLMs in handling complex repository-level tasks, such as resolving GitHub issues, a significant challenge in software development. The proposed MAGIS framework offers a novel approach with potential to significantly improve LLM applications in software evolution and maintenance, opening exciting new research avenues in multi-agent systems and LLM-assisted software development.
Visual Insights#
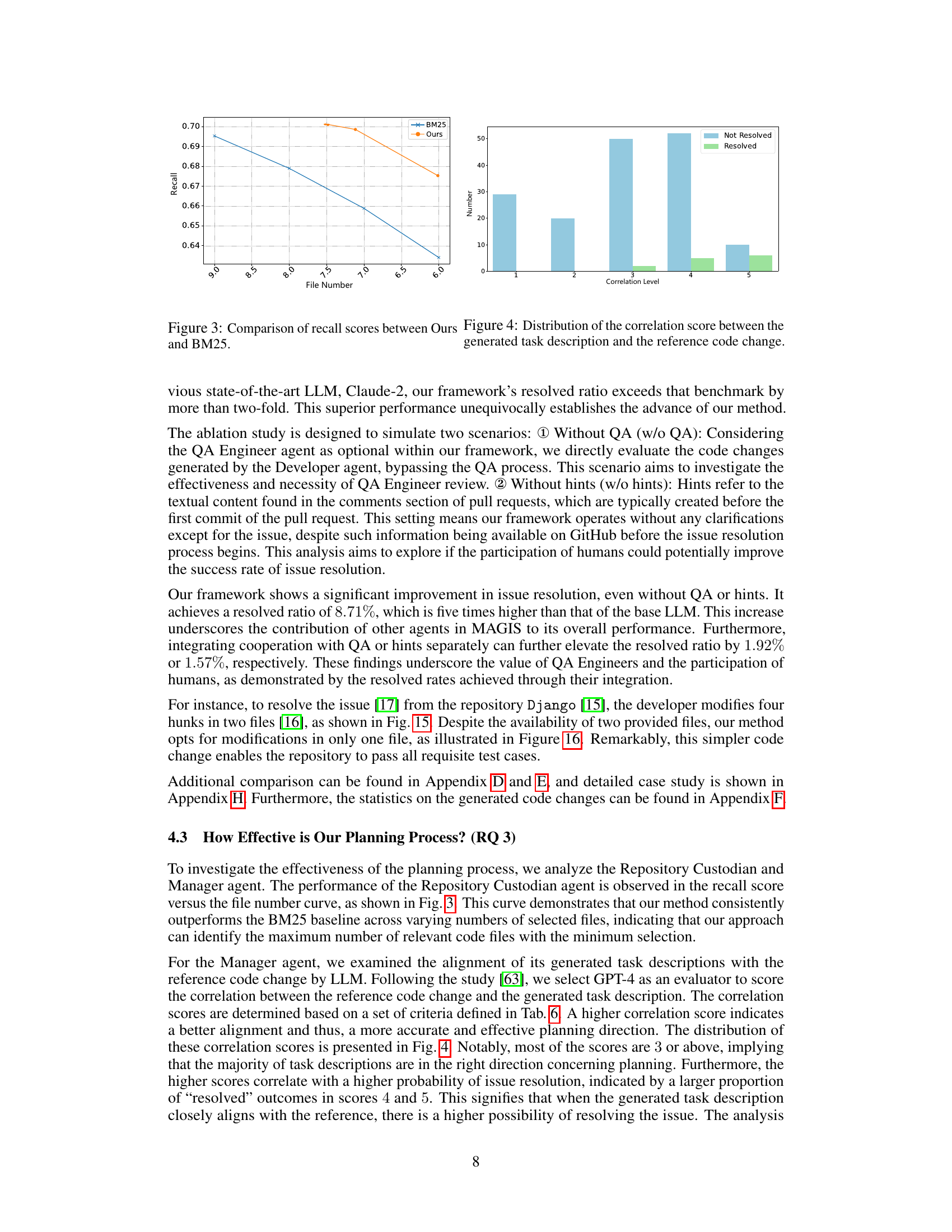
🔼 This figure compares the line locating coverage ratios achieved by three different LLMs (GPT-3.5, GPT-4, and Claude-2). The x-axis shows the coverage ratio, ranging from 0 to 1 (0 representing no overlap and 1 representing perfect overlap between generated and reference lines). The y-axis represents the frequency of instances with each coverage ratio. The graph helps visualize the accuracy of each LLM in identifying the correct lines of code to modify during GitHub issue resolution. A higher proportion of instances with ratios closer to 1 indicates better accuracy in line location.
read the caption
Figure 1: The comparison of line locating coverage ratio between three LLMs. The vertical axis representing the frequency of the range of line locating coverage ratio for each group, and the horizontal axis representing the line locating coverage ratio.

