↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Diffusion models, while powerful generative models, suffer from a phenomenon called “content shift” when their internal activations (diffusion features) are used for discriminative tasks. This shift creates discrepancies between the input image and the extracted features, degrading performance. Existing methods lack a systematic way to address this issue, limiting the reliability and effectiveness of diffusion features for tasks like semantic segmentation and correspondence.
The paper introduces GATE, a novel framework that effectively utilizes off-the-shelf image generation techniques to suppress this content shift. GATE provides a practical guideline for choosing and integrating these techniques. Empirical results on various datasets demonstrate GATE’s effectiveness in significantly improving the performance of diffusion features across different tasks and datasets, highlighting its potential as a universal booster for improving the quality of diffusion features. This simple yet effective method offers a generic solution to enhance the performance of various applications based on diffusion features.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in using diffusion models for discriminative tasks, namely, the phenomenon of “content shift.” By proposing a novel method to mitigate this issue and providing a practical guideline for evaluating the effectiveness of various techniques, this work significantly improves the performance and generalizability of diffusion features. It opens up new avenues for research in utilizing off-the-shelf generation techniques to enhance the quality of features extracted from various models.
Visual Insights#
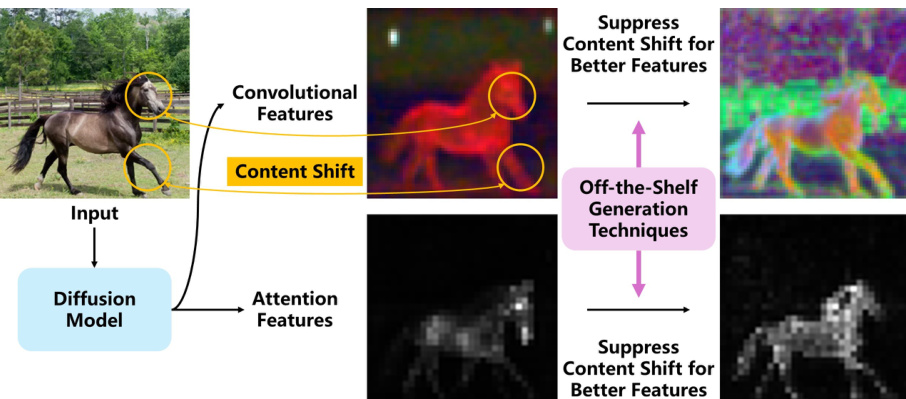
The figure illustrates the concept of ‘content shift’ in diffusion features. It shows that the features extracted from a diffusion model (convolutional and attention features) don’t perfectly match the input image. There are subtle but noticeable differences in content, which the authors call ‘content shift’. The figure suggests that this content shift can be mitigated using off-the-shelf image generation techniques.
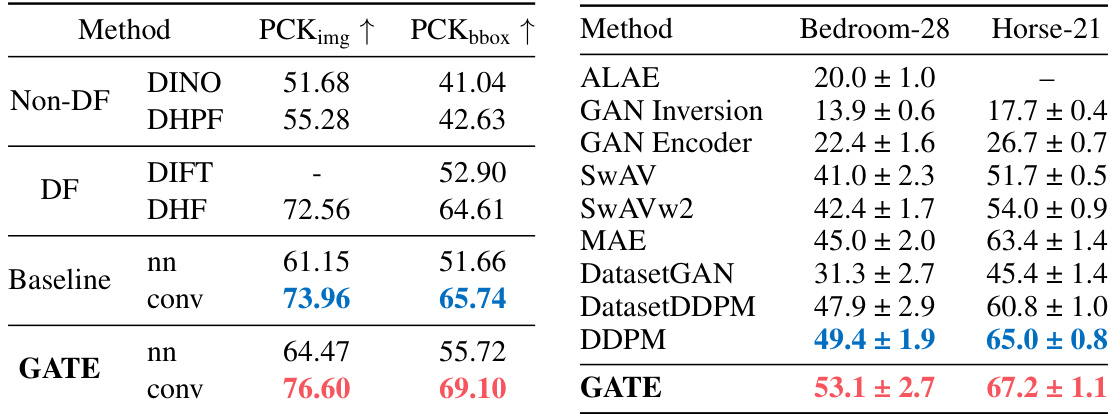
This table presents the performance comparison of different methods on semantic correspondence and label-scarce semantic segmentation tasks. The left side shows results for semantic correspondence, measured by PCK@0.1 (Percentage of Correct Keypoints within 0.1 of the image or bounding box size). The right side shows results for label-scarce semantic segmentation, using mIoU (mean Intersection over Union) as the metric. Methods are categorized into Non-DF (non-diffusion feature), DF (diffusion feature), Baseline (using standard diffusion features without any enhancements), and GATE (the proposed method). The best performing method for each task is highlighted in red, while the second-best is in blue.
In-depth insights#
Content Shift Issue#
The paper’s ‘Content Shift Issue’ section is crucial as it identifies a core problem in using diffusion models for feature extraction. The authors highlight a universal phenomenon where the extracted features subtly differ from the input image, a discrepancy they term ‘content shift’. This shift, even if imperceptible visually, significantly impacts the features’ quality and downstream task performance. The root cause is identified as an inherent characteristic of diffusion models: the process of reconstructing a clean image from a noisy input involves a degree of ‘imagination’, leading to a drift from the original information. This is not a flaw but an inherent property, which makes the problem ubiquitous. The proposed solution, leveraging readily-available off-the-shelf generation techniques, offers a practical approach to mitigate this issue by better guiding the reconstruction process toward fidelity to the original image. This innovative approach provides a generic boost to diffusion feature performance.
GATE Guideline#
