↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Entity alignment (EA) is crucial for integrating knowledge graphs (KGs), but existing methods heavily rely on manual annotations which is expensive and time consuming. Large Language Models (LLMs) offer a potential solution by automating annotation, but their outputs are often noisy and the annotation space is large, making direct application challenging. Furthermore, using LLMs for annotation can be prohibitively expensive.
LLM4EA addresses these challenges by employing a unified framework that integrates active learning and unsupervised label refinement. Active learning strategically selects entities to annotate, significantly reducing the annotation space, while unsupervised label refinement enhances the accuracy of noisy LLM annotations. Experiments show LLM4EA outperforms other baselines across various datasets, demonstrating its effectiveness, robustness, and efficiency, opening up new possibilities for automated EA and large-scale knowledge graph integration.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the expensive and challenging task of entity alignment in knowledge graphs by leveraging large language models (LLMs). It presents a novel framework that addresses the issues of noisy LLM annotations and computational cost, opening exciting avenues for more efficient and accurate knowledge graph integration. The findings are highly relevant to current research trends in knowledge representation and reasoning, impacting numerous applications that rely on integrated and accurate knowledge bases.
Visual Insights#

This figure illustrates the overall architecture of the LLM4EA framework. The framework consists of four main components: an active sampling module, an LLM annotator, an unsupervised label refiner, and a base entity alignment (EA) model. The active sampling module selects important entities to annotate using feedback from the EA model, optimizing the usage of LLM queries. The LLM annotator generates pseudo-labels for the selected entities, which are refined by the unsupervised label refiner. The refined labels are then used to train the base EA model. The output of the EA model is used to update the active sampling policy in an iterative manner, forming a cycle to progressively refine the alignment results.
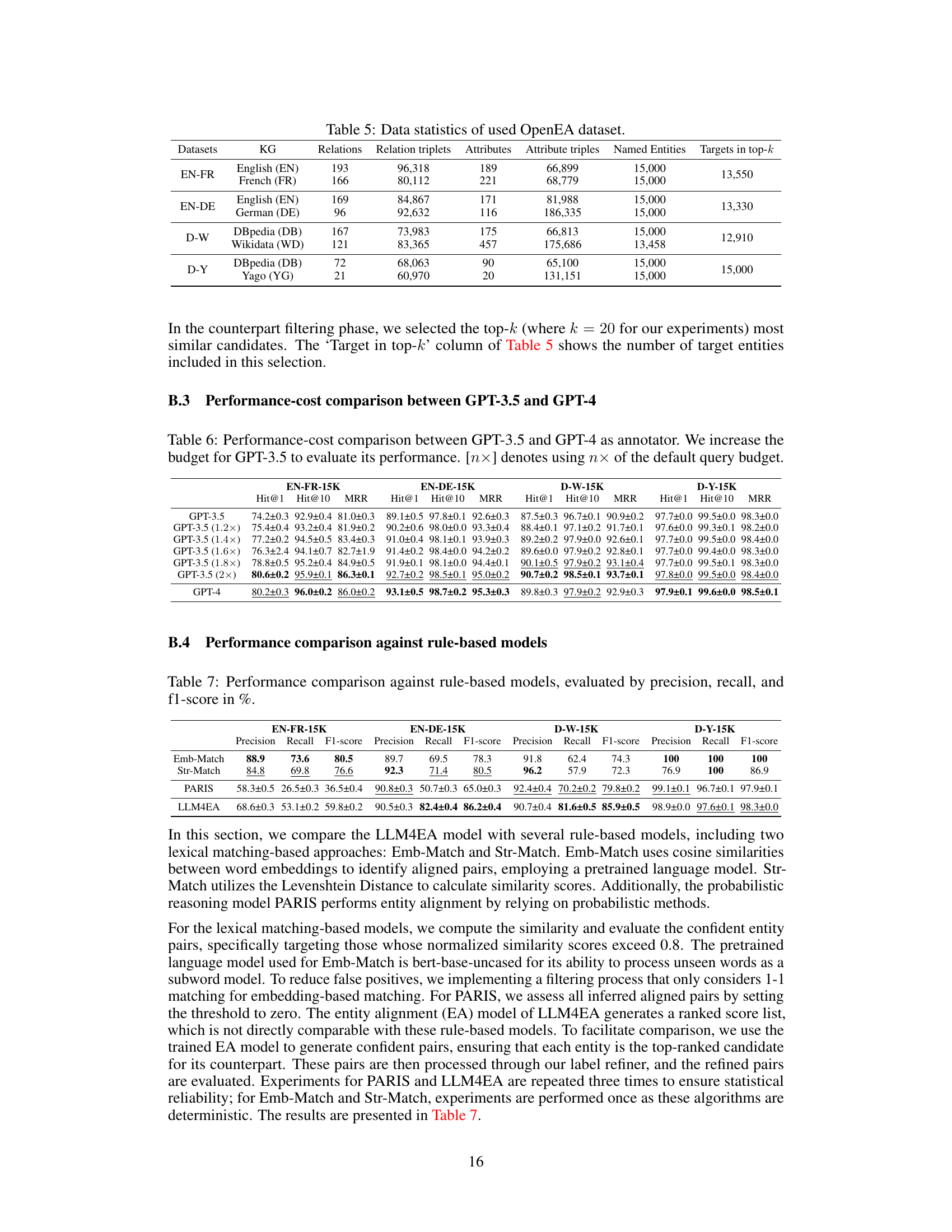
This table presents a comprehensive evaluation of different entity alignment models’ performance across four benchmark datasets (EN-FR-15K, EN-DE-15K, D-W-15K, and D-Y-15K). The performance is evaluated using two metrics: Hit@K (the percentage of correctly aligned entity pairs within the top K ranked predictions, for K=1 and K=10) and Mean Reciprocal Rank (MRR, which measures the average precision of the ranking). The results are presented for various models, including baselines and the proposed LLM4EA, and each model’s performance is reported as a mean ± standard deviation based on three independent experimental trials. This provides a detailed comparison demonstrating LLM4EA’s superior performance.
