↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Reinforcement Learning (RL) agents are increasingly used in real-world applications, creating a need to anticipate their actions. Unexpected agent behaviors can have significant consequences, especially in safety-critical scenarios, thus accurate prediction is essential. Current methods are not sufficient, thus methods to improve predictability are needed.
This paper compares three types of RL agents (explicitly, implicitly, and non-planning) using two prediction approaches: an inner-state approach (examining internal computations) and a simulation-based approach (using a world model). Results show explicitly-planned agents are substantially more predictable, likely due to their use of explicit plans. The inner-state approach using plans outperformed simulation-based methods for action prediction. However, results regarding event prediction were less conclusive.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in deploying RL agents in real-world settings: predicting their future actions and events. This is crucial for ensuring safety, improving human-agent interaction, and enabling timely interventions. The findings, especially the comparative analysis of different RL agent types and prediction methods, provide valuable insights for researchers working on safer and more reliable RL systems. The proposed approaches, using inner states and simulations, open up new avenues for improving predictability, which is a key focus in current research trends.
Visual Insights#

This figure shows three example game states from the Sokoban environment used in the paper’s experiments. Sokoban is a game where the player must push boxes into designated goal locations. The figure highlights the complexity of the task, showing different layouts and the need for planning. A blue tile is added to one of the levels to demonstrate the ’event prediction’ task, where the model is asked to predict if the agent will reach this specific location within a certain number of steps.
In-depth insights#
RL Agent Prediction#
Predicting the future actions of reinforcement learning (RL) agents is crucial for safe and effective human-agent interaction, especially as RL agents are increasingly deployed in real-world settings. This challenge necessitates the development of robust prediction methods. The core of the problem lies in the inherent complexity of RL agents, which often exhibit non-deterministic and context-dependent behaviors. Two prominent approaches for addressing this are the inner state approach, which uses internal agent representations (like plans or neuron activations) to predict future actions, and the simulation-based approach, which relies on learned world models to simulate the agent’s behavior and forecast its future actions. The effectiveness of each approach is intrinsically linked to the specific RL algorithm employed. Explicit planning agents, which utilize explicit planning mechanisms, often show significantly higher predictability, particularly when using the inner state approach. However, the quality of the world model is a critical factor when applying the simulation-based approach. Inaccurate models can lead to unreliable predictions, highlighting the need for robust model learning techniques. The choice of prediction method is significantly influenced by agent type and the availability of high-quality world models, emphasizing the importance of carefully considering these factors when developing RL agent prediction systems. Future research should focus on developing more generalizable and robust methods that can adapt to different RL algorithms and environmental complexities.
Inner State Methods#
Inner state methods offer a powerful approach to predict future actions of reinforcement learning agents by leveraging internal agent computations. Direct access to inner states, such as plans (for explicitly planning agents) or neural network activations, bypasses the need for complex world models. This leads to enhanced robustness against inaccuracies in model learning and reduces computational cost. While plans prove highly informative, especially for explicitly planning agents, using internal states for implicitly planning or non-planning agents might reveal less predictable information. This highlights the importance of agent architecture in determining the efficacy of inner state prediction. Although inner state methods offer significant advantages, data accessibility is crucial, as complete access to agent internals is not always feasible, representing a limitation of this approach.
Simulation Approach#
A simulation approach in the context of predicting future actions of reinforcement learning agents offers a powerful alternative to directly analyzing agent internal states. By creating a learned world model, typically a neural network, researchers can simulate the agent’s behavior within this model, generating predictions of future actions and events. This is particularly useful for agents that don’t explicitly plan, making their internal states less informative. The accuracy of this approach, however, is heavily reliant on the fidelity of the world model. A high-fidelity model will closely mirror the real environment, leading to accurate predictions. Conversely, an inaccurate or incomplete world model can yield significant errors, highlighting a critical limitation. The simulation approach, therefore, represents a trade-off: while potentially providing more accurate predictions than internal-state analysis for certain agent types, its success depends fundamentally on the quality of the learned world model. This necessitates careful training and validation of this model to ensure robustness and reliability. In essence, the simulation method offers a powerful predictive tool, but one that is directly contingent on the quality of its underlying model.
