↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
In-context learning (ICL) has shown promise in improving large language and multimodal models, but it faces challenges: high computational cost when using many demonstrations and sensitivity to the quality of demonstrations. These challenges are particularly acute in multimodal tasks like visual question answering (VQA). Current approaches try to extract the most informative features from demonstrations into non-learnable vectors; however, these methods fail to work well for complex multimodal tasks.
This study proposes LIVE (Learnable In-Context Vector) to address these issues. LIVE learns to extract essential information from demonstrations improving ICL performance. Experiments show that LIVE significantly reduces computational costs and enhances the accuracy of VQA compared to existing methods. The learnable nature of LIVE allows it to effectively capture the essence of demonstrations, outperforming non-learnable methods in complex multimodal tasks and achieving improved efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large multimodal models (LMMs) and in-context learning (ICL). It addresses the significant computational cost and sensitivity to demonstration selection inherent in ICL for LMMs. By introducing LIVE, a novel learnable approach, this research offers a more efficient and robust method for improving ICL in complex multimodal tasks like Visual Question Answering (VQA), opening new avenues for research in this rapidly developing field. The efficiency gains and improved accuracy demonstrated by LIVE hold significant practical implications.
Visual Insights#
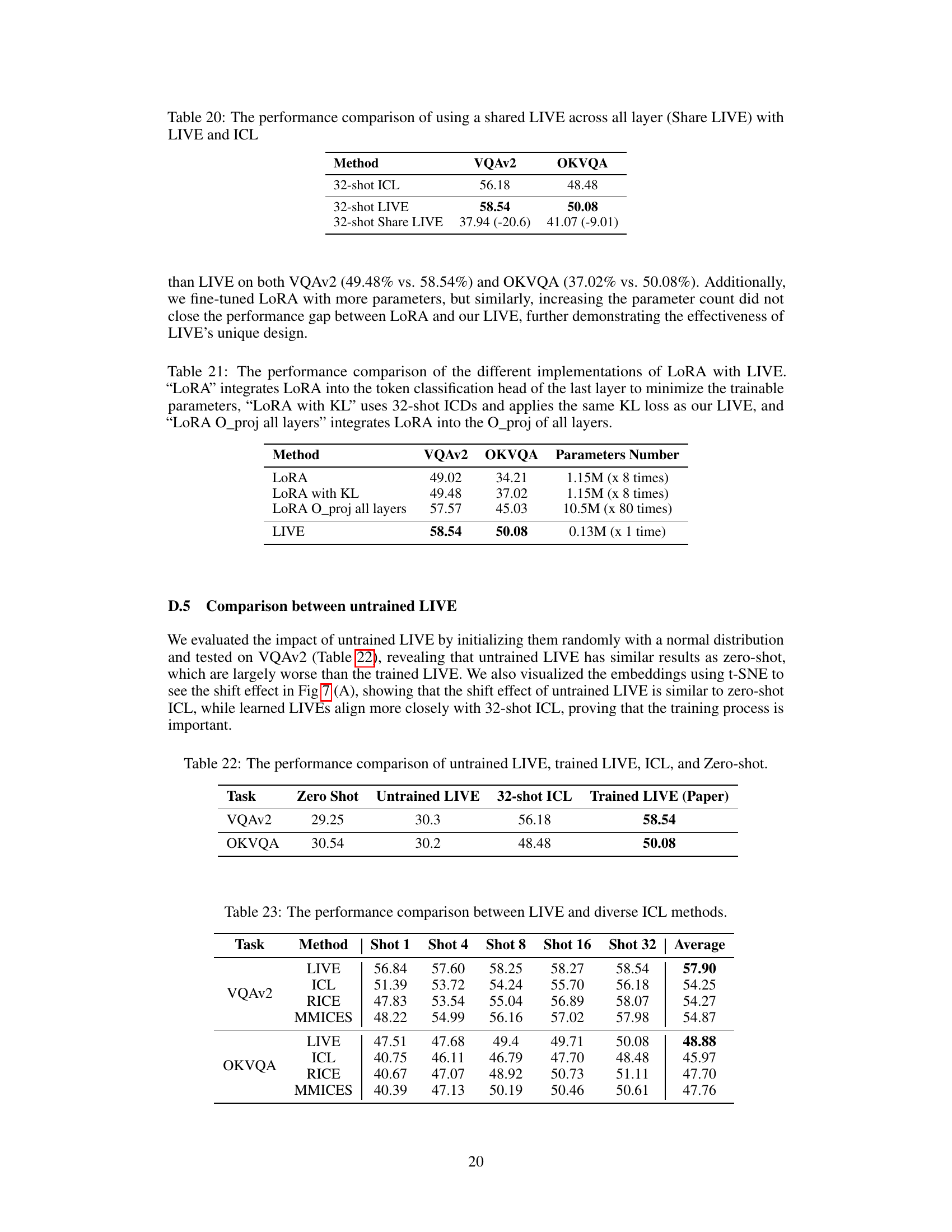
This figure compares the conventional In-Context Learning (ICL) method with the proposed Learnable In-Context Vector (LIVE) method. Panel (a) shows that conventional ICL is highly sensitive to the choice of in-context demonstrations (ICDs), requiring more ICDs for high performance which in turn increases inference time and the number of FLOPs. Panel (b) demonstrates that LIVE, by inputting a shift vector derived from demonstrations, significantly reduces inference time and the number of FLOPs while maintaining comparable accuracy, making it more robust to ICD selection.