In-depth insights#
Noisy LLM Labels#
Large language models (LLMs) are powerful tools for various natural language processing tasks. However, their application to knowledge graph entity alignment presents challenges due to the inherent noise in LLM-generated labels. LLMs’ probabilistic nature and the ambiguity in real-world knowledge graph data can lead to inaccurate and unreliable alignments. This noise significantly impacts the accuracy and efficiency of entity alignment models. Addressing this issue requires robust strategies such as active learning to focus annotation efforts on the most informative entities and unsupervised label refinement to iteratively improve label accuracy using probabilistic reasoning. Successfully handling noisy LLM labels is crucial for building effective and scalable entity alignment systems. The development of techniques that mitigate the impact of noisy labels is an active research area, critical for harnessing the full potential of LLMs in knowledge graph applications.
Active Learning#
Active learning, in the context of entity alignment, is a crucial technique to efficiently leverage limited resources. Instead of passively annotating all entity pairs, active learning strategically selects the most informative ones for annotation by a Large Language Model (LLM). This selection process is guided by uncertainty measures, which identify entities whose alignment is most ambiguous. Prioritizing high-uncertainty entities significantly reduces the annotation space while maximizing the model’s learning potential. The framework often dynamically updates its selection policy based on feedback from a base entity alignment model, improving efficiency and accuracy iteratively. A key challenge is managing noisy LLM annotations. By combining active learning with robust label refinement techniques, the overall framework effectively leverages LLMs for entity alignment, enhancing both effectiveness and efficiency.
LLM4EA Framework#
The LLM4EA framework presents a novel approach to entity alignment in knowledge graphs by effectively leveraging large language models (LLMs). Its core innovation lies in addressing the challenges posed by noisy LLM annotations and the vast search space inherent in real-world knowledge graphs. LLM4EA employs an active learning strategy to prioritize the annotation of the most informative entities, significantly reducing the annotation burden. Furthermore, it integrates an unsupervised label refinement module that enhances the accuracy of LLM-generated labels through probabilistic reasoning, mitigating the negative impact of noisy data. By iteratively optimizing the active learning policy based on feedback from a base entity alignment model, LLM4EA achieves a high level of efficiency and robustness. The combined effect of active learning and label refinement leads to superior alignment performance, surpassing existing methods in terms of effectiveness and efficiency, and showcasing adaptability to various datasets and LLMs.
