↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current research in robotic grasping lacks datasets with natural human language guidance, hindering progress in language-guided dexterous grasp generation. This limits robots’ ability to perform human-like grasping tasks based on natural instructions. The creation of such datasets is expensive, involving extensive annotation efforts.
To address these challenges, the paper introduces “Dexterous Grasp as You Say” (DexGYS), a novel task that aims to enable robots to perform dexterous grasping based on human language instructions. They developed DexGYSNet, a large-scale dataset constructed efficiently using a hand-object interaction retargeting strategy and an LLM-assisted annotation system. They also introduce DexGYSGrasp, a framework for generating high-quality, diverse, and intent-aligned grasps that decomposes complex learning into two progressive objectives, overcoming challenges from traditional penetration loss functions. The experiments validate the effectiveness of both the dataset and the framework, showcasing advancements in natural human-robot interaction.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical need for datasets and methods enabling robots to grasp objects based on human language instructions. Its cost-effective dataset creation and novel framework offer significant advancements in human-robot interaction, opening up new avenues for research in natural language processing and robotics.
Visual Insights#
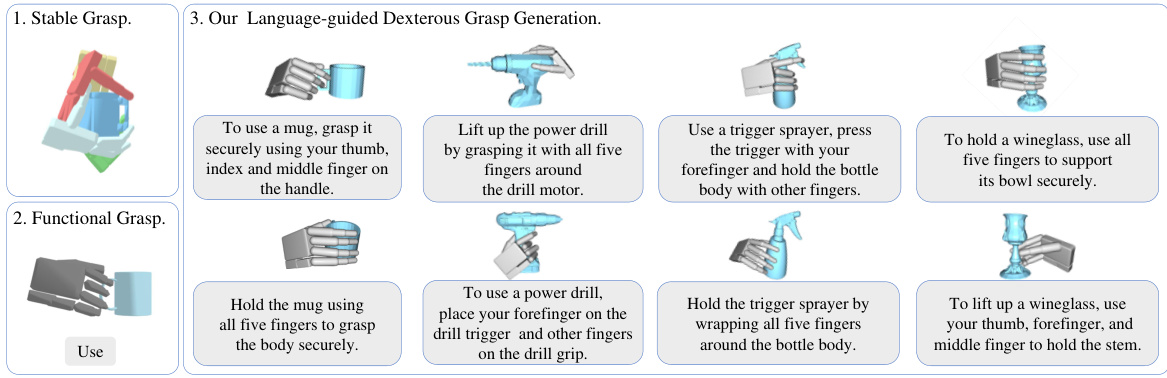
This figure compares the proposed language-guided dexterous grasp generation task with traditional approaches. Traditional methods focus either on grasp quality or fixed functionalities, lacking the flexibility of language-based control. The proposed method allows robots to generate dexterous grasps based on human language instructions, enabling more natural human-robot interaction.
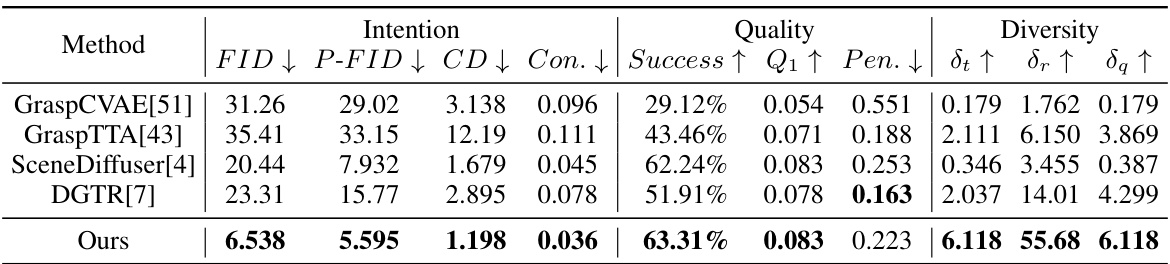
This table presents a quantitative comparison of the proposed DexGYSGrasp framework against several state-of-the-art (SOTA) methods on the DexGYSNet dataset. The comparison is based on several metrics related to intention, quality, and diversity of generated grasps. Lower is better for FID, P-FID, CD, Con., and Pen., while higher is better for Success, Q1, St, Sr, and δα.
