↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but adapting them to specific tasks is expensive and time-consuming, either through fine-tuning or in-context learning. Fine-tuning requires substantial computational resources and in-context learning can be slow. This paper addresses these issues by proposing a novel method.
The proposed method, Reference Trustable Decoding (RTD), is training-free. It enhances the decoding stage by using a reference datastore, allowing flexible knowledge integration without parameter adjustments and enhancing speed. This technique demonstrates comparable performance to traditional methods while maintaining cost-effectiveness and making it a significant advance in LLM augmentation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs because it introduces a novel, training-free method to efficiently adapt LLMs to various downstream tasks. This is particularly significant given the high cost and resource demands often associated with traditional fine-tuning and in-context learning techniques. The proposed approach, Reference Trustable Decoding (RTD), paves the way for more efficient and cost-effective LLM adaptation, opening up exciting new avenues for research and development.
Visual Insights#
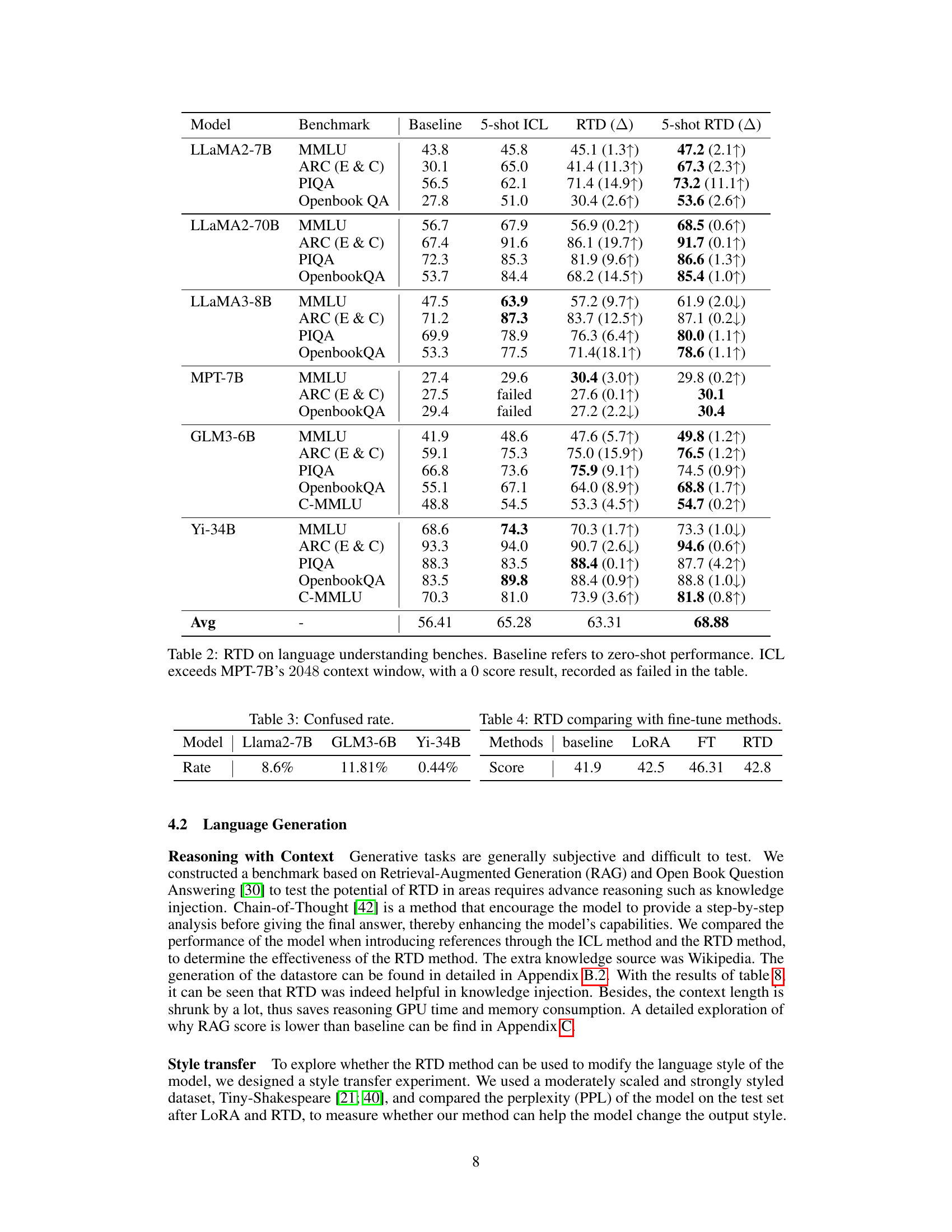
This figure presents a comparison of the performance of different LLMs on several reasoning tasks. It shows the results for a baseline LLM (default decoding) and an augmented version using the proposed Reference Trustable Decoding (RTD) method. The figure displays results for both zero-shot and five-shot settings, with and without multi-head RTD. Each point on the radar charts represents the performance of a given method on a specific reasoning test (STEM, Social Science, OBQA, Humanities, Other, ARC-E, and ARC-C). The comparison highlights the improvement in reasoning capabilities achieved by RTD, particularly in five-shot scenarios.
