↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current audio-visual (AV) representation learning often overlooks the importance of data alignment. Misaligned audio (noise, synchronization issues) limits the quality of joint representations. This paper addresses this issue by proposing AVAgent, a novel data-centric approach to improve AV joint representations.
AVAgent uses a multi-modal LLM to analyze audio and video, plan audio edits, and use a VLM to evaluate the results. This agentic workflow iteratively refines the alignment. Experiments show that AVAgent significantly improves performance on several downstream tasks (classification, localization, separation) compared to existing methods, demonstrating the impact of a data-centric approach.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel data-centric approach to enhance audio-visual representation learning by intelligently aligning audio signals to visual data. This addresses a critical issue in the field, improves the quality of AV data, and leads to state-of-the-art performance in various downstream tasks. It opens new avenues for research by leveraging LLMs for data enhancement and highlights the significance of data quality in AV representation learning.
Visual Insights#

The figure illustrates the AVAgent workflow, a three-step cyclic process for improving audio-visual joint representations. The workflow starts with a ’tool use’ phase where a multimodal LLM processes both audio and video inputs separately to create textual descriptions. Next, in the ‘planning’ phase, the AVAgent (an LLM-based assistant) analyzes these descriptions, determines if alignment is needed, and plans audio editing actions. Finally, in the ‘reflection’ phase, a vision-language model (VLM) evaluates the results, providing feedback to the AVAgent. This cyclic process of tool use, planning, and reflection continues until the audio and video are well-aligned.
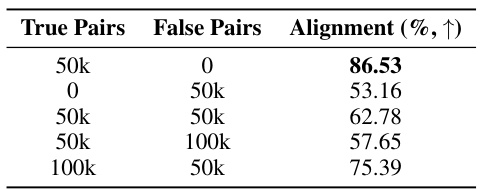
This table presents a quantitative analysis of visual and temporal alignment scores before and after applying the proposed audio-visual alignment method. It shows the impact of the number of ’true’ (aligned) and ‘false’ (misaligned) audio-visual pairs on the alignment scores, demonstrating that the proposed method improves both visual and temporal alignment.
In-depth insights#
Agentic AV Alignment#
Agentic AV alignment presents a novel approach to enhancing audio-visual (AV) data quality by actively aligning audio signals with visual content using a large language model (LLM)-driven agent. This data-centric approach directly addresses common issues like background noise and temporal misalignment. The agent’s workflow involves iterative refinement cycles: First, it uses a multimodal LLM to independently analyze audio and visual data, generating descriptions. Next, the LLM plans audio edits based on this analysis, performing tasks such as noise reduction or synchronization adjustments. Finally, a vision-language model (VLM) evaluates the results, providing feedback for iterative improvement. This agentic workflow, with its built-in feedback loop, enables adaptive alignment tailored to each AV pair. Unlike traditional approaches that assume pre-aligned data, this method actively improves data quality before representation learning, leading to significant improvements in various downstream tasks. This framework demonstrates the potential of LLMs for intelligent data pre-processing, showcasing a powerful paradigm shift in AV representation learning.
LLM-Driven AudioFix#
An LLM-driven AudioFix system presents a novel approach to audio enhancement. It leverages the power of large language models to intelligently analyze audio, identify issues like noise, clipping, or inconsistencies, and apply targeted fixes. The key advantage is the context-aware nature of the corrections. Unlike traditional methods relying solely on algorithms, the LLM understands the semantic content of the audio, leading to more natural and effective repairs. For instance, the system could intelligently reduce background noise during speech while preserving the desired sounds, or automatically adjust volume levels to maintain consistency. This adaptive approach significantly improves audio quality and could be particularly useful for applications where perfect audio recording is not feasible. However, the system’s efficacy hinges on the quality of the input audio and the LLM’s training data. The system’s robustness to unexpected audio issues also needs to be thoroughly evaluated. Ethical considerations surrounding potential misuse are also paramount, requiring careful consideration of safeguards.
Data-Centric AV#
A data-centric approach to audio-visual (AV) processing prioritizes enhancing the quality and alignment of AV data before feeding it into models. This contrasts with model-centric methods, which focus primarily on algorithmic improvements. Data-centric AV recognizes that noisy or misaligned audio and video significantly hinder model performance. Therefore, it emphasizes preprocessing techniques like intelligent noise reduction, synchronization, and data augmentation. By improving data quality through careful alignment and cleaning, a data-centric method aims to increase the robustness and generalizability of AV models. This approach often involves leveraging large language models (LLMs) and vision-language models (VLMs) to analyze and correct discrepancies between audio and video streams. The use of LLMs for planning data modifications and VLMs for evaluating results is a key characteristic of this approach, resulting in a data-centric workflow that iteratively improves data quality and alignment. This iterative cycle distinguishes data-centric AV from conventional approaches, producing cleaner, more aligned data, thereby boosting the performance of subsequent learning methods on downstream AV tasks.
AV Representation#
Audio-visual (AV) representation learning seeks to fuse audio and visual data for improved performance in tasks like captioning and sound source separation. Early methods focused on concatenating or merging features from separate audio and visual processing streams. However, this approach often struggles with misalignment issues such as background noise, asynchronicity, or inconsistent contextual information between modalities. Recent advances emphasize the importance of data pre-processing and alignment techniques to address these issues before joint representation learning. More sophisticated methods explore the use of large language models (LLMs) to intelligently analyze and adjust audio data to better match visual context, showing promising improvements in downstream tasks. Future research should focus on developing more robust and efficient alignment strategies, particularly those handling complex real-world scenarios with substantial noise or distortion, leading to more accurate and reliable AV representations.
Future of AV#
The future of audio-visual (AV) technology is bright, promising significant advancements across diverse fields. Improved data quality and alignment will be crucial, leveraging AI-driven techniques like those demonstrated in the paper to create more robust and accurate AV representations. Large Language Models (LLMs) and Vision-Language Models (VLMs) will play an increasingly vital role in processing and understanding AV data, enabling more sophisticated applications like automatic captioning, content retrieval, and human-computer interaction. Agentic workflows, as explored in this research, offer a powerful means for automating data refinement, adapting to diverse audio and visual inputs, and enhancing synchronization. However, challenges remain, including the need to address computational resource requirements and ensure ethical considerations are at the forefront of development, especially regarding issues of privacy and potential misuse. Ultimately, the future will see more seamless integration of AV modalities, leading to enhanced applications in media, entertainment, accessibility, education, and surveillance.
More visual insights#
More on figures