In-depth insights#
DexGYS: A New Task#
The proposed task, “Dexterous Grasp as You Say” (DexGYS), presents a significant advancement in robotics by bridging the gap between human language commands and robot dexterity. DexGYS moves beyond prior work that focused solely on grasp stability or limited predefined tasks. Instead, it challenges robots to execute dexterous grasps based on nuanced natural language instructions. This requires a new level of understanding and integration between language processing, grasp planning, and motor control. The novelty lies not just in the task itself, but also in the necessity of creating a new dataset (DexGYSNet) with high-quality annotations of both dexterous grasps and their corresponding language descriptions. This dataset is crucial for training and validating models that can successfully execute DexGYS, highlighting a key contribution of the research. The ambition of DexGYS demonstrates a shift towards more intuitive and natural human-robot interaction, paving the way for robots that understand and respond to complex, context-rich instructions.
Dataset Creation#
The creation of a robust and representative dataset is paramount for training effective models in the field of language-guided dexterous grasp generation. A high-quality dataset needs to capture the nuanced relationship between human language instructions, object properties, and corresponding dexterous grasps. Cost-effectiveness is a crucial factor to consider when constructing such a large-scale dataset. Strategies like hand-object interaction retargeting and LLM-assisted annotation greatly reduce manual efforts. However, challenges exist in ensuring the dataset’s diversity and quality, especially when dealing with various object shapes and complex human language descriptions. Careful design of annotation systems and data augmentation techniques are vital to mitigate biases and achieve broad coverage. Ultimately, the success of this research hinges on the dataset’s ability to accurately reflect the complexity of the real-world task, facilitating the development of generalized and robust AI models.
Progressive Learning#
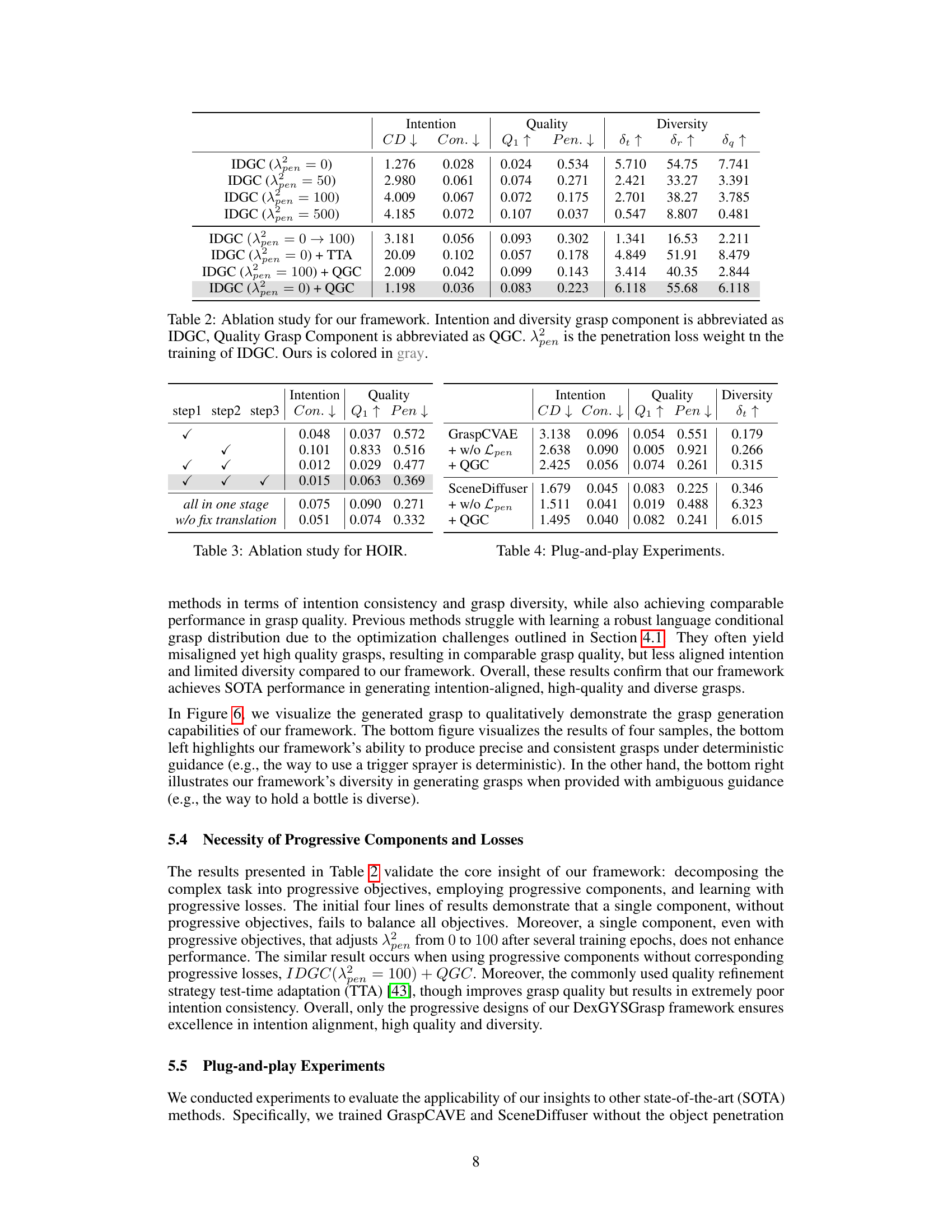
Progressive learning, in the context of dexterous grasp generation, presents a compelling approach to overcome the complexities inherent in simultaneously optimizing for intention alignment, grasp quality, and diversity. Instead of tackling these multifaceted objectives concurrently, which often leads to suboptimal results (as seen in the impact of penetration loss on grasp diversity and intention alignment), progressive learning decomposes the learning process. This sequential strategy first focuses on building a robust grasp distribution that prioritizes intention alignment and diversity, effectively sidestepping constraints such as penetration loss that hinder these aspects. A second stage then refines these initial grasps, focusing on improving quality while maintaining the established intention consistency. This two-stage approach allows each component to target specific and more manageable optimization goals, significantly enhancing overall performance. The strategic use of losses is also crucial; by separating the objectives, the appropriate loss functions can be applied to each stage, avoiding conflicts and facilitating more effective learning. The results highlight the power of progressive learning in achieving high-quality, diverse, and intent-aligned dexterous grasps.