🔼 This table presents the correlation coefficients between various complexity metrics (number of files, functions, hunks, added lines of code, deleted lines of code, and changed lines of code) and the success of issue resolution. The analysis was performed using logistic regression due to the skewed distribution of the data and the binary nature of the outcome (resolved/not resolved). Asterisks (*) indicate statistically significant correlations (p-value < 0.05). The table shows how the complexity of the code changes impacts the ability of LLMs to resolve GitHub issues.
read the caption
Table 1: Correlation between the complexity indices and the issue resolution.
In-depth insights#
LLM Issue Solving#
LLM-based issue resolution in software development presents a complex challenge. While LLMs excel at code generation, their effectiveness in addressing repository-level issues, such as those found on GitHub, remains limited. Direct application of LLMs often fails due to constraints imposed by context length and the need for advanced code understanding beyond simple function-level tasks. This necessitates a more sophisticated approach, likely involving multi-agent frameworks. The development of such frameworks requires careful consideration of agent roles and collaboration strategies, potentially mirroring human workflows, to overcome LLM limitations. The evaluation of these multi-agent systems requires robust benchmarks that assess both the efficiency and effectiveness of issue resolution, going beyond simple success/failure metrics and considering factors such as the complexity of the code changes and the speed of resolution. Future work should focus on enhancing LLMs’ ability to handle long-context inputs, developing more sophisticated agent designs, and creating more comprehensive benchmarks to fully realize the potential of LLMs in improving software development processes.
Multi-Agent Design#
A thoughtful multi-agent design is crucial for effectively leveraging LLMs in complex tasks like GitHub issue resolution. Collaboration among specialized agents—a manager for coordination, a repository custodian for efficient file location, developers for code modification, and quality assurance engineers for review—is key. Each agent’s role is carefully defined to utilize LLMs’ strengths while mitigating weaknesses. The manager’s role, in particular, is pivotal in orchestrating the entire process, decomposing complex tasks, and ensuring efficient collaboration among agents. Careful agent design considers the limitations of LLMs regarding context length and computational cost, prompting optimization strategies. The framework’s structure mirrors established human workflows, highlighting the importance of collaboration in problem-solving. Empirical evaluation demonstrates that the multi-agent approach significantly outperforms single-agent baselines, validating the design’s effectiveness in addressing the challenges of repository-level code changes.
SWE-Bench Results#
An analysis of SWE-Bench results would involve a detailed examination of the methodology, metrics, and the overall performance of various Large Language Models (LLMs) on the dataset. Key aspects to consider include the dataset’s composition, the specific tasks LLMs were asked to perform (e.g., resolving GitHub issues), and the evaluation metrics used. A critical analysis should highlight not only the quantitative results (e.g., accuracy, F1-score), but also the qualitative aspects, such as the types of errors made by different models. Understanding the limitations of the SWE-Bench dataset itself is crucial, exploring factors such as the representativeness of the included GitHub repositories and the extent to which the tasks reflect real-world software development challenges. Furthermore, a thoughtful analysis would compare the performance of different LLMs, potentially correlating performance with architectural differences or training methodologies. Examining the reasons behind discrepancies in LLM performance is paramount; are some models better at specific types of issues, and if so, why? Finally, the analysis should discuss the implications of these findings for the broader field of LLM applications in software engineering.
Code Complexity#
Analyzing code complexity within the context of a research paper focusing on GitHub issue resolution reveals crucial insights into the challenges of automated code modification. Increased code complexity, measured by metrics such as the number of modified files, functions, and lines of code, strongly correlates with a decreased likelihood of successful issue resolution. This highlights the limitations of Large Language Models (LLMs) when tackling intricate code changes within extensive repositories. The research likely investigates how various agents within a proposed multi-agent framework address these challenges by breaking down complex tasks into smaller, manageable subtasks. A deeper exploration might analyze the types of complexities that pose the biggest challenges for LLMs, perhaps distinguishing between syntactic complexity (e.g., deeply nested structures) versus semantic complexity (e.g., intricate logical flow or interactions with numerous modules). The study likely also assesses the effectiveness of different strategies for managing complexity, such as code refactoring, modularization, and the use of comments to enhance code readability and understandability. Ultimately, understanding code complexity is critical to creating effective systems for automated software maintenance and repair.
Future Work#
Future research could explore several promising avenues. Extending MAGIS to handle a broader range of programming languages and software project types is crucial for wider applicability. Currently, the framework’s performance is evaluated primarily on Python projects. Investigating its effectiveness on other languages like Java, C++, or JavaScript, and diverse software architectures (e.g., microservices), would significantly broaden its impact. Improving the robustness of the system to deal with complex and ambiguous issue descriptions is another key area. The current framework’s success hinges on clear issue descriptions. A deeper investigation into natural language processing techniques for improved issue understanding and task decomposition is needed. Integrating more sophisticated code analysis tools within the framework could enhance the accuracy and efficiency of code changes. Current line locating and modification heavily relies on LLMs, and supplementing this with static and dynamic analysis tools would improve precision and reduce the likelihood of introducing unintended side effects. Finally, a thorough investigation into the impact of the QA Engineer agent is warranted. While the ablation study shows a positive effect, a deeper analysis into specific scenarios where QA improves success rate would offer more actionable insight. Quantifying this improvement would also lead to more effective framework optimization.
More visual insights#
More on figures

