TL;DR#
Visible-infrared person re-identification (VI-ReID) faces the challenge of significant modality differences due to the absence of color information in infrared images. Existing methods often struggle to effectively bridge this gap, resulting in suboptimal retrieval performance. This limitation hinders the development of robust and reliable VI-ReID systems for real-world applications.
To address this issue, the researchers propose a novel Text-enhanced VI-ReID framework driven by Large Foundation Models (TVI-LFM). TVI-LFM uses large language and vision-language models to automatically generate textual descriptions for infrared images, effectively enriching their representations. The framework incorporates an incremental fine-tuning strategy to align these generated texts with the original images and a modality ensemble retrieval strategy to leverage the complementary strengths of various modalities. The results demonstrate that TVI-LFM significantly improves VI-ReID performance on three expanded datasets, showcasing its effectiveness and robustness.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves visible-infrared person re-identification (VI-ReID) by leveraging large foundation models. This addresses a critical challenge in VI-ReID, the lack of color information in infrared images. The proposed framework, TVI-LFM, offers a novel approach to enhance infrared representations and improve retrieval accuracy, paving the way for more robust and efficient multi-modal retrieval systems. This work also introduces three new expanded VI-ReID datasets for future research.
Visual Insights#
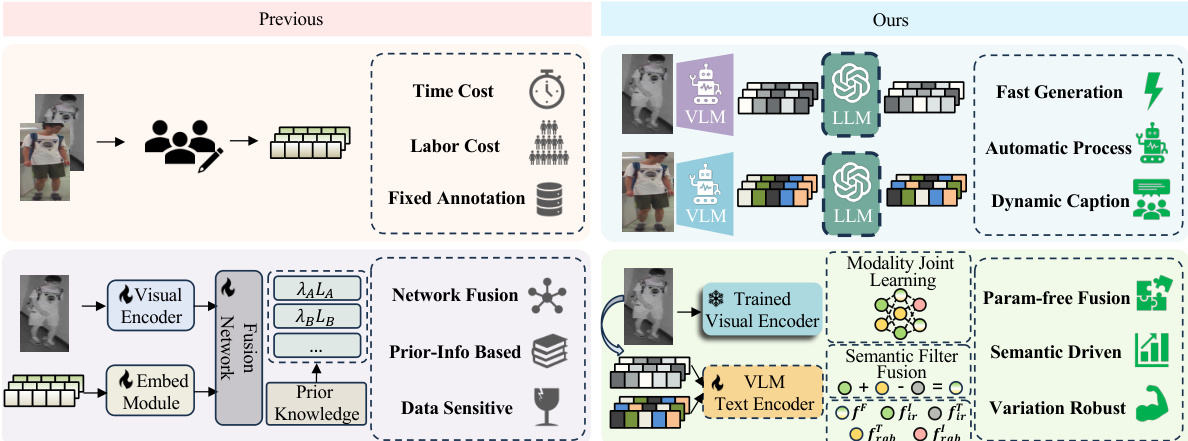
🔼 This figure compares the proposed method with existing methods for Visible-Infrared Person Re-identification (VI-ReID). Existing methods use manual annotation, complex architectures, and prior knowledge, resulting in high time and labor costs, increased parameters, and data sensitivity. The proposed method uses Vision-Language Models (VLMs) and Large Language Models (LLMs) to automatically generate dynamic text descriptions, improving robustness. It also fine-tunes a pre-trained VLM to align features across modalities, creating semantically consistent fusion features without extra parameters. The figure visually shows this difference in approach and highlights the advantages of the proposed method.
read the caption
Figure 1: Illustration of our idea. Existing methods rely on fixed manual annotation, complex architecture and prior-knowledge-based optimization to enrich infrared modality. Leading to significant time and labor cost, additional parameters and data sensitivity. In contrast, our method employs VLM and LLM to automatically generate dynamic text, improving the robustness against text variation; fine-tunes a pre-trained VLM through aligning features across all modalities, enabling the framework to create fusion features semantically consistent with visible modality in a parameter-free manner.