Real-World Results#
A dedicated ‘Real-World Results’ section would critically assess the paper’s claims by testing the DexGYSGrasp framework in practical scenarios. This would involve evaluating the framework’s performance across diverse objects and challenging conditions. Key aspects to consider would be the grasp success rate, robustness to noise and variations in object placement, and the system’s ability to handle unexpected events such as partial occlusions or slippery surfaces. Qualitative analysis would involve comparing the generated grasps to human-like grasping strategies and providing visual evidence of successful and failed grasps. A detailed comparison of real-world performance against simulation results would highlight the limitations and potential improvements needed for broader real-world applicability. By including metrics such as success rate and comparing against benchmark methods, the section would showcase the practical value and limitations of the proposed dexterous grasp generation system.
Future Work#
Future research directions stemming from this dexterous grasping work could explore more complex and nuanced language instructions, potentially incorporating contextual information and ambiguities. Improving grasp quality and robustness in real-world scenarios is crucial, addressing factors like object variability, sensor noise, and unexpected disturbances. This could involve more sophisticated hand-object interaction models or leveraging reinforcement learning techniques. Expanding to a wider range of objects and tasks would demonstrate broader applicability, requiring more diverse datasets and potentially advancements in object recognition and scene understanding. Finally, investigating the integration of this dexterous grasping system with other robotic capabilities, such as manipulation and task planning, would be vital for building more advanced and autonomous robotic systems. Addressing potential safety and ethical concerns around the deployment of dexterous robots is also paramount, requiring careful consideration of unintended consequences and developing appropriate safeguards.
More visual insights#
More on figures
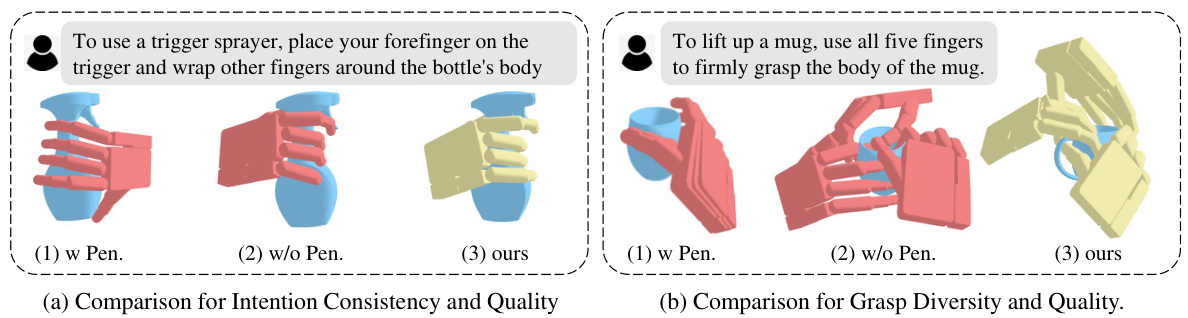
This figure shows the effects of using a penetration loss term during training of a dexterous grasp generation model. The left panel (a) compares models trained with and without penetration loss. It shows that including penetration loss causes a misalignment between the intended grasp and the actual grasp, and that excluding it results in the hand penetrating the object. The right panel (b) compares grasp diversity, showing that models trained without penetration loss produce more diverse grasps, but the grasps may be infeasible due to penetration. The figure highlights the tradeoff between generating feasible grasps and achieving diverse, intent-aligned grasps, leading to the adoption of a two-stage training approach in the proposed DexGYSGrasp framework.