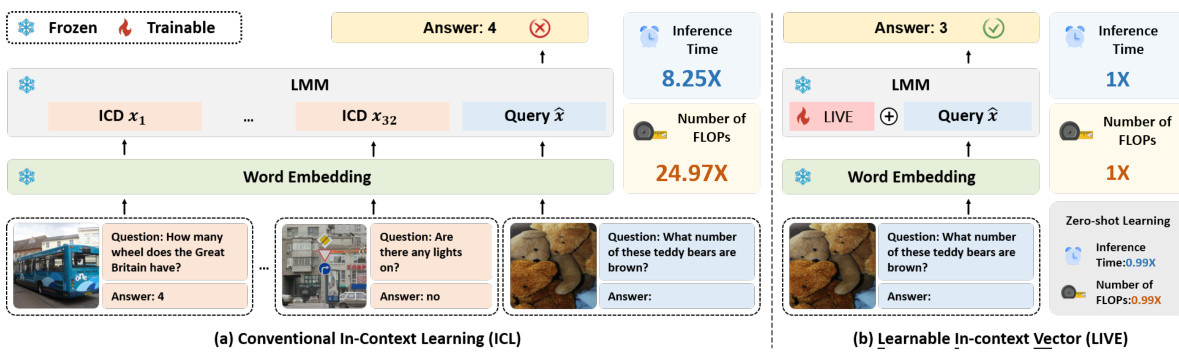
This table compares the performance of different In-Context Vector (ICV) methods and a fine-tuning method (LoRA) on two Visual Question Answering (VQA) datasets: VQAv2 and OKVQA. The methods compared include a zero-shot baseline, 32-shot In-Context Learning (ICL), three non-learnable ICV methods (Task Vector, Function Vector, and PCA-ICV), and LoRA. The table shows the accuracy achieved by each method and the total number of trainable parameters used. The numbers in parentheses indicate how many times larger the trainable parameters are compared to LIVE (Ours).
In-depth insights#
LIVE: Learnable ICV#
The proposed “LIVE: Learnable ICV” method presents a novel approach to improve in-context learning (ICL) in large multimodal models (LMMs). Traditional ICL methods suffer from high computational costs and sensitivity to the selection of in-context demonstrations. LIVE aims to overcome these limitations by learning a compact vector representation of essential task information from demonstrations. This learnable in-context vector (LIV) is then used to efficiently guide the LMM during inference, thereby significantly reducing computational cost and improving accuracy. Unlike non-learnable ICV methods, LIVE learns a task-specific shift direction, enabling better adaptation to complex multimodal tasks like Visual Question Answering (VQA). The method’s effectiveness is demonstrated through experiments showing improved accuracy and reduced computational overhead compared to traditional ICL and other non-learnable ICV techniques. The learnable nature of LIVE offers greater flexibility and robustness compared to methods that rely on statically extracted representations of demonstrations.
ICL Efficiency Gains#
In the realm of large language models (LLMs), In-Context Learning (ICL) presents a powerful paradigm for adapting models to new tasks without explicit retraining. However, ICL’s efficiency can be significantly hampered by the increased computational cost associated with processing numerous in-context demonstrations (ICDs). This paper explores strategies for enhancing the efficiency of ICL, focusing on reducing inference time and the sensitivity of performance to ICD selection. A key aspect is the introduction of Learnable In-Context Vectors (LIVE), which aim to distill essential task information from the ICDs into a compact representation that significantly reduces computational load while preserving accuracy. LIVE’s effectiveness is particularly highlighted in complex multimodal tasks such as Visual Question Answering (VQA), where the benefits of reduced computational cost and improved robustness are even more pronounced. The results demonstrate substantial efficiency gains compared to traditional ICL and other non-learnable ICV methods, making LIVE a promising approach for optimizing ICL performance in demanding applications.
VQA Task Distillation#
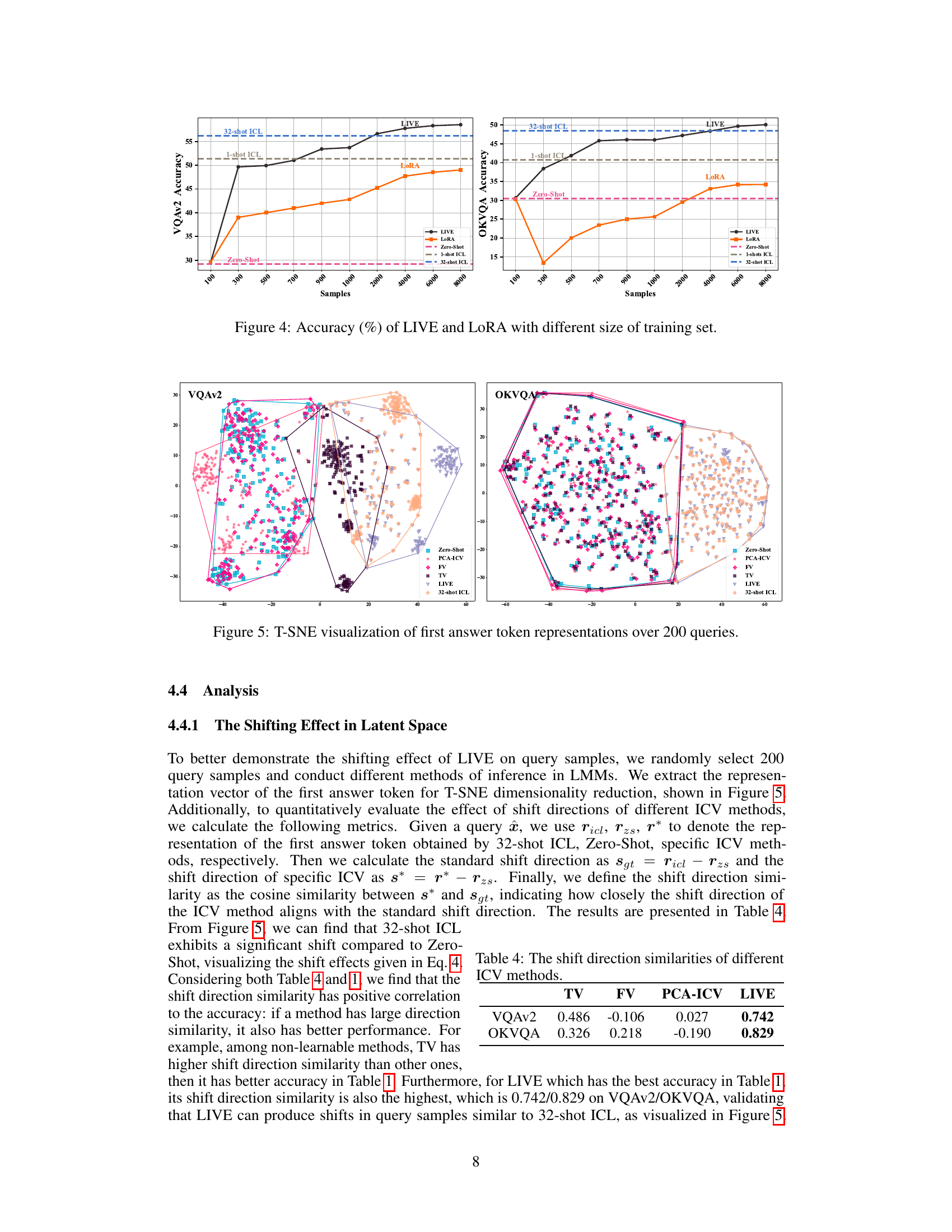