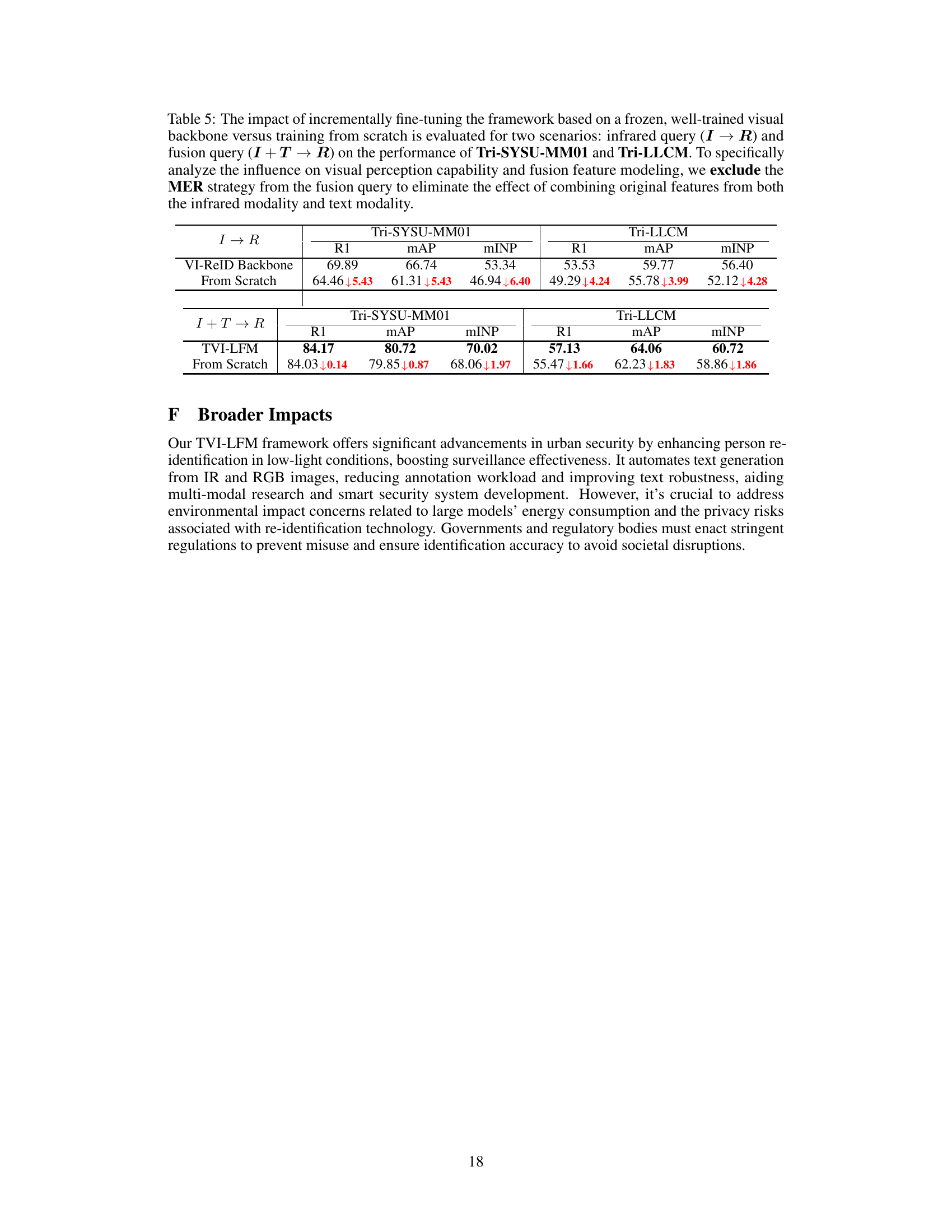
🔼 This ablation study analyzes the contribution of each component (SFF, MJL, LLM, MER) in the proposed TVI-LFM framework. It shows the impact of each component on the retrieval performance using fusion queries (combining infrared, text, and fusion features) on two datasets: Tri-SYSU-MM01 and Tri-LLCM. The results are presented as Rank-1 accuracy, mean Average Precision (mAP), and mean Inverse Negative Penalty (mINP). Each row represents a different combination of components included in the framework. The table demonstrates the incremental improvement in performance as more components are added.
read the caption
Table 1: Ablation study on fusion query (I + T → R) about each component on the performance of Tri-SYSU-MM01 and Tri-LLCM datasets. Rank (R) at first accuracy (%), mAP(%), and mINP(%) are reported.
In-depth insights#
VI-ReID Challenges#
Visible-Infrared Person Re-identification (VI-ReID) presents unique challenges stemming from the inherent differences between visible and infrared modalities. Significant modality discrepancies, such as the lack of color information in infrared images, make it difficult to establish consistent feature representations across modalities. Variations in imaging conditions (lighting, viewpoint, etc.) further exacerbate these issues, impacting feature extraction and matching. Domain adaptation becomes crucial to bridge the gap between modalities. The lack of large-scale annotated datasets hinders the development and evaluation of robust VI-ReID models. Existing methods often struggle with effectively combining information from both modalities, leading to suboptimal performance. Addressing these challenges requires innovative approaches to feature representation learning, modality alignment, and the development of effective cross-modal matching strategies. Advanced techniques for handling variations in appearance and imaging conditions are needed. Finally, the creation of more extensive and comprehensively annotated datasets would significantly improve VI-ReID model development and evaluation.
