↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Graph Neural Networks (GNNs) struggle with real-world data, which often involves complex and heterogeneous distributional shifts. Existing methods either rely on data augmentation (which might not cover all shifts) or learn invariant representations (which often overlook instance heterogeneity). These approaches struggle with unseen, real-world shifts, limiting GNNs’ practical use.
To address these issues, the authors developed GraphMETRO. This model uses a Mixture-of-Experts approach to decompose any complex distribution shift into smaller, interpretable components. Each expert model targets a specific shift to produce a referential representation, and a gating model identifies the shift components. The objective aligns representations from different expert models to ensure reliable optimization. GraphMETRO achieves state-of-the-art performance on several real-world datasets, demonstrating improved generalization capabilities and enhanced interpretability.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on graph neural networks (GNNs) and out-of-distribution (OOD) generalization. It addresses the critical challenge of GNNs’ vulnerability to real-world data shifts, providing a novel approach with state-of-the-art results. The proposed method, its interpretability, and the theoretical backing make it highly relevant to current research trends and open exciting avenues for future work in robust GNN development and OOD generalization.
Visual Insights#
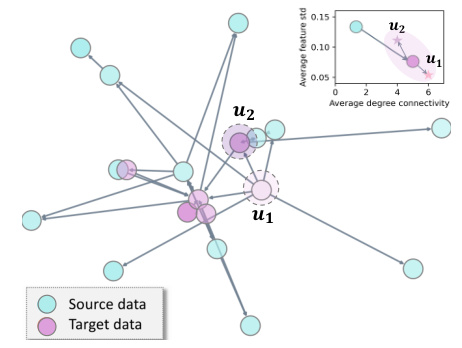
This figure shows an example of complex distributional shifts in real-world graph data, using the WebKB dataset. It highlights two aspects: a general distribution shift from the source to the target distribution, and instance-wise heterogeneity within the target distribution. Specific nodes (u1 and u2) in the target distribution exhibit different degrees of change in their features (e.g., average node degree and average feature standard deviation), illustrating the complexity and diversity of distributional shifts that can occur in real-world scenarios.
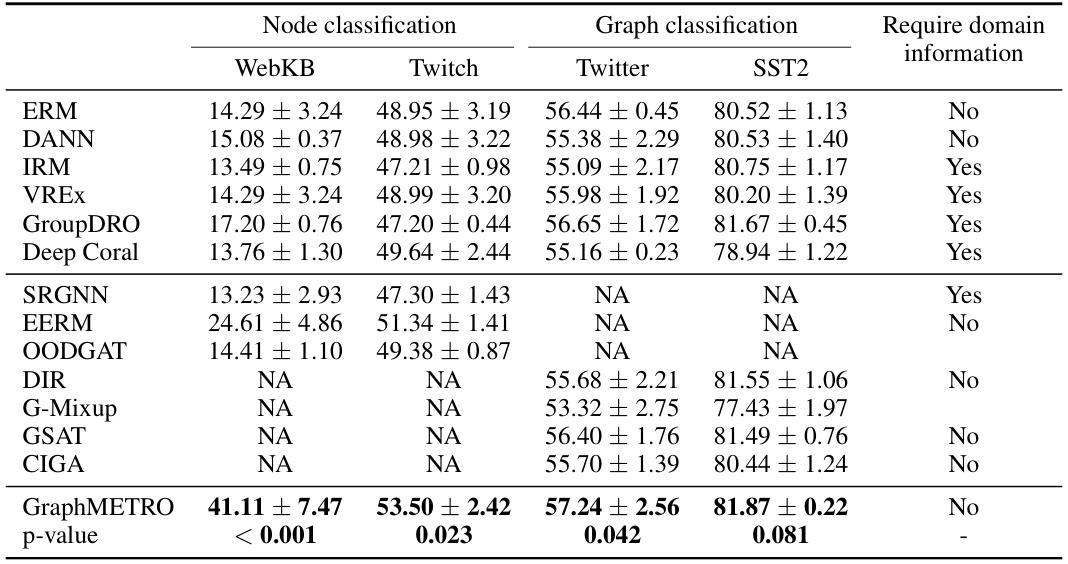
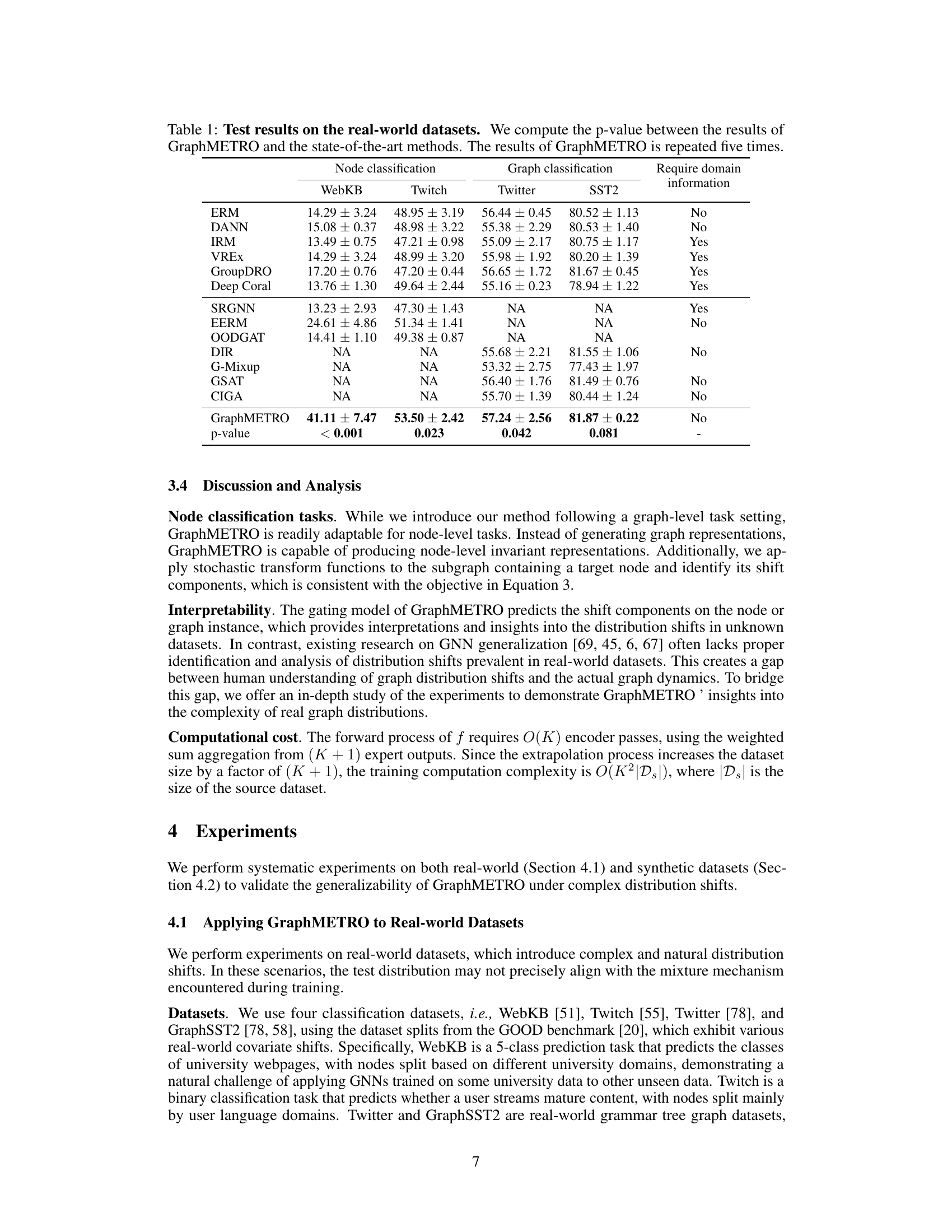
This table presents the performance comparison of GraphMETRO against several state-of-the-art methods on four real-world datasets for node and graph classification tasks. The datasets include WebKB, Twitch, Twitter, and SST2. The table shows the accuracy achieved by each method on each dataset, along with p-values indicating the statistical significance of GraphMETRO’s improvement over the baselines. GraphMETRO’s results are averaged over five independent runs.