VQA task distillation is a promising approach to improve efficiency and robustness in visual question answering (VQA). The core idea revolves around distilling the knowledge and task-specific information inherent in a large set of VQA demonstrations into a compact, learnable representation, such as an In-Context Vector (ICV). This contrasts with traditional In-Context Learning (ICL), which relies on feeding numerous demonstrations directly to the model, leading to increased computational cost and sensitivity to demonstration selection. Effective task distillation methods learn a vector that captures the essence of the task, enabling accurate VQA responses without the overhead of numerous samples. This approach offers significant advantages, including reduced inference time and improved performance, especially when handling complex, multimodal inputs. The critical challenge lies in designing a distillation method that effectively captures the relevant aspects of the task while discarding irrelevant details from the training data. Learnable methods, unlike their non-learnable counterparts, show significant promise in effectively capturing the complex relationships and nuances present in VQA tasks. Further research should focus on developing more sophisticated distillation methods to further enhance the performance and reduce the reliance on computationally expensive ICL.
Multimodal ICL Limits#
Multimodal In-Context Learning (ICL) holds immense promise but faces significant hurdles. Computational cost explodes as the number of in-context demonstrations increases, hindering real-world applications. Performance is highly sensitive to the quality and selection of these demonstrations, creating an optimization challenge. The inherent complexity of multimodal data exacerbates these issues, as the interaction between different modalities (image, text, etc.) becomes difficult to manage effectively. Existing non-learnable methods for distilling task information from demonstrations often fail to capture the nuanced nature of complex multimodal tasks. Therefore, developing efficient and robust strategies for demonstration selection, feature extraction, and model adaptation is crucial to unlock the full potential of multimodal ICL.
Future Research: LIVE#
Future research directions for LIVE could explore its generalizability across diverse LMM architectures and multimodal tasks, going beyond VQA. Investigating the impact of different demonstration selection strategies and their effect on LIVE’s performance is crucial. Furthermore, research should focus on improving LIVE’s efficiency by optimizing the training process and potentially exploring alternative methods for distilling task information. A deeper analysis of the interplay between LIVE and different layers of the LLM is needed to understand how LIVE interacts with the LLM’s internal mechanisms. Finally, exploring the potential for incorporating external knowledge into LIVE to enhance its performance on tasks requiring world knowledge is a promising avenue. Addressing potential biases and ethical considerations related to the training data and applications of LIVE is also vital for responsible development.
More visual insights#
More on figures