Foundation Model Use#
This research leverages large foundation models (LFMs), specifically Vision-Language Models (VLMs) and Large Language Models (LLMs), to address the challenge of Visible-Infrared Person Re-identification (VI-ReID). The core idea is to enrich the feature representation of infrared images, which lack color information, by incorporating textual descriptions. A VLM generates these descriptions, and an LLM augments them for improved robustness. This approach is novel in its automation, avoiding the labor-intensive manual annotation of previous methods. The framework demonstrates significant improvements in VI-ReID performance, showcasing the effectiveness of LFMs in handling cross-modal retrieval tasks. The incremental fine-tuning strategy is key to aligning generated text features with visual modalities, ensuring semantic consistency. Furthermore, the modality ensemble retrieval method improves robustness by integrating diverse feature representations.
TVI-LFM Framework#
The TVI-LFM framework, a novel approach to Visible-Infrared Person Re-identification (VI-ReID), cleverly leverages Large Foundation Models (LFMs) to overcome the inherent challenges of cross-modal retrieval. Its core innovation lies in enriching the information-poor infrared modality with textual descriptions generated by fine-tuned Vision-Language Models (VLMs) and augmented by Language Models (LLMs). This text-enhancement strategy, implemented through the Incremental Fine-tuning Strategy (IFS) module, aligns generated texts with original images to minimize domain gaps and learn complementary features. The modality alignment capabilities of VLMs, coupled with VLM-generated filters, create a fusion modality that maintains semantic consistency between infrared and visible features. Further enhancing performance, the Modality Ensemble Retrieval (MER) strategy combines strengths of all modalities for improved robustness and retrieval effectiveness. TVI-LFM significantly improves VI-ReID results by addressing the critical issue of missing information in infrared imagery, highlighting the potential of LFMs to boost performance in challenging multi-modal tasks.
Ablation Study Results#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a research paper, “Ablation Study Results” would detail the performance of a model with and without each component. Key insights are revealed by comparing the full model’s performance against the variations. For example, if removing a specific module significantly degrades performance, it highlights the module’s importance. Conversely, a negligible impact suggests that the removed module may be redundant or less crucial. A well-designed ablation study strengthens the paper’s claims by demonstrating the necessity of each included component. The results section should clearly present these performance differences, possibly using tables or graphs to visualize the effects, enabling the readers to readily grasp the significance of each module. A robust ablation study increases a model’s trustworthiness and reproducibility.
Future Research#
The paper’s “Future Research” section could fruitfully explore improving the robustness of the model to variations in text descriptions generated by the large language model (LLM). The current reliance on LLM-generated text introduces a potential vulnerability; inconsistencies in the descriptions could negatively impact performance. Further investigation into methods for fine-tuning the VLM to minimize the domain gap between generated text and original visual modalities is warranted. This involves enhancing the alignment capabilities and refining the incremental fine-tuning strategy. Additionally, exploring alternative modalities beyond visible and infrared (e.g., depth, thermal, radar) to create richer, more robust multi-modal representations could significantly improve the framework’s accuracy. Finally, extensive comparative analysis against a broader range of state-of-the-art VI-ReID methods on larger and more diverse datasets is crucial to fully assess the model’s generalizability and scalability.
