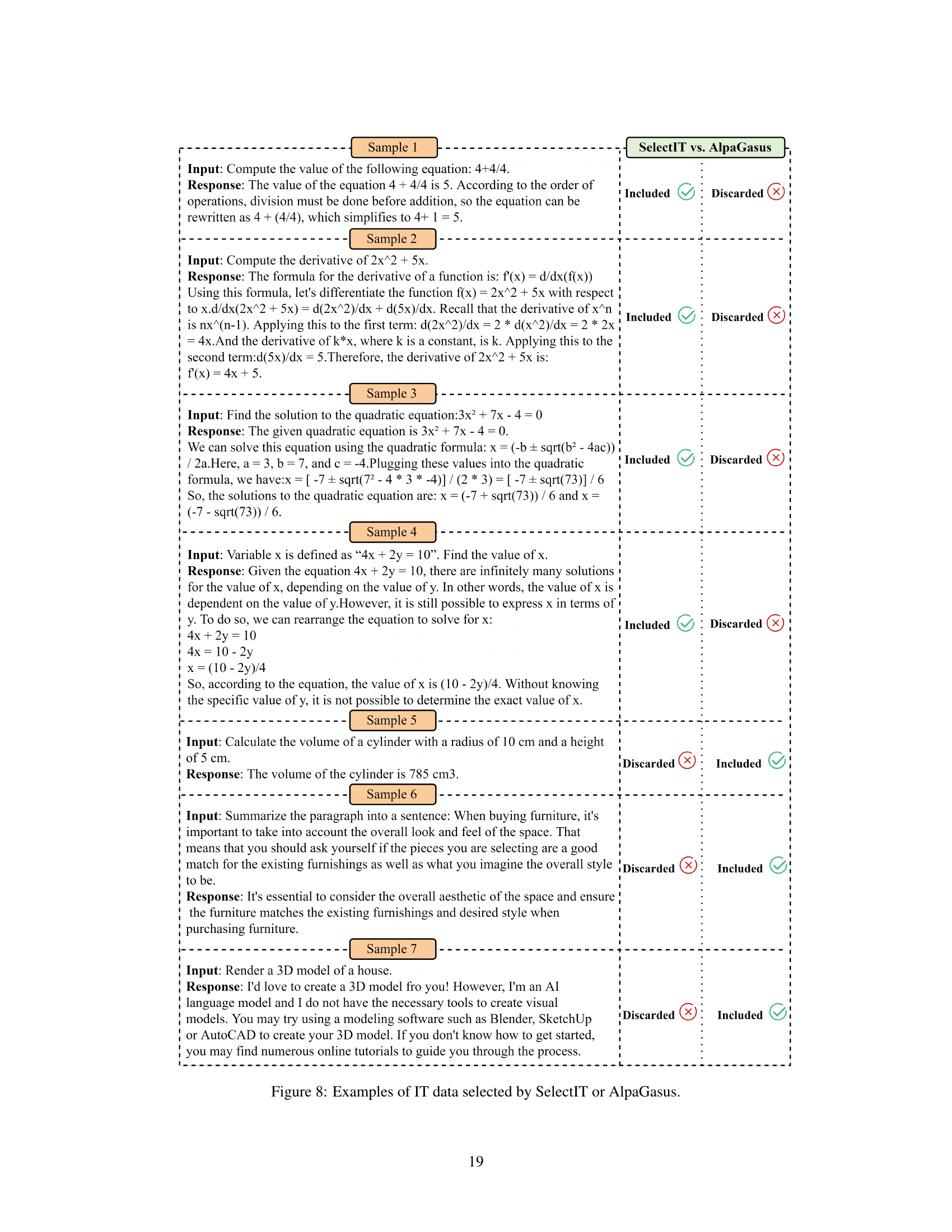
↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Instruction tuning (IT) significantly boosts Large Language Model (LLM) performance, but selecting high-quality IT data is often costly and resource-intensive. Existing methods often rely on extra models or data, limiting widespread adoption. This is problematic, as the quality of the data is shown to be more critical than the quantity.
SelectIT, a novel method, addresses this by using the LLM’s inherent uncertainty to select high-quality data without external resources. SelectIT analyzes uncertainty at the token, sentence, and model levels to rate data quality. Experiments show that SelectIT outperforms existing methods and generates the Selective Alpaca dataset, demonstrating that longer, more computationally intensive instruction data yields better results.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs because it introduces a novel method for improving model performance using high-quality instruction data. SelectIT offers a resource-efficient solution, improving LLM capabilities without extra models or data, and providing insights into optimal data characteristics. This opens up new avenues for research in data selection and LLM instruction tuning, benefiting various applications.
Visual Insights#
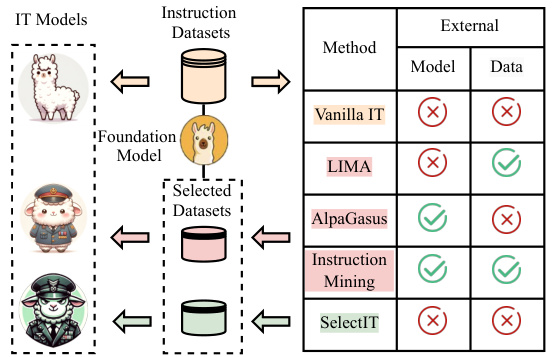
This figure is a comparison of different methods for instruction tuning (IT) of large language models (LLMs). It highlights that existing advanced methods like LIMA, AlpaGasus, and Instruction Mining rely on either external models or additional data for selecting high-quality instruction data. In contrast, SelectIT leverages the LLM’s intrinsic capabilities and doesn’t require extra resources, making it a more efficient and accessible approach.