Sokoban Experiments#
The Sokoban experiments section likely details the empirical evaluation of the proposed prediction methods. The researchers probably used Sokoban, a classic puzzle game, due to its inherent planning aspect and diverse solvable states which makes it suitable for testing the agent’s ability to predict future actions and events. The experiments likely involved training various RL agents (explicit planners, implicit planners, and non-planners) on multiple Sokoban levels and then applying the proposed inner state and simulation-based prediction approaches to assess their performance. Key metrics would likely include the accuracy of action prediction and the F1-score of event prediction across different agent types and prediction horizons. Crucially, a comparison between inner-state and simulation approaches is highlighted, revealing which approach offers better predictability and robustness, especially when considering the quality of learned world models. The results may have shown that the plans of explicit planners are highly informative, while simulation-based approaches, though potentially more accurate with perfect world models, are sensitive to model inaccuracies. The Sokoban environment, with its distinct planning challenges, offers a strong testbed to evaluate the generalizability of these prediction methods, moving beyond the specific RL algorithms used during training.
Future Work#
The paper’s “Future Work” section suggests several promising avenues for extending this research. Expanding the experimental scope to encompass a wider variety of RL algorithms and environments is crucial to assess the generalizability of the findings. Investigating safety mechanisms that leverage action prediction to modify agent behavior presents a significant opportunity to enhance the safety and reliability of real-world deployments. The