This figure illustrates the LIVE training pipeline, comparing it to conventional In-Context Learning (ICL). Panel (a) shows the distribution of the Large Multimodal Model (LMM) output P(V, α; M) when using the Learnable In-Context Vector (LIVE). Panel (b) demonstrates how LIVE is added to the query representation to simulate the shift effect of the in-context demonstrations, highlighting the mechanism of LIVE’s intervention in the LMM. Finally, panel (c) shows the distribution of the LMM output P(x|XD; M) when using conventional ICL with demonstrations, serving as a baseline for comparison with LIVE. The figure visually conveys how LIVE aims to efficiently mimic the effect of ICL using a smaller input size.

This figure compares the conventional In-Context Learning (ICL) method with the proposed Learnable In-Context Vector (LIVE) method. Panel (a) illustrates that conventional ICL is highly sensitive to the selection of in-context demonstrations (ICDs) and requires significantly more inference time as the number of ICDs increases. Panel (b) shows that LIVE mitigates these issues by using a learned shift vector, resulting in a more robust and efficient approach with reduced inference time and FLOPs.

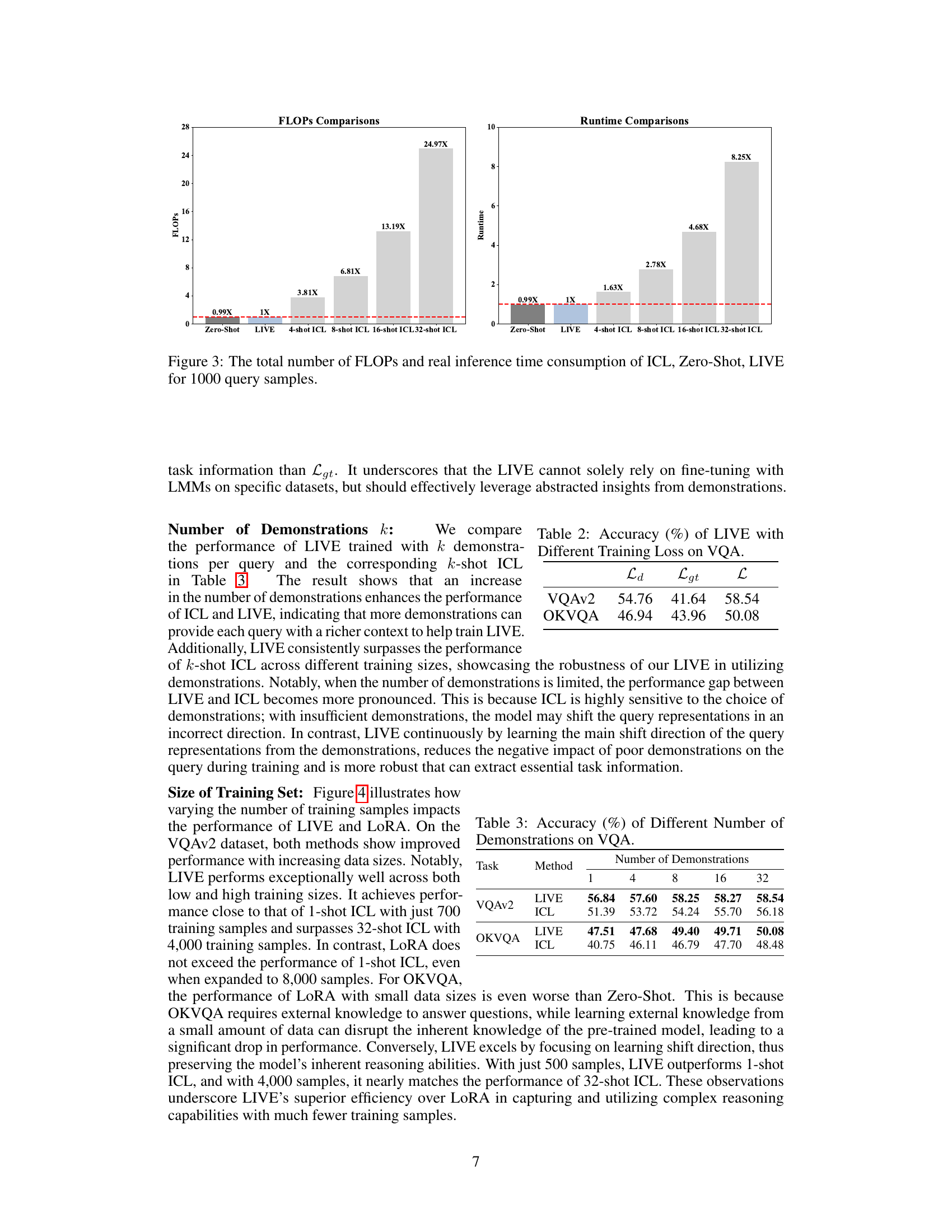
This figure compares the computational efficiency and inference speed of three different methods: Conventional In-Context Learning (ICL), Zero-shot learning, and the proposed Learnable In-Context Vector (LIVE). It shows that LIVE significantly reduces both the number of FLOPs (floating-point operations) and the inference time compared to ICL while maintaining performance similar to zero-shot learning. The results highlight LIVE’s computational advantage for Visual Question Answering (VQA) tasks.