In-depth insights#
Graph Shift Deconvolution#
The hypothetical concept of ‘Graph Shift Deconvolution’ presents a compelling direction for enhancing graph neural network (GNN) robustness. It suggests a method to decompose complex distributional shifts affecting graph data into their constituent components. By disentangling these shifts, the approach could potentially enable more effective strategies for mitigating the negative effects of data heterogeneity. This deconvolution process could involve identifying and separating variations in graph structure, node features, and edge properties, leading to more interpretable models and ultimately, improved generalization. A crucial aspect of successful deconvolution is the identification of the underlying, perhaps latent, factors driving these shifts. A key challenge would be to design algorithms that reliably accomplish this decomposition, especially for complex real-world scenarios involving multiple interacting factors. The practical implementation would require carefully selecting appropriate methods for each component of the deconvolution process, potentially benefiting from advanced techniques in causal inference or disentanglement learning. Ultimately, effective ‘Graph Shift Deconvolution’ could lead to GNNs exhibiting significantly improved robustness and generalization, paving the way for reliable performance across diverse, unpredictable graph datasets.
MoE-based Generalization#
Utilizing Mixture-of-Experts (MoE) for enhanced generalization in machine learning models, particularly within the context of handling complex graph data and distribution shifts, presents a powerful approach. The core idea is to decompose the inherent complexity of real-world graph data into manageable sub-problems, each handled by a specialized expert model. This decomposition, often guided by a gating network that determines the most relevant expert for a given data point, helps address the issue of distribution shifts. Each expert focuses on a specific aspect or type of data variation, leading to improved robustness and generalization compared to models trained on a single, unified representation. Furthermore, aligning the representations generated by different experts helps ensure a consistent and coherent overall model output. The inherent modularity of MoE architectures allows for greater flexibility and adaptability to new, unseen data distributions. However, a key challenge lies in designing and training these expert models effectively and ensuring efficient coordination between them. Careful consideration of the gating mechanism, the alignment strategy between experts, and the overall architecture is critical for success.
Referential Invariance#
Referential invariance, in the context of Graph Neural Networks (GNNs) handling distribution shifts, is a crucial concept for building robust and generalizable models. It emphasizes learning representations that remain consistent regardless of specific data variations. The core idea is to align representations from different expert models, each specialized to handle a specific type of distribution shift, within a common referential space. This alignment is achieved through a reference model, which provides a stable anchor point, and a novel objective function that encourages alignment between expert outputs and the reference model. This approach mitigates issues caused by the divergence of representation spaces among multiple experts, which can occur when each expert learns features specific to its assigned type of shift. By ensuring that the representations across all experts are aligned in a shared referential space, GraphMETRO achieves more stable and reliable aggregation of expert opinions, ultimately leading to improved generalization and robustness to unseen distribution shifts. The concept is similar to invariant learning but moves beyond simply identifying invariant features, tackling diverse, multi-faceted shifts. The strategy of creating referentially invariant representations is particularly powerful when addressing complex real-world data characterized by heterogenous shifts that arise from combinations of several factors, as it allows for each shift to be addressed specifically yet maintains a cohesive overall representation.
Real-world Evaluation#
A robust ‘Real-world Evaluation’ section is crucial for validating the claims of any research paper. It should go beyond simply reporting accuracy metrics and delve into the nuances of real-world data. This necessitates careful consideration of data heterogeneity, complex distributional shifts, and the inherent challenges in obtaining truly representative real-world datasets. A strong evaluation would involve a thorough analysis of performance across various subsets of the data, exploring sensitivity to different types of shifts, and comparing against relevant baselines that reflect the current state-of-the-art. The discussion should also transparently address limitations of the real-world data used, acknowledging potential biases or confounding factors that might influence the results. Ultimately, a compelling real-world evaluation provides a holistic perspective on the generalizability and practical applicability of the proposed method, building confidence in its usefulness beyond the confines of controlled experimental settings. Addressing edge cases and failure modes is also critical for demonstrating robustness.
