TL;DR#
Cross-domain few-shot learning (CDFSL) using Vision Transformers (ViTs) faces challenges due to limited data in target domains and the difficulty of knowledge transfer from source domains. Existing CDFSL methods often struggle to effectively leverage knowledge from the source domain. This paper investigates the role of the CLS (class) token in ViTs during CDFSL. It identifies an intriguing phenomenon: random initialization of the CLS token, instead of transferring pre-trained weights, surprisingly improves performance on the target domain. This discovery highlights the CLS token’s unexpected sensitivity to domain-specific information.
To address the issues and leverage the finding, the authors propose a novel method that decouples the domain information from the CLS token during source domain training and then adapts it efficiently during target domain learning. The proposed method achieves superior performance on various benchmark datasets, demonstrating its effectiveness in handling the domain gap and limited target data in few-shot learning scenarios. Their findings offer insights into improving ViT’s generalization across domains and contribute to advancement in few-shot learning. The method focuses on decoupling and adapting the CLS token, significantly enhancing performance and providing a new direction for research in CDFSL with ViTs.
Key Takeaways#
Why does it matter?#
This paper is important because it reveals a previously overlooked phenomenon in Vision Transformers and proposes a novel method to improve cross-domain few-shot learning. It challenges existing assumptions about the role of the CLS token and opens new avenues for research in transfer learning and domain adaptation. The method’s success in decoupling domain information from the CLS token and adapting it efficiently to new domains is highly relevant to current research trends in few-shot learning and has the potential to significantly impact various applications.
Visual Insights#

🔼 This figure shows the architecture of Vision Transformer (ViT) with image tokens and a CLS token. It then presents results of a 5-way 1-shot classification experiment on source and target domains for a cross-domain few-shot learning (CDFSL) task. The key finding is that, while loading the pre-trained CLS token improves source domain performance, not loading it (leaving it at random initialization) improves target domain performance. This unexpected behavior motivates the rest of the paper.
read the caption
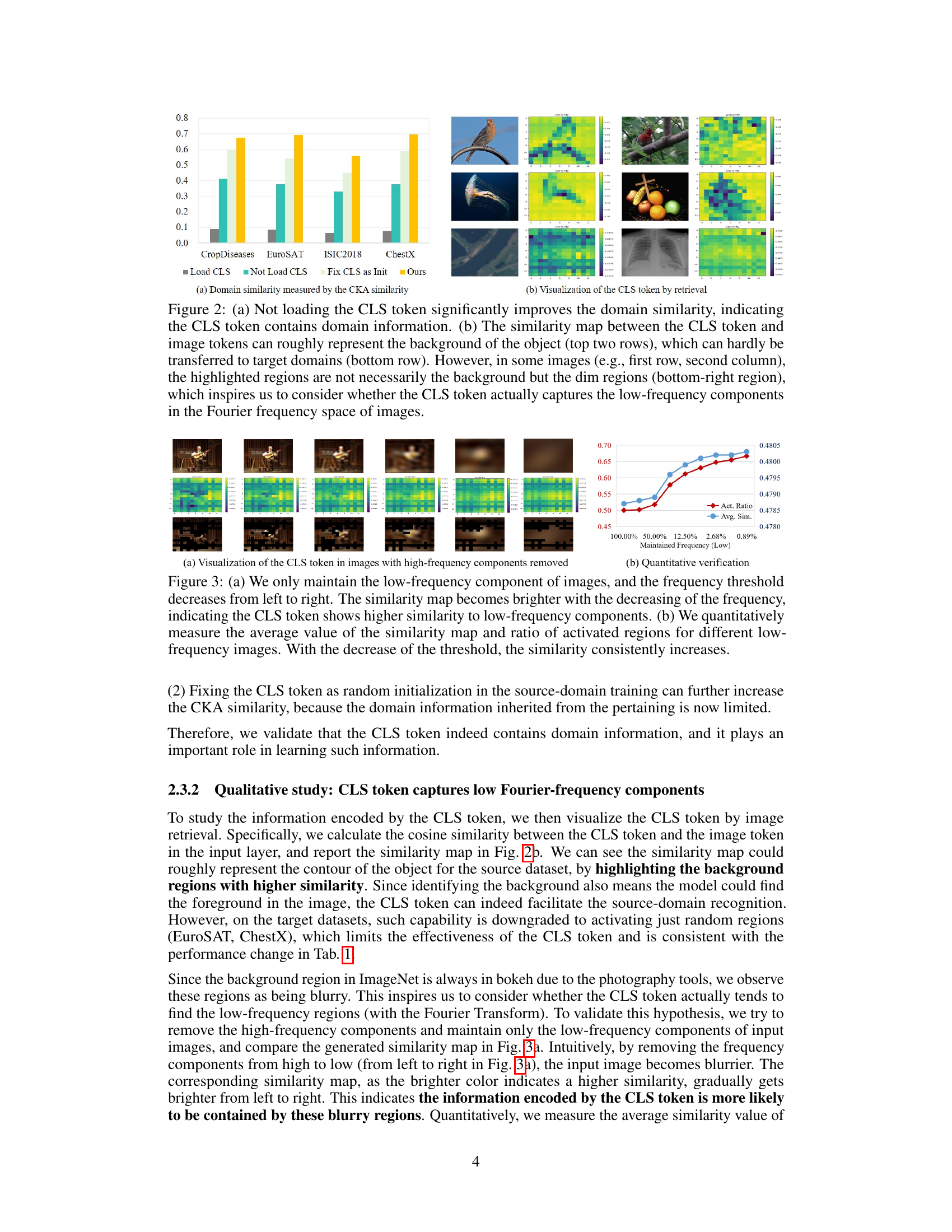
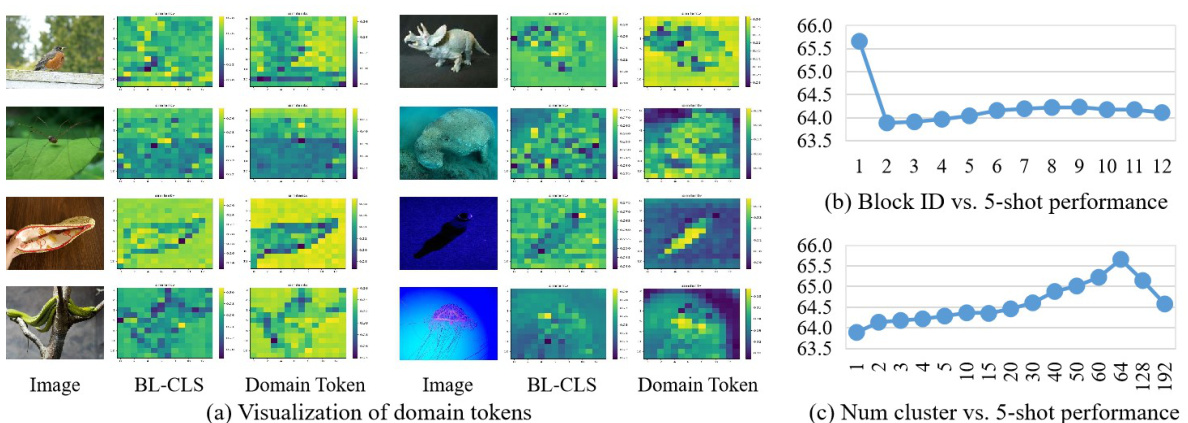
Figure 1: (a) Vision Transformer (ViT) takes image tokens and a learnable CLS token as input. For the Cross-Domain Few-Shot Learning (CDFSL) task, after the training on the source-domain dataset, we evaluate the model on both the source-domain classes (b) and target-domain classes (c) by the 5-way 1-shot classification. We find an intriguing phenomenon neglected by previous works: although not loading the CLS token parameters (i.e., leaving them to random initialization) on the source-domain classes harms the performance (b), not loading these parameters consistently improves the target-domain performance (c). In this paper, we delve into this phenomenon for an interpretation, and propose a simple but effective method based on them for the CDFSL task.
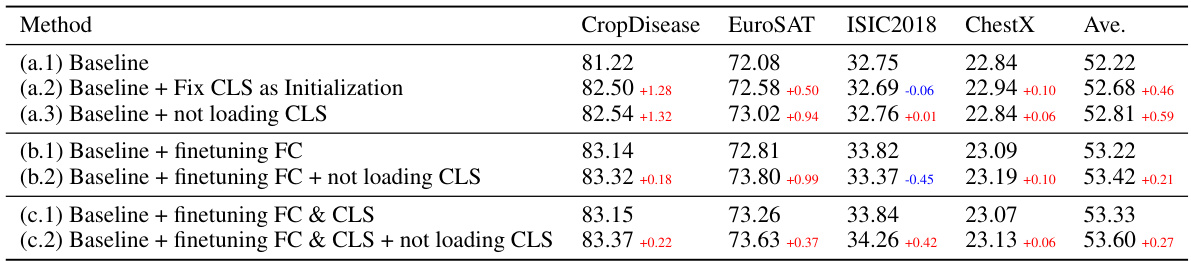
🔼 This table presents the results of experiments comparing different methods for cross-domain few-shot learning, focusing on the impact of loading versus not loading the CLS token parameters. It shows that not loading the CLS token consistently improves performance on the target domain datasets across various experimental settings (baseline, finetuning the fully connected layer, finetuning both the fully connected layer and the CLS token), even though this sometimes harms source-domain performance.