This figure illustrates the AVAgent framework’s workflow. It uses a multimodal LLM to convert audio and video data into text descriptions. The AVAgent then plans audio edits (noise reduction, synchronization) based on these descriptions. Finally, a vision-language model (VLM) assesses the edits, providing feedback to refine the process iteratively, creating a cycle.

This figure illustrates the AVAGENT framework, a cyclic workflow with three main steps: Tool Use, Planning, and Reflection. In the Tool Use step, a multimodal LLM processes both audio and video data separately, generating textual descriptions. The Planning step uses the LLMs to decide whether audio adjustments are needed and to plan appropriate audio editing actions. Finally, the Reflection step employs a vision-language model (VLM) to evaluate the impact of those actions and provide feedback to the LLM for the next iteration. The entire process gradually aligns audio signals with visual content, improving AV joint representations.

This figure illustrates the AVAGENT workflow, a three-step cyclic process: 1) Tool use: A multimodal LLM processes audio and visual data separately into language descriptions. 2) Planning: The AVAgent uses these descriptions to decide if alignment is needed and plans audio edits (e.g., noise reduction, speed adjustment). 3) Reflection: A Vision-Language Model (VLM) evaluates the edited audio’s match to the visual content, providing feedback for the next cycle. This iterative process refines the audio to better align with the visuals, improving the joint audio-visual representation.

This figure illustrates the AVAGENT framework, a cyclic workflow composed of three stages: tool use, planning, and reflection. In the tool use stage, a multimodal LLM processes audio and visual data separately, generating textual descriptions. These descriptions are then used by the AVAgent in the planning stage to determine necessary audio adjustments (e.g., noise reduction, synchronization). Finally, a Vision-Language Model (VLM) in the reflection stage evaluates the effectiveness of these adjustments, providing feedback to the AVAgent to refine the process iteratively. The goal is to progressively align audio and visual signals for improved joint representation.