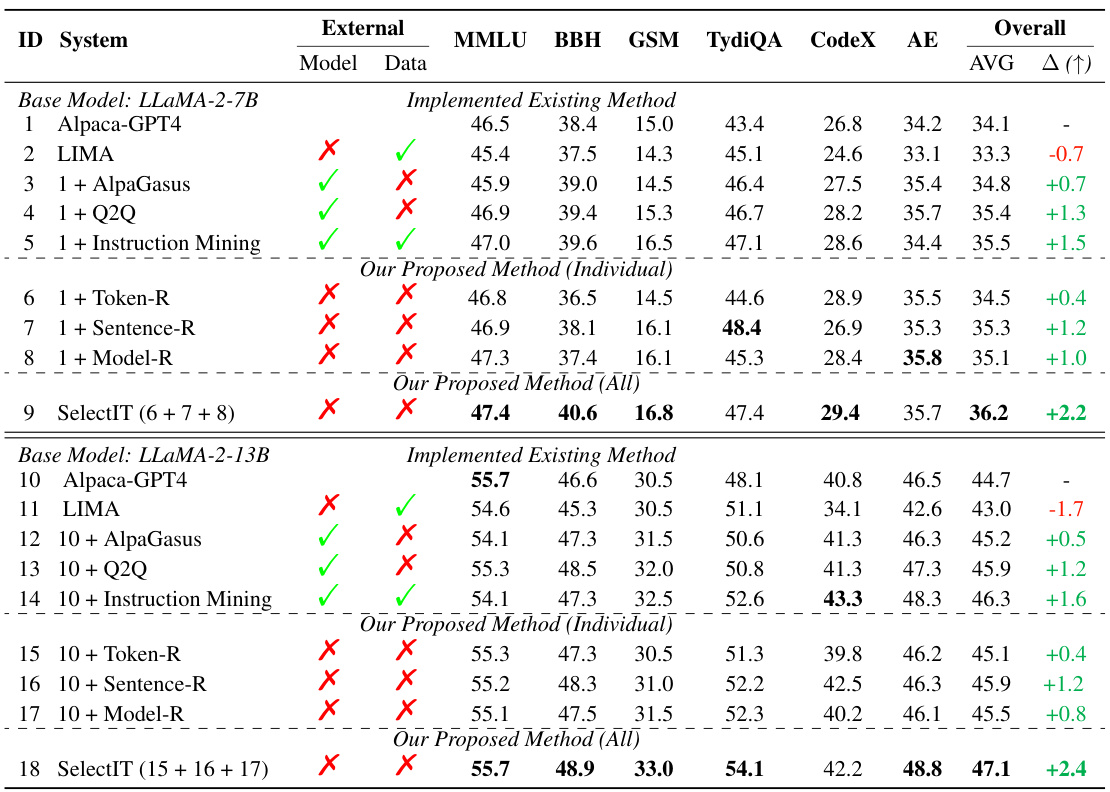
This table presents the overall performance comparison of different instruction tuning methods on two base LLMs (LLaMA-2-7B and LLaMA-2-13B). It contrasts the performance of Alpaca-GPT4, LIMA, AlpaGasus, Q2Q, Instruction Mining, and three individual components of the proposed SelectIT method (Token-R, Sentence-R, Model-R) against the full SelectIT approach. The results are shown for various downstream tasks (MMLU, BBH, GSM, TyDiQA, CodeX, AE) and an overall average, offering a comprehensive evaluation of each method’s effectiveness in improving LLM abilities. All scores represent the average of three independent runs with varying random seeds.
In-depth insights#
LLM Uncertainty#
LLM uncertainty, the inherent unpredictability in Large Language Model (LLM) outputs, is a critical area of study. Understanding and leveraging this uncertainty is key to improving LLM performance and reliability. This paper explores this by using the LLM’s own uncertainty estimates (at the token, sentence, and model level) to select high-quality instruction tuning data. This novel approach, named SelectIT, avoids reliance on external models or datasets, making it more efficient and widely applicable. The core idea is that the LLM’s uncertainty about an instruction indicates potentially problematic or low-quality data points. By identifying and filtering these uncertain examples, SelectIT refines the training set. SelectIT’s effectiveness in improving model ability and robustness across diverse foundation models highlights the importance of harnessing the intrinsic capabilities of LLMs for data optimization. This method represents a significant advancement in the efficient and cost-effective training of LLMs, moving away from the resource-intensive practices that depend on external evaluation models. Further research could explore the precise nature of uncertainty and how different types of uncertainty contribute to data quality assessment and model performance. Quantifying and understanding the relationship between various uncertainty measures and the ultimate quality of the selected data would improve the efficacy and interpretability of this approach.
SelectIT Method#
The SelectIT method is a novel approach to instruction tuning (IT) for large language models (LLMs) that leverages the inherent uncertainty within LLMs themselves. Instead of relying on external models or datasets for data selection, SelectIT uses a multi-level self-reflection process to evaluate the quality of instruction-response pairs. This process begins with token-level self-reflection, analyzing the prediction uncertainty of the LLM at the token level. Then, sentence-level self-reflection incorporates the variability in LLM responses caused by different phrasings of the same instruction. Finally, model-level self-reflection integrates the uncertainty across multiple LLMs to make a more robust judgment on data quality. By combining these levels of reflection, SelectIT effectively selects a subset of high-quality IT data, leading to significant improvements in LLM performance. This method is particularly valuable for its efficiency and cost-effectiveness, as it avoids the need for extra models and resources.