read the caption
Table 1: Not Loading the CLS token improves the cross-domain performance in most cases.
In-depth insights#
CLS Token Role#
The CLS token’s role in Vision Transformers (ViTs), especially within the context of cross-domain few-shot learning (CDFSL), is multifaceted and surprisingly influential. While initially intended as a simple classification token, research reveals its capacity to absorb domain-specific information, impacting both source and target domain performance. Random initialization of the CLS token during target-domain fine-tuning, rather than loading pre-trained parameters, consistently improves performance, indicating that the pre-trained CLS token may carry ‘poisonous’ domain-specific information hindering generalization. This suggests that the CLS token implicitly encodes low-frequency image components, which correlates with domain characteristics and negatively impacts cross-domain adaptability. Therefore, decoupling domain information from the CLS token during source-domain training is crucial, facilitating efficient few-shot learning on target domains by allowing the CLS token to adapt to new domains without initial biases. Methodologies for this decoupling, such as introducing pseudo-domain tokens, effectively address this issue, leading to improved results and highlighting the critical role of careful CLS token management in ViT-based CDFSL.
Domain Decoupling#
The concept of ‘domain decoupling’ in the context of cross-domain few-shot learning (CDFSL) using Vision Transformers (ViTs) centers on mitigating the negative transfer effects stemming from the inherent characteristics of the CLS token. The CLS token, acting as a global representation vector, readily absorbs domain-specific information during source domain training. This can hinder generalization to target domains. Domain decoupling methods aim to disentangle this domain information from the CLS token, making it more domain-agnostic during source domain training. This often involves strategies such as random initialization or the introduction of separate domain-specific tokens to absorb domain bias, leaving the CLS token free to learn generalized features. Consequently, during target domain adaptation, a decoupled CLS token can effectively capture target-specific information more efficiently with limited data, improving few-shot learning performance. The effectiveness of this approach depends heavily on effectively decoupling domain-specific information without sacrificing essential features beneficial for source domain learning. Therefore, finding an optimal balance between decoupling and preserving valuable source domain information is crucial for the success of domain decoupling techniques in achieving state-of-the-art performance in CDFSL.
Frequency Analysis#
A thoughtful frequency analysis of a research paper would involve examining the distribution of terms, phrases, or concepts across the document. Identifying high-frequency terms can quickly reveal the paper’s central themes and arguments. Low-frequency terms, on the other hand, may point to nuanced or specialized concepts that warrant closer scrutiny. By analyzing the frequency of different elements, we could uncover relationships and patterns that highlight the paper’s structure, methodology, and key findings. Visualizing frequencies, perhaps through word clouds or graphs, would offer a powerful way to communicate these insights and quickly grasp the paper’s most prominent aspects. Moreover, a sophisticated frequency analysis might consider the context in which terms appear. For instance, the frequency of certain words or phrases might vary significantly across different sections, suggesting shifts in focus or emphasis. Such a granular analysis could reveal hidden complexities that a simple word count might miss.