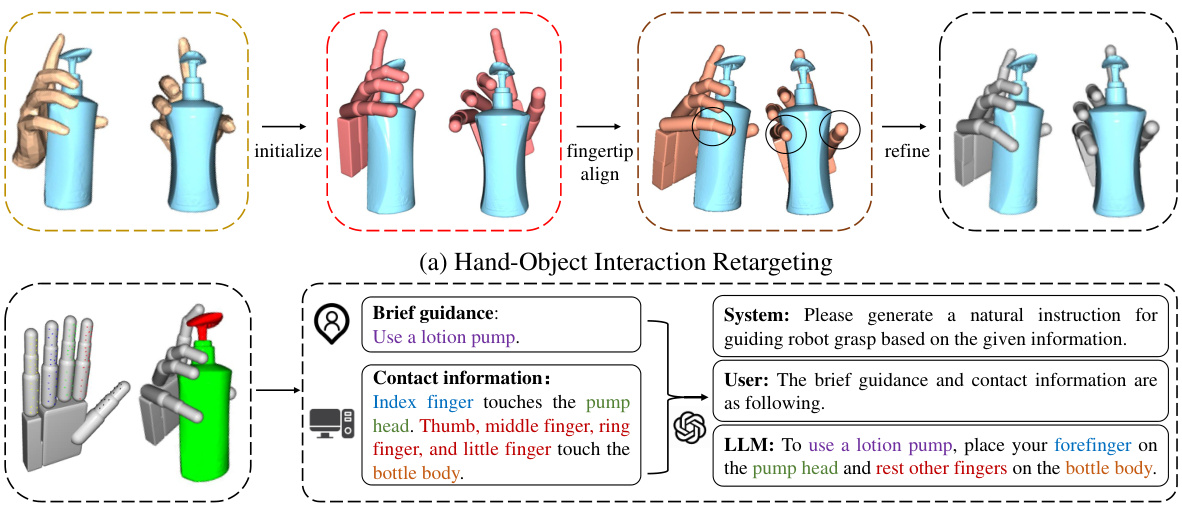
This figure illustrates the two-stage process of creating the DexGYSNet dataset. The first stage, (a) Hand-Object Interaction Retargeting (HOIR), shows how human hand poses are transferred to robotic dexterous hands while maintaining hand-object contact. This involves three steps: initialization, fingertip alignment, and interaction refinement. The second stage, (b) LLM-assisted Language Guidance Annotation, uses a Large Language Model (LLM) to automatically generate natural language instructions based on the hand-object interaction data.
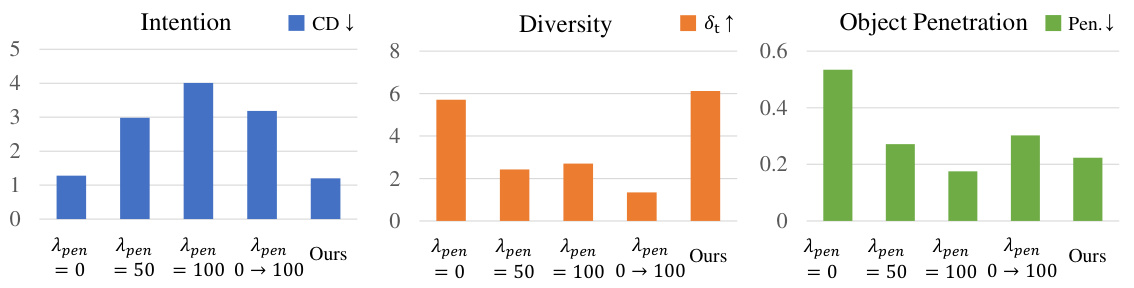
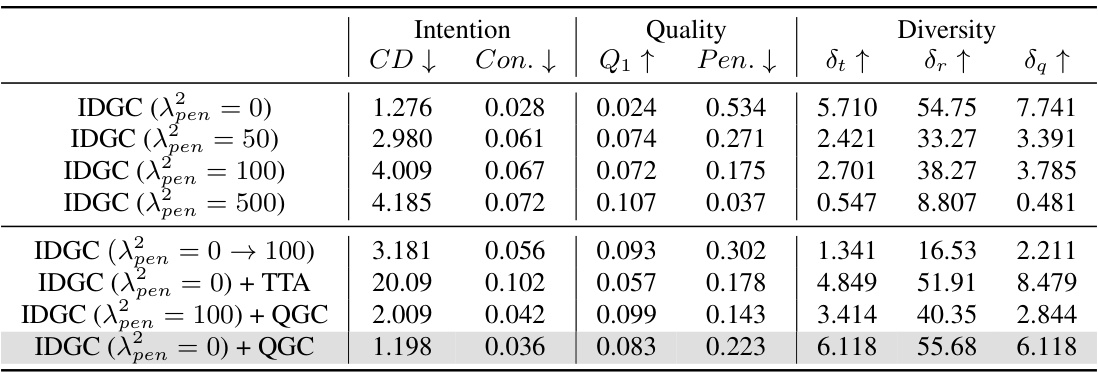
This figure shows the quantitative experimental results obtained with different object penetration loss weights (λpen). It compares the performance of the proposed method against baselines across three key metrics: Intention Consistency (measured by Chamfer Distance, CD), Diversity (measured by standard deviation of hand translation, δt), and Object Penetration (Penetration depth). The results demonstrate that the proposed method effectively balances intention alignment, grasp diversity, and penetration avoidance, outperforming the baselines.
