↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Dynamic non-line-of-sight (NLOS) imaging aims to capture images of hidden objects indirectly, but its slow speed has been a major limitation. Previous methods struggle with reconstructing high-resolution volumes from undersampled measurements and often neglect the temporal relationships between frames, especially in dynamic scenes. This leads to blurry and incomplete reconstructions.
To overcome this, researchers developed a novel method called ST-Mamba. This method uses neighboring frames to aggregate information about the hidden object and improve the quality of the reconstructed video. The ST-Mamba framework includes a wave-based loss function to handle noise, and it was evaluated using a new dataset of synthetic and real-world videos. Results showed that ST-Mamba significantly outperforms existing methods, achieving both higher resolution and accuracy in reconstructing dynamic NLOS videos.
Key Takeaways#
Why does it matter?#
This paper is important because it presents the first spatial-temporal Mamba (ST-Mamba) method for dynamic non-line-of-sight (NLOS) imaging. This addresses a critical challenge in the field by improving the temporal consistency across transient frames, which is crucial for high-quality reconstruction of dynamic scenes. The introduction of a new dataset for training and evaluation further enhances the value of this research for the community.
Visual Insights#
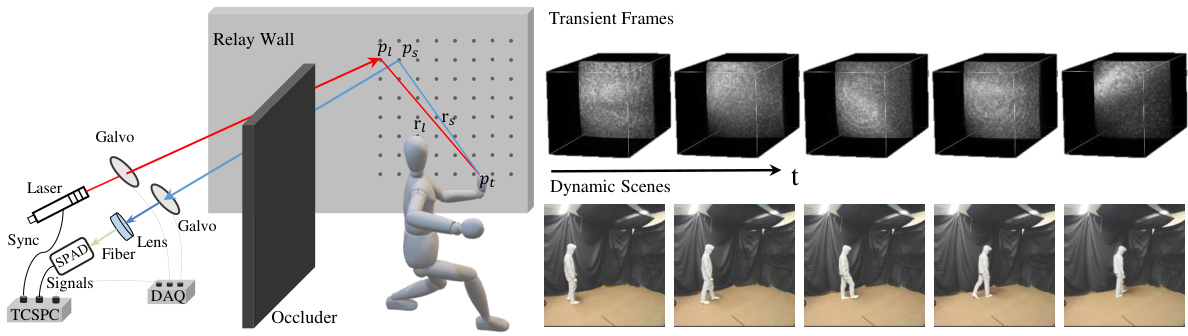
This figure illustrates the setup for active non-line-of-sight (NLOS) imaging. On the left, a schematic shows the components involved in capturing indirect light reflections from a hidden object via a relay wall, including a pulsed laser, galvo mirrors for scanning, a SPAD detector, and a TCSPC system for timing measurements. The right side shows a series of transient frames representing the dynamic scenes captured by the system. This represents the data that the algorithm will analyze in order to reconstruct the 3D hidden scene.
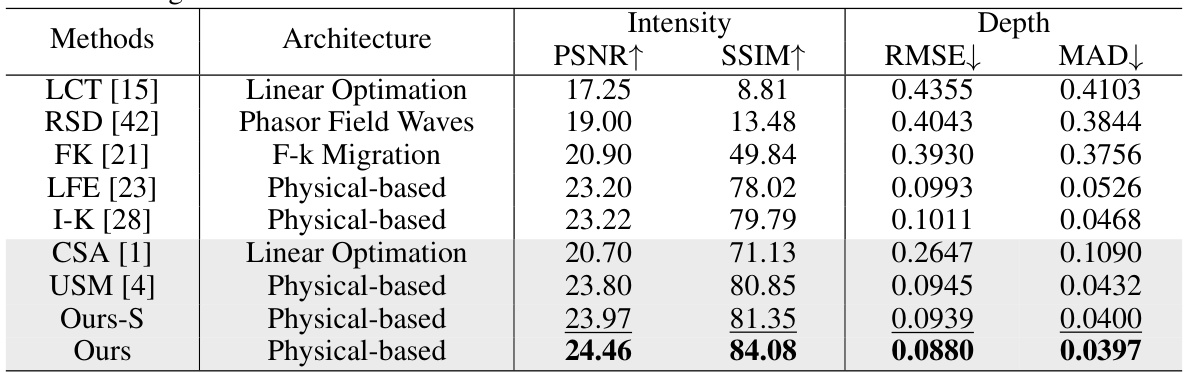
This table presents a quantitative comparison of different methods for non-line-of-sight (NLOS) imaging reconstruction using synthetic data. It shows the performance of various methods (LCT, RSD, FK, LFE, I-K, CSA, USM, Ours-S, and Ours) in terms of intensity (PSNR, SSIM, RMSE) and depth (RMSE, MAD) metrics. The input resolution is 16x16 and the output resolution is upscaled to 128x128. The methods using under-scanning measurements are highlighted in gray. The best performing method for each metric is shown in bold, and the second-best is underlined.