authors also acknowledge the need to develop new RL algorithms that inherently possess both high performance and predictability, suggesting a move toward intrinsically safer AI systems. Finally, the importance of addressing the challenge of inaccurate world models in real-world applications is highlighted, underscoring the need for more robust and adaptable prediction techniques. These future research directions emphasize the pursuit of practical applications and a deeper understanding of the interplay between predictability and RL agent behavior.
More visual insights#
More on figures

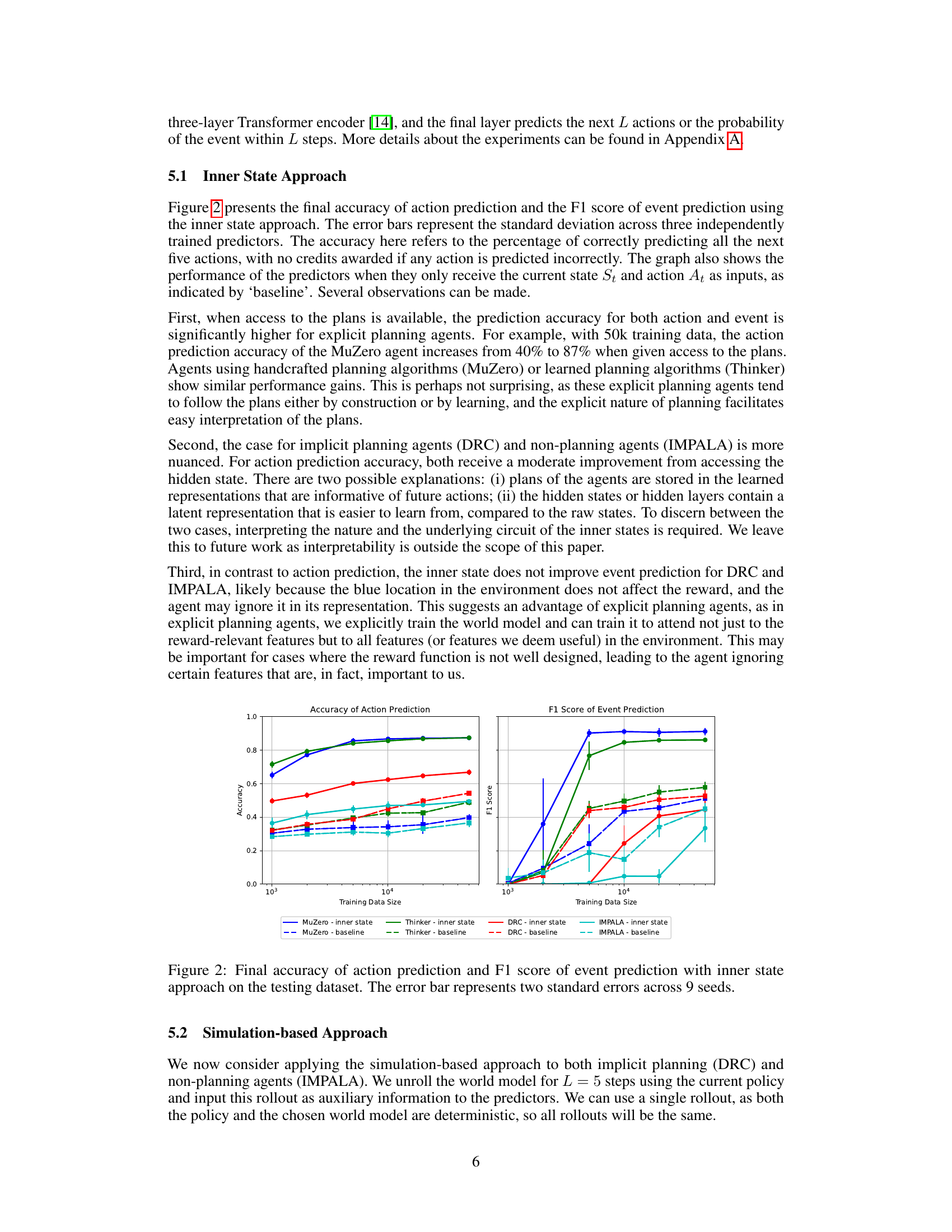
This figure displays the performance of action and event prediction using the inner state approach. It shows the accuracy of predicting all five future actions correctly (no partial credit) and the F1 score for event prediction (predicting whether a specific event occurs within a certain time window). Separate lines depict results for four different RL agent types (MuZero, Thinker, DRC, and IMPALA). The ‘inner state’ lines represent results when the model has access to the agent’s internal state (e.g., plans, hidden layer activations), while ‘baseline’ lines show results when only the current state and action are used. Error bars represent the standard deviation across multiple runs. The x-axis shows the size of the training dataset used.
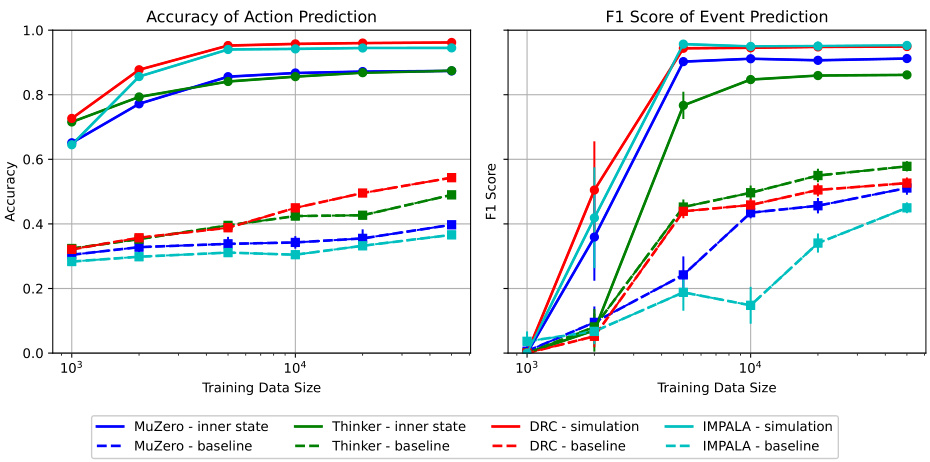
This figure shows the results of using an inner state approach for predicting future actions and events. It compares the performance of the predictor when given access to the agent’s inner state (e.g., plans, neuron activations) versus when only given the current state and action. The performance is measured using accuracy for action prediction and F1 score for event prediction. The error bars represent the standard deviation across nine independent runs.