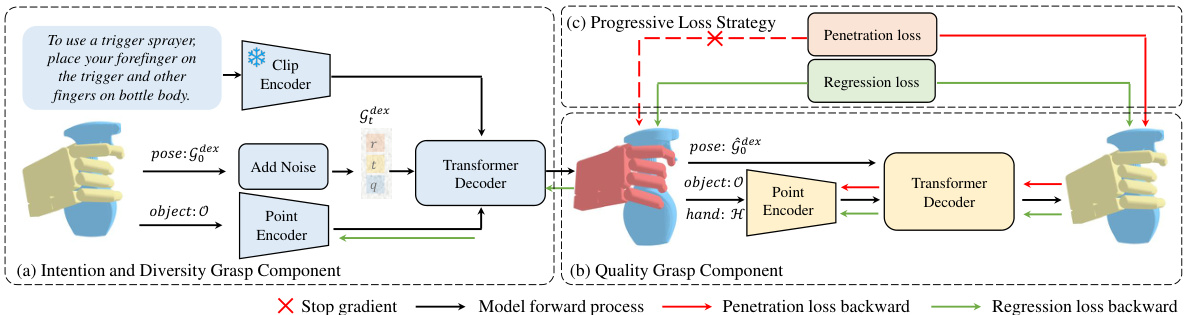
This figure shows the architecture of the DexGYSGrasp framework, which consists of two components: the Intention and Diversity Grasp Component and the Quality Grasp Component. The first component focuses on generating diverse and intention-aligned grasps using only regression loss, while the second component refines the grasps to improve quality by incorporating both regression and penetration losses. A progressive training strategy is employed, with the first component’s output used as input to the second. The figure illustrates the flow of information through both components and highlights the role of different loss functions in the training process.
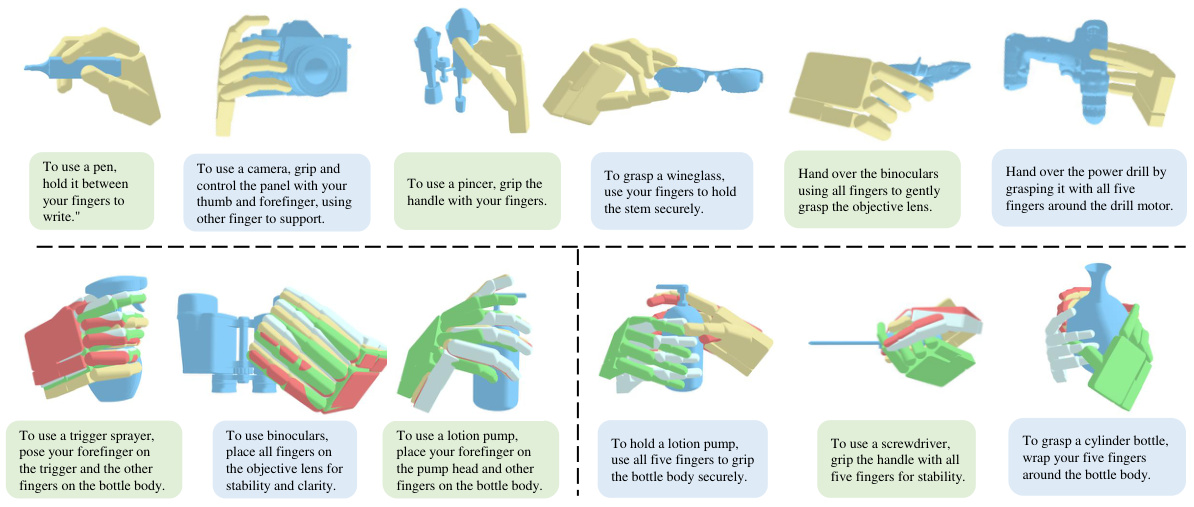
This figure visualizes examples of dexterous grasps generated by the proposed DexGYSGrasp framework. The top row shows one example grasp for each object and corresponding language instruction demonstrating the system’s ability to generate accurate grasps based on clear instructions. The bottom row showcases four examples of grasps generated for the same object but with more ambiguous instructions, highlighting the framework’s capacity to generate diverse grasps that still align with the intent of the instruction.

