↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current generative models often struggle with complex multi-agent decision-making problems due to a lack of trial-and-error experience and reasoning capabilities. Existing methods often produce sketchy solutions and fail to capture the nuanced dynamics of multi-agent interactions. This necessitates a new approach that combines real-world experience and reasoning with generative modeling.
This paper introduces Learning Before Interaction (LBI), a framework that integrates a language-guided simulator into a multi-agent reinforcement learning pipeline. LBI uses an image tokenizer and a causal transformer to model dynamics, and a bidirectional transformer trained via expert demonstrations to model rewards. The method’s effectiveness is validated by outperforming existing methods on the StarCraft Multi-Agent Challenge benchmark. The key contributions are the novel dataset, the interactive simulator design, and the improved answer quality for multi-agent decision-making problems.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the limitations of existing generative models in complex multi-agent decision-making scenarios. By introducing a novel framework that integrates language-guided simulation and multi-agent reinforcement learning, it significantly improves the quality and explainability of generated answers. This work opens new avenues for research in multi-agent systems, model-based reinforcement learning, and generative AI, with potential applications in various domains.
Visual Insights#
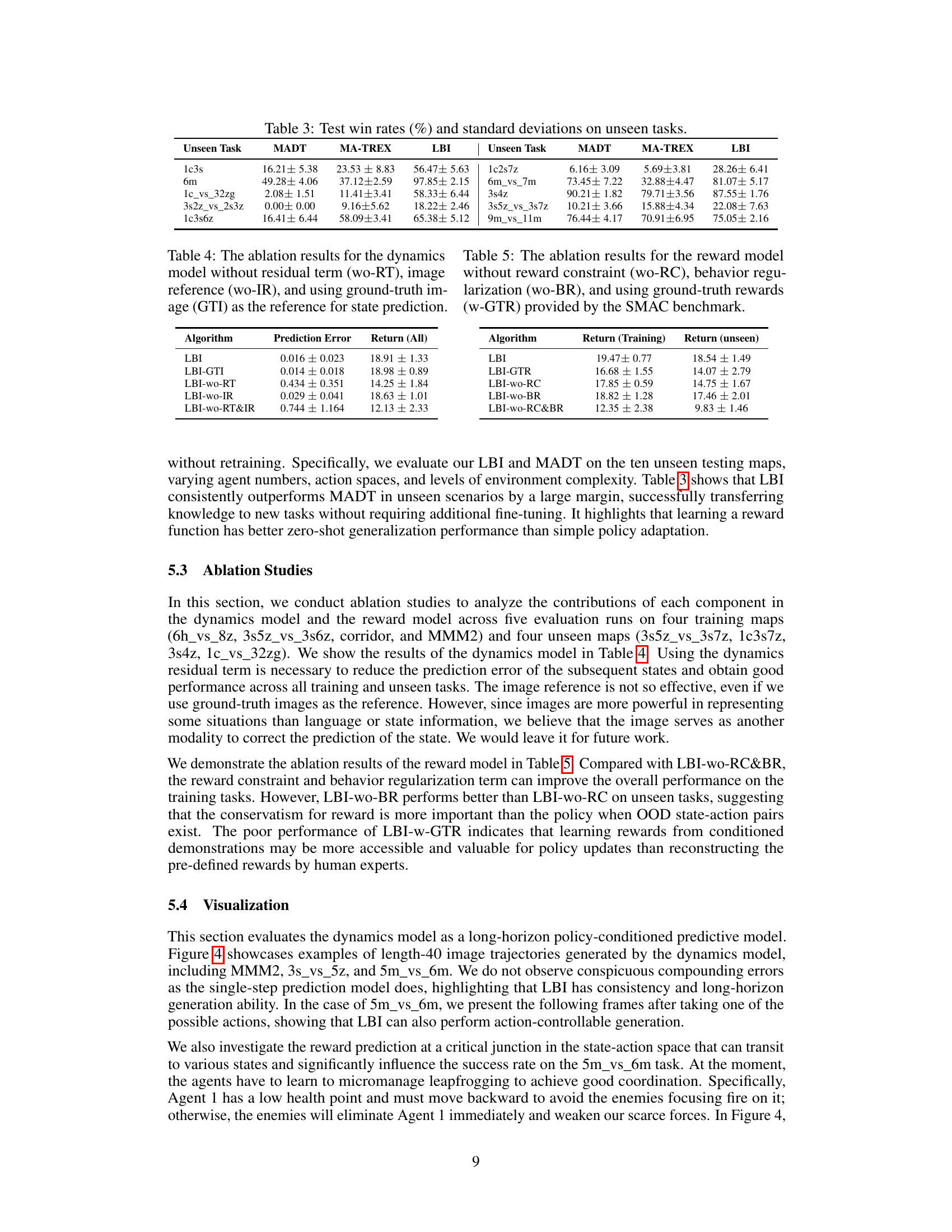
This figure illustrates the limitations of current vision-language models like GPT-4 in solving complex multi-agent decision-making problems. GPT-4’s response to a sample question is shown to be vague and inaccurate. The figure then introduces the Learning Before Interaction (LBI) framework as a solution. LBI uses a simulator to train a multi-agent reinforcement learning (MARL) policy which is then used to generate a more accurate and grounded answer by simulating the interaction in the given environment.
This table presents the performance comparison between the proposed LBI method and several baseline imitation learning methods on various StarCraft II maps. The win rate is used as the evaluation metric, and the standard deviation shows the performance variability. It highlights the superior performance of LBI compared to baseline methods.
In-depth insights#
Generative World Model#
The core concept of a Generative World Model in this research is to create a simulated environment that mirrors the real-world dynamics of a multi-agent decision-making problem. This model is not just a static representation but rather a dynamic system that learns and predicts the consequences of actions taken by multiple agents. The approach uses a combination of image tokenization and causal transformers for modeling environment dynamics. This allows it to generate image sequences reflecting transitions between states. The inclusion of a reward model trained via expert demonstrations further enhances the framework’s ability to produce high-quality, grounded answers to complex problems. Learning before Interaction (LBI), is the novel paradigm employed, enabling the world model to train a joint policy that improves answers by generating consistent and explainable sequences of interactions. The success hinges on the model’s capability to learn both the environment’s dynamics and the reward function, using natural language guidance to make this process efficient and effective.