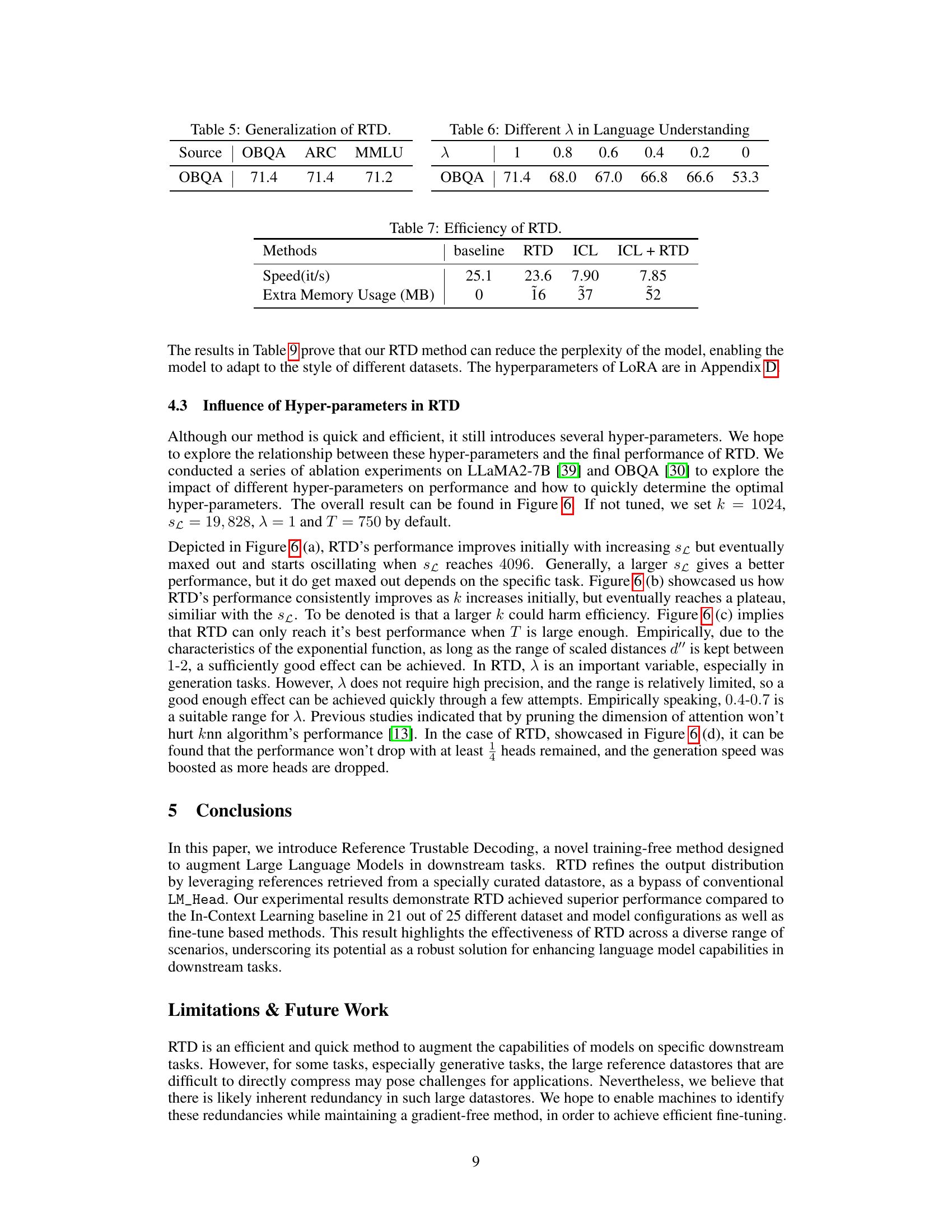
This table compares the performance of the Reference Trustable Decoding (RTD) method and its multi-head variant (MH-RTD) on the Open Book Question Answering (OBQA) benchmark. It shows the scores achieved by each method using three different large language models (LLMs): MPT-7B, LLaMA2-7B, and LLaMA2-70B. The results demonstrate the improvement in performance offered by the multi-head approach over the single-head RTD.