The GATE (GenerAtion Techniques Enhanced) guideline is a crucial contribution of the research paper, offering a practical framework for evaluating the effectiveness of various off-the-shelf generation techniques in suppressing content shift within diffusion features. This addresses a key limitation of using diffusion models for discriminative tasks. The guideline cleverly leverages Img2Img generation as a proxy for evaluating a technique’s ability to steer the reconstruction process closer to the original input image, thus reducing the content shift. By comparing the generated image to the input, GATE provides a quantitative and qualitative way to assess each technique, facilitating efficient selection of the most beneficial methods for enhancing diffusion features. The simplicity and practicality of the GATE guideline are noteworthy, as it avoids the need for extensive experimentation directly within the feature extraction pipeline. This makes it easily applicable to a range of techniques, promoting a more generic approach and validating its potential as a significant booster for diffusion features. Further, the amalgamation of multiple techniques, suggested by GATE, results in superior performance, demonstrating the value of combining complementary strengths to overcome the inherent content shift in diffusion features.
Technique Effects#
The effectiveness of different techniques in suppressing content shift, a phenomenon hindering the quality of diffusion features, is a key area of investigation. Fine-grained prompts, while simple to implement, offer limited improvement. ControlNet, by contrast, shows significant promise due to its ability to directly steer the reconstruction process. The success of LoRA demonstrates the potential of leveraging pre-trained models’ strengths. Feature amalgamation, combining outputs from multiple techniques, presents a promising avenue for optimization, exceeding the effectiveness of individual techniques. However, the need for careful selection and optimized integration of these off-the-shelf methods is highlighted, as not all techniques are equally effective and some, like classifier-free guidance, prove ineffective at addressing the issue. Quantitative and qualitative evaluation metrics are crucial to guide the selection process, ensuring that selected techniques demonstrably enhance feature quality by reducing the content shift.
Ablation Study#
An ablation study systematically investigates the contribution of individual components within a machine learning model by removing or “ablating” them and evaluating the performance drop. This helps identify crucial parts and understand their relative importance. In the context of a research paper, an ablation study section would typically present results showing the impact of removing specific features, modules, or hyperparameters. A well-executed ablation study strengthens the paper’s claims, demonstrating that reported improvements aren’t due to an overall system effect but stem from the specific contribution being studied. Clear methodology and visualizations are essential to make ablation results easily understandable and convincing. A strong ablation study will also explore the interplay between components, showing whether there are synergistic or antagonistic effects when components are combined or removed. The results should be presented quantitatively (e.g., using performance metrics) and sometimes qualitatively (e.g., with visualizations). A thoughtful ablation study goes beyond simply removing features, exploring combinations of features to unveil more nuanced insights into the model’s behavior and ultimately bolstering the paper’s overall credibility.
Future Work#
The ‘Future Work’ section of this research paper presents exciting avenues for extending the current findings on suppressing content shift in diffusion features. One key area is exploring a wider range of off-the-shelf generation techniques, beyond the three (Fine-Grained Prompts, ControlNet, LoRA) initially investigated. This could significantly enhance the effectiveness and versatility of the proposed GATE methodology. Further research into the impact of different diffusion models and their inherent characteristics on content shift is crucial for establishing the generalizability of the findings. Investigating alternative feature extraction methods and their susceptibility to content shift would provide a more comprehensive understanding. A quantitative evaluation using a larger, more diverse set of datasets is necessary to solidify the robustness and broad applicability of GATE. Finally, examining how content shift influences various downstream tasks, beyond those examined in the study, will provide crucial insights into the practical implications of the proposed approach. The study’s authors propose that the integration of AUC-based tools could lead to new opportunities within the field.
More visual insights#
More on figures