In-depth insights#
Dynamic NLOS Imaging#
Dynamic Non-Line-of-Sight (NLOS) imaging aims to reconstruct hidden scenes by analyzing indirect light reflections. Traditional NLOS methods suffer from slow acquisition times due to their raster-scanning approach. Dynamic NLOS imaging seeks to overcome this limitation by reconstructing high-resolution volumes from sparsely sampled, rapidly acquired transient measurements. This presents challenges in terms of data consistency across frames and managing the inherently noisy data. The key is to effectively fuse multi-frame information, enforcing temporal consistency to enhance reconstruction quality and robustness. This requires sophisticated algorithms that leverage temporal correlations and address the signal-to-noise ratio limitations. Advances in deep learning and novel algorithms like spatial-temporal Mamba offer promising solutions. Further research should focus on developing robust, efficient algorithms, suitable for real-time dynamic NLOS imaging, and creating large-scale datasets for training and evaluating such algorithms. The potential impact on various fields, such as autonomous driving and robotics, is significant.
ST-Mamba Fusion#
ST-Mamba fusion, as a hypothetical concept based on the provided context, likely refers to a method that integrates spatial and temporal information within a non-line-of-sight (NLOS) imaging system. The ‘ST’ likely stands for spatio-temporal, highlighting the integration of both spatial and temporal dimensions of the transient measurement data. The core of this fusion likely lies in combining data from multiple transient frames, exploiting the temporal consistency to improve reconstruction quality. This is crucial in dynamic NLOS imaging where the target scene changes over time, requiring the fusion of transient data to accurately capture these changes. The Mamba module, likely a recurrent neural network architecture, would process and fuse this multi-frame information efficiently. The strength of this approach lies in addressing the limitations of using individual transient frames, which suffer from noise and incomplete information. By integrating across frames, the method likely improves the signal-to-noise ratio and provides a more robust and complete reconstruction of the hidden scene, particularly for dynamic scenes.
Wave-Based Loss#
A wave-based loss function in the context of non-line-of-sight (NLOS) imaging aims to leverage the inherent wave nature of light to improve reconstruction quality, particularly when dealing with noisy transient measurements. This approach likely involves formulating a loss that operates directly on the wavefront or its representation in the frequency domain (e.g., the Fourier transform), rather than only relying on intensity or other scalar metrics. By incorporating wave-based constraints, such as the preservation of phase information or the enforcement of physical wave propagation models, the loss function can better regularize the reconstruction process and reduce artifacts. This is especially valuable in NLOS imaging because the indirect nature of light interactions leads to weak signals and significant noise. A thoughtfully designed wave-based loss should promote reconstructions that exhibit physically plausible wave behavior and are robust to noise. The use of synthetic data would play a key role in training a model using a wave-based loss function, helping to ensure that the model learns to appropriately handle the complex wave dynamics present in NLOS imaging data. A well-designed wave-based loss function should effectively improve the accuracy and robustness of the 3D scene reconstruction and could potentially lead to advancements in dynamic NLOS imaging.