🔼 This figure presents a detailed flowchart of the MAGIS framework. It illustrates the process of resolving GitHub issues, starting from issue identification and ending with code merging into the repository. The process is divided into two main stages: Planning and Coding. The Planning stage involves locating relevant code files, assembling a team of agents (Manager, Repository Custodian, Developer, and Quality Assurance Engineer), and conducting a kick-off meeting to coordinate tasks. The Coding stage consists of code generation, review, and iterative refinement by the collaboration of Developers and QA Engineers. Each stage contains multiple steps and agent interactions, shown in detail in the flowchart. The figure is linked to Figure 7 (Kick-off Meeting), suggesting a detailed view of the kick-off process is shown in Figure 7.
read the caption
Figure 14: Detailed overview of our framework, MAGIS (Kick-off meeting refers to Fig. 7).
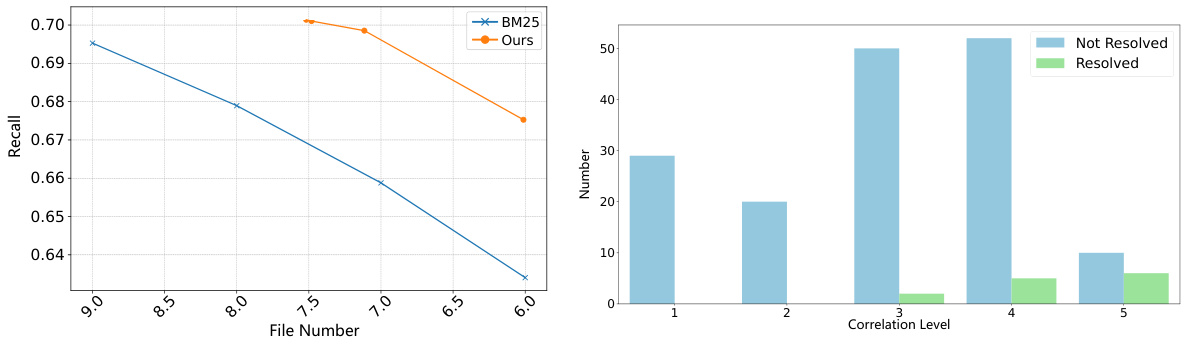
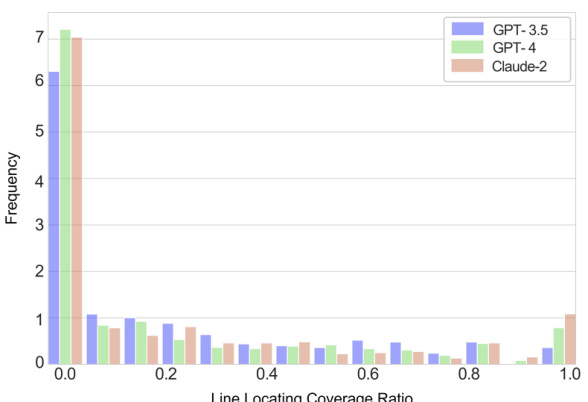
🔼 The figure shows the comparison of recall scores between the proposed method and the BM25 method for locating relevant files. The x-axis represents the number of files, and the y-axis represents the recall score. The graph demonstrates that the proposed method consistently outperforms BM25 across different numbers of files considered.
read the caption
Figure 3: Comparison of recall scores between Ours and BM25.