This figure illustrates the feature extraction process. It starts with an input image, which is encoded using a Variational Autoencoder (VAE) and then noise is added. This noisy image is fed into a pre-trained diffusion UNet. The UNet’s activations from the upsampling stages are collected as convolutional features. Additionally, the average of the similarity maps from the cross-attention layers is taken as the attention features. These features are then used for downstream discriminative tasks.
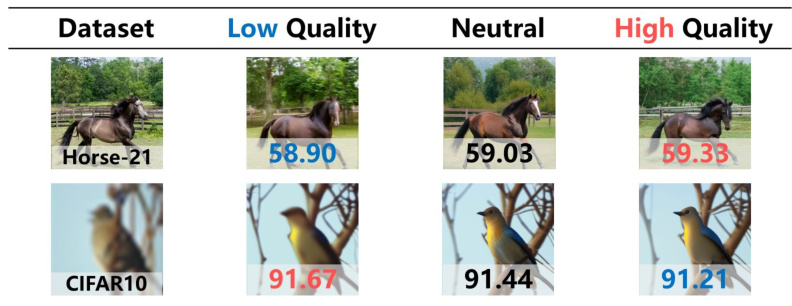
This figure shows the results of an experiment testing the impact of prompt quality on the performance of a model. Two datasets, Horse-21 (high-quality images) and CIFAR-10 (low-quality images) were used. Different prompts were used which reflected different levels of image quality (low, neutral, high). The results show that using prompts that accurately describe the image quality leads to better performance, suggesting that content shift (differences between the features and the input image) negatively impacts the model’s performance, especially at small timesteps.

