TL;DR#
Current open-world object detection methods often suffer from computationally expensive training, susceptibility to noisy data, and lack of contextual information. Existing approaches either train contrastive models from scratch or align detection model outputs with image-level region representations, both being resource-intensive and potentially inaccurate.
RegionSpot addresses these limitations by integrating off-the-shelf foundation models (a localization model like SAM and a vision-language model like CLIP), exploiting their respective strengths in localization and semantics. It uses a lightweight attention-based module to integrate their knowledge without fine-tuning the foundation models, resulting in significant performance improvements and substantial computational savings. Experiments demonstrate RegionSpot’s superior performance over existing techniques in open-world object recognition tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents RegionSpot, a novel and efficient framework for region-level visual understanding that significantly outperforms existing methods. Its efficiency and effectiveness in open-world object recognition make it highly relevant to current research trends and open new avenues for improving object detection and image understanding tasks.
Visual Insights#

🔼 This figure compares three different approaches for region-level visual understanding. (a) shows a common approach where image-level representations from cropped regions are used to train a region recognition model. (b) illustrates a method that fine-tunes both vision and text models with a large dataset of region-label pairs. Finally, (c) presents the RegionSpot approach, which leverages pre-trained localization and vision-language models and focuses on learning their representational correlation to improve efficiency.
read the caption
Figure 1: Illustration of typical region-level visual understanding architecture. (a) Learning the region recognition model by distilling image-level ViL representations from cropped regions and incorporating them into a detection model (e.g., [7]). (b) Fully fine-tuning both vision and text models with a substantial dataset of region-label pairs. (c) Our proposed approach integrates pretrained (frozen) localization and ViL models, emphasizing the learning of their representational correlation.
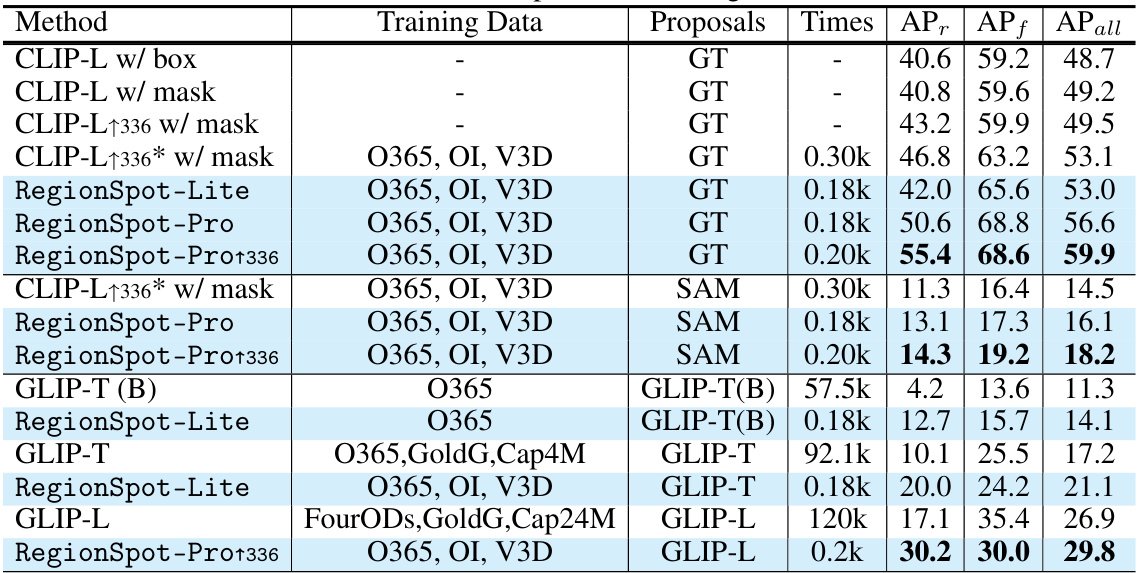
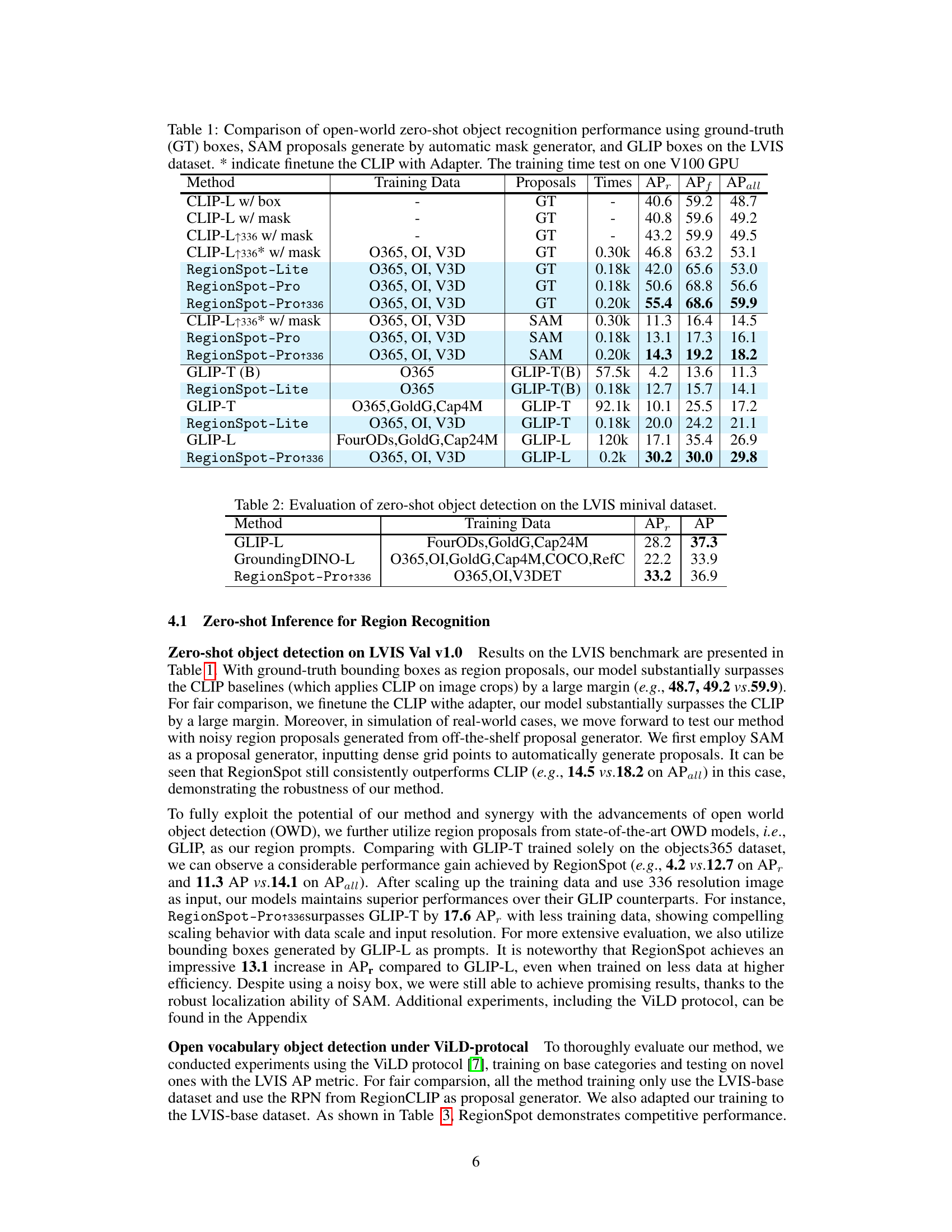
🔼 This table compares the performance of open-world zero-shot object recognition using three different methods: ground-truth boxes, SAM proposals (generated automatically), and GLIP boxes. It shows the Average Precision (AP) for different metrics (APr, APf, APall) and training time on a single V100 GPU. The table also highlights the impact of finetuning CLIP with an adapter and the use of different proposal generation methods on performance.
read the caption
Table 1: Comparison of open-world zero-shot object recognition performance using ground-truth (GT) boxes, SAM proposals generate by automatic mask generator, and GLIP boxes on the LVIS dataset. * indicate finetune the CLIP with Adapter. The training time test on one V100 GPU
In-depth insights#
RegionSpot Framework#