More visual insights#
More on figures

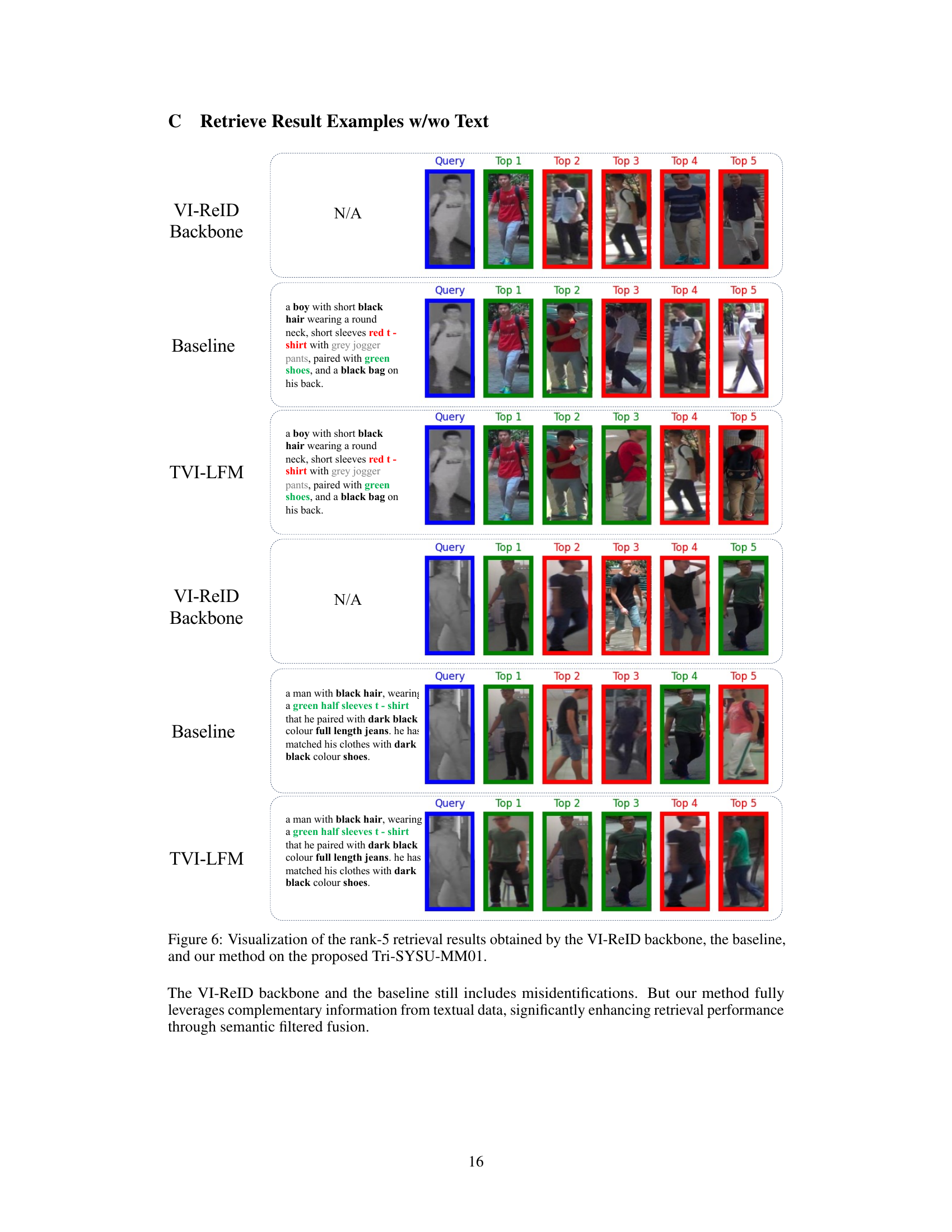
🔼 This figure illustrates the proposed TVI-LFM framework for visible-infrared person re-identification. It highlights three key modules: 1. Modality-Specific Caption (MSC): Uses fine-tuned Vision-Language Models (VLMs) to generate captions for visible and infrared images, with an additional Large Language Model (LLM) for augmentation, enriching the infrared modality with textual information. 2. Incremental Fine-tuning Strategy (IFS): Fine-tunes a pre-trained VLM to align the generated textual features with the original image features. This step creates fusion features that semantically align with visible features, leading to improved representation of infrared modality. Modality Joint Learning is also used to align the features across all modalities. 3. Modality Ensemble Retrieval (MER): Combines the strengths of all query modalities (infrared, visible, and text features) to create an ensemble query that leverages their complementary strengths, improving retrieval accuracy.
read the caption
Figure 2: Illustration of our TVI-LFM, including Modality-Specific Caption (MSC), Incremental Fine-tuning Strategy (IFS), and Modality Ensemble Retrieval (MER). MSC utilizes fine-tuned VLMs as modal-specific captioners and employs an LLM for augmentation. IFS fine-tunes a pre-trained VLM to create fusion features semantically consistent with visible features. MER leverages the strengths of all query modalities to form ensemble queries, thereby improving the retrieval performance.

🔼 This figure illustrates the Semantic Filtered Fusion (SFF) module. It shows how the module leverages the alignment between generated text features and original image features to create fusion features. By arithmetically adding textual complementary information to the infrared features, SFF generates fusion features semantically consistent with the visible modality. The examples highlight how color information, missing in the infrared, is effectively incorporated into the fusion features by using the text descriptions. This process ensures the semantic consistency between fusion and visible modalities.
read the caption
Figure 3: The Visualization of SFF. With the aligned features of generated texts and original images, SFF creates fusion features semantically consistent with visible modality by arithmetically adding the textual complementary information for infrared modality to the infrared features.