This figure shows the results of real-world experiments using the DexGYSGrasp framework with an Allegro hand, a Flexiv Rizon 4 arm, and an Intel Realsense D415 camera. The experiments involved several objects, each with multiple grasp instructions given as natural language commands. The images illustrate the successful execution of the grasps, demonstrating the system’s ability to perform dexterous manipulation according to human language instruction. The results show varying degrees of success (3/10 to 9/10), highlighting the current limitations and the need for improvement in real-world applications.
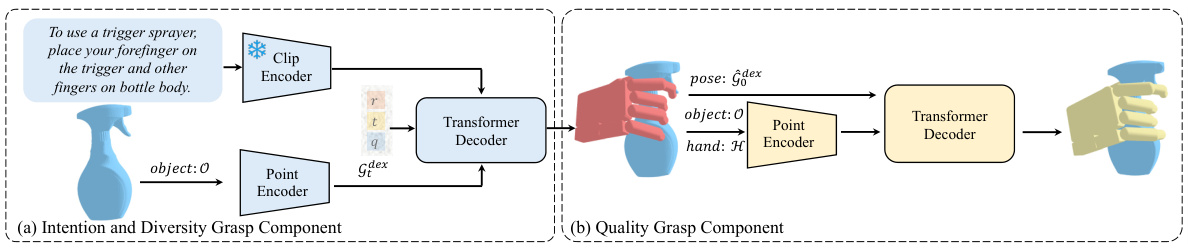
This figure shows the overall architecture of the DexGYSGrasp framework, which consists of two main components: the Intention and Diversity Grasp Component and the Quality Grasp Component. The first component, using only regression loss, reconstructs the original hand pose from noisy data, conditioned on language and object information. The second component refines the initially generated grasp by incorporating both regression and penetration losses to improve grasp quality while maintaining intention consistency.
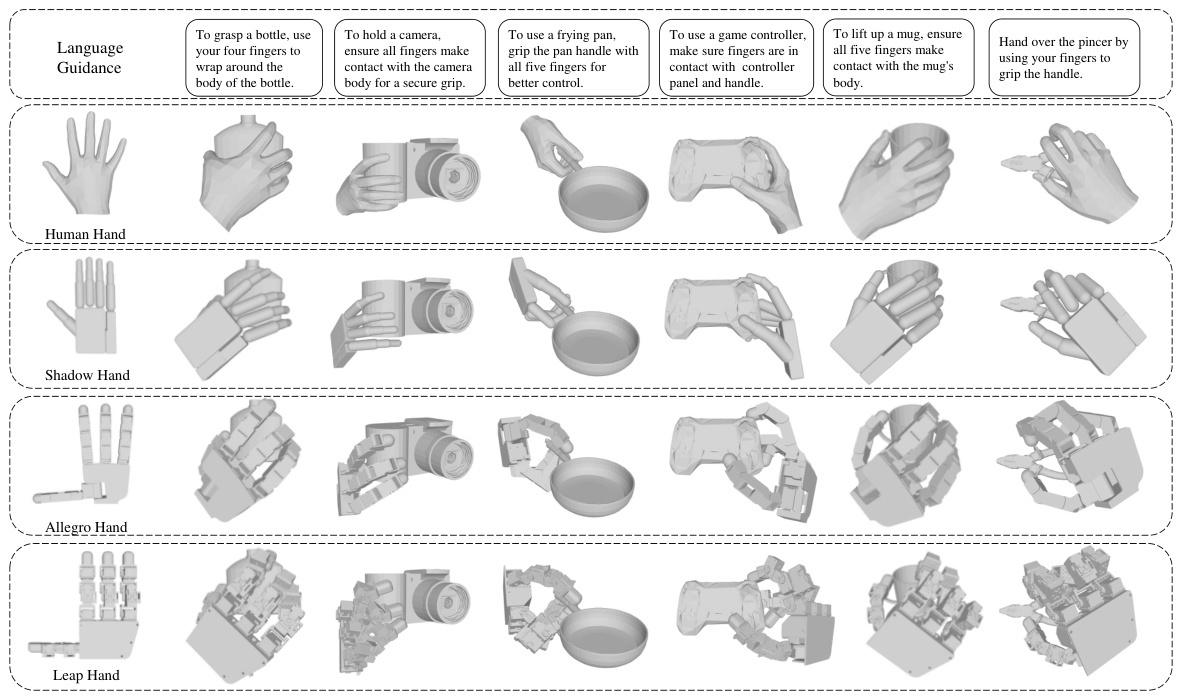
This figure shows the generalization of the DexGYSNet dataset to various dexterous hands. It displays the grasps generated for several common objects (bottle, camera, frying pan, game controller, mug, and pincer) across four different hand models: a human hand, a Shadow Hand, an Allegro Hand, and a Leap Hand. Each row presents the grasp poses generated for the same language guidance instruction, highlighting the consistent generation across the different hand types and demonstrating the flexibility and adaptability of the DexGYSNet dataset.