Synthetic Dataset#
The creation of a synthetic dataset is a crucial aspect of this research, addressing the lack of readily available dynamic NLOS video datasets. The authors meticulously designed this dataset to simulate real-world conditions, incorporating features like dynamic objects with varying trajectories, realistic noise levels reflecting low SNR in transient measurements, and even the introduction of detector jitter to mimic imperfections in real hardware. This approach allowed for thorough training of their model and reliable evaluation, enhancing the generalizability of the results. The use of synthetic data before moving to real-world data is a smart methodological choice, minimizing issues arising from noisy or limited real-world data, especially in a relatively nascent field like dynamic NLOS imaging. The specific design choices within the synthetic dataset (e.g., the number of frames, object complexity, noise characteristics) are important considerations influencing both the model’s learning process and the overall validation of the findings.
Future Directions#
Future research in dynamic non-line-of-sight (NLOS) imaging should prioritize developing more robust and efficient methods for handling noise and low signal-to-noise ratios (SNR) inherent in transient measurements. Addressing the computational complexity associated with high-resolution reconstruction is also crucial. Exploration of novel hardware designs and advanced sensor technologies, such as improved single-photon detectors, could significantly enhance the speed and accuracy of data acquisition. Furthermore, investigating new algorithms that effectively leverage temporal consistency across multiple frames, perhaps by adopting advanced deep learning architectures or physics-based models, is a promising area. Finally, expanding the types of scenarios and objects studied, and creating larger and more diverse datasets, will help accelerate progress in developing practical dynamic NLOS imaging systems for real-world applications. The development of benchmark datasets would also greatly benefit the community.
More visual insights#
More on figures

This figure shows three aspects of the experimental setup used in the paper. (a) presents example images from a synthetic dataset, showing intensity images and corresponding transient slices in x-y plane of the transient frames; (b) shows the physical setup for capturing the data, including the arrangement of the laser, mirrors, and camera; (c) provides a detailed view of the custom-built imaging system used, including all the major components such as the laser, SPAD detector, TCSPC, and DAQ.

This figure illustrates the pipeline of the proposed dynamic NLOS reconstruction method. It takes three consecutive transient frames as input. The interleaved extraction module first processes these frames. Then, the spatial-temporal Mamba (ST-Mamba) and cross ST-Mamba modules integrate information across frames to improve the quality of the target frame. The transient spreading module increases the spatial resolution of the target transient frame. Finally, the feature extraction, feature transformation, and refinement modules reconstruct the hidden volume, intensity image and depth map of the target frame.

This figure shows the architecture of the proposed ST-Mamba and cross ST-Mamba modules. The ST-Mamba module (a) takes input features (Fin) and processes them through a series of layers including normalization (Norm), multi-layer perceptrons (MLP), convolution (CONV), temporal and spatial state space models (SSM), and activation functions to produce output features (Ft). The cross ST-Mamba module (b) takes the output features (Ft) from ST-Mamba and adjacent frame features (Ft+1) as input. These are processed through the same layers (Norm, MLP, CONV, Temporal SSM, Spatial SSM, and Activation), and then combined to create aligned features (Fa). Both modules aim to leverage temporal and spatial relationships between transient frames to improve dynamic NLOS reconstruction.

This figure shows a qualitative comparison of different methods for dynamic NLOS imaging on two synthetic sequences. Each sequence contains multiple frames, represented by the ‘#’ symbol. The input to each method had a spatial resolution of 16x16 pixels, while the output resolution was upscaled to 128x128 pixels. The figure allows for a visual comparison of the reconstruction quality achieved by various techniques, including LCT, RSD, FK, LFE, I-K, CSA, USM, Ours-S (single frame version of the proposed method), and Ours (the proposed method). The ground truth images are also provided for reference (GT).