Future Research#
The paper’s conclusion points towards several promising avenues for future research. Extending GraphMETRO to handle label distribution shifts is a key area, as the current work focuses solely on structural and feature shifts. This would broaden the model’s applicability to a wider range of real-world scenarios. Further investigation into the selection and design of stochastic transform functions is also warranted. The current set, while effective, may not capture all types of real-world shifts, and exploring new functions or a more systematic approach to function design could significantly improve performance and robustness. Finally, exploring alternative architectures for expert models is suggested, potentially finding a better balance between model expressiveness and computational efficiency. The current architecture’s dependence on multiple encoders could limit scalability. Investigating shared modules or other architectural innovations could unlock further enhancements. Overall, the future research directions focus on increasing GraphMETRO’s versatility and efficiency, thereby expanding its applicability in real-world graph data analysis.
More visual insights#
More on figures
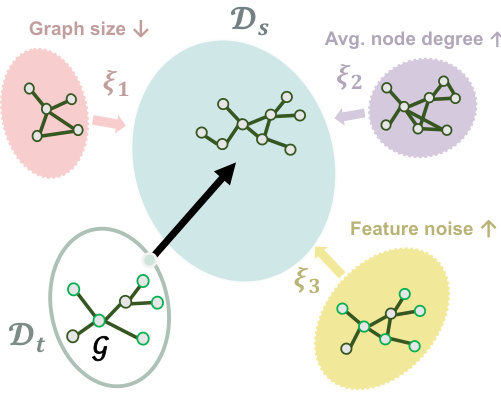
This figure provides a high-level overview and the architecture of GraphMETRO. The high-level concept illustrates how GraphMETRO decomposes distribution shifts into three dimensions (graph size, node degree, and feature noise). The architecture shows how the gating model identifies these shift components and how multiple expert models generate referential representations to mitigate these shifts. These representations are then aggregated and fed into a classifier.
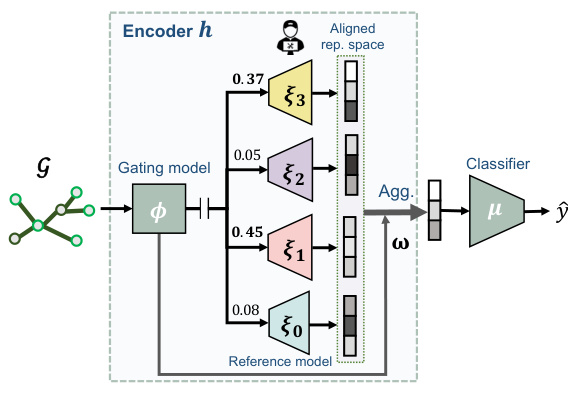
This figure provides a high-level overview and detailed architecture of the GraphMETRO model for graph classification. Panel (a) illustrates the concept of decomposing a complex distribution shift into simpler, interpretable shift components (e.g., graph size, node degree, feature noise). Panel (b) shows the architecture, which uses a gating model to determine the contribution of each shift component and multiple expert models, each focusing on a specific component. A key aspect is the alignment of representations across expert models, ensuring reliable optimization and referential invariance to shifts. The final representation, invariant to distributional shifts, is fed to a classifier.