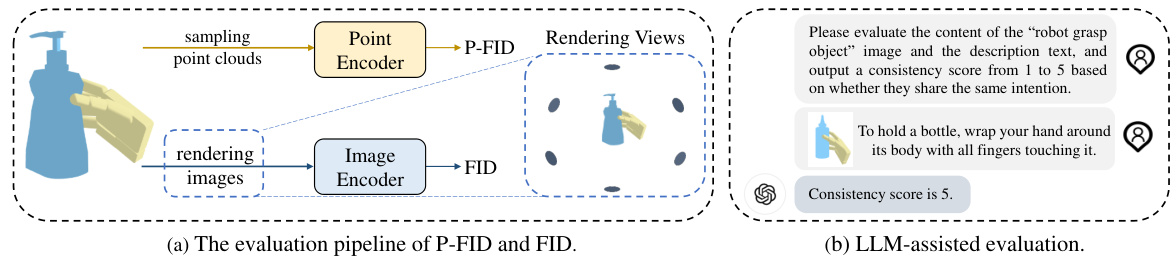
This figure shows two ways to evaluate the intention consistency of the generated grasps. (a) shows how the Fréchet Inception Distance (FID) is used to compare the generated grasp with the ground truth. (b) explains that when the ground truth is unavailable (like in 3D object datasets), the LLM GPT-4 is used to assess the consistency between the generated grasp and a text description of the intended action.
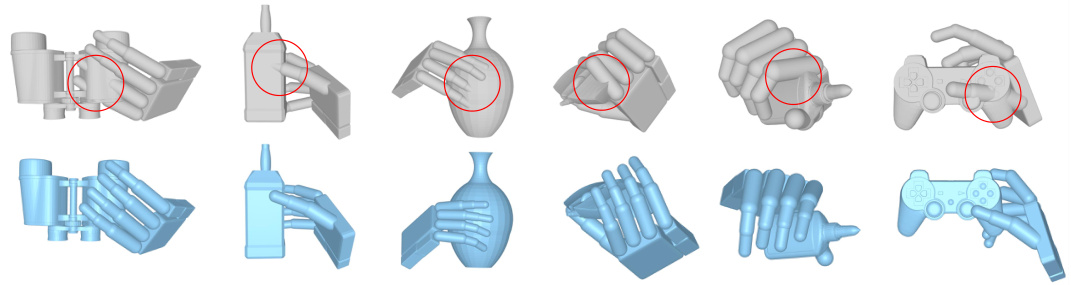
This figure shows the effect of using a penetration loss term in training a dexterous grasp model. The top row (a) demonstrates that using penetration loss causes misaligned grasps (inconsistent with the intended action), whereas not using it causes the hand to penetrate the object. The bottom row (b) shows that using penetration loss also reduces the diversity of generated grasps. This highlights the challenge of simultaneously optimizing for intention alignment, grasp quality, and diversity, and motivates the use of a progressive training approach.

This figure demonstrates the flexibility of the DexGYSGrasp framework in handling task-oriented instructions. Instead of detailed language descriptions, simple commands like ‘use’ and ‘hold’ are used as input. The figure shows examples of generated grasps for various objects (mug, tablet, camera) under these simplified instructions, highlighting the system’s ability to adapt to different task types.

The image shows the physical setup for the real-world experiments. A Flexiv Rizon 4 arm, an Allegro Hand, and an Intel Realsense D415 camera are shown. Various 3D printed objects are also visible, indicating the test objects used. The setup involves a robotic arm equipped with a dexterous hand, positioned to interact with the objects in front of a dark background. A depth camera is used to capture the 3D information for the scene.