The core of the proposed approach is the RegionSpot framework, a novel method for region-level visual understanding that leverages the strengths of pre-trained foundation models without extensive fine-tuning. Its key innovation is the integration of position-aware localization knowledge (from a model like SAM) with semantic information (from a ViL model like CLIP). This integration is achieved through a lightweight attention-based module that correlates localization and semantic features, allowing for efficient and effective region-level representation learning. By keeping the foundation models frozen, RegionSpot avoids the computationally expensive training requirements and susceptibility to noisy data that plague other region-level recognition methods. This strategy allows for rapid training and significant computational savings, while still delivering state-of-the-art performance in open-world object recognition. The framework’s flexibility and efficiency are highlighted by its ability to seamlessly incorporate advancements in both localization and ViL models, making it a promising direction for future research in region-level visual understanding.
Frozen Model Synergy#
The concept of “Frozen Model Synergy” in a research paper likely refers to a method that leverages pre-trained, frozen models (models whose weights are not updated during training) to achieve a combined outcome superior to using any single model alone. This approach is appealing because it avoids the computationally expensive and time-consuming process of training large models from scratch. The synergy comes from combining the strengths of different models, perhaps using one for detection, one for feature extraction, and one for semantic understanding. Key advantages include reduced training time, decreased computational resources, and potential improvements in overall performance by using pre-trained expertise. However, challenges might include limitations imposed by the fixed weights of the frozen models, potential incompatibility between model outputs, and difficulties in efficiently integrating different model outputs. The effectiveness of the approach depends greatly on the appropriate selection of pre-trained models and the design of the synergistic integration mechanism. A successful implementation would highlight the efficiency gains and performance boosts resulting from combining the capabilities of multiple models without retraining.
Zero-Shot Object Detection#
Zero-shot object detection is a challenging problem in computer vision that focuses on detecting objects from unseen classes during training. This contrasts with traditional object detection, which requires training data for each class. Approaches often leverage auxiliary information like visual attributes, semantic embeddings from vision-language models (like CLIP), or knowledge graphs to bridge the gap between seen and unseen classes. Success hinges on effectively transferring knowledge from known classes to unknown ones, typically using techniques like knowledge distillation or transfer learning. A key aspect is handling ambiguity in visual features, as unseen objects may share visual characteristics with known ones. This area is highly active, with ongoing research striving to improve accuracy and efficiency, particularly dealing with noisy or incomplete data and mitigating biases. Future directions involve exploring more robust knowledge transfer methods, further leveraging large language models and refining techniques to handle the inherent complexities of open-world scenarios.