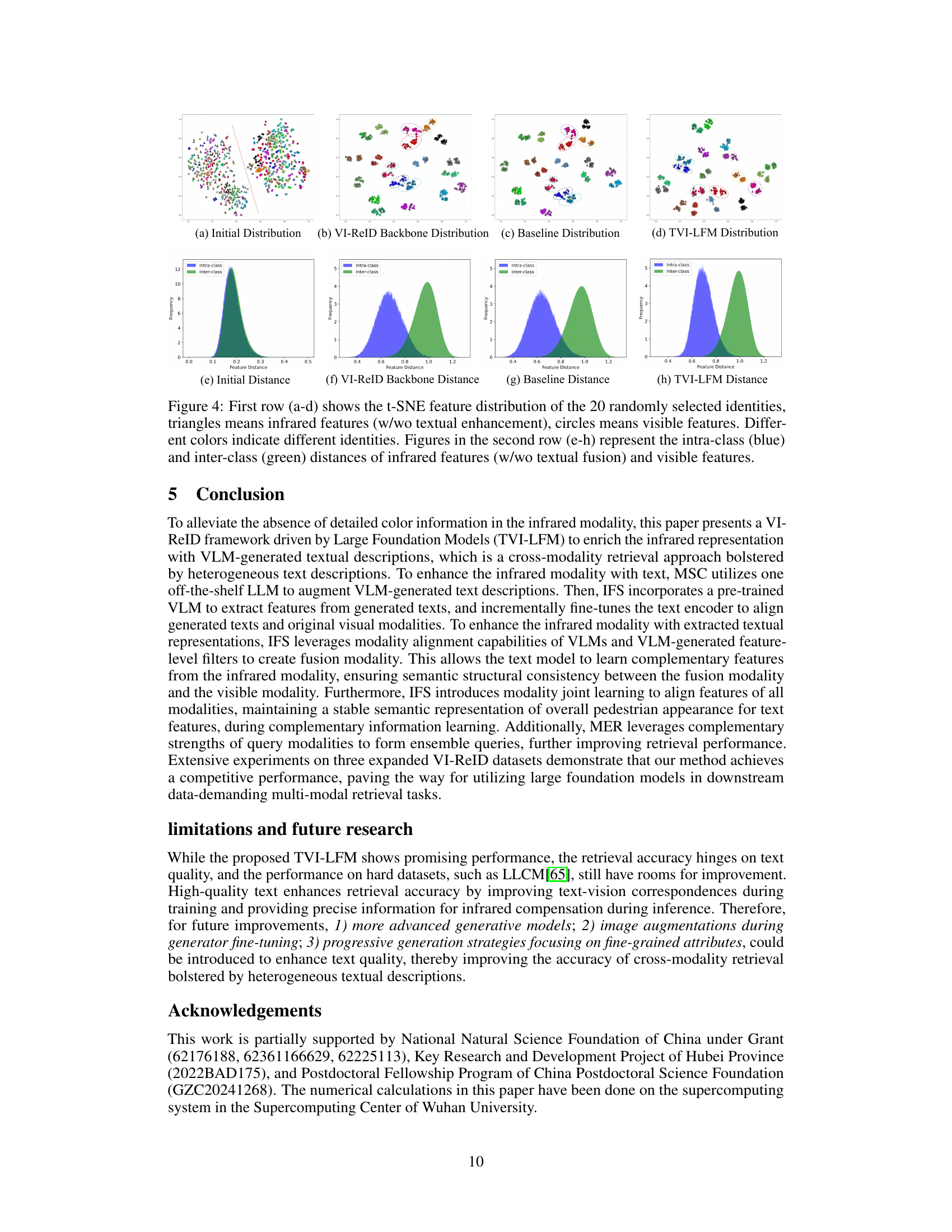
🔼 This figure visualizes the effectiveness of the proposed TVI-LFM method by comparing feature distributions using t-SNE. The top row shows t-SNE plots of feature distributions for different methods: initial features, features from a VI-ReID backbone, features from the baseline model, and features from TVI-LFM. The different colors represent different identities, triangles represent infrared features, and circles represent visible features. This helps illustrate how well the features are separated. The bottom row displays the distribution of intra-class (blue) and inter-class (green) distances for each method. The goal is to show that TVI-LFM better separates features of different identities and reduces the intra-class distance while increasing inter-class distances, indicating improved performance.
read the caption
Figure 4: First row (a-d) shows the t-SNE feature distribution of the 20 randomly selected identities, triangles means infrared features (w/wo textual enhancement), circles means visible features. Different colors indicate different identities. Figures in the second row (e-h) represent the intra-class (blue) and inter-class (green) distances of infrared features (w/wo textual fusion) and visible features.