In-depth insights#
LLM Augmentation#
Large Language Model (LLM) augmentation is a crucial area of research focusing on enhancing the capabilities of LLMs. Current methods primarily involve in-context learning (ICL) and parameter-efficient fine-tuning (PEFT). ICL leverages few-shot learning or retrieval-augmented generation to adapt LLMs to downstream tasks without altering model parameters, but suffers from slower inference speeds. PEFT modifies a minimal subset of parameters, requiring less computational resources than full fine-tuning, but still demands significant training. A novel approach like Reference Trustable Decoding (RTD) aims to address these limitations by offering a training-free method that dynamically selects relevant references based on input, adapting the model’s vocabulary distribution without parameter changes, hence enhancing both speed and efficiency. The core idea is to optimize the final output distribution for trustable response generation. This paradigm shift avoids costly training while offering a compelling alternative to existing augmentation methods.
RTD Framework#
The RTD framework presents a novel, training-free approach to augmenting large language models (LLMs). It operates by constructing a reference datastore from training examples, and during decoding, it selects relevant references based on the input’s hidden state. This process modifies the final vocabulary distribution, leading to more reliable outputs without the need for fine-tuning. Key advantages include improved downstream task adaptation with reduced computational costs, faster inference speeds, and enhanced trust in LLM responses. The framework exhibits strong orthogonality, allowing for concurrent use with traditional methods like ICL and PEFT. While effective, the RTD method is not without limitations. Its performance is sensitive to the quality and size of the reference datastore and the selection of hyperparameters, necessitating careful consideration during implementation. Future research should focus on optimizing datastore efficiency and robust hyperparameter selection to further enhance the framework’s versatility and improve its performance on various downstream tasks.
Multi-head RTD#
The concept of “Multi-head RTD” extends the core idea of Reference Trustable Decoding (RTD) by incorporating a multi-head attention mechanism, mirroring the architecture of large language models (LLMs). This suggests a significant improvement in efficiency and performance. By splitting the large attention vector into smaller, independent heads, the method overcomes the computational bottleneck associated with processing long sequences and large amounts of data, inherent in the original RTD approach. Each head independently queries a subset of the reference datastore, leading to parallel processing and faster inference times. The merging of results from multiple heads likely enhances the robustness and accuracy of the final output. This parallel processing allows for the integration of more context and information with significantly lower latency and space occupancy compared to single-head RTD. The design of Multi-head RTD is, therefore, optimized for efficiency, reducing both time and memory resource consumption while maintaining comparable or improved accuracy, making it highly scalable and suitable for implementation in resource-constrained environments.
Efficiency Gains#
The research paper explores efficiency gains in adapting large language models (LLMs) to downstream tasks. Traditional methods like in-context learning (ICL) and parameter-efficient fine-tuning (PEFT) suffer from slow inference speeds and high resource demands. Reference Trustable Decoding (RTD), the proposed method, achieves significant efficiency improvements by leveraging a reference datastore to guide the model’s output distribution, eliminating the need for fine-tuning and drastically reducing the inference time. The approach focuses on the decoding stage, using a compact input length, while maintaining comparable or even better performance than ICL and PEFT. Multi-head RTD further enhances efficiency by splitting attention vectors, enabling flexible resource allocation and memory optimization. These efficiency gains are quantified through experimental evaluations on various LLMs and benchmark datasets, showcasing RTD’s ability to adapt quickly and cost-effectively, paving the way for more efficient LLM deployment and usage.