🔼 This figure compares the distribution of line locating coverage ratios achieved by MAGIS and three baseline LLMs (GPT-4, Claude-2, and GPT-3.5). The x-axis represents the line locating coverage ratio, while the y-axis shows the frequency of instances with that ratio. MAGIS demonstrates a much higher frequency of instances with coverage ratios close to 1, indicating superior accuracy in locating the relevant lines of code that need modification. The baselines show more instances with lower coverage ratios, implying less accurate line location.
read the caption
Figure 5: Comparison of line locating coverage between MAGIS (Ours) and baselines.

🔼 This figure presents a detailed illustration of the MAGIS framework, depicting the workflow of each agent across the planning and coding phases. It expands on the high-level overview given in Figure 2, showing the interaction of the four agents, the information flow between them, the decision-making process, and the iterative refinement of code changes. The figure provides a more thorough understanding of the framework’s operations.
read the caption
Figure 14: Detailed overview of our framework, MAGIS (Kick-off meeting refers to Fig. 7).
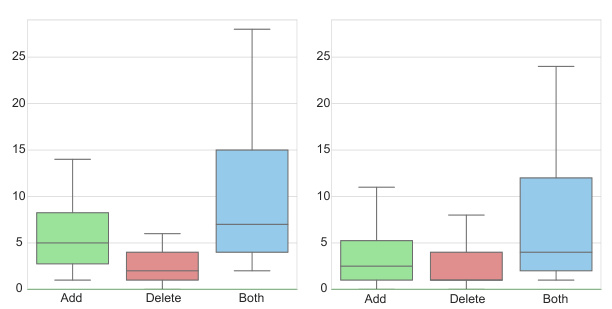
🔼 This figure shows the distribution of the number of lines of code (LoC) modified in instances where the GitHub issue was successfully resolved. It helps to understand the complexity of the code changes handled by the MAGIS framework in successful cases. The distribution is broken down by whether lines were added, deleted, or both, providing insights into the types of code modifications the framework effectively addresses.
read the caption
Figure 8: Distribution of the LoC in the resolved instances.
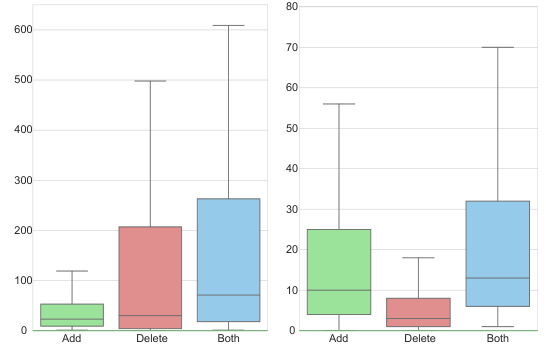
🔼 This figure shows the distribution of Lines of Code (LoC) changes in resolved instances, broken down into added, deleted, and both added and deleted lines. The distribution helps to illustrate the complexity of the code changes involved in successfully resolving issues using the MAGIS framework. It provides a visual representation of the frequency of different LoC change magnitudes in resolved instances, allowing for a comparison with unsuccessful attempts (shown in Figure 9).
read the caption
Figure 8: Distribution of the LoC in the resolved instances.

