↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current LM-based recommenders rely on language modeling losses, which are suboptimal for ranking tasks. They often use a single positive item and ignore valuable negative feedback. This limitation hinders their ability to accurately model user preferences, impacting recommendation quality. Existing DPO methods are limited by only handling pairwise comparisons.
This paper proposes Softmax-DPO, a novel loss function designed for LM-based recommenders. Softmax-DPO incorporates multiple negative items and extends the traditional Plackett-Luce model to handle partial rankings. The authors theoretically link Softmax-DPO to the softmax loss, showcasing its effectiveness in mining hard negatives and providing better ranking gradients. Empirical results across three real-world datasets show that Softmax-DPO outperforms state-of-the-art methods, showcasing its capability in modeling user preferences and boosting recommendation performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with language models for recommendation. It challenges the prevailing paradigm of using language modeling losses, highlighting their inadequacy for ranking tasks. The proposed Softmax-DPO loss provides a superior alternative, opening new avenues for improving recommendation accuracy and enhancing user experience. The theoretical analysis and empirical results offer valuable insights for advancing LM-based recommenders, a rapidly growing field.
Visual Insights#
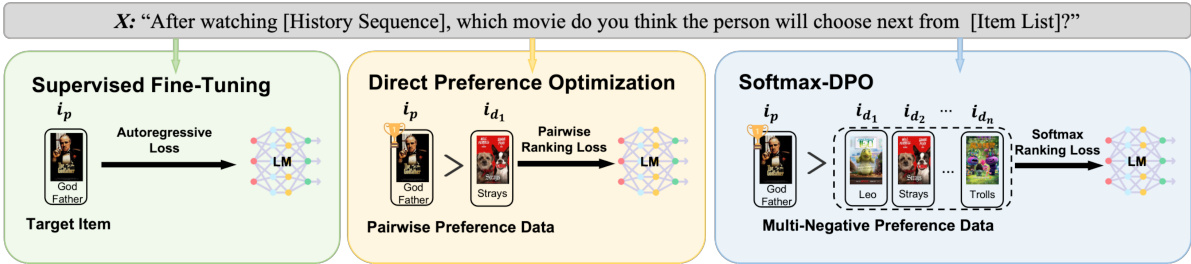
This figure illustrates the framework of the proposed Softmax-DPO (S-DPO) method and contrasts it with existing LM-based recommendation approaches. It shows three stages: Supervised Fine-Tuning, Direct Preference Optimization, and Softmax-DPO. The first stage uses autoregressive loss to fine-tune the language model (LM). The second stage utilizes pairwise ranking loss with pairwise preference data. The final stage, S-DPO, incorporates multiple negatives into the preference data and leverages softmax ranking loss for enhanced performance in distinguishing preferred items from negative ones. It highlights the evolution of the method from language modeling to a direct preference optimization approach.
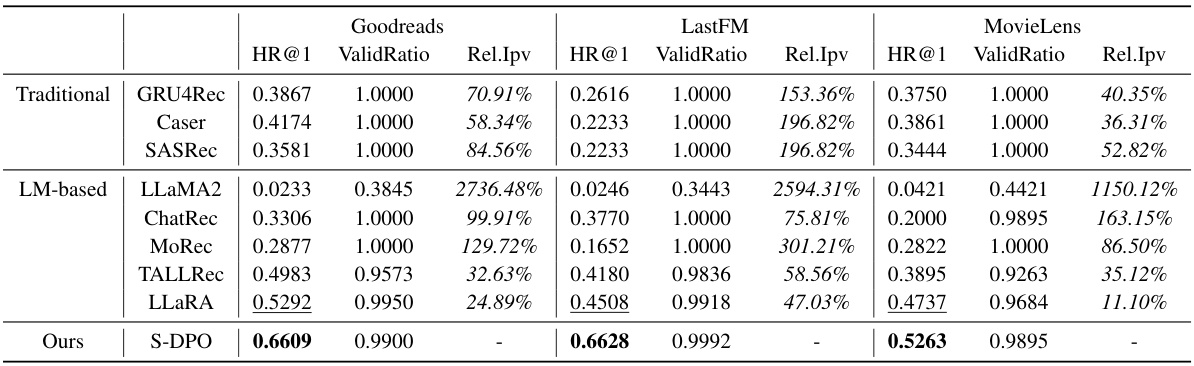
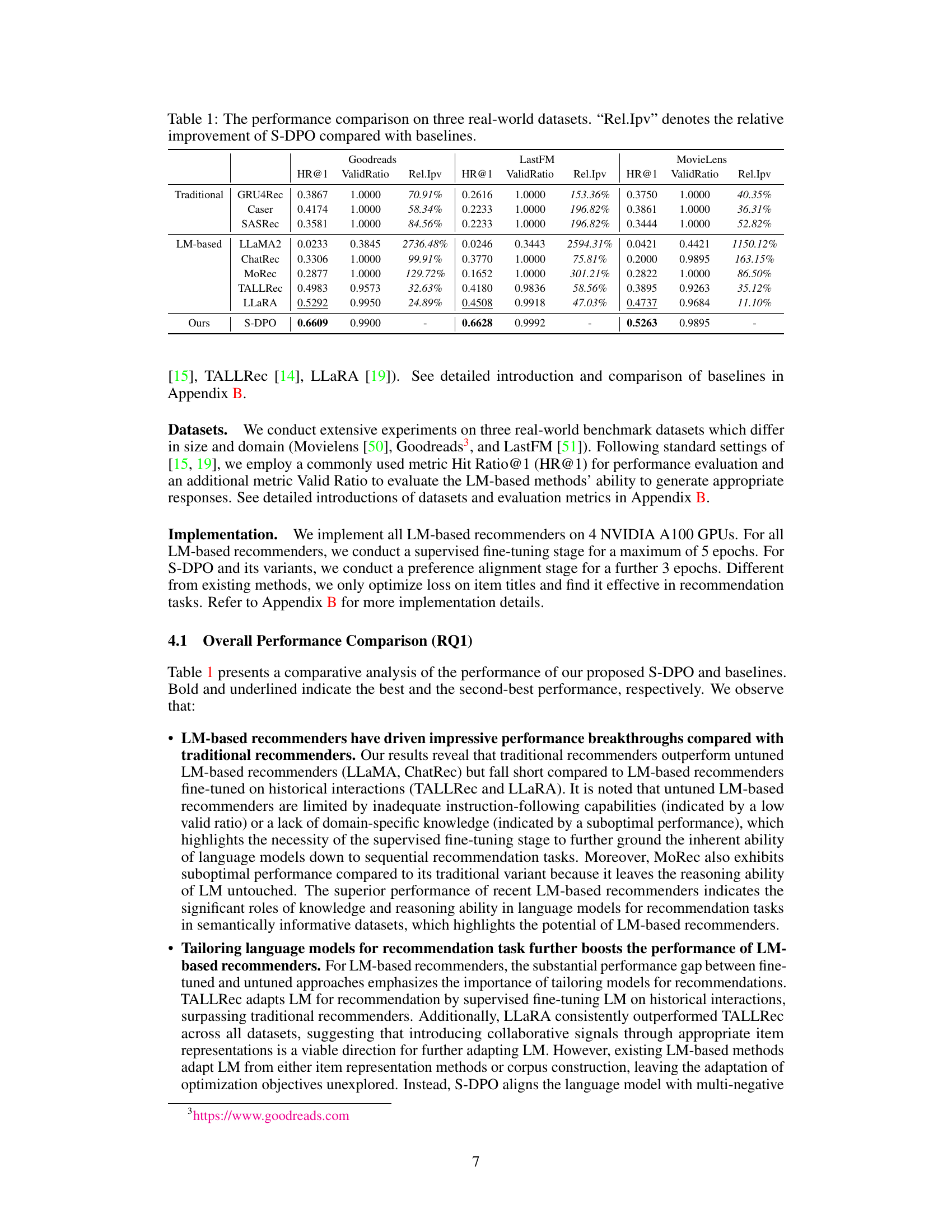
This table presents a comparison of the performance of S-DPO against various baseline models across three real-world datasets (Goodreads, LastFM, and MovieLens). The metrics used are Hit Ratio@1 (HR@1), which measures the accuracy of recommending the correct item as the top choice, and ValidRatio, representing the percentage of correctly generated responses. Rel.Ipv shows the relative improvement of S-DPO over each baseline model. The table highlights S-DPO’s superior performance compared to traditional methods (GRU4Rec, Caser, SASRec), LM-based models (LLaMA2, ChatRec, MoRec), and other LM-enhanced models (TALLRec, LLARA).