CDFSL Benchmark#
A hypothetical ‘CDFSL Benchmark’ section in a research paper would likely detail the datasets and evaluation metrics used to assess the performance of cross-domain few-shot learning (CDFSL) models. It would be crucial to establish a rigorous benchmark to fairly compare different approaches. This would involve selecting datasets that represent diverse domain characteristics and exhibit varying degrees of domain shift, ensuring the benchmark is both challenging and representative. The paper would also describe the specific few-shot learning protocols used (e.g., k-shot, n-way), along with the evaluation metrics employed. Accuracy and F1-score are common metrics, but others specific to image classification or other tasks may also be used. A strong benchmark requires not just the choice of appropriate datasets, but a clear articulation of experimental setup. The rationale for the specific dataset choices and metrics should be explained, detailing how they capture the essential challenges of CDFSL. Transparency and reproducibility are paramount, with the complete experimental setup and procedures provided to allow other researchers to replicate results and conduct further analysis on the established benchmark.
Future of CLS#
The “Future of CLS” in vision transformers, especially within cross-domain few-shot learning (CDFSL), is promising but hinges on several key factors. Decoupling domain information from the CLS token during source domain training, as demonstrated in the paper, is crucial to preventing negative transfer and enhancing generalization to target domains. Further research should explore more sophisticated techniques for achieving this decoupling, potentially leveraging techniques from domain adaptation or adversarial training. Investigating the interaction between CLS token initialization strategies and downstream performance is another avenue for future work; the current findings suggest that random initialization can be surprisingly effective in some scenarios, but a deeper understanding is needed. Additionally, expanding upon the low-frequency component interpretation of the CLS token, exploring other frequency domains or representation learning techniques might unlock further improvements in cross-domain learning. Finally, applying similar principles to other transformer architectures or extending beyond image classification to other tasks remains a worthwhile area of investigation.
More visual insights#
More on figures
🔼 This figure shows the architecture of Vision Transformer and the results of experiments on source domain and target domain with and without loading the CLS token. The results indicate that not loading the CLS token improves the target domain performance, while harming the source domain performance. This phenomenon is further investigated in the paper.
read the caption
Figure 1: (a) Vision Transformer (ViT) takes image tokens and a learnable CLS token as input. For the Cross-Domain Few-Shot Learning (CDFSL) task, after the training on the source-domain dataset, we evaluate the model on both the source-domain classes (b) and target-domain classes (c) by the 5-way 1-shot classification. We find an intriguing phenomenon neglected by previous works: although not loading the CLS token parameters (i.e., leaving them to random initialization) on the source-domain classes harms the performance (b), not loading these parameters consistently improves the target-domain performance (c). In this paper, we delve into this phenomenon for an interpretation, and propose a simple but effective method based on them for the CDFSL task.
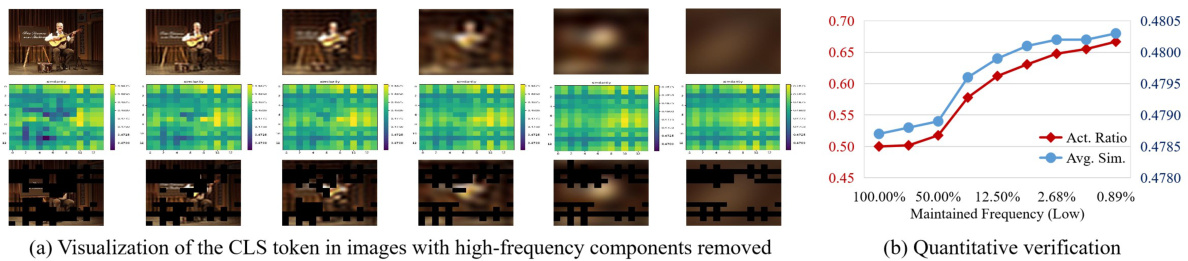
🔼 This figure shows experimental results that qualitatively and quantitatively verify that the CLS token focuses on low-frequency components of images. (a) shows a series of images with progressively lower frequency components retained and their corresponding similarity maps with the CLS token. The similarity increases as the frequency decreases, demonstrating the CLS token’s preference for low-frequency information. (b) provides quantitative support using average similarity map values and the ratio of activated regions, showing a consistent increase as the frequency threshold decreases. This reinforces the interpretation that the CLS token preferentially captures low-frequency, domain-related information.
read the caption
Figure 3: (a) We only maintain the low-frequency component of images, and the frequency threshold decreases from left to right. The similarity map becomes brighter with the decreasing of the frequency, indicating the CLS token shows higher similarity to low-frequency components. (b) We quantitatively measure the average value of the similarity map and ratio of activated regions for different low-frequency images. With the decrease of the threshold, the similarity consistently increases.

🔼 This figure shows the architecture of Vision Transformer and the results of experiments on source and target domains for 5-way 1-shot classification with and without loading the CLS token. The results indicate that not loading CLS token parameters consistently improves the target domain performance although it harms the source domain performance. This phenomenon motivates the authors to investigate the role of CLS token in cross-domain few-shot learning.
read the caption
Figure 1: (a) Vision Transformer (ViT) takes image tokens and a learnable CLS token as input. For the Cross-Domain Few-Shot Learning (CDFSL) task, after the training on the source-domain dataset, we evaluate the model on both the source-domain classes (b) and target-domain classes (c) by the 5-way 1-shot classification. We find an intriguing phenomenon neglected by previous works: although not loading the CLS token parameters (i.e., leaving them to random initialization) on the source-domain classes harms the performance (b), not loading these parameters consistently improves the target-domain performance (c). In this paper, we delve into this phenomenon for an interpretation, and propose a simple but effective method based on them for the CDFSL task.
