↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current Vision-Language Models (VLMs) struggle with the intertwined nature of perception and reasoning, hindering independent assessment and optimization. Existing methods lack a systematic way to evaluate these capabilities separately. This creates challenges in understanding model strengths and weaknesses, impeding the development of more efficient and powerful VLMs.
The researchers introduce Prism, a modular framework that addresses this issue by decoupling perception and reasoning. Prism uses a VLM for perception (extracting visual information) and an LLM for reasoning (answering the question). This design allows for independent evaluation of various VLMs and LLMs, revealing insights into individual strengths and limitations. Prism demonstrates superior performance on various benchmarks using a smaller VLM paired with a large LLM, showcasing its efficiency and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with vision-language models (VLMs). It introduces Prism, a novel framework that decouples perception and reasoning in VLMs, enabling more effective model analysis and optimization. This addresses a critical challenge in VLM research, paving the way for more efficient and powerful models, especially for vision-language tasks. The framework also works as an efficient VLM.
Visual Insights#
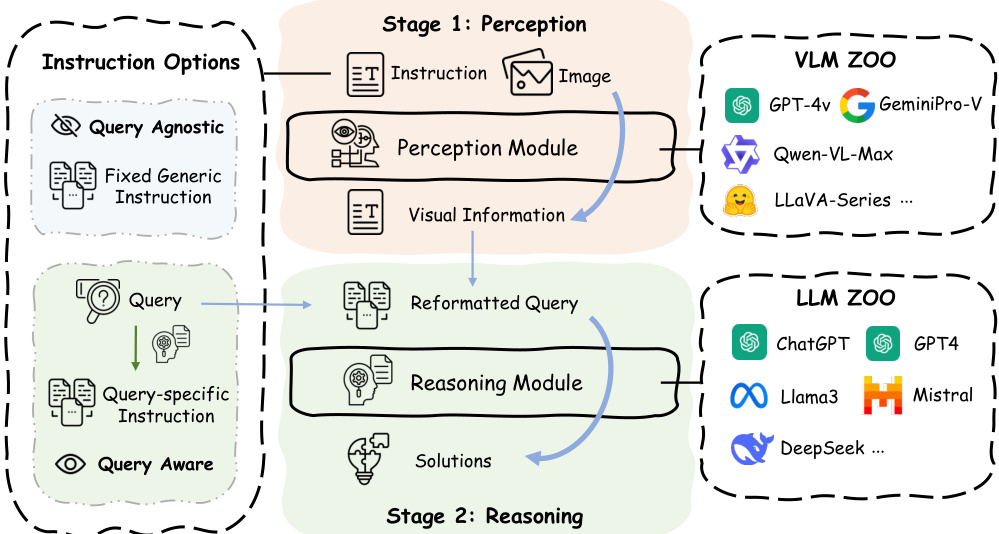
🔼 The figure illustrates the architecture of the Prism framework, which decouples the perception and reasoning stages of visual question answering. Image-query pairs are input. The perception stage uses a Vision Language Model (VLM) to extract visual information from the image guided by an instruction (either query-agnostic or query-aware). This information is then combined with the original question to form a reformatted query for the reasoning stage. The reasoning stage employs a Large Language Model (LLM) to generate the final answer based on the textual visual information and reformatted query. The figure shows various options for instructions and lists several example VLMs and LLMs.
read the caption
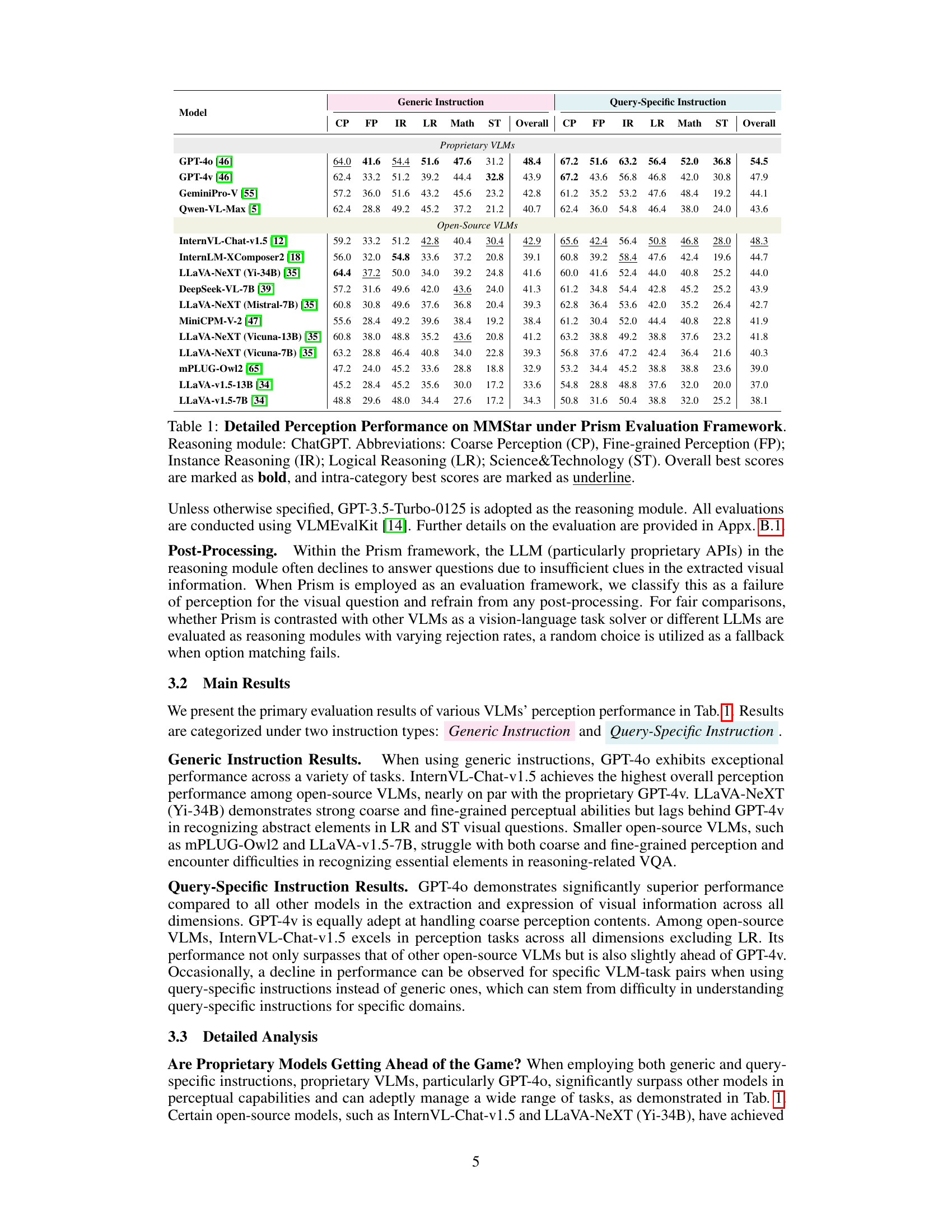
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.