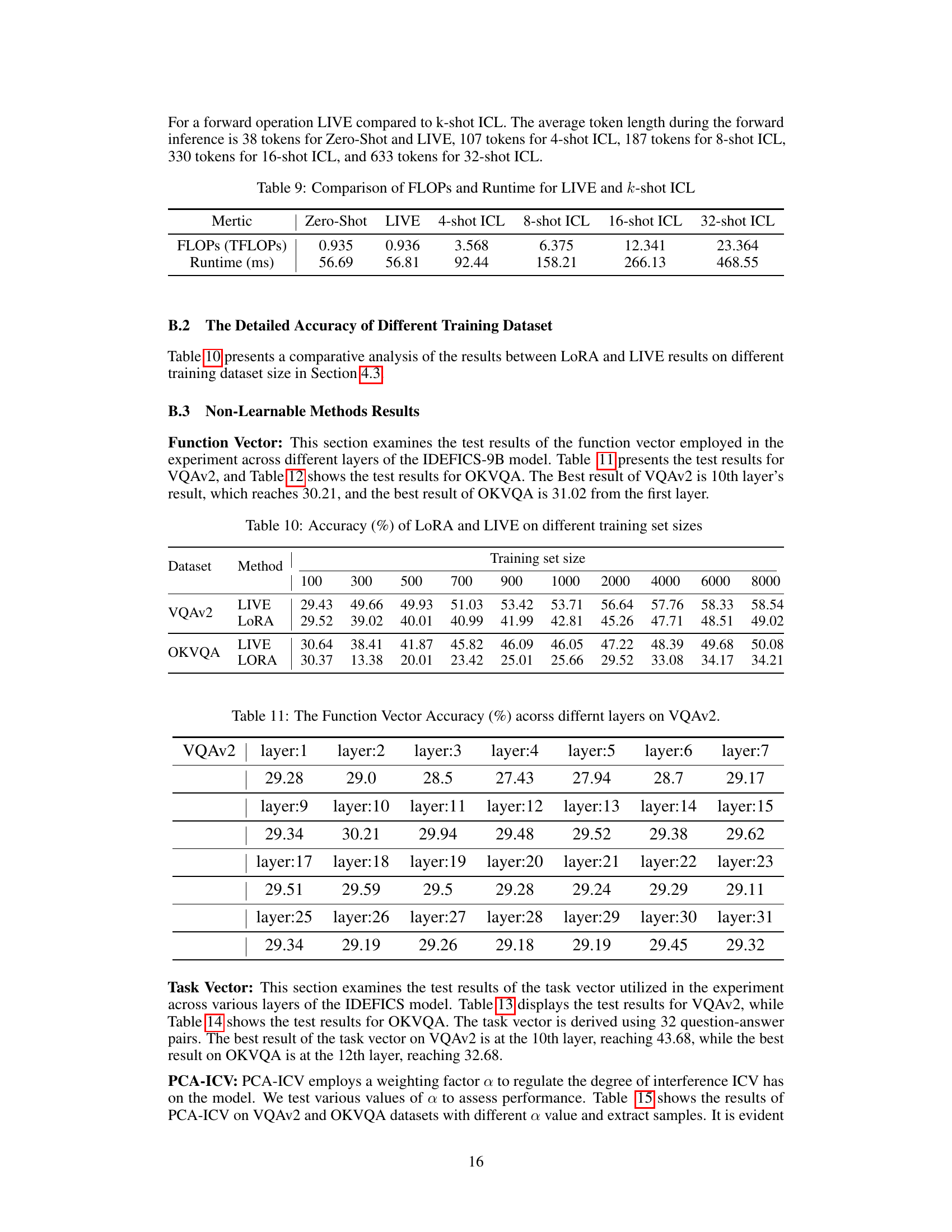
This figure visualizes the effect of different methods (Zero-Shot, PCA-ICV, FV, TV, LIVE, and 32-shot ICL) on the representation of the first answer token in the latent space of the LLM. It uses t-SNE to reduce the dimensionality of the representations for better visualization. The plot shows how each method shifts the representation of the query compared to the zero-shot baseline, illustrating the impact of in-context demonstrations and the proposed LIVE method on the model’s output. The clustering and separation of points for each method illustrate the effectiveness of the different approaches in guiding the model’s attention and improving its performance.

This figure illustrates the LIVE training pipeline, comparing it to conventional in-context learning. Panel (a) shows the output distribution of the language model when using the Learnable In-Context Vector (LIVE) to shift the query representations. Panel (b) visually depicts how LIVE modifies the query representations by simulating the shift effect that demonstrations normally provide in ICL. Panel (c) shows the output distribution of the language model when using demonstrations in a traditional in-context learning setup. The figure highlights LIVE’s ability to replace the need for multiple demonstrations, thus improving efficiency and reducing sensitivity to demonstration selection.

This figure visualizes the effect of different methods (Zero-Shot, 32-shot ICL, Untrained LIVE, and Trained LIVE) on the representation of the first answer token in the latent space of a language model. The visualization uses t-SNE to reduce the dimensionality of the representations and show their distribution in 2D. By comparing the distributions generated by these different methods, we can observe how each method shifts the representation of the query towards the correct answer, and the extent to which each method achieves this effect. The figure demonstrates that Trained LIVE’s representation is closer to the 32-shot ICL method than other methods, signifying its effectiveness in simulating the effect of multiple demonstrations in in-context learning.
More on tables

This table presents the accuracy achieved by the LIVE model on two VQA datasets (VQAv2 and OKVQA) when trained using different loss functions. It compares the performance using only the KL divergence loss (Ld), only the ground truth loss (Lgt), and a combined loss (L) that balances both. The results demonstrate the impact of different loss functions on the model’s accuracy.
This table compares the accuracy of different in-context learning (ICL) methods and a fine-tuning method (LoRA) on two Visual Question Answering (VQA) datasets: VQAv2 and OKVQA. The methods compared include a baseline zero-shot approach, 32-shot ICL, three non-learnable In-Context Vector (ICV) methods (Task Vector, Function Vector, PCA-ICV), and the proposed Learnable In-Context Vector (LIVE) method. The table also shows the number of trainable parameters for each method, relative to the number of trainable parameters in LIVE.