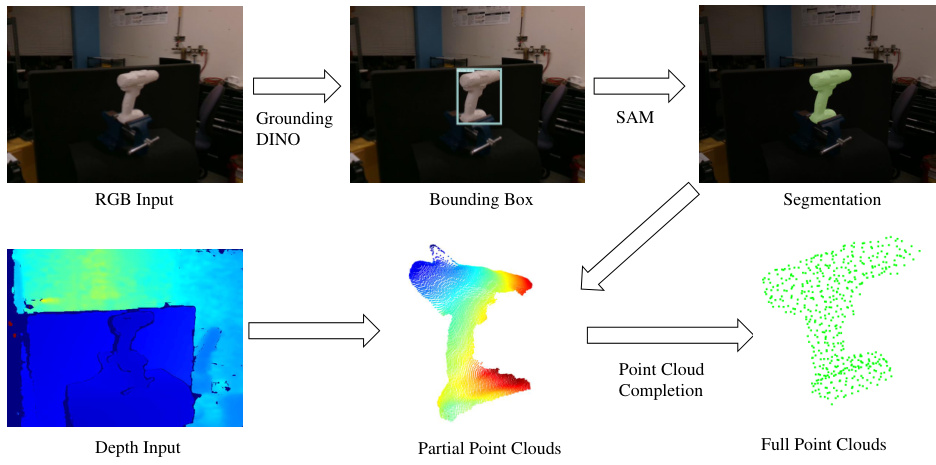
This figure shows the pipeline used to obtain the full point cloud from real-world RGB and depth images. First, Grounding DINO detects the object’s bounding box in the RGB image. Then, SAM is used to generate a segmentation mask. This mask is used to crop the relevant part of the depth image, generating a partial point cloud. Finally, a point cloud completion network takes the partial point cloud to generate a complete full point cloud which is then used in the DexGYSGrasp framework.

The figure visualizes real-world experiments showing the robot performing dexterous grasps based on various language commands. It demonstrates the robot’s ability to successfully manipulate objects like a power drill, trigger sprayer, game controller, pincer, frying pan, and wine glass, by adapting its grasp according to the instructions.
More on tables
This table presents a comparison of the proposed DexGYSGrasp framework against state-of-the-art (SOTA) methods on the DexGYSNet dataset. It evaluates performance across three key aspects: Intention (measured by FID, P-FID, and CD), Quality (measured by Success rate, Q1, and Penetration depth), and Diversity (measured by St, Sr, and δα). Lower values for FID, P-FID, CD, and Penetration are better, while higher values for Success rate, Q1, St, Sr, and δα are preferred.
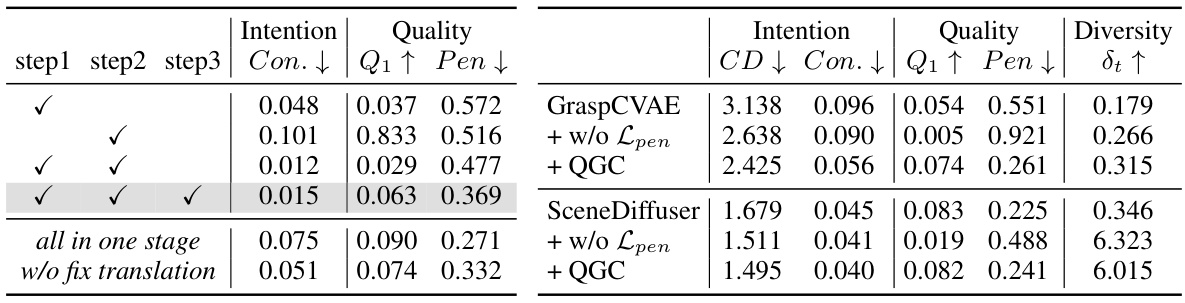
This table presents a quantitative comparison of the proposed DexGYSGrasp framework against state-of-the-art (SOTA) methods on the DexGYSNet dataset. It evaluates the performance across multiple metrics, categorized into Intention (measuring alignment with instructions), Quality (assessing grasp stability and avoidance of penetration), and Diversity (evaluating the variety of generated grasps). Lower values are generally better for intention and penetration, while higher values are preferred for quality and diversity metrics.

This table presents a comparison of the proposed method’s performance on the DexGYSNet dataset against several state-of-the-art (SOTA) methods. It evaluates performance across multiple metrics, including intention (FID, P-FID, CD, Con.), quality (Success, Q1, Pen.), and diversity (St, Sr, δα). Lower values are generally better for intention and quality metrics, while higher values are better for diversity and success rate.
Full paper#