This figure shows the results of applying the proposed dynamic NLOS reconstruction method to real-world data. The top row displays reconstruction results for simple planar objects in rigid motion, while the bottom row shows results for a scene with non-rigid motion (a person moving their arms). The input measurements used a 16x16 spatial scanning grid, and the method reconstructed a hidden volume with a resolution of 128x128 pixels. The results are compared against several baseline methods.

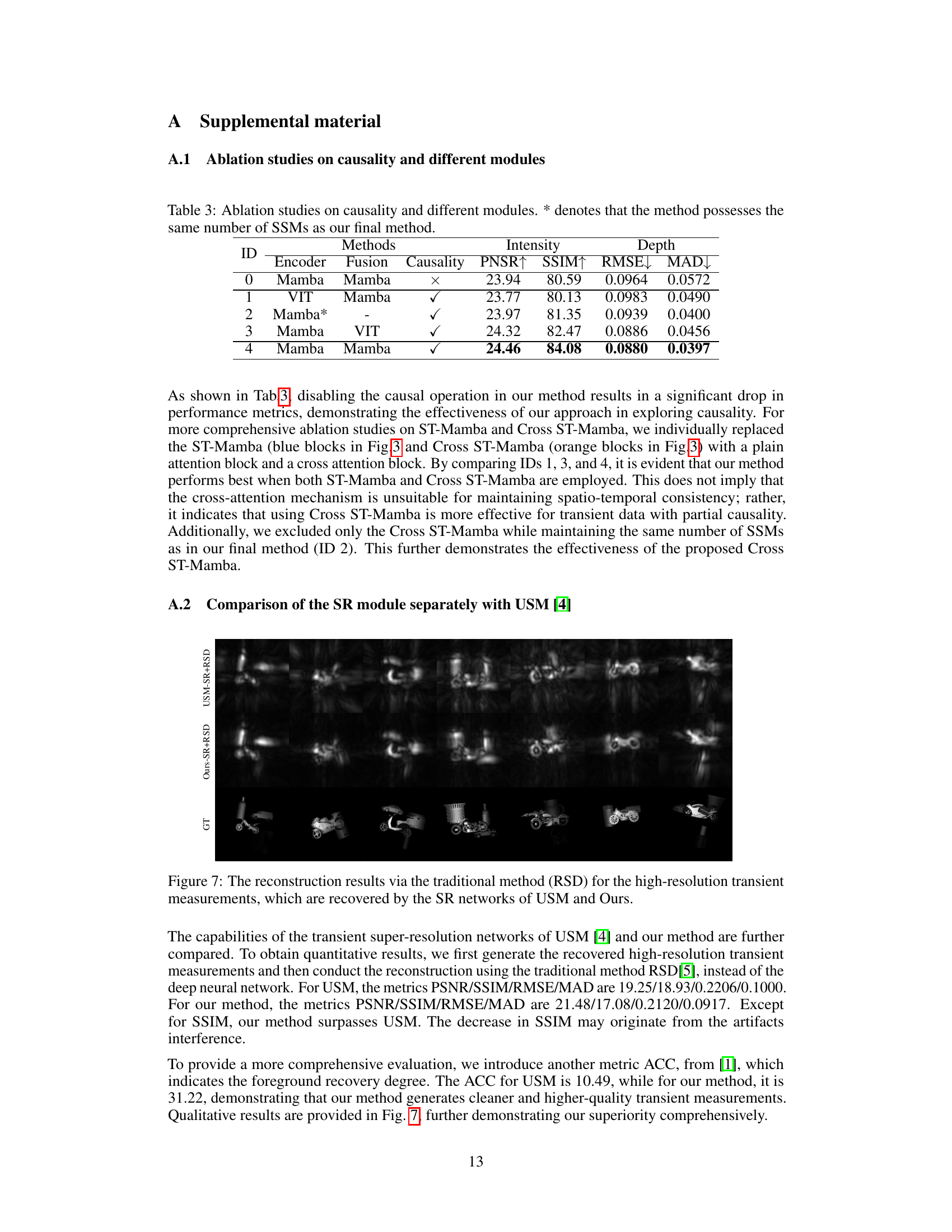
This figure compares the performance of the proposed method’s super-resolution (SR) module against USM’s SR module. Both methods’ SR modules are used to generate high-resolution transient measurements, which are then input into a traditional reconstruction method (RSD). The top two rows show the results using USM-SR+RSD and Ours-SR+RSD respectively, while the bottom row shows the ground truth (GT). The comparison highlights the superior quality of the proposed method’s SR module in generating clearer and more detailed high-resolution transient measurements suitable for improved reconstruction.