LBI Framework#
The LBI (Learning Before Interaction) framework is a novel approach to multi-agent decision-making that leverages generative world models. Instead of directly training a policy on real-world interactions, which can be costly and time-consuming, LBI first trains a world model to simulate the environment’s dynamics and reward function. This model is trained using expert demonstrations paired with image data and language descriptions of the tasks. The key innovation is that the simulator allows the agents to learn through trial-and-error in a safe and efficient simulated environment, before interacting with the real world. Once the world model is trained, an off-policy MARL algorithm is used to train a joint policy in the simulated environment. This policy is then deployed in the real world, enabling the agents to make more informed decisions. The LBI framework’s ability to generate consistent interaction sequences and explainable reward functions is a significant contribution opening up new possibilities for training generative models in complex, multi-agent settings. A major strength of LBI lies in its ability to address the limitations of existing methods that struggle with complex, multi-agent decision problems by incorporating simulation and trial-and-error learning. However, a key limitation is its reliance on the accuracy of the learned world model, which can affect the quality of the generated answers. Further research could focus on improving the robustness and generalizability of the world model, as well as exploring different MARL algorithms for policy learning.
MARL Datasets#
The effectiveness of multi-agent reinforcement learning (MARL) heavily relies on the quality and quantity of training data. Creating diverse and representative MARL datasets is a significant challenge, particularly when dealing with complex environments and interactions. A well-designed dataset should capture a wide range of scenarios, including various agent configurations, environmental conditions, and task objectives. Data augmentation techniques, such as adding noise or modifying existing trajectories, can significantly improve the robustness of trained agents. Careful consideration of data bias is also critical; biased datasets can lead to agents that perform poorly in real-world settings or exhibit unintended behaviors. The creation of benchmark datasets, like the StarCraft Multi-Agent Challenge (SMAC), has advanced the field, but the need for more diverse and challenging datasets persists. Future research should focus on developing new methodologies for generating realistic and unbiased MARL datasets, exploring techniques such as generative models and simulation environments to augment or replace real-world data collection. This will be crucial for advancing the state-of-the-art in MARL and enabling the development of truly robust and generalizable multi-agent systems.