Future of RTD#
The future of Reference Trustable Decoding (RTD) appears promising, particularly given its training-free nature and demonstrated effectiveness. Further research should focus on enhancing the efficiency of the reference datastore construction and retrieval processes. This could involve exploring more advanced data structures and search algorithms, potentially leveraging techniques from approximate nearest neighbor search to handle very large datasets efficiently. Another area for improvement lies in developing strategies to handle the complexity of diverse downstream tasks. While RTD shows promise across various benchmarks, further investigation into task-specific adaptations and intelligent reference selection mechanisms is needed. Investigating the optimal balance between datastore size and accuracy will be crucial to optimize RTD’s performance, especially considering the memory overhead associated with larger datastores. Finally, exploring the potential synergy between RTD and other methods like PEFT and ICL could lead to even more powerful approaches for augmenting LLMs. Combining RTD’s efficiency with the targeted adaptations offered by these other methods could represent a significant advance in efficient and effective LLM enhancement.
More visual insights#
More on figures
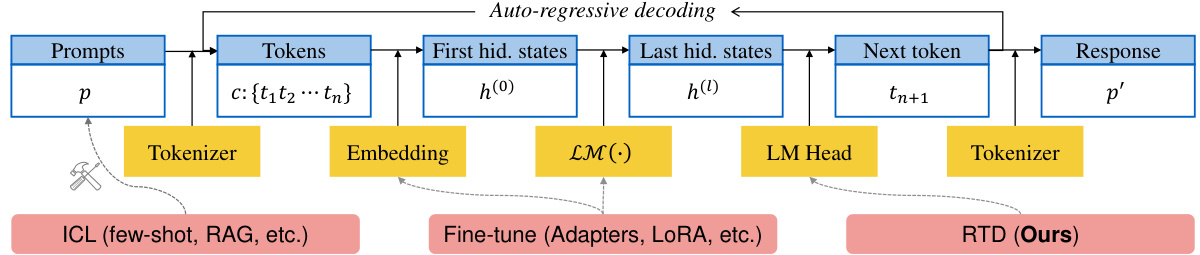
This figure illustrates the different approaches to adapting Large Language Models (LLMs) to downstream tasks. It shows the standard LLM pipeline, highlighting the input (prompts), tokenization, embedding, and autoregressive decoding process. It then compares three methods: In-Context Learning (ICL), which focuses on optimizing the input; Parameter-Efficient Fine-Tuning (PEFT), which modifies the model’s parameters; and the authors’ proposed Reference Trustable Decoding (RTD), which optimizes the final output distribution using a reference datastore without further training.

This figure illustrates the overall architecture of the Reference Trustable Decoding (RTD) method. It shows how a reference datastore is created from a task dataset. The datastore contains key-value pairs, where keys are the last hidden states of the language model and values are corresponding labels. During inference, the language model processes the input, generating hidden states. RTD then uses these states to query the reference datastore, retrieving relevant references, which are then used to refine the final output distribution. The process concludes with the generation of the next token.
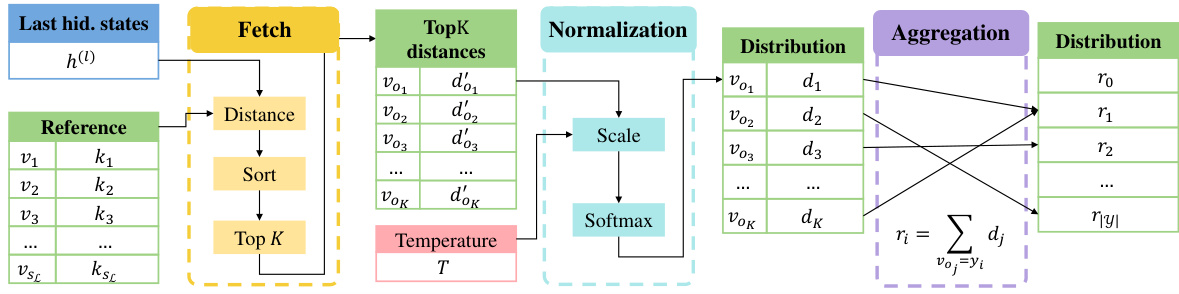
This figure illustrates the three stages of the Reference Trustable Decoding (RTD) process: Fetch, Normalization, and Aggregation. In the Fetch stage, the Euclidean distance between the last hidden states from the language model and all keys in the reference datastore is calculated. The top K nearest keys are then selected and stored in a set Lh. The Normalization stage involves scaling these distances using a temperature parameter T and then applying the softmax function to obtain a valid probability distribution. Finally, the Aggregation stage sums the probabilities for all values that share the same label to yield the final reference possibility distribution r. This distribution is then combined with the output distribution from the Language Model’s LM Head to produce the final output.