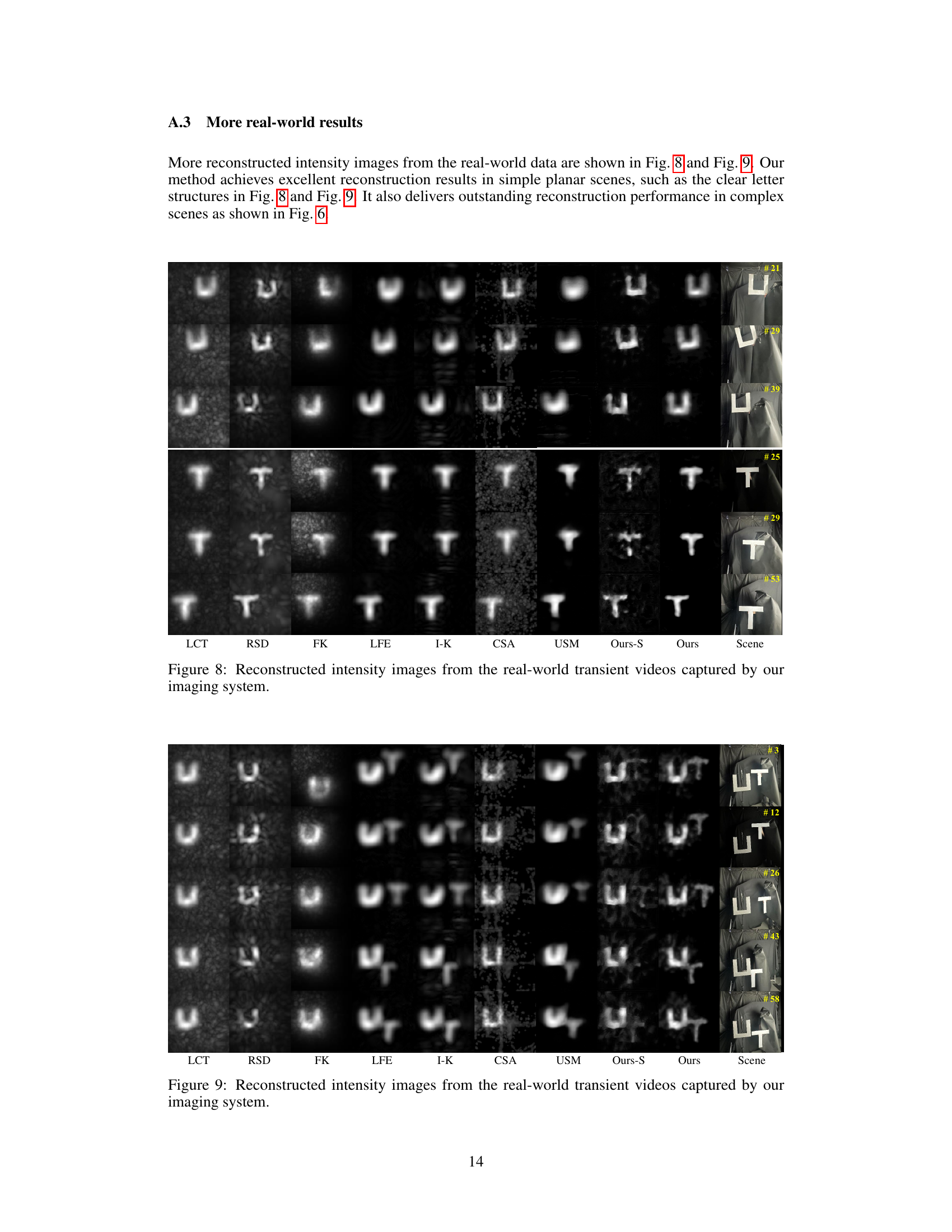
This figure shows the results of reconstructing real-world scenes using the proposed method. The top row displays the results for a scene with letter ‘U’ shaped objects. The bottom row shows the results for a scene with letter ‘T’ shaped objects. Each column shows results from different methods, including the proposed method (Ours), a single-frame version of the proposed method (Ours-S), and several baselines (LCT, RSD, FK, LFE, I-K, CSA, USM). The ground truth is shown in the last column. The input spatial resolution is 16x16, while the output resolution is 128x128.