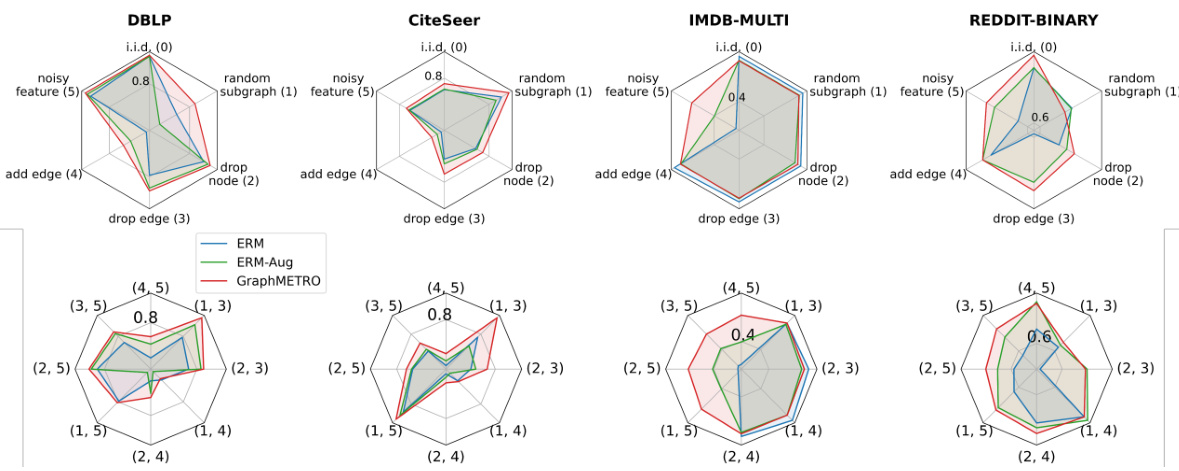
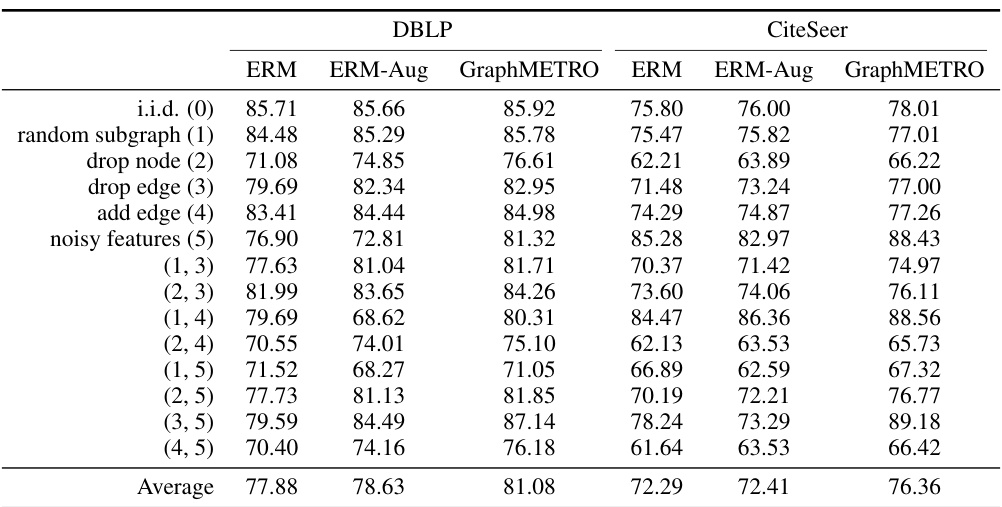
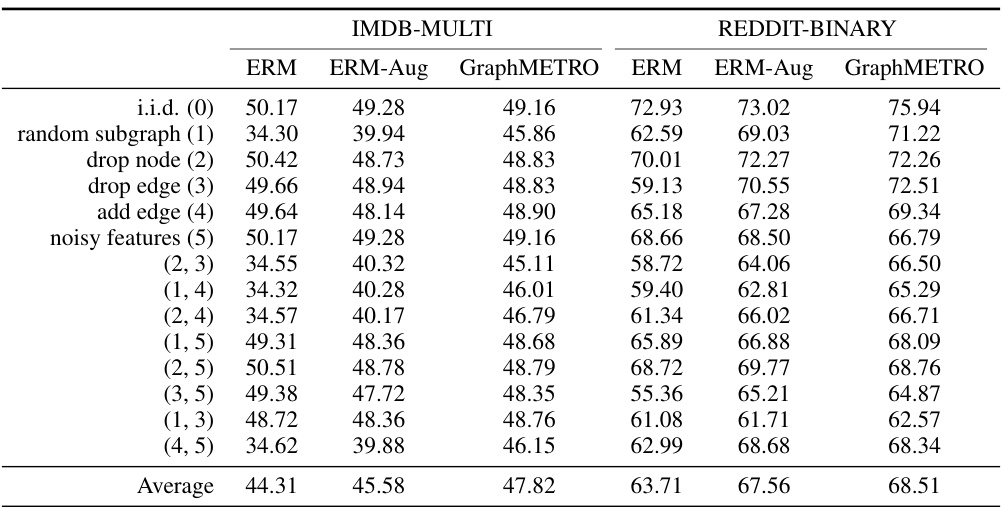
This figure displays the results of experiments conducted on synthetic datasets with various distribution shifts. The top row shows the performance of different methods (ERM, ERM-Aug, and GraphMETRO) when dealing with single shift components. The bottom row shows their performance when facing combinations of two shift components. Each axis represents a different type of shift and the values indicate the testing accuracy. The figure illustrates how GraphMETRO handles complex shifts that result from the combination of multiple individual shifts.