Selective Alpaca#
The concept of “Selective Alpaca” represents a refined, high-quality instruction tuning dataset derived from the original Alpaca dataset. This refinement is achieved not through brute-force scaling, but through a novel data selection method called SelectIT. SelectIT leverages the intrinsic uncertainty present within LLMs to identify and prioritize higher-quality data points, eliminating the need for external models or resources. The key innovation is using the LLM’s own uncertainty estimations (at token, sentence, and model levels) to assess the quality of each instruction-response pair, creating a more efficient and cost-effective approach to instruction tuning. The resulting “Selective Alpaca” dataset, therefore, is expected to be more effective and less computationally expensive to use for training, leading to enhanced performance in downstream tasks. The reduced dataset size further contrasts with trends of simply increasing the volume of training data, highlighting the importance of quality over quantity in instruction tuning. This approach promises to improve the efficiency and accessibility of instruction tuning for LLMs.
Ablation Study#
An ablation study systematically removes components of a system to assess their individual contributions. In the context of a machine learning model, this might involve removing different data selection methods or components of the SelectIT framework to understand their impact on overall model performance. A well-designed ablation study isolates the impact of individual components, showing whether each is necessary and beneficial. This is critical for understanding the SelectIT approach, demonstrating that its combined components are synergistic, leading to better results than any single component alone. By analyzing the effect of removing each component—token, sentence, and model-level self-reflection—the researchers can quantify the value of each component in the SelectIT pipeline. The results likely show a performance drop when any component is removed, confirming the importance of each module’s contribution to SelectIT’s overall effectiveness. Further investigation might involve systematically varying the hyperparameters to determine the robustness of the findings and the optimal configuration of the model.
Future Work#
Future research directions stemming from this SelectIT method could explore several promising avenues. Expanding the evaluation to encompass a broader range of LLMs, including larger parameter models, is crucial to assess the method’s scalability and generalizability. A comparative analysis against other advanced data selection techniques, considering various evaluation metrics beyond those used in this study, would provide a more comprehensive understanding of SelectIT’s strengths and weaknesses. Investigating the impact of different instruction tuning dataset characteristics—such as instruction style, data distribution, and task complexity—on SelectIT’s performance could lead to valuable insights for tailoring the data selection process. Finally, researching efficient strategies to integrate SelectIT into the instruction tuning pipeline would optimize the process and its integration within current LLM training workflows. Exploring the potential of SelectIT for other downstream tasks beyond those studied in this paper could also reveal additional impactful applications. The relationship between data quality and computational cost associated with data selection needs further investigation.