🔼 This figure illustrates the architecture of the proposed Text-enhanced Visible-Infrared Person Re-identification framework driven by Large Foundation Models (TVI-LFM). It shows three main modules: Modality-Specific Caption (MSC), Incremental Fine-tuning Strategy (IFS), and Modality Ensemble Retrieval (MER). MSC automatically generates text captions for visible and infrared images using fine-tuned Vision-Language Models (VLMs) and augments them with a Large Language Model (LLM). IFS fine-tunes a pre-trained VLM to align generated texts with original images and creates fusion features. MER combines features from all modalities to form ensemble queries, improving retrieval performance. The figure highlights the interactions and data flow between different modules, demonstrating the overall workflow of the proposed method.
read the caption
Figure 2: Illustration of our TVI-LFM, including Modality-Specific Caption (MSC), Incremental Fine-tuning Strategy (IFS), and Modality Ensemble Retrieval (MER). MSC utilizes fine-tuned VLMs as modal-specific captioners and employs an LLM for augmentation. IFS fine-tunes a pre-trained VLM to create fusion features semantically consistent with visible features. MER leverages the strengths of all query modalities to form ensemble queries, thereby improving the retrieval performance.

🔼 This figure illustrates the proposed TVI-LFM framework, which consists of three main modules: Modality-Specific Caption (MSC), Incremental Fine-tuning Strategy (IFS), and Modality Ensemble Retrieval (MER). MSC uses fine-tuned Vision-Language Models (VLMs) to generate captions