This figure provides a high-level overview of the AVAgent framework, illustrating the three main steps involved in the agentic workflow: tool use, planning, and reflection. The workflow starts with a multimodal LLM processing both audio and visual data independently, generating separate textual descriptions. The AVAgent then uses these descriptions to plan necessary audio edits (e.g., noise reduction, synchronization). Finally, a Vision-Language Model (VLM) assesses the results of these edits to provide feedback for the next iteration of the cycle. This cyclical process progressively improves the alignment between audio and visual data, resulting in enhanced joint representation.
More on tables
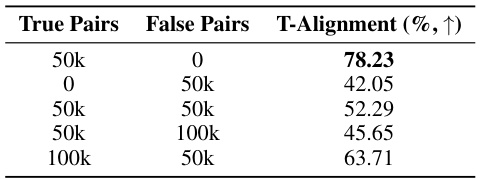
This table presents the results of data analysis focusing on visual alignment and temporal synchronization. It compares the performance of the proposed method against a baseline. ‘True Pairs’ represent video-audio pairs where the audio has been modified by the proposed method, while ‘False Pairs’ represent pairs with original, unmodified audio. The ‘T-Alignment (%)’ column shows the percentage improvement in temporal alignment achieved by the proposed method, demonstrating its effectiveness in enhancing synchronization between audio and video.