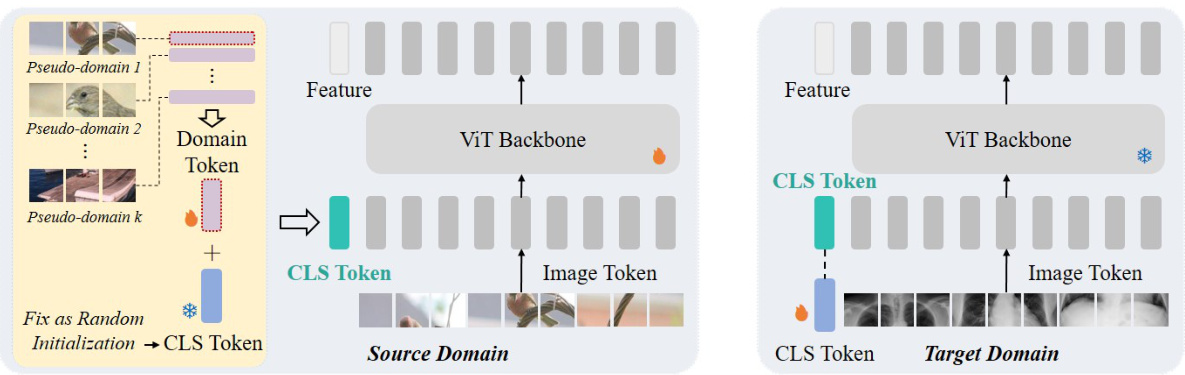
🔼 This figure illustrates the proposed method for decoupling domain information from the CLS token in Vision Transformers for cross-domain few-shot learning. During source domain training, pseudo-domains are created, each with a domain token added to a randomly initialized CLS token. This prevents the CLS token from absorbing source domain-specific information. During target domain adaptation, the domain tokens are removed, and the CLS token is fine-tuned to learn target domain information, enabling efficient few-shot learning.
read the caption
Figure 4: Based on the phenomenon and interpretation, we propose to decouple the domain information from the CLS token to make it domain-agnostic during the source-domain training, and utilize the CLS token's characteristic in absorbing domain information for efficient target-domain adaptation. Specifically, during the source-domain training, we generate pseudo domains on the source dataset by clustering, and apply a domain token for each pseudo domain. We fix the CLS token as the random initialization, and add the domain token to the fixed CLS token, so that domain tokens will substitute the CLS token in absorbing domain information, which decouples the domain information from the CLS token. During the target-domain adaptation, we abandon domain tokens and finetune the CLS token to absorb target-domain information for efficient few-shot learning.
🔼 This figure shows the architecture of Vision Transformer and the results of experiments on source and target domains with and without loading CLS token parameters. It highlights a key finding of the paper: leaving the CLS token to random initialization, rather than loading pre-trained parameters, consistently improves performance on the target domain despite harming source domain performance.
read the caption
Figure 1: (a) Vision Transformer (ViT) takes image tokens and a learnable CLS token as input. For the Cross-Domain Few-Shot Learning (CDFSL) task, after the training on the source-domain dataset, we evaluate the model on both the source-domain classes (b) and target-domain classes (c) by the 5-way 1-shot classification. We find an intriguing phenomenon neglected by previous works: although not loading the CLS token parameters (i.e., leaving them to random initialization) on the source-domain classes harms the performance (b), not loading these parameters consistently improves the target-domain performance (c). In this paper, we delve into this phenomenon for an interpretation, and propose a simple but effective method based on them for the CDFSL task.
🔼 This figure shows the architecture of Vision Transformer, and experimental results of training a model on source and target domains. The key finding is that leaving the CLS token’s parameters uninitialized (not loading them from the source domain model) improves performance on the target domain, despite slightly harming performance on the source domain. This counterintuitive result motivates the rest of the paper.
read the caption
Figure 1: (a) Vision Transformer (ViT) takes image tokens and a learnable CLS token as input. For the Cross-Domain Few-Shot Learning (CDFSL) task, after the training on the source-domain dataset, we evaluate the model on both the source-domain classes (b) and target-domain classes (c) by the 5-way 1-shot classification. We find an intriguing phenomenon neglected by previous works: although not loading the CLS token parameters (i.e., leaving them to random initialization) on the source-domain classes harms the performance (b), not loading these parameters consistently improves the target-domain performance (c). In this paper, we delve into this phenomenon for an interpretation, and propose a simple but effective method based on them for the CDFSL task.

🔼 This figure shows the architecture of Vision Transformer (ViT) and the results of experiments on source and target domains with and without loading the CLS token parameters. The intriguing phenomenon observed is that not loading the CLS token (leaving it randomly initialized) hurts performance on the source domain but consistently improves performance on the target domain. This observation motivates the rest of the paper, leading to a method for efficient few-shot learning.
read the caption
Figure 1: (a) Vision Transformer (ViT) takes image tokens and a learnable CLS token as input. For the Cross-Domain Few-Shot Learning (CDFSL) task, after the training on the source-domain dataset, we evaluate the model on both the source-domain classes (b) and target-domain classes (c) by the 5-way 1-shot classification. We find an intriguing phenomenon neglected by previous works: although not loading the CLS token parameters (i.e., leaving them to random initialization) on the source-domain classes harms the performance (b), not loading these parameters consistently improves the target-domain performance (c). In this paper, we delve into this phenomenon for an interpretation, and propose a simple but effective method based on them for the CDFSL task.