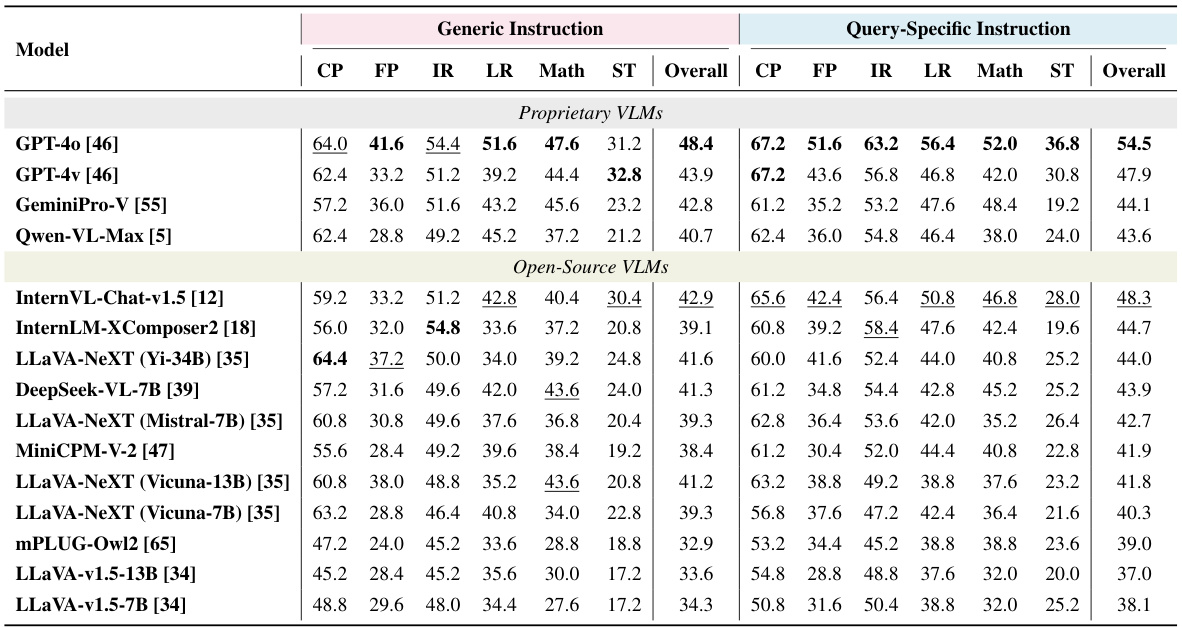
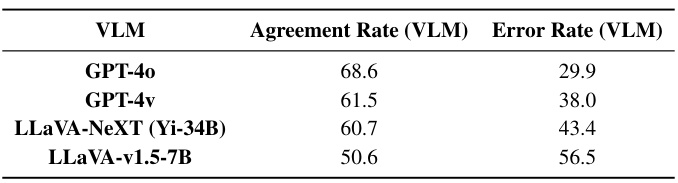
🔼 This table presents a detailed breakdown of the perception performance of various Vision-Language Models (VLMs) on the MMStar benchmark. The performance is analyzed using the Prism framework, which separates perception and reasoning processes. The table shows the performance of different VLMs across various sub-tasks (Coarse Perception, Fine-grained Perception, Instance Reasoning, Logical Reasoning, Science & Technology, and Math) using both generic and query-specific instructions. The best overall scores and best scores within each category are highlighted.
read the caption
Table 1: Detailed Perception Performance on MMStar under Prism Evaluation Framework. Reasoning module: ChatGPT. Abbreviations: Coarse Perception (CP), Fine-grained Perception (FP); Instance Reasoning (IR); Logical Reasoning (LR); Science&Technology (ST). Overall best scores are marked as bold, and intra-category best scores are marked as underline.
In-depth insights#
VLM Decoupling#
The concept of “VLM Decoupling” revolves around separating the perception and reasoning components within Vision-Language Models (VLMs). Traditionally, VLMs operate end-to-end, making it difficult to isolate and analyze the individual contributions of these two crucial faculties. Decoupling allows researchers to assess the strengths and weaknesses of each component independently. This granular analysis enables a more precise understanding of model behavior, facilitating targeted improvements. For instance, researchers can identify if a VLM’s shortcomings stem from weak perception (inability to accurately extract visual information) or deficient reasoning (failure to logically utilize the extracted information to answer questions). This decoupling approach also opens avenues for designing more efficient VLMs. By combining a specialized, lightweight perception module with a powerful reasoning module (e.g., a Large Language Model), it’s possible to achieve performance comparable to much larger, monolithic VLMs while reducing computational costs and improving efficiency. The ability to systematically swap and compare different perception and reasoning modules offers significant benefits for both evaluating existing VLMs and constructing novel architectures.