for visible and infrared images, then leverages a Large Language Model (LLM) to augment these captions. IFS incrementally fine-tunes a pre-trained VLM to align generated textual features with original image features, creating semantically consistent fusion features. Finally, MER combines features from all modalities to form an ensemble query, enhancing retrieval accuracy.
read the caption
Figure 2: Illustration of our TVI-LFM, including Modality-Specific Caption (MSC), Incremental Fine-tuning Strategy (IFS), and Modality Ensemble Retrieval (MER). MSC utilizes fine-tuned VLMs as modal-specific captioners and employs an LLM for augmentation. IFS fine-tunes a pre-trained VLM to create fusion features semantically consistent with visible features. MER leverages the strengths of all query modalities to form ensemble queries, thereby improving the retrieval performance.
More on tables
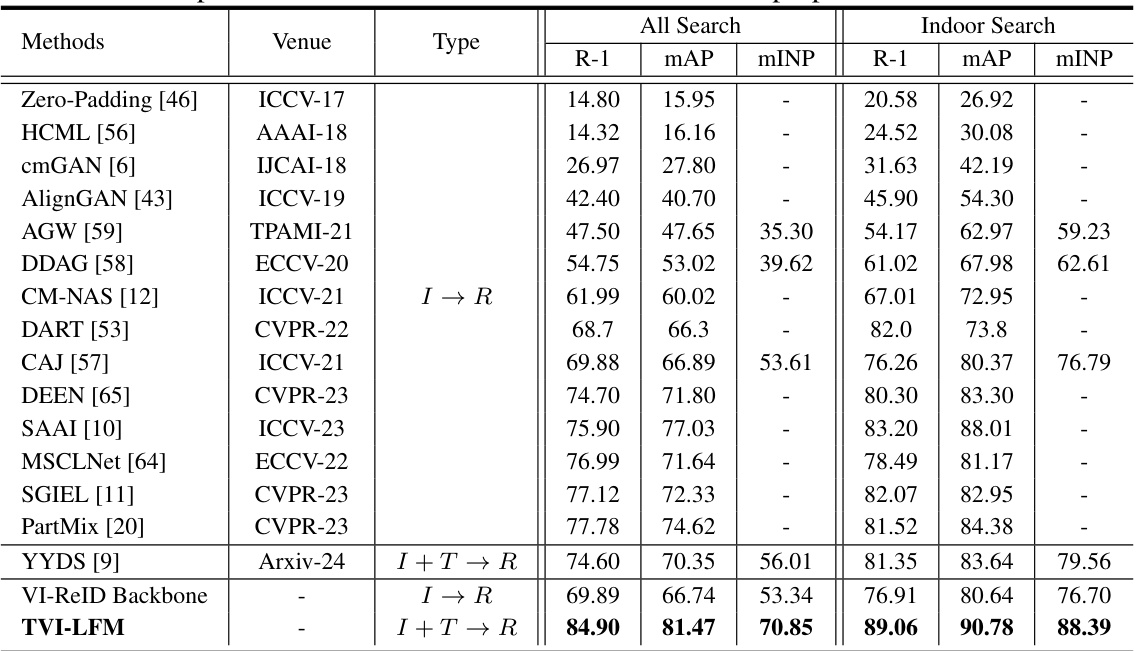
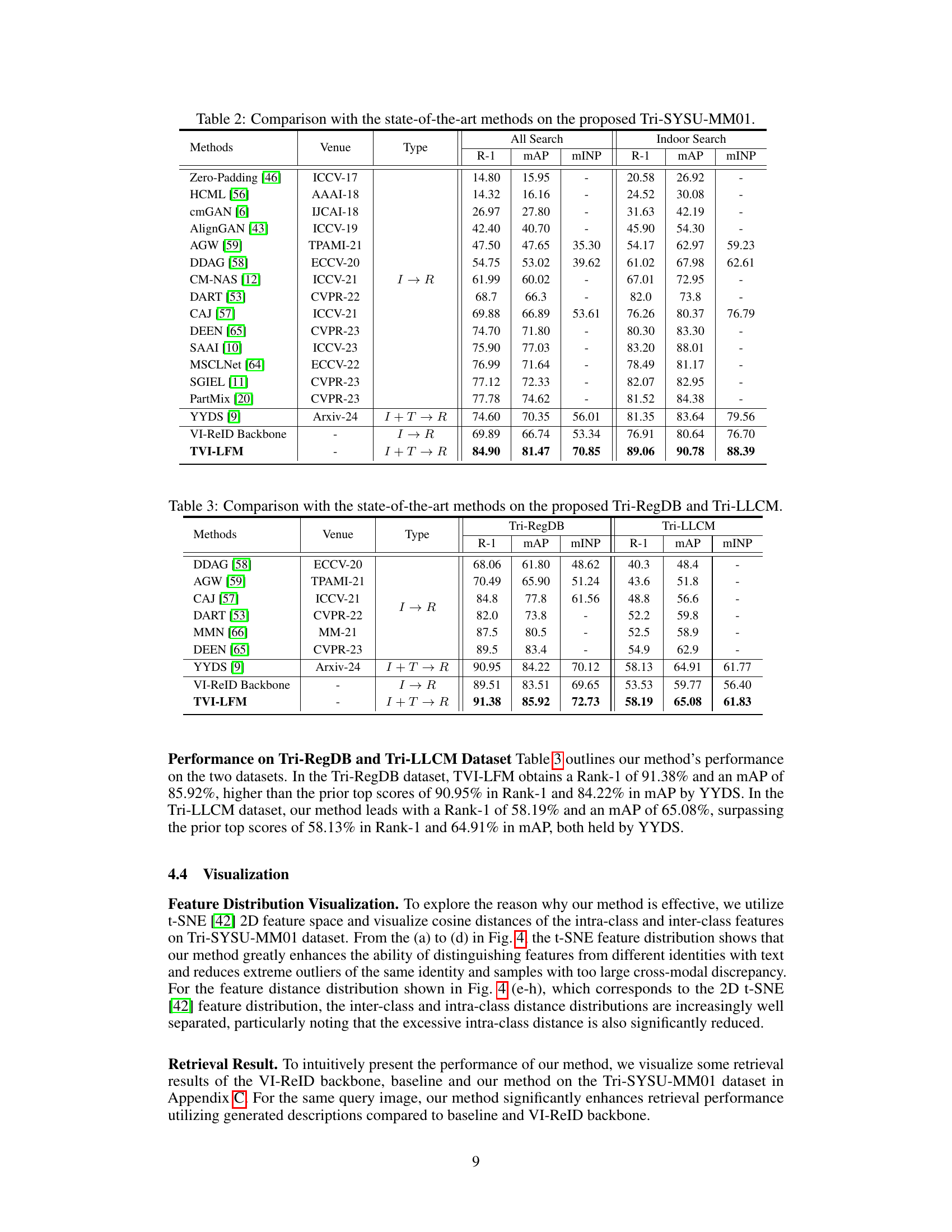
🔼 This table compares the performance of the proposed TVI-LFM method with other state-of-the-art methods on the Tri-SYSU-MM01 dataset. It shows the Rank-1 accuracy (R-1), mean Average Precision (mAP), and mean Inverse Negative Penalty (mINP) for both ‘All Search’ and ‘Indoor Search’ scenarios. The methods are categorized by their type (I → R for visible-to-infrared retrieval, and I + T → R for visible-infrared retrieval enhanced with text). The table highlights the superior performance of TVI-LFM compared to existing approaches.
read the caption
Table 2: Comparison with the state-of-the-art methods on the proposed Tri-SYSU-MM01.