Label Refinement#
The core idea of label refinement is to improve the accuracy of noisy labels generated by Large Language Models (LLMs). LLMs, while powerful, can produce inaccurate annotations, especially in the context of large, complex knowledge graphs. The proposed method uses probabilistic reasoning to assess the compatibility of labels. Incompatibility suggests potential errors and helps identify reliable labels. This process continuously refines the accuracy of labels, leading to a more reliable training set for the entity alignment model. The iterative nature of the refinement process allows the model to learn from both the initial noisy labels and subsequent improvements. A key advantage is that it’s unsupervised, meaning it does not require additional human annotation, making it efficient and scalable.
Future of LLMs#
The future of LLMs is incredibly promising, yet riddled with challenges. Continued advancements in model architecture and training techniques will likely lead to even more powerful and versatile models capable of complex reasoning and nuanced understanding. Accessibility remains a key hurdle, with the computational cost of training and deploying large models limiting widespread adoption. Ethical considerations are paramount, demanding careful attention to biases, misinformation, and potential misuse. Addressing these concerns will require collaborative efforts from researchers, policymakers, and the broader AI community. Furthermore, research into more efficient models is crucial, exploring techniques like parameter-efficient fine-tuning and model compression to reduce the resource demands of LLMs. Ultimately, the successful integration of LLMs into various applications hinges on a balanced approach that prioritizes both technological progress and responsible development.
More visual insights#
More on figures

This figure shows the mean reciprocal rank (MRR) achieved by using either GPT-3.5 or GPT-4 as the annotator for generating pseudo-labels for entity alignment across four different datasets. The x-axis represents the query budget (increased for GPT-3.5 to compare performance at different costs), and the y-axis represents the MRR. Error bars show the standard deviation across three repeated experiments for each condition. The figure demonstrates the trade-off between cost and performance with different LLMs and demonstrates that GPT-4 is more efficient for entity alignment than GPT-3.5 at the default budget.
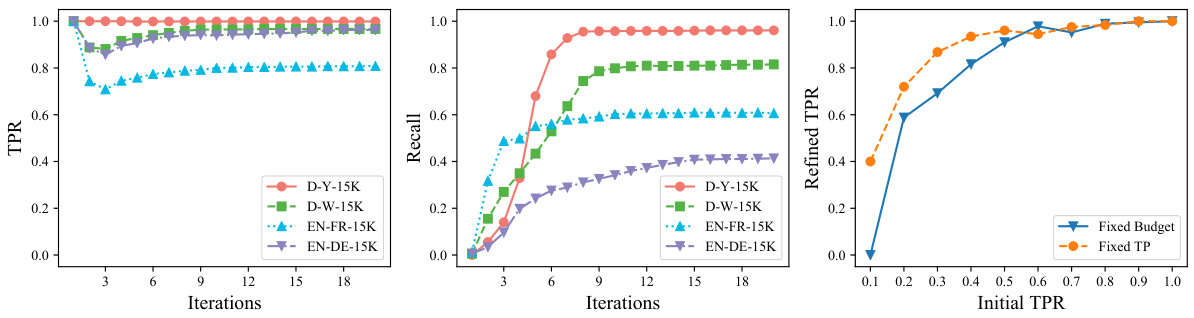
This figure analyzes the performance of the label refinement module in LLM4EA. The left and middle subfigures show how TPR and recall evolve across iterations for four datasets, demonstrating the refinement process’s effectiveness in improving label accuracy. The right subfigure shows the robustness of the refinement process by testing it with initial pseudo-labels of varying quality (initial TPRs), highlighting its ability to consistently improve TPR.