Prism Framework#
The Prism framework, as described in the research paper, is a modular and highly adaptable approach designed to decouple and assess the capabilities of vision-language models (VLMs). It systematically separates the perception and reasoning processes within VLMs, enabling a more granular analysis of individual model components. By using a VLM to extract visual information and an LLM for reasoning, Prism offers independent evaluation of perception and reasoning strengths. This modular design is highly advantageous for analyzing both proprietary and open-source VLMs, providing valuable insights into their respective competencies. The framework’s adaptability extends to its functionality as an efficient vision-language model solver in itself, combining a lightweight VLM focused on perception with a powerful LLM optimized for reasoning. This approach proves cost-effective, yielding performance on par with much larger VLMs, highlighting Prism’s potential as a versatile tool for both evaluation and practical application in vision-language tasks.
MMStar Analysis#
An MMStar analysis within a vision-language model (VLM) research paper would likely involve a thorough evaluation of the model’s performance on the MMStar benchmark. This benchmark is known for its rigor and focus on multimodal understanding, emphasizing the importance of both visual perception and reasoning capabilities. A comprehensive MMStar analysis would likely explore the model’s strengths and weaknesses across various question categories within the benchmark, providing a granular performance breakdown. Key aspects would include analyzing performance on questions requiring fine-grained visual perception, logical reasoning, and cross-modal understanding. The analysis should quantitatively assess the model’s accuracy, comparing its performance to other state-of-the-art VLMs and potentially identifying any systematic biases or limitations in its capabilities. Visualizations such as bar charts or heatmaps could provide helpful insights into the model’s performance profile across different MMStar question categories. Furthermore, a qualitative analysis of the model’s errors and successes could reveal valuable insights into the model’s decision-making process and how it interacts with various types of visual and textual information. The analysis might also explore the efficiency of the model in terms of computation time and resources. Ultimately, a robust MMStar analysis would offer a holistic understanding of the VLM’s capabilities and contribute valuable insights into the state-of-the-art in multimodal understanding. The analysis may also highlight specific areas of strength and weaknesses for the model to inform future research and development.
Efficient VLMs#
Efficient Vision-Language Models (VLMs) are crucial for real-world applications due to resource constraints. Prism, the framework introduced in the paper, directly addresses this need by decoupling perception and reasoning tasks. This allows for the use of lightweight VLMs focused solely on perception, paired with powerful, but computationally cheaper, LLMs for reasoning. This modular design significantly reduces training and operational costs, enabling superior performance compared to larger, monolithic VLMs. The effectiveness of this approach is validated through quantitative evaluations, demonstrating that Prism achieves performance comparable to much larger models. The key to efficiency lies in the specialized roles of each module, optimizing resource utilization without compromising accuracy. This architecture highlights the potential of a cost-effective, modular approach to VLM development, paving the way for more accessible and widely deployable vision-language AI.