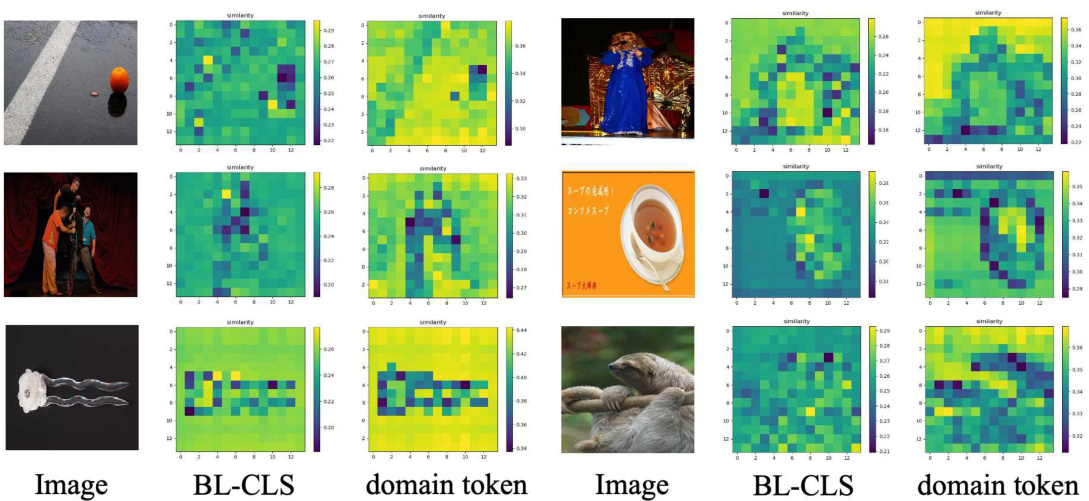
🔼 This figure visualizes the effect of using domain tokens compared to the baseline CLS tokens in capturing domain information. It shows similarity maps between image tokens and either the baseline CLS token or the proposed domain tokens. The brighter regions indicate higher similarity. The domain tokens achieve significantly brighter similarity maps, demonstrating their enhanced ability to absorb relevant domain information, which is crucial for effective cross-domain few-shot learning.
read the caption
Figure 8: Applying the domain token significantly improves the domain similarity compared to the CLS token of the baseline method (BL-CLS), validating the effectiveness of our approach in absorbing domain information.

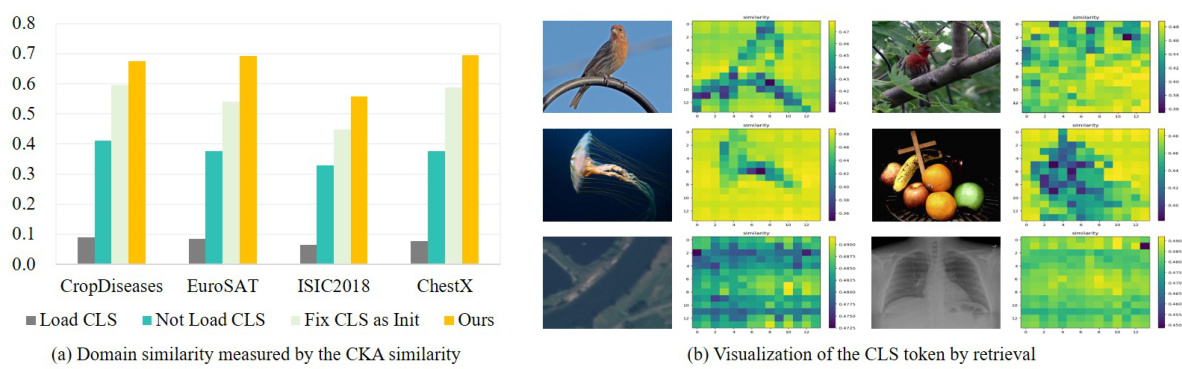
🔼 Figure 2 presents the results of experiments that investigate the domain information contained within the CLS token. (a) Shows that not loading the CLS token increases the CKA similarity between source and target domains, suggesting that the CLS token holds domain-specific information that hinders cross-domain transfer. (b) Visualizes the similarity map between the CLS token and image tokens, highlighting regions that the CLS token focuses on during source domain training. This visualization reveals that the CLS token tends to capture low-frequency components, often associated with background information, making it less effective for transfer to different domains. Noteworthy is the observation in (b) that, in some cases, the CLS token highlights blurry or dim areas, hinting at a possible focus on low-frequency image components beyond mere background.
read the caption