In-depth insights#
Softmax-DPO Intro#
An introductory section titled “Softmax-DPO Intro” would ideally set the stage for a novel approach to preference optimization in recommendation systems. It should highlight the limitations of existing LM-based recommenders, which often rely on language modeling losses that fail to fully capture user preferences and ranking signals. The introduction would then position Softmax-DPO as a solution, emphasizing its use of softmax loss and multiple negatives to better model preference data and handle the inherent complexity of ranking tasks. It could mention the connection to Direct Preference Optimization (DPO) but stress the key innovation of integrating softmax, potentially detailing how this improved loss function encourages the model to learn more discriminative rankings, facilitating better item differentiation and reward assignment for preferred items. The section should conclude by briefly outlining the structure of the subsequent parts of the paper, indicating what will be shown theoretically and empirically to support the efficacy of the Softmax-DPO method.
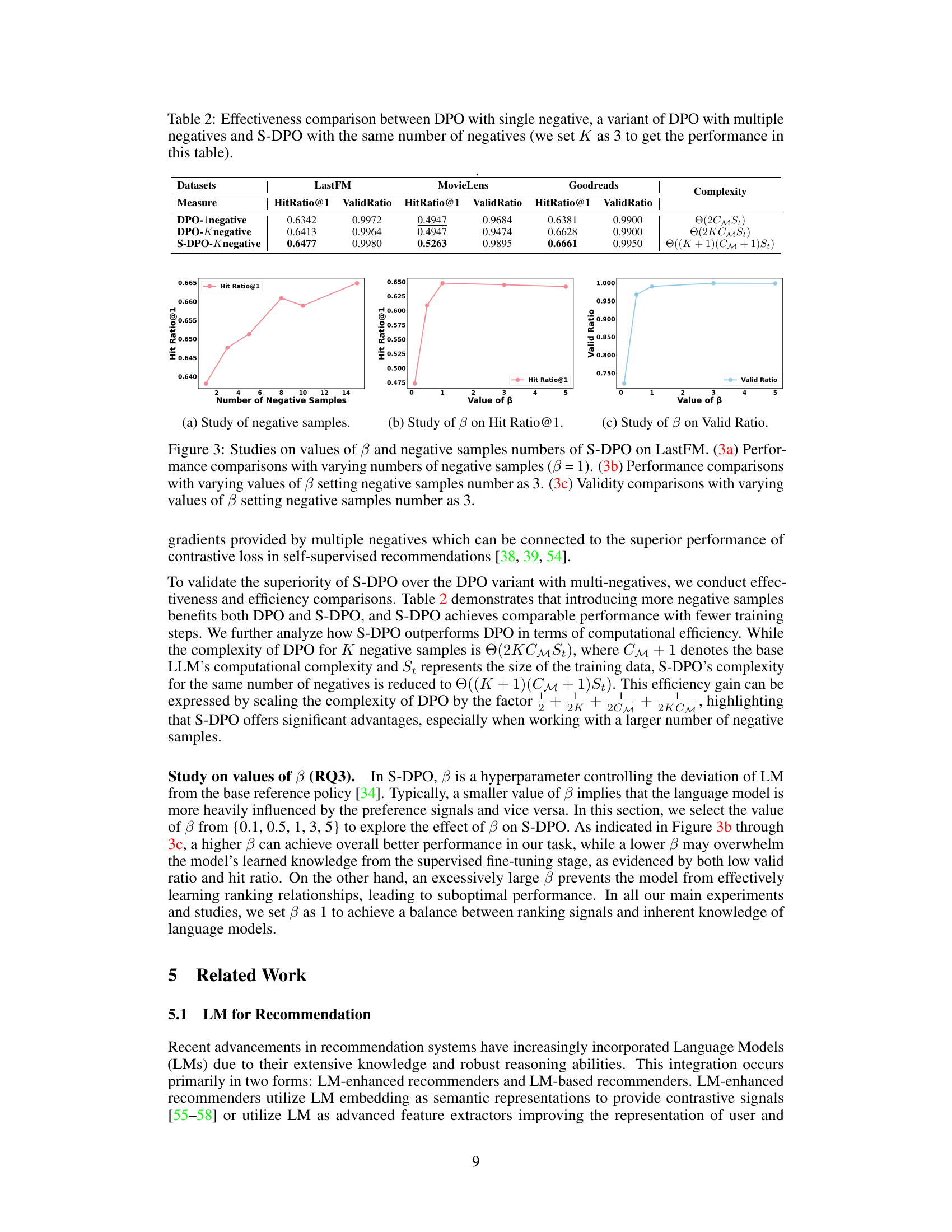
Multi-Negative DPO#
The concept of “Multi-Negative DPO” suggests an extension of Direct Preference Optimization (DPO) to handle multiple negative examples simultaneously, rather than just one. This is a significant advancement because in many real-world scenarios, particularly recommendation systems, a user’s preference isn’t solely defined by what they liked, but also by what they didn’t like. Traditional DPO, limited to a single negative comparison per positive example, overlooks this rich source of information. By incorporating multiple negatives, Multi-Negative DPO can better capture the nuances of user preferences and lead to more accurate ranking models. This approach leverages the power of contrastive learning, allowing the model to learn more effectively by distinguishing between preferred and non-preferred items. The theoretical and empirical results suggest Multi-Negative DPO may achieve superior performance compared to traditional DPO and other ranking methods due to its increased ability to identify and weigh ‘hard’ negative examples, effectively improving gradient quality and reward allocation for preferred items. A key challenge would be managing the computational cost associated with handling multiple negatives, particularly with large datasets. However, the potential benefits in terms of ranking accuracy and enhanced understanding of user preferences appear significant enough to warrant the additional computational resources.