This figure shows the results of reconstructing hidden objects from real-world data captured by the authors’ non-line-of-sight (NLOS) imaging system. The input data consists of transient measurements from a 16x16 spatial scanning grid, which is then upsampled to a 128x128 resolution for the final reconstruction. The figure compares the results from several different methods, including the proposed method and several baselines. It demonstrates the ability of the proposed method to reconstruct high-quality images even from sparsely sampled real-world data.
More on tables
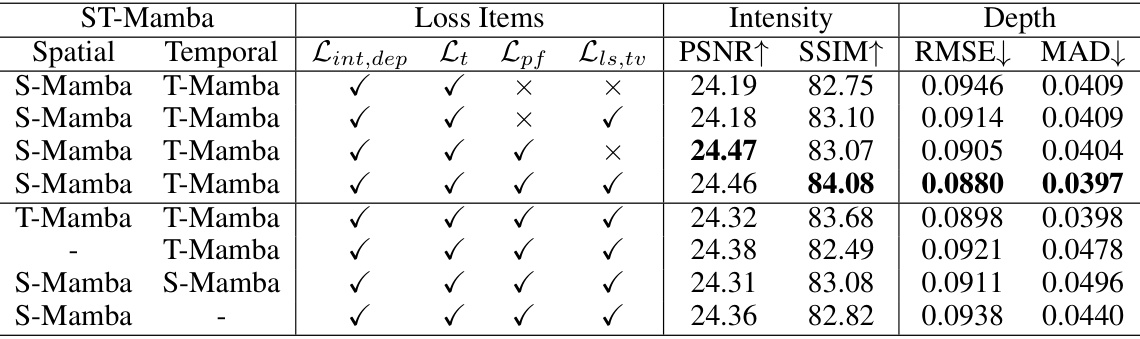
This table presents the ablation study results, analyzing the impact of different loss functions and the spatial-temporal Mamba mechanism on the model’s performance. It shows the PSNR, SSIM, RMSE, and MAD metrics for intensity and depth estimation across various model configurations. The configurations systematically remove or include specific loss components (Lint,dep, Lt, Lpf, Lis,tv) and different parts of the Mamba mechanism (spatial, temporal, or both). This allows for a quantitative assessment of each component’s contribution to the overall reconstruction quality.

This table presents the results of ablation studies conducted to evaluate the impact of causality and different module choices on the overall performance of the proposed dynamic NLOS reconstruction method. It compares various configurations, systematically varying the encoder (Mamba or Vision Transformer), fusion method (Mamba or Vision Transformer), and the inclusion of causality in the model. The performance metrics used for comparison are Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Root Mean Squared Error (RMSE), and Mean Absolute Difference (MAD), for both intensity and depth components of the reconstruction. The results show the importance of causality and the optimal choice of components for achieving the best performance.

This table compares the inference time and memory usage of different methods for non-line-of-sight (NLOS) imaging. It highlights the trade-off between speed and resource consumption. The methods are categorized, showing those specifically designed for under-scanning measurements. The time is measured in seconds, and memory is in megabytes (M).
Full paper#