This figure visualizes the process of content shift in diffusion models. It shows how the early activations of a diffusion model add noise to the input image (a). These noisy inputs are progressively denoised by the model, and in the middle stages (d), a reconstructed ‘clean’ activation is obtained. However, this reconstructed image (d) differs from the original input image (a). This difference, what authors call ‘content shift’, is caused by information lost during the noisy process and subsequent reconstruction. The final output noise (e) demonstrates the model’s attempt to refine this reconstructed activation toward the original image, further illustrating that the content shift occurs during the reconstruction phase.
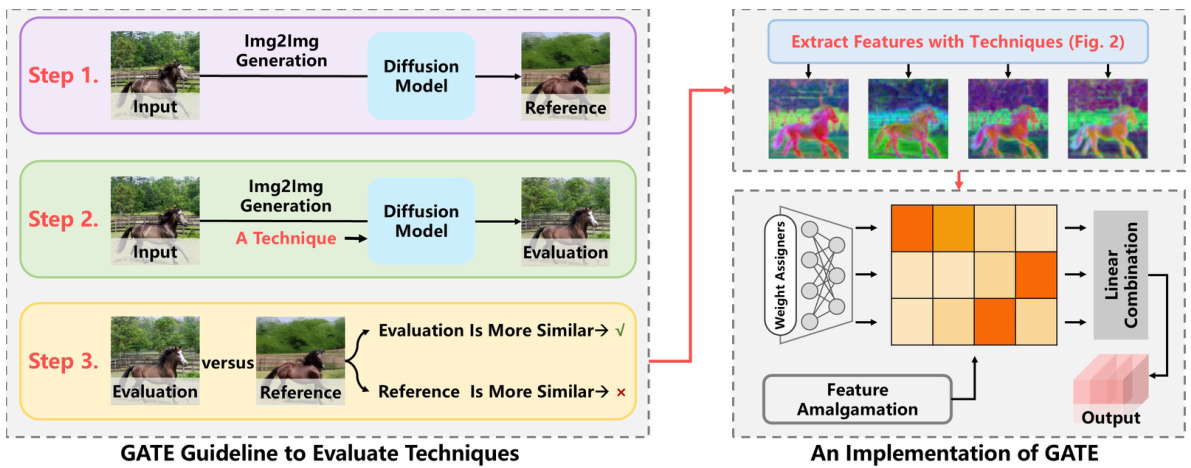
This figure illustrates the proposed GATE (GenerAtion Techniques Enhanced) guideline and its implementation. The GATE guideline uses Img2Img generation to evaluate whether a generation technique reduces content shift in diffusion features. A technique is considered helpful if it generates an image closer to the original input. The implementation uses three generation techniques (Fine-Grained Prompts, ControlNet, and LoRA) and combines features from these techniques using feature amalgamation.