More visual insights#
More on figures

This figure illustrates the overall framework of the SelectIT method. It shows three main levels of self-reflection: token-level, sentence-level, and model-level. Each level uses the inherent uncertainty within LLMs to score the quality of instruction tuning (IT) data. The token-level focuses on the next-token prediction probability, sentence-level incorporates variations in prompt phrasing, and model-level considers the discrepancies between different LLMs’ evaluations. These individual scores are then combined to produce a final quality score for each data point, enabling effective selection of high-quality data without requiring external resources.
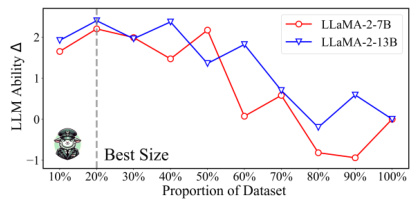
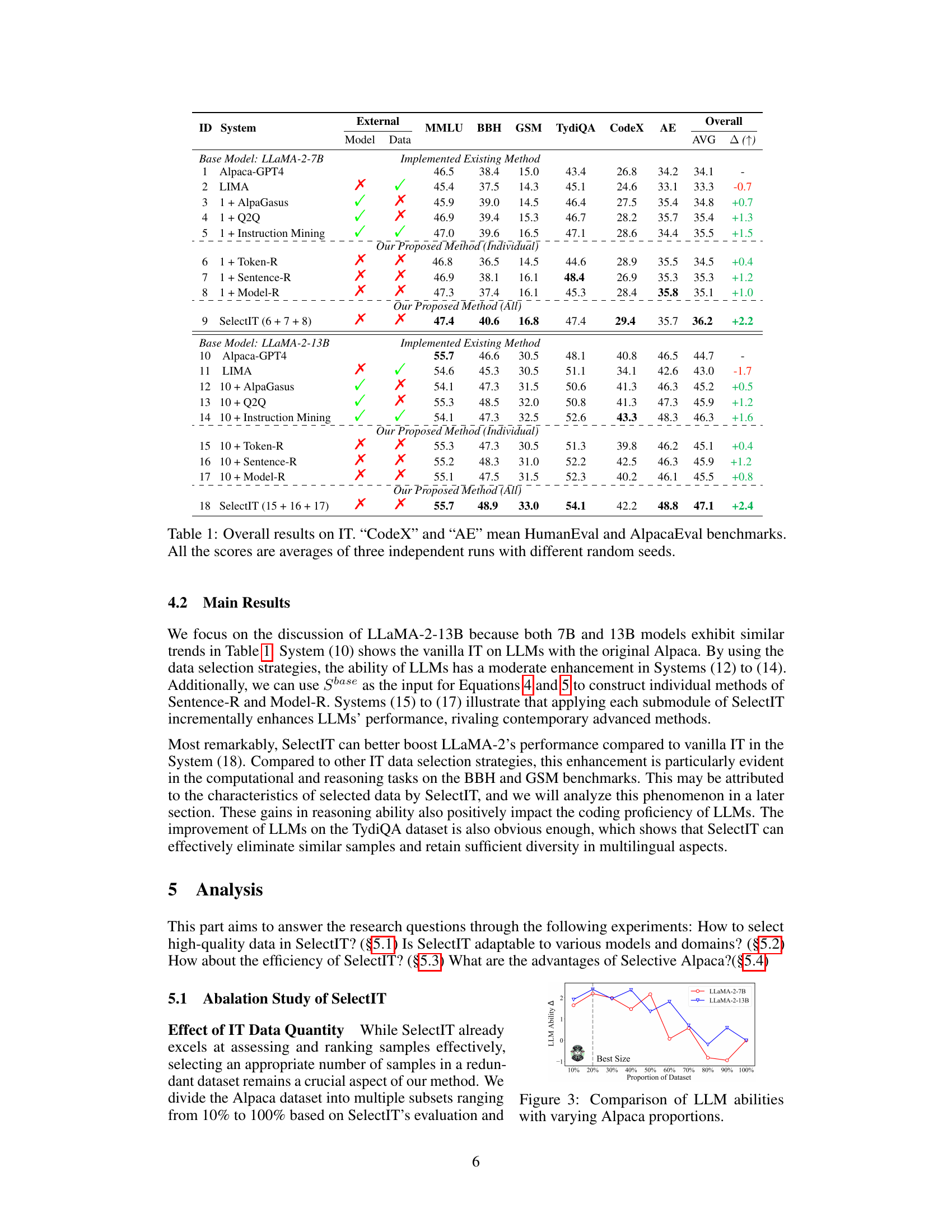
This figure shows the results of an ablation study on the impact of the size of the instruction tuning dataset on the performance of LLMs. The x-axis represents the proportion of the Alpaca dataset used for training, ranging from 10% to 100%. The y-axis shows the change in LLM ability (Δ), likely measured by some benchmark score, reflecting the improvement achieved by fine-tuning with different proportions of data. Two lines are plotted, representing the performance of LLaMA-2-7B and LLaMA-2-13B models. The graph illustrates an optimal range (marked as ‘Best Size’) where using a smaller subset of the data (around 20-40%) yields better results than using the full dataset. This highlights the importance of data quality over quantity in instruction tuning.
This figure illustrates the overall framework of the SelectIT method for selective instruction tuning. It shows three main levels of self-reflection: token-level, sentence-level, and model-level. Each level leverages the intrinsic uncertainty of LLMs to improve the accuracy of IT data selection. The token-level uses next-token prediction probabilities, the sentence-level considers the variance in scores from multiple prompts, and the model-level integrates the ratings from multiple LLMs. Finally, these three levels are combined to generate a final score for each data point, allowing SelectIT to effectively select high-quality data without external resources.

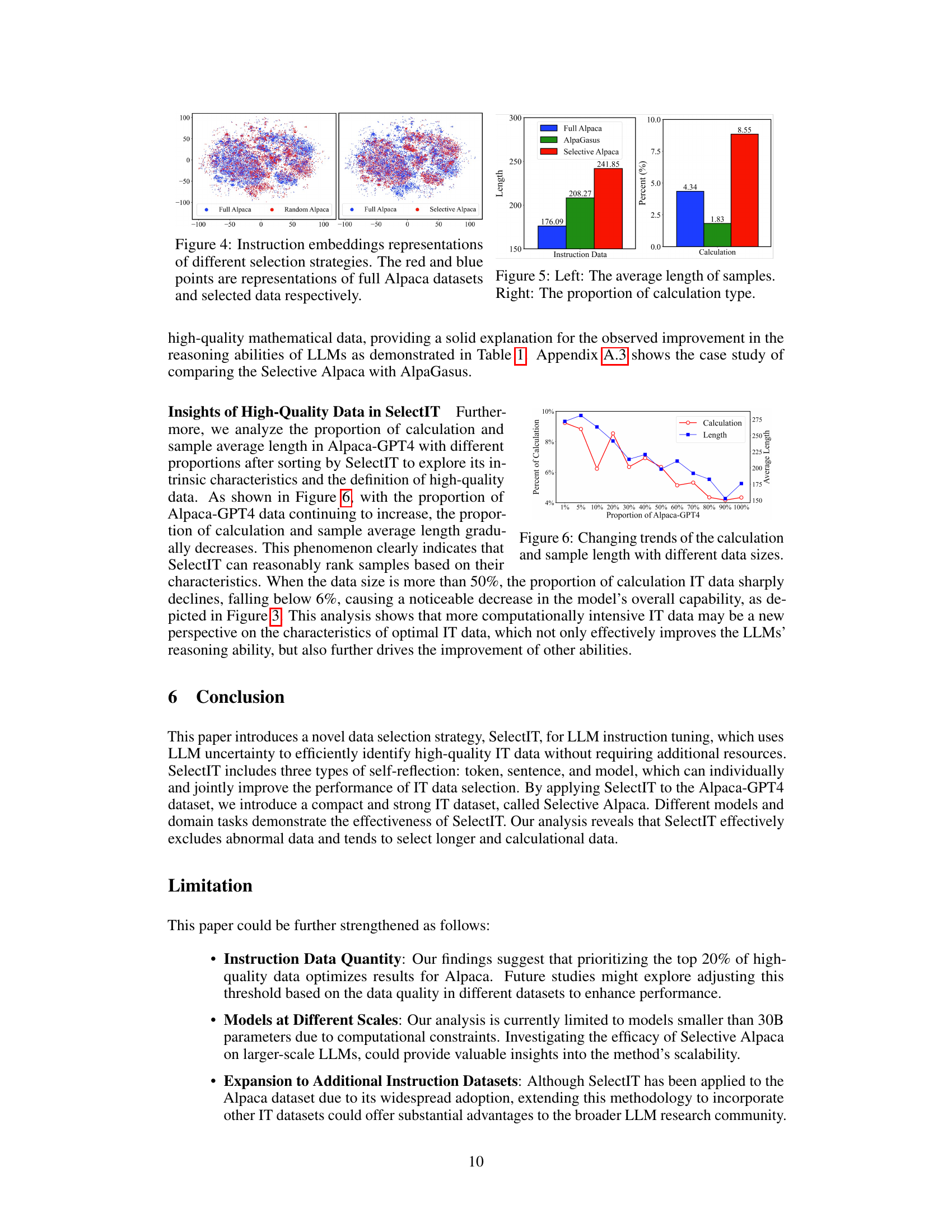
This figure shows two bar charts comparing the characteristics of instructions in three datasets: Full Alpaca, AlpaGasus, and Selective Alpaca. The left chart displays the average length of instructions in each dataset, showing that Selective Alpaca has the longest average instruction length (241.85), followed by AlpaGasus (208.27), and Full Alpaca (176.09). The right chart shows the percentage of instructions that involve calculations in each dataset. Selective Alpaca has the highest percentage (8.55%), indicating a higher proportion of computationally intensive instructions compared to AlpaGasus (1.83%) and Full Alpaca (4.34%). This suggests that SelectIT preferentially selects instructions with a higher computational complexity.