🔼 This figure presents a detailed illustration of the MAGIS framework, outlining the roles of each agent (Manager, Repository Custodian, Developer, QA Engineer) and their collaboration throughout the planning and coding phases. It expands on Figure 2, providing a more comprehensive visual representation of the entire process, from issue identification and team formation to code generation, review, and integration. The detailed steps in locating code files and lines, as well as the kick-off meeting process, are also shown. This allows for a clearer understanding of the agent interactions and the overall workflow within MAGIS.
read the caption
Figure 14: Detailed overview of our framework, MAGIS (Kick-off meeting refers to Fig. 7).

🔼 This figure presents a detailed illustration of the MAGIS framework. It breaks down the process into planning and coding phases. The planning phase includes locating code files, building a team, and conducting a kick-off meeting. The coding phase involves code generation, QA engineer review, and testing. The diagram shows the interactions between different agent types (Manager, Repository Custodian, Developer, QA Engineer) and how they contribute to resolving GitHub issues. Specific prompts used by each agent are also shown in this detailed illustration.
read the caption
Figure 14: Detailed overview of our framework, MAGIS (Kick-off meeting refers to Fig. 7).

🔼 This figure shows a bar chart visualizing the number of applied and resolved instances across various software repositories. The x-axis represents the different repositories, while the y-axis displays the counts for both applied and resolved instances. The different bar colors represent resolved and applied instances respectively. The chart highlights the variation in success rates of the MAGIS framework across different codebases, indicating potential influence of repository-specific factors on the framework’s performance.
read the caption
Figure 13: The number of applied and resolved instances in different repositories.
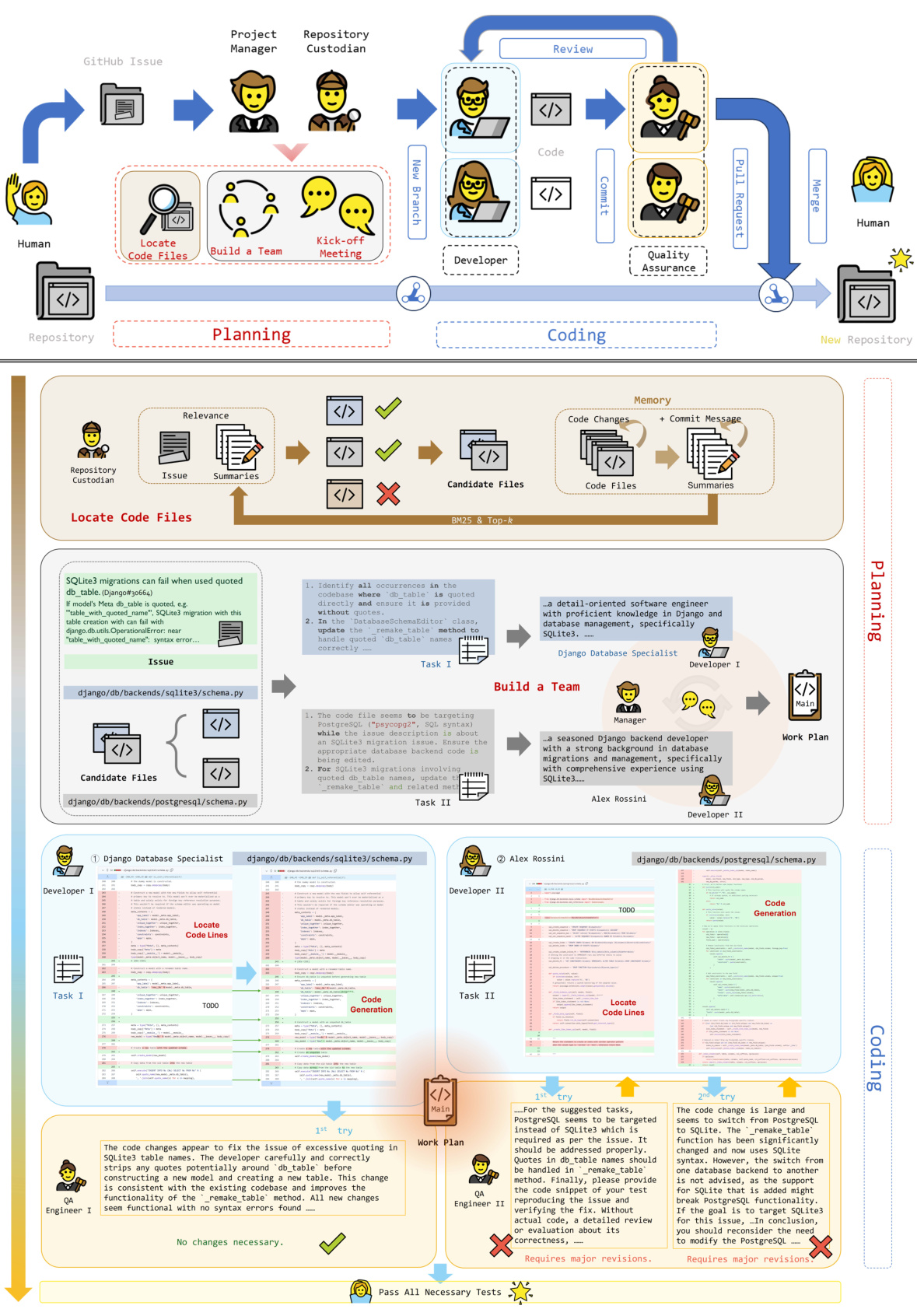
🔼 This figure presents a detailed illustration of the MAGIS framework, expanding on the high-level overview in Figure 2. It breaks down the multi-agent collaboration process into distinct phases, including planning and coding. The planning phase involves the Manager and Repository Custodian agents in locating relevant files and generating summaries, followed by building a team of developers and holding a kick-off meeting to define tasks and the overall workflow. The coding phase depicts the collaboration of developers, quality assurance engineers, and the manager in generating and reviewing code changes. The figure also shows the memory mechanism utilized for efficiently querying files. This detailed view clarifies the roles and interactions of each agent in the workflow, providing a comprehensive visual representation of the MAGIS framework.
read the caption
Figure 14: Detailed overview of our framework, MAGIS (Kick-off meeting refers to Fig. 7).