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending Prism’s analytical capabilities to encompass a broader range of multimodal benchmarks and vision-language tasks is crucial. This would involve rigorous testing on datasets that assess diverse reasoning abilities and visual understanding, offering a more comprehensive evaluation of VLMs. Investigating the impact of different instruction phrasing and formats on both perception and reasoning stages of Prism is another key area. This includes exploring various levels of detail in instructions and the incorporation of chain-of-thought prompting to see how these changes affect the quality of visual information extraction and answer accuracy. Finally, developing more sophisticated error analysis techniques would enhance the framework’s capacity for identifying specific model weaknesses and guiding targeted model optimization. By focusing on these areas, Prism can solidify its role as a leading-edge tool for understanding and advancing VLM capabilities.
More visual insights#
More on figures
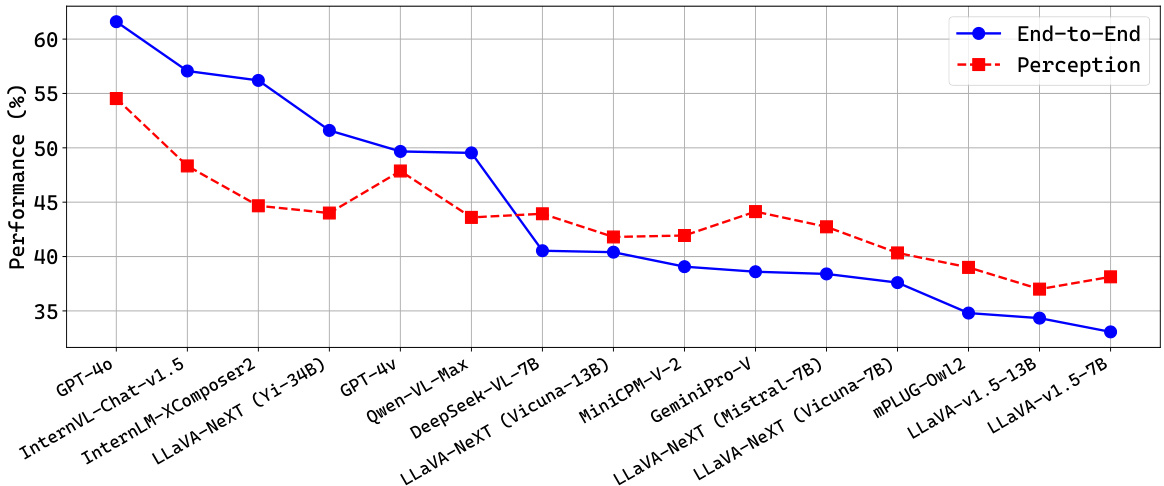
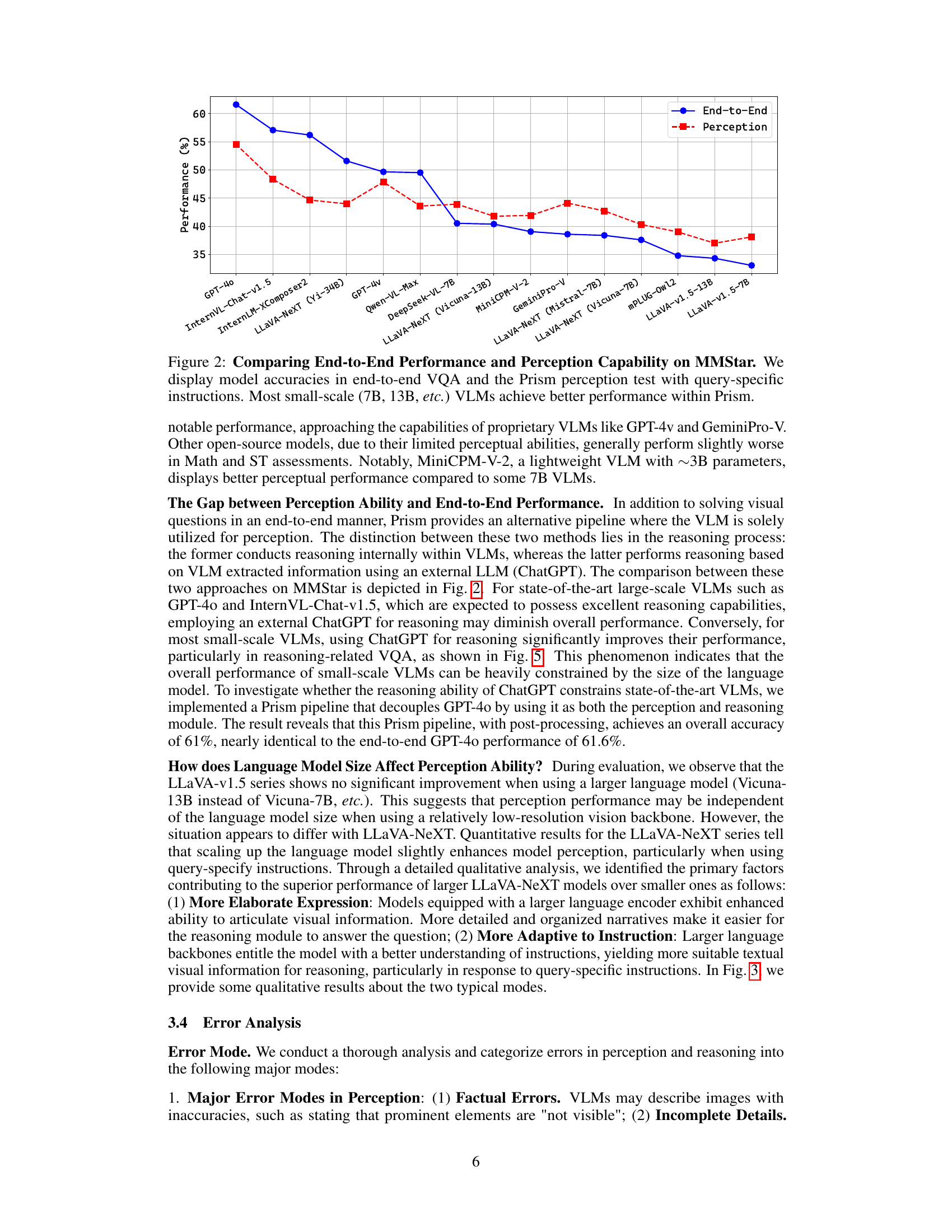
🔼 This figure compares the overall performance of various vision-language models (VLMs) in a standard end-to-end visual question answering (VQA) task versus a two-stage approach using the Prism framework. The two-stage approach separates perception (extracting visual information) and reasoning (answering the question based on visual information). The graph shows that while large proprietary VLMs like GPT-40 generally perform better overall, smaller, open-source models often show improved performance when using Prism’s two-stage approach, suggesting that these models’ limitations may primarily lie in their reasoning capabilities rather than perception.
read the caption
Figure 2: Comparing End-to-End Performance and Perception Capability on MMStar. We display model accuracies in end-to-end VQA and the Prism perception test with query-specific instructions. Most small-scale (7B, 13B, etc.) VLMs achieve better performance within Prism.

🔼 The figure illustrates the architecture of the Prism framework, which is a modular system designed to decouple the perception and reasoning processes involved in visual question answering. It takes image-query pairs as input and consists of two stages: a perception stage where a VLM extracts visual information from an image based on an instruction (which can be either query-agnostic or query-aware) and a reasoning stage where an LLM generates an answer using the reformatted query containing textual information from both the original query and the visual information extracted by the VLM. This modular design allows for systematic comparison and assessment of both VLMs and LLMs.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.
🔼 The figure compares the performance of various vision-language models (VLMs) on the MMStar benchmark in two settings: end-to-end visual question answering (VQA) and a decoupled approach using the Prism framework. The Prism approach separates perception (visual information extraction) and reasoning (answer generation). The graph shows that most small-scale VLMs (those with 7B or 13B parameters) perform better when using the Prism framework compared to the end-to-end approach. This suggests that the limitations of these smaller models are primarily in reasoning rather than perception.
read the caption
Figure 2: Comparing End-to-End Performance and Perception Capability on MMStar. We display model accuracies in end-to-end VQA and the Prism perception test with query-specific instructions. Most small-scale (7B, 13B, etc.) VLMs achieve better performance within Prism.

🔼 This figure illustrates the architecture of the Prism framework, which is a two-stage framework for decoupling and assessing the capabilities of Vision-Language Models (VLMs). The first stage involves a VLM that extracts visual information from an image, based on an instruction (query-agnostic or query-aware). The second stage utilizes a Large Language Model (LLM) to generate an answer based on the extracted visual information and the original question. This modular design allows for separate assessment of perception and reasoning capabilities.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.