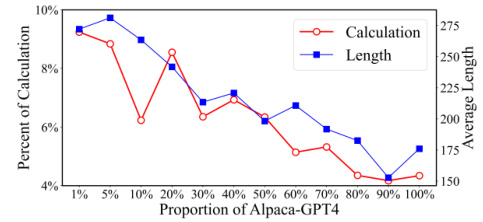
This figure shows the trends of the proportion of calculation and the average length of samples in Alpaca-GPT4 dataset with different proportions after sorting by SelectIT. It illustrates how these characteristics change as more data is included. The key observation is that as the proportion of Alpaca-GPT4 data increases beyond 50%, the proportion of calculation-based instruction tuning data drops significantly (below 6%), leading to a noticeable decline in the overall capabilities of the LLMs. This suggests that longer, more computationally intensive instruction tuning data might be more effective for improving LLMs’ abilities.

This figure illustrates the overall framework of the SelectIT method, which leverages the uncertainty inherent in LLMs at three levels: token, sentence, and model. Each level contributes to a score for each piece of instruction tuning (IT) data, ultimately leading to a ranked list of data suitable for fine-tuning. This process eliminates the need for additional models or data.
More on tables

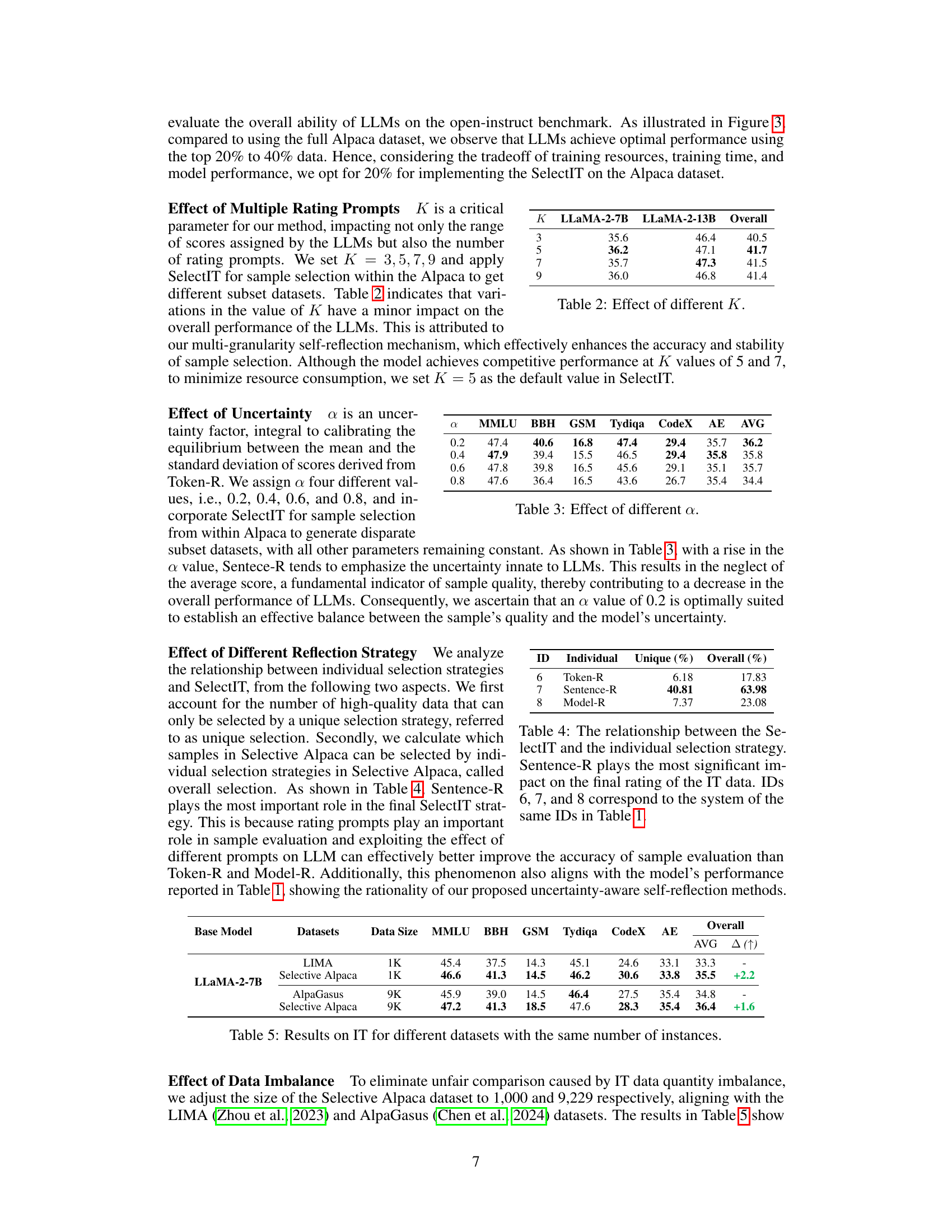
This table shows the overall performance of LLMs on the open-instruct benchmark with different values of K (number of rating prompts). The results are averages across three independent runs with different random seeds. The table helps determine the optimal value of K by showing how variations in the parameter impact the performance of LLMs.