This table compares the accuracy of different in-context learning (ICL) methods on the VQAv2 and OKVQA datasets. The methods compared include Zero-Shot (no in-context examples), 32-shot ICL (32 in-context demonstrations), three non-learnable ICV (In-Context Vector) methods (Task Vector, Function Vector, PCA-ICV), LoRA (a finetuning method), and the proposed LIVE method. The numbers in parentheses indicate how many times larger the model’s trainable parameters are compared to LIVE’s.

This table compares the accuracy of different methods for visual question answering (VQA) on two datasets: VQAv2 and OKVQA. The methods compared include Zero-Shot (no context), 32-shot ICL (conventional in-context learning with 32 demonstrations), three non-learnable In-Context Vector (ICV) methods (Task Vector, Function Vector, PCA-ICV), LoRA (a parameter-efficient fine-tuning method), and the proposed LIVE method. The table shows the accuracy achieved by each method and the number of trainable parameters used (relative to the number used in LIVE).
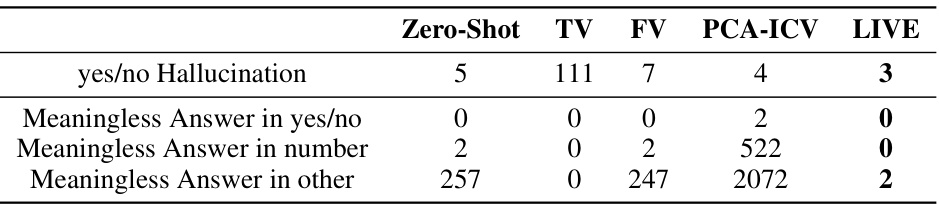
This table compares the accuracy of different in-context learning methods on two visual question answering datasets (VQAv2 and OKVQA). The methods compared include a zero-shot baseline, 32-shot in-context learning (ICL), three non-learnable in-context vector (ICV) methods (Task Vector, Function Vector, PCA-ICV), a LoRA fine-tuning method, and the proposed LIVE method. The number in parentheses indicates the relative size of the trainable parameters of each method compared to the LIVE method. It shows the performance improvements LIVE offers over other methods in terms of accuracy while being computationally efficient.

This table compares the accuracy achieved by various methods on the VQAv2 and OKVQA datasets. The methods include Zero-Shot (no context), 32-shot ICL (conventional In-Context Learning with 32 demonstrations), three non-learnable ICV (In-Context Vector) methods (Task Vector, Function Vector, PCA-ICV), LoRA (a finetuning method), and the proposed LIVE method. The numbers in parentheses indicate how many times larger the number of trainable parameters is for each method compared to LIVE. It demonstrates LIVE’s superior accuracy and efficiency compared to other methods.

This table compares the accuracy achieved by different in-context learning (ICL) methods and fine-tuning methods on VQAv2 and OKVQA datasets. It shows the performance of zero-shot learning, 32-shot ICL, three non-learnable ICV methods (Task Vector, Function Vector, PCA-In-Context Vector), LoRA, and the proposed LIVE method. The numbers in parentheses indicate the relative size of trainable parameters compared to LIVE. This provides a quantitative assessment of the effectiveness and efficiency of various methods compared to the proposed method.

This table compares the accuracy achieved by different methods on the VQAv2 and OKVQA datasets. The methods include a zero-shot baseline, 32-shot In-Context Learning (ICL), three non-learnable In-Context Vector (ICV) methods (Task Vector, Function Vector, PCA-ICV), LoRA (a finetuning method), and the proposed LIVE method. The numbers in parentheses indicate how many times larger the trainable parameter count is for each method compared to LIVE. This table showcases the performance gains of LIVE compared to traditional methods, highlighting its efficiency and accuracy in visual question answering.