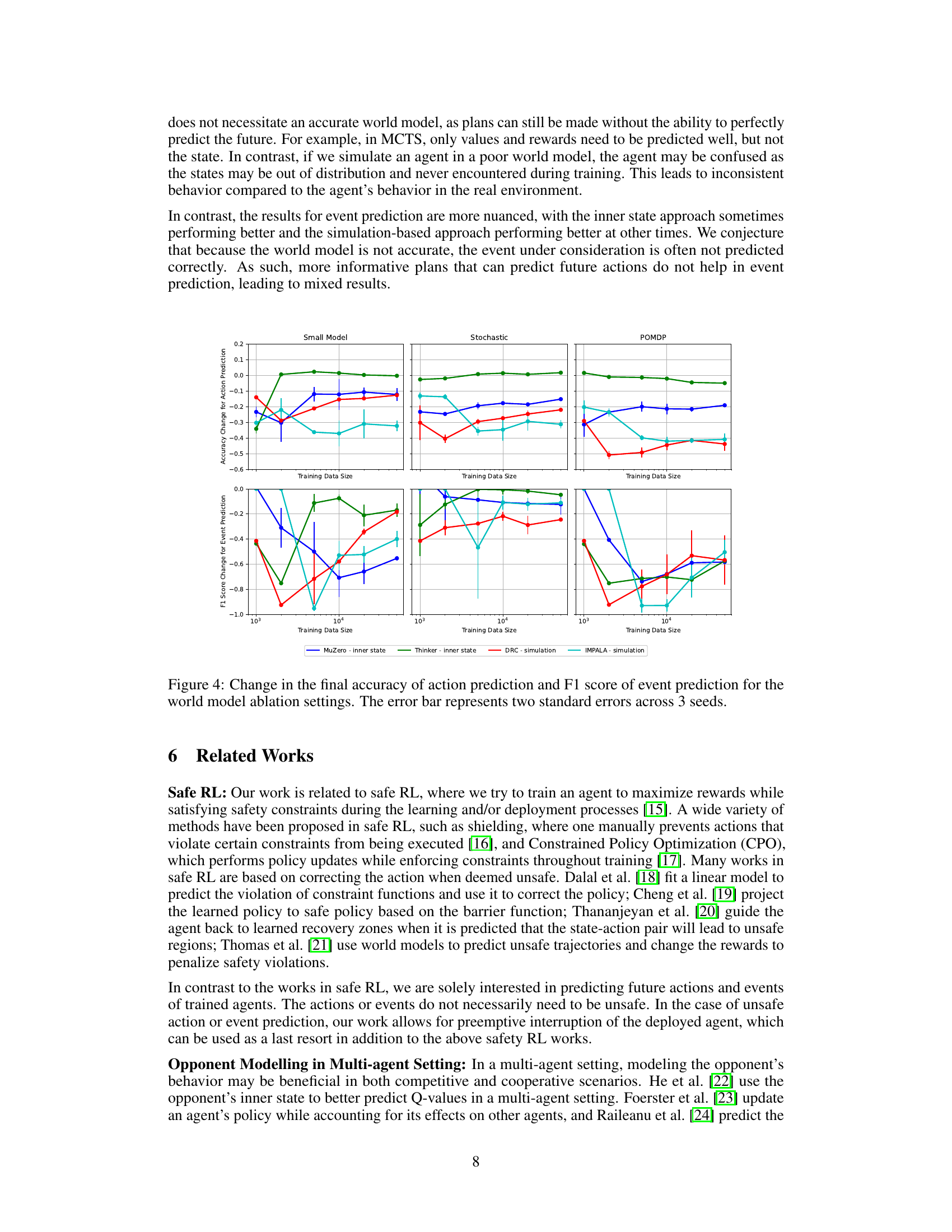
This figure displays the effect of world model inaccuracies on the performance of action and event prediction. It shows the change in accuracy and F1 score compared to a default, accurate model setting. The three model ablation settings shown are a smaller model, a stochastic model, and a partially observable Markov decision process (POMDP). The results reveal that the inner state approach of explicit planning agents shows more robustness to inaccuracies compared to the simulation-based approaches for action prediction. For event prediction, the effects are more varied.