This table presents the results of experiments conducted to determine the optimal value of the uncertainty factor (α) used in the SelectIT method. Different values of α were tested (0.2, 0.4, 0.6, 0.8), and the resulting performance of LLMs on various benchmarks (MMLU, BBH, GSM, Tydiqa, CodeX, AE) is shown. The average performance across all benchmarks is also reported. This allows for the evaluation of how α influences the balance between the mean and standard deviation of scores from Token-R, thereby affecting the overall quality assessment of IT data. The results help in determining the optimal value for α which gives the best balance for high-quality IT data selection.
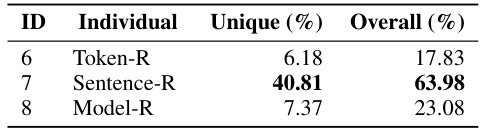
This table shows the contribution of each submodule (Token-R, Sentence-R, Model-R) of SelectIT to the final data selection. It highlights the percentage of samples uniquely selected by each method and the overall percentage of samples selected by each method in the final set of high-quality data from Selective Alpaca. Sentence-R is clearly the most influential component.

This table presents the overall performance comparison of different instruction tuning methods on two LLaMA-2 base models (7B and 13B parameters). It compares the performance using the original Alpaca dataset with several high-quality data selection methods (AlpaGasus, Q2Q, Instruction Mining) and the proposed SelectIT method (using individual components Token-R, Sentence-R, Model-R and all three combined). The evaluation is performed across multiple benchmarks assessing various LLM capabilities: MMLU (factual knowledge), BBH and GSM (reasoning), TyDiQA (multilingual), HumanEval (CodeX - coding), and AlpacaEval (AE - open-ended generation). The results show the average score across three independent runs and highlight the improvement achieved by SelectIT compared to baselines and individual components.
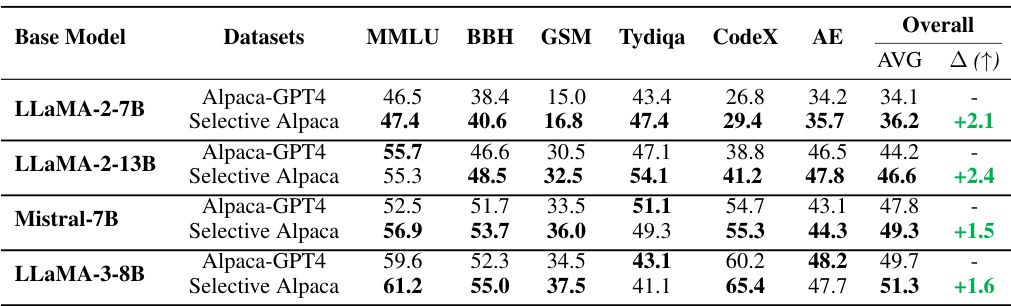
This table presents the overall performance of different models and methods on various instruction tuning benchmarks. It compares the performance of the base Llama-2 models (7B and 13B parameters) with various instruction tuning methods, including Alpaca-GPT4, LIMA, AlpaGasus, Q2Q, Instruction Mining, and the proposed SelectIT method, across different evaluation metrics such as MMLU, BBH, GSM, TydiQA, CodeX (HumanEval), and AE (AlpacaEval). The table showcases the average scores across three independent runs, demonstrating the effectiveness of each method in improving the LLM’s performance.

This table presents the results of instruction tuning (IT) experiments conducted on various instruction tuning datasets. It compares the performance of LLMs fine-tuned with the original datasets (WizardLM and Orca-GPT4) against the performance of LLMs fine-tuned with datasets curated using the SelectIT method. The table includes performance metrics across multiple benchmarks (MMLU, BBH, GSM, Tydiqa, Codex, and AE), the size of each dataset, and the overall average performance improvement achieved by SelectIT. The results show that SelectIT consistently improves performance across various datasets and benchmarks.