S-DPO Properties#
The heading ‘S-DPO Properties’ suggests a discussion of the key characteristics and advantages of the proposed Softmax-Direct Preference Optimization (S-DPO) method. A thoughtful analysis would likely explore several crucial aspects. Firstly, it should delve into the theoretical connections between S-DPO and existing methods like Bayesian Personalized Ranking (BPR) and softmax loss, highlighting how S-DPO leverages the strengths of these approaches while addressing their limitations. This would involve examining the mathematical relationships and showing how S-DPO’s formulation incorporates multiple negatives, leading to improved gradient estimations and better handling of hard negative samples. Secondly, the analysis should highlight the empirical advantages of S-DPO, such as its ability to effectively model user preferences, provide better rewards for preferred items, and achieve superior ranking performance compared to baselines. The convergence behavior, and the computational efficiency of S-DPO relative to other methods should also be discussed. Finally, the discussion should explain how the inherent properties of S-DPO such as hard negative mining contribute to its superior performance in recommendation tasks.
Experiment Results#
The experiment results section of a research paper is critical for validating the claims made in the introduction and methodology. A strong results section will clearly present the key findings, using tables and figures to visually represent the data effectively. Statistical significance should be explicitly stated, indicating whether observed differences are likely due to chance or represent a true effect. Error bars should be included to provide a sense of the variability and reliability of the measurements. The discussion of the results should go beyond simply stating the findings. A thoughtful analysis comparing the performance of different methods or models and explaining any unexpected results is crucial. The authors should connect the results back to the hypotheses or research questions posed earlier, and discuss the implications of their findings in the broader context of the field. A lack of clarity or detail in the presentation of the results significantly weakens the paper’s overall contribution and credibility. Attention to detail, including proper labeling of axes, clear captions, and a logical flow of information, is critical for a strong and convincing results section.
Future of S-DPO#
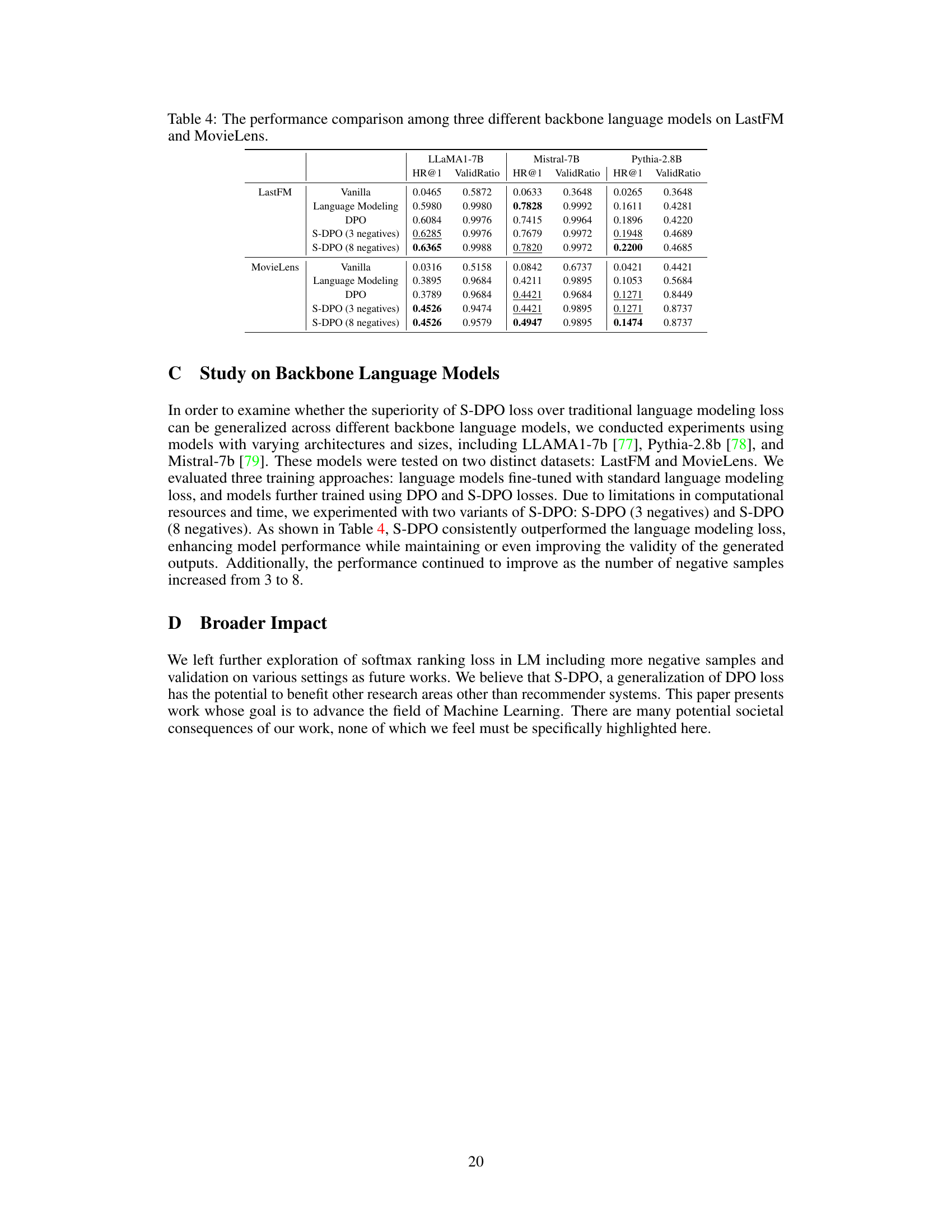