🔼 The figure shows the architecture of the Prism framework. Prism consists of two stages: a perception stage and a reasoning stage. In the perception stage, an image and an instruction (which can be either query-agnostic or query-aware) are fed into a Vision Language Model (VLM) to extract visual information and articulate this information in textual form. In the reasoning stage, this textual visual information and the original question are fed into a Large Language Model (LLM) to generate an answer. The VLM and LLM can be replaced flexibly to enable various combinations to assess their perception and reasoning capabilities separately.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.

🔼 This figure illustrates the architecture of the Prism framework. It shows two stages: a perception stage and a reasoning stage. In the perception stage, an image and an instruction (either query-agnostic or query-aware) are input to a Vision Language Model (VLM) to extract visual information. This information is then formatted as text. In the reasoning stage, a Large Language Model (LLM) receives the textual visual information and the original question to produce the final answer.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.

🔼 The figure shows the architecture of the Prism framework, which consists of two stages: a perception stage and a reasoning stage. In the perception stage, a Vision Language Model (VLM) receives an image and a query (which can be either query-agnostic or query-aware). The VLM processes the image and query to extract relevant visual information, which is then converted into text. In the reasoning stage, a Large Language Model (LLM) receives the textual visual information and the original query. The LLM processes this information to generate a final answer.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.

🔼 The figure shows the architecture of the Prism framework, which consists of two stages: a perception stage and a reasoning stage. In the perception stage, a Vision Language Model (VLM) extracts visual information from an image and reformats it into a textual form, based on a given instruction (which can be query-agnostic or query-aware). In the reasoning stage, a Large Language Model (LLM) uses this textual information along with the original query to generate a final answer. Different VLMs and LLMs can be used in each stage, allowing for flexible experimentation and evaluation.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.

🔼 The figure shows the architecture of the Prism framework, which consists of two stages: a perception stage and a reasoning stage. In the perception stage, a Vision Language Model (VLM) extracts visual information from an image and reformats it into a textual form. In the reasoning stage, a Large Language Model (LLM) generates an answer based on the reformatted query and the original question. The framework is modular and flexible, allowing for different VLMs and LLMs to be used. This modular design allows for decoupling and assessment of the perception and reasoning capabilities of VLMs.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.