🔼 This figure presents a detailed overview of the MAGIS framework. It visually depicts the workflow of the four agents (Manager, Repository Custodian, Developer, and QA Engineer) involved in resolving GitHub issues. The diagram breaks down the process into planning and coding phases, illustrating the interactions and data flow between each agent. The planning phase shows the issue being received, relevant files identified, tasks assigned, and a kick-off meeting held to establish the plan. The coding phase outlines the steps taken by Developers and QA Engineers to generate and review code changes. The figure provides a comprehensive view of the multi-agent collaboration in solving GitHub issues.
read the caption
Figure 14: Detailed overview of our framework, MAGIS (Kick-off meeting refers to Fig. 7).

🔼 This figure presents a detailed overview of the MAGIS framework, illustrating the interactions between the four agents (Manager, Repository Custodian, Developer, and QA Engineer) across the planning and coding phases. The planning phase involves locating code files using the BM25 algorithm, building a team of agents, and holding a kick-off meeting to define tasks and workflows. The coding phase shows the iterative process of code generation, review by the QA Engineer, and merging of code changes. The figure highlights the collaborative nature of the process and the roles each agent plays in resolving GitHub issues.
read the caption
Figure 14: Detailed overview of our framework, MAGIS (Kick-off meeting refers to Fig. 7).
More on tables

🔼 This table presents the correlation coefficients between various complexity metrics (number of files, functions, hunks, added lines of code, deleted lines of code, and changed lines of code) and the success of issue resolution for three different LLMs (GPT-3.5, GPT-4, and Claude-2). A negative correlation indicates that as complexity increases, the likelihood of successful issue resolution decreases. The asterisk (*) indicates statistical significance (p-value < 0.05).
read the caption
Table 1: Correlation between the complexity indices and the issue resolution.