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, removing parts of the proposed model (dynamics model and reward model) and evaluating the resulting performance on various tasks allows researchers to isolate and understand the impact of each component. Removing the residual term from the dynamics model, for instance, might reveal its significance in improving state prediction accuracy, showcasing that the term’s contribution lies beyond merely enhancing overall performance. Similarly, removing the reward constraint and/or behavior regularization terms from the reward model would clarify their individual and combined roles in improving generalization or preventing overfitting. The use of ground-truth images versus model-generated images highlights the effect of imperfect state representations on performance, demonstrating whether the method can still achieve success with limited information, and suggesting the importance of high-quality image-based state modeling. Through these systematic analyses, researchers demonstrate the effectiveness of each module and provide valuable insights into the design choices made, thus strengthening the paper’s overall argument. The results help in verifying the proposed architecture’s robustness and inform future model development decisions.
Future Work#
The paper’s conclusion suggests several avenues for future research. Improving the efficiency of the simulator is paramount; reducing computational costs and improving response time are crucial for broader applicability. Extending the approach beyond StarCraft II is another vital direction, applying the Learning Before Interaction (LBI) framework to more diverse multi-agent environments and tasks. Investigating different MARL algorithms within the LBI framework would help determine its overall effectiveness and robustness. A critical area for improvement lies in enhanced generalization capabilities. While LBI demonstrates promising zero-shot generalization, further research is needed to enhance its ability to handle unseen tasks and domains effectively. Finally, exploring more sophisticated world models with better long-term predictability could substantially enhance the accuracy and reliability of the generated interactions and plans.
More visual insights#
More on figures
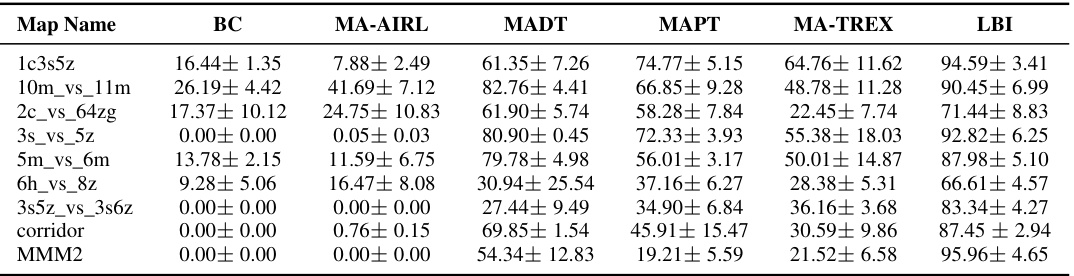
This figure illustrates the process of creating the VisionSMAC dataset and training the Vector Quantized Variational Autoencoder (VQ-VAE). State-based trajectories from the SMAC benchmark are first parsed to generate images and task descriptions using a parser. These images and descriptions, along with the original state-based trajectories, then serve as the input for VQ-VAE training, which learns to encode images into discrete tokens.
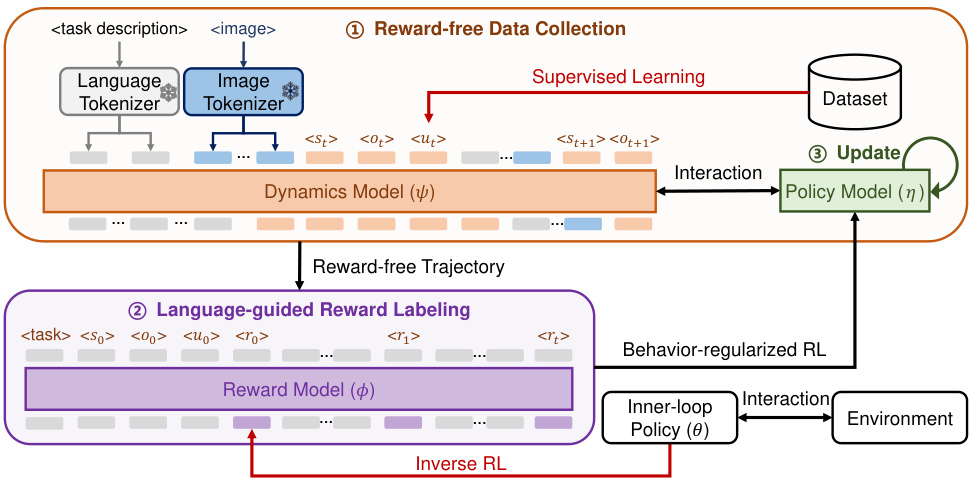
This figure shows a detailed overview of the Learning Before Interaction (LBI) framework. It begins with reward-free data collection, where the dynamics model is trained using language and image tokenizers to predict the next state and action. A language-guided reward labeling step then uses a reward model to infer rewards based on expert trajectories. These reward-free and reward-labeled trajectories are used to train the policy model via behavior-regularized reinforcement learning. The process involves an inner-loop policy used to generate data for reward model training and an interaction with an external environment to update the policy.