This figure shows the results of image-to-image (Img2Img) generation using three different techniques: Fine-Grained Prompts, ControlNet, and LoRA. Each technique aims to suppress content shift in diffusion features by steering the reconstruction process towards the original clean image. The input image is shown alongside the reference image (generated using a high-repainting Img2Img approach to amplify content divergence), as well as the results obtained with each generation technique. The figure visually demonstrates the effectiveness of these techniques in mitigating content shift and improving the quality of diffusion features, supporting the claim that off-the-shelf generation techniques can be effectively used to improve diffusion features.

This figure visualizes the impact of different timesteps and generation techniques on diffusion features. The top row displays features extracted using the basic model at various timesteps, showing the evolution of features during the reconstruction process. The bottom row showcases features obtained by combining different generation techniques, illustrating how these methods enhance the diversity of the generated features. This diversity is crucial because it enhances robustness and generalizability when these features are used in downstream tasks.
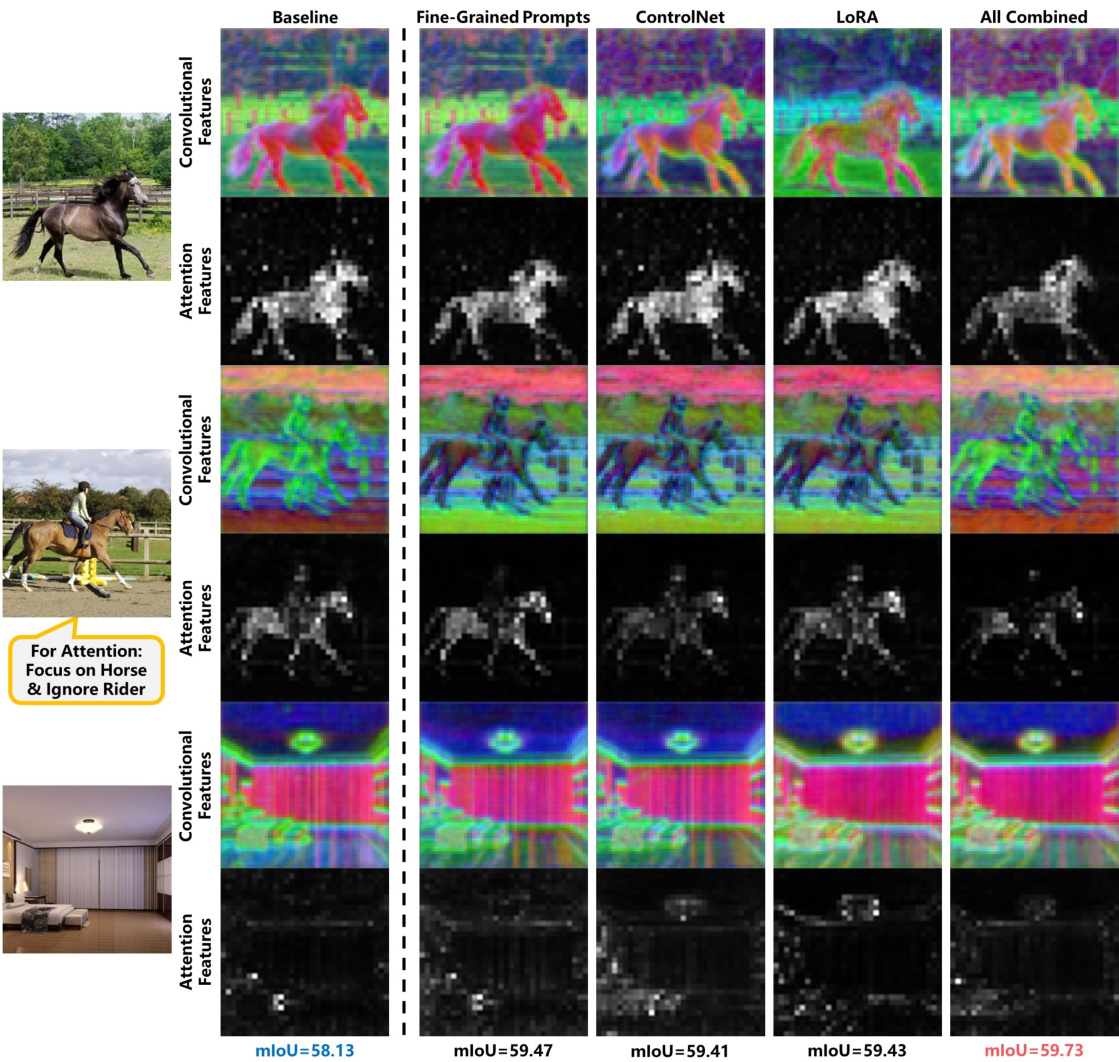
This figure shows the effect of the proposed GATE method on feature quality without using feature amalgamation. It displays feature visualizations (attention and convolutional features) for three different images using different methods: baseline, fine-grained prompts, ControlNet, LORA, and all combined. The results show that using the proposed GATE method enhances feature quality and improves the ability to focus on specific features, even in complex scenes, compared to using the baseline method. The mIoU performance is also shown for each method on a single Horse-21 split.

This figure illustrates the concept of ‘content shift’ in diffusion features. The input image (a horse) is processed by a diffusion model, and the resulting features (activations within the model) are shown. The key point is that the features don’t perfectly match the input image; there are subtle differences, which the authors refer to as content shift. These differences impede the accuracy of using these features for downstream tasks. The figure shows that this can be mitigated through off-the-shelf generation techniques.

This figure shows the impact of using the proposed GATE method without feature amalgamation. It displays three example images (a kitchen, a street scene, and a portrait), and their corresponding convolutional and attention features. Each image’s features are shown under different conditions (Baseline, Fine-Grained Prompts, ControlNet, LoRA, and All Combined). This visualization allows for a qualitative comparison of the effects of the individual and combined methods on content shift and feature clarity. The mIoU performance metric for a single Horse-21 split is provided below each image, highlighting the relative success of each approach.
This figure illustrates the proposed GATE (GenerAtion Techniques Enhanced) guideline and its implementation. The GATE guideline evaluates the effectiveness of off-the-shelf generation techniques in suppressing content shift in diffusion features. It uses Img2Img generation to assess whether a technique brings the generated image closer to the original input image. If it does, then the technique is considered to effectively suppress content shift. The implementation part shows how three chosen techniques (Fine-Grained Prompts, ControlNet, and LoRA) are combined and their features are amalgamated for better results.