The future of Softmax Direct Preference Optimization (S-DPO) looks promising, given its demonstrated ability to effectively leverage multiple negative samples and enhance LM-based recommender performance. Further research could explore the optimal number of negative samples, balancing the gains in performance against computational costs. Investigating alternative negative sampling strategies beyond random sampling, such as those that prioritize hard negatives, could further improve efficiency and effectiveness. Adapting S-DPO for various recommendation scenarios, including those with diverse data formats or user interaction types, is crucial. Theoretical analysis to solidify the connection between S-DPO and other loss functions, like contrastive loss, could lead to novel insights and further advancements. Finally, exploring the use of S-DPO in conjunction with other LM-based techniques like reinforcement learning, could unlock synergistic effects and create even more sophisticated recommendation systems.
More visual insights#
More on figures

This figure presents a comprehensive analysis of the proposed S-DPO method. Subfigure (a) shows an ablation study comparing S-DPO’s performance against the standard supervised fine-tuning (SFT) and the original DPO method across three datasets (LastFM, Goodreads, and MovieLens). Subfigure (b) illustrates the validation loss curves for both DPO and S-DPO on the LastFM dataset, highlighting the faster convergence of S-DPO. Finally, subfigure (c) displays the reward (preference score) for the preferred item over the training steps for both methods on the LastFM dataset, demonstrating that S-DPO consistently assigns a higher reward to the preferred item.

This figure presents the results of an ablation study comparing S-DPO with supervised fine-tuning (SFT) and DPO on three different datasets, demonstrating the superior performance of S-DPO. Additionally, it shows the validation loss and reward of preferred items curves over training steps for both DPO and S-DPO on the LastFM dataset, highlighting S-DPO’s faster convergence and better rewards for preferred items.
More on tables
This table compares the performance of S-DPO against various baselines across three real-world datasets: MovieLens, Goodreads, and LastFM. For each dataset and model, it shows the Hit Ratio@1 (HR@1) and Valid Ratio. Rel.Ipv indicates the relative improvement of S-DPO compared to each baseline.

This table compares the performance of S-DPO against various baselines across three real-world datasets (Goodreads, LastFM, MovieLens). The metrics used are HR@1 (Hit Ratio at 1) and ValidRatio. Rel.Ipv represents the relative improvement of S-DPO compared to each baseline. The table showcases S-DPO’s superiority in recommendation performance across different datasets and baselines, highlighting the effectiveness of the proposed method.
Full paper#