This figure demonstrates the effectiveness of GraphMETRO in generating invariant representations and identifying dominant shift components. (a) shows an invariance matrix visualizing how well each expert model is invariant to different shift components. The diagonal elements represent the model’s invariance to its own assigned shift, while off-diagonal values show the impact of other shifts. Low diagonal values indicate strong invariance. (b) depicts the mixture of shifts found by GraphMETRO on two datasets (WebKB and Twitch), showing the relative influence of each shift component.
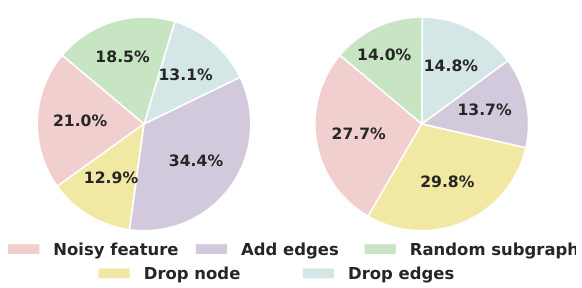
Figure 4(a) shows an invariance matrix visualizing how well each expert model generates representations invariant to a specific shift component. The lighter the color, the higher the invariance. Figure 4(b) shows the contribution of each shift component to the distribution shift in WebKB and Twitch datasets. The larger the value, the more significant the impact of the component.
This figure shows an example of distribution shift on the WebKB dataset. The thick arrow indicates the overall distribution shift from the source to the target domain. However, the thin arrows highlight that even within the target domain, there is instance-wise heterogeneity, as shown by nodes u1 and u2 exhibiting varying degrees of change in their features. This example illustrates the complex and dynamic nature of real-world graph data, motivating the need for models that can generalize well to various forms of distribution shift.
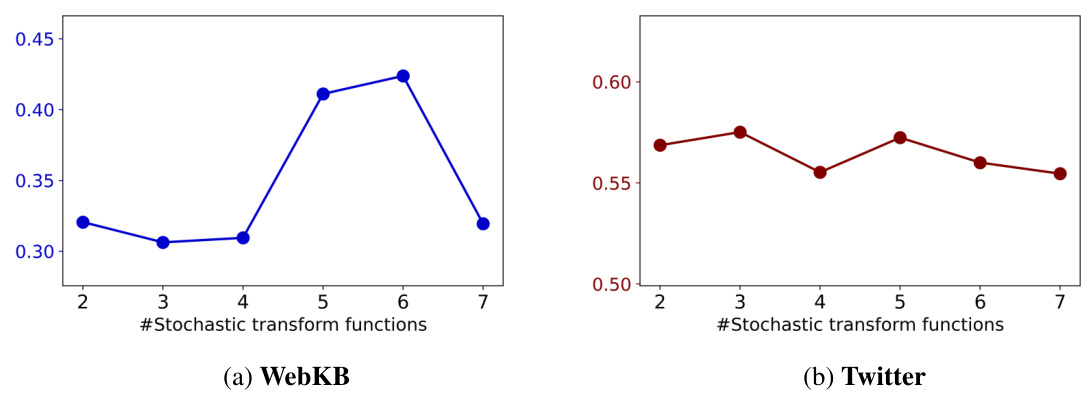
This figure shows the results of applying GraphMETRO to synthetic datasets with various combinations of distribution shifts. The first row displays the accuracy for single, isolated shift components, while the second row illustrates the accuracy for datasets with combinations of two different shifts. This helps to demonstrate GraphMETRO’s ability to handle complex, multi-dimensional distribution shifts.