Computational Efficiency#
Computational efficiency is a critical aspect of any machine learning model, especially in the context of computer vision tasks that often involve massive datasets and complex architectures. The authors emphasize the efficiency of their proposed RegionSpot model by highlighting its ability to integrate pretrained models (SAM and CLIP) without requiring extensive fine-tuning. This approach dramatically reduces the training time and computational resources needed, as demonstrated by their comparison against state-of-the-art methods. The significant reduction in training time achieved by RegionSpot showcases the model’s ability to harness the pre-trained knowledge efficiently. In the context of limited computational resources, this becomes a significant advantage, allowing researchers to train high-performing models without needing extensive computational infrastructure. Furthermore, the model’s effectiveness with a smaller number of learnable parameters highlights its efficiency in parameter utilization, contributing to overall computational efficiency. This focus on efficiency without compromising performance is a key contribution, making RegionSpot particularly suitable for real-world applications with constraints on computational resources.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the efficiency and scalability of the RegionSpot architecture is crucial, particularly for handling extremely large datasets and high-resolution images. Investigating alternative methods for integrating localization and semantic information could lead to performance gains and potentially reduce reliance on pre-trained models. This could involve exploring different attention mechanisms, or novel fusion techniques. Adapting RegionSpot for various downstream tasks beyond object recognition, such as instance segmentation and panoptic segmentation, would be a valuable extension of its capabilities. Finally, a deeper investigation into the model’s robustness to noisy data and adversarial attacks is needed to ensure its reliability in real-world applications. Addressing limitations in dealing with rare or unseen objects and enhancing the model’s ability to handle complex scenes are critical next steps.
More visual insights#
More on figures
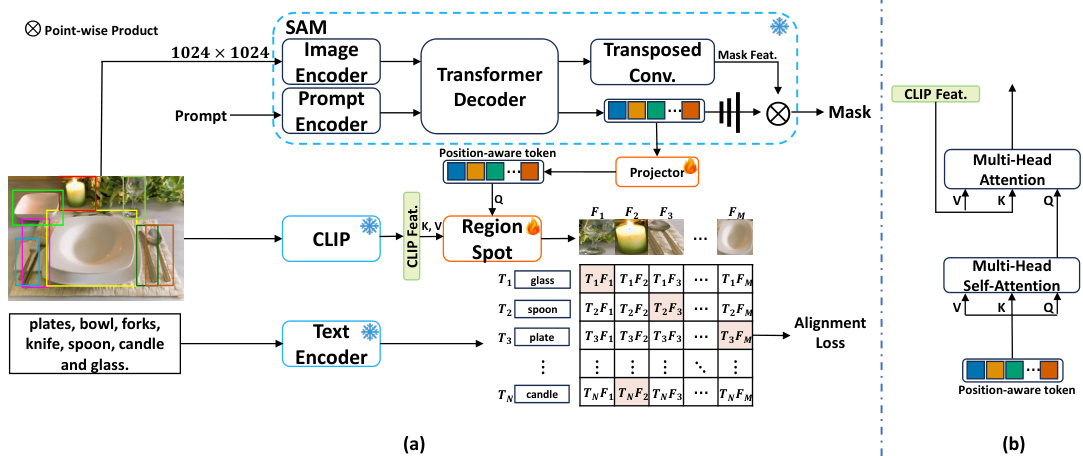
🔼 This figure illustrates the RegionSpot architecture. Panel (a) shows the overall workflow, highlighting how position-aware tokens from a localization model (like SAM) are combined with image-level features from a vision-language model (like CLIP) to create region-level semantic tokens. These tokens are then used in a region-text alignment step. Panel (b) zooms in on the cross-modal feature interaction, which is based on a transformer’s attention mechanism to effectively fuse localization and semantic information.
read the caption
Figure 2: Overview of our proposed RegionSpot. (a) We integrate position-aware tokens from a localization model, such as SAM, with image-level feature maps extracted from a ViL model like CLIP. This integration yields region-level semantic tokens, which are then subjected to region text alignment. (b) Our cross-modal feature interaction design based on the attention mechanism.