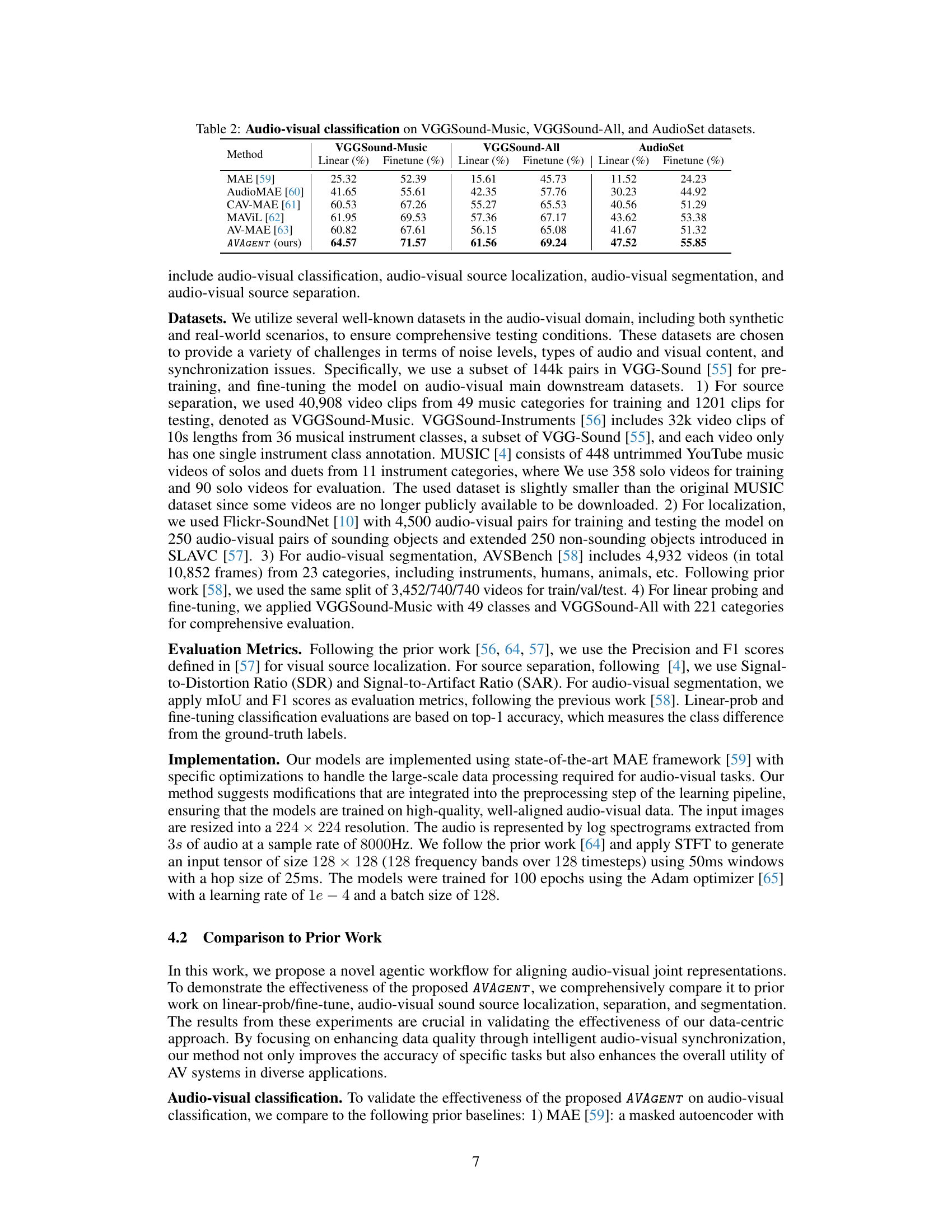
This table presents the performance comparison of the proposed AVAGENT model against various state-of-the-art baselines on three different audio-visual classification datasets: VGGSound-Music, VGGSound-All, and AudioSet. The results are shown in terms of linear probing accuracy and finetune accuracy. Higher percentages indicate better performance. The table highlights the superior performance of the AVAGENT method in this task.
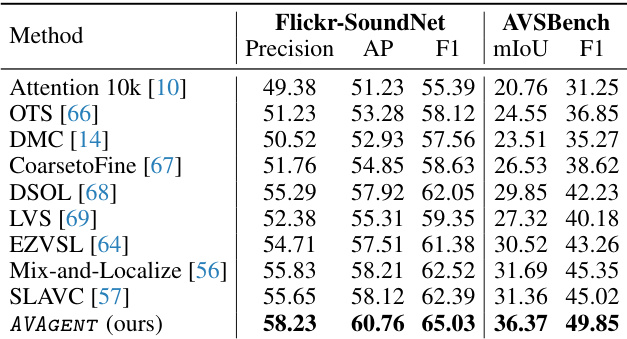
This table presents a quantitative comparison of the proposed AVAGENT model against several state-of-the-art methods for sound source localization and segmentation tasks. The evaluation is performed on two benchmark datasets, Flickr-SoundNet and AVSBench, using metrics such as Precision, Average Precision (AP), F1 score, mean Intersection over Union (mIoU), and F1 score for segmentation. Higher scores indicate better performance.
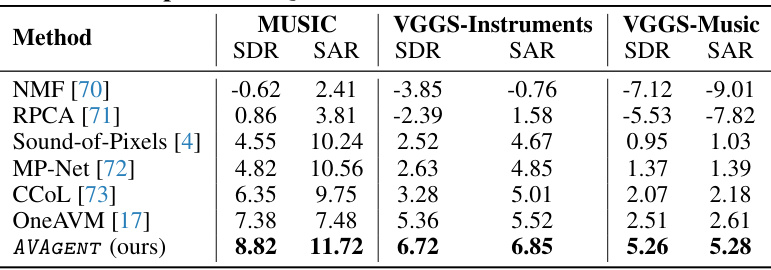
This table presents a quantitative comparison of different sound source separation methods on two datasets: MUSIC and VGGSound. The evaluation metrics used are SDR (Signal-to-Distortion Ratio) and SAR (Signal-to-Artifact Ratio). Higher values of SDR and SAR indicate better separation performance. The table allows for a comparison of the proposed AVAGENT method against several established baselines in the field of audio source separation.

This table presents the performance of the proposed AVAGENT model and several baseline models on three audio-visual classification datasets: VGGSound-Music, VGGSound-All, and AudioSet. The results are shown in terms of linear probing accuracy and fine-tuning accuracy for each model on each dataset. The table highlights the superior performance of the AVAGENT model compared to the baselines, demonstrating its effectiveness in improving audio-visual representation learning for classification tasks.