This figure visualizes the predictions of the dynamics and reward models. The top three rows show image sequences generated by the dynamics model for three different maps (MMM2, 3s_vs_5z, and 5m_vs_6m). The bottom row focuses on a specific scenario from the 5m_vs_6m map, highlighting the learned reward function for Agent 1 at a critical juncture where the agent has low health. The bar charts represent learned vs. game rewards for Agent 1’s actions (no-operation, stopping, moving in cardinal directions, and selecting an enemy to attack). The figure showcases the model’s ability to generate long-horizon, consistent trajectories and provide explainable reward functions for various situations.

This figure illustrates the process of creating the VisionSMAC dataset and training the VQ-VAE. The VisionSMAC dataset is created by converting state-based trajectories from the StarCraft Multi-Agent Challenge (SMAC) benchmark into images and language descriptions using a parser. The VQ-VAE is then trained on these images to generate discrete representations of each frame. These discrete representations are later used in the interactive simulator. The image shows the pipeline including the state-based trajectory data, a parser converting these into images and task descriptions, and the VQ-VAE training.

This figure illustrates the Learning Before Interaction (LBI) framework. It shows the process of reward-free data collection using an off-policy MARL algorithm to collect trajectories, followed by language-guided reward labeling using a reward model. The policy model is then updated using a behavior-regularized RL approach, improving the policy in the simulator environment. The final output is an image sequence generated by the interaction of the dynamics model and the converged policy.
This figure shows the overall architecture of the Learning Before Interaction (LBI) framework. It details the three main stages: reward-free data collection, language-guided reward labeling, and policy model update. The reward-free data collection stage uses a randomly initialized off-policy MARL algorithm to collect trajectories from the dynamics model. These trajectories are then used in the language-guided reward labeling stage, where the reward model assigns rewards to state-action pairs based on the trajectories and task descriptions. Finally, the policy model is updated using a behavior-regularized RL algorithm. This figure provides a high-level overview of the entire LBI process.

This figure shows the overview of the proposed Learning before Interaction (LBI) framework. It illustrates the three main stages: reward-free data collection, language-guided reward labeling, and policy updates. The reward-free data collection uses a randomly initialized off-policy MARL algorithm to generate reward-free trajectories using the dynamics model. The language-guided reward labeling uses the reward model to assign rewards to these trajectories using the task description. Finally, the policy model is updated using behavior-regularized RL, combining the reward-free trajectories and the language-guided rewards. The LBI framework aims to leverage a generative world model (consisting of a dynamics and a reward model) for improved multi-agent decision making.
More on tables

This table presents a comparison of the test return and standard deviations achieved by the proposed Learning Before Interaction (LBI) method and several existing offline reinforcement learning methods, including BCQ-MA, CQL-MA, ICQ, OMAR, and OMIGA, across four different StarCraft II maps: 5m_vs_6m, 2c_vs_64zg, 6h_vs_8z, and corridor. The results showcase LBI’s superior performance in terms of average return compared to other methods on the selected maps.

This table presents the results of applying the LBI model and two baseline models (MADT and MA-TREX) on unseen tasks from the StarCraft Multi-Agent Challenge benchmark. It demonstrates the zero-shot generalization capabilities of the LBI model, showing its ability to perform well on tasks not seen during training, unlike the baseline models. The table displays the win rates (percentage of games won) and their standard deviations across different unseen scenarios, highlighting the superior performance of LBI.
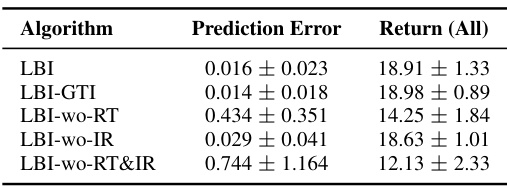
This table presents the ablation study of the dynamics model. It shows the prediction error and return (average return across all training maps) for different configurations of the dynamics model: - LBI: The complete dynamics model. - LBI-GTI: Using ground truth images for state prediction. - LBI-wo-RT: Removing the residual term in the dynamics model. - LBI-wo-IR: Removing the image reference in the dynamics model. - LBI-wo-RT&IR: Removing both the residual term and image reference in the dynamics model. The results show the impact of each component on the model’s performance.

This table presents the ablation study results on the reward model. It shows the impact of removing the reward constraint (wo-RC), the behavior regularization (wo-BR), and using ground-truth rewards (w-GTR) on the model’s performance. The results are broken down by return on training and unseen tasks, allowing for an analysis of how each component contributes to the overall performance. The table helps to determine the importance of each component in the model’s design and effectiveness.