This figure illustrates the concept of content shift in diffusion features. It shows that there are differences between the input image and the features extracted from a diffusion model. These differences, termed ‘content shift’, negatively impact the quality of diffusion features. The figure also proposes that off-the-shelf image generation techniques can be used to mitigate this content shift by leveraging the inherent connection between generation and feature extraction in diffusion models. The figure visually shows different stages in the process: input image, convolutional features directly from the diffusion model, and features after content shift suppression using generation techniques.

This figure illustrates the problem of content shift in diffusion features. The left side shows a standard diffusion model feature extraction process, highlighting the difference between the input image and the resulting features. This difference is labeled ‘content shift’. The right side demonstrates how off-the-shelf generation techniques can be used to mitigate content shift and produce better features that are more consistent with the input image. This shows the core concept of the paper, which is to address the limitations of traditional diffusion feature extraction by leveraging readily available image generation techniques.
This figure illustrates the concept of ‘content shift’ in diffusion features. It shows that the features extracted from a diffusion model often differ from the input image in terms of content, such as the exact shape of an object. This difference hinders the performance of diffusion features in discriminative tasks. The figure also suggests that off-the-shelf generation techniques can be used to suppress content shift and improve the quality of diffusion features.

This figure illustrates the concept of content shift in diffusion features. It shows how the features extracted from a diffusion model (the ‘Diffusion Model’ box) can differ from the input image. These differences are highlighted as ‘Content Shift’. The figure proposes that off-the-shelf generation techniques can be used to mitigate this content shift, leading to better features. It visually compares convolutional features, attention features, and how the application of generation techniques affects the features, resulting in suppressed content shift and better features.

This figure illustrates the concept of content shift in diffusion features. It shows how the features extracted from a diffusion model (the internal activations) can differ from the input image. These differences, termed ‘content shift,’ represent discrepancies in details such as object shapes and exact forms. The figure highlights that these differences can be mitigated by applying off-the-shelf image generation techniques to the process of feature extraction. The figure visually compares input images to their corresponding convolutional and attention features (produced by the diffusion model), clearly showing the differences in content between the input and the features. It then suggests that the content shift can be reduced by using off-the-shelf image generation techniques during the feature extraction process.
The figure illustrates the concept of content shift in diffusion features, which is a discrepancy between input images and the features extracted from a diffusion model. It shows how off-the-shelf generation techniques can potentially mitigate this issue by reducing the difference between the input and the generated features. The figure uses visual examples to highlight the problem and proposed solution.
More on tables
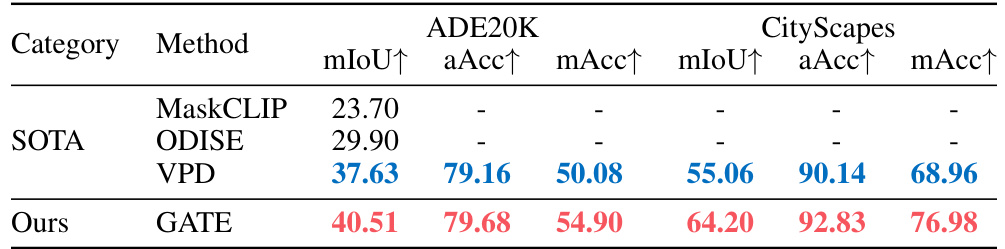
This table presents the results of the proposed GATE method on two standard semantic segmentation datasets: ADE20K and CityScapes. It compares the performance of GATE against other state-of-the-art (SOTA) methods. The metrics used are mean Intersection over Union (mIoU), overall accuracy (aAcc), and mean accuracy (mAcc). The best performing method for each metric is highlighted in red, and the second-best is in blue, indicating the relative improvements achieved by GATE.