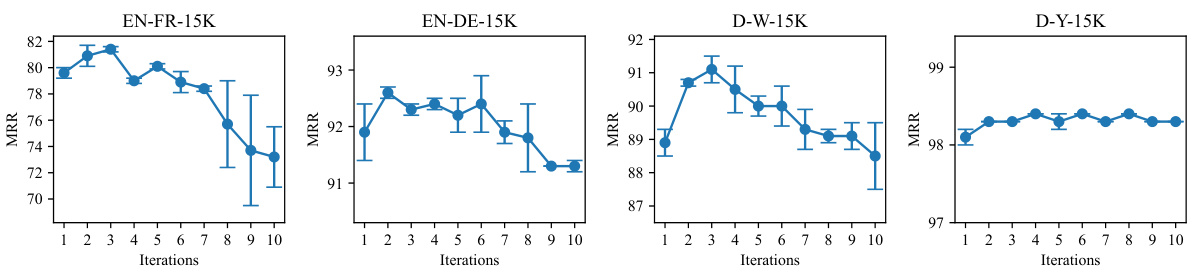
This figure visualizes the results of experiments evaluating the performance of entity alignment across four different datasets. The x-axis represents the number of active sampling iterations, while the y-axis shows the Mean Reciprocal Rank (MRR), a metric assessing the accuracy of the entity alignment. Each dataset’s results are presented in a separate subplot. The plots show how the MRR changes as the number of iterations increases, allowing for observation of the relationship between the number of iterations performed in the active sampling process and the accuracy of the model’s alignment predictions. Error bars are included to indicate the variability across the repeated experiments.
More on tables
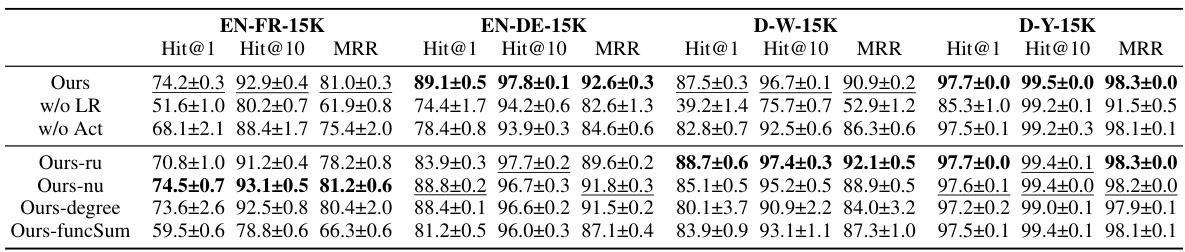
This table presents the ablation study results for the LLM4EA framework. It shows the impact of removing key components (label refiner and active selection) and replacing the active selection policy with alternative methods (using only relational uncertainty, neighbor uncertainty, degree, or functionality sum) on the overall performance across four datasets (EN-FR-15K, EN-DE-15K, D-W-15K, D-Y-15K) using metrics Hit@1, Hit@10, and MRR.

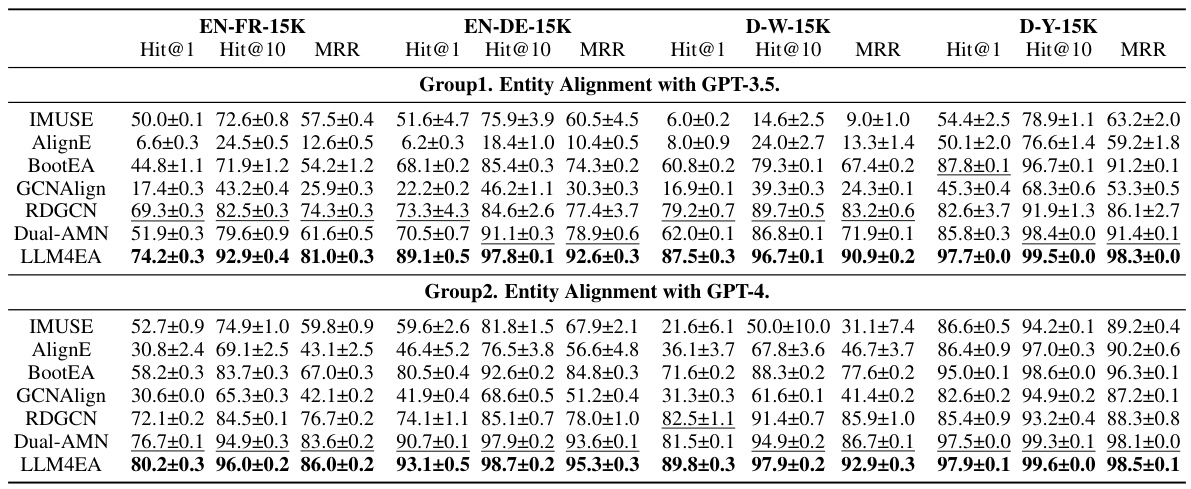
This table presents a comprehensive evaluation of different entity alignment methods’ performance across four benchmark datasets (EN-FR-15K, EN-DE-15K, D-W-15K, and D-Y-15K). The evaluation metrics used are Hit@1, Hit@10, and Mean Reciprocal Rank (MRR), all expressed as percentages. Results are averaged over three independent trials to provide a measure of statistical reliability. The table compares the performance of LLM4EA against several baseline methods (IMUSE, AlignE, BootEA, GCNAlign, RDGCN, and Dual-AMN).