This figure illustrates the difference between the single-head RTD and the multi-head RTD. In single-head RTD, the last hidden states h(l) from the language model are directly used to query the reference datastore L, which returns a distribution r. In multi-head RTD, however, h(l) is first split into multiple heads (h(l,1), h(l,2),…,h(l,h)), and each head independently queries a corresponding sub-datastore L(i). The resulting distributions from each head (r(1), r(2),…,r(h)) are then merged to produce the final distribution r.

This figure presents a comparison of the performance of a large language model (LLM) using standard decoding versus the proposed Reference Trustable Decoding (RTD) method. The results are shown across various reasoning tests, broken down by category (e.g., STEM, Social Science, Humanities). It visually demonstrates that RTD consistently improves the LLM’s performance compared to the baseline in different reasoning domains.
More on tables
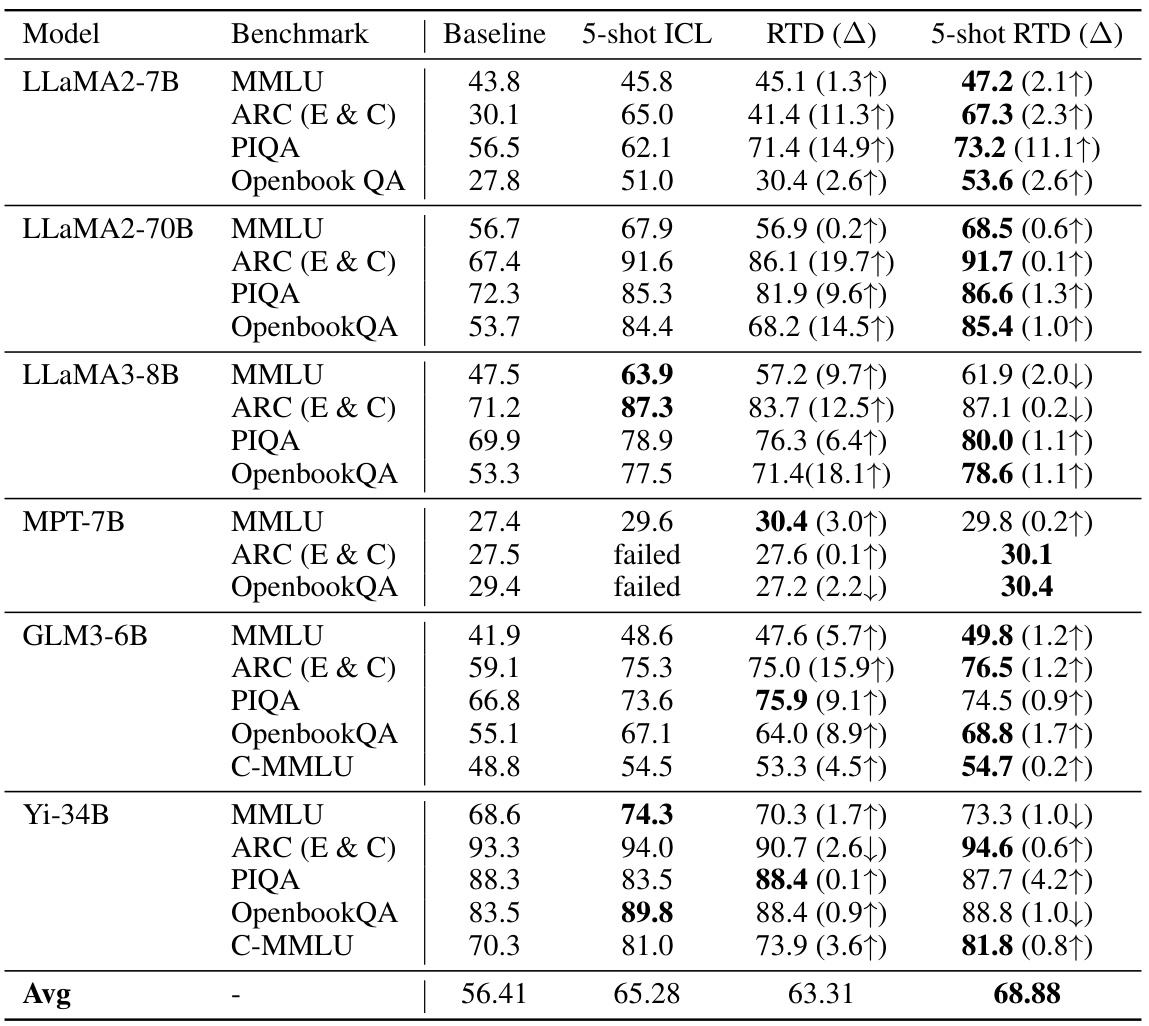
This table presents the results of the Reference Trustable Decoding (RTD) method on several language understanding benchmarks. It compares the performance of RTD against a baseline (zero-shot), 5-shot In-Context Learning (ICL), and 5-shot RTD. The benchmarks include various reasoning and comprehension tasks. The table shows that RTD consistently improves performance over the baseline, and often matches or surpasses the performance of 5-shot ICL, demonstrating the effectiveness of RTD in adapting LLMs to downstream tasks without the need for additional training.

This table presents the results of applying the Reference Trustable Decoding (RTD) method to various language understanding benchmarks. It compares the performance of RTD against a baseline (zero-shot performance) and In-Context Learning (ICL) with 5-shot and 5-shot RTD. The table shows improvements gained by RTD on various Language Models across multiple benchmarks. Note that some ICL results are marked as ‘failed’ due to exceeding the model’s context window limit.