This figure visualizes the outputs of the trained world model under various settings. The leftmost column shows the initial state, and each subsequent column represents a time step in the simulation (with five consecutive ‘UP’ actions as input). The rows represent different model variations: Default (standard model), Small Model (a smaller, less complex model), Stochastic (a model with added randomness), and POMDP (a partially observable model). Comparing across the rows provides a visual demonstration of the impacts of these variations on model accuracy in predicting the agent’s subsequent states.
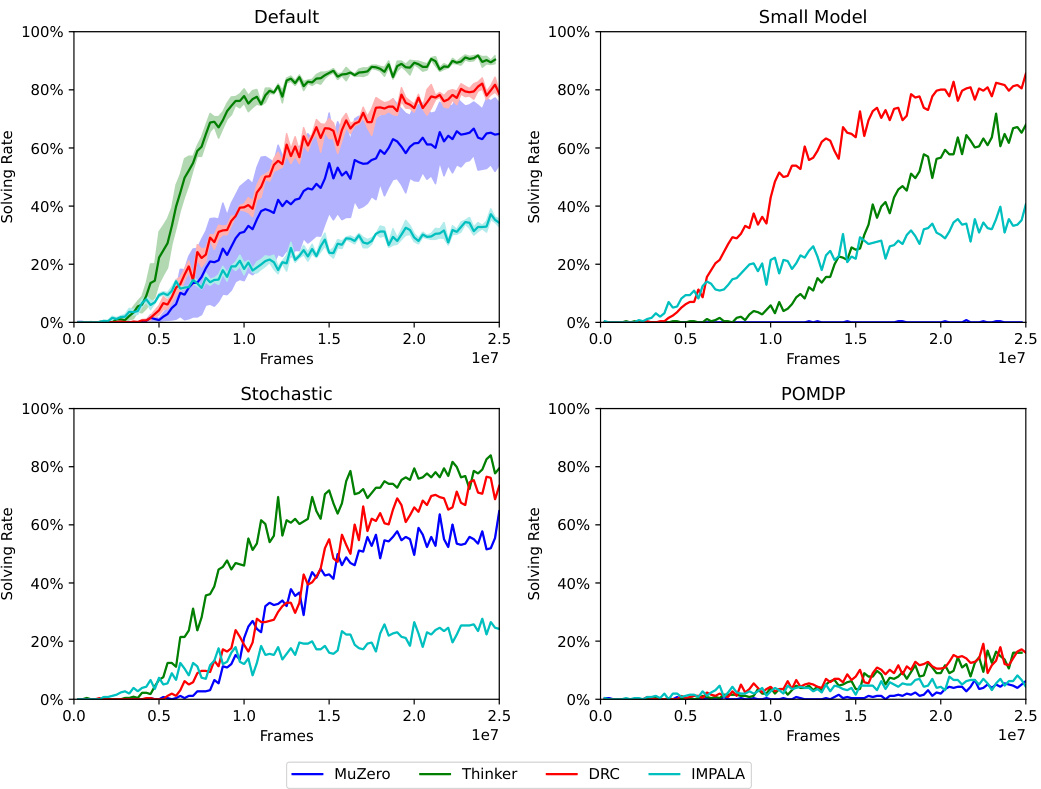
This figure shows the learning curves of four different reinforcement learning agents (MuZero, Thinker, DRC, and IMPALA) trained on the Sokoban environment. The x-axis represents the number of frames (or training steps) and the y-axis represents the average solving rate over the last 200 episodes. The plot includes four subplots corresponding to the different experimental settings: default, small model, stochastic, and POMDP. The shaded regions in the default setting subplot show the standard error for each agent across three different random seeds. These curves illustrate how well the agents learn to solve Sokoban tasks under various conditions, indicating differences in learning speed and performance between various RL algorithms.