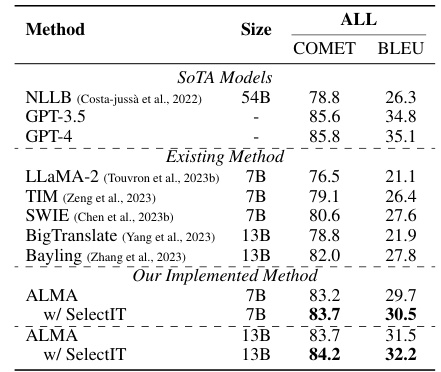
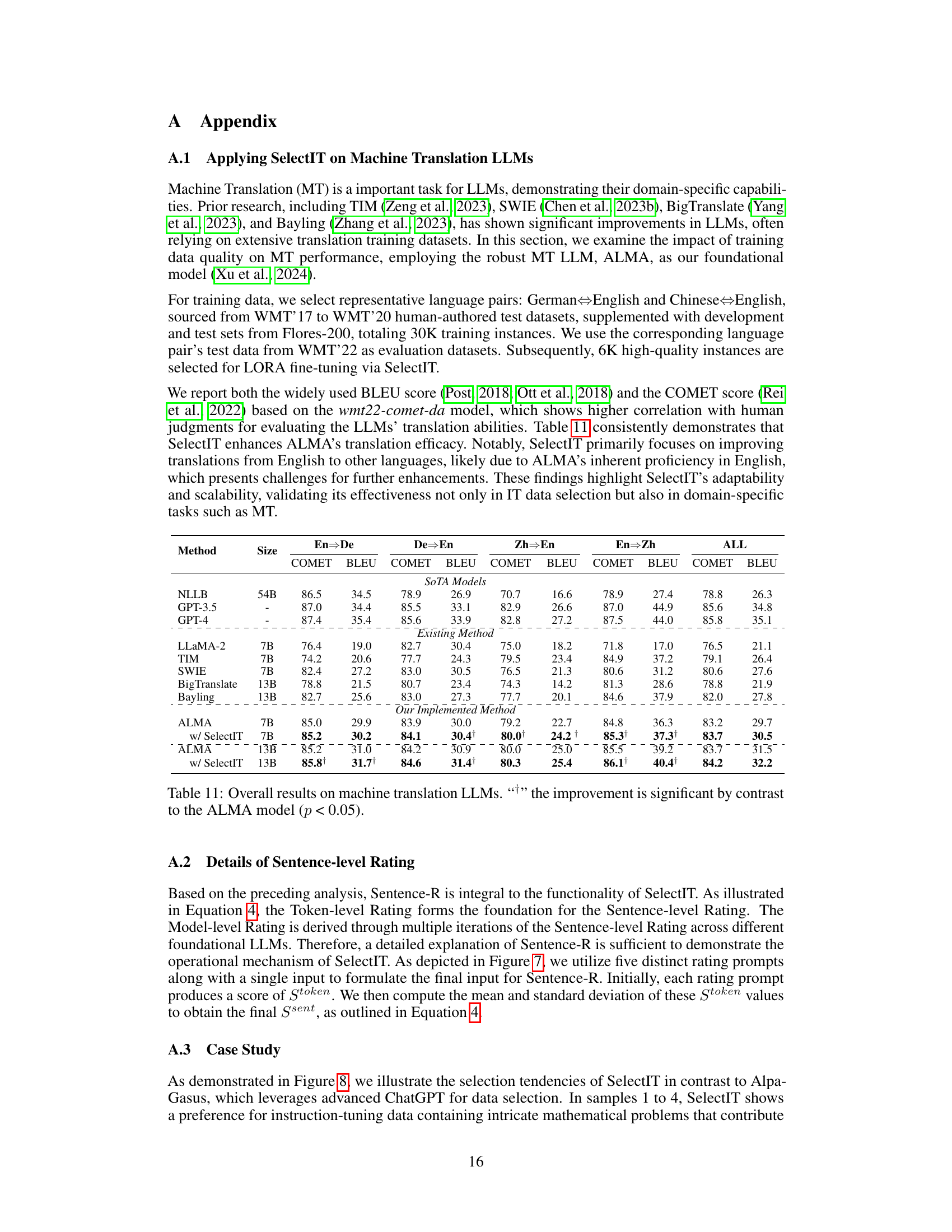
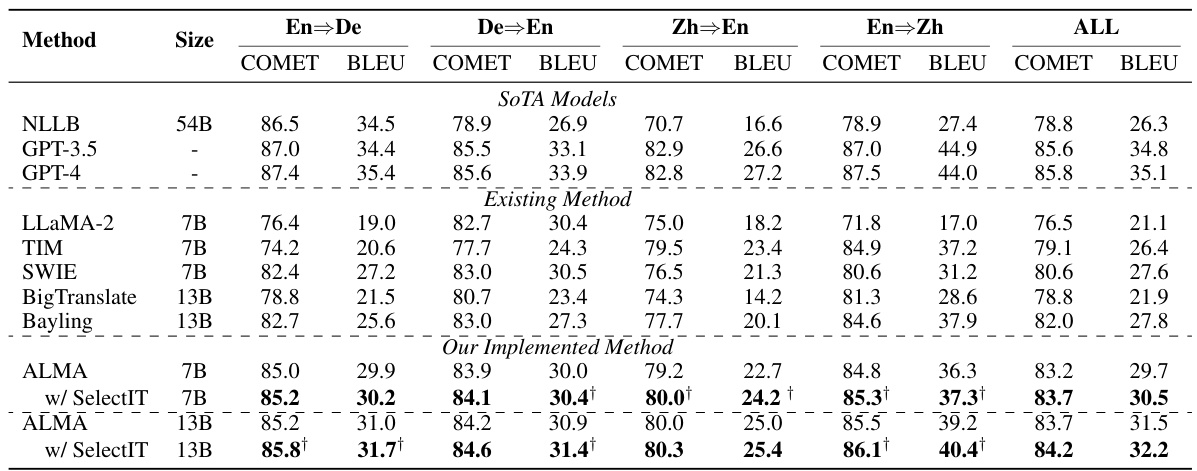
This table compares the performance of various machine translation (MT) large language models (LLMs) on the task of translating between four language pairs: English to German, German to English, English to Chinese, and Chinese to English. The models are evaluated using two metrics: COMET and BLEU scores. The table includes state-of-the-art (SOTA) models as baselines and several existing methods. The key focus is on showing how the ALMA model, when enhanced with the SelectIT method for data selection, outperforms other models, especially in the COMET scores.