🔼 This figure shows a qualitative comparison of object detection results between GLIP-T and the proposed RegionSpot model on the LVIS dataset. Three image examples are presented. Each image shows the bounding boxes and predicted labels from both models. The results visually demonstrate that RegionSpot achieves higher accuracy in recognizing and labeling objects compared to GLIP-T, especially for smaller or more nuanced objects.
read the caption
Figure 3: Qualitative prediction results of GLIP-T [18] (first row) and RegionSpot (second row) on the LVIS dataset [8]. Our model recognizes the objects more accurately. Best viewed when zooming-in.

🔼 This figure visualizes the cross-attention mechanism within the RegionSpot model. It shows how position-aware tokens (from the localization model, SAM) interact with the image-level semantic features (from the ViL model, CLIP). The attention maps highlight the correlation between the localized regions and their semantic representations in the full image. The blue and red boxes in the image correspond to the left and right attention maps respectively, demonstrating how the model integrates positional and semantic information.
read the caption
Figure 4: Cross-attention maps in RegionSpot. These maps show that the position-aware token aligns effectively with the semantic feature map of the entire image. In each row, the blue and red boxes are corresponding to the left and right maps respectively.

🔼 This figure shows a qualitative comparison of object recognition results between GLIP-T and the proposed RegionSpot model on the LVIS dataset. Three image examples are presented, each showing the bounding boxes and predicted labels from both methods. RegionSpot demonstrates superior accuracy in recognizing objects within the images, particularly in identifying smaller or more obscure objects.
read the caption
Figure 3: Qualitative prediction results of GLIP-T [18] (first row) and RegionSpot (second row) on the LVIS dataset [8]. Our model recognizes the objects more accurately. Best viewed when zooming-in.
More on tables