This table presents the results of an experiment comparing the effectiveness of ControlNet and IP-Adapter in suppressing content shift. The metric used is mIoU (mean Intersection over Union), a common evaluation metric for semantic segmentation. The table shows that using only ControlNet within the GATE framework leads to a higher mIoU than using only IP-Adapter or no technique at all (DDPM baseline). The full GATE approach (combining both techniques) achieves the highest mIoU, indicating that combining multiple techniques is beneficial for suppressing content shift and improving the overall performance of diffusion features.

This table presents the results of applying the GATE method to SDXL features. It compares the performance of using only basic features (Baseline), using basic features along with a single technique (Individual), and using basic features along with multiple techniques (Combined). The mIoU metric is used to evaluate the performance, and the best result for each setting is highlighted in red. The table demonstrates that combining multiple techniques through GATE improves the quality of features.

This table presents the quantitative results of the proposed GATE method on semantic correspondence and label-scarce semantic segmentation tasks. It compares the performance of GATE against various state-of-the-art (SOTA) methods. The left side shows results for semantic correspondence (measured by PCK@0.1), while the right side displays results for label-scarce semantic segmentation (measured by mIoU). The best performing method for each metric is highlighted in red, with the second-best in blue. The table demonstrates the effectiveness of GATE in enhancing the performance of diffusion features on these tasks.

This table presents the results of an ablation study on the Horse-21 dataset, investigating the impact of feature amalgamation on model performance. Different combinations of feature extraction methods (Basic, Basic* (different timestep), Fine-Grained Prompts, ControlNet, and LoRA) were evaluated and their mIoU scores are reported. The goal was to determine if combining multiple feature extraction techniques improved performance compared to using only one method or using different timesteps.
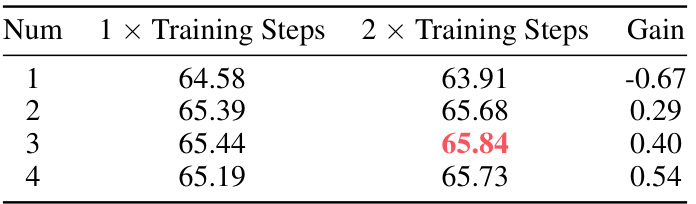
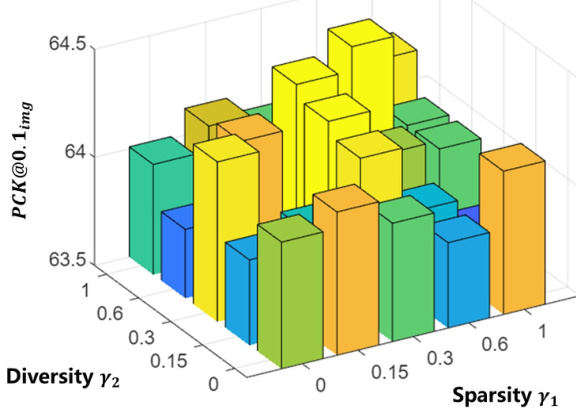
This table presents the results of an ablation study on the number of weight assigners used in the feature amalgamation process. The mIoU (mean Intersection over Union) metric, indicating the performance of semantic correspondence, is reported for different numbers of weight assigners (1 to 4). The results are shown for two different training durations: 1x and 2x the training steps. The ‘Gain’ column shows the performance improvement compared to the 1x training steps. The best result for each number of weight assigners is highlighted in red. The table helps demonstrate that adding more weight assigners can enhance performance, but there’s a trade-off with training time and computational cost.

This table presents the accuracy results (%) for image classification on the CIFAR10 dataset. Three methods are compared: ResNet-50 (a standard convolutional neural network), a baseline using diffusion features without the proposed GATE technique, and the proposed GATE method. The results show that the GATE method outperforms both ResNet-50 and the diffusion feature baseline, indicating its effectiveness in improving the quality of diffusion features for image classification.
Full paper#



