This table compares the performance of different in-context learning (ICL) methods and a fine-tuning method (LoRA) on two Visual Question Answering (VQA) datasets (VQAv2 and OKVQA). The methods compared include several non-learnable In-Context Vector (ICV) methods (Task Vector, Function Vector, PCA-ICV) along with 32-shot ICL and the proposed Learnable In-Context Vector (LIVE) method. The table shows accuracy and the number of trainable parameters for each method, relative to the number of parameters in LIVE.
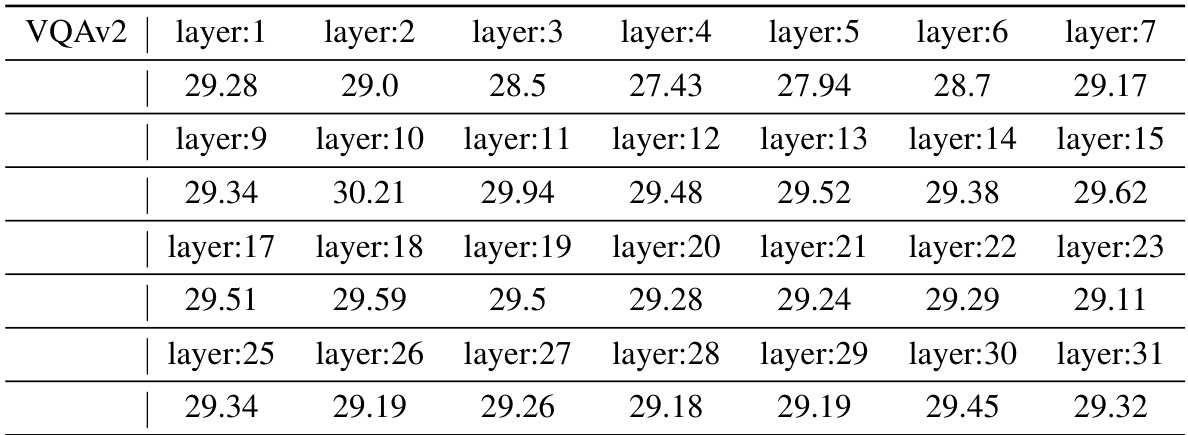
This table presents a comparison of the accuracy achieved by various methods on two Visual Question Answering (VQA) datasets: VQAv2 and OKVQA. The methods compared include the baseline Zero-Shot approach, the standard 32-shot In-Context Learning (ICL), three non-learnable In-Context Vector (ICV) methods (Task Vector, Function Vector, and PCA-ICV), the LoRA finetuning method, and the proposed LIVE method. The table highlights the accuracy improvement of LIVE over other methods while using significantly fewer trainable parameters. The numbers in parentheses indicate the relative size of the model’s trainable parameters compared to LIVE.

This table compares the accuracy of different methods for visual question answering (VQA) on two datasets, VQAv2 and OKVQA. The methods compared include a zero-shot baseline, 32-shot In-Context Learning (ICL), three non-learnable In-Context Vector (ICV) methods (Task Vector, Function Vector, and PCA-ICV), LoRA (a fine-tuning method), and the proposed LIVE method. The table shows accuracy and the number of trainable parameters relative to LIVE’s parameter count for each method, highlighting LIVE’s efficiency in terms of both accuracy and parameter usage.

This table compares the performance of various In-Context Vector (ICV) methods and fine-tuning methods (LoRA) on two VQA datasets (VQAv2 and OKVQA). It shows accuracy results for a zero-shot baseline, a 32-shot In-Context Learning (ICL) approach, three non-learnable ICV methods (Task Vector, Function Vector, PCA-ICV), and the proposed LIVE method. The numbers in parentheses indicate the relative number of trainable parameters compared to LIVE.
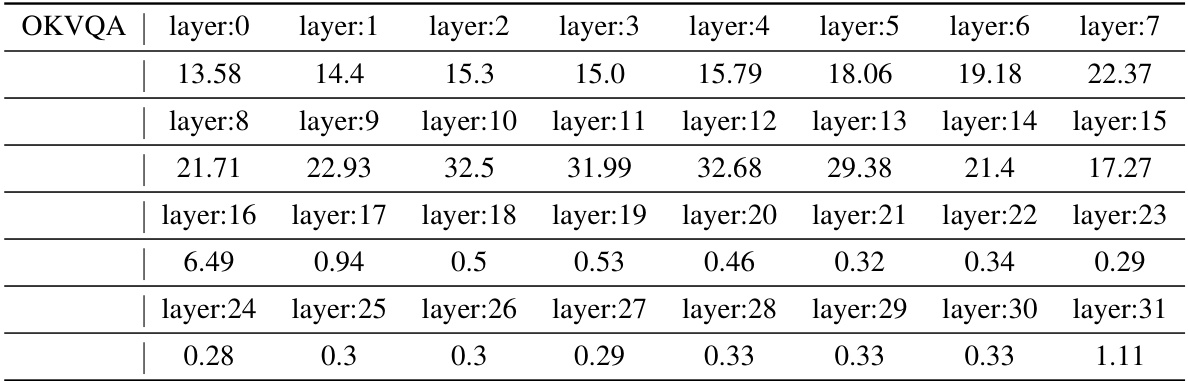
This table compares the performance of different In-Context Vector (ICV) methods and the fine-tuning method LoRA on two Visual Question Answering (VQA) datasets, VQAv2 and OKVQA. It shows the accuracy achieved by each method, including zero-shot, 32-shot ICL (In-Context Learning), three non-learnable ICV methods (Task Vector, Function Vector, PCA-In-Context Vector), and LoRA. The number of trainable parameters for each method, relative to LIVE, are also shown.

This table compares the performance of different In-Context Vector (ICV) methods and a finetuning method (LoRA) on two Visual Question Answering (VQA) datasets: VQAv2 and OKVQA. It shows accuracy results for a zero-shot baseline, 32-shot In-Context Learning (ICL), three non-learnable ICV methods (Task Vector, Function Vector, PCA-ICV), and the proposed Learnable In-Context Vector (LIVE) method. The table also indicates how many times larger the trainable parameter count of each method is compared to LIVE’s trainable parameters. This allows for a comparison of performance versus model complexity.