Figure 2: (a) Not loading the CLS token significantly improves the domain similarity, indicating the CLS token contains domain information. (b) The similarity map between the CLS token and image tokens can roughly represent the background of the object (top two rows), which can hardly be transferred to target domains (bottom row). However, in some images (e.g., first row, second column), the highlighted regions are not necessarily the background but the dim regions (bottom-right region), which inspires us to consider whether the CLS token actually captures the low-frequency components in the Fourier frequency space of images.
More on tables
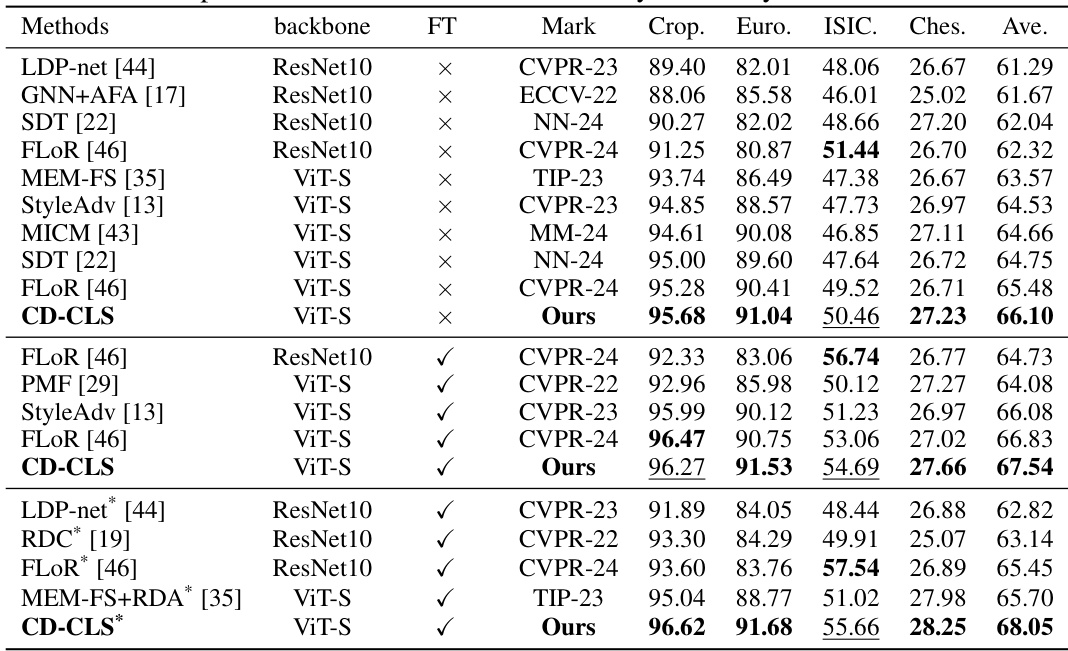
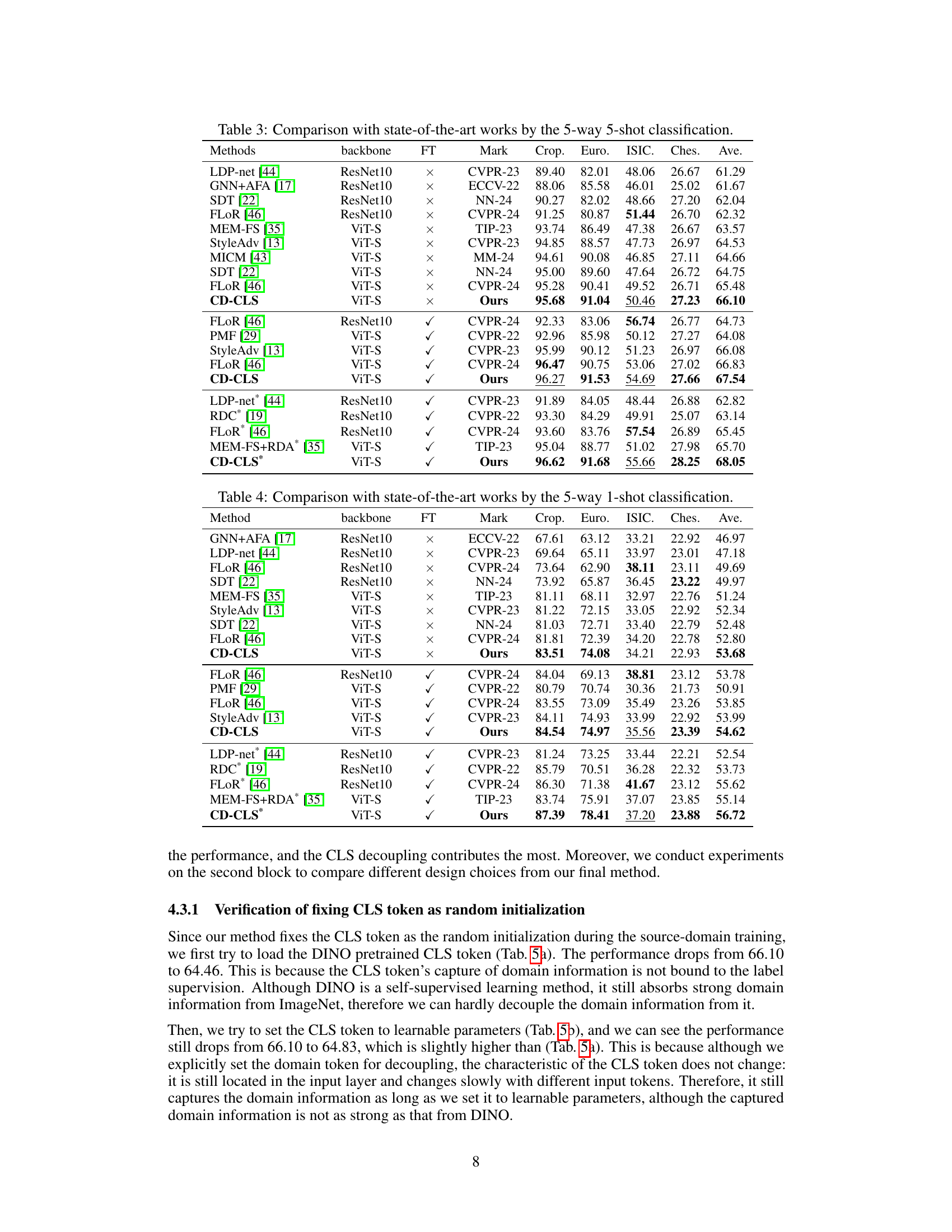
🔼 This table compares the proposed method’s performance with other state-of-the-art methods on four benchmark datasets (CropDisease, EuroSAT, ISIC2018, and ChestX) using the 5-way 5-shot classification task. It shows the accuracy achieved by each method, broken down by dataset and whether or not fine-tuning was used. The table helps to demonstrate the effectiveness of the proposed method compared to existing approaches.
read the caption
Table 3: Comparison with state-of-the-art works by the 5-way 5-shot classification.
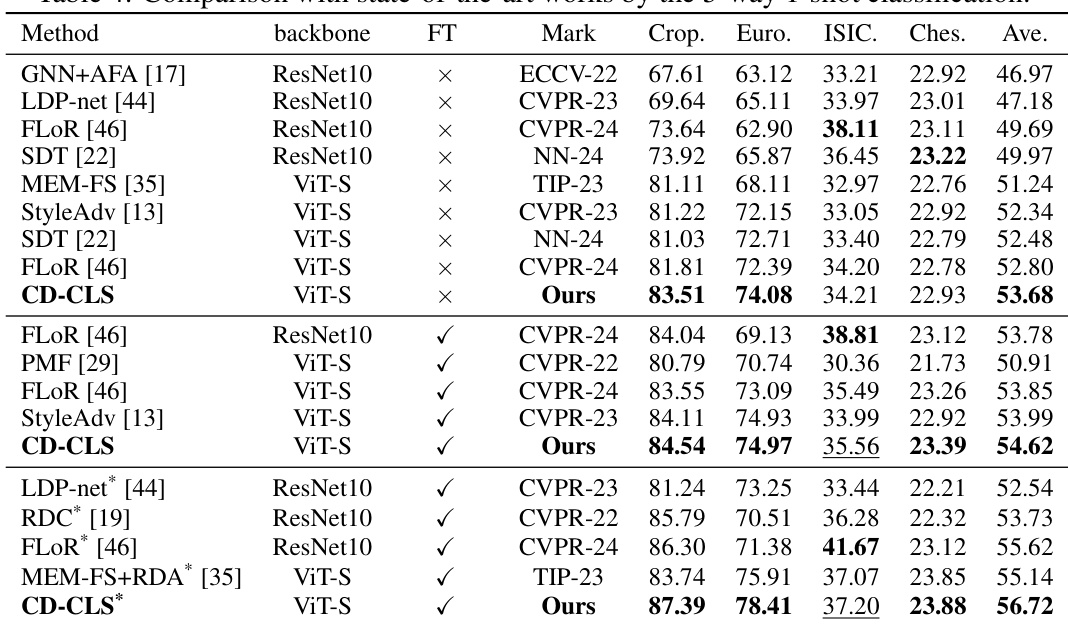
🔼 This table compares the proposed CD-CLS method with other state-of-the-art methods on four benchmark datasets (CropDisease, EuroSAT, ISIC2018, and ChestX) using the 5-way 5-shot classification setting. It shows the performance of each method across different datasets, differentiating between methods that use finetuning and those that don’t. The table highlights the superior performance of the CD-CLS method.