🔼 This table presents the performance comparison of zero-shot object detection methods on the LVIS minival dataset. It shows the Average Precision (AP) and Average Precision for rare categories (APr) for three different models: GLIP-L, GroundingDINO-L, and RegionSpot-Pro1336. The table highlights RegionSpot-Pro1336’s superior performance, exceeding both GLIP-L and GroundingDINO-L in both AP and APr, despite using less training data.
read the caption
Table 2: Evaluation of zero-shot object detection on the LVIS minival dataset.
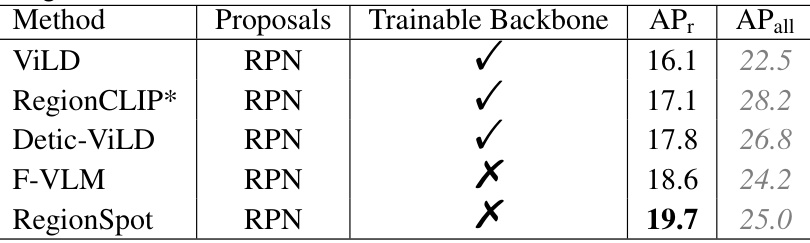
🔼 This table compares the performance of various methods under the ViLD protocol [7] for zero-shot object detection using the ResNet50 backbone. The table shows the Average Precision (AP) scores for rare and all categories. The * indicates that the RegionCLIP model was pre-trained with CC-3M. The table highlights the performance of the proposed RegionSpot model, demonstrating its superiority over the other methods, especially in terms of AP for rare categories.
read the caption
Table 3: Comparison under the ViLD protocol [7]. All methods use the ResNet50 backbone. * indicate pre-training with CC-3M
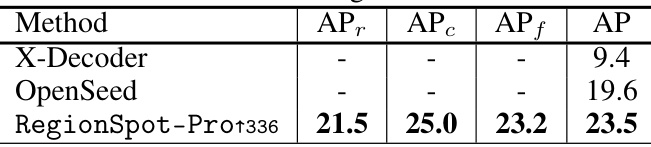
🔼 This table presents the performance comparison of zero-shot instance segmentation on the LVIS minival dataset among three different methods: X-Decoder, OpenSeed, and the proposed RegionSpot-Pro1336. The metrics used for comparison are Average Precision (AP) for different aspects: APr (Average Precision for region), APc (Average Precision for category), APf (Average Precision for both region and category), and overall AP. The results show that RegionSpot-Pro1336 significantly outperforms the other two methods in all metrics.
read the caption
Table 4: Evaluation of zero-shot instance segmentation on the LVIS minival dataset.

🔼 This table presents the performance comparison of several zero-shot object detection methods on the ODinW dataset. The methods are evaluated across six categories (Aerial, Drone, Aquarium, PascalVOC, shellfish, vehicles), and an average performance is also reported. The results highlight the improvements achieved by RegionSpot-Pro1336, which significantly outperforms other methods like GLIP-T, GLIP-L, and GroundingDINO-T.
read the caption
Table 5: Evaluation of zero-shot object detection on the ODinW dataset.

🔼 This ablation study analyzes the impact of different components on the RegionSpot model’s performance on the LVIS dataset. It investigates three aspects: (a) the effect of integrating CLIP vision embeddings, (b) the selection of position-aware tokens generated at different stages in the SAM model, and (c) the effect of varying the depth of the RegionSpot model architecture. The results quantify how each component contributes to the overall performance improvement.
read the caption
Table 6: Ablation experiments on LVIS. (a) The effective of CLIP vision encoder; (b) Position-aware tokens selection; (c) Depth of RegionSpot.

🔼 This table presents the ablation study results on the LVIS dataset, focusing on two aspects: prompt engineering and the impact of different SAM (Segment Anything Model) sizes. The first part shows how using multiple boxes as prompts and incorporating text prompts affects the performance, measured by Average Precision (AP) across different metrics. The second part demonstrates how different SAM backbone sizes (ViT-B and ViT-L) influence the box and mask Average Precision.
read the caption
Table 7: Ablation experiments on LVIS. (a) The effective of propmpt engineering; (b) The effective of SAM
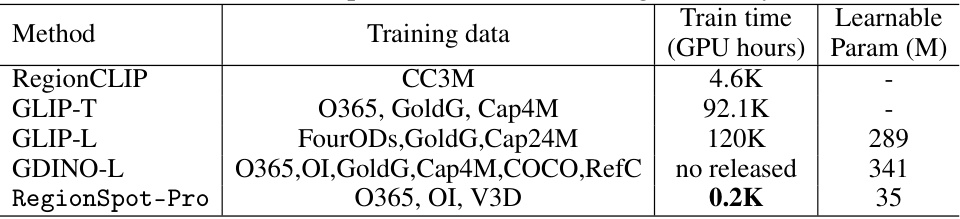
🔼 This table compares the training efficiency (in GPU hours) and the number of learnable parameters (in millions) of different methods for open-world object detection. The methods compared are RegionCLIP, GLIP-T, GLIP-L, GDINO-L, and RegionSpot-Pro. The training datasets used for each method are also listed. RegionSpot-Pro demonstrates significantly greater training efficiency than other methods.
read the caption
Table 8: Comparisons with the training efficiency.

🔼 This table shows the performance improvements observed when augmenting the training data size. By integrating additional detection data from diverse sources, the model’s performance consistently improves. Compared to training with only Objects365, adding OpenImages improves AP from 15.9 to 20.1. Further including V3DET results in an overall AP of 23.7. This improvement is particularly significant for rare categories (an increase of +8.5 AP to 24.9), highlighting the benefit of a larger vocabulary in the training data.
read the caption
Table 9: Effect of increasing the detection training data.
Full paper#