This table presents the overall performance of different instruction tuning methods on various downstream tasks. It compares the baseline performance of LLaMA-2 models (7B and 13B parameters) with instruction tuning using Alpaca-GPT4, LIMA, AlpaGasus, Q2Q, Instruction Mining, and the proposed SelectIT method. The evaluation metrics include MMLU, BBH, GSM, TyDiQA, HumanEval (CodeX), and AlpacaEval (AE), which cover factual knowledge, reasoning, multilinguality, and code generation. The table shows that SelectIT outperforms existing methods, yielding significant improvements across all benchmarks. Results are averages from three independent runs for robustness.
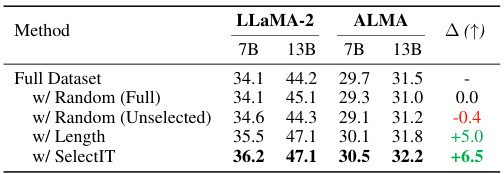
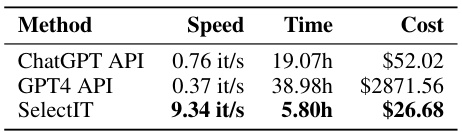
This table compares the performance of LLMs (LLaMA-2 and ALMA) trained with different data selection strategies. The ‘Full Dataset’ row shows the baseline performance using the complete Alpaca dataset. The other rows show the performance when using only a subset of the data selected by different methods: randomly selecting 20% of the full dataset, randomly selecting 20% of the unselected data (i.e., the data not selected by SelectIT), selecting 20% of the data based on sample length, and finally, using the data selected by SelectIT. The Δ column shows the improvement in performance compared to the baseline (Full Dataset). The results indicate that SelectIT significantly outperforms the other methods.
This table presents the overall performance comparison of different instruction tuning methods on various benchmarks including MMLU, BBH, GSM, TyDiQA, CodeX, and AE. It shows the average scores across three independent runs using different random seeds, allowing for a statistically robust evaluation of each method. The table distinguishes between baseline models (LLaMA-2 7B and 13B), existing methods (Alpaca-GPT4, LIMA, AlpaGasus, Q2Q, Instruction Mining), and the proposed SelectIT method, with and without its individual components (Token-R, Sentence-R, Model-R). The results highlight SelectIT’s superior performance compared to existing methods.

This table presents the overall performance of different instruction tuning methods on various downstream tasks. It compares the baseline LLaMA-2 models (7B and 13B parameters) with several existing instruction tuning data selection methods (Alpaca-GPT4, LIMA, AlpaGasus, Q2Q, Instruction Mining) and the proposed SelectIT method, both individually (Token-R, Sentence-R, Model-R) and combined. The evaluation metrics include performance on MMLU, BBH, GSM, TyDiQA, HumanEval (CodeX), and AlpacaEval (AE) benchmarks. The scores represent the average of three independent runs, using different random seeds, highlighting the robustness of the findings. SelectIT demonstrates consistent improvement across all benchmarks, particularly in the combined model.

This table presents the overall results of instruction tuning (IT) experiments using different methods and baselines on various benchmarks. The benchmarks cover different aspects of LLM abilities, including factual knowledge (MMLU), reasoning (BBH and GSM), multilingual capabilities (TyDiQA), and coding proficiency (CodeX). Alpaca-GPT4, LIMA, AlpaGasus, Q2Q and Instruction mining are also shown for comparison. The results are the average scores across three runs, demonstrating the performance improvement achieved by the proposed SelectIT method on LLAMA-2 (7B and 13B).

This table presents the overall results of different machine translation models on various metrics such as COMET and BLEU scores. It compares the performance of several state-of-the-art models against ALMA, both with and without SelectIT. The table highlights the significant improvement achieved by ALMA when using the SelectIT method for data selection, particularly for the English-to-other language translation tasks.

This table presents the overall results of instruction tuning (IT) experiments using different methods on two base models, LLaMA-2-7B and LLaMA-2-13B. It compares the performance of several methods for selecting high-quality instruction data, including existing methods like Alpaca-GPT4, LIMA, AlpaGasus, Q2Q, and Instruction Mining, and the proposed SelectIT method. The evaluation is conducted across multiple benchmarks: MMLU (Massive Multitask Language Understanding), BBH (Big-Bench-Hard), GSM (Grade School Math), TyDiQA (multilingual question answering), CodeX (HumanEval coding), and AE (AlpacaEval). The table shows the average score across three independent runs for each method and benchmark, allowing for a comparison of the effectiveness of different data selection techniques in improving the performance of LLMs on various tasks.

This table presents the overall performance comparison of different instruction tuning methods on various benchmark tasks using LLAMA-2-7B and LLAMA-2-13B as base models. It compares the baseline performance of Alpaca-GPT4, LIMA, and other existing data selection methods with the proposed SelectIT approach. The results are broken down by benchmark (MMLU, BBH, GSM, TydiQA, CodeX, AE), showing the average scores across three independent runs for each method. This allows for a comprehensive comparison of the effectiveness of the different approaches to instruction tuning.

This table presents the overall results of instruction tuning (IT) experiments on various LLMs using different datasets and methods. It compares the performance of LLMs on multiple benchmark tasks, including factual knowledge (MMLU), reasoning (BBH, GSM), multilingual question answering (TyDiQA), coding (CodeX), and open-ended generation (AlpacaEval). The table shows the average performance scores across three independent runs, with various data selection methods compared against baselines.
Full paper#