This table presents the results of the entity alignment experiments. It compares the performance of LLM4EA against several baseline models across four different datasets (EN-FR-15K, EN-DE-15K, D-W-15K, D-Y-15K). The performance metrics used are Hit@1, Hit@10, and Mean Reciprocal Rank (MRR), all expressed as percentages. The results are averaged over three trials to account for the inherent randomness of Large Language Models. The table allows for a direct comparison of LLM4EA’s performance against existing entity alignment methods.
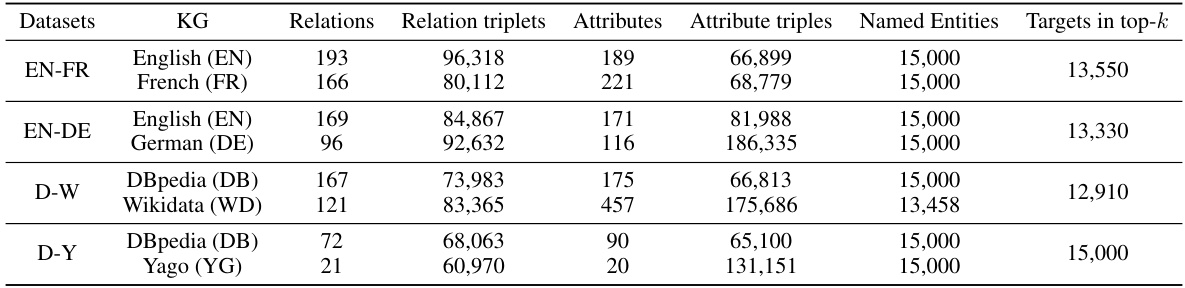
This table presents a detailed breakdown of the statistics for each of the four datasets used in the OpenEA benchmark. For each dataset, it shows the number of relations and relation triplets in each knowledge graph (KG), the number of attributes and attribute triplets, the number of entities with names, and the number of target entities present within the top-k most similar candidates selected during the counterpart filtering phase.

This table presents a comprehensive evaluation of different entity alignment methods across four benchmark datasets (EN-FR-15K, EN-DE-15K, D-W-15K, and D-Y-15K). The performance of each method is assessed using three metrics: Hit@1, Hit@10, and Mean Reciprocal Rank (MRR). The results are presented as percentages and represent the average performance over three independent trials, providing a measure of the methods’ robustness and stability. The table allows for a comparison of the proposed LLM4EA framework against several baselines, highlighting its improved effectiveness in entity alignment.

This table compares the performance of the proposed LLM4EA model against several rule-based baselines on four benchmark datasets (EN-FR-15K, EN-DE-15K, D-W-15K, and D-Y-15K). The rule-based methods include two lexical matching approaches (Emb-Match and Str-Match) and a probabilistic reasoning model (PARIS). The table shows the precision, recall, and F1-score for each method on each dataset, highlighting the superior performance of LLM4EA compared to the baselines.
Full paper#