This table shows the distribution of returns obtained during the training phase across ten different maps in the StarCraft Multi-Agent Challenge (SMAC) benchmark. Each map presents a unique set of challenges for the multi-agent system, resulting in varying levels of success. The average return across all ten maps was 19.64 ± 1.63. This information provides insight into the difficulty and variability of the training environment.
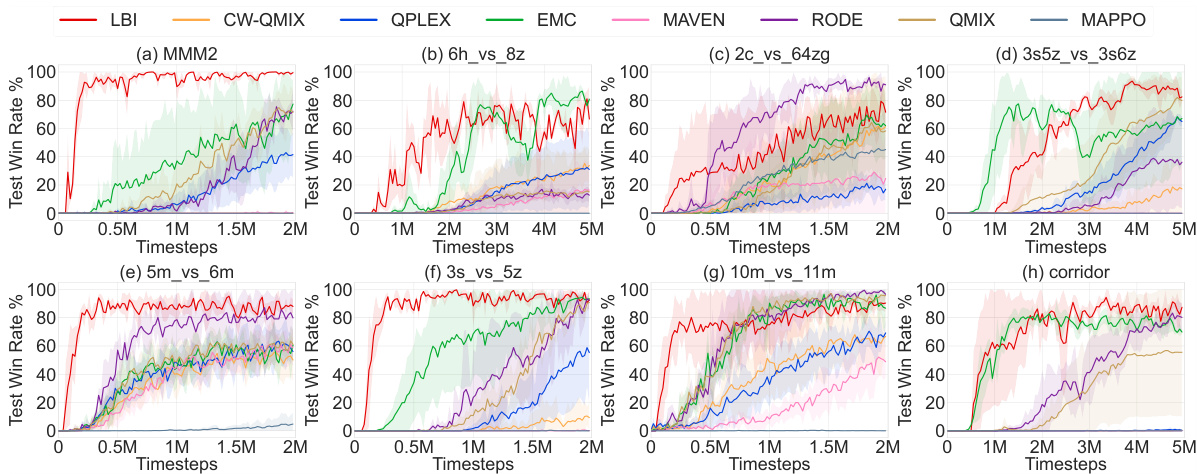
This table compares the test win rates and standard deviations of the proposed LBI method against several other imitation learning methods across various StarCraft II maps. It shows LBI’s performance in comparison to baselines, highlighting the method’s effectiveness in multi-agent decision-making tasks.
This table presents the test win rates and standard deviations achieved by the proposed Learning Before Interaction (LBI) method and several imitation learning baselines across various StarCraft Multi-Agent Challenge (SMAC) maps. The results demonstrate LBI’s superior performance compared to the baseline methods. The maps represent different complexities and scenarios in the SMAC benchmark.

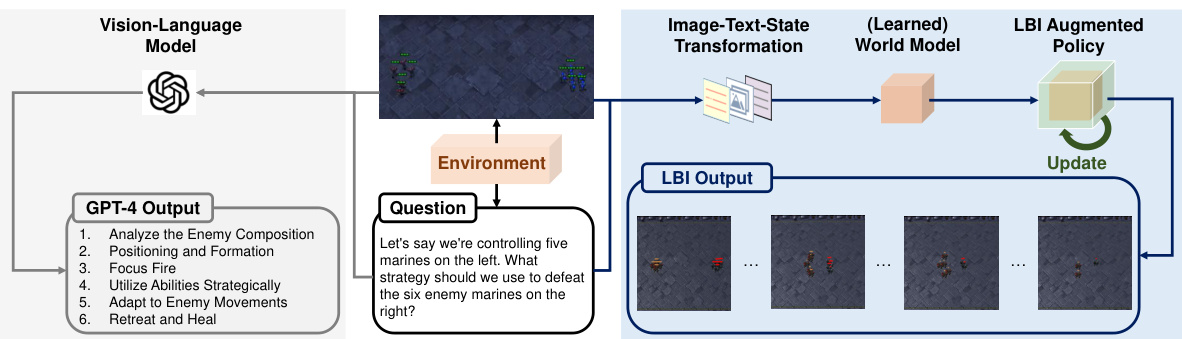
This table presents the test win rates and standard deviations achieved by the proposed Learning Before Interaction (LBI) method and several imitation learning baselines across multiple StarCraft II maps. It compares the performance of LBI against methods such as Behavior Cloning (BC), Multi-Agent Adversarial Inverse Reinforcement Learning (MA-AIRL), Multi-Agent Decision Transformer (MADT), Multi-Agent TREX (MA-TREX), and Multi-Agent Preference-based Return Transformer (MAPT). The results show LBI’s significantly higher win rates and better performance in most scenarios.
Full paper#