read the caption
Table 3: Comparison with state-of-the-art works by the 5-way 5-shot classification.

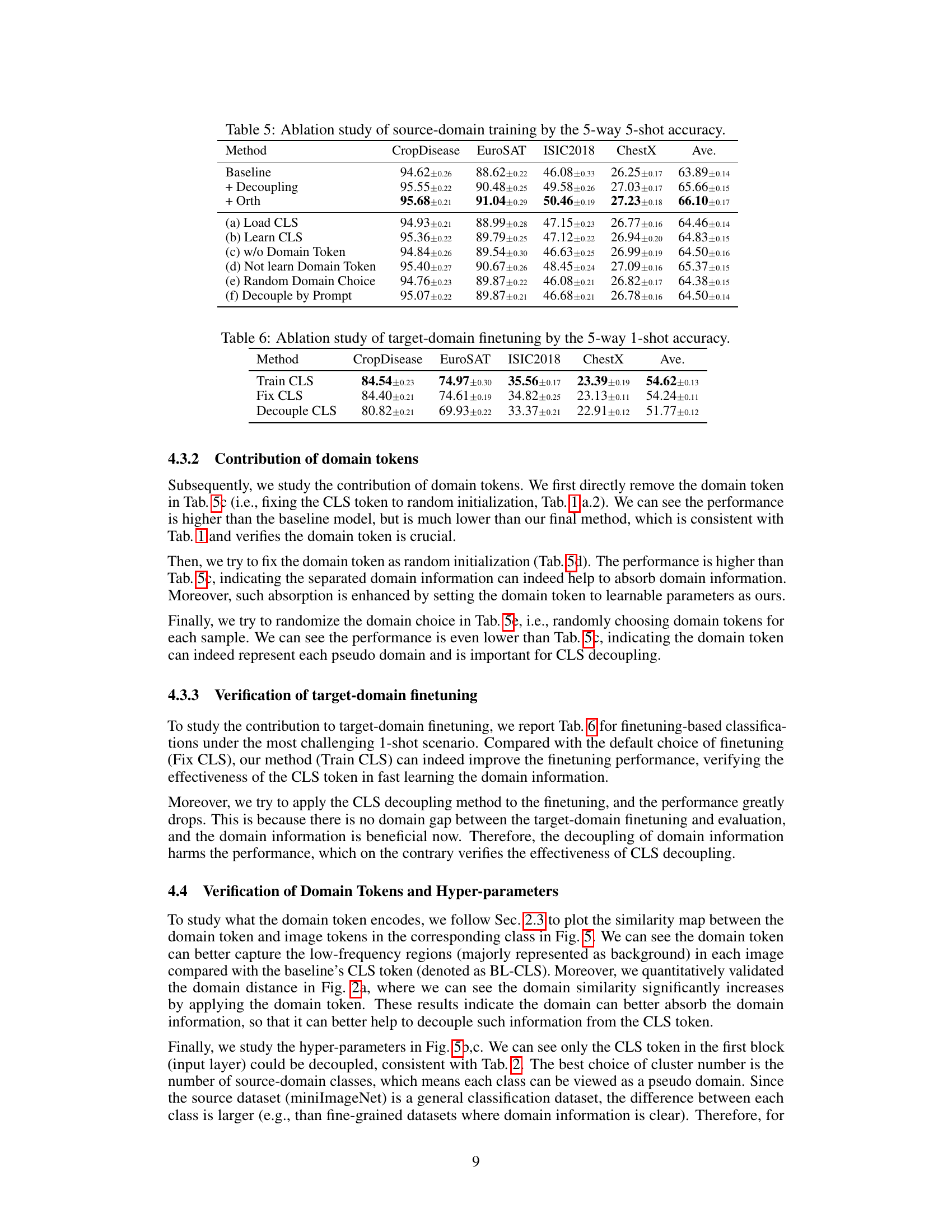
🔼 This table presents the results of an ablation study on the source-domain training process. It shows how different modifications to the training affect the 5-way 5-shot accuracy across four benchmark datasets (CropDisease, EuroSAT, ISIC2018, ChestX). Each row represents a different variation of the training method, allowing for the assessment of the individual impact of different components and techniques. The goal is to understand the contribution of various design choices to the overall performance.
read the caption
Table 5: Ablation study of source-domain training by the 5-way 5-shot accuracy.

🔼 This table presents the results of an ablation study on target-domain finetuning using a 5-way 1-shot accuracy metric. It compares the performance of three different methods: training the CLS token, fixing the CLS token, and decoupling the CLS token. The results are shown across four different benchmark datasets (CropDisease, EuroSAT, ISIC2018, ChestX) and an average across all datasets. The table helps to understand the impact of different approaches to handling the CLS token during target-domain fine-tuning on the overall model performance in a few-shot learning context.
read the caption
Table 6: Ablation study of target-domain finetuning by the 5-way 1-shot accuracy.