🔼 The figure illustrates the architecture of the Prism framework, which is a two-stage system for decoupling and assessing the capabilities of Vision-Language Models (VLMs). In the first stage, a VLM extracts visual information from an image and a query, which is then fed to an LLM in the second stage. The LLM generates an answer based on the combined visual and textual information. The modular design allows for flexible combination of VLMs and LLMs for evaluating their relative capabilities.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.
🔼 The figure shows the architecture of the Prism framework, which is composed of two stages: perception and reasoning. In the perception stage, a VLM takes an image and a query as input and extracts visual information. This information is then passed to the reasoning stage, where an LLM generates an answer based on the extracted information and the original query. The framework is designed to decouple perception and reasoning processes, which is important for assessing the capabilities of VLMs.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.

🔼 The figure shows the architecture of the Prism framework. It consists of two main stages: a perception stage and a reasoning stage. In the perception stage, a Vision Language Model (VLM) takes an image and a query as input and extracts visual information from the image. This information is then passed to the reasoning stage, where a Large Language Model (LLM) uses the extracted visual information along with the original query to generate a final answer.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.

🔼 The figure shows the architecture of the Prism framework, which consists of two stages: a perception stage and a reasoning stage. In the perception stage, a Vision Language Model (VLM) processes an image and a query to extract visual information. Then, in the reasoning stage, a Large Language Model (LLM) takes the reformatted query (combining the original query and the extracted visual information) as input to generate the final answer. The figure shows the different components of the two stages, including the instruction options, the VLM zoo, the LLM zoo, and the output.
read the caption
Figure 1: Prism Framework Architecture. Prism framework takes image-query pairs as input. An instruction (can be query-agnostic or query-aware) and the image are first fed into the VLM to extract visual information. Then, an LLM is used to generate the answer based on the reformatted query which combines the original question and visual information in textual form.
More on tables
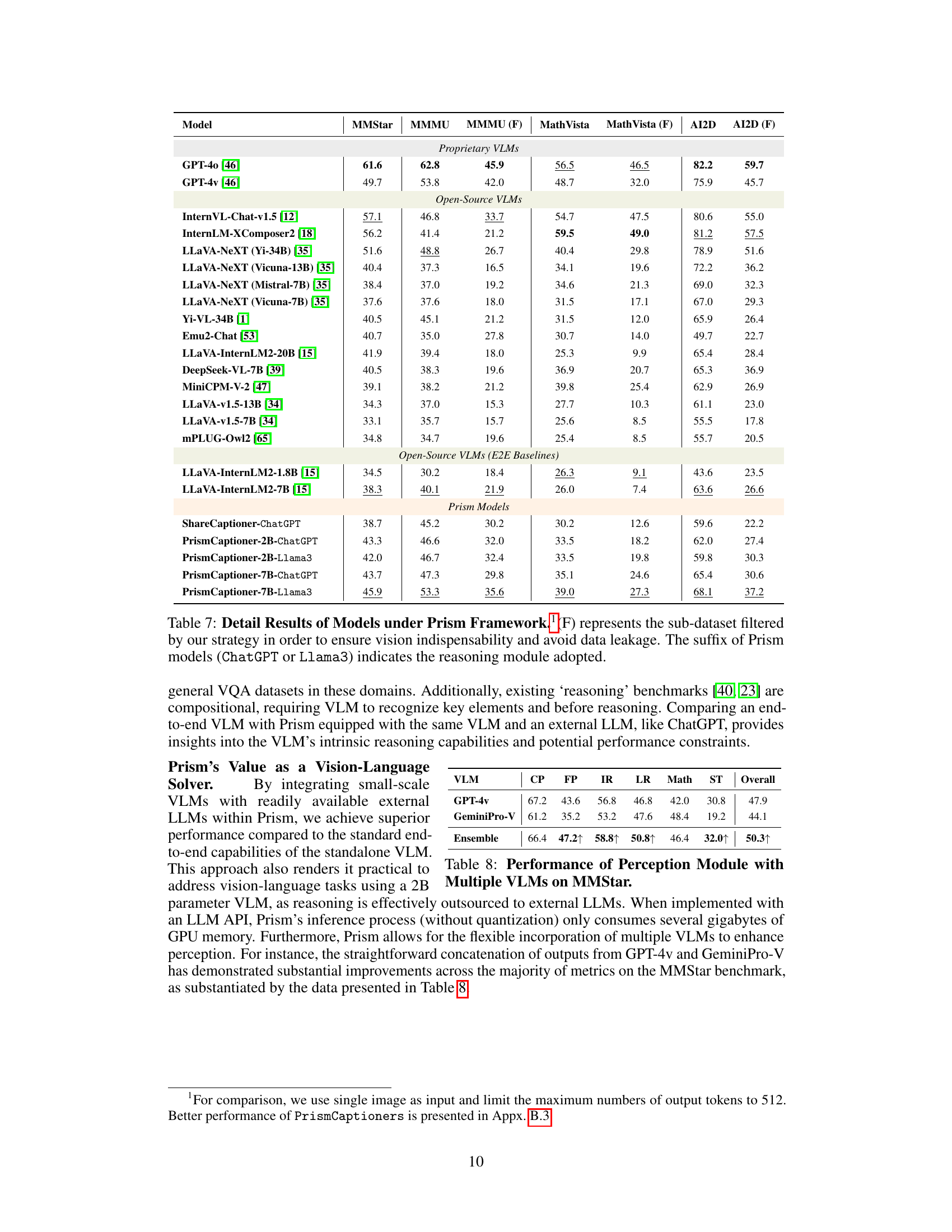
🔼 This table presents a detailed breakdown of the perception performance of various Vision-Language Models (VLMs) on the MMStar benchmark. The performance is assessed using the Prism framework, with ChatGPT serving as the reasoning module. The results are categorized into five sub-categories: Coarse Perception (CP), Fine-grained Perception (FP), Instance Reasoning (IR), Logical Reasoning (LR), and Science & Technology (ST). The best overall scores and the best scores within each category are highlighted. This allows for a comparison of perception capabilities across different VLMs, revealing relative strengths and weaknesses in various aspects of visual understanding.
read the caption
Table 1: Detailed Perception Performance on MMStar under Prism Evaluation Framework. Reasoning module: ChatGPT. Abbreviations: Coarse Perception (CP), Fine-grained Perception (FP); Instance Reasoning (IR); Logical Reasoning (LR); Science&Technology (ST). Overall best scores are marked as bold, and intra-category best scores are marked as underline.