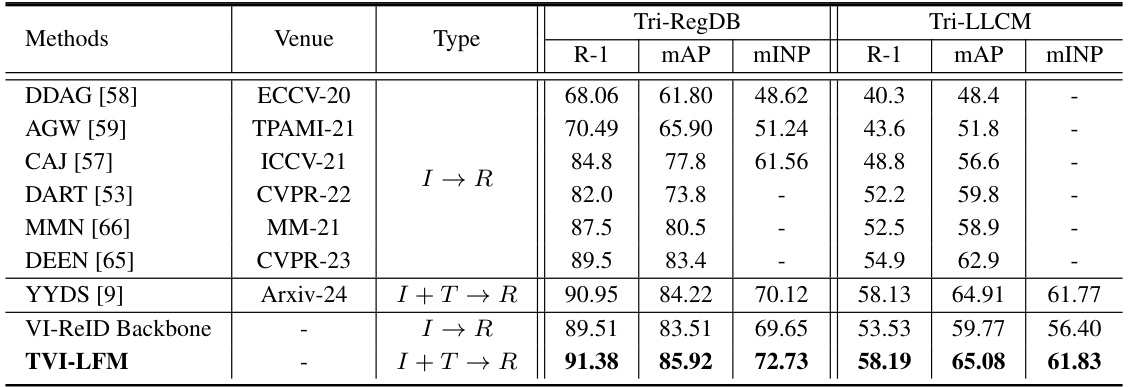
🔼 This table compares the performance of the proposed TVI-LFM model against several state-of-the-art methods on two datasets: Tri-RegDB and Tri-LLCM. The comparison is made using three metrics: Rank-1 accuracy (R-1), mean Average Precision (mAP), and mean Inverse Negative Penalty (mINP). The table shows that TVI-LFM outperforms other methods on both datasets, achieving higher values for all three metrics.
read the caption
Table 3: Comparison with the state-of-the-art methods on the proposed Tri-RegDB and Tri-LLCM.
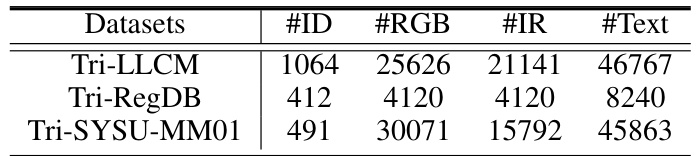
🔼 This table presents a summary of the statistics for the three expanded datasets used in the experiments: Tri-LLCM, Tri-RegDB, and Tri-SYSU-MM01. For each dataset, it shows the number of identities (#ID), RGB images (#RGB), infrared images (#IR), and generated text descriptions (#Text). These statistics provide context for understanding the scale and characteristics of the data used to evaluate the proposed model.
read the caption
Table 4: Dataset statistics
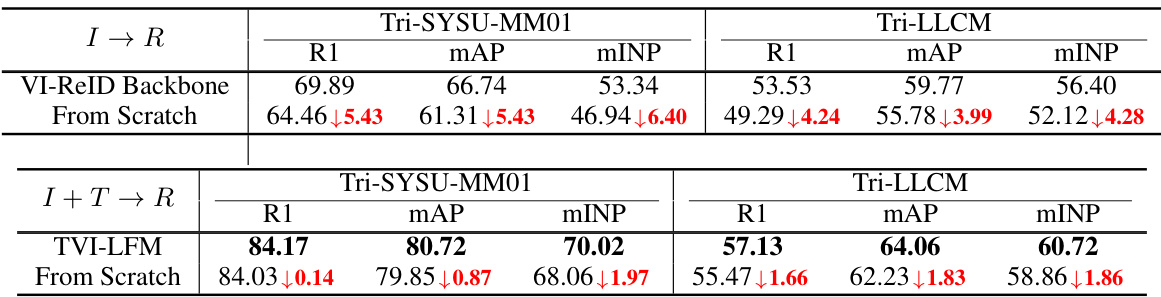
🔼 This table presents the results of an ablation study conducted to evaluate the impact of each component of the proposed TVI-LFM framework on the Tri-SYSU-MM01 and Tri-LLCM datasets. The study systematically removes each component to assess its effect on the performance metrics: Rank-1 accuracy (R1), mean Average Precision (mAP), and mean Inverse Negative Penalty (mINP). The table shows how each component (SFF, MJL, LLM, MER) contributes to the overall performance improvement of the framework.
read the caption
Table 1: Ablation study on fusion query (I + T → R) about each component on the performance of Tri-SYSU-MM01 and Tri-LLCM datasets. Rank (R) at first accuracy (%), mAP(%), and mINP(%) are reported.
Full paper#