This table presents a performance comparison between the Reference Trustable Decoding (RTD) method and its multi-head variant (MH-RTD) on the Open Book Question Answering (OBQA) benchmark. It shows the scores achieved by RTD and MH-RTD using three different large language models: MPT-7B, LLaMA2-7B, and LLaMA2-70B. The results demonstrate the improvement in performance offered by the multi-head approach.

This table presents the results of the OBQA benchmark using different values for the hyperparameter λ in the RTD method. It shows how the performance of the model on the OBQA task changes with different values of λ, demonstrating the impact of this hyperparameter on the overall performance of the RTD method in language understanding tasks.

This table compares the inference speed (tokens per second) and extra memory usage (in MB) for different methods: baseline (default LLM), RTD, ICL, and ICL+RTD. It shows that RTD has a comparable speed to the baseline while having significantly less memory consumption. Combining ICL and RTD further improves speed but increases memory usage.

This table presents a comparison of the performance of Reference Trustable Decoding (RTD) and Multi-head Reference Trustable Decoding (MH-RTD) on the Open Book Question Answering (OBQA) benchmark. It shows the accuracy achieved by each method using three different large language models: MPT-7B, LLaMA2-7B, and LLaMA2-70B. The results demonstrate the effectiveness of MH-RTD compared to RTD in improving the accuracy on OBQA.

This table shows the average token length of different sections in the Open Book Question Answering (OBQA) dataset. The sections include the Wikipedia context, the question itself, and the response. The data helps to understand the relative lengths of different parts of the OBQA task, which is important in the context of the paper’s discussion of the effect of input length on language model performance.

This table compares the performance of Reference Trustable Decoding (RTD) and Multi-head Reference Trustable Decoding (MH-RTD) on the Open Book Question Answering (OBQA) benchmark. It shows the scores achieved by these methods using different language models (MPT-7B, LLaMA2-7B, and LLaMA2-70B). The results highlight the performance improvement offered by MH-RTD over RTD.
Full paper#