🔼 This table presents a detailed breakdown of the perception performance of various Vision Language Models (VLMs) on the MMStar benchmark, using ChatGPT as the reasoning module. It compares the performance of proprietary and open-source VLMs across five categories: Coarse Perception, Fine-grained Perception, Instance Reasoning, Logical Reasoning, and Science & Technology. The best overall score and best scores within each category are highlighted.
read the caption
Table 1: Detailed Perception Performance on MMStar under Prism Evaluation Framework. Reasoning module: ChatGPT. Abbreviations: Coarse Perception (CP), Fine-grained Perception (FP); Instance Reasoning (IR); Logical Reasoning (LR); Science&Technology (ST). Overall best scores are marked as bold, and intra-category best scores are marked as underline.
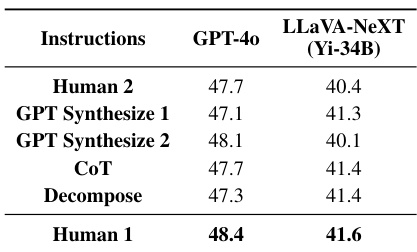
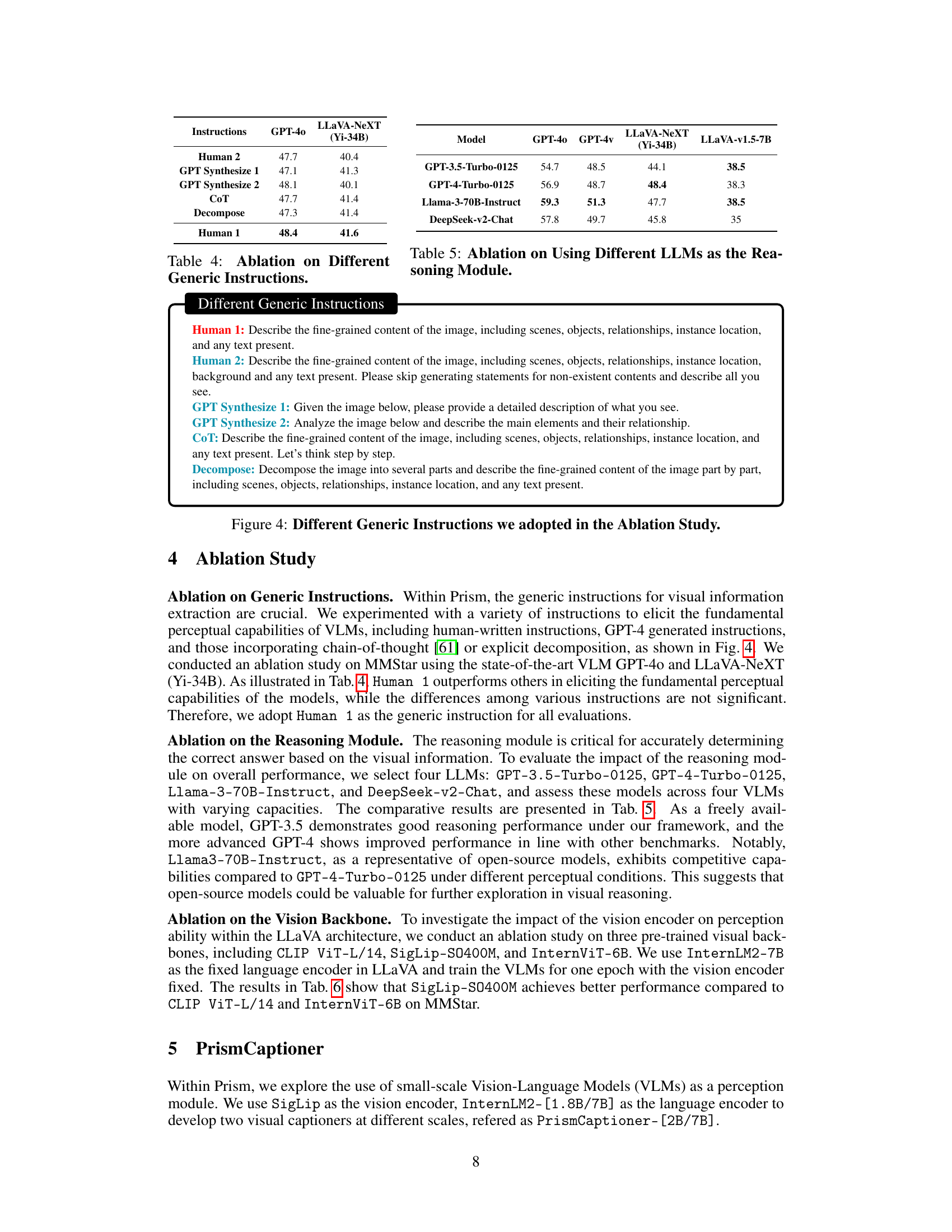
🔼 This ablation study investigates the impact of different generic instructions for visual information extraction on the performance of two state-of-the-art VLMs: GPT-40 and LLaVA-NeXT (Yi-34B). Five different instruction types are compared, including human-written instructions and various GPT-generated instructions that utilize different prompting strategies such as chain-of-thought prompting or decomposition-based prompting. The results show that while different generic instructions lead to some performance variation, the differences are not significant. Therefore, the authors opt to use the ‘Human 1’ instruction for subsequent evaluations as a standard.
read the caption
Table 4: Ablation on Different Generic Instructions.
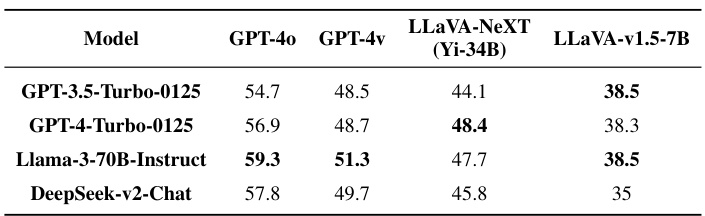
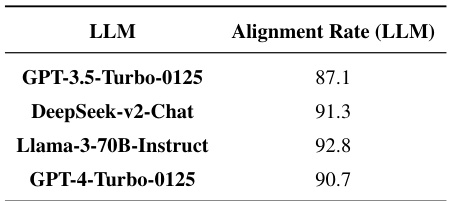
🔼 This table presents the ablation study results focusing on the impact of using different Large Language Models (LLMs) as the reasoning module within the Prism framework. It shows the performance of four different LLMs (GPT-3.5-Turbo-0125, GPT-4-Turbo-0125, Llama-3-70B-Instruct, and DeepSeek-v2-Chat) when paired with various Vision Language Models (VLMs). The results demonstrate the performance variation caused by different LLMs on a range of vision-language tasks. Higher scores indicate better performance.
read the caption
Table 5: Ablation on Using Different LLMs as the Reasoning Module.
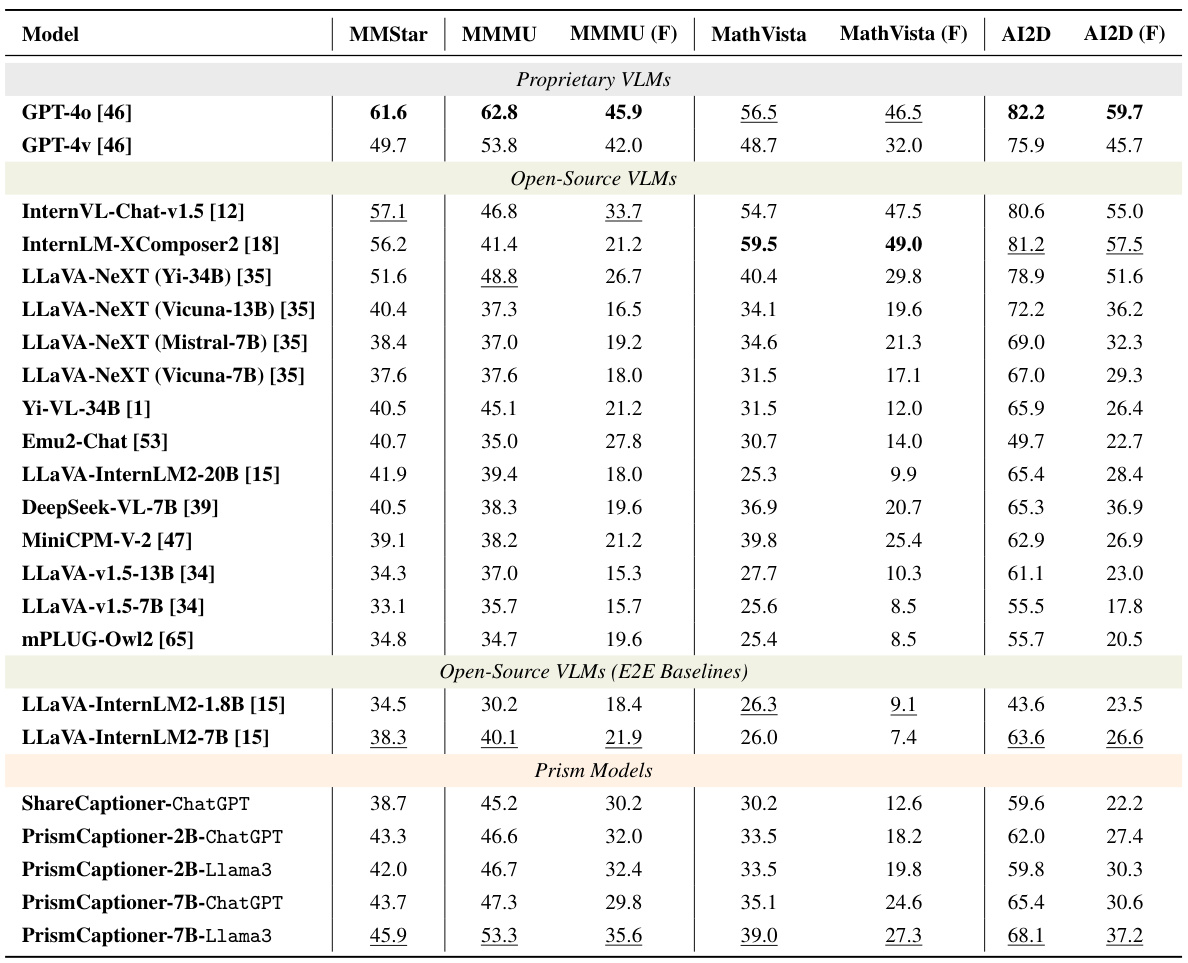
🔼 This table presents the detailed performance of various Vision-Language Models (VLMs) on the MMStar benchmark, focusing on their perception capabilities. The results are broken down by different instruction types (Generic and Query-Specific) and various sub-tasks within the benchmark (Coarse Perception, Fine-grained Perception, Instance Reasoning, Logical Reasoning, Science & Technology, and General). The table highlights the best overall performance and best performance within each category.
read the caption
Table 1: Detailed Perception Performance on MMStar under Prism Evaluation Framework. Reasoning module: ChatGPT. Abbreviations: Coarse Perception (CP), Fine-grained Perception (FP); Instance Reasoning (IR); Logical Reasoning (LR); Science&Technology (ST). Overall best scores are marked as bold, and intra-category best scores are marked as underline.
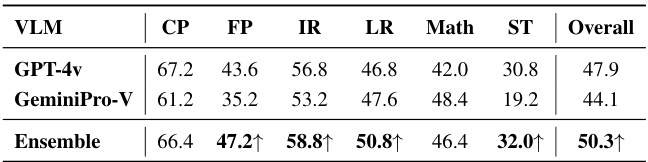