This table compares the accuracy of different methods on VQAv2 and OKVQA datasets. The methods include Zero-Shot, 32-shot ICL, three non-learnable ICV methods (Task Vector, Function Vector, PCA-In-Context Vector), LoRA (a fine-tuning method), and LIVE (the proposed method). The numbers in parentheses indicate the relative number of trainable parameters compared to LIVE. The table demonstrates LIVE’s superior accuracy and efficiency compared to other methods.

This table presents a comparison of the accuracy achieved by different methods on two VQA datasets (VQAv2 and OKVQA). The methods compared include Zero-Shot (no context), 32-shot ICL (conventional In-Context Learning with 32 demonstrations), three non-learnable ICV (In-Context Vector) methods (Task Vector, Function Vector, PCA-ICV), LoRA (a parameter-efficient fine-tuning method), and LIVE (the proposed Learnable In-Context Vector method). The table shows the accuracy of each method and the number of trainable parameters used (relative to the number of parameters in LIVE). This allows for a comparison of accuracy vs. model complexity/computational cost.

This table compares the performance of various methods on two VQA datasets (VQAv2 and OKVQA). The methods include a zero-shot baseline, 32-shot In-Context Learning (ICL), three non-learnable In-Context Vector (ICV) methods (Task Vector, Function Vector, PCA-ICV), and the proposed LoRA and LIVE methods. The table shows accuracy and the number of trainable parameters (relative to LIVE). It demonstrates the effectiveness of LIVE in improving accuracy and efficiency compared to other approaches.

This table presents the accuracy of different methods on VQAv2 and OKVQA datasets. It compares the performance of Zero-Shot, 32-shot ICL (In-Context Learning), three non-learnable In-Context Vector (ICV) methods (Task Vector, Function Vector, and PCA-ICV), LoRA (a finetuning method), and the proposed LIVE method. The numbers in parentheses show the relative number of trainable parameters compared to LIVE. The table highlights the superior accuracy of LIVE while using significantly fewer parameters than other methods, especially compared to 32-shot ICL.
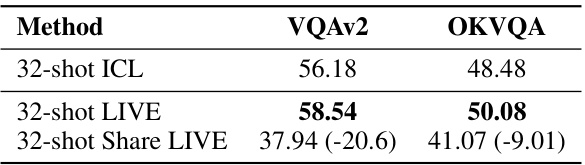
This table compares the accuracy of different in-context learning (ICL) methods and fine-tuning methods on two visual question answering (VQA) datasets: VQAv2 and OKVQA. The methods compared include Zero-Shot (no context), 32-shot ICL (32 in-context demonstrations), three non-learnable In-Context Vector (ICV) methods (Task Vector, Function Vector, PCA-ICV), LoRA (a fine-tuning method), and the proposed LIVE (Learnable In-Context Vector) method. The numbers in parentheses show the relative size of the trainable parameters for each method compared to LIVE.

This table presents a comparison of the accuracy achieved by different methods on the VQAv2 and OKVQA datasets. The methods compared include Zero-Shot (no in-context learning), 32-shot ICL (conventional in-context learning with 32 demonstrations), three non-learnable ICV methods (Task Vector, Function Vector, PCA-ICV), LoRA (a fine-tuning method), and the proposed LIVE method. The numbers in parentheses show the relative number of trainable parameters for each method, normalized to the number of parameters used by LIVE.

This table compares the accuracy of different methods on the VQAv2 and OKVQA datasets. The methods include zero-shot, 32-shot ICL, three non-learnable ICV methods (Task Vector, Function Vector, PCA-In-Context Vector), LoRA, and the proposed LIVE method. The numbers in parentheses indicate the multiple of the LIVE’s trainable parameters used by each method for a fairer comparison. It shows LIVE’s superior performance and efficiency compared to other methods.
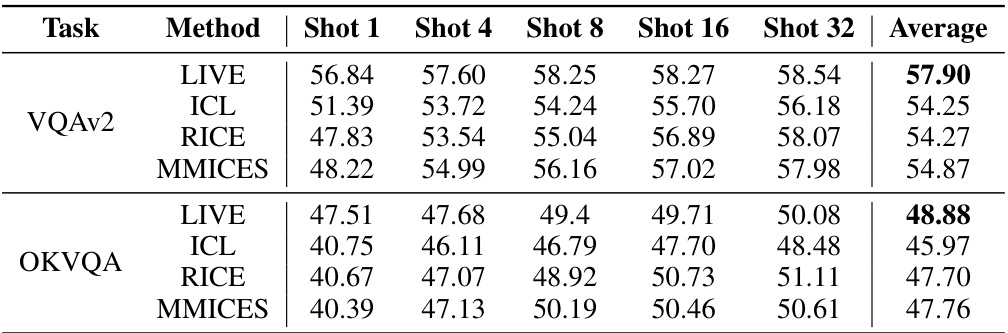
This table presents the accuracy achieved by various methods on the VQAv2 and OKVQA datasets. The methods compared include a zero-shot baseline, 32-shot In-Context Learning (ICL), three non-learnable In-Context Vector (ICV) methods (Task Vector, Function Vector, and PCA-In-Context Vector), LoRA (a parameter-efficient fine-tuning method), and the proposed LIVE method. The numbers in parentheses indicate the relative size of the trainable parameters for each method compared to LIVE. The table allows for a comparison of the performance and efficiency of different methods for visual question answering (VQA).
Full paper#