More on tables
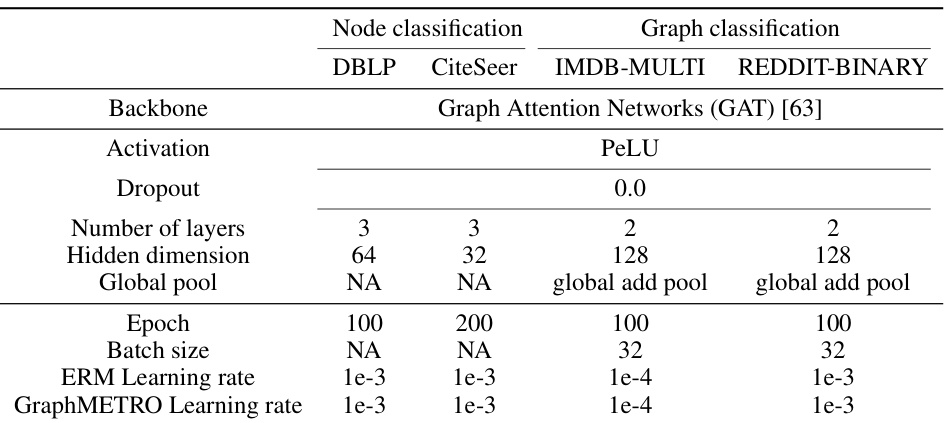
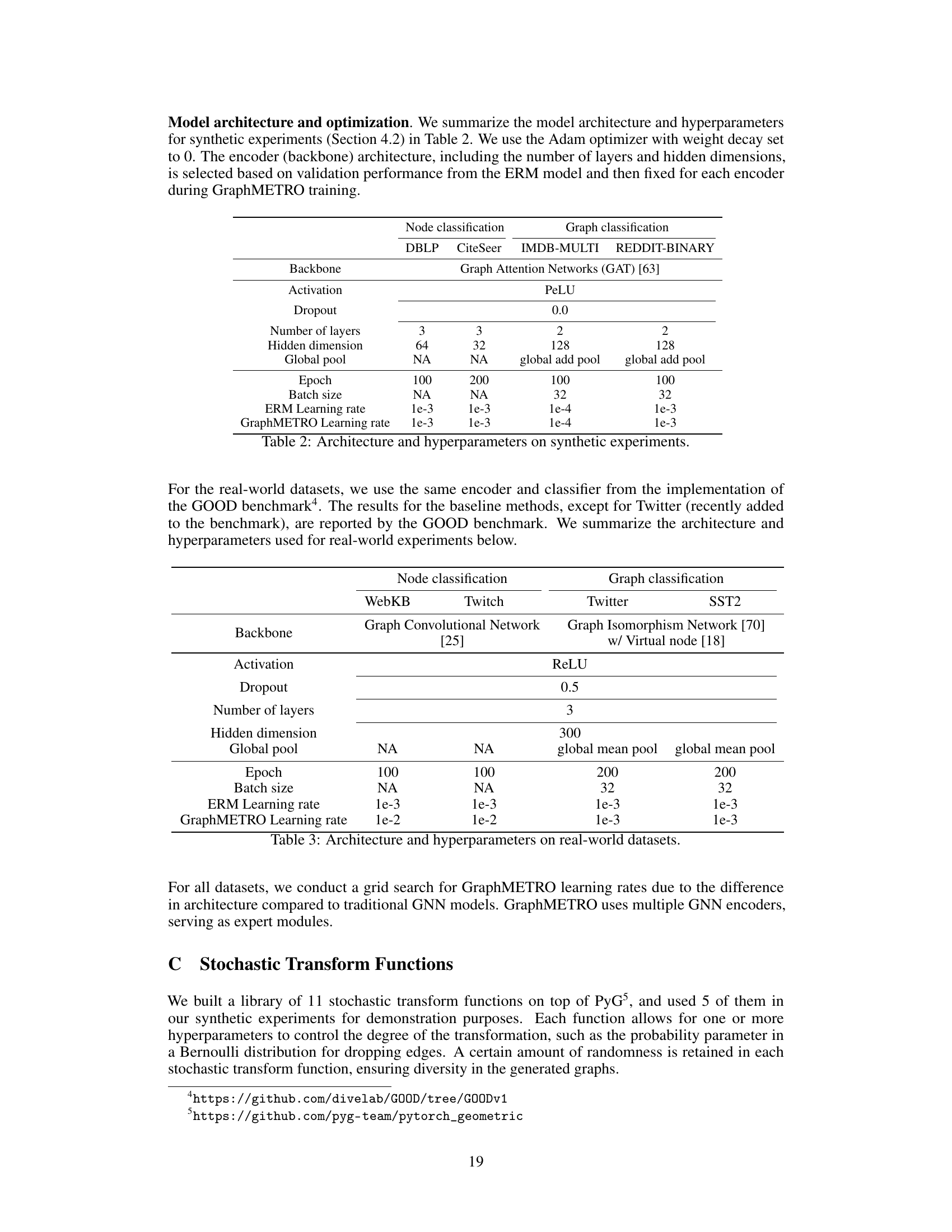
This table details the architecture and hyperparameters used in the synthetic experiments for both node and graph classification tasks. It shows the backbone architecture (Graph Attention Networks), activation function (PeLU), dropout rate, number of layers, hidden dimension, global pooling method, number of epochs, batch size, and learning rates for both ERM and GraphMETRO methods. Note that some values are NA (Not Applicable), indicating the absence of the respective hyperparameters for those specific experiments.

This table compares the performance of GraphMETRO against other state-of-the-art methods on four real-world datasets (WebKB, Twitch, Twitter, SST2) for both node and graph classification tasks. It shows the accuracy achieved by each method and includes p-values to indicate the statistical significance of GraphMETRO’s improvement. The ‘Require domain information’ column specifies whether the method utilizes domain-specific information during training.
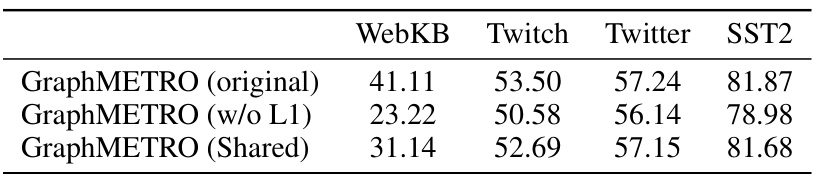
This table presents the results of ablation studies comparing three different versions of the GraphMETRO model on four real-world datasets (WebKB, Twitch, Twitter, SST2). The variations are: (original) the full model, (w/o L1) without the L1 loss component, and (Shared) using a shared encoder across the expert models instead of individual encoders. The table shows accuracy scores for each model variant on each dataset, demonstrating the impact of the L1 loss and the shared encoder design choices on performance. The results are averaged over five runs for improved reliability.

This table presents the results of an ablation study conducted to evaluate the impact of aligning expert models with the reference model in GraphMETRO. By comparing the performance of the original GraphMETRO model with a variant where the alignment is removed (λ = 0), the importance of this design choice for achieving high accuracy is demonstrated. The results show that aligning expert models with the reference model significantly improves performance across all four datasets (WebKB, Twitch, Twitter, SST2).
This table presents the test results of GraphMETRO and other state-of-the-art methods on four real-world datasets (WebKB, Twitch, Twitter, and SST2) for both node and graph classification tasks. For each dataset and task, it shows the accuracy achieved by each method, along with the p-value indicating the statistical significance of GraphMETRO’s improvement over the best-performing existing method. The GraphMETRO results are the average of five independent runs.
This table presents the test results of GraphMETRO and several state-of-the-art methods on four real-world datasets for node and graph classification tasks. The p-values show the statistical significance of GraphMETRO’s improvements over the baselines. The results for GraphMETRO are averaged over five runs, highlighting the model’s consistent performance. The table also indicates whether each dataset requires domain-specific information.
Full paper#