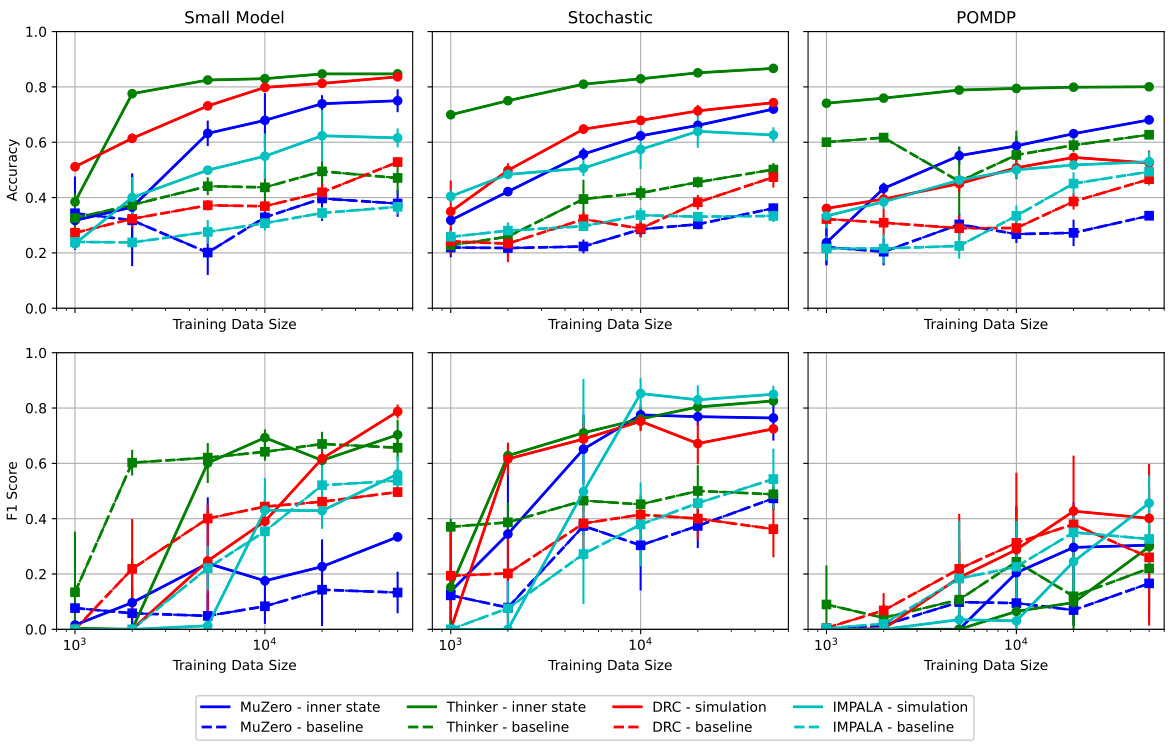
This figure shows the performance difference between the default setting and three model ablation settings: small model, stochastic action, and partially observable Markov Decision Process (POMDP). The x-axis represents the size of the training data used for the predictors. The y-axis shows the changes in both accuracy of action prediction and F1 score of event prediction. The three ablation settings demonstrate the impact of reduced model capacity (small model), unexpected stochasticity (stochastic action), and partial observability (POMDP) on the performance of the different prediction methods (inner state approach for MuZero, Thinker, and simulation-based approach for DRC, IMPALA). The results highlight the robustness of the inner state approach for explicit planning agents (MuZero, Thinker) under these challenging conditions.