🔼 This table presents the correlation coefficients between various complexity indices (number of files, functions, hunks, added lines of code, deleted lines of code, and changed lines of code) and the success rate of issue resolution for three different LLMs (GPT-3.5, GPT-4, and Claude-2). A statistically significant correlation (p-value < 0.05) is indicated by an asterisk (*). The negative correlations observed suggest that increased code complexity hinders the resolution of issues.
read the caption
Table 1: Correlation between the complexity indices and the issue resolution.
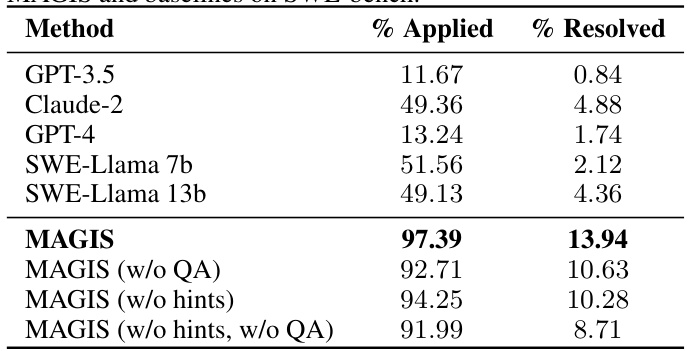
🔼 This table presents a comparison of the overall performance of the MAGIS framework against several baseline LLMs on the SWE-bench dataset. The performance is measured by two metrics: the percentage of instances where the code change was successfully generated and applied (% Applied) and the percentage of instances where the applied code change successfully resolved the issue (% Resolved). The table also shows the effect of ablations on the MAGIS framework, specifically removing the QA Engineer agent and/or hints from the workflow, to demonstrate the contribution of each component.
read the caption
Table 2: The comparison of overall performance between MAGIS and baselines on SWE-bench.

🔼 This table presents the correlation coefficients between several complexity indices and the success of issue resolution for three different LLMs (GPT-3.5, GPT-4, and Claude-2). The complexity indices include the number of files, functions, hunks, added lines of code, deleted lines of code, and changed lines of code. A statistically significant correlation (p-value < 0.05) is indicated with an asterisk. The negative correlations suggest that increased complexity tends to make issue resolution more difficult.
read the caption
Table 1: Correlation between the complexity indices and the issue resolution.

🔼 This table compares the performance of the MAGIS framework with several baselines on the SWE-bench lite dataset. The performance is measured by the percentage of GitHub issues resolved. The table shows that MAGIS outperforms other methods, achieving a higher resolved ratio (25.33%). Ablation studies show the impact of different components of MAGIS, such as the QA Engineer and hints, on the overall performance.
read the caption
Table 4: The comparison of overall performance between MAGIS and baselines on SWE-bench lite.

🔼 This table presents a statistical comparison between the code changes generated by the MAGIS framework and the ground truth (gold standard) for both resolved and unresolved instances from the SWE-bench dataset. It provides metrics on the number of code files, functions, hunks, added lines of code (LoC), deleted lines of code, and the start and end indices of the code changes. Minimum, maximum, and average values are given for each metric, offering insights into the complexity of code modifications handled by the system for both successful and unsuccessful resolutions.
read the caption
Table 5: The statistical analysis of our framework on resolved and applied but not resolved instances.

🔼 This table presents a statistical comparison between the resolved and unresolved instances processed by the MAGIS framework. For each category (resolved and unresolved), it shows the minimum, maximum, and average values for several key metrics including: number of code files, number of functions, number of hunks, number of added lines of code (LoC), number of deleted lines of code (LoC), the starting line index of the code change, the ending line index of the code change, and the total number of lines changed. The data provides insights into the complexity of code changes in successful versus unsuccessful resolutions, highlighting the challenges faced in complex scenarios and suggesting areas for potential improvement.
read the caption
Table 5: The statistical analysis of our framework on resolved and applied but not resolved instances.
Full paper#