🔼 This table presents a detailed breakdown of the perception performance of various Vision-Language Models (VLMs) on the MMStar benchmark. The evaluation is conducted using the Prism framework, with ChatGPT as the reasoning module. The table shows the performance for each VLM across several categories (CP, FP, IR, LR, Math, ST) and provides an overall score. Best scores are highlighted in bold, with the best score within each category underlined.
read the caption
Table 1: Detailed Perception Performance on MMStar under Prism Evaluation Framework. Reasoning module: ChatGPT. Abbreviations: Coarse Perception (CP), Fine-grained Perception (FP); Instance Reasoning (IR); Logical Reasoning (LR); Science&Technology (ST). Overall best scores are marked as bold, and intra-category best scores are marked as underline.
🔼 This table presents the detailed performance results of various Vision-Language Models (VLMs) on the MMStar benchmark, specifically focusing on their perception capabilities. The evaluation was conducted using the Prism framework with ChatGPT as the reasoning module. The table is divided into two sections: Proprietary VLMs and Open-Source VLMs. For each VLM, the performance metrics are provided across several categories: Coarse Perception (CP), Fine-grained Perception (FP), Instance Reasoning (IR), Logical Reasoning (LR), Math, and Science & Technology (ST). The overall performance is also presented, with the best overall scores and the best scores within each category highlighted.
read the caption
Table 1: Detailed Perception Performance on MMStar under Prism Evaluation Framework. Reasoning module: ChatGPT. Abbreviations: Coarse Perception (CP), Fine-grained Perception (FP); Instance Reasoning (IR); Logical Reasoning (LR); Science&Technology (ST). Overall best scores are marked as bold, and intra-category best scores are marked as underline.

🔼 This table presents a more detailed breakdown of the performance results for the PrismCaptioner models. It shows the performance across different benchmarks (MMStar, MMMU, MMMU (F), MathVista, MathVista (F), AI2D, and AI2D (F)) when using multiple images as inputs and a maximum output length of 2048 tokens. The results are broken down by model and language model used (ChatGPT or Llama3). This allows for a more granular understanding of the models’ capabilities in various scenarios. Note the use of (F) to signify a filtered subset of data.
read the caption
Table 10: More Detailed Performance Results of PrismCaptioners
🔼 This table presents the detailed quantitative results of evaluating the perception capabilities of various Vision-Language Models (VLMs) on the MMStar benchmark using the Prism framework. The evaluation uses ChatGPT as the reasoning module and two types of instructions: generic and query-specific. The table shows the performance of each VLM across five aspects: Coarse Perception, Fine-grained Perception, Instance Reasoning, Logical Reasoning, and Science & Technology. The best overall scores and the best scores within each category are highlighted.
read the caption
Table 1: Detailed Perception Performance on MMStar under Prism Evaluation Framework. Reasoning module: ChatGPT. Abbreviations: Coarse Perception (CP), Fine-grained Perception (FP); Instance Reasoning (IR); Logical Reasoning (LR); Science&Technology (ST). Overall best scores are marked as bold, and intra-category best scores are marked as underline.
Full paper#