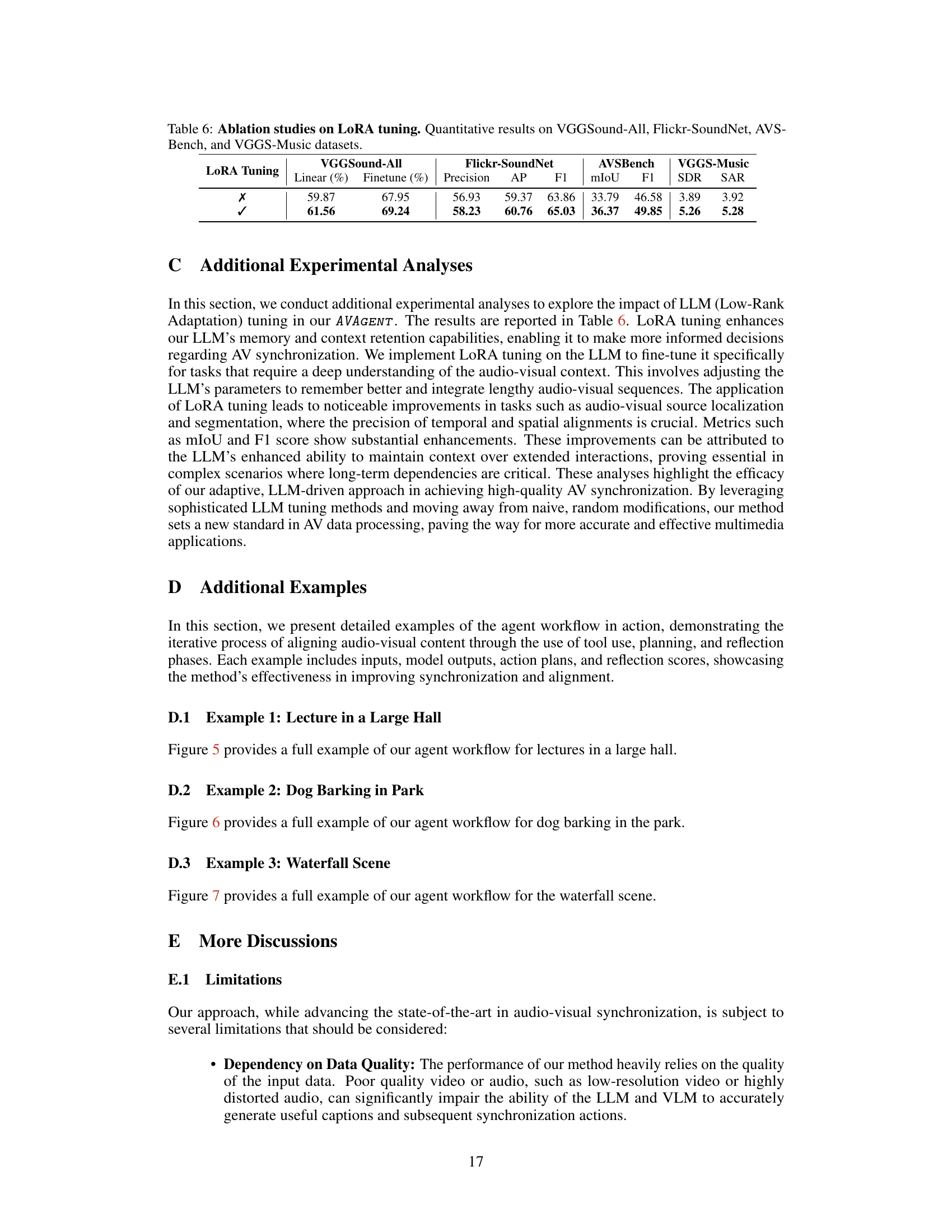
This ablation study investigates the impact of LoRA (Low-Rank Adaptation) tuning on the performance of the AVAgent model across four different audio-visual datasets. The results presented show the impact of LoRA tuning across various downstream tasks including linear probing, fine-tuning, precision, average precision (AP), F1 score, mean Intersection over Union (mIoU), and Signal-to-Distortion Ratio (SDR) and Signal-to-Artifact Ratio (SAR). The study compares the model’s performance with and without LoRA tuning to highlight its effectiveness.
Full paper#