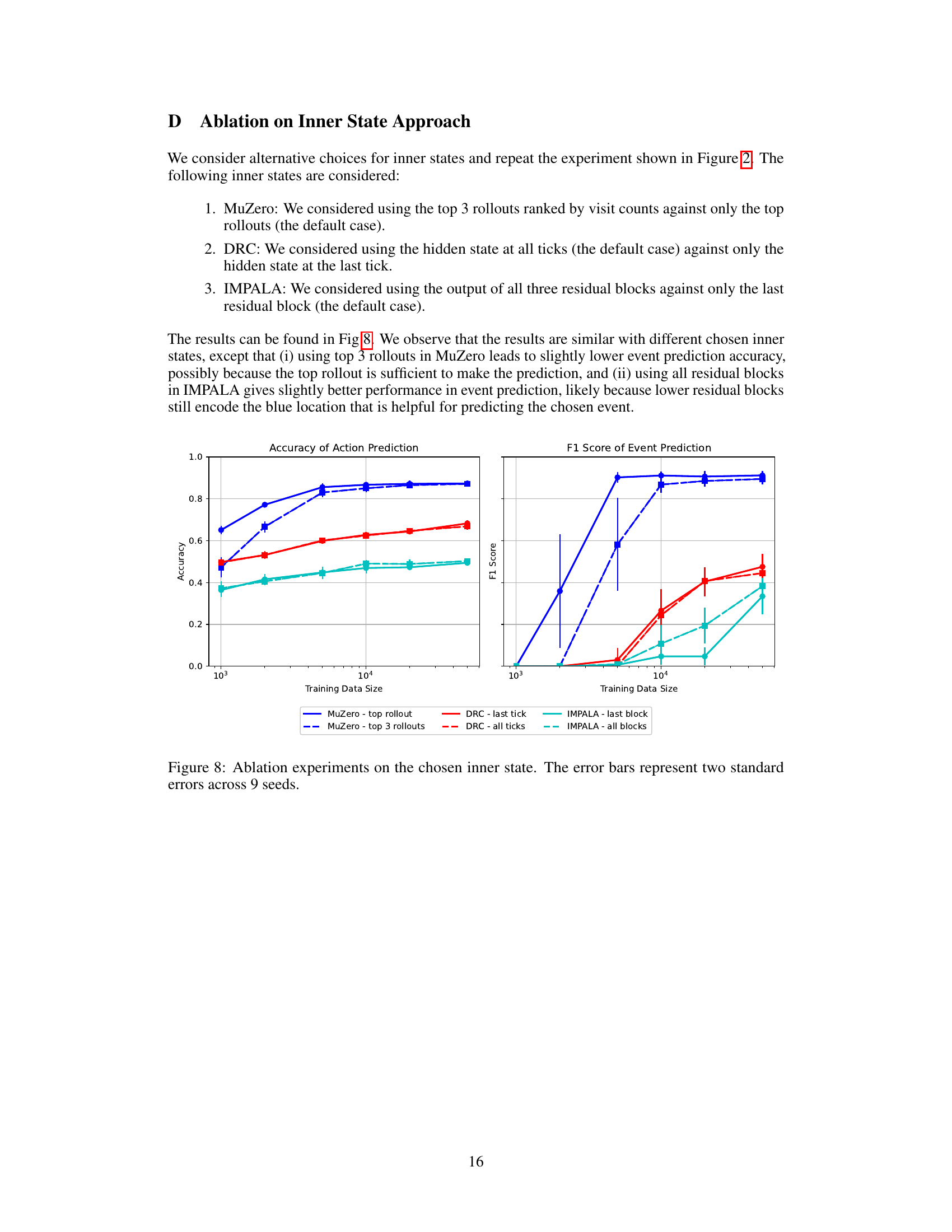
This figure presents the results of ablation experiments conducted on the inner state approach for action and event prediction. Different choices of inner states were tested for MuZero, DRC, and IMPALA agents, evaluating the impact on predictive accuracy. For MuZero, using either the top rollout or the top 3 rollouts was compared. For DRC, using the hidden state at the last tick or all ticks was investigated. IMPALA was tested with the output of either the last residual block or all three residual blocks. The results show that the choice of inner state has a relatively minor impact on the overall predictive accuracy, suggesting robustness in the chosen approach.
Full paper#