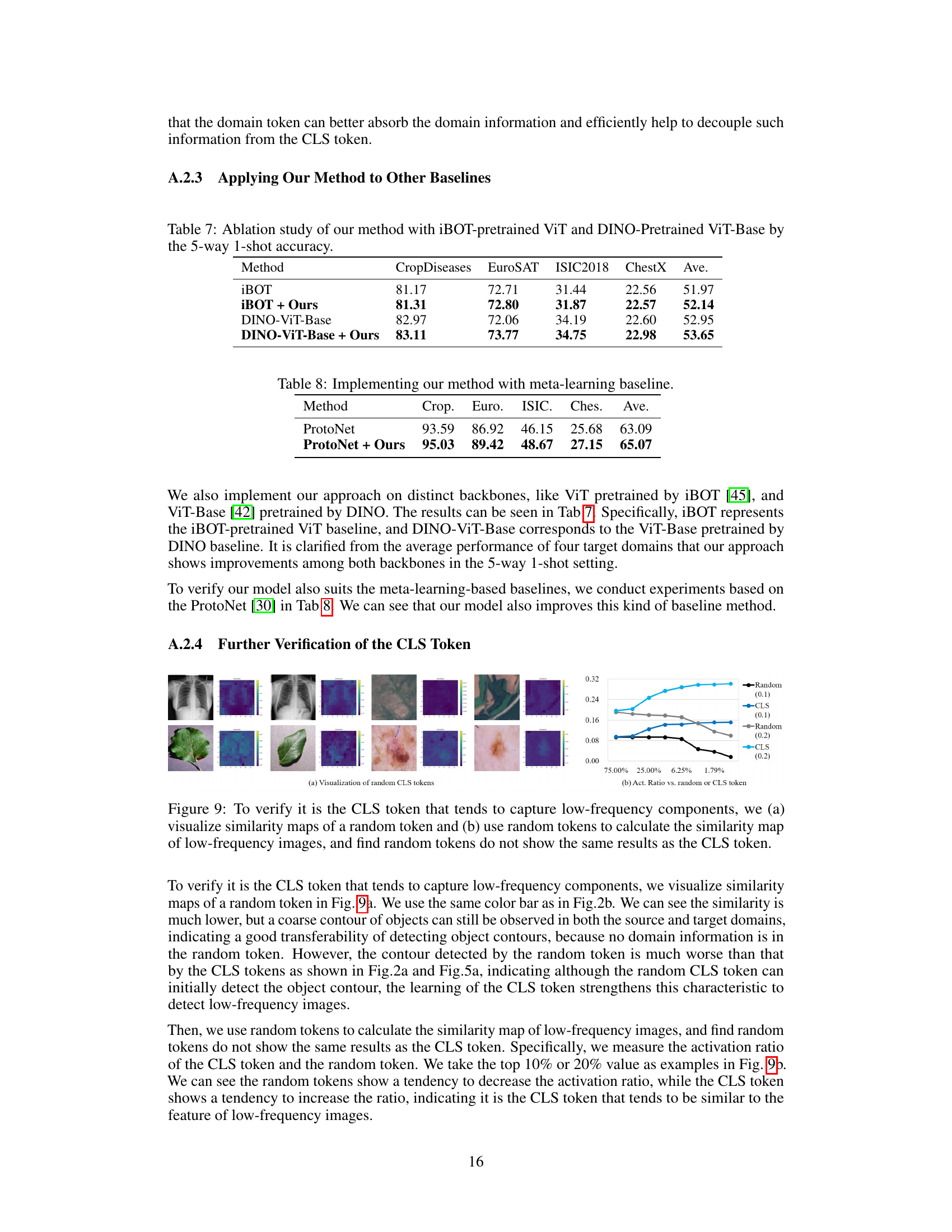
🔼 This table presents the ablation study of the proposed method by comparing its performance with two different pre-trained models: iBOT and DINO-ViT-Base. The results are shown for four different benchmark datasets (CropDiseases, EuroSAT, ISIC2018, and ChestX) using the 5-way 1-shot classification accuracy. The table demonstrates that adding the proposed method consistently improves the performance across all datasets and both pre-trained models, indicating the effectiveness of the proposed approach for improving cross-domain few-shot learning.
read the caption
Table 7: Ablation study of our method with iBOT-pretrained ViT and DINO-Pretrained ViT-Base by the 5-way 1-shot accuracy.

🔼 This table presents the results of the proposed method when integrated with a meta-learning baseline, specifically ProtoNet. It shows a comparison of the performance of ProtoNet alone versus ProtoNet enhanced with the authors’ method across four benchmark datasets (CropDisease, EuroSAT, ISIC2018, and ChestX). The average accuracy is notably improved by adding the authors’ method to the ProtoNet baseline, demonstrating its effectiveness even when combined with alternative approaches.
read the caption
Table 8: Implementing our method with meta-learning baseline.
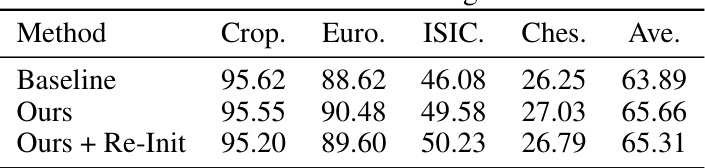
🔼 This table presents the ablation study results for the source-domain training phase using a 5-way 5-shot classification task. It shows the impact of different modifications on the model’s performance, including the impact of decoupling, orthogonal loss, loading and learning CLS tokens, using domain tokens, and random domain selection. The baseline results are compared to these modified approaches to demonstrate the effectiveness of the proposed method.
read the caption
Table 5: Ablation study of source-domain training by the 5-way 5-shot accuracy.
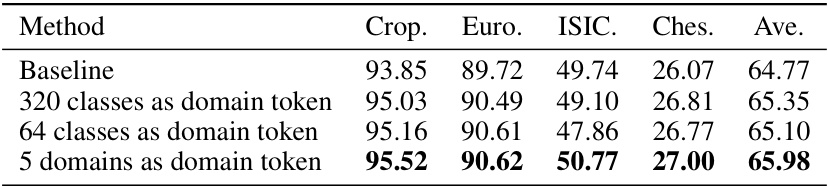
🔼 This table presents the ablation study on the source-domain training, comparing different numbers of domains used as domain tokens (320 classes, 64 classes, and 5 domains). The results show that using 5 domains as domain tokens yields the best average performance across four benchmark datasets.
read the caption
Table 10: Training with datasets of 5 constructed domains.
Full paper#